
Autenticidad, Dalle-2 y Midjourney y nuestra fascinación por las imágenes y el arte generados por IA
Publicado: 2022-08-04Este artículo trata sobre la tecnología detrás de plataformas como Dalle-2 y Midjourney, y por qué los creadores de Open AI deberían potencialmente pagarle dinero, no cobrarle...
Cada vez más personas en Internet están nombrando a Dalle-2 y Open AI como una estafa. La razón es que Dalle-2 ahora se está convirtiendo repentinamente en un servicio monetizado, donde necesita comprar créditos, si usa la plataforma más allá del límite beta.
DALLE 2 es solo una de las muchas plataformas nuevas que le ofrecen acceso a contenido generado por IA y afirma que puede usarlo con fines comerciales. Otras plataformas incluyen Midjourney, Jasper Art, Nightcafe, Starry AI y Craiyon. Nos centraremos en Dalle 2 en esta publicación de blog, pero son casi idénticos cuando se trata de desafíos y problemas legales.
La estafa es una declaración bastante dura en nuestra opinión, pero existe un problema obvio al usar datos que otras personas han creado (fotos, videos, anotaciones, personas en las imágenes, etc.) y luego comenzar a venderlos a las mismas personas.
Muchos de nosotros podemos pasar por alto este problema, simplemente porque estamos fascinados con la nueva tecnología. Algo que es totalmente comprensible.
Sin embargo, aunque DALL-E 2 al final del día es solo una máquina avanzada de reconocimiento de patrones, su salida no es neutral y los patrones no provienen del aire fresco.
Se basan en toneladas de datos, donde hay múltiples preguntas legales que hacer. Preguntas que son importantes para ti como usuario potencial de las imágenes que generas.
 Imagen creada por DALLE-2
Imagen creada por DALLE-2
Los modelos de IA no se pueden comparar con los seres humanos
Debe comenzar leyendo este brillante artículo en Engadget, antes de comenzar a considerar el uso de imágenes DALL-E 2 con fines comerciales.
En el artículo de Engadget señalan otra cosa muy importante. A saber, el hecho de que DALL-E 2 y OpenAI NO están renunciando a su propio derecho a comercializar imágenes que los usuarios crean usando DALL-E. Básicamente, lo que significa que puede generar imágenes que luego venderán comercialmente a otros.
Esto muestra que las intenciones son muy diferentes a la analogía que a veces se usa, donde los promotores de DALLE-2 lo compararán con un estudiante que lee el trabajo de un autor establecido. En este ejemplo, el estudiante puede aprender los estilos y patrones del autor y luego encontrarlos aplicables en otros contextos y reutilizarlos allí.
Sin embargo, no se trata de un cerebro humano que usa la memoria creativa para crear nuevos trabajos creativos. Se trata de una máquina de reconocimiento de patrones que reutiliza y, en algunos casos, reproduce datos de entrenamiento en imágenes que luego se usan o incluso se venden comercialmente. Son simplemente dos mundos diferentes, tanto metafórica como literalmente hablando.
 Foto real del mundo real.
Foto real del mundo real.
Promesa de autenticidad de JumpStory
Este artículo es para las personas que desean comprender en un nivel más profundo cómo funciona esta nueva tecnología de generación de imágenes de IA. Pero antes de comenzar, solo algunas palabras sobre por qué JumpStory no está construyendo actualmente una máquina similar.
Por supuesto, nos han hecho esa pregunta varias veces. Sobre todo teniendo en cuenta que ya usamos IA en nuestra empresa y que tenemos acceso a millones de imágenes auténticas.
Sin embargo, esta no es una discusión tecnológica para nosotros, sino ética. Una discusión que ha resultado en nuestra Promesa de Autenticidad.
Estamos fundamentalmente en contra de un futuro en el que las imágenes generadas por IA se conviertan en la norma y no en la excepción. Llámenos anticuados, pero creemos que el mundo REAL es hermoso.
Estamos orgullosos de que nuestras fotos y videos retraten a seres humanos reales en diferentes formas y tamaños. No estamos en contra del uso de la IA, pero no creemos que deba usarse para generar personas o realidades falsas.
Tecnologías como los medios sintéticos y DALL-E 2 pueden ser fascinantes en la superficie, pero también representan un riesgo real. Corren el riesgo de desdibujar las líneas entre lo real y lo falso, lo que será una amenaza fundamental para la confianza entre los seres humanos.
Es por eso que JumpStory no usa inteligencia artificial para generar imágenes falsas, sino que usa IA para identificar qué imágenes son originales, auténticas y, por supuesto, legales para usar con fines comerciales.

Estas son las imágenes que encuentra usando nuestro servicio, y hemos llamado a nuestro enfoque 'Inteligencia Auténtica'.
Comprender cómo se generan las imágenes de IA
Suficiente sobre JumpStory y los problemas legales con DALL-E 2 por ahora. Veamos cómo se generan las imágenes de IA en plataformas como DALLE-2, Imagen, Crayion (anteriormente Dall-E Mini), Midjourney, etc. … Usando DALLE-2 como el ejemplo más publicitado actualmente.
Para empezar, DALLE-2 puede realizar diferentes tipos de tareas, pero en esta entrada de blog nos centraremos en la tarea de generación de imágenes.
Cómo funciona es que se ingresa un mensaje de texto en un codificador de texto. Este codificador está entrenado para mapear el aviso a un espacio de representación. Posteriormente, un llamado modelo anterior asigna el texto codificado a una codificación de imagen correspondiente que captura la información semántica del indicador de codificación de texto.
(Si esto ya se está poniendo un poco geek, lo siento mucho, pero se pondrá aún peor)
El paso final para el codificador de imágenes es generar una imagen que visualice la información semántica que recibió el codificador. Estos son los conceptos básicos de máquinas como Open AI.
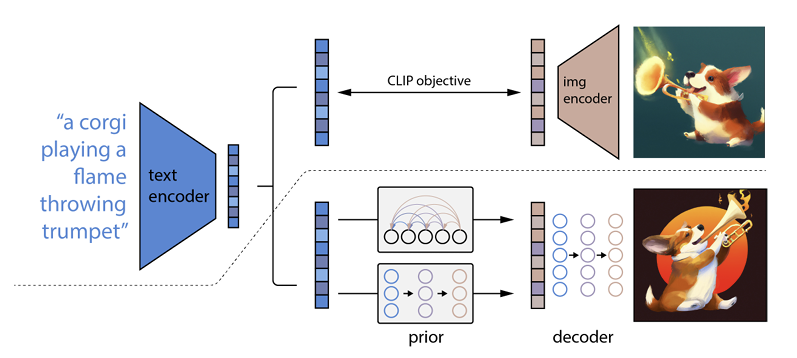
La relación entre el texto y las imágenes.
DALL-E 2 y tecnologías similares a menudo se denominan generadores de texto a imagen. La razón es su capacidad para recibir una entrada de texto y entregar una salida de imagen.
Para darte un ejemplo esto es “Un astronauta montando un caballo al estilo de Andy Warhol:

fuente: DALLE-2
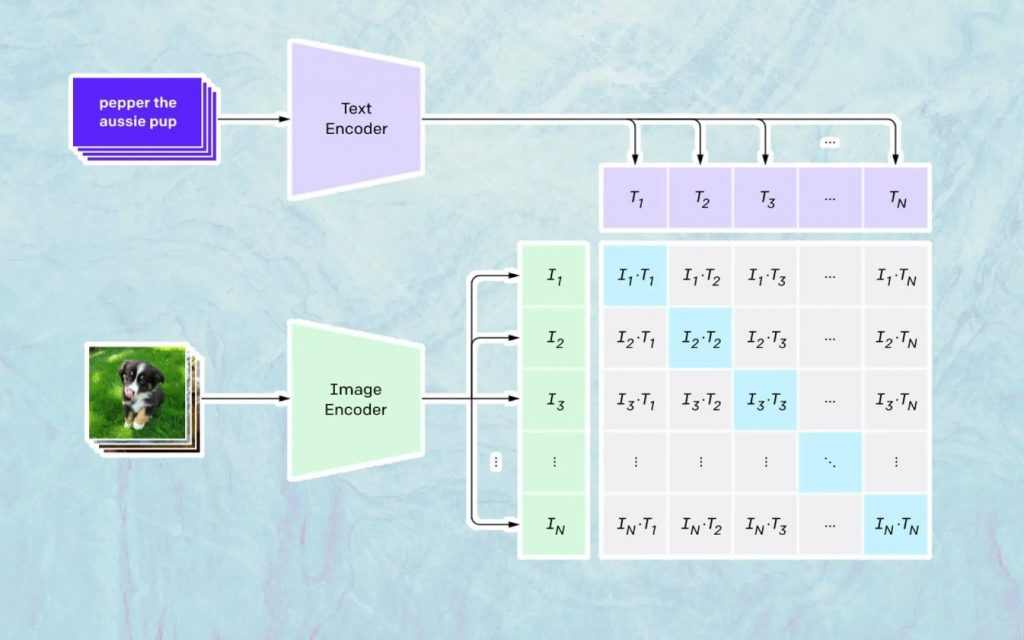
Lo que sucede aquí se basa en el modelo de Open AI llamado CLIP. CLIP es la abreviatura de "Entrenamiento previo de imágenes de lenguaje contrastivo" y es un modelo muy complejo entrenado en millones de imágenes y subtítulos.
En lo que CLIP es especialmente bueno es en comprender cuánto se relaciona un texto en particular con una imagen en particular. La clave aquí no es el pie de foto, sino qué tan relacionado está un pie de foto determinado con una imagen determinada.
Este tipo de tecnología se llama 'contrastiva', y lo que CLIP es capaz de hacer es aprender la semántica del lenguaje natural. La forma en que CLIP ha aprendido esto es a través de un proceso, donde el objetivo es (ahora citando la documentación tecnológica): “maximizar simultáneamente la similitud de coseno entre N pares de imágenes/títulos codificados correctamente y minimizar la similitud de coseno entre N 2 – N imágenes codificadas incorrectas /pares de subtítulos”.
Generando las imágenes
Como se describió anteriormente, el modelo CLIP aprende un espacio de representación en el que puede determinar cómo se relacionan las codificaciones de imágenes y textos.
La siguiente tarea es usar este espacio para generar imágenes. Para este propósito, Open AI ha desarrollado otro modelo llamado GLIDE, que puede usar la entrada de CLIP y, usando un modelo de difusión, realizar la generación de imágenes.
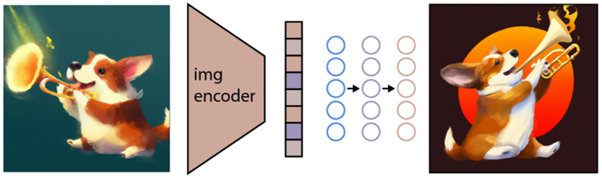
Para explicar brevemente qué es un modelo de difusión, es básicamente un modelo que aprende a generar datos invirtiendo un proceso de ruido gradual. Lamento que esto ahora se vuelva muy técnico, así que para citar una descripción que se encuentra en la documentación de Open AI:
“El proceso de generación de ruido se ve como una cadena de Markov parametrizada que gradualmente agrega ruido a una imagen para corromperla, lo que finalmente (asintóticamente) da como resultado un ruido gaussiano puro. El modelo de difusión aprende a navegar hacia atrás a lo largo de esta cadena, eliminando gradualmente el ruido en una serie de pasos de tiempo para revertir este proceso”.

Si quieres profundizar aún más en la tecnología, te recomendamos leer este excelente artículo de Ryan O'Connor.