
マルチモーダルおよび多言語検索の台頭
公開: 2022-01-06テキストクエリを超えて検索を拡張し、言語の壁を取り除くことは、検索エンジンの未来を形作る最近の傾向です。 AIを活用した新しい機能により、検索エンジンはより優れた検索エクスペリエンスを促進すると同時に、ユーザーが特定の情報を取得するのに役立つ新しいツールを提供することを検討しています。 この記事では、マルチモーダルおよび多言語検索システムの注目を集めているトピックについて説明します。 また、Wordliftで作成したデモ検索ツールの結果も表示します。
次世代の検索エンジン
優れたユーザーエクスペリエンスには、ユーザーと検索エンジン間の複数の相互作用の側面が含まれます。 ユーザーインターフェイスのデザインとその使いやすさから、検索意図の理解とあいまいなクエリの解決まで、大規模な検索エンジンは次世代の検索ツールを準備しています。
マルチモーダル検索
マルチモーダル検索エンジンを説明する1つの方法は、単一のクエリでテキストと画像を処理できるシステムについて考えることです。 このような検索エンジンを使用すると、ユーザーはマルチモーダル検索インターフェイスを介して入力クエリを表現できるようになり、その結果、より自然で直感的な検索エクスペリエンスが可能になります。
電子商取引のWebサイトでは、マルチモーダル検索エンジンを使用すると、インデックス付きデータベースから関連ドキュメントを取得できます。 関連性は、テキスト、画像、音声、ビデオなどの複数の形式で、特定のクエリに対する利用可能な製品の類似性を測定することによって評価されます。 結果として、この検索エンジンは、その基礎となるメカニズムが異なる入力モーダル、つまりフォーマットを同時に処理できるため、マルチモーダルシステムです。
たとえば、検索クエリは「フローラルドレス」の形式をとることができます。 この場合、多数の花柄のドレスがWebストアで入手できます。 ただし、次の図に示すように、検索エンジンはユーザーにとって本当に満足のいくものではないドレスを返します。
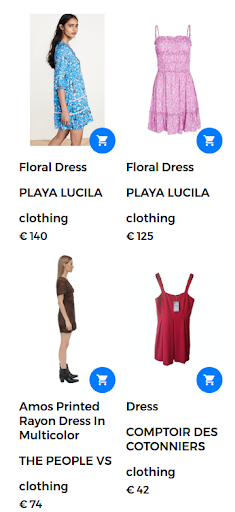
クエリ「フローラルドレス」の結果が返されました。
優れた検索エクスペリエンスを提供し、関連性の高い結果を返すために、マルチモーダル検索エンジンは、単一のクエリでテキストと画像を組み合わせることができます。 この場合、ユーザーは目的の製品のサンプル画像を提供します。 この検索をマルチモーダル検索として実行すると、入力画像は次の画像に示す花柄のドレスになります。

マルチモーダルクエリ用にユーザーが提供した画像。
このシナリオでは、クエリの最初の部分は同じままで(花柄のドレス)、2番目の部分はマルチモーダルクエリに視覚的な側面を追加します。 返された結果は、ユーザーが提供した花柄のドレスに似たドレスを生成します。 このユースケースでは、まったく同じドレスが利用可能であるため、他の同様のドレスに沿って返される最初の結果になります。
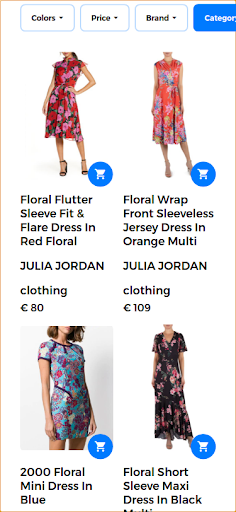
マルチモーダルクエリに応答して返される関連する検索結果。
MUM
Googleは、複雑な検索タスクでユーザーを支援する新しいテクノロジーを導入しました。 MUMと呼ばれるこの新しいテクノロジーは、Multitask Unified Modelの略で、言語の壁を打ち破り、Webページや写真などのさまざまなコンテンツ形式にわたる情報を解釈することができます。
Googleレンズは、画像とテキストを1つのクエリに組み合わせるという利点を活用した最初の製品の1つです。 検索コンテキストでは、MUMを使用すると、ユーザーが提供する画像内の特定の花柄などのパターンを簡単に見つけることができます。
MUMは、ここに示されている情報を理解するための新しいAIマイルストーンです。
「私たちはMUMの調査を始めたばかりですが、人々が自然に情報を伝達し解釈するさまざまな方法をすべてGoogleが理解できる未来に向けた重要なマイルストーンです。」
GoogleのMUMマルチモーダル検索の詳細については、次のWebストーリーを確認してください。 
言語間での検索の拡張
画像は言語に依存しませんが、検索語は言語固有です。 多言語システムを設計するタスクは、さまざまな言語にわたる言語モデルを構築することに要約されます。
多言語検索
現在の検索システムの重要な制限の1つは、ユーザーが検索クエリを書いた言語で書かれた、または注釈が付けられたドキュメントを取得することです。一般に、これらのエンジンは英語のみです。 このような単一言語の検索エンジンは、異なる言語で書かれた有用な情報を見つける際のこれらのシステムの有用性を制限します。
一方、多言語システムは、ある言語でクエリを受け入れ、他の言語でインデックス付けされたドキュメントを取得します。 実際には、ある言語で書かれたドキュメントのコンテンツまたはキャプションを別の言語のテキストクエリと照合することにより、データベースから関連するドキュメントを取得できる場合、検索システムは多言語に対応します。 マッチング手法は、構文メカニズムからセマンティック検索アプローチにまで及びます。
異なる言語の文と視覚的概念を組み合わせることが、言語を超えた視覚言語モデルの使用を促進するための最初のステップです。 良いニュースは、視覚的な概念がすべての人間によってほぼ同じように解釈されることです。 これらのシステムは、複数のソースからの情報を複数の言語にまたがって組み込むことができ、マルチモーダル多言語システムと呼ばれます。 ただし、次のセクションで説明するように、画像とテキストのペアリングは、すべての言語で大規模に実行できるとは限りません。
[ケーススタディ]ページ上のSEOで新しい市場の成長を促進する
 ケーススタディを読む
ケーススタディを読むMUMからMURALへ
高度な深層学習と自然言語処理技術を検索エンジンに適用するための取り組みが増えています。 Googleは、ユーザーが画像を使用して単語を表現できるようにする新しい研究成果を発表しました。 たとえば、「ヴァリハ」という言葉は、チューブツィターで作られた楽器を指し、マダガスカルの人々によって演奏されます。 この単語はほとんどの言語に直接翻訳されていませんが、画像を使用して簡単に説明できます。
MURAと呼ばれる新しいシステムは、言語間でのマルチモーダル、マルチタスク検索の略です。 これにより、ターゲット言語に直接翻訳されない可能性のある1つの言語の単語の問題に対処できます。 このような問題があると、事前にトレーニングされた多くの多言語モデルは、意味的に関連する単語を見つけられないか、リソース不足の言語との間で単語を正確に翻訳できません。 実際、MURALは多くの現実の問題に取り組むことができます。
- さまざまな言語でさまざまな精神的意味を伝える単語: 1つの例は、英語とヒンディー語の「結婚式」という単語で、Googleブログの次の画像に示すようにさまざまな精神的イメージを伝えます。
- Web上のリソース不足の言語のデータの不足:Web上のテキストと画像のペアの90%は、リソースの多い上位10の言語に属しています。

画像はウィキペディアから取得され、CC BY-SA 4.0ライセンスでPsoni2402(左)とDavid McCandless(右)にクレジットされています。

クエリのあいまいさを減らし、リソース不足の言語の画像とテキストのペアの不足の問題に対する解決策を提供することは、AIを搭載した次世代の検索エンジンに向けたもう1つの改善です。
多言語およびマルチモーダル検索の実行
この作業では、既存のツールと利用可能な言語およびビジョンモデルを使用して、単一の言語を超え、一度に複数のモダリティを処理できるマルチモーダル多言語システムを設計します。
まず、多言語システムを設計するには、異なる言語に由来する単語を意味的に接続することが重要です。 第二に、システムをマルチモーダルにするには、言語の表現を画像に関連付ける必要があります。 結果として、これはマルチモーダル検索多言語の長年の目的に向けた大きな一歩です。
コンテキスト
このマルチモーダル多言語システムの主な使用例は、画像とテキストを同時に組み合わせたクエリを指定して、データセットから関連する画像を返すことです。 このように、さまざまなマルチモーダルおよびマルチリンガルのシナリオを示すいくつかの例を示します。
このデモアプリのバックボーンは、オープンソースのニューラル検索エコシステムであるJinaAIを利用しています。 ディープニューラルネットワーク情報検索(またはニューラルIR)を利用したニューラル検索は、マルチモーダルシステムを構築するための魅力的なソリューションです。 このデモでは、HuggingFaceのMPNetTransformerアーキテクチャ、multilingual-mpnet-base-v2を使用して、テキストの説明とキャプションを処理します。 ビジュアル部分はMobileNetV2を使用しています。
以下では、多言語およびマルチモーダル検索エンジンの能力を示すための一連のテストを紹介します。 デモツールの結果を提示する前に、これらのテストを説明する重要な要素のリストを次に示します。
- データベースは、音楽を演奏している人々を描いた1,000枚の画像で構成されています。 これらの画像は、公開データセットFlickr30Kから取得されています。
- すべての画像には英語で書かれたキャプションがあります。
ステップ1:英語のテキストクエリから始める
まず、ほとんどの検索エンジンが動作する現在の方法を反映するテキストクエリから始めます。 クエリは「ミュージシャンのグループ」です。
クエリ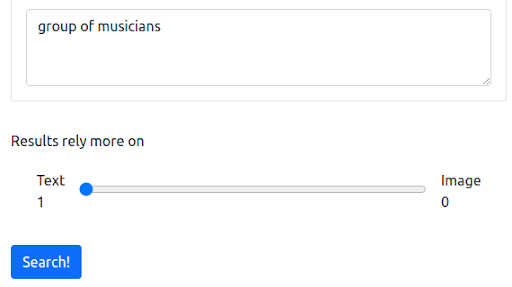
結果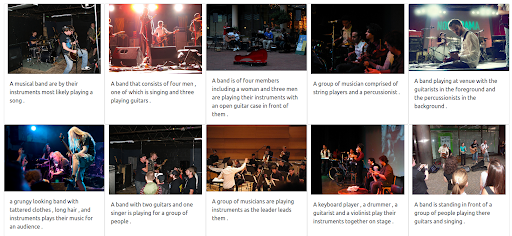
Jinaベースのデモ検索エンジンは、入力クエリに意味的に関連するミュージシャンの画像を返します。 しかし、これは私たちが望むタイプのミュージシャンではないかもしれません。
ステップ2:マルチモダリティを追加する
ここで、前のテキストクエリと画像の両方を組み合わせたクエリを発行して、マルチモダリティを追加しましょう。 この画像は、私たちが探しているミュージシャンをより正確に表しています。
まず第一に、UIはそのようなタイプのクエリの発行をサポートする必要があります。 次に、結果を取得するときに各モダリティの重要性のバランスをとるために重みを割り当てる必要があります。 この場合、テキストと画像の両方の重みは等しくなります(0.5)。 以下に示すように、新しい検索結果には、入力画像クエリに視覚的に類似した多数の画像が含まれています。
クエリ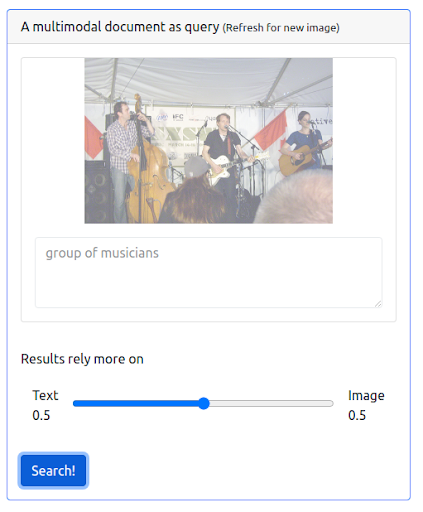
結果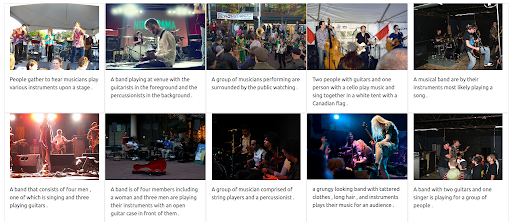
ステップ3:画像に最大の重みを割り当てる
画像に最大の重みを与えることも可能です。 そうすると、入力テキストがクエリから除外されます。 この場合、入力画像と視覚的に類似している画像がさらに返され、最初の位置にランク付けされます。 覚えておくべきことの1つは、結果がデータセットで利用可能な画像に限定されることです。
クエリ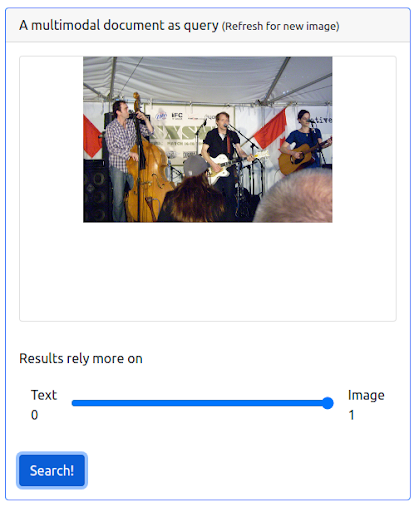
結果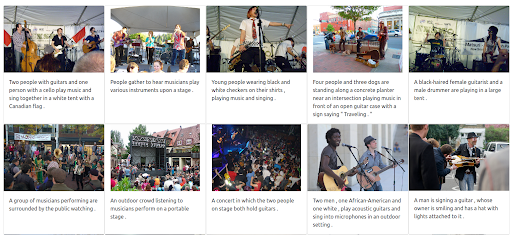
ステップ4:多言語検索をテストする
次に、同じクエリを発行しますが、異なる言語を使用してみましょう。 この多言語システムの全力を説明するために、テキストの重みが最大化されています。 画像のキャプションは英語のみであることを忘れないでください。 次の言語をカバーするために検索が繰り返されます。
- フランス語: Groupe de musiciens
- イタリア語: Gruppo di musicisti
- ドイツ語: Gruppe von Musikern
入力クエリの言語に関係なく、返される結果は関連性があり、3つの言語間で一貫しています。 結果を以下に示します。
フランス語でのクエリの結果
イタリア語でのクエリの結果
ドイツ語でのクエリの結果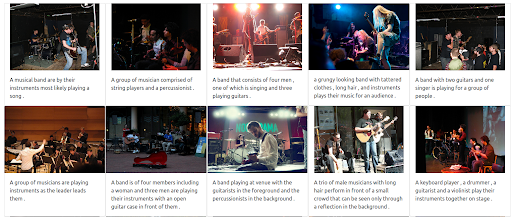
検索のマルチモーダル多言語の未来
今後数年間で、人工知能はますます検索を変革し、人々がクエリを表現して情報を探索するためのまったく新しい方法を解き放ちます。 Googleがすでに発表しているように、MUMで情報を理解することは、AIのマイルストーンを表しています。 将来的には、より多くのAIを利用したシステムに、より優れた検索エクスペリエンスの提供から高度な質問への回答、言語の壁の解消からさまざまな検索モードの単一クエリへの結合まで、さまざまな機能と改善が含まれる予定です。