
Pythonでのセマンティックキーワードクラスタリング
公開: 2021-04-19デジタルマーケティングの神話に満ちた世界では、日常の問題に対する実用的な解決策を考え出すことが私たちに必要なものであると私たちは信じています。
PEMAVORでは、デジタルマーケティング愛好家のニーズを満たすために、常に専門知識と知識を共有しています。 そのため、ROIを向上させるために、無料のPythonスクリプトを投稿することがよくあります。
Pythonを使用したSEOキーワードクラスタリングは、50行未満のPythonコードで、大規模なSEOプロジェクトの新しい洞察を得る道を開きました。
このスクリプトの背後にある考え方は、「誇張された料金」を支払うことなくキーワードをグループ化できるようにすることでした…まあ、私たちは誰を知っていますか…
しかし、このスクリプトだけでは不十分であることがわかりました。 別のスクリプトが必要なので、キーワードの理解を深めることができます。「意味と意味の関係によってキーワードをグループ化できる必要があります。 」
それでは、 PythonforSEOをさらに一歩進めましょう。
オンクロールデータ³
 もっと詳しく知る
もっと詳しく知るセマンティッククラスタリングの従来の方法
ご存知のように、セマンティクスの従来の方法は、 word2vecモデルを構築してから、WordMoverのDistanceを使用してキーワードをクラスター化することです。
しかし、これらのモデルは、構築とトレーニングに多くの時間と労力を要します。 そこで、より簡単なソリューションを提供したいと思います。 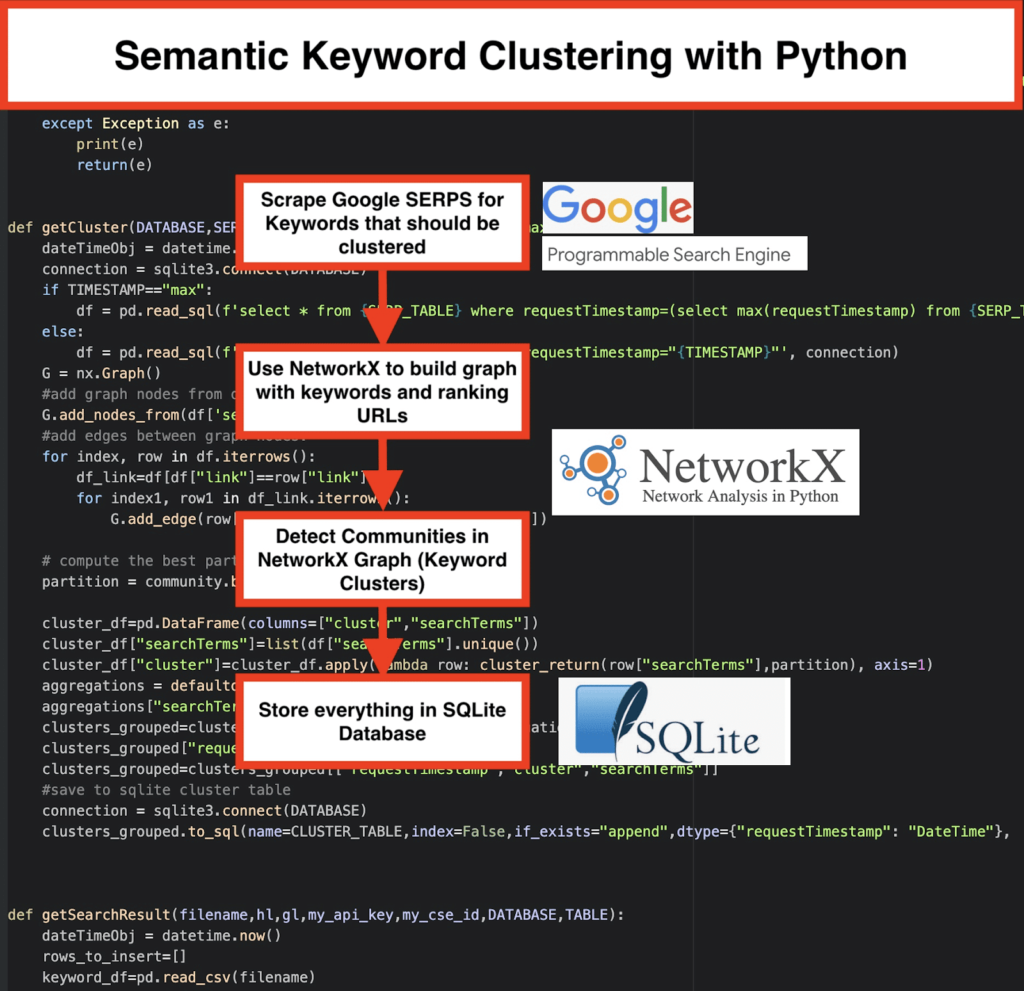
GoogleSERPの結果とセマンティクスの発見
GoogleはNLPモデルを利用して、最高の検索結果を提供します。 パンドラの箱を開けるようなもので、正確にはわかりません。
ただし、モデルを構築するのではなく、このボックスを使用して、セマンティクスと意味によってキーワードをグループ化できます。
これが私たちのやり方です:
️最初に、トピックのキーワードのリストを考え出します。
️次に、各キーワードのSERPデータをスクレイプします。
️次に、ランキングページとキーワードの関係でグラフを作成します。
️同じページが異なるキーワードでランク付けされている限り、それらは互いに関連していることを意味します。 これは、セマンティックキーワードクラスターの作成の背後にあるコア原則です。
Pythonですべてをまとめる時が来ました
Pythonスクリプトは、次の関数を提供します。
- Googleのカスタム検索エンジンを使用して、キーワードリストのSERPをダウンロードします。 データはSQLiteデータベースに保存されます。 ここでは、カスタム検索APIを設定する必要があります。
- 次に、1日あたり100リクエストの無料割り当てを利用します。 ただし、待ちたくない場合や大きなデータセットがある場合は、1000クエストあたり5ドルの有料プランも提供しています。
- 急いでいない場合は、 SQLiteソリューションを使用することをお勧めします。SERPの結果は実行ごとにテーブルに追加されます。 (翌日再び割り当てがある場合は、100個のキーワードの新しいシリーズを取得するだけです。)
- その間、 Pythonスクリプトでこれらの変数を設定する必要があります。
- CSV_FILE =” keyswords.csv”=>ここにキーワードを保存します
- LANGUAGE =“ en”
- COUNTRY =“ en”
- API_KEY =” xxxxxxx”
- CSE_ID =” xxxxxxx”
-
getSearchResult(CSV_FILE,LANGUAGE,COUNTRY,API_KEY,CSE_ID,DATABASE,SERP_TABLE)を実行すると、SERP結果がデータベースに書き込まれます。 - クラスタリングは、networkxとコミュニティ検出モジュールによって実行されます。 データはSQLiteデータベースからフェッチされます–クラスタリングは
getCluster(DATABASE,SERP_TABLE,CLUSTER_TABLE,TIMESTAMP)れます - クラスタリングの結果はSQLiteテーブルにあります。変更しない限り、名前はデフォルトで「keyword_clusters」です。
以下に、完全なコードを示します。
#Pemavor.comによるセマンティックキーワードクラスタリング #作成者:Stefan Neefischer([email protected]) googleapiclient.discoveryインポートビルドから パンダをpdとしてインポートします レーベンシュタインをインポートする 日時からインポート日時 fuzzywuzzyimportfuzzから urllib.parseからインポートurlparse tldからインポートget_tld langidをインポートする jsonをインポートする パンダをpdとしてインポートします numpyをnpとしてインポートします networkxをnxとしてインポートします インポートコミュニティ sqlite3をインポートします 数学をインポートする import io コレクションからimportdefaultdict def cluster_return(searchTerm、partition): パーティションを返す[searchTerm] def language_detection(str_lan): lan = langid.classify(str_lan) lan[0]を返します def extract_domain(url、remove_http = True): uri = urlparse(url) remove_httpの場合: domain_name = f "{uri.netloc}" そうしないと: domain_name = f "{uri.netloc}:// {uri.netloc}" domain_nameを返します def extract_mainDomain(url): res = get_tld(url、as_object = True) res.fldを返す def fuzzy_ratio(str1、str2): fuzz.ratio(str1、str2)を返します def fuzzy_token_set_ratio(str1、str2): fuzz.token_set_ratio(str1、str2)を返します def google_search(search_term、api_key、cse_id、hl、gl、** kwargs): 試す: service = build( "customsearch"、 "v1"、developerKey = api_key、cache_discovery = False) res = service.cse()。list(q = search_term、hl = hl、gl = gl、fields ='queries(request(totalResults、searchTerms、hl、gl))、items(title、displayLink、link、snippet)' 、num = 10、cx = cse_id、** kwargs).execute() 解像度を返す eとしての例外を除く: print(e) return(e) def google_search_default_language(search_term、api_key、cse_id、gl、** kwargs): 試す: service = build( "customsearch"、 "v1"、developerKey = api_key、cache_discovery = False) res = service.cse()。list(q = search_term、gl = gl、fields ='queries(request(totalResults、searchTerms、hl、gl))、items(title、displayLink、link、snippet)'、num = 10 、cx = cse_id、** kwargs).execute() 解像度を返す eとしての例外を除く: print(e) return(e) def getCluster(DATABASE、SERP_TABLE、CLUSTER_TABLE、TIMESTAMP = "max"): dateTimeObj = datetime.now() 接続=sqlite3.connect(DATABASE) TIMESTAMP == "max"の場合: df = pd.read_sql(f'select * from {SERP_TABLE} where requestTimestamp =(select max(requestTimestamp)from {SERP_TABLE})'、connection) そうしないと: df = pd.read_sql(f'select * from {SERP_TABLE} where requestTimestamp = "{TIMESTAMP}"'、connection) G = nx.Graph() #データフレーム列からグラフノードを追加 G.add_nodes_from(df ['searchTerms']) #グラフノード間にエッジを追加: インデックスの場合、df.iterrows()の行: df_link = df [df ["link"] == row ["link"]] df_link.iterrows()のindex1、row1の場合: G.add_edge(row ["searchTerms"]、row1 ['searchTerms']) #コミュニティ(クラスター)に最適なパーティションを計算する パーティション=community.best_partition(G) cluster_df = pd.DataFrame(columns = ["cluster"、 "searchTerms"]) cluster_df ["searchTerms"] = list(df ["searchTerms"]。unique()) cluster_df ["cluster"] = cluster_df.apply(lambda row:cluster_return(row ["searchTerms"]、partition)、axis = 1) 集計=defaultdict() 集計["searchTerms"]='| '。加入 cluster_grouped = cluster_df.groupby( "cluster")。agg(aggregations).reset_index() clusters_grouped ["requestTimestamp"] = dateTimeObj clusters_grouped = clusters_grouped [["requestTimestamp"、 "cluster"、 "searchTerms"]] #sqliteクラスターテーブルに保存 接続=sqlite3.connect(DATABASE) clusters_grouped.to_sql(name = CLUSTER_TABLE、index = False、if_exists = "append"、dtype = {"requestTimestamp": "DateTime"}、con = connection) def getSearchResult(filename、hl、gl、my_api_key、my_cse_id、DATABASE、TABLE): dateTimeObj = datetime.now() rows_to_insert = [] keyword_df = pd.read_csv(ファイル名) キーワード=keyword_df.iloc[:、0] .tolist() キーワードのクエリの場合: hl == "default"の場合: 結果=google_search_default_language(query、my_api_key、my_cse_id、gl) そうしないと: 結果=google_search(query、my_api_key、my_cse_id、hl、gl) 結果に「items」、結果に「queries」の場合: range(0、len(result ["items"]))の位置の場合: result ["items"] [position] ["position"] = position + 1 result ["items"] [position] ["main_domain"] = extract_mainDomain(result ["items"] [position] ["link"]) result ["items"] [position] ["title_matchScore_token"] = fuzzy_token_set_ratio(result ["items"] [position] ["title"]、query) result ["items"] [position] ["snippet_matchScore_token"] = fuzzy_token_set_ratio(result ["items"] [position] ["snippet"]、query) result ["items"] [position] ["title_matchScore_order"] = fuzzy_ratio(result ["items"] [position] ["title"]、query) result ["items"] [position] ["snippet_matchScore_order"] = fuzzy_ratio(result ["items"] [position] ["snippet"]、query) result ["items"] [position] ["snipped_language"] = language_detection(result ["items"] [position] ["snippet"]) range(0、len(result ["items"]))の位置の場合: rows_to_insert.append({"requestTimestamp":dateTimeObj、 "searchTerms":query、 "gl":gl、 "hl":hl、 "totalResults":result ["queries"] ["request"] [0] ["totalResults"]、 "link":result ["items"] [position] ["link"]、 "displayLink":result ["items"] [position] ["displayLink"]、 "main_domain":result ["items"] [position] ["main_domain"]、 "position":result ["items"] [position] ["position"]、 "snippet":result ["items"] [position] ["snippet"]、 "snipped_language":result ["items"] [position] ["snipped_language"]、 "snippet_matchScore_order":result ["items"] [position] ["snippet_matchScore_order"]、 "snippet_matchScore_token":result ["items"] [position] ["snippet_matchScore_token"]、 "title":result ["items"] [position] ["title"]、 "title_matchScore_order":result ["items"] [position] ["title_matchScore_order"]、 "title_matchScore_token":result ["items"] [position] ["title_matchScore_token"]、 }) df = pd.DataFrame(rows_to_insert) #serpの結果をsqliteデータベースに保存 接続=sqlite3.connect(DATABASE) df.to_sql(name = TABLE、index = False、if_exists = "append"、dtype = {"requestTimestamp": "DateTime"}、con = connection) #################################################### #################################################### ########################################## #私を読んでください:# #################################################### #################################################### ########################################## #1-あなたはグーグルカスタム検索エンジンを設定する必要があります。 # #APIキーとSearchIdを提供してください。 # #また、SERP結果を監視する国と言語を設定します。 # #APIキーと検索IDをまだお持ちでない場合は、# #このページの「前提条件」セクションの手順に従うことができますhttps://developers.google.com/custom-search/v1/overview#prerequisites# ## #2-結果の保存に使用するデータベース、serpテーブル、クラスターテーブルの名前も入力する必要があります。 # ## #3-serpに使用されるキーワードを含むcsvファイル名またはフルパスを入力します# ## #4-キーワードクラスタリングの場合、クラスタリングに使用されるserp結果のタイムスタンプを入力します。 # #最後の検索結果をクラスター化する必要がある場合は、タイムスタンプに「max」と入力します。 # #または「2021-02-1817:18:05.195321」のような特定のタイムスタンプを入力できます# ## #5-SqliteプログラムのDBブラウザで結果を参照します# #################################################### #################################################### ########################################## serpのキーワードを持つ#csvファイル名 CSV_FILE = "keywords.csv" #言語を決定する LANGUAGE = "en" #detrmine city COUNTRY = "en" #googleカスタム検索jsonapiキー API_KEY="ここにキーを入力してください" #検索エンジンID CSE_ #sqliteデータベース名 DATABASE = "keywords.db" #serp結果を保存するテーブル名 SERP_TABLE = "keywords_serps" #キーワードに対してserpを実行 getSearchResult(CSV_FILE、LANGUAGE、COUNTRY、API_KEY、CSE_ID、DATABASE、SERP_TABLE) クラスタの結果が保存する#table名。 CLUSTER_TABLE = "keyword_clusters" #特定のタイムスタンプのクラスターを作成する場合は、タイムスタンプを入力してください #最後のserp結果のクラスターを作成する必要がある場合は、「max」値で送信します #TIMESTAMP = "2021-02-18 17:18:05.195321" TIMESTAMP = "max" #ネットワークとコミュニティアルゴリズムに従ってキーワードクラスターを実行する getCluster(DATABASE、SERP_TABLE、CLUSTER_TABLE、TIMESTAMP)

GoogleSERPの結果とセマンティクスの発見
セマンティックモデルに依存せずに、キーワードをセマンティッククラスターにグループ化するショートカットを備えたこのスクリプトを楽しんでいただけたでしょうか。 これらのモデルは複雑で高価なことが多いため、セマンティックプロパティを共有するキーワードを特定する他の方法を検討することが重要です。
意味的に関連するキーワードを一緒に扱うことにより、主題をより適切にカバーし、サイト上の記事を相互にリンクし、特定のトピックに対するWebサイトのランクを上げることができます。