
Cómo responder preguntas de datos complejas con datos de Oncrawl, fuera de Oncrawl
Publicado: 2022-01-04Una de las ventajas de Oncrawl para SEO empresarial es tener acceso completo a sus datos sin procesar. Ya sea que esté conectando sus datos de SEO a un BI o un flujo de trabajo de ciencia de datos, realizando sus propios análisis o trabajando dentro de las pautas de seguridad de datos para su organización, los datos de auditoría de sitio web y SEO sin procesar pueden servir para muchos propósitos.
Hoy veremos cómo usar los datos de Oncrawl para responder preguntas complejas sobre datos.
¿Qué es una pregunta de datos complejos?
Las preguntas de datos complejos son preguntas que no se pueden responder con una simple búsqueda en la base de datos, pero requieren procesamiento de datos para obtener la respuesta.
Aquí hay algunos ejemplos comunes de preguntas de datos "complejas" que los SEO suelen tener:
- Crear una lista de todos los enlaces que apuntan a páginas que redirigen a otras páginas con un estado 404
- Crear una lista de todos los enlaces y su texto de anclaje que apunta a páginas en una segmentación basada en métricas que no son de URL
Cómo responder preguntas de datos complejas en Oncrawl
La estructura de datos de Oncrawl está diseñada para permitir que casi todos los sitios busquen datos casi en tiempo real. Esto implica almacenar diferentes tipos de datos en diferentes conjuntos de datos para garantizar que los tiempos de búsqueda se mantengan al mínimo en la interfaz. Por ejemplo, almacenamos todos los datos asociados con las URL en un conjunto de datos: código de respuesta, número de enlaces salientes, tipo de datos estructurados presentes, número de palabras, número de visitas orgánicas... Y almacenamos todos los datos relacionados con los enlaces en un conjunto de datos separado: destino del enlace, origen del enlace, texto de anclaje...
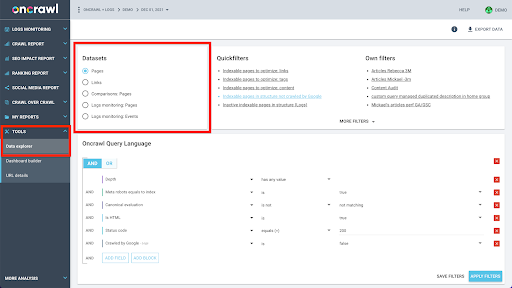
Unir estos conjuntos de datos es computacionalmente complejo y no siempre es compatible con la interfaz de la aplicación Oncrawl. Cuando esté interesado en buscar algo que requiera filtrar un conjunto de datos para buscar algo en otro, le recomendamos que manipule los datos sin procesar por su cuenta.
Dado que todos los datos de Oncrawl están disponibles para usted, hay muchas formas de unir conjuntos de datos y expresar consultas complejas.
En este artículo, veremos uno de ellos, usando Google Cloud y BigQuery, que es apropiado para conjuntos de datos muy grandes como los que encuentran muchos de nuestros clientes al examinar datos de sitios con grandes volúmenes de páginas.
Lo que necesitarás
Para seguir el método que discutiremos en este artículo, necesitará acceso a las siguientes herramientas:
- oncrawl
- La API de Oncrawl con Big Data Export
- Almacenamiento en la nube de Google
- BigQuery
- Una secuencia de comandos de Python para transferir datos de Oncrawl a BigQuery (lo desarrollaremos durante el artículo).
Antes de comenzar, deberá tener acceso a un informe de rastreo completo en Oncrawl.
Cómo aprovechar los datos de Oncrawl en Google BigQuery
El plan para el artículo de hoy es el siguiente:
- Primero, nos aseguraremos de que Google Cloud Storage esté configurado para recibir datos de Oncrawl.
- A continuación, usaremos una secuencia de comandos de Python para ejecutar las exportaciones de Big Data de Oncrawl para exportar los datos de un rastreo determinado a un depósito de Google Cloud Storage. Exportaremos dos conjuntos de datos: páginas y enlaces.
- Cuando haya terminado, crearemos un conjunto de datos en Google BigQuery. Luego, crearemos una tabla a partir de cada una de las dos exportaciones dentro del conjunto de datos de BigQuery.
- Finalmente, experimentaremos consultando los conjuntos de datos individuales y luego ambos conjuntos de datos juntos para encontrar la respuesta a una pregunta compleja.
Configuración dentro de Google Cloud para recibir datos de Oncrawl
Para ejecutar esta guía en un entorno de espacio aislado dedicado, le recomendamos que cree un nuevo proyecto de Google Cloud para aislarlo de sus proyectos existentes en curso.
Empecemos por la casa de Google Cloud.
Desde su página de inicio de Google Cloud, tiene acceso a muchas cosas además del almacenamiento en la nube. Estamos interesados en los depósitos de Cloud Storage, que están disponibles dentro del nivel de almacenamiento en la nube de Google Cloud Platform: 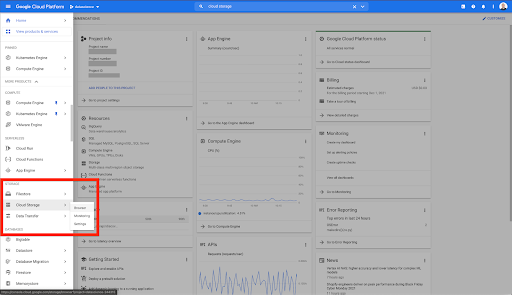
También puede acceder al navegador de Cloud Storage directamente en https://console.cloud.google.com/storage/browser.
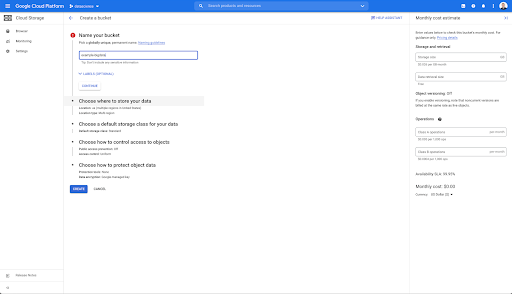
Luego, debe crear un depósito de almacenamiento en la nube y otorgar los permisos correctos para que la cuenta de servicio de Oncrawl pueda escribir en él, con el prefijo de su elección.
El depósito de Google Cloud Storage servirá como almacenamiento temporal para almacenar las exportaciones de Big Data de Oncrawl antes de cargarlas en Google BigQuery.
En este cubo, también he creado dos carpetas: "enlaces" y "páginas": 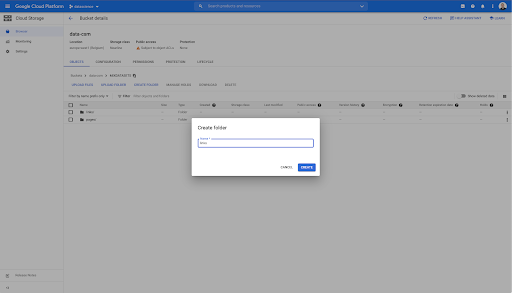
Exportación de conjuntos de datos desde Oncrawl
Ahora que hemos configurado el espacio donde queremos guardar los datos, necesitamos exportarlos desde Oncrawl. Exportar a un depósito de Google Cloud Storage con Oncrawl es particularmente fácil, ya que podemos exportar datos en el formato correcto y guardarlos directamente en el depósito. Esto elimina cualquier paso adicional.
Creación de una clave API
La exportación de datos de Oncrawl en formato Parquet para BigQuery requerirá el uso de una clave de API para actuar en la API mediante programación, en nombre del propietario de la cuenta de Oncrawl. La aplicación Oncrawl permite a los usuarios crear claves de API con nombre para que su cuenta esté siempre bien organizada y limpia. Las claves API también están asociadas con diferentes permisos (ámbitos) para que pueda administrar las claves y sus propósitos.
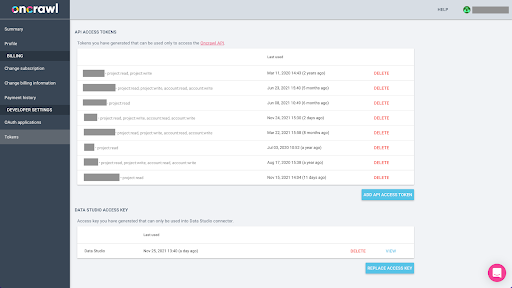
Llamemos a nuestra nueva clave 'Clave de sesión de conocimiento'. La función de exportación de Big Data requiere permisos de escritura en la cuenta, porque estamos creando las exportaciones de datos. Para realizar esto, necesitamos tener acceso de lectura en el proyecto y acceso de lectura y escritura en la cuenta.
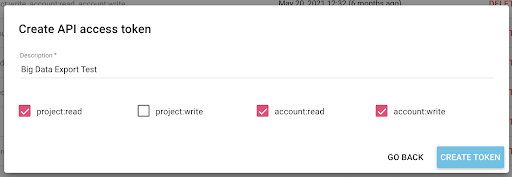
Ahora tenemos una nueva clave API, que copiaré en mi portapapeles.
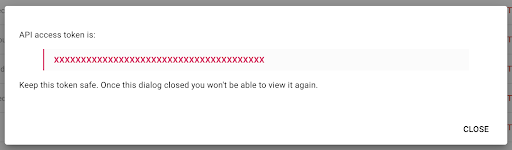
Tenga en cuenta que, por razones de seguridad, tiene la posibilidad de copiar la clave solo una vez . Si olvida copiar la clave, deberá eliminar la clave y crear una nueva.
Creando tu secuencia de comandos de Python
Construí un cuaderno de Google Colab para esto, pero compartiré el código a continuación para que puedas crear tus propias herramientas o tu propio cuaderno.
1. Almacene su clave API en una variable global
Primero, arrancamos el entorno y declaramos la clave API en una variable global llamada "Oncrawl Token". Luego, nos preparamos para el resto del experimento:
#@title Accede a la API Oncrawl
#@markdown Proporcione su token de API a continuación para permitir que este cuaderno acceda a sus datos de Oncrawl:
# TU TOKEN PARA LA API ONCRAWL
ONCRAWL_TOKEN = "" #@param {tipo:"cadena"}
!pip instalar prisión
desde IPython.display importar clear_output
borrar_salida()
imprimir('Todo cargado.') 
2. Cree una lista desplegable para elegir el proyecto de Oncrawl con el que desea trabajar
Luego, usando esa clave, queremos poder elegir el proyecto con el que queremos jugar al obtener la lista de proyectos y crear un widget desplegable a partir de esa lista. Al ejecutar el segundo bloque de código, lleve a cabo los siguientes pasos:
- Llamaremos a la API de Oncrawl para obtener la lista de los proyectos en la cuenta usando la clave de API que se acaba de enviar.
- Una vez que tenemos la lista del proyecto de la respuesta de la API, la formateamos como una lista utilizando el nombre del proyecto y la URL de inicio del proyecto.
- Almacenamos el ID del proyecto que se proporcionó en la respuesta.
- Creamos un menú desplegable y lo mostramos debajo del bloque de código.
#@title Seleccione el sitio web para analizar eligiendo el proyecto Oncrawl correspondiente
solicitudes de importación
prisión de importación
importar ipywidgets como widgets
importar json
# Obtener lista de proyectos
respuesta = solicitudes.get("https://app.oncrawl.com/api/v2/projects?limit={limit}&sort={sort}".format(
límite=1000,
sort='nombre:asc'
),
headers={ 'Autorización': 'Portador'+ONCRAWL_TOKEN }
)
json_res = respuesta.json()
#preparar menú desplegable para permitir que el usuario seleccione un proyecto
proyectos = []
para el elemento en json_res['proyectos']:
proyectos.append(('{} - {}'.format(elemento['nombre'], elemento['start_url']), elemento['id']))
salida = widgets.Salida()
dropdown_purpose = widgets.Dropdown(opciones = proyectos, descripción="Proyecto: ")
def dropdown_project_evenhandler(cambiar):
salida.clear_output()
con salida:
mostrar (proyectos)
dropdown_purpose.observe(dropdown_project_evenhandler, nombres='valor')
mostrar (desplegable_propósito) Desde el menú desplegable que esto crea, puede ver la lista completa del proyecto al que tiene acceso la clave API. 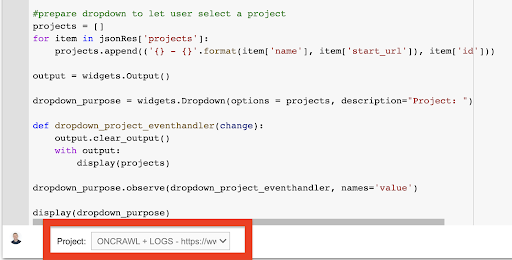
Para el propósito de la demostración de hoy, estamos usando un proyecto de demostración basado en el sitio web de Oncrawl.
3. Cree una lista desplegable para elegir el perfil de rastreo dentro del proyecto con el que desea trabajar
A continuación, decidiremos qué perfil de rastreo utilizar. Queremos elegir un perfil de rastreo dentro de este proyecto. El proyecto de demostración tiene muchas configuraciones de rastreo diferentes: 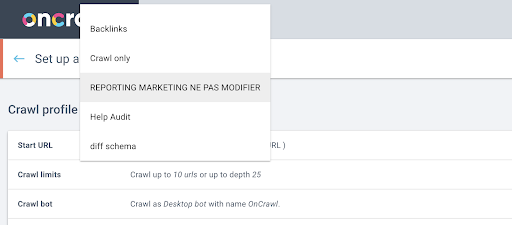
En este caso, estamos analizando un proyecto que los equipos de Oncrawl suelen utilizar para experimentos, por lo que voy a elegir el perfil de rastreo utilizado por el equipo de marketing para supervisar el rendimiento del sitio web de Oncrawl. Dado que se supone que este es el perfil de rastreo más estable, es una buena opción para el experimento de hoy.
Para obtener el perfil de rastreo, usaremos la API de Oncrawl, para solicitar el último rastreo dentro de cada perfil de rastreo del proyecto:
- Nos preparamos para consultar la API de Oncrawl para el proyecto dado.
- Solicitaremos todos los rastreos devueltos en orden descendente según su fecha de "creación".
solicitudes de importación
importar json
importar ipywidgets como widgets
project_id = menú desplegable_propósito.valor
# Obtenga detalles de los proyectos (incluya todos los rastreos en el proyecto)
proyecto = solicitudes.get("https://app.oncrawl.com/api/v2/projects/{}".format(project_id),
params=dict(include_nested_resources=True, sort="created_at:desc"),
headers={ 'Autorización': 'Portador'+ONCRAWL_TOKEN }).json()
# Rastreos de grupo por perfil de rastreo (nombre de rastreo)
rastreos_por_config = {}
probar:
para rastrear en el proyecto ['rastreos']:
si rastreo['estado'] en ["hecho"]:
si crawl['crawl_config']['name'] no está en crawls_by_config.keys():
crawls_by_config[rastrear['crawl_config']['name']] = {'crawl_ids' : [], 'is_crawl_archived' : False}
if len(crawls_by_config[crawl['crawl_config']['name']]['crawl_ids']) == 0:
crawls_by_config[rastrear['crawl_config']['name']]['crawl_ids'].append(rastrear['id'])
if rastrear['estado'] == "archivado":
crawls_by_config[crawl['crawl_config']['name']]['is_crawl_archived'] = Verdadero
excepto Excepción como e:
generar excepción ("error {}, {}". formato (e, proyecto))
# Cree la lista para la selección desplegable
lista = [("{} ({})".format(k, len(v['crawl_ids'])), k) para k, v en crawls_by_config.items()]
dropdown_crawl_configs = widgets.Dropdown(opciones = lista, descripción="Configuraciones de rastreo:")
def dropdown_cc_evenhandler(cambiar):
salida.clear_output()
con salida:
mostrar (rastreos_por_config)
si len(rastreos_por_config.valores()) == 0:
print('No se encontró rastreo en vivo en este proyecto')
dropdown_crawl_configs.observe(dropdown_cc_eventhandler, nombres='valor')
mostrar (dropdown_crawl_configs)Cuando se ejecuta este código, la API Oncrawl nos responderá con la lista de los rastreos descendiendo por la propiedad "creado en".
Luego, dado que solo queremos centrarnos en los rastreos que están terminados, repasaremos la lista de rastreos. Para cada rastreo individual con un estado de "hecho", guardaremos el nombre del perfil de rastreo y almacenaremos la identificación del rastreo.
Mantendremos como máximo un perfil de rastreo por rastreo para que no queramos exponer demasiados rastreos.
El resultado es este nuevo menú desplegable creado a partir de la lista de perfiles de rastreo del proyecto. Elegiremos el que queramos. Esto tomará el último rastreo ejecutado por el equipo de marketing: 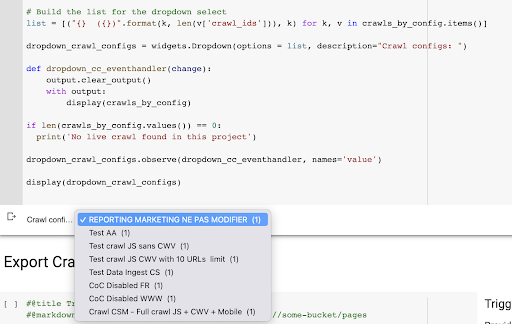
4. Identificar el último rastreo con el perfil que queremos usar
Ya tenemos el ID de rastreo asociado con el último rastreo en el perfil elegido. Está oculto en el diccionario de objetos "crawl_by_config". 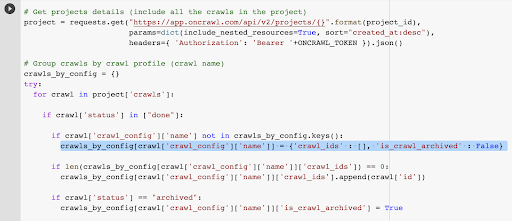
Puede verificar esto fácilmente en la interfaz: encuentre el último rastreo completado en este análisis de perfil. 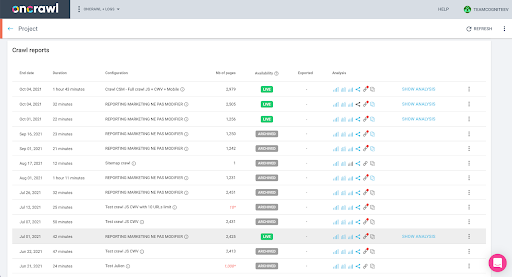
Si hacemos clic para ver el análisis, veremos que el ID de rastreo termina en E617. 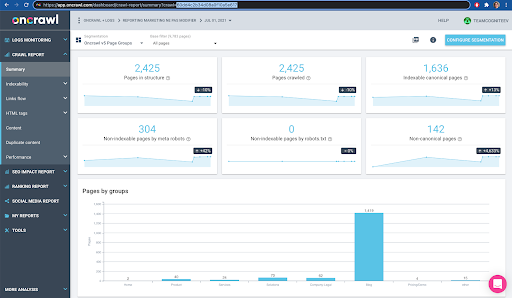
Solo tomemos nota del ID de rastreo para la demostración de hoy.
Por supuesto, si ya sabe lo que está haciendo, puede omitir los pasos que acabamos de cubrir para llamar a la API de Oncrawl para obtener la lista de proyectos y la lista de rastreos por perfil de rastreo: ya tiene el ID de rastreo de la interfaz, y esta ID es todo lo que necesita para ejecutar la exportación.
Los pasos que hemos seguido hasta ahora son simplemente para facilitar el proceso de obtener el último rastreo del perfil de rastreo dado del proyecto dado, dado a lo que tiene acceso la clave API. Esto puede ser útil si proporciona esta solución a otros usuarios o si busca automatizarla.
5. Exportar resultados de rastreo
Ahora, veremos el comando de exportación:
#@title Activar exportación de bigdata
#@markdown Proporcione su depósito de GCS y el prefijo gs://some-bucket/pages
# SU CUBO DE GCS
gcs_bucket = #@param {tipo:"cadena"}
gcs_prefix = #@param {tipo:"cadena"}
# Obtener el ID del último rastreo del proyecto/perfil de rastreo dado
list_crawl_ids = crawls_by_config[dropdown_crawl_configs.value]['crawl_ids']
last_crawl_id = list_crawl_ids[0]
# Carga útil de plantilla para consulta de exportación de datos
carga útil = {
"exportación_de_datos": {
"tipo_datos": 'página',
"resource_id": last_crawl_id,
"formato_de_salida": 'parquet',
"objetivo": 'gcs',
"parámetros_objetivo": {
"gcs_bucket": gcs_bucket,
"gcs_prefijo": gcs_prefijo
}
}
}
# Activar exportación
export = request.post("https://app.oncrawl.com/api/v2/account/data_exports", json=payload, headers={ 'Autorización': 'Portador'+ONCRAWL_TOKEN }).json()
# Muestra la respuesta de la API
mostrar (exportar)
# Almacenar ID de exportación para uso futuro
export_id = export['data_export']['id']Queremos exportar al depósito de Cloud Storage que configuramos anteriormente.
Dentro de eso vamos a exportar las páginas para el último ID de rastreo:
- El último ID de rastreo se obtiene de la lista de ID de rastreo, que se almacena en algún lugar del diccionario "crawls_by_config", que se creó en el paso 3.
- Queremos elegir el correspondiente al menú desplegable en el paso 4, por lo que usamos el atributo de valor del menú desplegable.
- Luego, extraemos el atributo crawl_ID. Esta es una lista. Mantendremos los 50 elementos principales en la lista. Necesitamos hacer esto porque en el paso 2, como recordará, cuando creamos el diccionario crawls_by_config, solo almacenamos una ID de rastreo por nombre de configuración.
Configuré campos de entrada para que sea más fácil proporcionar el depósito y el prefijo de Google Cloud Storage, o la carpeta, donde queremos enviar la exportación. 
A los efectos de la demostración, hoy escribiremos en la carpeta "mixed dataset", en una de las carpetas que ya configuré. Cuando configuramos nuestro depósito en Google Cloud Storage, recordará que preparé carpetas para la exportación de "enlaces" y para la exportación de "páginas".
Para la primera exportación, querremos exportar las páginas a la carpeta "páginas" para el último ID de rastreo utilizando el formato de archivo Parquet. 
En los resultados a continuación, verá la carga útil que se enviará al punto final de exportación de datos, que es el punto final para solicitar una exportación de Big Data usando una clave API:
# Carga útil de plantilla para consulta de exportación de datos
carga útil = {
"exportación_de_datos": {
"tipo_datos": 'página',
"resource_id": last_crawl_id,
"formato_de_salida": 'parquet',
"objetivo": 'gcs',
"parámetros_objetivo": {
"gcs_bucket": gcs_bucket,
"gcs_prefijo": gcs_prefijo
}
}
}
Este contiene varios elementos, incluido el tipo de conjunto de datos que desea exportar. Puede exportar el conjunto de datos de la página, el conjunto de datos de enlace, el conjunto de datos de clústeres o el conjunto de datos de datos estructurados. Si no sabe qué se puede hacer, puede ingresar un error aquí, y cuando llame a la API, recibirá un mensaje que indica que la elección del tipo de datos debe ser página, enlace, clúster o datos estructurados. El mensaje se ve así:

{'fields': [{'message': 'No es una opción válida. Debe ser uno de "página", "enlace", "clúster", "datos_estructurados".',
'nombre': 'tipo_datos',
'tipo': 'opción_inválida'}],
'tipo': 'invalid_request_parameters'}
Para el experimento de hoy, exportaremos el conjunto de datos de la página y el conjunto de datos del enlace en exportaciones separadas.
Comencemos con el conjunto de datos de la página. Cuando ejecuto este bloque de código, imprimí el resultado de la llamada API, que se ve así:
{'exportación_de_datos': {'tipo_de_datos': 'página',
'export_failure_reason': Ninguno,
'id': 'XXXXXXXXXXXXXXX',
'formato_de_salida': 'parqué',
'output_format_parameters': Ninguno,
'output_row_count': Ninguno,
'tamaño_de_salida_en_bytes: 1634460016000,
'id_recurso': '60dd4c2b34d08a0f10a5e617',
'estado': 'SOLICITADO',
'objetivo': 'gcs',
'parámetros_objetivo': {'gcs_bucket': 'datos-cms',
'gcs_prefix': 'MIXDATASETS/páginas/'}}}
Esto me permite ver que se solicitó la exportación.
Si queremos comprobar el estado de la exportación, es muy sencillo. Utilizando el ID de exportación que guardamos al final de este bloque de código, podemos solicitar el estado de la exportación en cualquier momento con la siguiente llamada a la API:
# ESTADO DE EXPORTACIÓN
export_status = request.get("https://app.oncrawl.com/api/v2/account/data_exports/{}".format(export_id), headers={ 'Autorización': 'Portador'+ONCRAWL_TOKEN }).json ()
mostrar (estado_exportación)
Esto indicará un estado como parte del objeto JSON devuelto:
{'exportación_de_datos': {'tipo_de_datos': 'página',
'export_failure_reason': Ninguno,
'id': 'XXXXXXXXXXXXXXX',
'formato_de_salida': 'parquet',
'output_format_parameters': Ninguno,
'output_row_count': Ninguno,
'tamaño_de_salida_en_bytes': Ninguno,
'solicitado_en': 1638350549000,
'id_recurso': '60dd4c2b34d08a0f10a5e617',
'estado': 'EXPORTANDO',
'objetivo': 'gcs',
'parámetros_objetivo': {'gcs_bucket': 'datos-csm',
'gcs_prefix': 'MIXDATASETS/páginas/'}}} Cuando se completa la exportación ( 'status': 'DONE' ), podemos volver a Google Cloud Storage.
Si buscamos en nuestro depósito y vamos a la carpeta "enlaces", no hay nada aquí todavía porque exportamos las páginas. 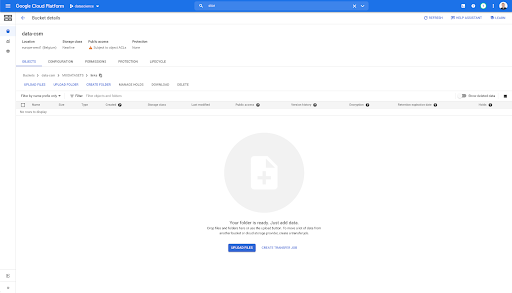
Sin embargo, cuando miramos en la carpeta "páginas", podemos ver que la exportación se ha realizado correctamente. Tenemos un archivo de Parquet: 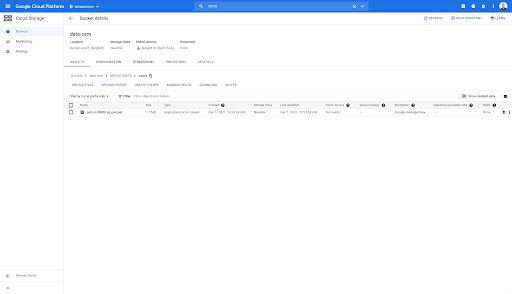
En esta etapa, el conjunto de datos de páginas está listo para importarse en BigQuery, pero primero repetiremos los pasos anteriores para obtener el archivo Parquet para los enlaces:
- Asegúrese de establecer el prefijo de los enlaces.
- Elija el tipo de datos "enlace".
- Vuelva a ejecutar este bloque de código para solicitar la segunda exportación.

Esto producirá un archivo Parquet en la carpeta "enlaces".
Creación de conjuntos de datos de BigQuery
Mientras se ejecuta la exportación, podemos avanzar y comenzar a crear conjuntos de datos en BigQuery e importar los archivos de Parquet en tablas separadas. Luego uniremos las mesas.
Lo que queremos hacer ahora es jugar con Google Big Query, que es algo disponible como parte de Google Cloud Platform. Puede usar la barra de búsqueda en la parte superior de la pantalla o ir directamente a https://console.cloud.google.com/bigquery.
Creación de un conjunto de datos para su trabajo
Tendremos que crear un conjunto de datos dentro de Google BigQuery: 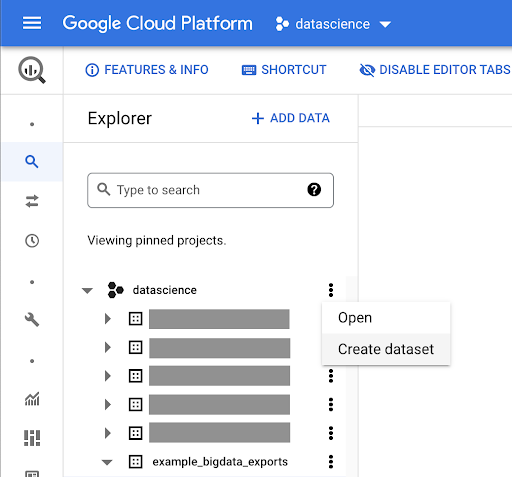
Deberá proporcionar un nombre al conjunto de datos y elegir la ubicación donde se almacenarán los datos. Esto es importante porque condicionará dónde se procesan los datos y no se puede cambiar. Esto puede tener un impacto si sus datos incluyen información cubierta por el RGPD u otras leyes de privacidad. 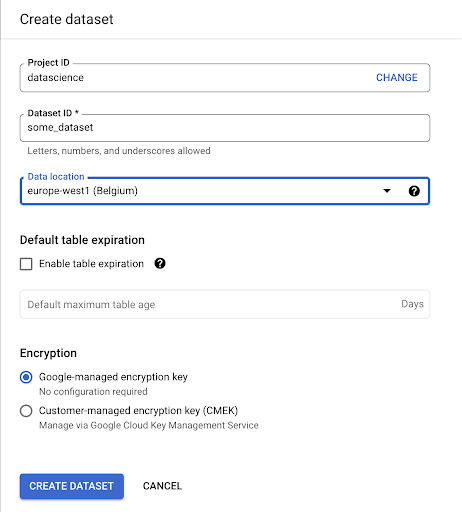
Este conjunto de datos está inicialmente vacío. Cuando lo abra, podrá crear una tabla, compartir el conjunto de datos, copiar, eliminar, etc.
Crear tablas para sus datos
Crearemos una tabla en este conjunto de datos. 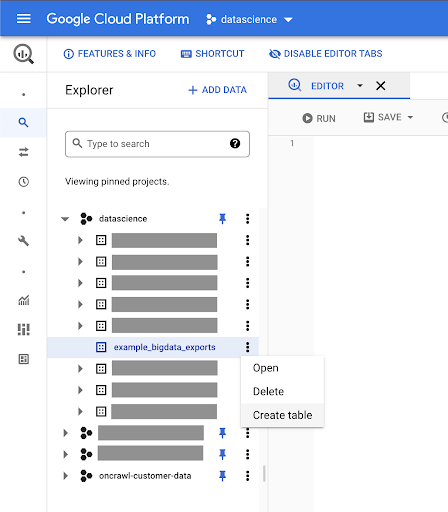
Puede crear una tabla vacía y luego proporcionar el esquema. El esquema es la definición de las columnas de la tabla. Puede definir el suyo propio o puede explorar Google Cloud Storage para elegir un esquema de un archivo.
Usaremos esta última opción. Navegaremos a nuestro cubo, luego a la carpeta "páginas". Elijamos el archivo de páginas. Solo hay un archivo, por lo que podemos seleccionar solo uno, pero si la exportación hubiera generado varios archivos, podríamos haberlos elegido todos. 
Cuando seleccionamos el archivo, automáticamente detecta que está en formato de archivo Parquet. Queremos crear una tabla llamada "páginas", y el esquema será definido por el archivo fuente. 
Cuando cargamos un archivo de Parquet, incrusta un esquema. En otras palabras, la definición de las columnas de la tabla que estamos creando se deducirá del esquema que ya existe dentro del archivo Parquet. Aquí es donde realmente ocurre una parte de la magia.
Avancemos y simplemente creemos la tabla a partir del archivo Parquet. 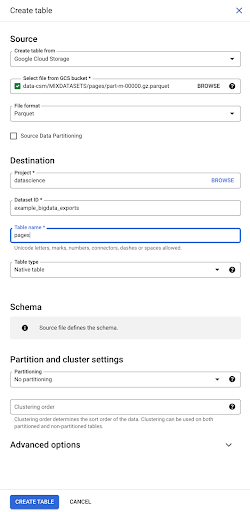
En la barra lateral izquierda, podemos ver ahora que apareció una tabla dentro de nuestro conjunto de datos, que es exactamente lo que queremos:
Entonces, ahora tenemos el esquema de la tabla de páginas con todos los campos que se han inferido automáticamente del archivo Parquet. Tenemos el Inrank, la profundidad de la página, si la página es una redirección y así sucesivamente: 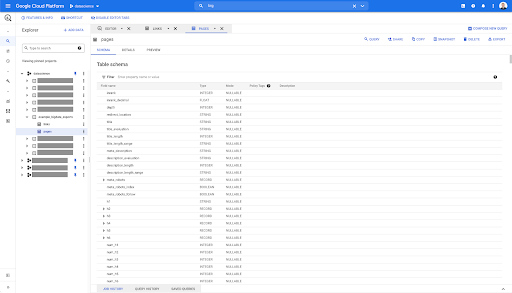
La mayoría de estos campos son los mismos que están disponibles en Data Studio a través del conector de Oncrawl Data Studio y los mismos que ve en Data Explorer en la interfaz de Oncrawl. 
Sin embargo, hay algunas diferencias. Cuando jugamos con la exportación de big data sin procesar, tiene todos los datos sin procesar.
- En Data Studio, se cambia el nombre de algunos campos, se ocultan otros y se agregan otros, como el estado.
- En el Explorador de datos, algunos campos son lo que llamamos "campos virtuales", lo que significa que pueden ser una especie de acceso directo a un campo subyacente. Estos campos virtuales disponibles en el Explorador de datos no aparecerán en el esquema, pero se pueden volver a crear según lo que esté disponible en el archivo Parquet.
Ahora cerremos esta tabla y hagámoslo de nuevo para los enlaces.
Para la tabla de enlaces, el esquema es un poco más pequeño. 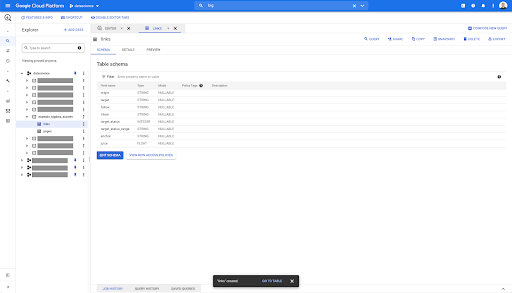
Solo contiene los siguientes campos:
- El origen del vínculo,
- El destino del enlace,
- La propiedad de seguimiento,
- La propiedad interna,
- El estado objetivo,
- El rango del estado objetivo,
- El texto de anclaje, y
- El jugo o la equidad comprada por el enlace.
En cualquier tabla de BigQuery, cuando hace clic en la pestaña de vista previa, tiene una vista previa de la tabla sin consultar la base de datos: 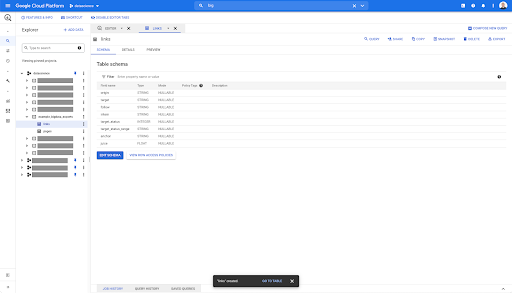
Esto le da una vista rápida de lo que está disponible en él. En la vista previa de la tabla de enlaces anterior, tiene una vista previa de cada fila y todas las columnas.
En algunos conjuntos de datos de Oncrawl, puede ver algunas filas que abarcan varias filas. No tengo un ejemplo para ti, pero si este es el caso, es porque algunos campos contienen una lista de valores. Por ejemplo, en la lista de encabezados h2 en una página, una sola fila abarcará varias filas en Big Query. Lo veremos más adelante si vemos un ejemplo.
Creando tu consulta
Si nunca ha creado una consulta en BigQuery, ahora es el momento de jugar con eso para familiarizarse con su funcionamiento. BigQuery usa SQL para buscar datos.
Cómo funcionan las consultas
Como ejemplo, veamos todas las URL y su rango interno...
SELECCIONE url, en rango ...
del conjunto de datos de las páginas...
SELECCIONE url, inrank DESDE `datascience-oncrawl.example_bigdata_exports.pages` ...
donde el código de estado de la página es 200…
SELECCIONE url, inrank DESDE `datascience-oncrawl.example_bigdata_exports.pages` DONDE status_code = 200 ...
y solo mantener los primeros 10 resultados:
SELECCIONE url, inrank DESDE `datascience-oncrawl.example_bigdata_exports.pages` DONDE código_estado = 200 LÍMITE 10
Cuando ejecutemos esta consulta, obtendremos las primeras 10 filas de la lista de páginas donde el código de estado es 200.
Cualquiera de estas propiedades puede ser modificada. Si quiero 1000 filas en lugar de 10, puedo establecer 1000 filas:
SELECCIONE url, inrank DESDE `datascience-oncrawl.example_bigdata_exports.pages` DONDE código_estado = 200 LÍMITE 1000
Si quiero ordenar, puedo hacerlo con "ordenar por": esto me dará todas las filas ordenadas por orden descendente.
SELECT url, inrank FROM `datascience-oncrawl.example_bigdata_exports.links` ORDER BY inrank DESC LIMIT 1000
Esta es mi primera consulta. Puedo guardarlo si quiero, lo que me dará la posibilidad de reutilizar esta consulta más adelante si quiero: 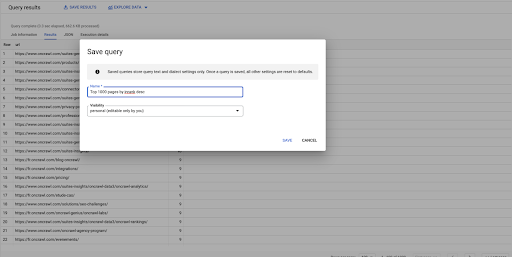
Uso de consultas para responder preguntas simples: enumeración de todos los enlaces internos a páginas con un estado 301
Ahora que sabemos cómo redactar una consulta, volvamos a nuestro problema original.
Queríamos responder preguntas de datos, ya fueran simples o complejas. Comencemos con una pregunta simple, como "¿cuáles son todos los enlaces internos que apuntan a páginas con un estado 301 (redireccionado) y dónde puedo encontrarlos?"
Creando una nueva consulta
Comenzaremos explorando cómo funciona esto.
Voy a querer columnas para los siguientes elementos de la base de datos de "enlaces":
- Origen
- Objetivo
- Código de estado de destino
SELECCIONE origen, destino, estado_objetivo DESDE `datascience-oncrawl.example_bigdata_exports.links`
Quiero limitarlos solo a enlaces internos, pero imaginemos que no recuerdo el nombre de la columna o el valor que indica si el enlace es interno o externo. Puedo ir al esquema para buscarlo y usar la vista previa para ver el valor: 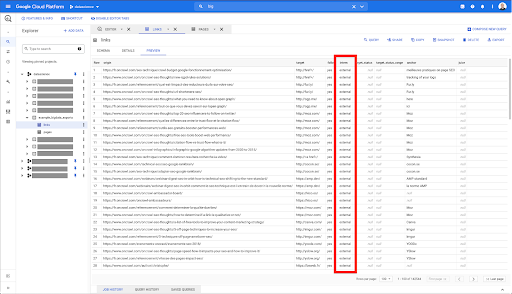
Esto me dice que la columna se llama "interno", y el posible rango de valores es "externo" o "interno".
En mi consulta, quiero especificar "donde interno es interno" y limitar los resultados a los primeros 100 por ahora:
SELECCIONE origen, destino, target_status DESDE `datascience-oncrawl.example_bigdata_exports.links` DONDE interno LIKE 'internal' LIMIT 100
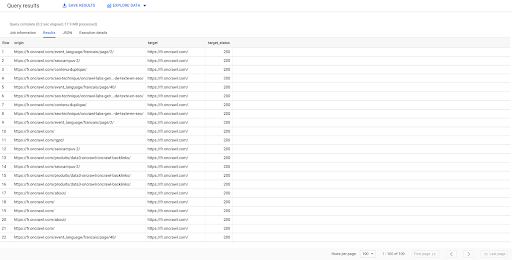
El resultado anterior muestra la lista de enlaces con su estado objetivo. Solo tenemos enlaces internos, y tenemos 100 de ellos, como se especifica en la consulta.
Si queremos tener solo enlaces internos a ese punto a páginas redirigidas, podríamos decir 'donde interno como interno y estado de destino es igual a 301':
SELECCIONE origin, target, target_status DESDE `datascience-oncrawl.example_bigdata_exports.links` DONDE interno LIKE 'internal' AND target_status = 301
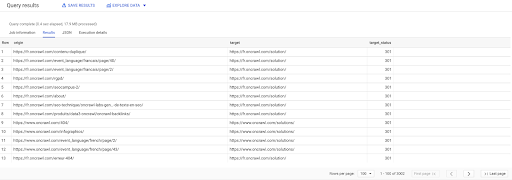
Si no sabemos cuántos de ellos existen, podemos ejecutar esta nueva consulta y veremos que hay 3002 enlaces internos con un estado objetivo de 301.
Unirse a las tablas: encontrar códigos de estado final de enlaces que apuntan a páginas redirigidas
En un sitio web, a menudo tiene enlaces a páginas que se redireccionan. Queremos saber el código de estado de la página a la que son redirigidos (o la URL de destino final).
En un conjunto de datos, tiene la información sobre los enlaces: la página de origen, la página de destino y su código de estado (como 301), pero no la URL a la que apunta una página redirigida. Y en el otro, tienes la información de los redireccionamientos y sus destinos finales, pero no la página original donde se encontró el enlace a ellos.
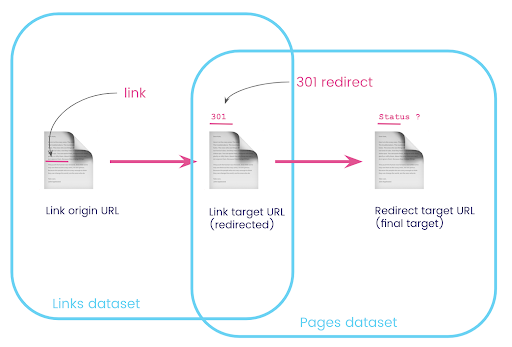
Desglosemos esto:
Primero, queremos enlaces a redireccionamientos. Escribamos esto. Queremos:
- El origen.
- El objetivo. El objetivo debe tener un código de estado 301.
- El destino final de la redirección.
En otras palabras, en el conjunto de datos de enlaces, queremos:
- El origen del vínculo.
- El destino del enlace
En el conjunto de datos de páginas, queremos:
- Todos los objetivos que son redirigidos
- El objetivo final de la redirección
Esto nos dará una consulta como:
SELECCIONE url, ubicación_redireccionamiento_final, estado_redireccionamiento_final DESDE `datascience-oncrawl.example_bigdata_exports.pages` AS páginas DONDE código_estado = 301 O código_estado = 302
Esto debería darme la primera parte de la ecuación.
Ahora necesito todos los enlaces que se vinculen a la página que son los resultados de la consulta que acabo de crear, usar alias para mis conjuntos de datos y unirlos en la URL de destino del enlace y la URL de la página. Esto corresponde al área superpuesta de los dos conjuntos de datos en el diagrama al comienzo de esta sección.
SELECCIONE enlaces.origen, paginas.url, páginas.final_redirect_ubicación, páginas.final_redirect_status DE `datascience-oncrawl.example_bigdata_exports.pages` páginas AS UNIRSE `datascience-oncrawl.example_bigdata_exports.links` enlaces AS EN enlaces.objetivo = páginas.url DÓNDE páginas.status_code = 301 O páginas.status_code = 302 ORDENAR POR origen ASC
En los resultados de la consulta, puedo cambiar el nombre de las columnas para que quede más claro, pero ya puedo ver que tengo un enlace de una página en la primera columna, que va a la página de la segunda columna, que a su vez se redirige a la página en la tercera columna. En la cuarta columna, tengo el código de estado del objetivo final: 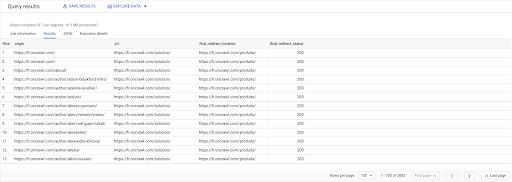
Ahora puedo saber qué enlaces apuntan a páginas redirigidas que no se resuelven en 200 páginas. Tal vez sean 404, por ejemplo, lo que me da una lista de prioridad de enlaces para corregir.
Vimos anteriormente cómo guardar una consulta. También podemos guardar los resultados, hasta 16000 líneas de resultados: 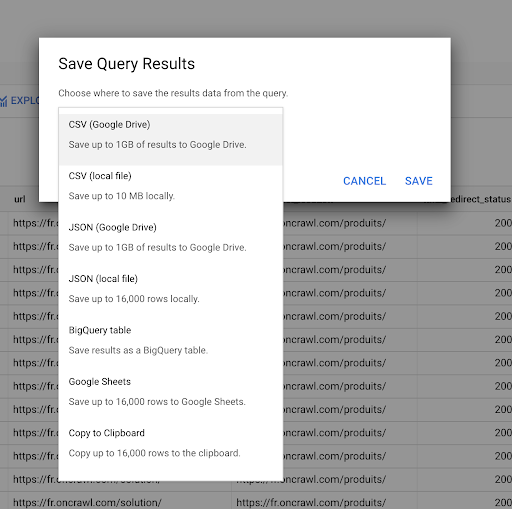
Entonces podemos usar estos resultados de muchas maneras diferentes. Aquí están algunos ejemplos:
- Podemos guardar esto como un archivo CSV o JSON localmente.
- Podemos guardarlo como una hoja de cálculo de Google Sheets y compartirlo con el resto del equipo.
- También podemos exportarlo directamente a Data Studio.
Los datos como ventaja estratégica
Con todas estas posibilidades, usar estratégicamente las respuestas a sus preguntas complejas es fácil. Es posible que ya tenga experiencia conectando los resultados de BigQuery con Data Studio u otras plataformas de visualización de datos, o que ya tenga un proceso implementado que envíe información a un equipo de ingeniería o incluso a un flujo de trabajo de inteligencia empresarial o análisis de datos.
Si ha incluido los pasos de este artículo como parte de un proceso, recuerde que puede automatizar todos los pasos en BigQuery: todas las acciones que realizamos en este artículo también son accesibles a través de la API de BigQuery. Esto significa que se pueden ejecutar mediante programación como parte de un script o una herramienta personalizada.
Cualesquiera que sean sus próximos pasos, el primer paso es siempre el acceso a los datos sin procesar de SEO y del sitio web. Creemos que este acceso a los datos es una de las partes más importantes del análisis técnico: con Oncrawl, siempre tendrá acceso completo a sus datos sin procesar.
El acceso a los datos también significa que puede ir más allá de lo que es posible en la interfaz de Oncrawl y explorar todas las relaciones entre sus datos, sin importar cuán complejas sean las preguntas que está haciendo.