
銀行セキュリティの強化: 不正行為検出のための機械学習
公開: 2023-11-14あらゆる機会には脅威が伴います。 銀行業界のデジタル化への移行により、顧客エクスペリエンスが向上し、これまで銀行口座を利用していなかった層にも顧客ベースが拡大しました。 欠点は、オンライン取引とデジタル決済ソリューションにより、詐欺師が悪用する新たな道が開かれてしまうことでした。
KMPG の不正調査の結果によると、サイバー攻撃の頻度と重大度が増大しており、その結果、数十億ドルの損失が発生していることがわかります。
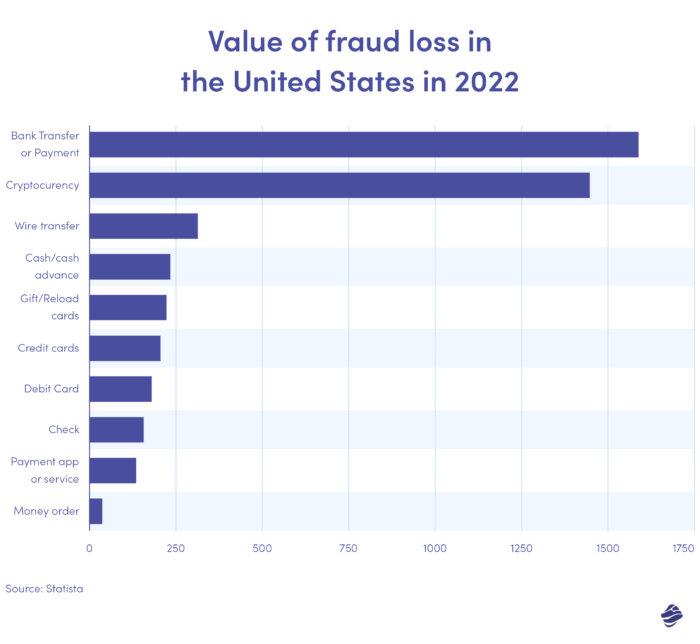
上のグラフは、2022 年の米国における支払方法別の詐欺被害額を示しています。銀行振込と支払いが最も多く、損失額は 15 億 9,000 万ドルでした。
これらの損失により、銀行機関は金融詐欺を検出、軽減、防止するための新しいソリューションの導入を余儀なくされています。 そのような手法の 1 つが人工知能 (AI)、特に機械学習です。
この記事では、利点や実際のアプリケーションなど、不正行為検出のための機械学習について知っておくべきことすべてについて説明します。
不正行為検出の進化
従来の不正検出は、ルールベースのアプローチに従います。 名前が示すように、取引が本物であるか不正であるかを決定する一連のルールまたは条件に基づいて動作します。 一般的な条件には、場所 (購入はユーザーの通常のエリア外か) と頻度 (購入の数と種類はユーザーにとって通常のものか) が含まれます。
取引は条件を満たした場合にのみ成立します。 たとえば、オハイオ州の顧客がニュージーランドで突然 POS チャージを請求されたとします。 場所がユーザーの市外局番外であるため、システムはトランザクションに不正なフラグを立てます。
このタイプの不正検出システムにはいくつかの欠点があります。
- 多数の誤検知が発生します。 ここで、本物の顧客からの支払いをブロックします。
- 柔軟性がありません。 ルールベースのアプローチでは固定された結果が使用されるため、デジタル バンキングのトレンドに適応することが困難になります。 新しい形態の詐欺を捕捉するにはルールを変更する必要があります。
- スケールが合わないんです。 データが増加すると、それを防ぐために必要な労力も増加します。 システムへの変更はすべて手動で行われるため、費用と時間がかかります。
ルールベースの不正検出が機能します。 ただし、その欠点により、現代のデジタル環境には適していません。 パターンを認識できず、人間の介入に依存します。
さらに、ハッカーは 9 時から 5 時までのスケジュールを遵守せず、位置情報のスプーフィングや顧客の行動のなりすましなどの高度な手法を導入して、不正検出システムを騙す可能性があります。 したがって、24 時間年中無休で稼働する、同様に高度に開発されたシステムが必要です。
機械学習を導入します。
機械学習は、データを使用して不正検出アルゴリズムをトレーニングし、データのパターンと関係を明らかにし、洞察を得て、予測を行う人工知能 (AI) です。
たとえ機械学習を知らなかったとしても、あなたはすでに機械学習についてよく知っています。 たとえば、Instagram の投稿に取り組むたびに、好きなコンテンツの種類に関する情報をアルゴリズムにフィードします。 次に、アプリを検索して同様のコンテンツを探してフィードに追加します。
機械学習が不正検出をどのように変えるか
機械学習を使用した銀行業務における不正検出は、より迅速、より柔軟、より正確に不正を特定し、対応できるようになり、すでに業界に変化をもたらしています。
AI システムは顧客データのパターンを分析し、過去の脅威や新たな脅威に基づいてルールを自動的に変更します。
先ほど述べたニュージーランドの POS 料金を覚えていますか? 機械学習を使用した不正行為検出では、同じ銀行カードでその場所への航空券が購入されたとみなします。 したがって、新しい借方は正当である可能性が最も高くなります。
不正行為を検出するアルゴリズムをトレーニングするために、教師あり機械学習と教師なし機械学習という 2 つのモデルが使用されます。
教師あり機械学習
教師あり学習モデルは、不正または非不正としてタグ付けされた大量のデータをアルゴリズムに供給します。 アルゴリズムはこれらの例を研究し、正当な取引と不正な取引を区別するパターンと関係を学習します。
この学習モデルはデータに手動でタグ付けする必要があるため、時間がかかります。 さらに、データセットは正しくラベル付けされ、よく整理されている必要があります。 トランザクションのタグ付けが間違っていると、アルゴリズムの精度に影響します。
さらに、トレーニング セットに含まれる入力からのみ学習します。 したがって、履歴データの一部ではない、新しく開始されたモバイル バンキング アプリの機能を介した取引にはフラグが立てられません。 詐欺師が悪用できる抜け穴が存在します。
教師なし機械学習
教師なし学習モデルでは、人間による入力は最小限に抑えられます。 このアルゴリズムは、大量のタグなしデータからパターンと関係を学習し、類似点と相違点に基づいてデータセットをグループ化します。
目的は、トレーニング データ セットに含まれていない異常なアクティビティを特定することです。 したがって、教師なし学習は、教師あり学習が途切れたところを回復し、新たな不正行為を検出します。
教師あり機械学習モデルと教師なし機械学習モデルのどちらかを選択する必要はないことに注意してください。 これらは一緒に使用することも (半教師あり学習モデル)、単独で使用することもできます。
不正行為検出に ML を使用する利点
銀行業務における機械学習を使用した不正検出の利点については示唆しましたが、さらに詳しく説明します。
- スピード
機械学習の計算は迅速に行われ、リアルタイムで不正行為の判断が下されます。 ルールベースのアルゴリズムもリアルタイムで決定しますが、不正行為のフラグを立てるには書面によるルールに依存します。
事前定義されたルールがない新しいシナリオでは何が起こるでしょうか? 偽陽性または偽陰性が発生します。
機械学習は新しいパターンを自動的に検出し、定期的な顧客のアクティビティを分析し、ミリ秒以内に適切な結果を計算します。
- 正確さ
ルールベースの検出システムは、顧客の行動の微妙な違いを検出しないため、本物の取引をブロックしたり、不正な取引を許可したりします。
機械学習システムは、既知の不正行為など、明文化されたルールを超える変数を考慮します。 これらの変数はトランザクションの状況を把握するのに役立ち、誤検知の率を下げます。
- 柔軟性
機械学習は柔軟かつ反応的です。 自己学習機能により、このシステムは新しいシナリオに適応し、新しい脅威を検出できます。 ルールベースのシステムは厳格であり、学習機能がありません。 したがって、事前に定義されたルールに従ってのみ不正行為に対応できます。
- 効率
機械学習アルゴリズムは、1 秒あたり数千のトランザクション データを分析できます。 軽度から中度の不正事件の調査に人件費や諸経費を費やす代わりに、機械学習を使用すれば、反復的または明らかな不正行為を処理できます。 これにより、詐欺の専門家は人間の洞察を必要とする複雑なパターンに集中できるようになります。
- スケーラビリティ
データ量の増加により、ルールベースのシステムに圧力がかかります。 新しいルールによりシステムは複雑になり、保守が困難になります。 エラーや矛盾があると、モデル全体が無効になる可能性があります。
機械学習システムはその逆です。 大量の新しいデータを吸収するだけでなく、改善も行います。
不正行為の検出に使用される機械学習技術
AI 不正検出で使用されるさまざまなアルゴリズムを検討する前に、システムがどのように機能するかを概説しましょう。
最初のステップはデータ入力です。 モデルの精度はデータの量と品質によって異なります。 高品質のデータを追加するほど、モデルの精度が高まります。
次に、モデルはデータを分析し、正常な動作と不正な動作を表す主要な特徴を抽出します。 これらの機能には、顧客 ID (電子メールまたは電話番号)、場所 (IP または配送先住所)、支払い方法 (カード所有者名および発行国) などが含まれます。
3 番目のステップは、本物の取引と不正な取引を区別するために (より多くのデータを使用して)アルゴリズムをトレーニングすることです。 モデルはトレーニング データ セットを受け取り、さまざまなケースにおける不正の確率を予測します。 アルゴリズムが十分にトレーニングされたら、起動する準備が整います。
次に、使用できるさまざまなアルゴリズムを見てみましょう。
1. ロジスティック回帰
ロジスティック回帰は教師あり学習アルゴリズムです。 モデルのパラメーターに基づいて、不正の確率を 2 値スケール (不正か非不正か) で計算します。
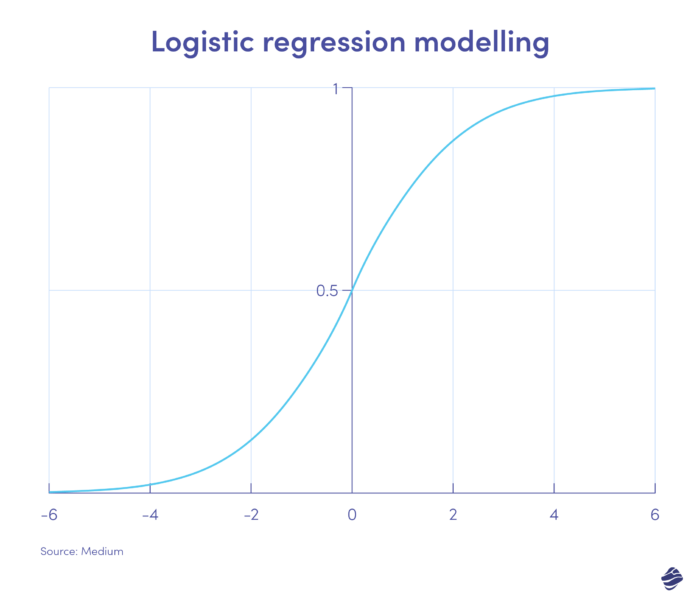
グラフのプラス側にあるトランザクションは不正である可能性が高く、マイナス側にあるトランザクションは正当である可能性が最も高くなります。
2. ディシジョンツリー
デシジョン ツリーは教師あり学習アルゴリズムですが、ロジスティック回帰アルゴリズムよりもさらに高度なものです。 これは、データをレベルごとに分析して取引が本物か不正かを判断する階層的な意思決定構造です。
以下は、クレジット カードの不正行為を検出するためのデシジョン ツリーの図です。
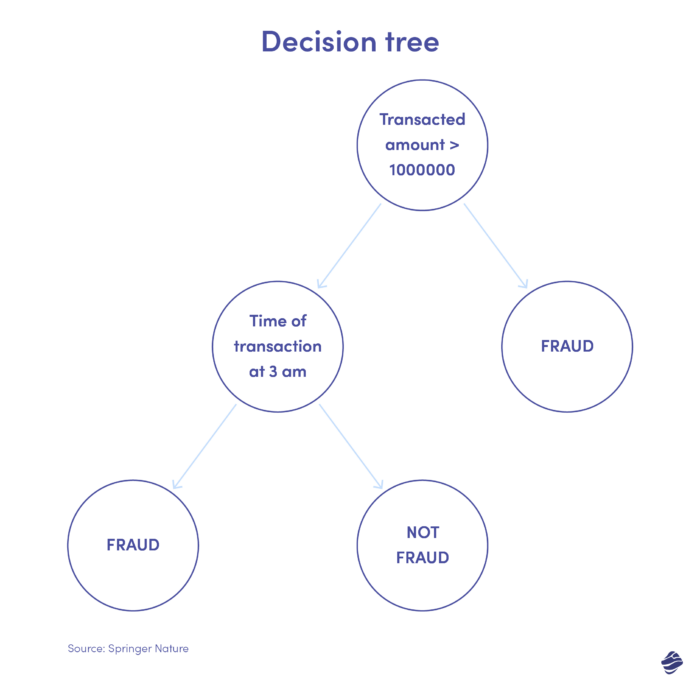
不正取引かどうかを判断する条件は取引金額です。 トランザクションの値が設定されたしきい値を超えると、アルゴリズムはそのトランザクションを不正であるとみなします。 そうでない場合、ツリーは別の条件、つまりトランザクション時間をチェックします。 通常とは異なるタイミング(ここでは午前 3 時)の場合は、詐欺の可能性があります。 そうでない場合は、別の条件がチェックされます。 それは続きます。
3. ランダムフォレスト
ランダム フォレストは多くのデシジョン ツリーを組み合わせたもので、各デシジョン ツリーが ID や場所などのさまざまな条件をチェックします。
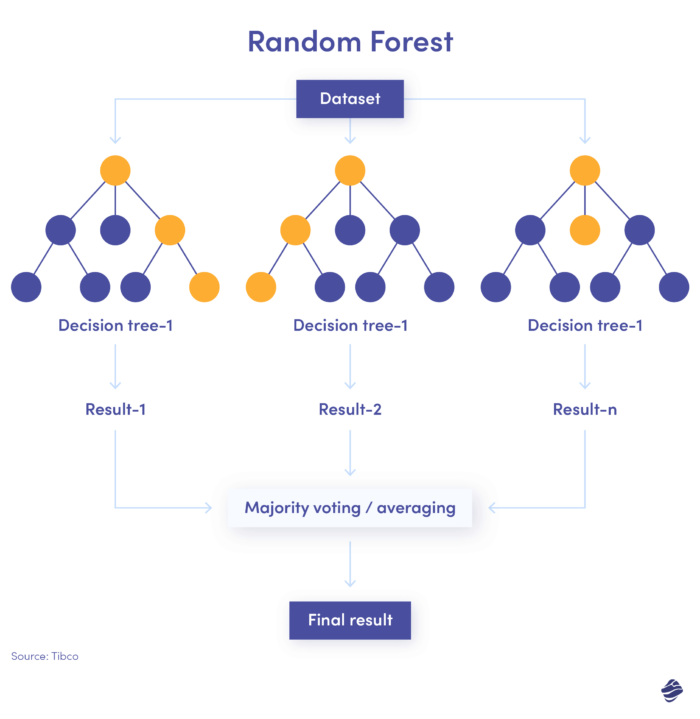
すべてのパラメータをチェックした後、各サブツリーで決定が行われます。 合計値により、取引が本物であるか不正であるかが決まります。

4. ニューラルネットワーク
ニューラル ネットワークは複雑な教師なしアルゴリズムです。 人間の脳にヒントを得たニューラル ネットワークは、データを複数の層で処理して高レベルの特徴を抽出します。 このアルゴリズムは、画像、テキスト、音声、その他のデータのパターンを認識できるディープ ラーニングと連携しています。
これはニューラル ネットワークの簡略化されたバージョンです。
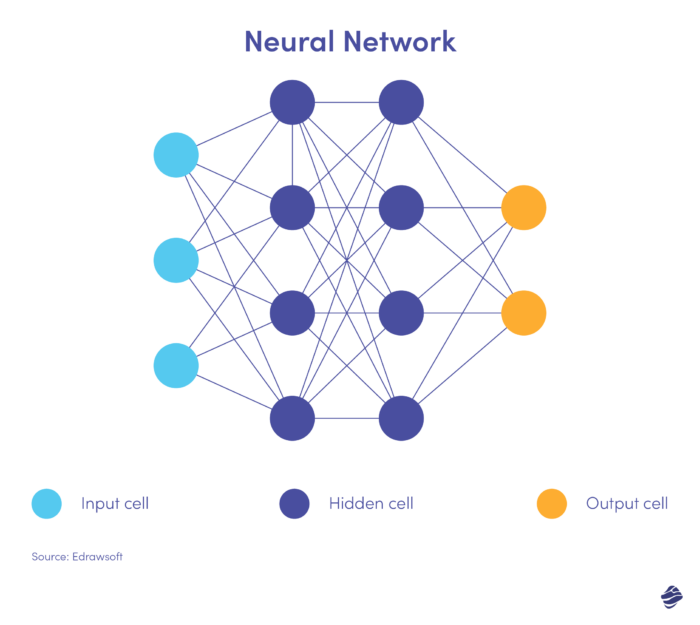
ニューラル ネットワークには、入力層、隠れ層、出力層の 3 つの層があります。 入力層はデータを処理し、隠れ層は入力層からのデータを分析して隠れたパターンを特定し、出力層はデータを分類します。
ディープ ニューラル ネットワークにはいくつかの隠れ層があります。 これらは、非線形関係を特定し、前例のない詐欺シナリオを検出するのに最適です。
5. サポートベクターマシン
サポート ベクター マシン (SVM) は、外れ値を予測、分類、検出する教師あり学習アルゴリズムです。
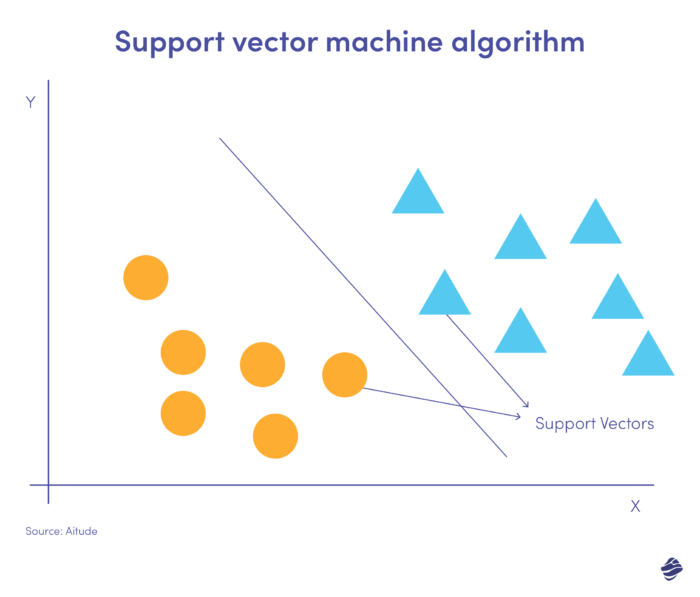
この線形 SVM の図は、超平面と呼ばれる直線で区切られた 2 つのデータ セットを示しています。 データを不正か非不正かに分類する決定境界です。
超平面から離れたデータ点は簡単に分類できます。 サポート ベクター (超平面に最も近い) を分類するのは困難です。 これらの外れ値は、除去されると超平面の位置に影響を与える可能性があります。
6. K 最近傍
K 最近傍 (KNN) は教師あり学習アルゴリズムです。 類似したアイテムが互いに近くに存在するという前提で動作します。
以下に簡単な図を示します。
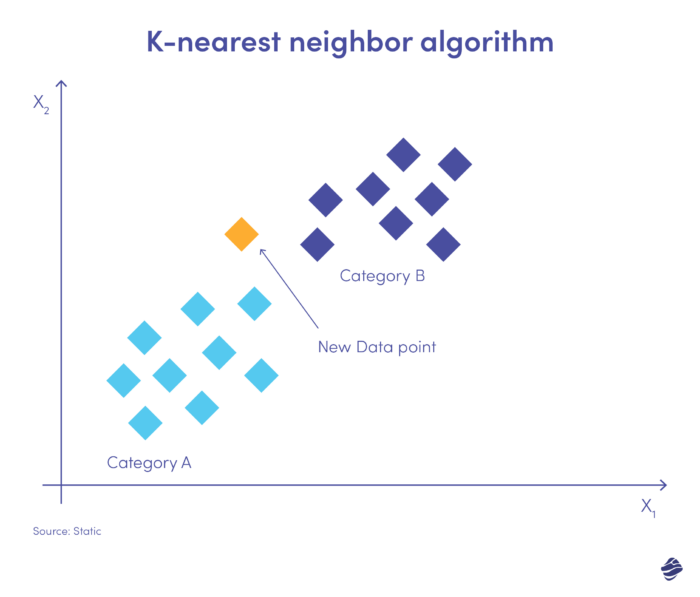
新しいデータ エントリは、カテゴリ A または B のいずれかに配置する必要があります。アルゴリズムは、ユークリッド距離と呼ばれる数式を使用してデータ ポイント間の距離を計算します。 新しいデータ ポイントは、最も多くの近傍を持つグループに分類されます。 最も近いデータ セットに「不正」のタグが付いている場合、そのトランザクションは不正として分類されます。
課題の解決と戦略的考慮事項
すべてのテクノロジーと同様に、不正検出のための機械学習の統合に関連して痛みが増大しています。 ここでは、直面する可能性のある一般的な課題をいくつか示します。
不十分なインフラストラクチャ
多くの銀行システムは、大量の複雑なデータを分析できません。 さらに、ほとんどのデータはサイロ化され、別のストレージ施設に保管されます。
残念ながら、この問題をすぐに解決する方法はありません。 適切なハードウェアとソフトウェアに投資する必要があります。
経験豊富なフィンテック アプリ開発代理店と提携し、特定のデータ セットに適切なアルゴリズムを自動的に選択し、生データをインポートして機械学習用に準備し、データを視覚化し、アルゴリズムをテストするなどのインフラストラクチャをセットアップする必要があります。
データの品質とセキュリティ
データ品質は、不正行為検出のための機械学習の導入を検討している金融機関にとって重要な問題です。 機械学習モデルは、良いデータと悪いデータを区別しません。 したがって、アルゴリズムが無関係または不完全なデータで汚染されている場合、モデルの精度は不正確になります。
Amazon Kinesis などのデータ取り込みソリューションは、生データを収集、クリーンアップ、変換して、機械学習モデルに適したものにします。 データがクリーンアップされ、整理されたら、機密データと非機密データを分離する必要があります。 機密情報を暗号化し、安全な施設に保管します。 このデータへのアクセスも制限する必要があります。
才能の欠如
人々が恐れていることとは裏腹に、機械学習は仕事を奪っているわけではありません。 それはまったく逆です。 人間の洞察力と経験を必要とする複雑な事件を管理するには、依然として不正アナリストが必要です。 また、機械学習は新しいテクノロジーであり、この分野の専門家が不足しています。
これは求職者にとっては朗報ですが、機械学習の可能性を最大限に活用できない機関にとってはそうではありません。 機械学習を実装するためのスキルセットを持つ企業と提携することで、このスピードバンプを克服できます。
機械学習を使用した銀行業務における不正検知のケーススタディ
次に、機械学習を使用した銀行業務における不正検出の実例を見てみましょう。
不正行為の検出
ダンスケ銀行はデンマークの多国籍金融会社です。 デンマーク最大の銀行であり、北欧の大手小売銀行です。 ルールベースの検出システムの下で、この銀行は不正行為を軽減するのに苦労しました。 不正検出率は 40%、誤検知率は 99.5% でした。
データ ソフトウェア会社である Teradata と協力して、Danske は潜在的な不正行為の特定を支援するために深層学習ソフトウェアを統合しました。 その結果、偽陽性が 60% 減少し、真陽性が 50% 増加しました。
マネーロンダリング対策
OakNorth は英国の商業融資銀行で、規模を拡大する企業に企業および個人の金融サービスを提供しています。 この銀行の審査プロセスは分断されており、1 つのプロバイダーがマネーロンダリング対策小切手を担当し、別のプロバイダーが顧客向けに対応していました。 さらに、政治的暴露者(PEP)の検査では多くの誤検知が発生しました。
この銀行は、詐欺および AML 検出会社である ComplyAdvantage と協力して、スクリーニングおよび継続的な監視ソリューションを統合して、コンプライアンスを合理化し、データを統合しました。 これにより、銀行の融資業務と貯蓄業務の間の迅速なデータ転送が容易になりました。
信用引受
Hawaiian USA Credit Union はハワイ最大の信用組合であり、フォーブス誌のベスト信用組合の 1 つです。 フィンテック企業に対して競争力を持ち、リスクを増大させることなく個人向けローンのポートフォリオを拡大したいと考えていました。
Zest AI と連携して、この信用組合は AI 主導の個人ローン モデルを使用して意思決定プロセスを自動化しました。 このモデルは 278 の変数を使用して、VantageScore 信用スコアリング システムよりも深い洞察を提供しました。 その結果、承認率は 21% 増加し、債務不履行/融資申請の不正率は 0% となりました。
不正行為検出に ML を使用する場合の重要な考慮事項
機械学習を使用した銀行業務における不正検出は効率的ですが、気が遠くなる作業でもあります。 これらのシステムは多くの正確なデータを必要とし、そうでないとモデルが期待どおりに機能しません。
そこで、機械学習プロセスを最適化するためのヒントをいくつか紹介します。
1. 入力変数の数を制限する
この記事全体を通して、「多ければ多いほど良い」と述べてきました。 データ量に関しては、これが当てはまります。 ただし、不正検出変数の数は少ないほど多くなります。
不正行為を調査する際に考慮すべき一般的な機能は次のとおりです。
- IPアドレス
- 電子メールアドレス
- お届け先の住所
- 平均注文/取引額
機能が少ないことの利点は、アルゴリズムのトレーニング時間が短縮されることです。 また、データセットの重複や無関係の問題も回避できます。
2. 法規制への準拠を確保する
不正行為の防止はデータ セキュリティの一部です。 もう 1 つはデータのプライバシーです。 多くの国には、機関が顧客データを収集、使用、保存する方法に関する法律があります。 いくつか例を挙げると、中国の個人情報保護法 (PIPL)、カリフォルニア州消費者プライバシー法 (CCPA)、欧州連合の一般データ保護規則 (GDPR) などがあります。
これらの法則は、機械学習で使用されるデータに影響を与えます。 ほとんどのデータ プライバシー コンプライアンス規制における主な原則は、通知と同意です。 機械学習アルゴリズムのトレーニング用のデータなど、ユーザーのリクエスト以外の目的で顧客データを使用する場合は、通知して許可を得る必要があります。
プライバシー基準を確実に遵守する最も簡単な方法は、規制に準拠した機能を備えた技術パートナーを利用することです。 たとえば、データのプライバシーとセキュリティを維持する方法を理解している銀行アプリ開発会社と提携する必要があります。
3. 適切なしきい値を設定する
トランザクション値ルールには、承認または拒否の応答をトリガーするための最小要件があります。 セキュリティとユーザー エクスペリエンスのバランスをとるしきい値が必要です。 しきい値が厳しすぎると、正当なトランザクションがブロックされる危険があります。 しきい値が緩すぎると、詐欺の成功率が高くなります。
リスク選好度を計算して、適切なバランスを見つけてください。 リスクレベルは金融機関や商品ごとに異なります。 たとえば、小規模融資銀行のサービスでは、少額融資に対して高いしきい値を設定することができます。 商業銀行は住宅ローンに対してこれほど寛大ではありません。
将来を予測する
未来は今ですが、不正行為対策プログラムで機械学習を使用している組織はわずか 17% です。 取り残されないでください。
機械学習を通じて銀行のセキュリティに期待できるブレークスルーをいくつか紹介します。
- デバイス プロファイリング: 銀行ネットワークに接続するさまざまなデバイスを識別し、特定のデバイスの機能と動作を分析します。
- 自動化された異常検出と対応: 既知のデバイスからの不正行為を特定し、影響を受けるシステムを隔離します。
- ゼロデイ検出: これまで知られていなかった脆弱性やマルウェアを特定し、組織をサイバー攻撃から保護します。
- データマスキング: 機密データを自動的に検出して匿名化します。
- 拡張された洞察: 複数のデバイスおよび場所にわたる不正行為の傾向を特定します。
- 革新的なポリシー: 機械学習の洞察を使用して、関連するセキュリティ ポリシーを推進します。
資産管理機関であっても信用組合であっても、AI と機械学習には不正行為を検出する大きなチャンスが秘められています。
ただし、ハッカーはこれらのテクノロジーを保護手段を回避するためにも使用することを覚えておくことが重要です。 こうした攻撃に先手を打つには、機械学習モデルを更新してください。 古き良き人間の知性を利用して AI ベースのセキュリティを強化することもできます。