
Webクローラーの概要
公開: 2016-03-08私が何をしているのか、SEOとは何かについて人々に話すとき、彼らは通常それをかなり早く理解するか、彼らがそうするように行動します。 優れたウェブサイト構造、優れたコンテンツ、優れた裏書バックリンク。 しかし、時々、それはもう少し技術的になり、私はあなたのウェブサイトをクロールする検索エンジンについて話すことになり、私は通常それらを失います…
なぜウェブサイトをクロールするのですか?
Webクロールは、インターネットのマッピングと、各Webサイトの相互接続方法から始まりました。 また、新しいオンラインページを見つけてインデックスを作成するために、検索エンジンでも使用されました。 Webクローラーは、Webサイトをテストし、問題が発見されたかどうかを分析することにより、Webサイトの脆弱性をテストするためにも使用されました。
今、あなたはあなたに洞察を提供するためにあなたのウェブサイトをクロールするツールを見つけることができます。 たとえば、OnCrawlはコンテンツに関するデータを提供し、オンサイトSEOまたはMajesticは、ページを指すすべてのリンクに関する洞察を提供します。
クローラーは情報を収集するために使用され、情報を使用および処理してドキュメントを分類し、収集されたデータに関する洞察を提供します。
クローラーの構築は、コードを少し知っている人なら誰でもアクセスできます。 ただし、効率的なクローラーを作成することはより困難であり、時間がかかります。
それはどのように機能しますか?
WebサイトまたはWebをクロールするには、最初にエントリポイントが必要です。 ロボットはあなたのウェブサイトが存在することを知っている必要があります。そうすれば彼らは来てそれを見ることができます。 昔は、あなたのウェブサイトがオンラインであることを彼らに伝えるためにあなたはあなたのウェブサイトを検索エンジンに提出したでしょう。 今、あなたはあなたのウェブサイトへのいくつかのリンクを簡単に構築することができます、そしてあなたはループにいます!
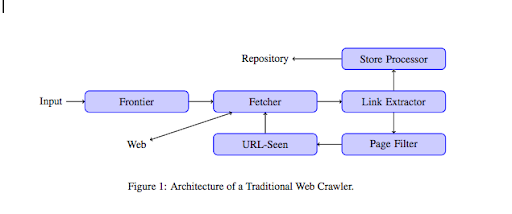
クローラーがWebサイトに到達すると、すべてのコンテンツを1行ずつ分析し、内部または外部に関係なく、各リンクをたどります。 リンクのないページに到達するまで、または404、403、500、503などのエラーが発生するまで、このように続けます。
より技術的な観点から、クローラーはURLのシード(またはリスト)を処理します。 これは、ページのコンテンツを取得するFetcherに渡されます。 次に、このコンテンツは、HTMLを解析してすべてのリンクを抽出するリンクエクストラクタに移動されます。 これらのリンクは、その名前が示すように、それらを保存するストアプロセッサの両方に送信されます。 これらのURLは、すべての興味深いリンクをURL表示モジュールに送信するページフィルターも通過します。 このモジュールは、URLがすでに表示されているかどうかを検出します。 そうでない場合は、ページのコンテンツなどを取得するFetcherに送信されます。
Flashなど、スパイダーがクロールできないコンテンツもあることに注意してください。 Javascriptは現在GoogleBotによって適切にクロールされていますが、時々クロールされません。 画像はGoogleが技術的にクロールできるコンテンツではありませんが、画像を理解し始めるのに十分スマートになりました!
ロボットが反対のことを言われなければ、ロボットはすべてを這うでしょう。 ここでrobots.txtファイルが非常に役立ちます。 クローラー(GoogleBotまたはMSN Botなどのクローラーごとに特定できます。ボットの詳細についてはこちらをご覧ください)に、クロールできないページを通知します。 たとえば、ファセットを使用したナビゲーションがあるとします。ロボットは付加価値がほとんどなく、クロールバジェットを使用するため、すべてのファセットをクロールしたくない場合があります。 この単純な線を使用すると、ロボットがそれを這うのを防ぐのに役立ちます
ユーザーエージェント: *
禁止:/ folder-a /
これは、すべてのロボットにフォルダAをクロールしないように指示します。
ユーザーエージェント:GoogleBot
禁止:/ repertoire-b /
一方、これは、GoogleボットのみがフォルダBをクロールできないことを指定します。
rel =” nofollow”タグを使用して特定のリンクをたどらないようにロボットに指示するHTMLの表示を使用することもできます。 一部のテストでは、リンクでrel =” nofollow”タグを使用しても、Googlebotによるフォローがブロックされないことが示されています。 これはその目的と矛盾しますが、他の場合に役立ちます。
[ケーススタディ]Googlebotのウェブサイトのクロール性を改善して可視性を向上させる
 ケーススタディを読む
ケーススタディを読む
クロール予算についておっしゃいましたが、それは何ですか?
あなたが検索エンジンによって発見されたウェブサイトを持っているとしましょう。 彼らは定期的にあなたがあなたのウェブサイトに更新を加えて新しいページを作成したかどうかを見に来ます。
各Webサイトには、Webサイトのページ数や健全性(たとえば、エラーが多い場合)などのいくつかの要因に応じて、独自のクロール予算があります。 検索コンソールにログインすることで、クロールの予算を簡単に把握できます。
クロール予算により、ロボットがWebサイトにアクセスするたびにクロールするページ数が決まります。 それはあなたがあなたのウェブサイトに持っているページの数に比例してリンクされており、それはすでにクロールされています。 一部のページは、特に定期的に更新される場合や重要なページからリンクされている場合に、他のページよりも頻繁にクロールされます。
たとえば、あなたの家は非常に頻繁にクロールされるメインのエントリポイントです。 ブログまたはカテゴリページがある場合、メインナビゲーションにリンクされていると、それらは頻繁にクロールされます。 ブログも定期的に更新されるため、頻繁にクロールされます。 ブログ投稿は、最初に公開されたときに頻繁にクロールされる可能性がありますが、数か月後には更新されない可能性があります。
ページがクロールされる頻度が高いほど、ロボットは他のページと比較して重要であると見なします。 これは、クロール予算の最適化に取り掛かる必要があるときです。
クロール予算の最適化
予算を最適化し、最も重要なページがそれに値する注目を集めるようにするために、サーバーログを分析し、Webサイトがどのようにクロールされているかを確認できます。
- トップページがクロールされる頻度
- 重要度の低いページが他のページよりもクロールされているのを確認できますか?
- ロボットは、Webサイトをクロールするときに、4xxまたは5xxエラーを頻繁に受け取りますか?
- ロボットはスパイダートラップに遭遇しますか? (マシューヘンリーはそれらについての素晴らしい記事を書きました)
ログを分析することで、重要性が低いと思われるページが頻繁にクロールされていることがわかります。 次に、内部リンク構造をさらに深く掘り下げる必要があります。 クロールされている場合は、それを指すリンクがたくさんある必要があります。
OnCrawlを使用して、これらすべてのエラー(4xxおよび5xx)の修正に取り組むこともできます。 これにより、クロール性とユーザーエクスペリエンスが向上します。これは、Win-Winのケースです。
クロールVSスクレイピング?
クロールとスクレイピングは、異なる目的で使用される2つの異なるものです。 Webサイトをクロールすると、ページが表示され、コンテンツをスキャンしたときに見つかったリンクをたどります。 その後、クローラーは別のページに移動します。
一方、スクレイピングとは、ページをスキャンして、ページから特定のデータを収集することです。タイトルタグ、メタディスクリプション、h1タグ、または価格表などのWebサイトの特定の領域です。 スクレーパーは通常「人間」として機能し、robots.txtファイルからのルールを無視し、フォームにファイルし、検出されないようにブラウザーのユーザーエージェントを使用します。
検索エンジンのクローラーは通常、スクレーパーとして機能するだけでなく、ランキングアルゴリズムでデータを処理するためにデータを収集する必要があります。 彼らは特定のデータを探しません。スクレーパーと比較して、ページで利用可能なすべてのデータを使用するだけで、さらに多くのデータを使用します(読み込み時間はページから取得できないものです)。 検索エンジンのクローラーは常に自分自身をクローラーとして識別します。これにより、Webサイトの所有者は、最後にWebサイトにアクセスしたのがいつかを知ることができます。 これは、実際のユーザーアクティビティを追跡するときに非常に役立ちます。
これで、クロール、その仕組み、およびそれが重要である理由についてもう少し理解できました。次のステップは、サーバーログの分析を開始することです。 これにより、ロボットがWebサイトとどのように相互作用するか、ロボットが頻繁にアクセスするページ、およびWebサイトにアクセスしているときに発生するエラーの数に関する深い洞察が得られます。
Webクローラーに関する技術的および歴史的な情報については、「Webクローラーの簡単な歴史」を参照してください。