
単語ベクトルとは何ですか?構造化マークアップがそれらをどのようにスーパーチャージするか
公開: 2021-07-28単語ベクトルをどのように定義しますか? この投稿では、単語ベクトルの概念を紹介します。 さまざまな種類の単語の埋め込み、さらに重要なことに、単語ベクトルがどのように機能するかについて説明します。 次に、単語ベクトルがSEOに与える影響を確認できます。これにより、構造化データのSchema.orgマークアップがSEOで単語ベクトルを活用するのにどのように役立つかを理解できます。
これらのトピックについて詳しく知りたい場合は、この投稿を読み続けてください。
すぐに飛び込みましょう。
単語ベクトルとは何ですか?
単語ベクトル(単語埋め込みとも呼ばれます)は、同様の意味を持つ単語が同等の表現を持つことを可能にする単語表現の一種です。
簡単に言うと、単語ベクトルは特定の単語のベクトル表現です。
ウィキペディアによると:
これは、自然言語処理(NLP)でテキスト分析用の単語を表すために使用される手法であり、通常、ベクトル空間に近い単語が同様の意味を持つ可能性が高いように、単語の意味をエンコードする実数値のベクトルとして使用されます。
次の例は、これをよりよく理解するのに役立ちます。
これらの類似した文を見てください:
良い一日を。 素晴らしい一日を。
それらはほとんど異なる意味を持っていません。 網羅的な語彙を構築すると(Vと呼びましょう)、すべての単語を組み合わせたV = {Have、a、good、great、day}になります。 この単語は次のようにエンコードできます。
単語のベクトル表現は、ワンホットエンコードされたベクトルである場合があります。1は単語が存在する位置を表し、0は残りを表します。
持っている=[1,0,0,0,0]
a = [0,1,0,0,0]
good = [0,0,1,0,0]
great = [0,0,0,1,0]
day = [0,0,0,0,1]
私たちの語彙に、王、女王、男、女、子供という5つの単語しかないとします。 単語を次のようにエンコードできます。
キング=[1,0,0,0,0]
クイーン=[0,1,0,0,0]
男=[0,0,1,00]
女性=[0,0,0,1,0]
子=[0,0,0,0,1]
単語の埋め込みの種類(単語ベクトル)
単語の埋め込みは、ベクトルがテキストを表すそのような手法の1つです。 埋め込みという単語のより一般的なタイプのいくつかを次に示します。
- 周波数ベースの埋め込み
- 予測ベースの埋め込み
ここでは、頻度ベースの埋め込みと予測ベースの埋め込みについて詳しくは説明しませんが、次のガイドが両方を理解するのに役立つ場合があります。
単語の埋め込みの直感的な理解と、テキストから特徴を作成するためのBag-of-Words(BOW)とTF-IDFの簡単な紹介
WORD2Vecの簡単な紹介
頻度ベースの埋め込みは人気を博していますが、単語のコンテキストを理解することにはまだ空白があり、単語の表現には制限があります。
予測ベースの埋め込み(WORD2Vec)は、GoogleのTomas Mikolovが率いる研究者チームによって、2013年に作成され、特許を取得し、NLPコミュニティに導入されました。
ウィキペディアによると、word2vecアルゴリズムは、ニューラルネットワークモデルを使用して、テキストの大きなコーパス(大きくて構造化されたテキストのセット)から単語の関連付けを学習します。
トレーニングが完了すると、このようなモデルは同義語を検出したり、部分的な文に追加の単語を提案したりできます。 たとえば、Word2Vecを使用すると、次のような結果を簡単に作成できます。キング–男性+女性=クイーン、これはほとんど魔法のような結果と見なされていました。
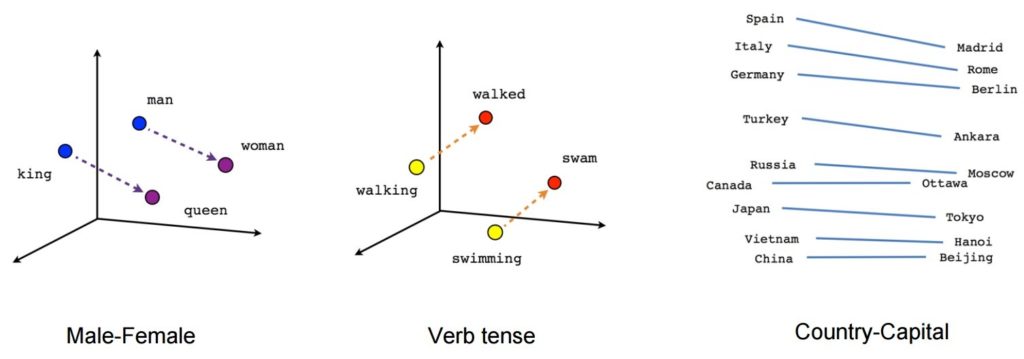 画像ソース:Tensorflow
画像ソース:Tensorflow
- [王]–[男性]+ [女性]〜= [女王](これについての別の考え方は、[王] – [女王]は[君主]の性別部分だけをエンコードしているということです)
- [walking] – [swimming] + [swam]〜= [walked](または[swam] – [swimming]は、動詞の「過去形」だけをエンコードしています)
- [madrid] – [spain] + [france]〜= [paris](または[madrid] – [spain]〜= [paris] – [france]これはおそらく大まかに「首都」です)
出典:Brainslab Digital
これは少し技術的なことですが、Stitch Fixは、意味関係と単語ベクトルに関する素晴らしい投稿をまとめました。
Word2Vecアルゴリズムは単一のアルゴリズムではなく、人間の理解と機械の理解を橋渡しするためにいくつかのAIメソッドを使用する2つの手法の組み合わせです。 この手法は、解決多くのNLP問題に不可欠です。
これらの2つの手法は次のとおりです。
- – CBOW(連続した単語の袋)またはCBOWモデル
- –スキップグラムモデル。
どちらも、単語の確率を提供する浅いニューラルネットワークであり、単語の比較や単語の類推などのタスクで役立つことが証明されています。
単語ベクトルとword2vecsのしくみ
Word VectorはGoogleが開発したAIモデルであり、非常に複雑なNLPタスクを解決するのに役立ちます。
「WordVectorモデルには、知っておくべき1つの中心的な目標があります。
これは、Googleが単語間の意味関係を検出するのに役立つアルゴリズムです。」
各単語は、同様のコンテキストで表示される単語のベクトルと一致するように、(複数の次元で表される数値として)ベクトルにエンコードされます。 したがって、テキストに対して密なベクトルが形成されます。
これらのベクトルモデルは、アイデアと言語の同等性、類似性、または関連性に基づいて、意味的に類似したフレーズを近くのポイントにマッピングします
[ケーススタディ]ページ上のSEOで新しい市場の成長を促進する
 ケーススタディを読む
ケーススタディを読むWord2Vec-それはどのように機能しますか?
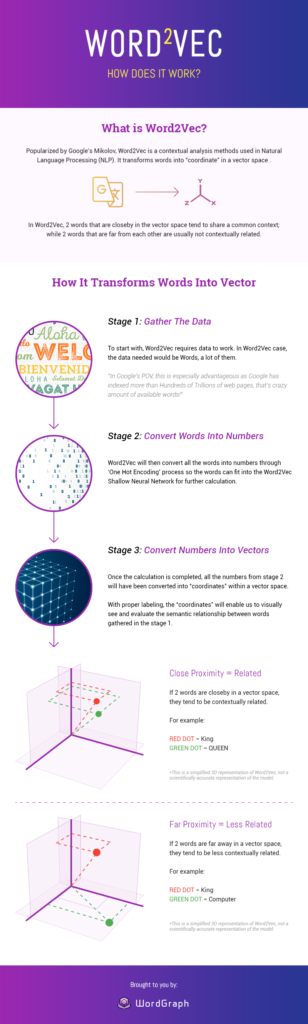
画像ソース:Seopressor
Word2Vecの長所と短所
Word2vecは、分布の類似性を生成するための非常に効果的な手法であることがわかりました。 私はここに他の利点のいくつかをリストしました:
- Word2vecの概念を理解するのは難しいことではありません。 Word2Vecはそれほど複雑ではないので、舞台裏で何が起こっているのか気づいていません。
- Word2Vecのアーキテクチャは非常に強力で使いやすいです。 他のテクニックと比較して、トレーニングは高速です。
- ここではトレーニングがほぼ完全に自動化されているため、人間がタグ付けしたデータは不要になりました。
- この手法は、小さいデータセットと大きいデータセットの両方で機能します。 結果として、それはスケールしやすいモデルです。
- 概念を知っていれば、概念とアルゴリズム全体を簡単に複製できます。
- 意味的類似性を非常によく捉えます。
- 正確で計算効率が高い
- このアプローチは監視されていないため、労力の面で非常に時間を節約できます。
Word2Vecの課題
Word2vecの概念は非常に効率的ですが、いくつかの点が少し難しいと感じるかもしれません。 最も一般的な課題のいくつかを次に示します。
- データセットのword2vecモデルを開発する場合、word2vecモデルは開発が簡単ですがデバッグが難しいため、デバッグが大きな課題になる可能性があります。
- あいまいさは扱いません。 したがって、複数の意味を持つ単語の場合、埋め込みはこれらの意味の平均をベクトル空間に反映します。
- 不明またはOOVの単語を処理できない:word2vecの最大の問題は、不明または語彙外(OOV)の単語を処理できないことです。
単語ベクトル:検索エンジン最適化のゲームチェンジャー?
多くのSEO専門家は、WordVectorが検索エンジン結果でのWebサイトのランキングに影響を与えると信じています。
過去5年間で、Googleはコンテンツの品質と言語の包括性に明確に焦点を当てた2つのアルゴリズムの更新を導入しました。
一歩下がって、更新について話しましょう。
ハチドリ
2013年、Hummingbirdは検索エンジンにセマンティック分析の機能を提供しました。 彼らのアルゴリズムに意味論を利用して組み込むことにより、彼らは検索の世界への新しい道を開きました。
Google Hummingbirdは、2010年のカフェイン以来の検索エンジンへの最大の変更でした。その名前は「正確で高速」であることから付けられました。

Search Engine Landによると、Hummingbirdはクエリ内の各単語により多くの注意を払い、特定の単語だけでなく、クエリ全体が考慮されるようにします。
Hummingbirdの主な目標は、特定のキーワードの結果を返すのではなく、クエリのコンテキストを理解することで、より良い結果を提供することでした。
「GoogleHummingbirdは2013年9月にリリースされました。」
ランクブレイン
2015年、Googleは人工知能(AI)を組み込んだ戦略であるRankBrainを発表しました。
ランクブレインは、Googleが複雑な検索クエリをより単純なものに分解するのに役立つアルゴリズムです。 RankBrainは、検索クエリを「人間の」言語からGoogleが簡単に理解できる言語に変換します。
Googleは、ブルームバーグが公開した記事で2015年10月26日にRankBrainの使用を確認しました。
BERT
2019年10月21日、BERTはGoogleの検索システムで展開を開始しました
BERTは、トランスフォーマーからの双方向エンコーダー表現の略で、自然言語処理(NLP)の事前トレーニングのためにGoogleが使用するニューラルネットワークベースの手法です。
つまり、BERTは、コンピューターが人間のように言語を理解するのに役立ちます。これは、GoogleがRankBrainを導入して以来の検索における最大の変化です。
これはRankBrainに代わるものではなく、コンテンツとクエリを理解するための追加されたメソッドです。
Googleは、ランキングシステムでBERTを追加として使用しています。 ランクブレインアルゴリズムは、一部のクエリに対して引き続き存在し、引き続き存在します。 しかし、GoogleがBERTがクエリをよりよく理解できると感じたとき、彼らはそれを使用します。
BERTの詳細については、Barry Schwartzによるこの投稿と、DawnAndersonの詳細なダイビングをご覧ください。
WordVectorsでサイトをランク付けする
あなたはすでにユニークなコンテンツを作成して公開していると思いますが、それを何度も磨いても、ランキングやトラフィックは向上しません。
なぜこれがあなたに起こっているのか疑問に思いますか?
Word Vector:GoogleのAIモデルが含まれていなかったことが原因である可能性があります。
- 最初のステップは、ニッチ市場の上位10のSERPランキングの単語ベクトルを特定することです。
- 競合他社が使用しているキーワードと、見落としている可能性のあるものを把握します。
高度な自然言語処理技術と機械学習フレームワークを活用したWord2Vecを適用することで、すべてを詳細に見ることができます。
ただし、これらは機械学習とNLPの手法を知っていれば可能ですが、次のツールを使用してコンテンツに単語ベクトルを適用できます。
WordGraph、世界初の単語ベクトルツール
この人工知能ツールは、自然言語処理用のニューラルネットワークで作成され、機械学習でトレーニングされています。
人工知能に基づいて、WordGraphはコンテンツを分析し、上位10位のWebサイトとの関連性を向上させるのに役立ちます。
それはあなたの主なキーワードに数学的にそして文脈的に関連しているキーワードを提案します。
個人的には、WordGraphとうまく連携する強力なSEOツールであるBIQと組み合わせています。
Biqに組み込まれているコンテンツインテリジェンスツールにコンテンツを追加します。 それはあなたがトップの位置にランク付けしたい場合に追加できるページ上のSEOのヒントの全リストを表示します。
この例では、コンテンツインテリジェンスがどのように機能するかを確認できます。 リストは、ページ上のSEOを習得し、実用的な方法を使用してランク付けするのに役立ちます。
単語ベクトルを過給する方法:構造化データマークアップの使用
スキーママークアップ、つまり構造化データは、検索エンジンがコンテンツをクロール、整理、表示するのに役立つschema.orgボキャブラリーを使用して作成されたコードの一種です(JSON、Java-Script Object Notationで記述)。
構造化データを追加する方法
構造化データは、HTMLにインラインスクリプトを追加することで、Webサイトに簡単に追加できます。
以下の例は、組織の構造化データを可能な限り単純な形式で定義する方法を示しています。
スキーママークアップを生成するには、このスキーママークアップジェネレーター(JSON-LD)を使用します。
https://www.telecloudvoip.com/のスキーママークアップのライブ例を次に示します。 ソースコードを確認し、JSONを検索します。
スキーママークアップコードが作成されたら、Googleのリッチリザルトテストを使用して、ページがリッチリザルトをサポートしているかどうかを確認します。
また、Semrushサイト監査ツールを使用して、各URLの構造化データ項目を調べ、リッチリザルトに含める資格のあるページを特定することもできます。 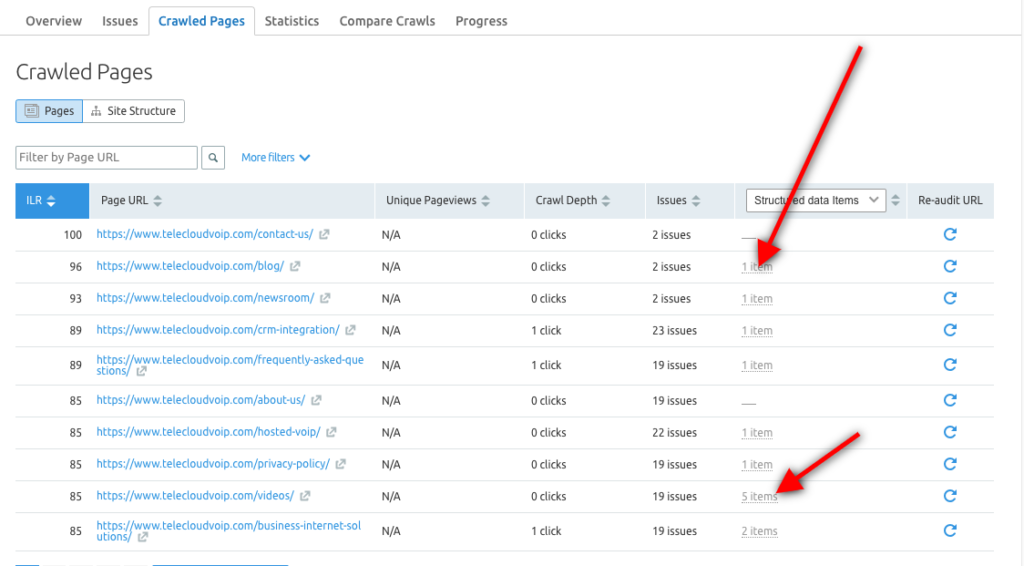
構造化データがSEOにとって重要なのはなぜですか?
構造化データはSEOにとって重要です。これは、Googleがウェブサイトやページの内容を理解するのに役立ち、コンテンツのランキングがより正確になるためです。
構造化データは、SERP(検索エンジンの結果ページ)をより多くの情報と精度で改善することにより、検索ボットのエクスペリエンスとユーザーエクスペリエンスの両方を改善します。
Google検索での影響を確認するには、検索コンソールに移動し、[パフォーマンス]>[検索結果]>[検索の外観]で、「動画」や「よくある質問」などの豊富な検索結果タイプの内訳を表示し、それらがもたらしたオーガニックインプレッションとクリックを確認できます。あなたのコンテンツのために。
構造化データのいくつかの利点は次のとおりです。
- 構造化データはセマンティック検索をサポートします
- また、E‑AT(専門知識、信頼性、信頼性)もサポートします
- 構造化されたデータがあると、コンバージョン率も上がる可能性があります。これは、より多くの人があなたのリストを見るようになり、彼らがあなたから購入する可能性が高くなるためです。
- 構造化データを使用すると、検索エンジンはブランド、Webサイト、およびコンテンツをよりよく理解できます。
- 検索エンジンは、連絡先ページ、製品の説明、レシピページ、イベントページ、および顧客レビューを簡単に区別できるようになります。
- 構造化データの助けを借りて、Googleはあなたのブランドに関するより良い、より正確な知識グラフと知識パネルを構築します。
- これらの改善により、より有機的なインプレッションと有機的なクリックが発生する可能性があります。
構造化データは現在、検索結果を強化するためにGoogleによって使用されています。 人々がキーワードを使用してあなたのウェブページを検索するとき、構造化されたデータはあなたがより良い結果を得るのを助けることができます。 スキーママークアップを追加すると、検索エンジンはコンテンツにさらに気付くようになります。
スキーママークアップは、さまざまなアイテムに実装できます。 以下に、スキーマを適用できるいくつかの領域を示します。
- 記事
- ブログ投稿
- ニュース記事
- イベント
- 製品
- ビデオ
- サービス
- レビュー
- 総合評価
- レストラン
- 地元企業
スキーマでマークアップできるアイテムの完全なリストは次のとおりです。
エンティティ埋め込みを使用した構造化データ
「エンティティ」という用語は、あらゆるタイプのオブジェクト、概念、または主題の表現を指します。 エンティティには、人、映画、本、アイデア、場所、会社、またはイベントがあります。
機械は実際には単語を理解できませんが、エンティティの埋め込みを使用すると、王–女王=夫–妻の関係を簡単に理解できます。
エンティティの埋め込みは、ワンホットエンコーディングよりも優れたパフォーマンスを発揮します
単語ベクトルアルゴリズムは、単語間の意味関係を発見するためにGoogleによって使用され、構造化データと組み合わせると、意味的に強化されたWebになります。
構造化データを使用することで、よりセマンティックWebに貢献できます。 これは、データを機械可読形式で記述する拡張Webです。
Webサイトの構造化されたセマンティックデータは、検索エンジンがコンテンツを適切なオーディエンスと照合するのに役立ちます。 NLP、機械学習、ディープラーニングを使用すると、ユーザーが検索するものと利用できるタイトルとの間のギャップを減らすことができます。
最終的な考え
単語ベクトルの概念とその重要性を理解したので、単語ベクトル、エンティティ埋め込み、構造化されたセマンティックデータを利用することで、有機的な検索戦略をより効果的かつ効率的にすることができます。
最高のランキング、トラフィック、コンバージョンを達成するには、単語ベクトル、エンティティ埋め込み、構造化されたセマンティックデータを使用して、ウェブページのコンテンツが正確、正確、信頼できることをGoogleに示す必要があります。