
出版社としてのGoogleの時代にスニペットを形作る方法
公開: 2019-10-22グーグルは、近年その傾向を無視するのが難しくなっているが、長い間、それ自体をコンテンツ発行者と見なしてきた。 これは、機械学習の進歩と新しい検索エンジン結果ページ(SERP)機能によって部分的に促進されました。
「コンテンツ発行者としてのGoogle」は、難しい選択を提示するため、多くのWebサイト所有者にとって潜在的な問題です。 あなたがすべき:
- コンテンツを保護し、Googleの結果から締め出されるリスクを冒しますか?
- グーグルがあなたのサイトに訪問者を送らないかもしれないことを知って、グーグルに無料のコンテンツソースを提供しますか?
2019年10月下旬に発効する新しいスニペット管理タグは、Googleによる意図の宣言と見なすことができます。 また、Webサイトの所有者にコンテンツを保護し、SERPでのページの表示方法を制御する手段を提供するための正しい方向への一歩でもあります。
なぜ質の高いコンテンツを心配するのですか?
Googleのプロパティは、業種にもよりますが、依然としてWebサイトへのトラフィックの約60%を提供します。そのため、Googleのゲームをプレイしないと、Webサイトの可視性とトラフィックに多大な悪影響を与える可能性があります。 しかし同時に、EATとQuality Raterガイドラインを通じて、Googleは、高品質のコンテンツがインターネットユーザーが求めているものであり、ウェブサイトが生き残るためにコンテンツの作成に投資する必要があることを明確に確立しました。
ユニークで高品質なコンテンツへの投資は、Webサイトの所有者が当然保護したいものです。 Webサイトは、コンテンツを提供する際に、他のプロバイダー(この場合は検索エンジン)が時間、お金、専門知識から利益を得ることができるようにします。
Googleはコンテンツをどのように使用しますか?
Googleはコンテンツを使用、リミックス、および書き換えて、検索エンジンユーザーからの質問に対する回答を提供します。 これらの回答は、SERPにさまざまな形式で表示されます。
検索結果のリスト、または「スニペット」
Googleは、元々Webページ自体から抽出されたさまざまな要素を使用して、検索結果で特定のWebページのスニペットを作成します。
- <タイトル>タグ
- <meta description =”スニペットテキスト”>タグ
- サポートされている構造化データのSchema.orgマークアップ
- URL
- ファビコン(一部の地域のモバイル検索結果)
現在、これらのいくつかはそのまま使用されています。 Googleはファビコンを置き換える権利を留保します。 Googleは、「ページのタイトルと説明の生成は完全に自動化されており、…[Googleは]この情報のさまざまなソースを使用しています。これには、各ページのタイトルとメタタグの説明情報が含まれます」と明示的に述べています。 最後に、最近のテストで見られたように、GoogleはSERPのURLの抑制を開始しました。
GoogleがSERPのURLを削除すると、TLDが「不良」になる場合があります。
それが.io、.org、.net、.ieなどであるかどうかわからない場合は、それらに偏って、より正当と思われる.comをクリックすることはできません。 大きな影響はないかもしれませんが、時間の経過とともに大きくなる微妙な影響になる可能性があります。 pic.twitter.com/CcQ2E0lVtZ
—ロスハジェンズ(@RossHudgens)2019年10月21日
注目のスニペット
Googleは、検索者の質問に答えるように見えるWebページからコンテンツを抽出することにより、検索結果のリストの前に表示される注目のスニペットを作成します。 2019年2月と6月に、アトリビューションなしで(または表示または簡単にアクセスできるアトリビューションなしで)表示される注目のスニペットのさまざまなエピソードがありました。いずれの場合も、Googleは出版社の権利をバイパスする意図を非難し、アトリビューションの欠如はエラー。
定義、天気、食べ物
特定の場所で辞書の定義や天気を検索すると、オートコンプリートボックスに回答が表示されます。属性はなく、検索を実行する必要もありません。
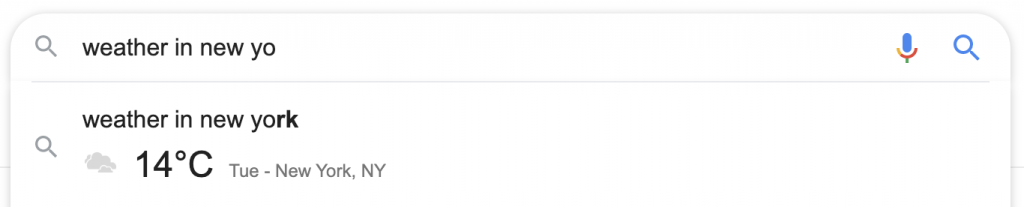
定義の場合、検索ボタンを押すと、サウンド、同義語、およびその他のSERP内機能を備えた完全な定義が利用可能になります。 検索者はオックスフォード辞書サイトにアクセスする必要はありません。オックスフォードの属性は、定義ボックスの下に小さな灰色のテキストで表示されます。
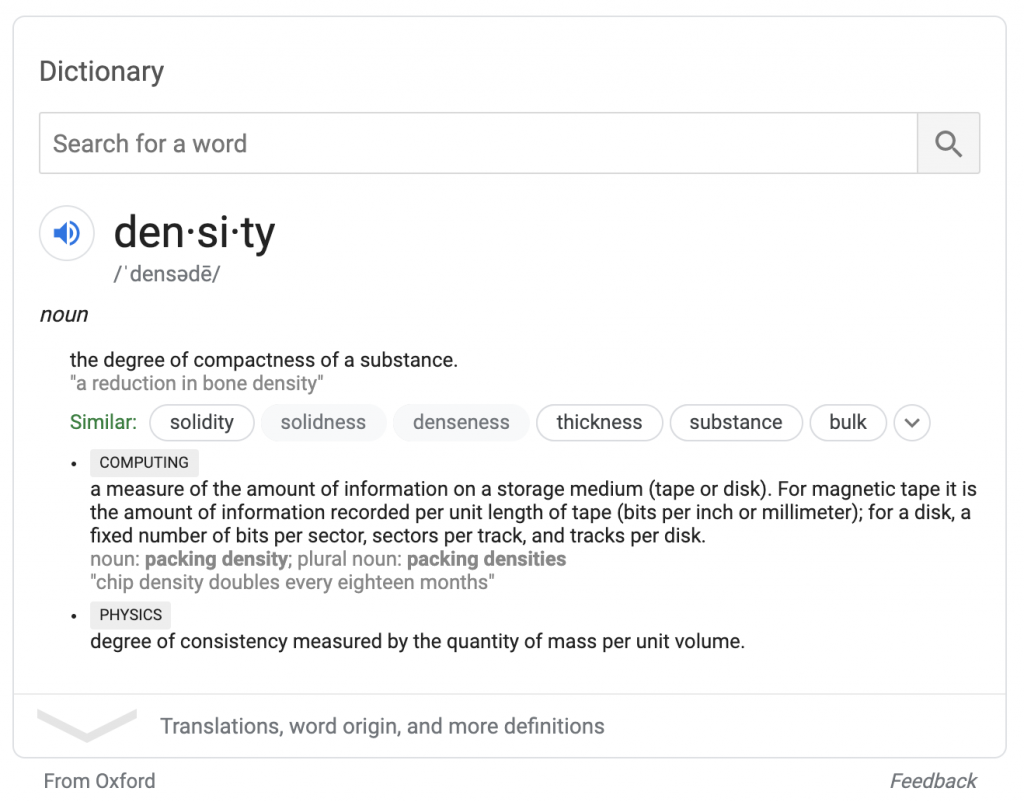
完全な天気検索では、weather.comのデータに基づいて同様の予測ボックスが提供されます。 Oxfordの属性と同様に、weather.comの属性はボックスの下に表示されます。 検索者は、weather.comにアクセスしなくても、ボックス内のデータを操作できます。
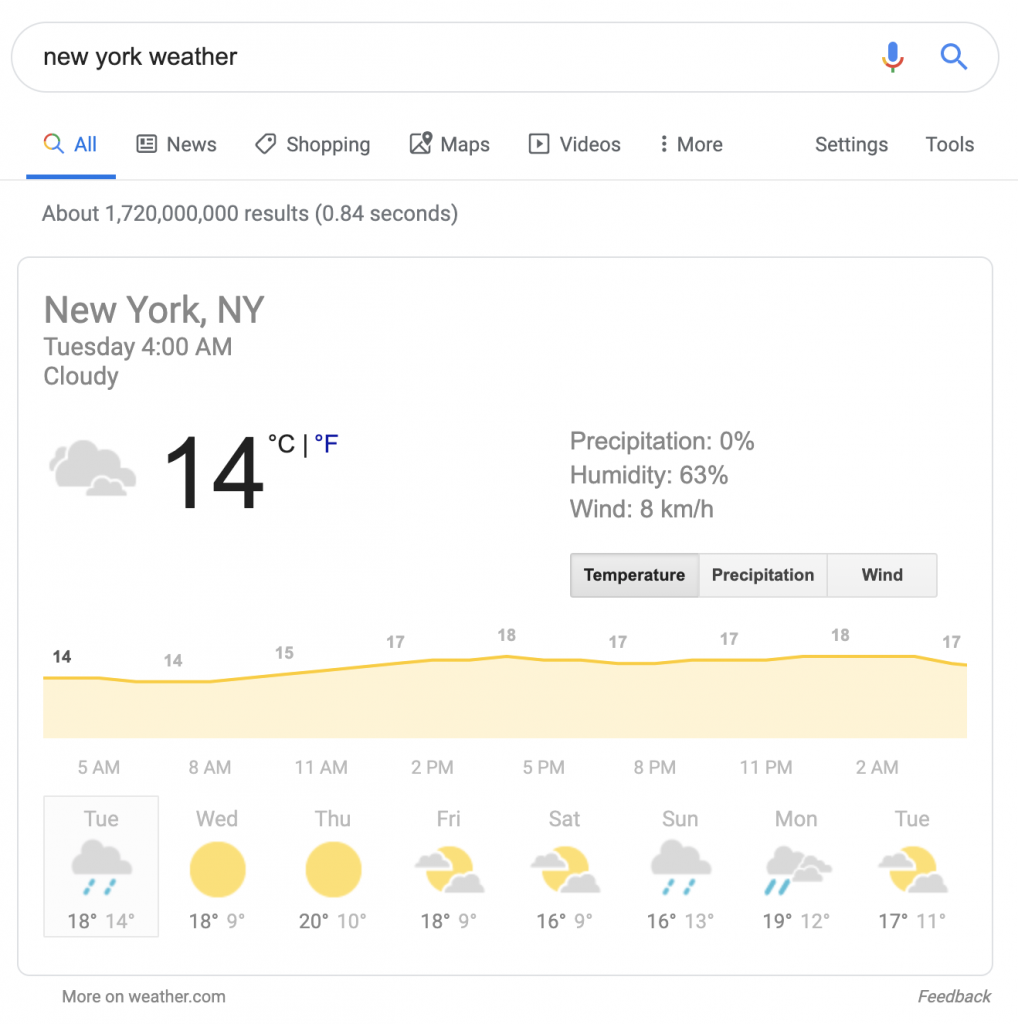
別の同様の検索結果は、栄養成分と食品成分に関するものです。
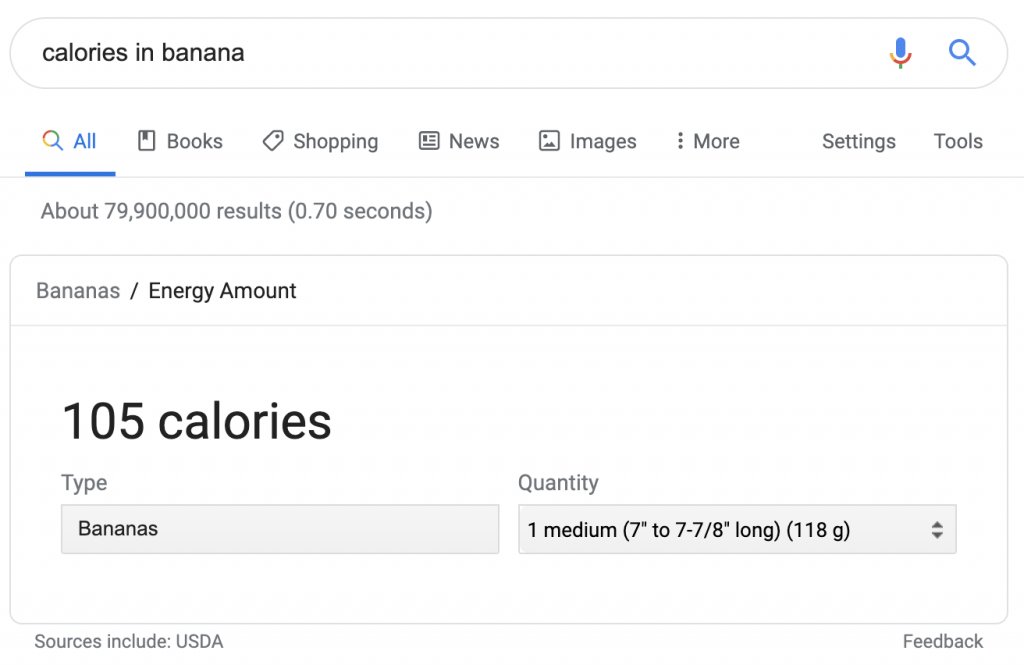
ただし、この場合、帰属は「ソースに含まれる」としてリストされます。 他のソースが使用されている場合、それらは表示またはアクセスできません。
ローカル指向の結果
多くの地域活動関連の結果も、さまざまな情報源から得られ、さまざまな集約および照合された情報を提供するSERPを作成します。 検索者は、さまざまなWebサイトにアクセスする代わりに、たとえば、近くで上映されている映画のリストを表示したり、さまざまな劇場で上映時間を調べたり、個々の映画の詳細(レビュー、概要など)を見つけたりできます。 検索者がGoogleがキュレートしたSERPを離れる必要はありません。
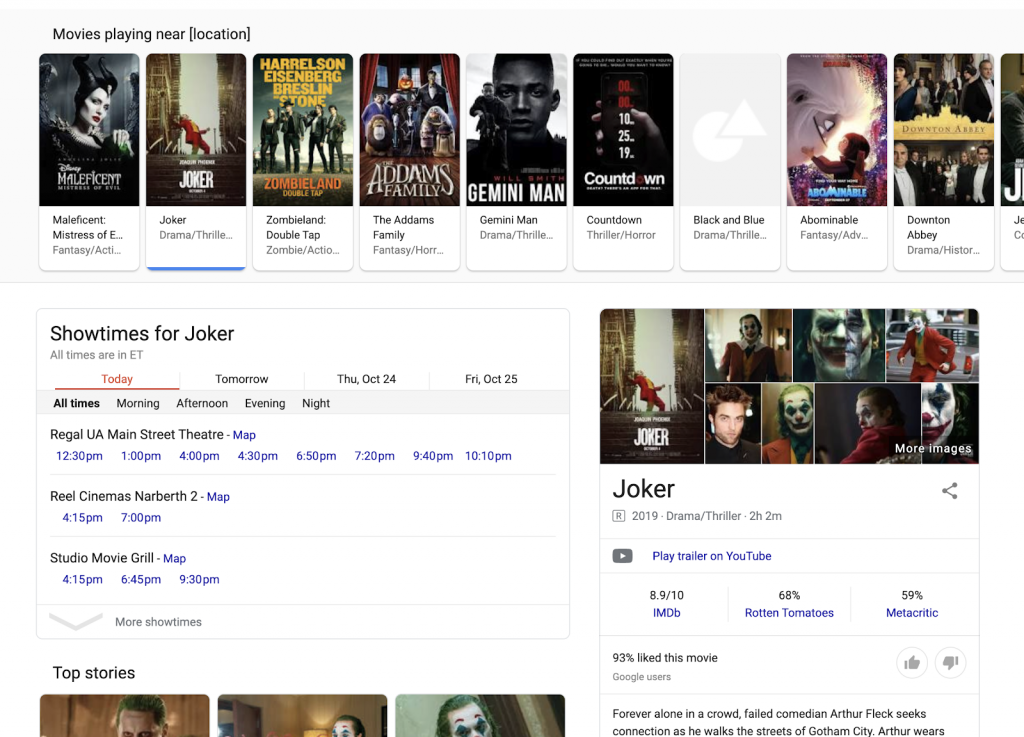
このタイプのSERPは、旅行を含む多くの異なる分野に拡大しています。
AMPストーリー
AMPストーリーは、「モバイルでのニュース消費」のための「ストーリーに焦点を合わせた」モードを提供します。 これらは、エンティティベースのインデックス作成によって、さまざまなソースからコンテンツを描画してリミックスするGoogleの機能がどのように向上したかを示す例です。 たとえば、Googleが作成した有名人の出演に関するストーリーでは、あるソースの画像と別のソースのテキストを組み合わせています。
ナレッジパネル
ナレッジパネルは、Googleのナレッジグラフの一部である「エンティティを検索したときにGoogleに表示される情報ボックス」です。 これらのパネルに表示される情報は、Googleが次のようにリストしている複数のソースから取得されます。
- 映画や音楽などの特定のトピックに関する信頼できるデータを提供するデータパートナー
- オープンウェブソース
- 自身の知識パネルで事実の編集を提案した検証済みエンティティ
- エンティティのGoogle画像検索結果のプレビュー
Googleは以前、ナレッジグラフがウィキペディア/ウィキデータ、CIAワールドファクトブック、公開ウェブ全体の構造化データ、Googleマイビジネスなどのソースに依存していることを示しました。
また、関連するエンティティを表示して、検索ユーザーが検索エンジンのWebサイトを離れることなくナレッジグラフをナビゲートできるようにすることもできます。
その他のSERP機能
その他のSERP機能には、検索ユーザーを別のWebサイトに誘導せずに、検索アクティビティに回答または再目標到達プロセスを試みるクエリ予測要素が含まれます。 例としては、モバイル検索やオートコンプリートでの結果なしの回答や、「People also ask」(PAA)ボックスなどがあります。


デスクトップのオートコンプリートボックスに回答として直接表示される、結果なしの検索(モバイル)の例
検索結果のコンテンツ管理
Schema.orgマークアップ
検索リストを形成する他の要素を直接制御することはほとんどなく、SEOは、Schema.orgマークアップを介してリッチスニペットの力に大きく依存して、リストをSERPで際立たせています。
ただし、Googleは、レビュースターやFAQマークアップなど、豊富なマークアップの乱用を取り締まっています。
検索結果のGoogleレビュースターは、更新後14%減少します。
—金融サイトが46%減少
—不動産サイトが46%減少
—法と政府のサイトが28%減少@dr_peteによる新しいデータhttps://t.co/DdlrCFIrsmpic.twitter.com/w2lj9WzpLR
— Cyrus(@CyrusShepard)2019年9月24日
SERPが#FAQの結果でいっぱいになるのを防ぐために、#Googleは3つのFAQ結果に上限を設定したようです#SEO @brodieseo @sengineland https://t.co/V8vSiKwrrv pic.twitter.com/A0Spmu9iMg
— AJ Ghergich(@SEO)2019年10月8日
使用できないコンテンツの明示的な表示
今週、Googleは、SERPでページスニペットを作成するために使用できるものに関するいくつかの制限をGoogleに示すために使用できるスニペット管理タグを展開しています。
新しい管理タグには、2つの主な制限があります。
- ページ上の構造化データ(Schema.orgマークアップ)には適用されません。 GoogleがサポートするSchema.org構造化データは、常に検索結果に表示できます。
- それらがSERP機能に必要な最小の長さを満たさない場合、それらは、注目のスニペットを含む、SERPの特定の「特別な機能」でページが使用されるのを妨げる可能性があります。 長さは言語によって異なるため、Googleは注目スニペットの最小の長さを公開していません。 Insead、「コンテンツを注目のスニペットとして表示したくない場合は、最大スニペットの長さを短くして実験することができます。」
Webサイトの所有者には、これらのタグを実装するための2つのオプションがあります。
1.メタロボットタグ
10月下旬から、世界中で、これらのメタロボットタグをページ<head>またはx-robotsHTTPヘッダーに追加できます。
- <meta name =” robots” content =” nosnippet “> –このページのスニペットテキストを表示しません。 画像のサムネイルは引き続き使用できます。
- <meta name =” robots” content =” max-snippet: 50”> –スニペットの最大文字数を文字数で設定します。 「0」のスニペットの長さは「nosnippet」と同等です。 スニペットの長さが「-1」の場合、スニペットの長さに制限がないことを意味すると解釈されます。
- <meta name =” robots” content =” max-video-preview: 3”> –ビデオプレビューの最大長を秒単位で設定します。 ビデオの長さが「0」の場合、ビデオのプレビューは表示されません。 「-1」のビデオ長は、ビデオプレビューの長さに制限がないことを意味すると解釈されます。
- <meta name =” robots” content =” max-image-preview: standard”> –このページの画像の最大画像サイズを設定します。 オプションは、「なし」、「標準」、または「大」です。
同じメタロボットタグで複数のスニペット管理演算子を使用できます。 各演算子はコンマで区切ります。
2.データ-nosnippetHTML属性
2019年後半に、新しいHTML属性data-nosnippetがGoogleによって認識されるようになります。 <span>、<div>、または<selection>タグに適用できます。
data-nosnippet属性は、適用されるタグ内のテキストがページのスニペットに表示されないようにします。
フランスのヨーロッパの報道機関向けのコンテンツ再利用の明示的な許可
グーグルのニュースコンテンツのリミックスと再発行は、すでにいくつかの場所で著作権法の限界を打ち破っている。 フランスは最近脚光を浴びています:
フランスの著作権法が変更されたため、ウェブサイトで検索プレビューを許可するメタタグが実装されていない限り、影響を受けるヨーロッパの報道機関のテキストスニペットや画像サムネイルはGoogle検索で表示されません。 (ソース)
つまり、Googleは、フランスでの検索結果から、コンテンツの再発行と最終的なリミックスを明示的に許可していないヨーロッパの出版物を除外します。
皮肉なことに、許可を与える方法は特に明確ではありません。明示的に許可されるメタロボットタグは「all」のみです。これは「デフォルト値であり、明示的にリストされている場合は効果がありません」。ただし、現在、フランスのSERPを除きます。
それ以外の場合、サイト運営者は、スニペット管理に関する発表に含まれていない規則を通じて、テキストと動画のプレビューの長さに制限がないことを示すか、検索プレビューを禁止したくないことを示すために任意の制限を課すことができます。 。
綱渡りをする
すべてのウェブサイトは、コンテンツの保護とGoogleのSERPでのプレゼンスの形成との間の適切なバランスを見つける必要があります。
Googleがコンテンツ発行者としてますます行動するにつれて、最小限の帰属でより多くのSERP機能が期待できます。また、コンテンツの所有者と作成者を保護することを目的とした著作権法が、Googleが表示できるものとできないものに影響を与える国も増えると予想されます。
私が興味深いと思うのは、これが著作権に与える影響です…人々はGが許可なくコンテンツを取得することに不満を持っています–スニペットタグは暗黙の許可になります。 それらが必要になるまでに長い時間がかかりますか?
— Jenny Halasz(@jennyhalasz)2019年10月15日
幸い、新しいスニペット管理ツールは、ウェブサイトの所有者にツールボックスの始まりを提供し、コンテンツのどの部分とどれだけをSERPでGoogleが再利用できるかを決定します。
今のところ、オリジナルのコンテンツが充実しているWebサイトには、スニペット管理タグを適切に実装するのが賢明だと思いますが、制限のみのタグがすべてのWebサイトに役立つとは限らないのではないかと心配しています。 この警告にもかかわらず、SERPのエクスペリエンスを最適化し、より多くのトラフィックを獲得するためにそれらを使用する方法はまだあります。
人々は新しいタグを採用すると思います。 Googleが自動的に取得してクリック率を最適化するよりも優れたエクスペリエンスを提供するために、これらのタグを使用してスニペットを「形成」する機会はかなりあると思います。
— Kevin_Indig(@Kevin_Indig)2019年10月16日
さまざまな分野での実験を見て、何が最も効果的かを見つけるのを楽しみにしています。