
A/B テストは月に何回実行する必要がありますか?
公開: 2023-01-19
これは、テスト プログラムを成功させるために考慮すべき重要な質問です。
あまりにも多くのテストを実行すると、個々の実験からあまり価値が得られずにリソースが浪費される可能性があります。
ただし、実行するテストが少なすぎると、より多くのコンバージョンをもたらす重要な最適化の機会を逃す可能性があります。
では、この難問を考えると、理想的なテスト ケイデンスはどのようなものでしょうか?
その質問に答えるために、世界で最も成功している進歩的な実験チームのいくつかを見ることが$en$eになります。
Amazonは頭に浮かぶそのような名前の1つです。
eコマースの巨人は、実験のゴリアテでもあります. 実際、Amazon は年間 12,000 以上の実験を行っていると言われています。 この量は、1 か月あたり約 1,000 回の実験に相当します。
Google や Microsoft の Bing などの企業も同様のペースを維持していると言われています。
ウィキペディアによると、検索エンジンの巨人はそれぞれ、年間 10,000 件以上の A/B テスト、または 1 か月あたり約 800 件のテストを実行しています。
そして、この速度で実行されているのは検索エンジンだけではありません。
Booking.com は実験的なもう 1 つの注目すべき名前です。 旅行予約サイトは、年間 25,000 件以上のテストを実施していると報告されています。これは、1 か月あたり 2,000 件以上、または 1 日あたり 70 件以上のテストに相当します。
しかし、調査によると、平均的な企業は月に 2 ~ 3 回のテストしか実施していません。
では、ほとんどの企業が 1 か月に数回のテストしか実施していないが、世界最高の企業の一部が 1 か月に数千回の実験を実施している場合、理想的には何回のテストを実施する必要があるでしょうか?
真の CRO スタイルでは、答えは「場合による」です。
それは何に依存していますか? 考慮する必要がある重要な要素の数。
実行する A/B テストの理想的な数は、特定の状況と、サンプル サイズ、テストのアイデアの複雑さ、利用可能なリソースなどの要因によって決まります。
A/B テストを実行する際に考慮すべき 6 つの要素
1 か月に実行するテストの数を決定する際に考慮すべき 6 つの重要な要素があります。 それらには以下が含まれます
- サンプルサイズの要件
- 組織の成熟度
- 利用可能な資源
- テストのアイデアの複雑さ
- テストのタイムライン
- 相互作用効果
それぞれについて深く掘り下げてみましょう。
サンプルサイズの要件
A/B テストでは、サンプル サイズは、信頼できるテストを実行するために必要なトラフィックの量を表します。
統計的に有効な調査を実施するには、代表的な大規模なユーザー サンプルが必要です。
理論的には、少数のユーザーで実験を行うことはできますが、あまり意味のある結果は得られません。
サンプルサイズが小さい場合でも、統計的に有意な結果が得られる可能性があります
たとえば、バージョン A とバージョン 2 が変換されたのを 10 人のユーザーだけが見た A/B テストを想像してみてください。 バージョン B を見たユーザーはわずか 8 人で、コンバージョンに至ったユーザーは 6 人でした。
このグラフが示すように、結果は統計的に有意です。
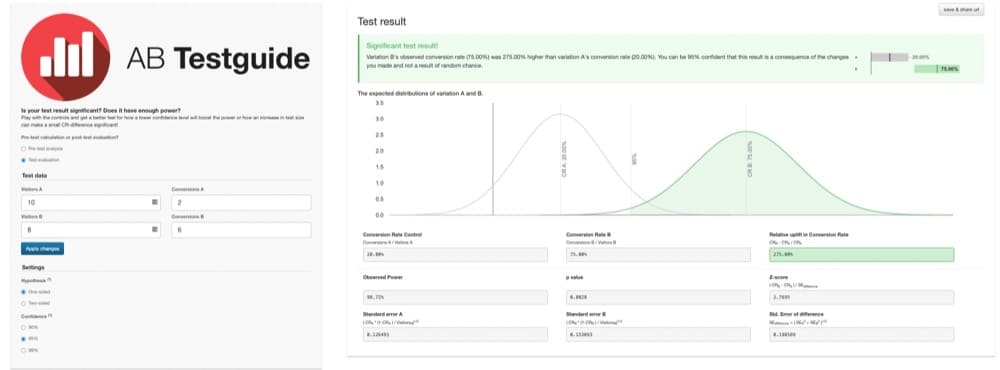
バージョン B は 275% 優れているようです。 しかし、これらの調査結果はあまり信頼できません。 サンプル サイズが小さすぎて、意味のある結果が得られません。
研究は力不足です。 ユーザーの大規模な代表的なサンプルは含まれていません。
テストの検出力が低いため、結果にエラーが発生しやすくなります。 そして、結果が偶然に生じたものなのか、それとも 1 つのバージョンが本当に優れているのかは明らかではありません。
この小さなサンプルでは、間違った結論を導き出しがちです。
適切に電源が入ったテスト
この落とし穴を克服するために、A/B テストは、代表的な大規模なユーザー サンプルを使用して適切に強化する必要があります。
どのくらいの大きさで十分ですか?
この質問は、簡単なサンプルサイズの計算を行うことで答えることができます。
サンプル サイズ要件を最も簡単に計算するには、サンプル サイズ計算ツールを使用することをお勧めします。 それらはたくさんあります。
私のお気に入りは Evan Miller のもので、柔軟で徹底しています。 さらに、使い方を理解できれば、ほぼすべての計算機を理解できます。
Evan Miller の電卓は次のようになります。
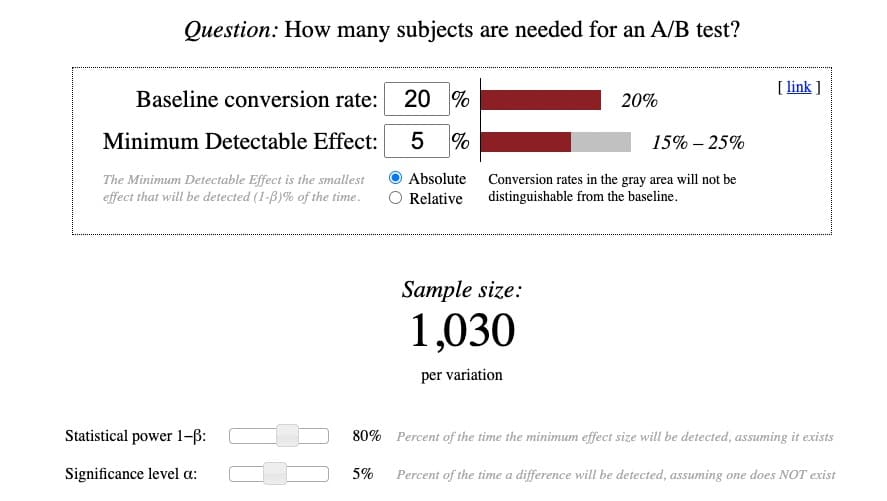
計算自体はかなり単純ですが、その背後にある用語を理解するのは簡単ではありません。 だから私は複合体を明確にしようとしました:
ベースライン コンバージョン率
ベースライン コンバージョン率は、コントロールまたは元のバージョンの既存のコンバージョン率です。 A/B テストを設定するときは、通常、「バージョン A」というラベルが付けられます。
このコンバージョン率は、分析プラットフォーム内で見つけることができるはずです。
A/B テストを実行したことがない場合、またはベースラインのコンバージョン率がわからない場合は、知識に基づいて最善の推測を行ってください。
ほとんどのサイト、業種、デバイス タイプでの平均コンバージョン率は 2 ~ 5% です。 そのため、ベースラインのコンバージョン率が本当によくわからない場合は、注意を怠って 2% のベースラインから始めてください。
ベースライン コンバージョン率が低いほど、必要なサンプル サイズが大きくなります。 およびその逆。
最小検出効果 (MDE)
最小検出効果 (MDE) は複雑な概念のように聞こえます。 しかし、この用語を 3 つの部分に分けると、はるかに理解しやすくなります。
- 最小= 最小
- 検出可能= 実験を実行して検出または発見しようとしている
- 効果= コントロールと処理の間の変換差
したがって、検出可能な効果の最小値は、テストを実行して検出したい最小のコンバージョン リフトです。
一部のデータ純粋主義者は、この定義が実際に関心の最小効果 (MEI) を説明していると主張します。 呼び方はどうであれ、目標は、テストを実行することで得られると予想されるコンバージョン リフトがどれくらい大きくなるかを予測することです。
この演習は非常に推測のように感じるかもしれませんが、このようなサンプル サイズ計算ツールや Convert の A/B テスト統計計算ツールを使用して、予想される MDE を計算できます。
非常に一般的な経験則として、2 ~ 5% の MDE が妥当と考えられます。 真に適切にパワーアップされたテストを実行する場合、これよりはるかに高い値は通常非現実的です。
MDE が小さいほど、必要なサンプル サイズが大きくなります。 およびその逆。
MDE は、絶対量または相対量として表すことができます。
絶対の
絶対 MDE は、コントロールとバリアントのコンバージョン率の生の数値の差です。
たとえば、ベースライン コンバージョン率が 2.77% で、バリアントが +3% の絶対 MDE を達成すると予想している場合、絶対差は 5.77% です。
相対的
対照的に、相対効果はバリアント間のパーセンテージ差を表します。
たとえば、ベースライン コンバージョン率が 2.77% で、バリアントが +3% の相対 MDE を達成すると予想している場合、相対差は 2.89% です。
一般に、ほとんどの実験者は相対的な上昇率を使用するため、通常はこの方法で結果を表すのが最適です。
統計的検出力 1−β
検出力とは、効果が実際に存在すると仮定した場合の、効果または変換差を見つける確率を指します。
テストの目的は、違いが存在する場合、それをエラーなしで有意義に検出するのに十分な能力があることを確認することです。 したがって、より高い電力は常に優れています。 ただし、トレードオフは、より大きなサンプル サイズが必要になることです。
0.80 の検出力は、標準的なベスト プラクティスと見なされます。 したがって、この電卓のデフォルトの範囲のままにしておくことができます。
この量は、80% の確率で、効果がある場合にエラーなく正確に検出できることを意味します。 そのため、効果を適切に検出できない可能性は 20% しかありません。 取る価値のあるリスク。
有意水準α
非常に単純な定義として、有意水準アルファは偽陽性率、または実際には存在しないコンバージョンの差が検出される時間の割合です。
A/B テストのベスト プラクティスとして、有意水準は 5% 以下にする必要があります。 したがって、この電卓のデフォルトのままにしておくことができます。
5% の有意水準 α は、実際には違いが存在しない場合でも、コントロールとバリアントの間に違いが見つかる可能性が 5% あることを意味します。
繰り返しますが、取る価値のあるリスクです。
サンプルサイズ要件の評価
これらの数値を計算機に入力すると、標準の 2 週間から 6 週間のテスト期間で適切にパワーアップされたテストを実行するのに十分なトラフィックがサイトにあることを確認できます。
検証するには、好みの分析プラットフォームにアクセスして、テストするサイトまたはページの一定期間の平均トラフィック レートの履歴を調べます。
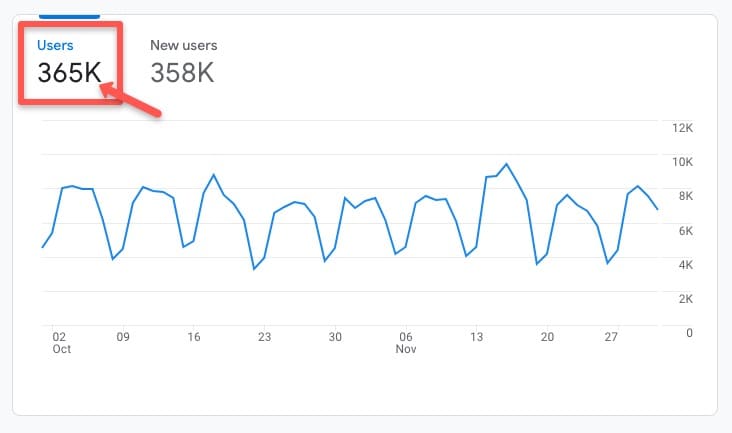
たとえば、この Google アナリティクス 4 (GA4) アカウントで、 [ライフ サイクル] > [獲得] > [獲得の概要] タブに移動すると、2022 年 10 月から 11 月までの最近の履歴期間に 365,000 人のユーザーがいたことがわかります。
既存のベースライン コンバージョン率 3.5%、相対 MDE 5%、標準検出力 80%、標準有意水準 5% に基づくと、計算機は、適切に実行するためにバリアントあたり 174,369 人の訪問者のサンプル サイズが必要であることを示しています。パワード A/B テスト:
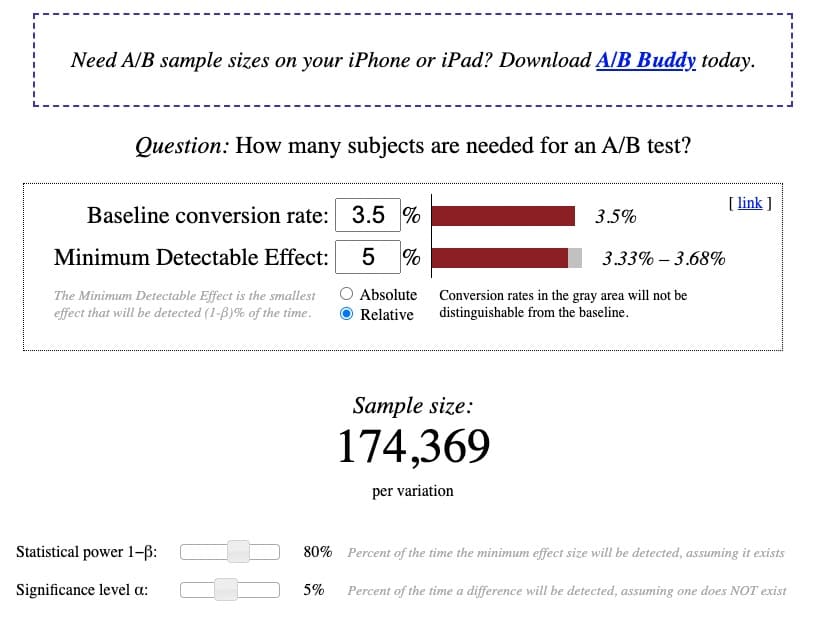
今後数か月間、トラフィックの傾向が比較的安定していると仮定すると、合理的なテスト期間内に、サイトが約 365,000 ユーザーまたは (365,000/2 バリアント) バリアントあたり 182,000 ビジターを達成すると予想するのが合理的です。
サンプル サイズの要件は達成可能であり、先に進んでテストを実行するための青信号が与えられます。
重要な注意点として、このサンプル サイズ要件の検証作業は、適切に強化されたテストを実行するのに十分なトラフィックがあるかどうかを確認できるように、調査を実行する前に常に実行する必要があります。
さらに、テストを実行するときは、事前に計算されたサンプル サイズの要件に到達する前にテストを停止しないでください。結果がすぐに重要になる場合でも.
サンプルサイズの要件を満たす前に勝者または敗者を時期尚早に宣言することは、「ピーク」と呼ばれるものであり、結果が完全に洗い流される前に誤った呼び出しを行う可能性がある危険なテスト方法です。
十分なトラフィックがある場合、いくつのテストを実行できますか?
テストするサイトまたはページがサンプル サイズの要件を満たしていると仮定すると、いくつのテストを実行できますか?
答えは、やはり場合によるということです。
Microsoft の Bing の元実験担当副社長である Ronny Kohavi が共有したプレゼンテーションによると、Microsoft は通常、1 日に 300 以上の実験を行っています。

しかし、彼らにはそれを行うためのトラフィックがあります。
各実験には 10 万人以上のユーザーがいます。
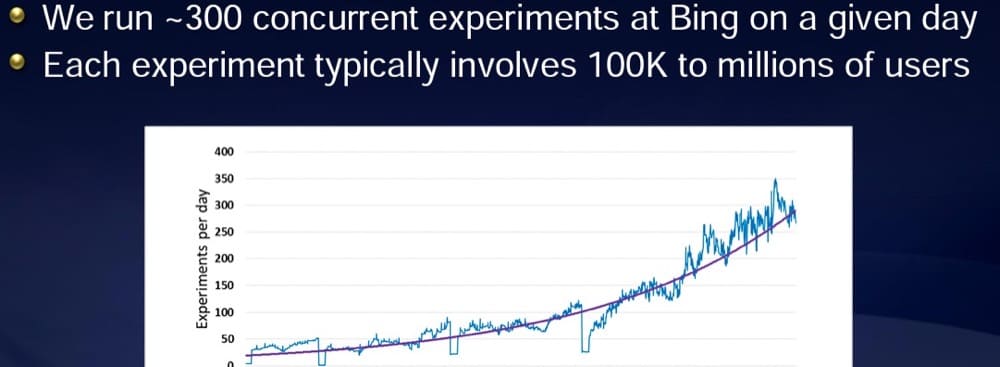
使用可能なトラフィックが多いほど、実行できるテストが多くなります。
どのテストでも、適切に強化された実験を実行するのに十分な大きさのサンプル サイズがあることを確認する必要があります。
トラフィックが制限されている小規模な組織の場合は、より品質の高いテストを少なくすることを検討してください。
結局のところ、重要なのは実行するテストの数ではなく、実験の結果です。
サンプルサイズの要件を満たせない場合のオプション
サンプル サイズの要件を満たせないことがわかった場合でも、心配する必要はありません。 実験はあなたのテーブルから外れていません。 利用可能な実験オプションがいくつかあります。
- トラフィック獲得に注力
大規模なサイトでも、特定のページでトラフィックが少ない場合があります。
サイト トラフィックまたは特定のページのトラフィックがサンプル サイズの要件を満たしていない場合は、より多くのトラフィックを獲得することに注力することを検討してください。
そのためには、積極的な検索エンジン最適化 (SEO) 戦略を実行して、検索エンジンで上位にランク付けし、より多くのクリックを獲得することができます。
また、Google 広告、LinkedIn 広告、さらにはバナー広告などのチャネルを通じて有料トラフィックを獲得することもできます.
これらの獲得活動は両方とも、Web トラフィックを促進するのに役立ち、ユーザーにとって何が最もコンバージョンにつながるかをテストする強力な機能を提供します。
ただし、サンプル サイズの要件を満たすために有料トラフィックを使用する場合は、訪問者の行動がトラフィック ソースによって異なる可能性があるため、テスト結果をトラフィック タイプ別にセグメント化することを検討してください。
- A/B テストが最適な実験方法であるかどうかを評価する
A/B テストは実験のゴールド スタンダードと見なされていますが、結果はその背後にあるデータと同じくらい優れています。
適切に強化されたテストを実行するのに十分なトラフィックがないことがわかった場合は、A/B テストが本当に最適な実験オプションであるかどうかを検討することをお勧めします。
必要なサンプル数がはるかに少なくても、非常に価値のある最適化の洞察を得ることができる研究ベースのアプローチは他にもあります。
ユーザー エクスペリエンス (UX) テスト、消費者調査、出口調査、または顧客インタビューは、A/B テストの代わりに試すことができる他のいくつかの実験方法です。
- 実現結果は方向データのみを提供する場合があります
ただし、A/B テストに熱心であれば、テストを実行できます。
結果は完全に正確ではない可能性があり、完全に信頼できる結果ではなく、可能性が高い結果を示す「方向性データ」のみが提供されることに注意してください。
結果が完全に正しいとは限らないため、コンバージョン効果を注意深く監視する必要があります。
とはいえ、正確な換算値よりも重要なことが多いのは、銀行口座の数字です。 それらが上昇している場合は、行っている最適化作業が機能していることがわかります。
テストの成熟度
サンプル サイズの要件に加えて、テストの頻度に影響を与えるもう 1 つの要因は、テスト組織の成熟度です。
テストの成熟度は、実験が組織文化の中でどのように確立されているか、および実験の実践がどのように高度であるかを説明するために使用される用語です。
Amazon、Google、Bing、Booking など、毎月数千のテストを実行している組織には、進歩的で成熟したテスト チームがあります。
それは偶然ではありません。
テストの頻度は、組織の成熟度レベルと密接に結びついている傾向があります。
実験が組織内に根付いている場合、経営陣はそれにコミットします。 同様に、組織全体の従業員は通常、実験をサポートして優先順位を付けることが奨励されており、テストのアイデアを提供するのに役立つ場合もあります。
これらの要因が一緒になると、適切なテスト プログラムを実行するのがはるかに簡単になります。
テストを強化したい場合は、まず組織の成熟度レベルを確認すると役立ちます。
次のような質問を評価することから始めます
- 経営幹部にとって実験はどれほど重要ですか?
- 実験を促進するためにどのようなリソースが提供されていますか?
- テストの最新情報を伝えるために利用できる通信チャネルは何ですか?
答えが「なし」またはそれに近い場合は、まずテスト文化の構築に取り組むことを検討してください。
組織がより進歩的な実験の文化を採用するにつれて、当然のことながら、テストの頻度を増やすことはより簡単になります。
実験の文化を作る方法に関する提案については、この記事やこの記事などのリソースを確認してください。
リソースの制約
すでにある程度の組織の賛同を得ていると仮定すると、次に取り組むべき問題はリソースの制約です。
時間、お金、および人間の力はすべて、テストの能力を制限する可能性がある制限です。 そして早速テスト。
リソースの制約を克服するには、テストの複雑さを評価することから始めると役立ちます。
単純なテストと複雑なテストのバランスを取る
実験者として、非常に単純なものから非常に複雑なものまで、さまざまなテストを実行することを選択できます。
簡単なテストには、コピーや色などの要素の最適化、画像の更新、ページ上の単一要素の移動が含まれる場合があります。
複雑なテストには、いくつかの要素の変更、ページ構造の変更、またはコンバージョン ファネルの更新が含まれる場合があります。 この種のテストでは、多くの場合、深いコーディング作業が必要になります。
数千回の A/B テストを実行した結果、約 3/5 の単純なテストと 3/5 の複雑なテストを常に同時に実行すると便利であることがわかりました。
より単純なテストは、迅速かつ簡単に勝利を収めることができます。
しかし、より大きな変更を伴うより大きなテストでは、より大きな効果が得られることがよくあります。 実際、いくつかの最適化調査によると、実行するテストが複雑であるほど、成功する可能性が高くなります。 そのため、頻繁に大規模なスイング テストを実行することを恐れないでください。
ただし、トレードオフは、テストの設計と構築により多くのリソースを費やすことになることです。 そして、勝てる保証はありません。
利用可能な人材に基づくテスト
あなたが単独の CRO ストラテジストであるか、小規模なチームで作業している場合、そのキャパシティは限られています。 単純か複雑かにかかわらず、月に 2 ~ 5 回のテストが必要になる場合があります。
対照的に、研究者、ストラテジスト、デザイナー、開発者、および QA スペシャリストからなる専任チームを擁する組織の場合、月に数十から数百のテストを実行する能力がある可能性があります。
実行する必要があるテストの数を決定するには、人材の可用性を評価します。
平均して、単純なテストのアイデア、ワイヤーフレーム、設計、開発、実装、QA、および結果の監視には 3 ~ 6 時間かかる場合があります。
一方、非常に複雑なテストでは、15 ~ 20 時間以上かかる場合があります。
1 か月に約 730 時間あるため、この貴重な時間に実行するテストとテストの数について十分に計算する必要があります。
テストのアイデアを計画して優先順位を付ける
最適なテスト構造を計画するのに役立つように、PIE、ICE、または PXL などのテストの優先順位付けフレームワークの使用を検討してください。
これらのフレームワークは、上位のテスト アイデアをランク付けし、実装の容易さを評価し、どのテストがコンバージョンを高める可能性が最も高いかを評価するための定量的な手法を提供します。
この評価を実施すると、優先順位を付けたテスト アイデアのリストは次のようになります。

上位のテスト アイデアをランク付けしたら、テスト ロードマップを作成して、テストのタイムラインと次のステップを視覚的に計画することもお勧めします。
ロードマップは次のようになります。
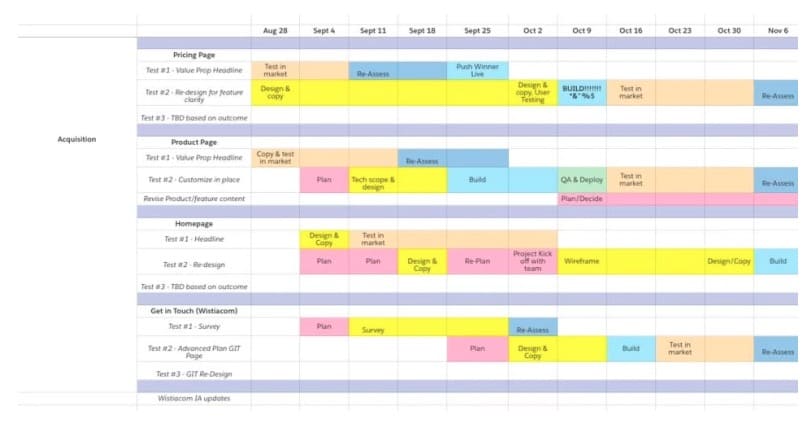
以下を含める必要があります。
- テストする予定のアイデアのページ別リスト。
- 各テスト段階 (設計、開発、QA など) にかかると予想される時間。
- 事前に計算されたサンプル サイズの要件に基づいて、各テストを実行する予定の期間。 このようなテスト期間計算機を使用して、テスト期間の要件を計算できます。
テストのアイデアを綿密に計画することで、テストの頻度とキャパシティをより正確に判断できるようになります。
テスト ロードマップを作成すると、実行できるテストの数が使用可能なリソースに基づいていることが明らかになる場合があります。
一度に複数のテストを実行する必要がありますか?
しかし、何かができるからといって、常にそうすべきだというわけではありません。
一度に複数のテストを実行する場合、最善のアプローチについては大きな議論があります。
Experiment Nation のリーダーである Rommil Santiago によるこのような記事は、論争の的となる質問を提起します: 複数の A/B テストを同時に実行してもよいのでしょうか?
一部の実験者は、絶対にそうではないと言うでしょう。
彼らは、一度に 1 ページずつ 1 つのテストだけを実行すべきだと主張するでしょう。 そうしないと、効果を適切に分離できません。
私がこのキャンプにいたのは、10 年近く前にそう教えられたからです。
一度に 1 つのページで 1 つの変更を加えた 1 つのテストのみを実行するように、厳密に教えられました。 私は何年もこの考え方で活動していましたが、より多くの結果をより早く求めた不安なクライアントを失望させました.
しかし、Facebook の元データ サイエンティストで、現在は Statsig の主任データ サイエンティストである Timothy Chan によるこの記事は、私の考えを完全に変えました。
チャン氏は論文の中で、相互作用効果は過大評価されていると主張しています。
実際、複数のテストを同時に実行することは問題にならないだけではありません。 それは本当にテストする唯一の方法です!
このスタンスは、ソーシャル メディアの巨人が同時に何百もの実験を成功裏に実行し、その多くが同じページ上で実行された Facebook での彼の時代のデータによって裏付けられています。
Ronny Kohavi や Hazjier Pourkhalkhali などのデータの専門家は同意します。 実際、成功をテストする最善の方法は、継続的に複数のテストを複数回実行することです。
そのため、テストの頻度を検討するときは、重複するテストの相互作用の影響について心配する必要はありません。 自由にテストします。
概要
A/B テストでは、実行する最適な数の A/B テストはありません。
理想的な数は、独自の状況に適したものです。
この数は、サイトのサンプル サイズの制約、アイデアのテストの複雑さ、利用可能なサポートとリソースなど、いくつかの要因に基づいています。
最終的に重要なのは、実行するテストの数ではなく、テストの品質と得られる結果です。 大きなリフトをもたらす単一のテストは、針を動かさないいくつかの決定的なテストよりもはるかに価値があります.
テストは、量よりも質が重要です。
A/B テスト プログラムを最大限に活用する方法について詳しくは、Convert の記事をご覧ください。

