
正規表現(Regex)とは何ですか?A / Bテストでそれらを使用する方法は?
公開: 2021-10-26
正規表現(または正規表現)は、CROの実践者にとって強力なツールになります。
多くのデータサイエンティスト、アナリスト、およびその他の人々は、間違いなく、キャリアのある時点でそれらに出くわしました。 技術的な知識がない人にとっては難しいかもしれませんが、これらの有用なパターンを習得することは、実験プログラムを向上させる確実な方法です!
このブログ投稿では、正規表現をわかりやすく説明して、テストで自信を持って使用できるようにします。
まず、構造とさまざまな種類の正規表現を分析します。 次に、使用する可能性のある正規表現の例と、これらのパターンをA/Bテストのさまざまな部分に実装する方法を示します。 最後に、これらをConvertExperiencesアプリで使用できるいくつかの方法を見ていきます。
- 正規表現とは何ですか?
- 正規表現をどのように記述、テスト、およびデバッグできますか?
- 正規表現の書き方
- 正規表現の基本文字
- 数量詞
- 特殊文字
- キャラクタークラス
- 正規表現の基本文字
- 正規表現をテストする方法
- 正規表現をデバッグする方法
- JavaScriptで正規表現を使用する方法
- 方法1の例
- 方法2の例
- 正規表現の書き方
- A / Bテストで正規表現が必要なのはなぜですか?
- A / Bテストで正規表現を使用する方法は?
- Regexのユースケース:Checkerを使用したConvertの正規表現インターフェイス
- Convert Experiencesアプリで正規表現を使用する方法(例付き)
- 1.正規表現のあるサイトエリア
- 2.正規表現を使用するオーディエンス
- 3.正規表現の目標
- 4.アクティブなWebサイトの正規表現
- 正規表現を使用するときに避けるべき一般的な間違い
- 1.開始文字と終了文字を含める
- 2.スラッシュを含める
- 3.文字数制限を超えています
- 4.同じページで同時実験を実行する
正規表現とは何ですか?
正規表現は、広く使用されているミニチュア言語のようなものであり、複雑なパターンに一致させることができます。そうしないと、何時間もの調査が必要になります。
これらは英数字構造であり、角かっこ{}括弧()、アスタリスク(*)、疑問符(?)、開き角かっこ([)閉じかっこ(])などの独自の記号セットが付属しています。
以下の正規表現に少し精通している場合は、これが適切な記事です。
/https?:\/\/(www\.)?[-a-zA-Z0-9@:%._\+~#=]{2,256}\.[az]{2,6}\b( [-a-zA-Z0-9 @:%_ \ +。〜#()?&// =] *)/正規表現をどのように記述、テスト、およびデバッグできますか?
それでは、正規表現で何ができるかをお見せしましょう。 まず、独自の複雑な正規表現を最初から作成する方法をいくつか見ていきます。
正規表現の書き方
最初の正規表現を作成するには、特定の構文、つまり特殊文字(メタ文字)と構築規則を使用する必要があります。 たとえば、以下は、nnn-nnn-nnnnのパターンで任意の10桁の電話番号に一致する単純な正規表現です。
\ d {3}-\ d {3}-\ d {4}自分で特定の構文を書き始めるか(検証された正規表現パターンが得られるまで多くの間違いを犯す)、または存在する利用可能な正規表現ジェネレーターの1つを使用することができます。 最もユーザーフレンドリーで使いやすいものの1つは、正規表現ジェネレーターです。
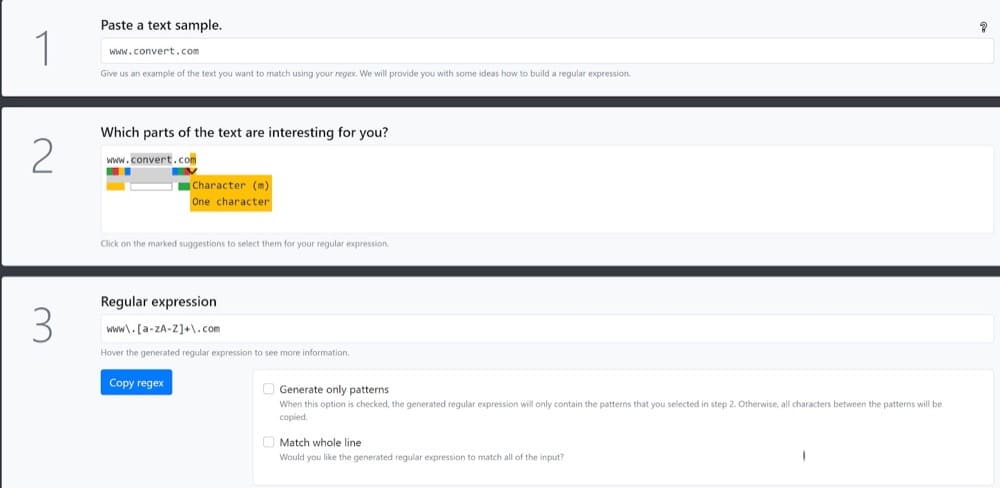
正規表現を使用して照合するテキストサンプルを貼り付け(例として、以下のConvertのURL www.convert.comを使用)、正規表現を作成するテキストのさまざまな部分を選択します。
それでおしまい! とても簡単。
これで、正規表現パターンを使用できるようになります。
w+\。[a-zA-Z]+\。com
別の例として、サポートの電子メールアドレスを入力し、アドレスのドメイン部分を指定して正規表現を作成することができます。
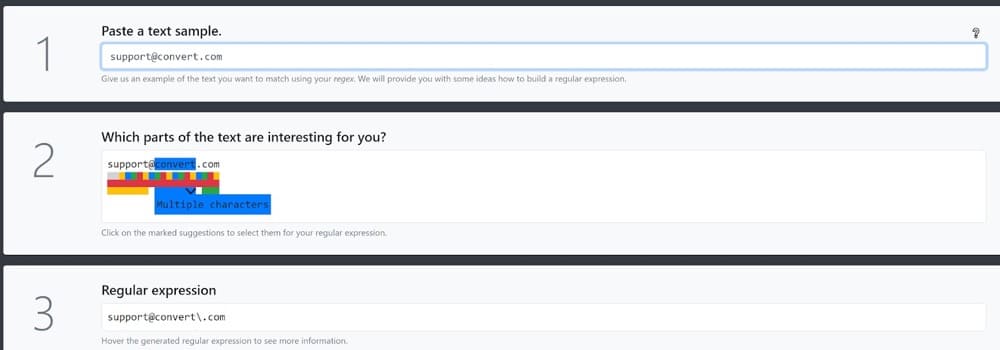
正規表現の準備が整い、使用するツールのすべてのサポートメールアドレスを1つずつコピーして貼り付けることなくターゲットにできるようになりました。
support @ [a-zA-Z]+\。com
あなたがより技術に精通していて、そのパターンを自分で書きたいのであれば、基本的な文字と数量詞に加えていくつかの構築規則を学び始めることができます。
正規表現の基本文字
これは、正規表現の最も一般的なルールを学びたい人のための簡単な「チートシート」です。
数量詞
では、複数の文字を一致させたい場合はどうでしょうか。 数量詞を使用する必要があります。 最も重要な数量詞は*?+です。 見覚えがあるかもしれませんが、まったく同じではありません。
- *その前にあるものの0個以上に一致します。
- ? ゼロまたはその前にあるものの1つに一致します。
- +その前にあるものの1つ以上に一致します。
特殊文字
正規表現の作成には、多くの特殊文字を使用できます。 最も頻繁に使用されるもののいくつかを次に示します。
| 。 | ドットは任意の1文字に一致します。 |
| \ n | 改行文字(またはCR + LFの組み合わせ)に一致します。 |
| \ t | タブに一致します(ASCII9)。 |
| \ d | 数字[0-9]に一致します。 |
| \ D | 数字以外に一致します。 |
| \ w | 英数字に一致します。 |
| \ W | 英数字以外の文字に一致します。 |
| \ s | 空白文字に一致します。 |
| \ S | 空白以外の文字に一致します。 |
| \ | \を使用して、特殊文字をエスケープします。 例えば、 \。 ドットに一致し、\\は円記号に一致します。 |
| ^ | 入力文字列の先頭で一致します。 |
| $ | 入力文字列の最後に一致します。 |
キャラクタークラス
文字を角かっこで囲むことでグループ化できます。 このように、クラス内の任意の文字が入力内の1つの文字と一致します。
| [abc] | a、b、cのいずれかに一致します。 |
| [az] | aとzの間の任意の文字に一致します。 (ASCIIオーダー) |
| [^ abc] | 角括弧の先頭にあるキャレット^は、「not」を示します。 この場合、a、b、またはc以外のものと一致します。 |
| [+ * ?.] | ほとんどの特殊文字は、角括弧内では意味がありません。 この式は、文字通り+、* 、?のいずれかに一致します。 またはドット。 |
正規表現の作成にサポートが必要ですか?
正規表現に慣れておらず、詳細を知りたい場合は、簡単なクラッシュコースを受講することを強くお勧めします。 正規表現は、学習にわずかな時間の投資しか必要としない強力なツールです。
正規表現をテストする方法
これで正規表現パターンの準備ができましたが、構文が正しいかどうかをテストしたいと思います。 手動で行うことができ、検証ルールを読むのに何時間も費やすことができます。 Mathias Bynensには、多くの正規表現の最良の比較に関するすばらしい記事があります。完璧なURL検証正規表現を探しています。 それは前進するためのクレイジーな方法です。
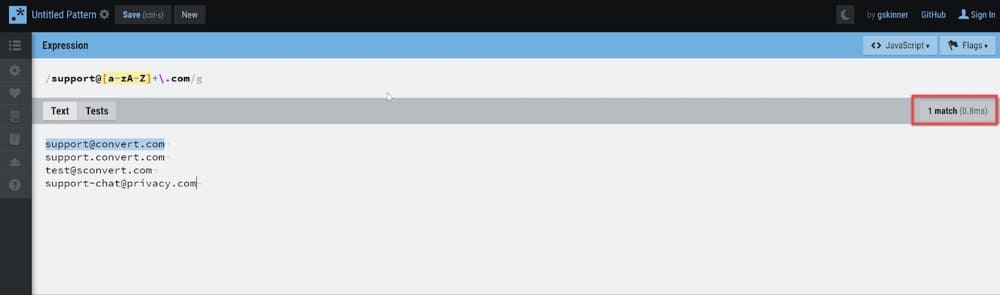
しかし、ありがたいことに、利用できる無料のオンライン正規表現バリデーターがたくさんあり、作成した正規表現パターンに対して文字列を迅速にテストできます。 そのうちの2つ、RegEx101とRegExrをお勧めします。 以下のスクリーンショットは後者のものですが、最も快適なものを自由に使用してください。
[式]フィールドに正規表現パターンを追加してから、[テキスト]フィールドに、パターンと一致するかどうかを確認するテキストを追加します。 入力したテキストのうち、特定のパターンに一致するものがいくつあるかをその場で確認できます。
これらの正規表現バリデーターは非常に強力です!
正規表現をデバッグする方法
正規表現のテストは、デバッグよりもはるかに重要です。 通常、結果を確認することで正規表現で何が起こっているかを簡単に把握できますが、意図したとおりに機能することを確認するには、考えられるすべての境界ケースで正規表現をテストする必要があります。 テストは最終的にあなたが本当にやりたいことを明らかにし、デバッグを役に立たなくします。
ただし、それでも正規表現パターンをデバッグする場合は、https://regex101.com/に入力できます。 サンプルセットで正規表現をテストし、マッチグループを色分けするだけでなく、内部で何が起こっているのかを完全に説明することもできます。
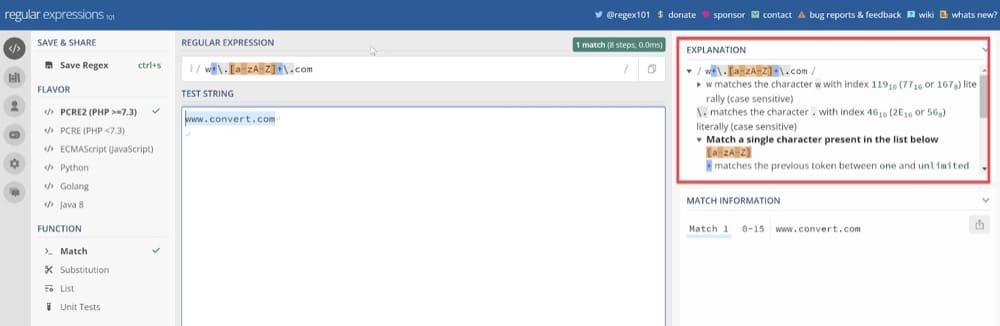
ただし、正規表現を使用している特定のプログラミング言語の特定のドキュメントを参照する必要があることに注意してください。それぞれに特定の制限があります。 特定の言語ではサポートされていないものもあります。
より「視覚的なデバッグ」エクスペリエンスが必要な場合は、Debuggexを試してください。
これは、次のような正規表現の経路を示しています。
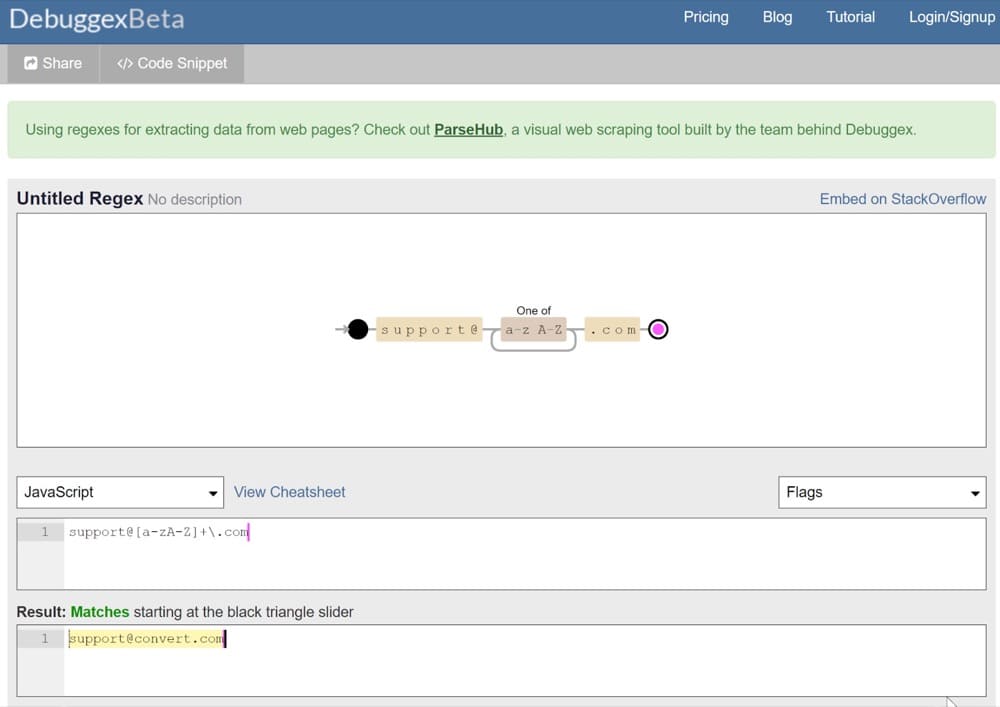
JavaScriptで正規表現を使用する方法
JavaScriptで正規表現を作成する方法は2つあります。 これは、RegExpモジュールを使用するか、スラッシュ(/)を使用してパターンを囲むことによって作成できます。 スラッシュ/…/は、正規表現を作成していることをJavaScriptに通知します。 これらは、文字列の引用符と同じ役割を果たします。
どちらの場合も、regexpは組み込みのRegExpモジュールのインスタンスになります。
これら2つの構文の主な違いは、スラッシュ/…/を使用するパターンは完全に静的であるのに対し、もう一方はその場で正規表現を生成できることです。
方法1の例
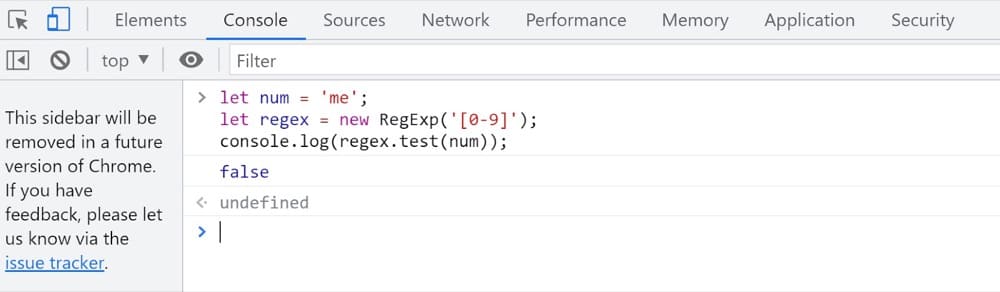
ユーザーの入力を検証し、入力に数字のみが含まれていることを確認するために使用される以下のRegExpの例を見てみましょう。
num ='me'; regex = new RegExp('[0-9]');とします。 console.log(regex.test(num)); //これはfalseを出力します
方法2の例
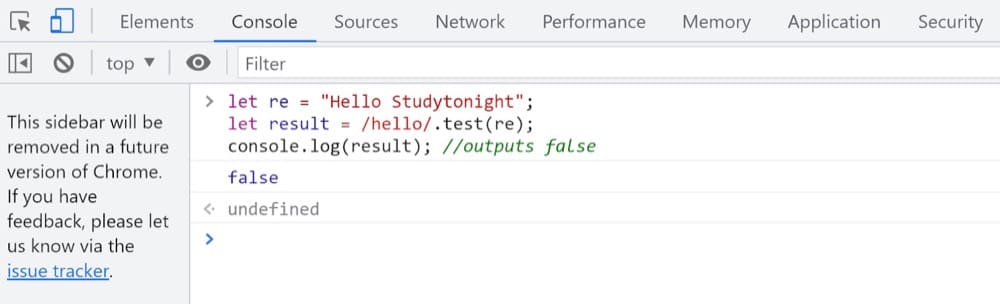
文字列内で完全に一致するものを探すリテラル表記を使用した単純な式を見てみましょう。 これは文字列と一致し、大文字と小文字を区別する検索を実行します。
re = "Hello Studytonight"; 結果=/hello/.test(re); console.log(result); //falseを出力します
それらを記述した後、JavaScript正規表現をテストするための2つの興味深い方法があります。
- RegExp.prototype.test():一致が見つかったかどうかをテストします。 正規表現に対してテストする文字列を受け入れます。 一致するものが見つかった場合は、trueまたはfalseを返します。
- RegExp.prototype.exec():一致するすべてのグループを含む配列を返します。 正規表現に対してテストする文字列を受け入れます。
次の例では、パターン/ JavaScript /が文字列に対してテストされ、一致するものが見つかったかどうかが確認されます。
var re = / JavaScript /; var str = "JavaScript"; if(re.test(str))document.writeln( "true");
次のコードスニペットでは、RegExpメソッドexecが、大文字と小文字(i)を無視して、文字列(g)全体で特定のパターン/ javascript*/を検索します。
var re = / javascript * / ig;
var str = "cfdsjavascript *(&Yjavascriptjs 888javascript";
var resultArray = re.exec(str);
while(resultArray){
document.writeln(resultArray [0]);
resultArray = re.exec(str);
}A / Bテストで正規表現が必要なのはなぜですか?
A / Bテストの正規表現は、主にターゲティングに使用されます。 ターゲティングは、経験の誰がどこで行うかを制御します。
ターゲティングを通じて、テストプラットフォームに、エクスペリエンスを表示するユーザー(Webサイトの訪問者の条件)と、サイトでエクスペリエンスを実行する場所(特定のURL)を指示します。
オーディエンスを定義することで、誰がその体験を見るかを決めることができます。 オーディエンス条件は、トラフィックソース、地理データ、行動データ、訪問者が持つ特定のCookie、および自分で指定できる無限の条件を定義できます。

URLターゲティングを定義することにより、エクスペリエンスを実行する場所を決定します。 URLターゲティング条件には、複数のドメイン、サブドメイン、クエリパラメータ、およびパスを含めることができます。
「完全一致」、「含む」、「開始」の演算子を使用してトラフィックをエクスペリエンスにバケット化することが不可能な場合があります。 これが正規表現の出番です。
これらは、エクスペリエンスから除外または含めることができ、正規表現で定義できる5つのサンプルオーディエンスです。
- 名前に共通の用語があり、残りは異なる広告キャンペーンからの訪問者(例:靴-購入-モバイル、指輪-購入-デスクトップ)。
- 特定のブラウザバージョン(Firefox 3.6.4など)を使用している訪問者。
- FacebookやTikTokなどのサードパーティサイトからの訪問者で、名前のグループを具体的に定義する必要があります。
- 以前にプロモーションを見たことがある訪問者。
- ログインしている訪問者とログイン機能を制御するためのCookieには、一意の識別子があります。
これらは、エクスペリエンスに含めたり除外したりする可能性のある5つのサンプルの場所であり、正規表現で定義できます。
- 動的/一意のクエリ文字列値を持つページ。
- 一般的な用語であるが一意の識別子を持つ特定のランディングページ。
- カテゴリとサブカテゴリのページ。
- 訪問者が1つのステップから次のステップに流れる間、チェックアウトファネルの複数のページ。
- 数ページを除いてどこでも。
A / Bテストで正規表現を使用する方法は?
正規表現は、完全または部分的なURLパターンの一致の恩恵を受けるA / B /MVT/パーソナライズ/A/A/マルチページ/スプリットURLエクスペリエンスで役立ちます。
A/Bテストで正規表現を使用して次のことができます。
- URLの構造を確認する
- 構造化URLから部分文字列を抽出します
- URLの一部を検索/置換/再配置
- URLをトークンに分割する
- URLの定数部分を見つけます。
これらはすべて、Convertエクスペリエンスをドラフトするときに定期的に表示されます。
正規表現の一致は、パス、末尾のパラメーター、またはその両方が同じWebページのURLで異なる可能性がある場合に役立ちます。
たとえば、ユーザーが多くのサブドメインの1つから来ており、URLがセッション識別子を使用している場合、正規表現を使用してURLの定数要素を定義できます。 かなり便利ですよね?
Convertでは、正規表現( regexおよびregexesに短縮)を使用して、特定のページセット、または複雑または動的なURLにエクスペリエンスをターゲティングできるようにします。 また、共通点を持つ複数の変数を使用してオーディエンスを定義するためにも使用されます。これにより、特定のWebサイト訪問者や、以下に示す他のいくつかのユースケースをターゲットにすることができます。
インターネット上には正規表現に関する多くの情報があり、その多くはConvert Experiencesでの正規表現の使用方法には実際には当てはまらないため、この正規表現ガイドを作成して開始するのに役立てています。
Regexのユースケース:Checkerを使用したConvertの正規表現インターフェイス
数式とパターンを変換UIに取り込む前に、使用できる正規表現テスター/バリデーターは多数あります。
慣れていないユーザーが独自の正規表現式を記述し、チェッカーで検証できるように、正規表現セクション(以下を参照)を設計しました。
次に、JavaScriptの組み込みの正規表現RegExpモジュールを使用して、正規表現の一致が評価されます。
チェッカーがアプリのさまざまな場所でどのように表示されるかの例を次に示します。
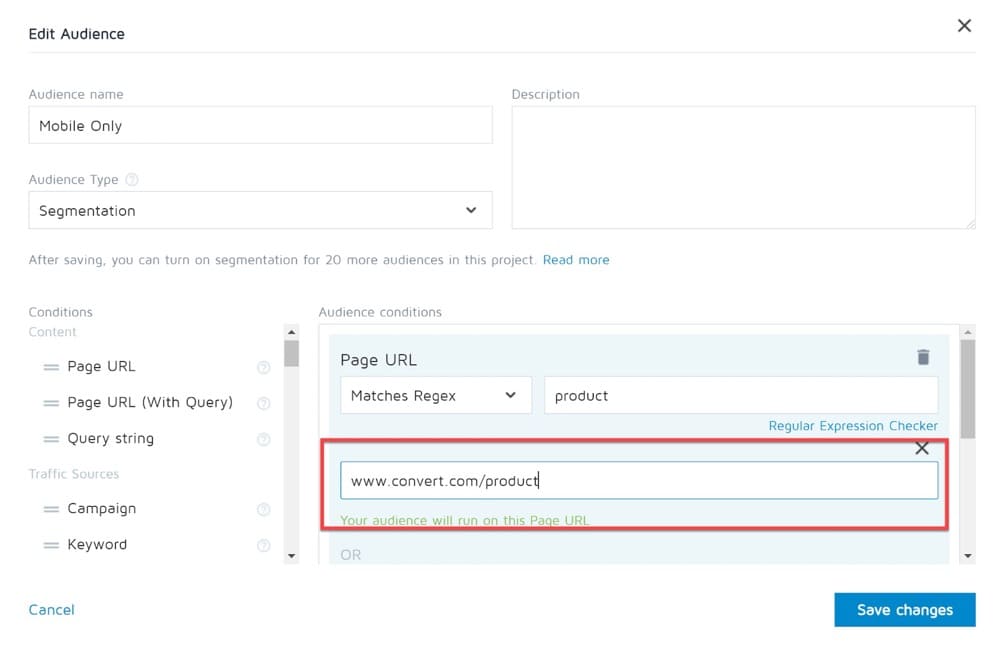
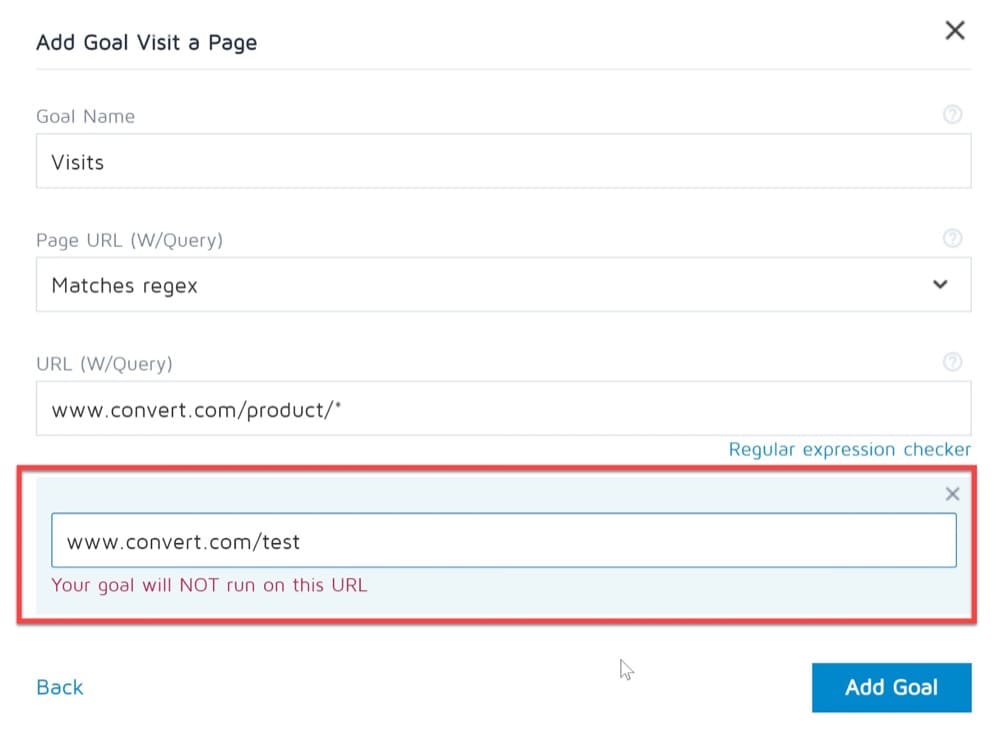
Convert Experiencesアプリで正規表現を使用する方法(例付き)
それでは、これらの各ユースケースを見ていき、正規表現が非常に役立つインスタンスの例をいくつか見てみましょう。
1.正規表現のあるサイトエリア
サイトエリアは、エクスペリエンスをトリガーするページターゲティング基準を構成するConvertExperiencesアプリ内の場所です。
最も基本的なURL構成は、たとえば「https://www.convert.com」のようなURLに基づいて実験をトリガーします。
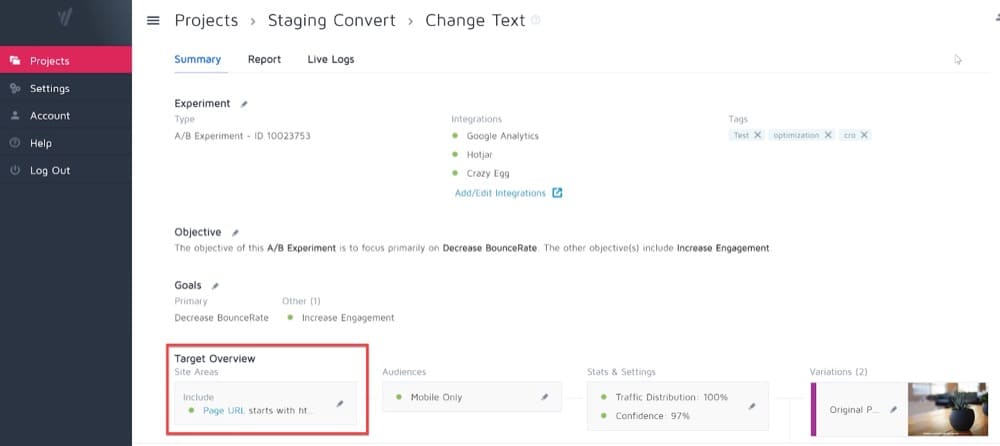
この設定は、最初に実験を作成するときに自動的に構成されます。 また、A /Bエクスペリメント/MVTエクスペリメント/パーソナライズを作成するために入力したURL、またはスプリットURLエクスペリメントの元のURLに設定されます。
ただし、サイトエリアがエクスペリエンスをトリガーするために提供するいくつかのオペレーターのいずれかを選択することにより、このデフォルト構成を変更できます。
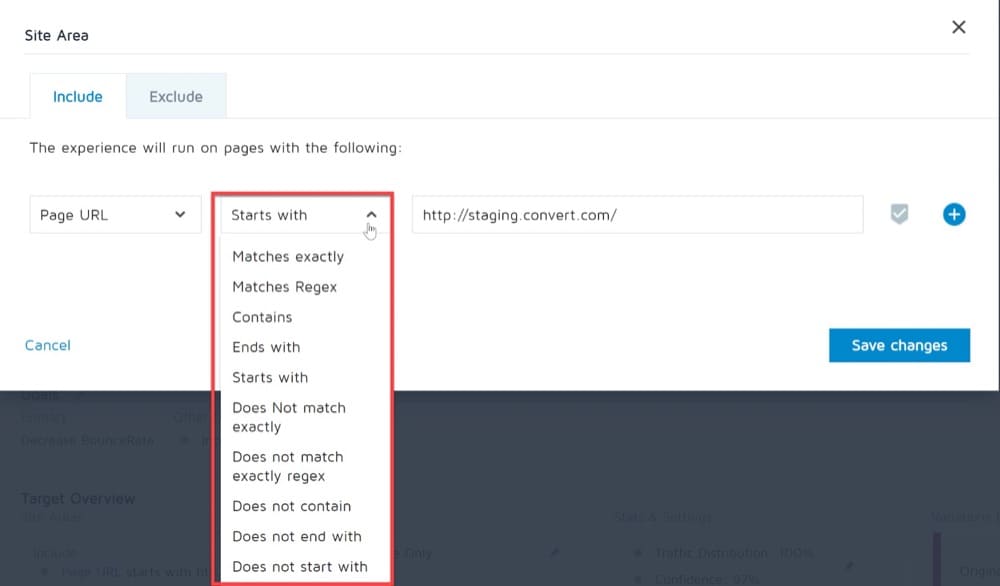
演算子の1つは「正規表現に一致」と呼ばれ、もう1つは「正規表現に正確に一致しない」と呼ばれます。
これらの2つのオプションを使用して、必要なURL設定を適用するのに他のオペレーターが役に立たない場合に、変換エクスペリエンスを実行するページを定義できます。
これを理解しやすくするためのいくつかのユースケースを見てみましょう!
例1
次の2つの条件でエクスペリエンスを実行したいとします。
- トラフィックソース=GoogleAdWords
- URLにprg=ABTESTが含まれています
サイトエリアで正規表現を作成する方法は次のとおりです。
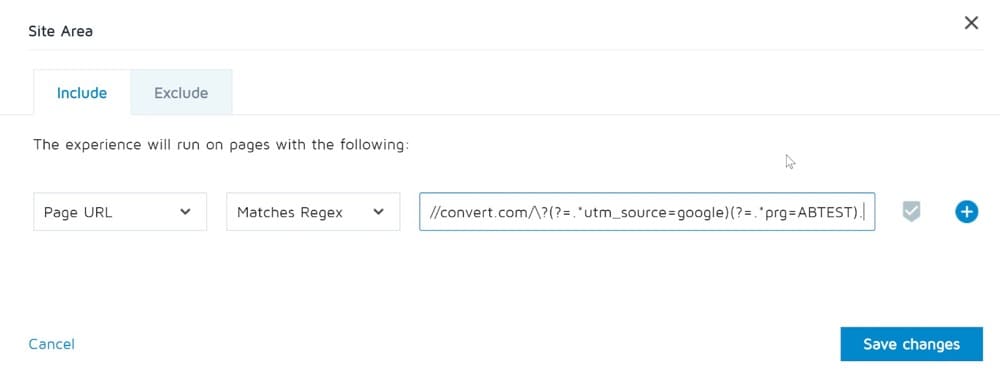
https://convert.com/\?(?=.*utm_source=google)(?=.*prg=ABTEST).*
例2
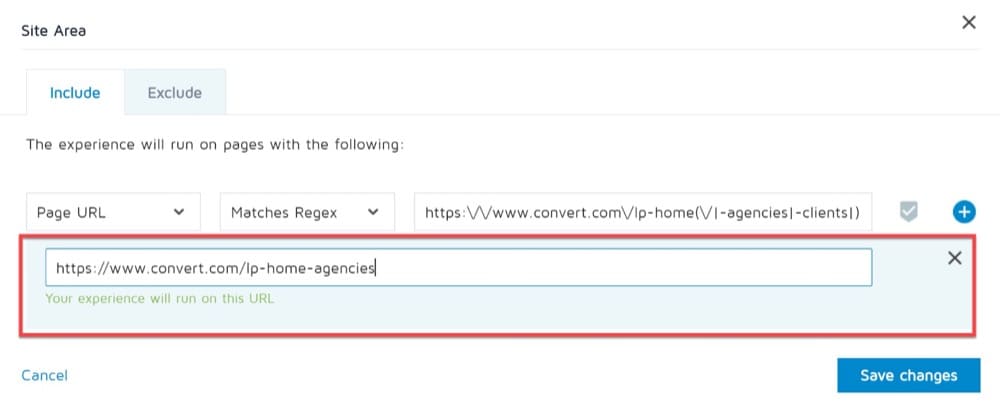
3つのランディングページを1つのバリアントと比較するとします。
ランディングページは次のとおりです。
- https://www.convert.com/lp-home
- https://www.convert.com/lp-home-agencies
- https://www.convert.com/lp-home-clients
バリアントはhttps://www.convert.com/lp-semhome/desktopです。
この例では、次のようにサイトエリアに正規表現を記述します。
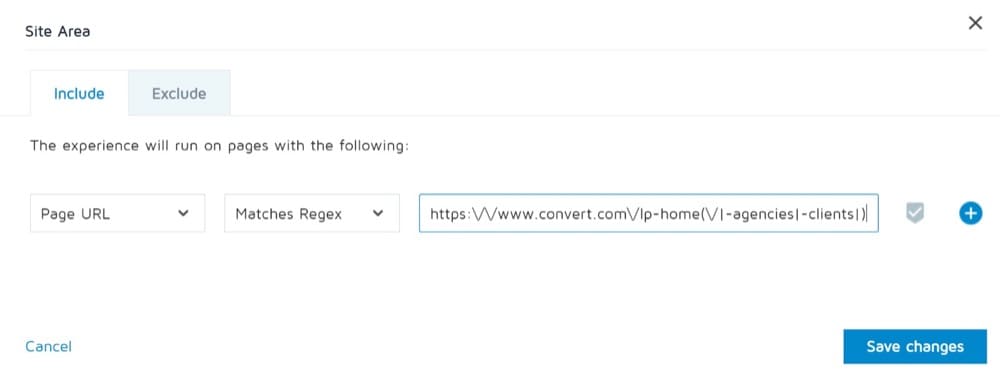
https:\ / \ / www.convert.com \ / lp-home(\ / | -agencies | -clients |)
例3
ここで、同僚が次のようなエクスペリエンスを設定するように依頼したとしましょう。
- オリジナルへのトラフィックは0である必要があります
- クエリパラメータにutm_bucket=competitorが含まれています
- トラフィックは2つのバリアント間で50/50に分割されるため、トラフィックがhttps://convert.com/?utm_bucket=competitorに到達すると、トラフィックの50%がhttps://convert.com/vs-offerpad/に到達します。 50%はhttps://convert.com/vs-zillow/にアクセスします
この場合、正規表現は次のようになります。
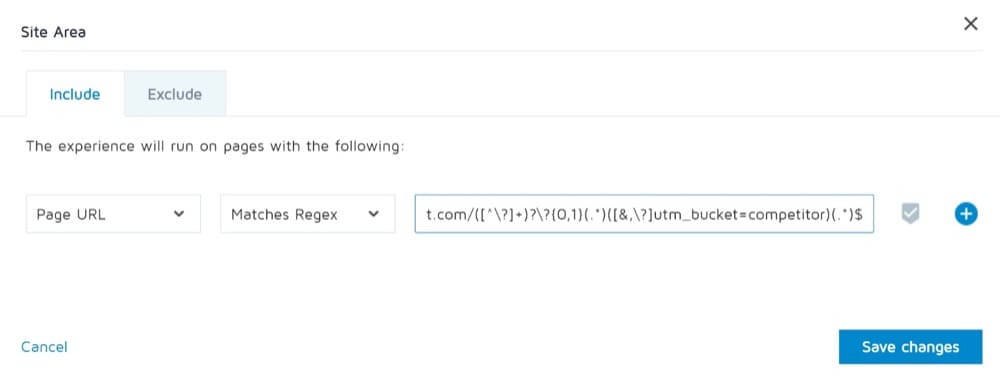
https://www.convert.com/([^\?]+)?\?{0,1}(.*)([&,\?]utm_bucket=competitor)(.*)$例4
別のケースとして、以下の条件をテストする場合があります。
- ページのURLには/collections/が含まれている必要があります
- ページURに/products/を含めることはできません
- ページのURLは完全に一致してはなりません:https://convert.com/collections/
- URLクエリパラメータに?v=tを含めることはできません
- 元のURLは、コレクションの下の任意のページにすることができます
ここでは、すべての条件を満たすために正規表現とオーディエンスを組み合わせる必要があります。 したがって、サイトエリアの正規表現は次のようになります。
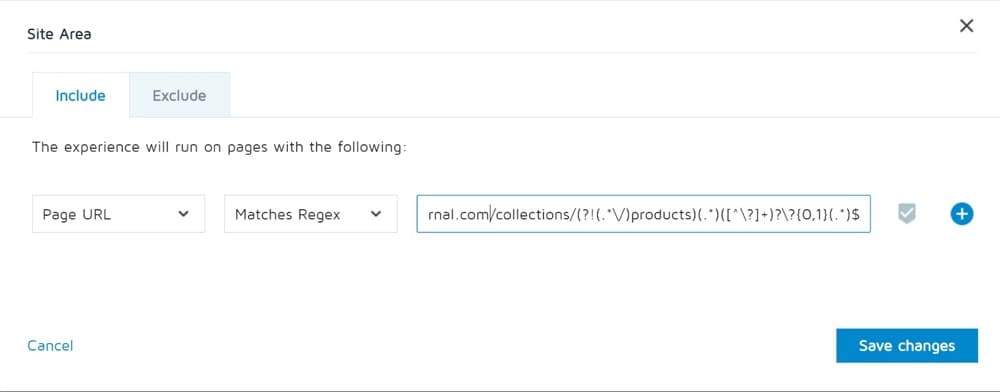
また、URLに?v=tが含まれる訪問者を除外するようにオーディエンスを定義することを忘れないでください。
https://www.convert.com/collections/(?!(.*\/)products)(.*)([^\?]+)?\?{0,1}(.*)$例5
この最後の例では、ショップサイズがURLに含まれている場合に、テストを実行してトラフィックを元のURLとバリアントの間で分割するスプリットURLエクスペリエンスを実行するとします。
1.オリジナルは次のいずれかになります。
https://convert.com/products/shop-size
https://convert.com/collections/new-products-deals/products/shop-size
https://convert.com/collections/fitting/products/shop-size
2.バリエーションURLは次のようになります:https://convert.com/products/the-original-fittings
ここで、これはあなたの正規表現になります:
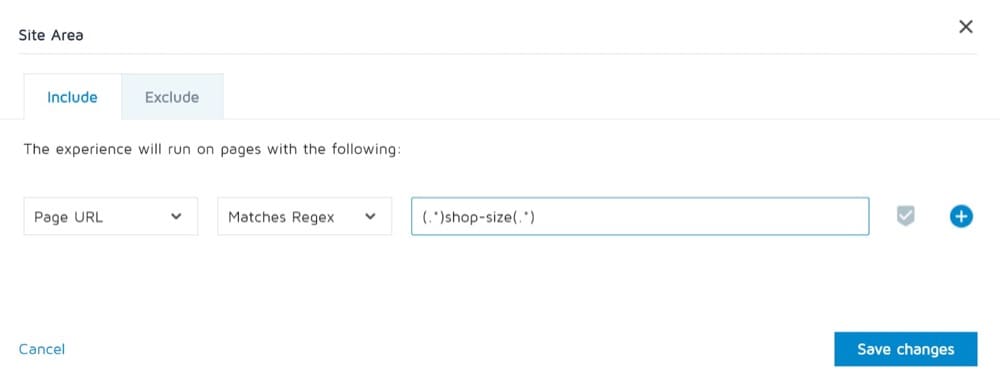
2.正規表現を使用するオーディエンス
Convert Experiencesアプリで正規表現を利用できるもう1つのセクションは、オーディエンスです。
オーディエンスとは、共通点があるユーザー/Webサイト訪問者のグループです。 オーディエンスを使用して、場所、サイトへのアクセスに使用されたデバイス、時間帯、ランディングページ、その他のユーザーの行動などの特定の基準に基づいて、Webサイトの訪問者をグループに分類します。
別のサブグループへの訪問者は、同じように行動または購入する可能性があります。 Convertが訪問者に適格なオーディエンスを決定し、正しいテストまたはバリエーションを実行できるようにする条件を指定することにより、オーディエンスを作成できます。
正規表現は、提供する3つのオーディエンスタイプの1つであるセグメンテーションでのみサポートされます。
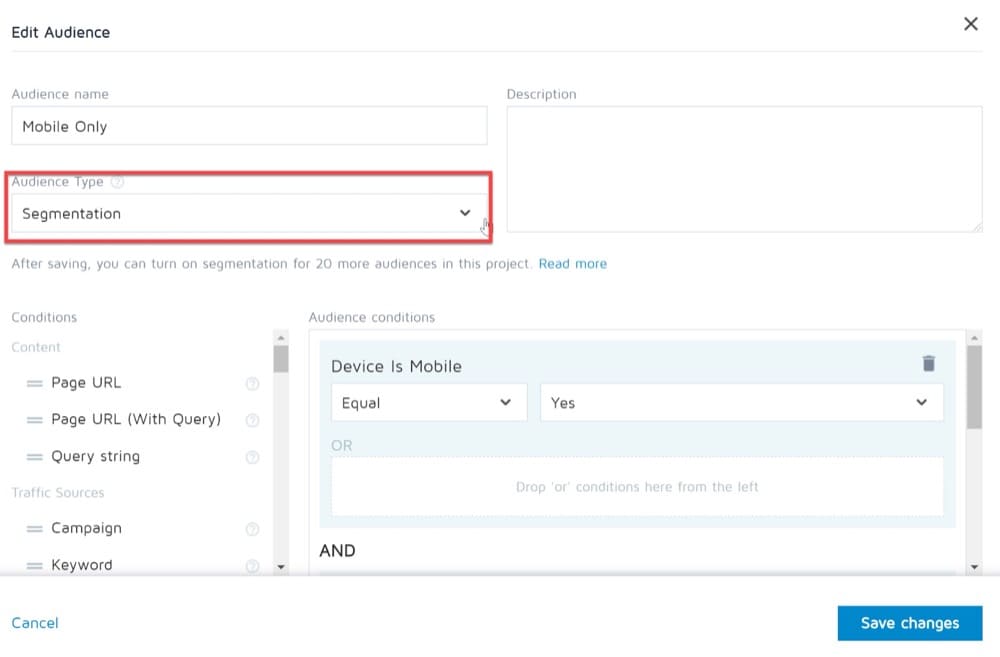
このタイプのオーディエンスを選択すると、次の条件が利用可能になります。
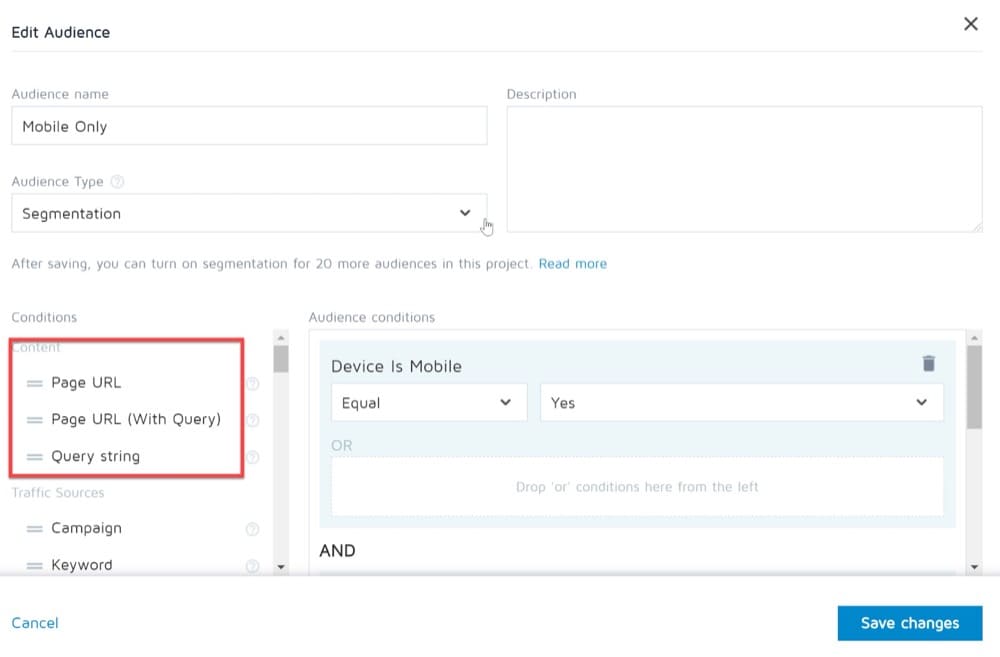
例
ランディングページが「製品」などの一般的な用語で構成されているWebサイト訪問者をターゲットにしたエクスペリエンスを実行するとします。 この場合、左側のリストから「ページURL」条件を選択し、次に「正規表現に一致」を演算子として選択します。
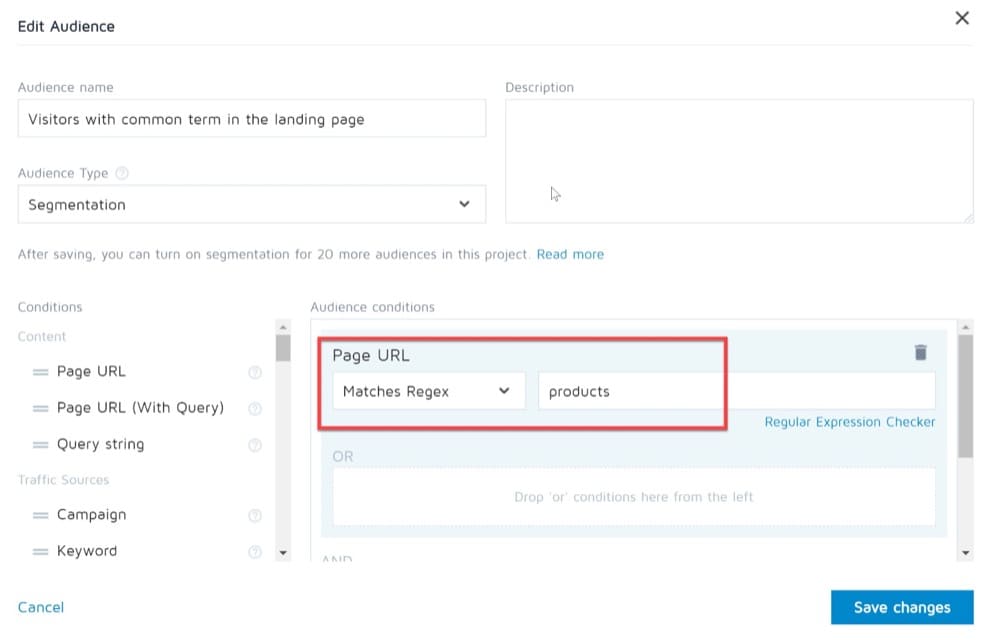
そして、あなたは完了です!
3.正規表現の目標
エクスペリエンスの目標コンバージョンを追跡するには、コンバージョンを記録するページのURLを指定する必要があります。 Convert Experiencesを使用すると、目標の変換を記録する特定のURL、ページパターン、またはページの正規表現(regex)を入力できます。
例
あなたの目標があなたのウェブサイトの特定のページにアクセスするユーザーの数をチェックすることであるとしましょう。
この場合、目標タイプを「特定のページにアクセス」として定義し、ユーザーがアクセスする必要のあるページURLを入力して、コンバージョンを記録する必要があります。
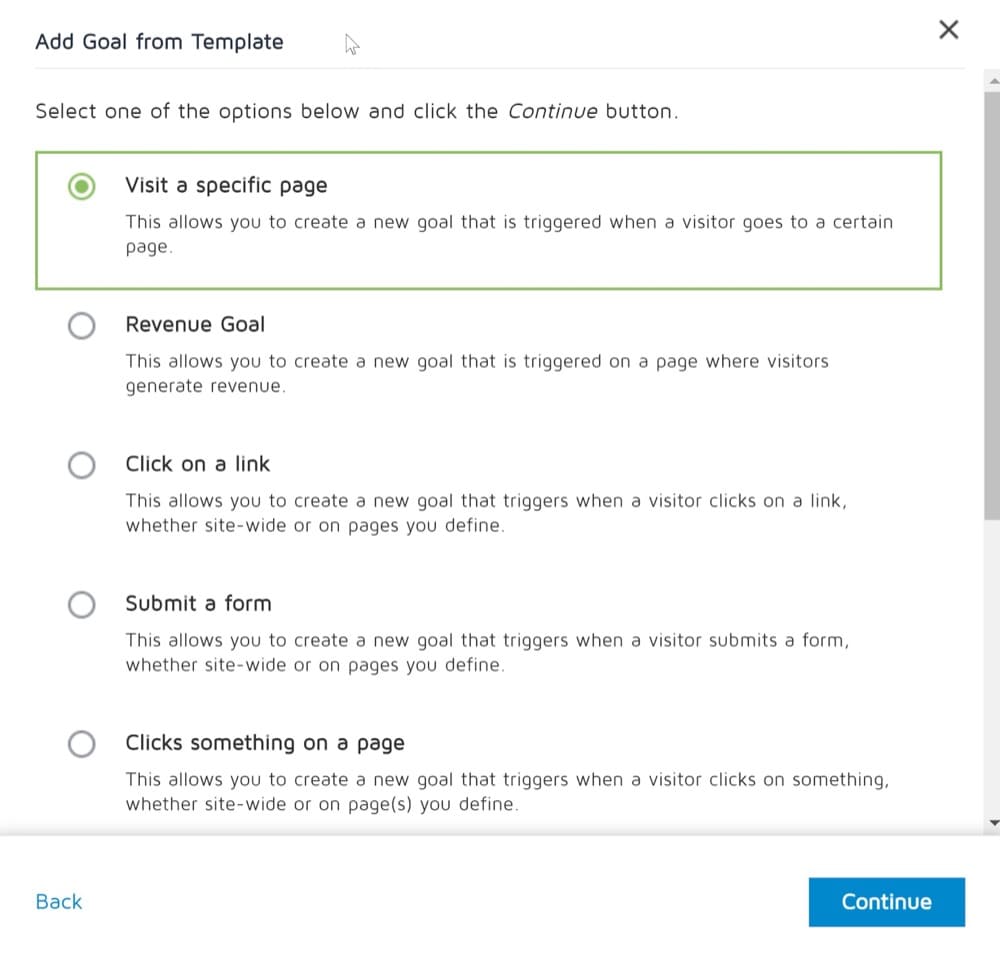
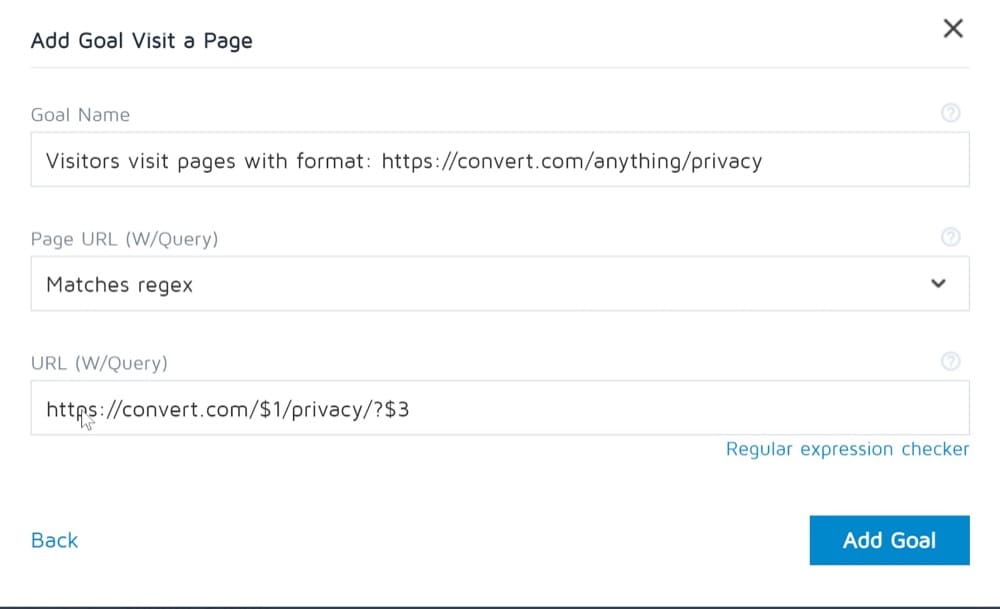
そして、これはあなたの正規表現がどのように見えるかです:
https://convert.com/$1/privacy/?$3
4.アクティブなWebサイトの正規表現
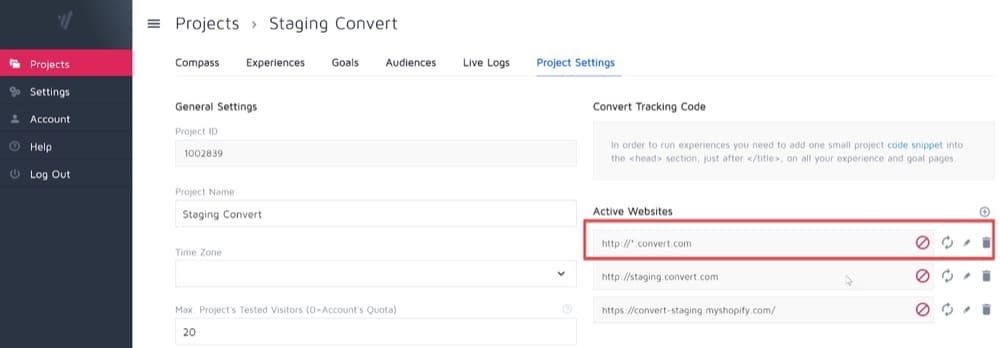
Convertは、「アクティブなWebサイト」設定でワイルドカードをサポートします。
たとえば、「domain.com」の下にすべてのサブドメインを含める場合は、「 http://*.domain.com 」のように「ActiveDomain」エントリを設定する必要があります。
正規表現を使用するときに避けるべき一般的な間違い
URLターゲティングの正規表現を一度定義してから無視するだけでは不十分です。 適切なページ/オーディエンス/目標が適切な実験で継続的に行われるようにするには、定期的なクリーンアップとチェックが必要です。
サポートチケットによく見られる主な間違いは次のとおりです。
1.開始文字と終了文字を含める
開始文字と終了文字(^と$)を含めると、パターンの前後のテキストを含むURLは一致しません。
それらの使用は避けてください。
追跡目的でURLに追加されるUTMパラメータなど、URLの最後にクエリ文字列が含まれることは非常に一般的です。
この例は次のとおりです。
https://www.convert.com/?utm_campaign=ads
2.スラッシュを含める
URLの末尾のスラッシュ(/)は、通常、オプションです。
正規表現の最後にその文字が含まれている場合、同じURLにアクセスしても、スラッシュなしでは一致しません。 その最後のスラッシュ文字は含めない方がよいでしょう。
3.文字数制限を超えています
すべての正規表現ターゲティングルールには750文字の制限があります。 この制限を超えても、問題を警告するエラーはスローされません(この制限に簡単に到達することはできないと思いますが)。
4.同じページで同時実験を実行する
同じページで複数の実験を同時に実行しようとすると、訪問者がどの実験に参加する必要があり、どの変更を最初に適用するかについて衝突が発生します。
このため、正規表現のURLターゲティングには注意する必要があります。 複数のA/Bテストのターゲティングルールを使用して同じページをターゲティングする場合は、衝突を防ぐためにこれらの手順を使用する必要があります。
正規表現を理解したり、Convert ExperiencesのURLターゲティングについてサポートを求めている場合は、サポートチームが質問に答える準備ができています。 アプリ内チャットを通じていつでも私たちに連絡することができます。 テストで自信を持って正規表現を使い始めることができるように、概要といくつかの例を紹介します。

