
Extraer automáticamente conceptos y palabras clave de un texto (Parte I: Los métodos tradicionales)
Publicado: 2022-02-22En el departamento de I+D de Oncrawl, buscamos cada vez más mejorar el contenido semántico de sus páginas web. Utilizando modelos de Machine Learning para el procesamiento del lenguaje natural (PNL), podemos comparar el contenido de tus páginas en detalle, crear resúmenes automáticos, completar o corregir las etiquetas de tus artículos, optimizar el contenido según tus datos de Google Search Console , etc.
En un artículo anterior, hablamos sobre la extracción de contenido de texto de páginas HTML. En esta ocasión, nos gustaría hablar sobre la extracción automática de palabras clave de un texto. Este tema se dividirá en dos posts:
- el primero cubrirá el contexto y los llamados métodos “tradicionales” con varios ejemplos concretos
- el segundo, que llegará pronto, se ocupará de enfoques más semánticos basados en transformadores y métodos de evaluación para comparar estos diferentes métodos
Contexto
Más allá de un título o un resumen, qué mejor manera de identificar el contenido de un texto, un artículo científico o una página web que con unas pocas palabras clave. Es una forma sencilla y muy eficaz de identificar el tema y los conceptos de un texto mucho más extenso. También puede ser una buena forma de categorizar una serie de textos: identificarlos y agruparlos por palabras clave. Los sitios que ofrecen artículos científicos como PubMed o arxiv.org pueden ofrecer categorías y recomendaciones basadas en estas palabras clave.
Las palabras clave también son muy útiles para indexar documentos muy grandes y para la recuperación de información, un campo de especialización muy conocido por los motores de búsqueda.
La falta de palabras clave es un problema recurrente en la categorización automática de artículos científicos [1]: muchos artículos no tienen palabras clave asignadas. Por lo tanto, se deben encontrar métodos para extraer automáticamente conceptos y palabras clave de un texto. Para evaluar la relevancia de un conjunto de palabras clave extraído automáticamente, los conjuntos de datos a menudo comparan las palabras clave extraídas por un algoritmo con palabras clave extraídas por varios humanos.
Como puedes imaginar, este es un problema que comparten los buscadores a la hora de categorizar las páginas web. Una mejor comprensión de los procesos automatizados de extracción de palabras clave permite comprender mejor por qué una página web se posiciona para tal o cual palabra clave. También puede revelar lagunas semánticas que impiden que se clasifique bien para la palabra clave a la que se ha dirigido.
Obviamente, hay varias formas de extraer palabras clave de un texto o un párrafo. En este primer post, describiremos los llamados enfoques “clásicos”.
[Ebook] SEO de datos: la próxima gran aventura
 Leer el libro electrónico
Leer el libro electrónicoRestricciones
Sin embargo, tenemos algunas limitaciones y requisitos previos en la elección de un algoritmo:
- El método debe poder extraer palabras clave de un solo documento. Algunos métodos requieren un corpus completo, es decir, varios cientos o incluso miles de documentos. Aunque estos métodos pueden ser utilizados por los motores de búsqueda, no serán útiles para un solo documento.
- Estamos en un caso de Machine Learning no supervisado. No disponemos de un conjunto de datos en francés, inglés u otros idiomas con datos anotados. En otras palabras, no tenemos miles de documentos con palabras clave ya extraídas.
- El método debe ser independiente del dominio/campo léxico del documento. Queremos poder extraer palabras clave de cualquier tipo de documento: artículos de noticias, páginas web, etc. Tenga en cuenta que algunos conjuntos de datos que ya tienen palabras clave extraídas para cada documento suelen ser de dominio específico de medicina, informática, etc.
- Algunos métodos se basan en modelos de etiquetado POS, es decir, la capacidad de un modelo NLP para identificar palabras en una oración por su tipo gramatical: un verbo, un sustantivo, un determinante. Determinar la importancia de una palabra clave que es un sustantivo en lugar de un determinante es claramente relevante. Sin embargo, según el idioma, los modelos de etiquetado de POS a veces tienen una calidad muy desigual.
Sobre los métodos tradicionales
Diferenciamos entre los llamados métodos “tradicionales” y los más recientes que utilizan técnicas de NLP – Natural Language Processing – como las incrustaciones de palabras y las incrustaciones contextuales. Este tema se tratará en una publicación futura. Pero primero, volvamos a los enfoques clásicos, distinguimos dos de ellos:
- el enfoque estadístico
- el enfoque gráfico
El enfoque estadístico se basará principalmente en las frecuencias de las palabras y su concurrencia. Partimos de hipótesis simples para construir heurísticas y extraer palabras importantes: una palabra muy frecuente, una serie de palabras consecutivas que aparecen varias veces, etc. Los métodos basados en grafos construirán un grafo donde cada nodo puede corresponder a una palabra, grupo de palabras u oración. Luego, cada arco puede representar la probabilidad (o frecuencia) de observar estas palabras juntas.
Aquí hay algunos métodos:
- Basado en estadísticas
- TF-FDI
- RASTRILLO
- Yake
- basado en gráficos
- Rango de texto
- TopicRank
- Rango único
Todos los ejemplos dados usan texto tomado de esta página web: Jazz au Tresor: John Coltrane – Impressions Graz 1962.
Enfoque estadístico
Le presentaremos los dos métodos Rake y Yake. En un contexto de SEO, es posible que haya oído hablar del método TF-IDF. Pero como requiere un corpus de documentos, no lo trataremos aquí.
RASTRILLO
RAKE significa extracción automática rápida de palabras clave. Hay varias implementaciones de este método en Python, incluido rake-nltk. La puntuación de cada palabra clave, que también se llama frase clave porque contiene varias palabras, se basa en dos elementos: la frecuencia de las palabras y la suma de sus co-ocurrencias. La constitución de cada frase clave es muy sencilla, consta de:
- cortar el texto en oraciones
- cortar cada frase en frases clave
En la siguiente oración, tomaremos todos los grupos de palabras separados por elementos de puntuación o stopwords:
Justo antes, Coltrane dirigía un quinteto, con Eric Dolphy a su lado y Reggie Workman al contrabajo.
Esto podría resultar en las siguientes frases clave:
"Just before", "Coltrane", "head", "quintet", "Eric Dolphy", "sides", "Reggie Workman", "double bass" .
Tenga en cuenta que las palabras vacías son una serie de palabras muy frecuentes como " the ", " in ", "y" or " it ". Como los métodos clásicos a menudo se basan en el cálculo de la frecuencia de aparición de las palabras, es importante elegir las palabras vacías con cuidado. La mayoría de las veces, no queremos tener palabras como >"to" , "the" or "de" en nuestras propuestas de frases clave. De hecho, estas palabras vacías no están asociadas con un campo léxico específico y, por lo tanto, son mucho menos relevantes que las palabras “ jazz ” o “ saxophone ”, por ejemplo.

Una vez que hemos aislado varias frases clave candidatas, les damos una puntuación según la frecuencia de las palabras y las co-ocurrencias. Cuanto mayor sea la puntuación, más relevantes se supone que son las frases clave.
Probemos rápidamente con el texto del artículo sobre John Coltrane.
# fragmento de python para rake de rake_nltk importar rastrillo # supongamos que ya tiene el artículo en la variable 'texto' rastrillo = rastrillo (palabras vacías = FRENCH_STOPWORDS, max_length = 4) rake.extract_keywords_from_text(texto) rake_keyphrases = rake.get_ranked_phrases_with_scores()[:TOP]
Aquí están las primeras 5 frases clave:
“radio pública nacional de austria”, “picos líricos más celestiales”, “graz tiene dos peculiaridades”, “john coltrane saxofón tenor”, “solo versión grabada”
Hay algunos inconvenientes en este método. El primero es la importancia de la elección de las palabras vacías porque se utilizan para dividir una oración en frases clave candidatas. La segunda es que cuando las frases clave son demasiado largas, a menudo tendrán una puntuación más alta debido a la concurrencia de las palabras presentes. Para limitar la longitud de las frases clave, hemos establecido el método con max_length=4 .
Yake
YAKE significa Otro extractor de palabras clave. Este método se basa en el siguiente artículo YAKE! Extracción de palabras clave de documentos individuales utilizando múltiples características locales que datan de 2020. Es un método más reciente que RAKE cuyos autores propusieron una implementación de Python disponible en Github.
En cuanto a RAKE, nos basaremos en la frecuencia de palabras y la co-ocurrencia. Los autores también agregarán algunas heurísticas interesantes:
- distinguiremos entre palabras en minúsculas y palabras en mayúsculas (ya sea la primera letra o la palabra completa). Supondremos aquí que las palabras que comienzan con una letra mayúscula (excepto al comienzo de una oración) son más relevantes que otras: nombres de personas, ciudades, países, marcas. Este es el mismo principio para todas las palabras en mayúsculas.
- la puntuación de cada frase clave candidata dependerá de su posición en el texto. Si las frases clave candidatas aparecen al principio del texto, tendrán una puntuación más alta que si aparecen al final. Por ejemplo, los artículos de noticias suelen mencionar conceptos importantes al comienzo del artículo.
# fragmento de Python para Yake desde yake importar KeywordExtractor como Yake yake = Yake(lan="fr", stopwords=FRENCH_STOPWORDS) yake_keyphrases = yake.extract_keywords(texto)
Al igual que RAKE, estos son los 5 mejores resultados:
“Tesoro Jazz”, “John Coltrane”, “Impresiones Graz”, “Graz”, “Coltrane”
A pesar de algunas duplicaciones de ciertas palabras en algunas frases clave, este método parece bastante interesante.
Enfoque gráfico
Este tipo de enfoque no está muy lejos del enfoque estadístico en el sentido de que también calcularemos las co-ocurrencias de palabras. El sufijo Rank asociado con algunos nombres de métodos, como TextRank , se basa en el principio del algoritmo PageRank para calcular la popularidad de cada página en función de sus enlaces entrantes y salientes.
[Ebook] Automatización de SEO con Oncrawl
 Leer el libro electrónico
Leer el libro electrónicoRango de texto
Este algoritmo proviene del artículo TextRank: Bringing Order into Texts de 2004 y se basa en los mismos principios que el algoritmo PageRank . Sin embargo, en lugar de construir un gráfico con páginas y enlaces, construiremos un gráfico con palabras. Cada palabra se vinculará con otras palabras según su co-ocurrencia.
Hay varias implementaciones en Python. En este artículo, presentaré pytextrank. Romperemos una de nuestras restricciones sobre el etiquetado de POS. De hecho, al construir el gráfico, no incluiremos todas las palabras como nodos. Solo se tendrán en cuenta verbos y sustantivos. Al igual que los métodos anteriores que usan palabras vacías para filtrar candidatos irrelevantes, el algoritmo TextRank usa el tipo gramatical de palabras.
Aquí hay un ejemplo de una parte del gráfico que será construido por el algoritmo: 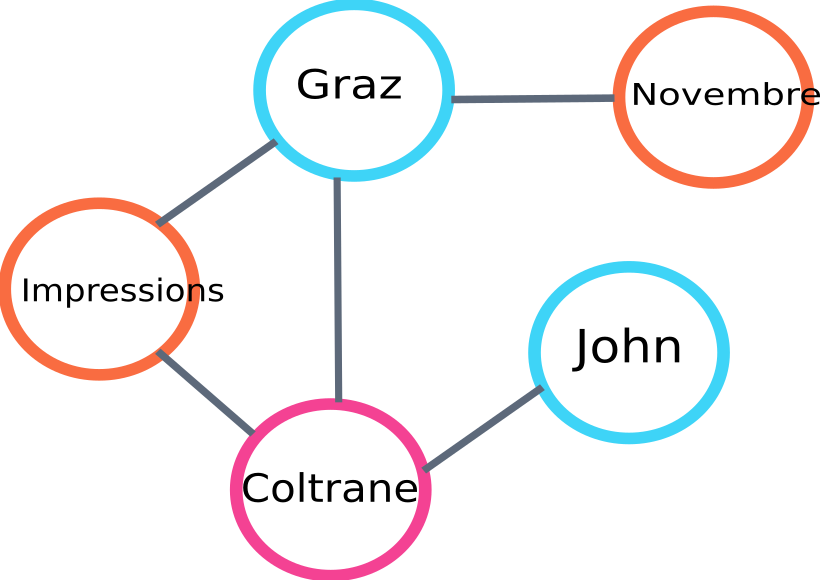
ejemplo de gráfico de clasificación de texto
Aquí hay un ejemplo de uso en Python. Tenga en cuenta que esta implementación utiliza el mecanismo de canalización de la biblioteca spaCy. Es esta biblioteca la que puede realizar el etiquetado de POS.
# fragmento de python para pytextrank
espacio de importación
importar pytextrank
# cargar un modelo francés
nlp = espacioso.load("fr_core_news_sm")
# agregar pytextrank a la tubería
nlp.add_pipe("clasificación de texto")
doc = pnl(texto)
textrank_keyphrases = doc._.frases
Estos son los 5 mejores resultados:
“Copenhague”, “noviembre”, “Impressions Graz”, “Graz”, “John Coltrane”
Además de extraer frases clave, TextRank también extrae oraciones. Esto puede ser muy útil para hacer los llamados “resúmenes extractivos”; este aspecto no se tratará en este artículo.
Conclusiones
Entre los tres métodos probados aquí, los dos últimos nos parecen bastante relevantes para el tema del texto. Para comparar mejor estos enfoques, obviamente tendríamos que evaluar estos diferentes modelos en una mayor cantidad de ejemplos. De hecho, existen métricas para medir la relevancia de estos modelos de extracción de palabras clave.
Las listas de palabras clave producidas por estos llamados modelos tradicionales proporcionan una base excelente para comprobar que sus páginas están bien orientadas. Además, dan una primera aproximación de cómo un buscador podría entender y clasificar el contenido.
Por otro lado, también se pueden usar otros métodos que usan modelos NLP pre-entrenados como BERT para extraer conceptos de un documento. Al contrario del llamado enfoque clásico, estos métodos suelen permitir una mejor captura de la semántica.
¡Los diferentes métodos de evaluación, incrustaciones contextuales y transformadores se presentarán en un segundo artículo sobre el tema!
Aquí está la lista de palabras clave extraídas de este artículo con uno de los tres métodos mencionados:
“métodos”, “palabras clave”, “frases clave”, “texto”, “palabras clave extraídas”, “procesamiento del lenguaje natural”
Referencias bibliográficas
- [1] Extracción automática de palabras clave mejorada dado un mayor conocimiento lingüístico, Anette Hulth, 2003
- [2] Extracción automática de palabras clave de documentos individuales, Stuart Rose et. al, 2010
- [3] ¡YA! Extracción de palabras clave de documentos individuales usando múltiples características locales, Ricardo Campos et. al, 2020
- [4] TextRank: poner orden en los textos, Rada Mihalcea et. al, 2004
Comience su prueba gratuita de 14 días
 Comience su prueba
Comience su prueba