
Googleコアアップデート:YMYLサイトの効果、問題、解決策
公開: 2019-12-04このケーススタディでは、トルコで最大の金融およびデジタル資産の1つであるHangikredi.comを見ていきます。 技術的なSEOの小見出しといくつかのグラフィックが表示されます。
このケーススタディは2つの記事で紹介されています。 この記事では、ウェブサイトに大きな悪影響を及ぼした3月12日のGoogle Core Updateと、それを打ち消すために行ったことについて説明します。 13の技術的な問題と解決策、および全体的な問題について見ていきます。
2回目の記事を読んで、このアップデートからの学習をどのように適用して、すべてのGoogleコアアップデートの勝者になるかを確認してください。
問題と解決策:3月12日のGoogleコアアップデートの影響の修正
3月12日のコアアルゴリズムアップデートまで、分析データに基づいて、すべてがWebサイトへのスムーズな航海でした。 ある日、コアアルゴリズムの更新に関するニュースが発表された後、ランキングが大幅に低下し、オフィスに大きな不満が生じました。 14日後に新しいSEOプロジェクトとプロセスを開始するために彼らが私を雇ったときだけ私が到着したので、私はその日を個人的に見ませんでした。
[ケーススタディ]ログファイル分析によるランキング、オーガニック訪問、売上の改善
 ケーススタディを読む
ケーススタディを読む3月12日のコアアルゴリズムアップデート後の会社のWebサイトの損傷レポートは次のとおりです。
- 36%のオーガニックセッションロス
- 65%クリックドロップ
- 30%のCTR損失
- 33%のオーガニックユーザー損失
- 1日あたり100000インプレッションが失われました。
- 9.72%のインプレッション損失
- 8000キーワードが失われました

さて、ケーススタディの記事の冒頭で述べたように、1つの質問をする必要があります。 「次のコアアルゴリズムの更新はいつ行われますか?」とは言えませんでした。 それはすでに起こっているからです。 質問は1つだけ残っていました。
「Googleは私と競合他社の間でどのような異なる基準を検討しましたか?」
上のグラフと被害レポートからわかるように、メインのトラフィックとキーワードが失われました。
1.問題:内部リンク
内部リンク数、アンカーテキスト、リンクフローを最初に確認したとき、競合他社が私の前にいることに気づきました。
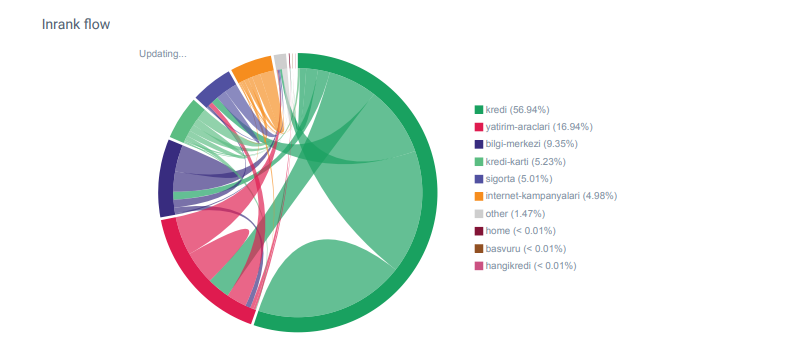
OnCrawlからのHangikredi.comのカテゴリのLinkflowレポート
私の主な競合他社には、数千のアンカーテキストを含む34万を超える内部リンクがあります。 最近、私たちのWebサイトには、貴重なアンカーテキストのない70000の内部リンクしかありませんでした。 さらに、内部リンクの欠如は、Webサイトのクロール予算と生産性に影響を及ぼしました。 トラフィックの80%はわずか20の製品ページで収集されましたが、サイトの90%は、ユーザーにとって役立つ情報が記載されたガイドページで構成されていました。 また、財務クエリのキーワードと関連性スコアのほとんどは、これらのページから取得されます。 また、孤立したページが無数に多すぎました。
内部リンク構造が欠落しているため、Kibanaでログ分析を行ったときに、最もクロールされたページが最もトラフィックの少ないページであることに気付きました。 また、これを内部リンクネットワークとペアリングしたところ、トラフィックが最も少ない企業ページ(プライバシー、Cookie、セキュリティ、会社概要ページ)の内部リンクの数が最大であることがわかりました。
次のセクションで説明するように、これにより、GooglebotはサイトをクロールしたときにPagerankから内部リンク要素を削除し、内部リンクが意図したとおりに構築されていないことに気付きました。
2.問題:サイトアーキテクチャ、内部ページランク、トラフィックおよびクロール効率
Googleの声明によると、内部リンクとアンカーテキストは、Googlebotがウェブページの重要性とコンテキストを理解するのに役立ちます。 内部PagerankまたはInrankは、複数の要因に基づいて計算されます。 ビル・スラフスキーによれば、内部リンクまたは外部リンクはすべて同じではありません。 ページランクフローのリンクの値は、その位置、種類、スタイル、およびフォントの太さによって異なります。

Googlebotがウェブサイトにとって重要なページを理解している場合、Googlebotはそれらをより多くクロールし、より速くインデックスに登録します。 内部リンクと正しいサイトツリー設計は、このための重要な要素です。 他の専門家も、この相関関係について何年にもわたってコメントしています。
「ほとんどのリンクは、アンカーテキストを介して少し追加のコンテキストを提供します。 少なくとも彼らはそうすべきですよね?」
–John Mueller、Google 2017「サイトで重要だと思われるページがある場合は、サイトの奥深くに15のリンクを埋めないでください。ディレクトリの長さについては話していません。実際には、15のリンクをクリックしてそのページを見つける必要があります。重要なページや利益率の高いページ、または実際にコンバージョンにつながるページがある場合は、ルートページからそのページへのリンクをエスカレートしてください。これは非常に理にかなっているようなものです。」
–マットカッツ、Google 2011「あるページが「連絡先」または「約」という単語で別のページにリンクしていて、リンク先のページに住所が含まれている場合、その住所の場所は、そのリンクを行っているページに関連していると見なされる可能性があります。」
変更された可能性のある12のGoogleリンク分析方法– Bill Slawski
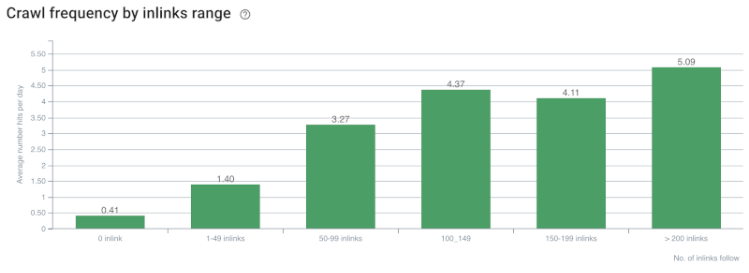
クロールレート/デマンドと内部リンクカウントの相関。 出典:OnCrawl。
これまでのところ、これらの推論を行うことができます。
- Googleはクリックの深さを気にします。 Webページがホームページに近い場合は、それがより重要になるはずです。 これは、2018年7月1日に英語のGoogleウェブマスターハングアウトでJohnMuellerによっても確認されました。
- Webページにそれを指す内部リンクがたくさんある場合、それは重要です。
- アンカーテキストは、Webページにコンテキストの力を与えることができます。
- 内部リンクは、位置、タイプ、フォントの太さ、またはスタイルに基づいて、さまざまなページランク量を送信できます。
- 内部ページ権限に関する明確なメッセージを検索エンジンのクローラーに提供するUXに適したサイトツリーは、Inrankの配布とクロールの効率にとってより良い選択です。
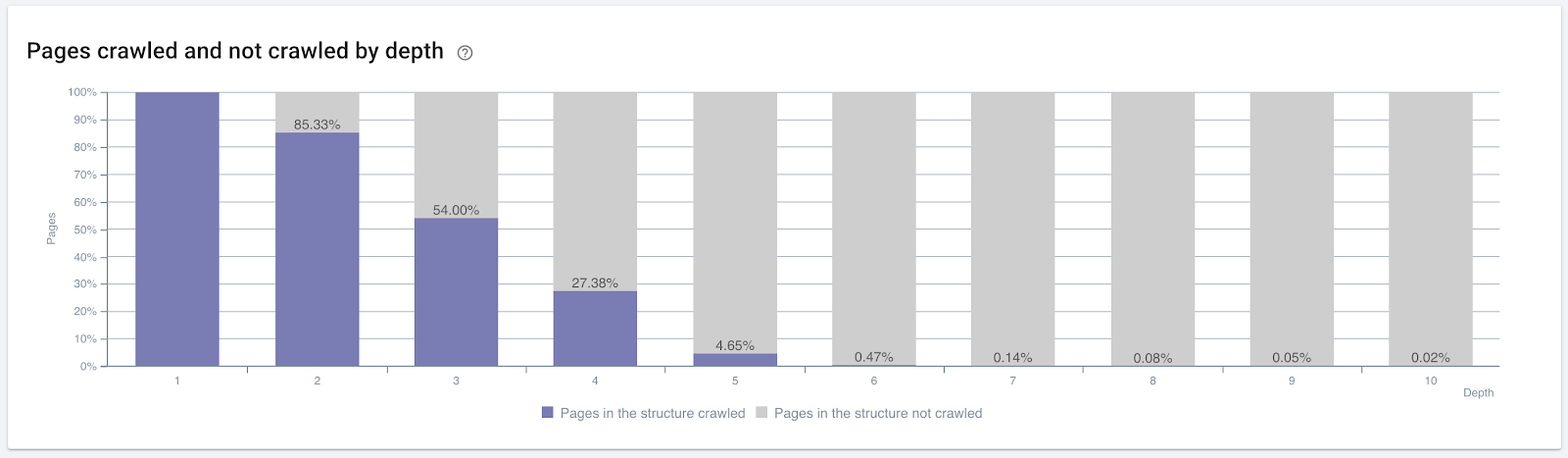
クリックの深さでクロールされたページの割合。 出典:OnCrawl。
しかし、これらは内部リンクの性質とクロール効率への影響を理解するのに十分ではありません。
オンクロールSEOクローラー
 もっと詳しく知る
もっと詳しく知る最も内部的にリンクされたページがトラフィックを作成したりクリックされたりしない場合は、サイトツリーと内部リンク構造がユーザーの意図に従って構築されていないことを示すシグナルが表示されます。 そして、Googleは常に、ユーザーインテントまたは検索エンティティを使用して最も関連性の高いページを見つけようとします。 この主題をより明確にするビル・スラフスキーからの別の引用があります:
「リソースが、それらのリンクを使用して受信したトラフィックに対して不均衡な多数のリソースによってリンクされている場合、そのリソースはランキングプロセスで降格される可能性があります。」
グラウンドホッグの更新はGoogleで行われただけですか? —ビル・スラフスキー「選択品質スコアは、滞留時間が長い(たとえば、しきい値期間より長い)選択の場合、滞留時間が短い選択の選択品質スコアよりも高くなる可能性があります。」
グラウンドホッグの更新はGoogleで行われただけですか? —ビル・スラフスキー
したがって、さらに2つの要因があります。
- リンク先ページの滞留時間。
- リンクによって生成されたユーザートラフィック。
内部リンク数とスタイル/位置だけが要因ではありません。 これらのリンクをたどるユーザーの数とその行動指標も重要です。 さらに、クリック/アクセスされたリンクやページは、クリックまたはアクセスされていないリンクやページよりもはるかに多くGoogleによってクロールされることがわかっています。
「私たちは、サイトのセクションの品質を理解するために、それらのセクションを理解する方向にますます進んでいます。」
John Mueller、2017年5月2日、英語のGoogleウェブマスターハングアウト。
これらすべての要因に照らして、2つの異なる異なるPagerankSimulatorの結果を共有します。
これらのページランクの計算は、ホームページを含むすべてのページが等しいことを前提として行われます。 実際の違いは、リンク階層によって決まります。
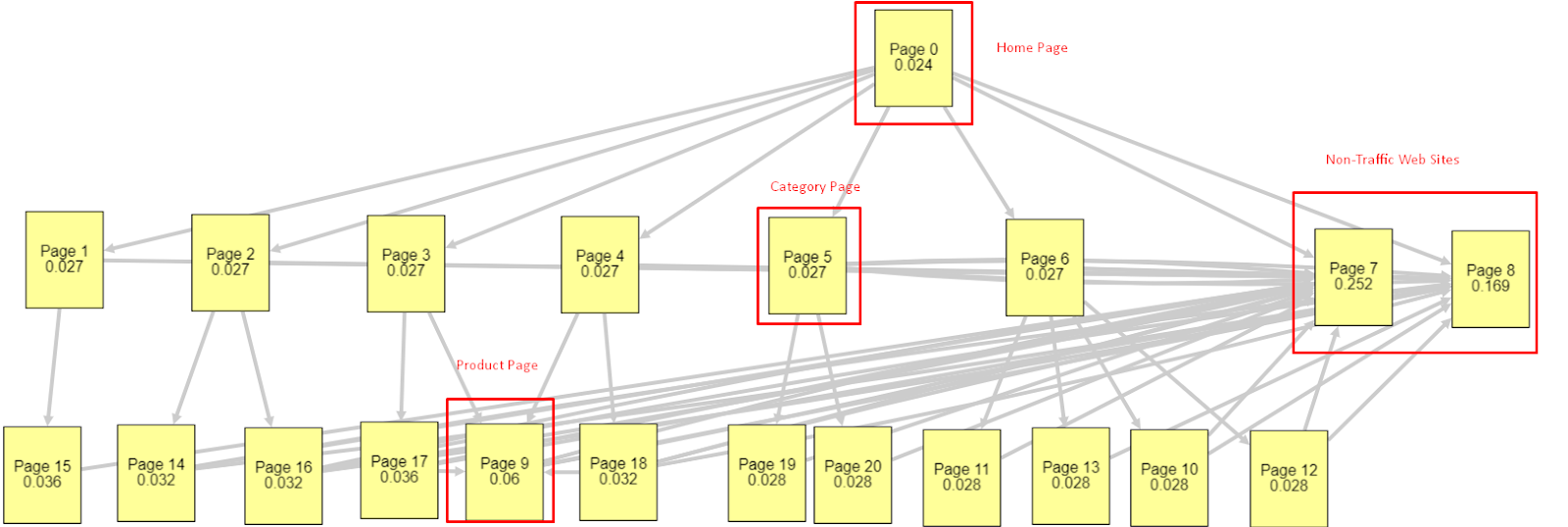
ここに示す例は、3月12日より前の内部リンク構造に近いものです。 ホームページPR:0.024、カテゴリページPR:0.027、製品ページPR:0.06、非トラフィックWebページPR:0.252。
お気づきかもしれませんが、Googlebotは、この内部リンク構造を信頼して、内部ページランクと内部ページの重要度を計算することはできません。 トラフィックのないページと製品のないページには、ホームページの12倍の権限があります。 製品ページ以上のものがあります。

この例は、6月5日のコアアルゴリズムアップデート前の状況に近いものです。ホームページPR:0.033、カテゴリページ:0,037、製品ページ:0,148、および非トラフィックページのPR:0,037。
お気づきかもしれませんが、内部リンクの構造はまだ正しくありませんが、少なくとも非トラフィックWebページには、カテゴリページや製品ページよりも多くのPRがありません。
Googleがユーザーフローとリクエストと意図に従って内部リンクとサイト構造をPagerankの範囲から外したことのさらなる証拠は何ですか? もちろん、Googlebotの動作とInlink Pagerankおよびランキングの相関関係:
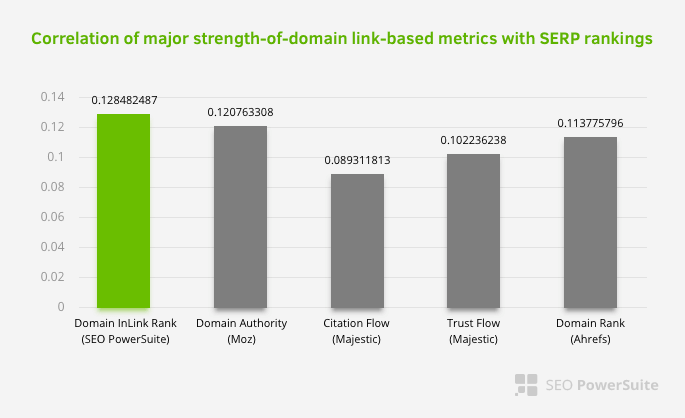
これは、特に内部リンクネットワークが他の要因よりも重要であることを意味するものではありません。 単一のポイントに焦点を当てたSEOの視点は決して成功することはできません。 サードパーティのツールを比較すると、内部のPagerank値が他の基準に関連して進んでいることがわかります。
Aleh BarysevichによるInlinkランクとランク相関の調査によると、内部リンクが最も多いページは、Webサイトの他のページよりもランクが高くなっています。 2019年3月4〜6日に実施された調査によると、33,500個のキーワードの内部Pagerankメトリックに従って、1,000,000ページが分析されました。 SEO PowerSuiteが実施したこの調査の結果は、Moz、Majestic、Ahrefsのさまざまな指標と比較され、より正確な結果が得られました。
3月12日のコアアルゴリズムアップデート前の当サイトの内部リンク番号の一部を次に示します。
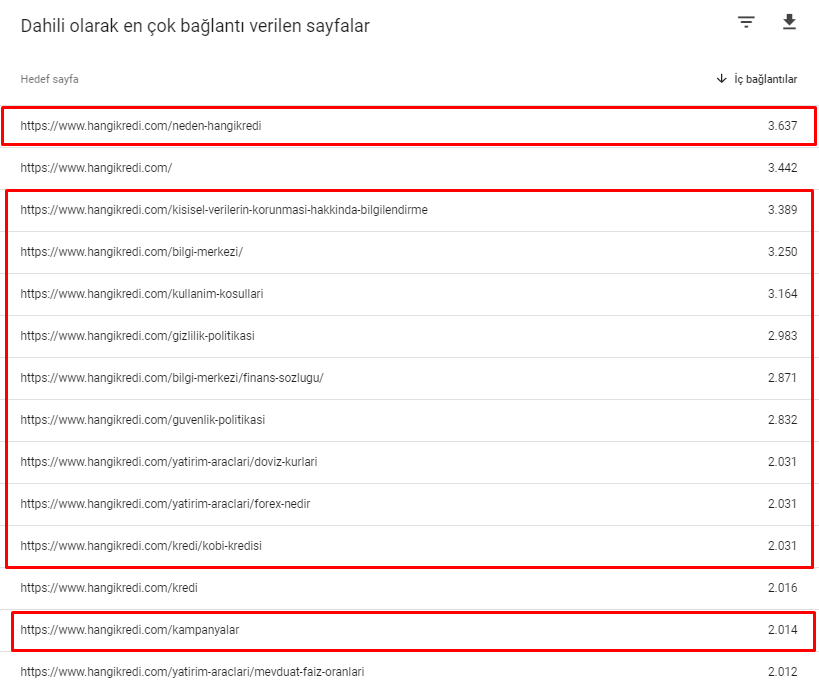
ご覧のとおり、内部接続スキームはユーザーの意図とフローを反映していませんでした。 トラフィックが最も少ないページ(マイナーな製品ページ)またはトラフィックを受け取らないページ(赤)は、最初のクリックの深さに直接あり、ホームページからPRを受け取ります。 また、ホームページよりもさらに多くの内部リンクを持っているものもありました。
これらすべてに照らして、この主題に関して示すことができる最後の2つのポイントのみがあります。
- 最も内部的にリンクされたページのクロール速度/需要
- リンクスカルプティングとページランク
2月1日から3月31日までの間に、Googlebotが最も頻繁にクロールしたページは次のとおりです。
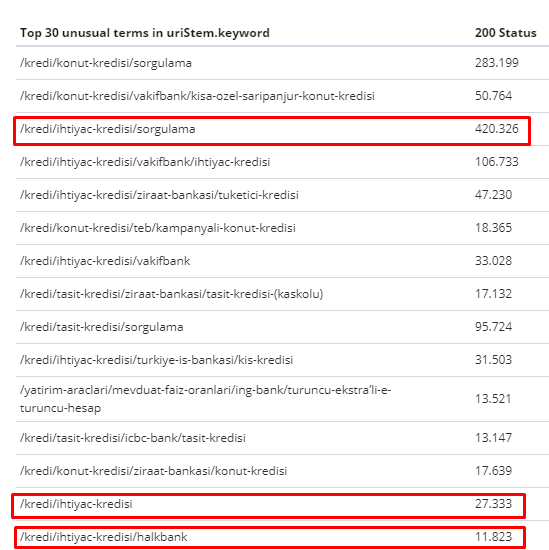
お気づきかもしれませんが、クロールされたページと内部リンクが最も多いページは完全に異なります。 内部リンクが最も多いページは、ユーザーの意図にとって便利ではありませんでした。 彼らは有機的なキーワードや直接的なSEOの価値を持っていません。 ((
赤いボックス内のURLは、最も訪問された重要な製品ページのカテゴリです。 このリストの他のページは、2番目または3番目に訪問された重要なカテゴリです。)
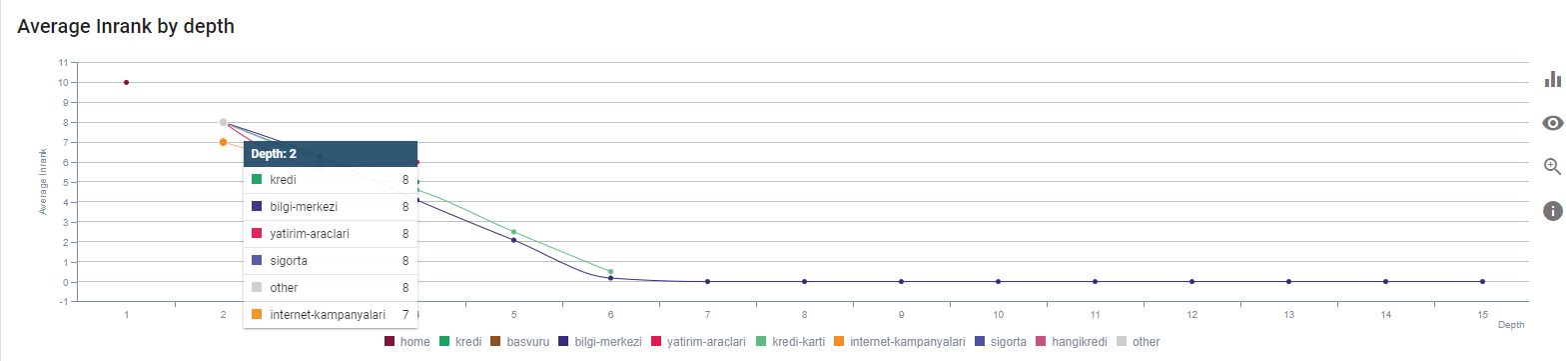
ページの深さによる現在のランク付け。 出典:Oncrawl。
リンクスカルプティングとは何ですか?内部的にフォローされていないリンクをどうするか?
ほとんどのSEOが信じていることに反して、「nofollow」タグでマークされたリンクは依然として内部のPagerank値を渡します。 私にとって、これらすべての年月を経て、2009年6月15日からの彼のPagerankSculptingArticleでMattCuttsよりもこのSEO要素をよりよく語った人は誰もいません。
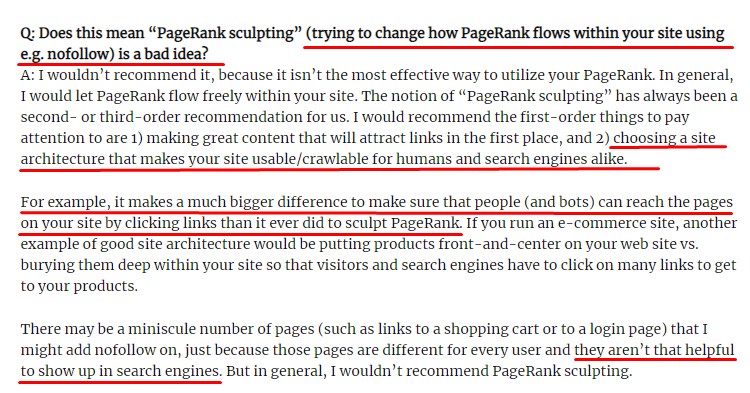
PagerankSculptingの本当の目的を示すLinkSculptingの便利な部分。
「ウェブサイト内のPageRankのスカルプトには、nofollowを使用しないことをお勧めします。おそらく、思ったとおりに機能しないからです。」
–John Mueller、Google 2017
Googleとユーザーの観点から価値のないウェブページがある場合は、「nofollow」のタグを付けないでください。 Pagerankの流れは止まりません。 robots.txtファイルからそれらを禁止する必要があります。 このように、Googlebotはそれらをクロールしませんが、内部ページランクをそれらに渡しません。 しかし、マット・カッツが10年前に言ったように、これは本当に価値のないページにのみ使用する必要があります。 アフィリエイトマーケティングの自動リダイレクトを行うページや、ほとんどコンテンツがないページは、ここでの便利な例です。
解決策:より優れた、より自然な内部リンク構造
競合他社には不利な点がありました。 彼らのウェブサイトには、より多くのアンカーテキストとより多くの内部リンクがありましたが、それらの構造は自然で有用ではありませんでした。 サイトの各ページで同じアンカーテキストが同じ文で使用されていました。 各ページのエントリ段落は、この反復的なコンテンツで覆われていました。 すべてのユーザーと検索エンジンは、これがユーザーの利益を考慮した自然な構造ではないことを簡単に認識できます。
そこで、内部リンク構造を修正するために3つのことを行うことにしました。
- サイト情報アーキテクチャまたはサイトツリーは、コンテンツ内に配置されたリンクとは異なるパスをたどる必要があります。 ユーザーの心とキーワードニューラルネットワークをより厳密に追跡する必要があります。
- 各コンテンツでは、対象のページのメインキーワードと一緒にサイドキーワードを使用する必要があります。
- アンカーテキストは自然で、コンテンツに適合している必要があり、ユーザーの認識に注意して、各ページの異なるポイントで使用する必要があります
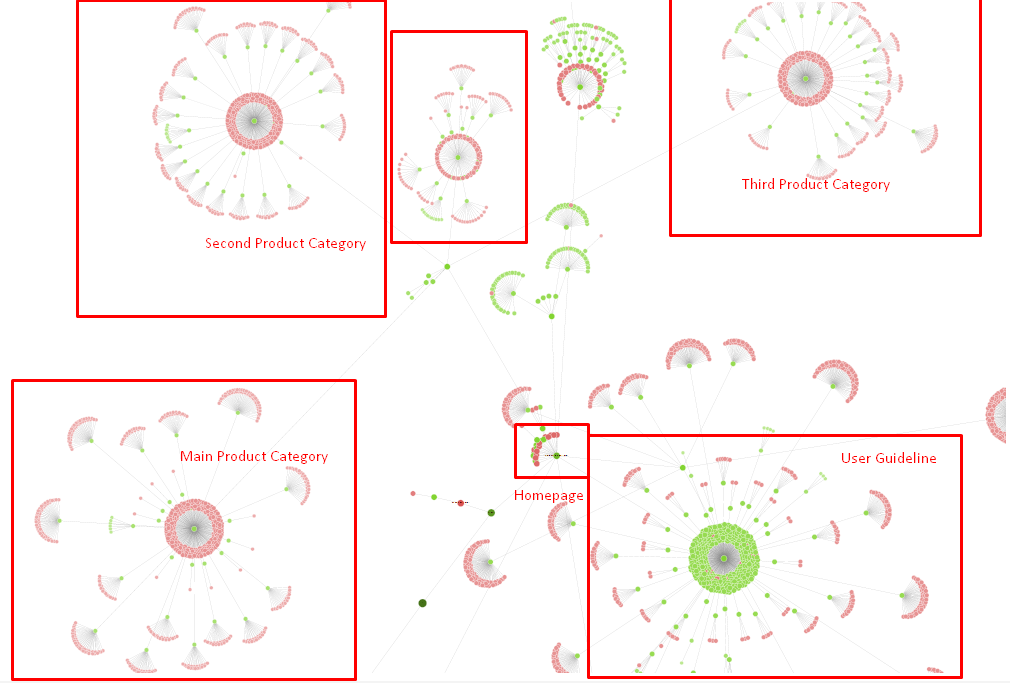
今のところ、サイトツリーとリンク構造の一部です。
上の図では、現在の内部リンクリンクとサイトツリーを確認できます。
この問題を修正するために行ったことのいくつかを以下に示します。
- 便利なアンカーを使用して、さらに30000の内部リンクを作成しました。
- ユーザーにはナチュラルスポットとキーワードを使用しました。
- 内部リンクには、繰り返しの文やパターンは使用しませんでした。
- ウェブページのInrankについてGooglebotに適切なシグナルを送りました。
- Log Analysisを使用して、正しい内部リンク構造がクロール効率に与える影響を調べたところ、メインの製品ページが以前の統計と比較してクロールされていることがわかりました。
- 孤立したページに対して50000を超える内部リンクを作成しました。
- サブページに電力を供給するためにホームページの内部リンクを使用し、ホームページ上にさらに多くの内部リンクソースを作成しました。
- Pagerank Powerを保護するために、いくつかの不要な外部リンクにもnofollowタグを使用しました。 (これは内部リンクに関するものではありませんが、同じ目的を果たします。)
3.問題:コンテンツ構造
Googleによると、YMYL Webサイトの場合、信頼性と権限は他のタイプのサイトよりもはるかに重要です。

昔は、キーワードはただのキーワードでした。 しかし今では、それらは明確に定義され、特異で、意味があり、区別できるエンティティでもあります。 私たちのコンテンツには、4つの主な問題がありました。
- 私たちのコンテンツは短かった。 (通常、コンテンツの長さは重要ではありません。ただし、この場合、トピックに関する十分な情報が含まれていませんでした。)
- 私たちの作家の名前は、実体として特異で、意味があり、区別できるものではありませんでした。
- 私たちのコンテンツは目に優しいものではありませんでした。 言い換えれば、それは「ファーストフード」のコンテンツではありませんでした。 小見出しのない内容でした。
- マーケティング用語を使用しました。 1段落のスペースで、ユーザーのブランド名とその広告を識別できます。
- 情報ページから製品ページにユーザーを誘導するボタンがたくさんありました。
- 製品ページの内容には、十分な情報や包括的なガイドラインがありませんでした。
- デザインはユーザーフレンドリーではありませんでした。 フォントと背景は基本的に同じ色を使用していました。 (これは、インフラストラクチャの問題のため、ほとんどの場合まだ当てはまります。)
- 画像や動画はコンテンツの一部として見られていませんでした。
- 特定のキーワードのユーザーインテントと検索インテントは、これまで重要であるとは見なされていませんでした。
- 同じトピックについて、重複した、不要な、反復的なコンテンツがたくさんありました。
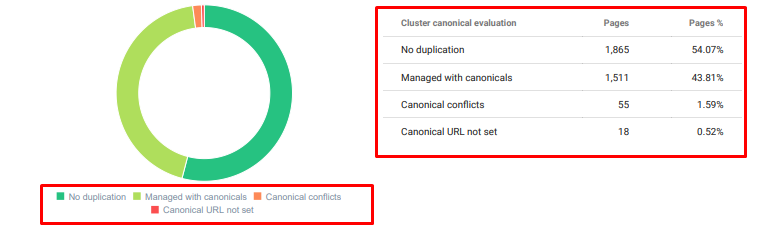
今日から重複コンテンツ監査をオンクロールします。
解決策:ユーザー信頼のためのより良いコンテンツ構造
サイト全体の問題をチェックする場合、アシスタントとしてサイト全体の監査プログラムを使用することは、SEOプロジェクトに費やされた時間を整理するためのより良い方法です。 内部リンクセクションと同様に、OncrawlSiteAuditを他のツールやXpath検査と一緒に使用しました。
まず、コンテンツセクションのすべての問題を修正するには時間がかかりすぎます。 崩壊する危機の時代には、時間は贅沢でした。 そこで、次のようなクイックウィンの問題を修正することにしました。
- 重複した、不要で反復的なコンテンツの削除
- 包括的な情報が不足しているショートコンテンツとシンコンテンツの統合
- 小見出しと目で追跡可能な構造が欠けていたコンテンツを再公開する
- コンテンツの集中的なマーケティングトーンの修正
- コンテンツから多くの召喚状ボタンを削除する
- 画像やビデオとのより良いビジュアルコミュニケーション
- コンテンツとターゲットキーワードをユーザーと検索の意図と互換性のあるものにする
- 信頼のためのコンテンツでの金融および教育機関の使用と表示
- 承認の社会的証明を作成するためのソーシャルコミュニティの使用
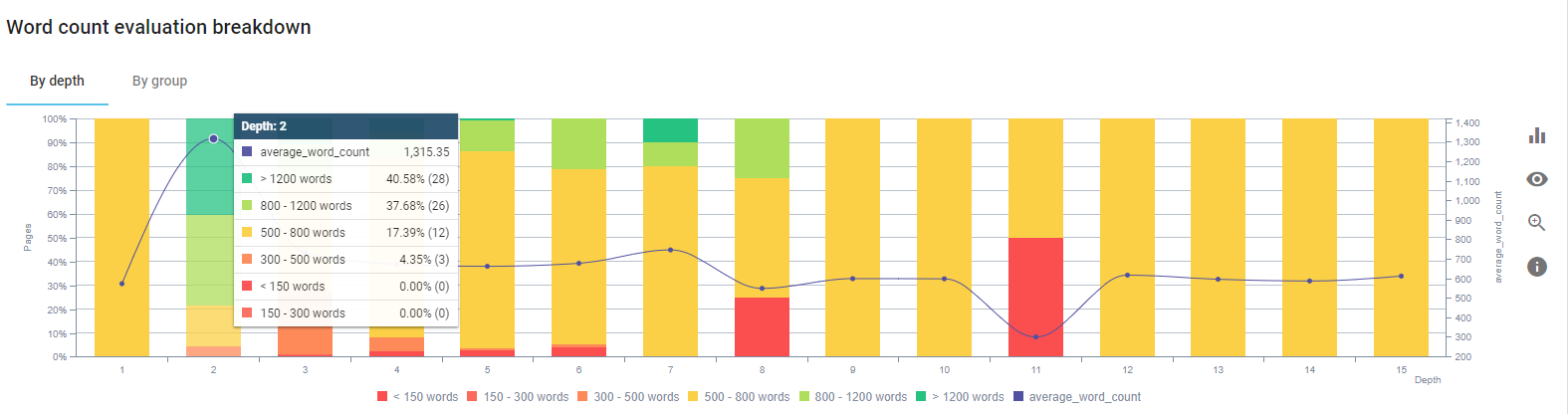

製品ページとそれに最も近いガイドページの内容を修正することに集中しました。
このプロセスの開始時に、当社の製品およびトランザクションのランディング/ガイドラインページのほとんどは、包括的な情報なしで500語未満でした。
25日間で、実行したアクションは次のとおりです。
- 重複した、不要で反復的なコンテンツを含む228ページを削除しました。 (Ccontentのバックリンクプロファイルは、削除プロセスの前にチェックされました。また、Googlebotとの通信を改善するために301または410のステータスコードを使用しました。)
- 包括的な情報が不足している123ページ以上を組み合わせた。
- コンテンツの重要性とユーザーの要求に応じて小見出しを使用しました。
- マーケティングスタイルの言語でブランド名とCTAボタンを削除しました。
- メイントピックを強調するために画像にテキストを含めます。
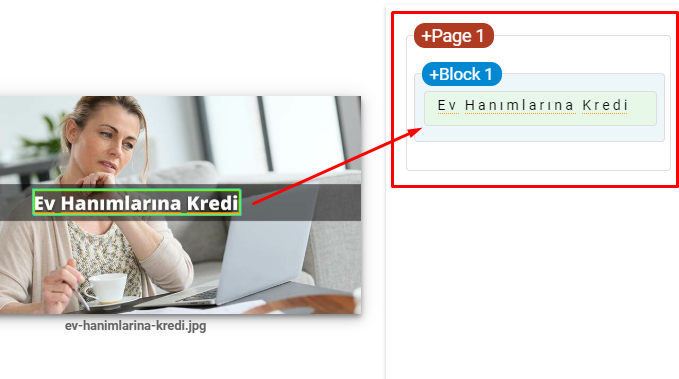
これは、GoogleのVisionAIのスクリーンショットです。 Googleは画像内のテキストを読み取り、エンティティ内の感情やアイデンティティを検出できます。
- より多くのユーザーを引き付けるために私たちのソーシャルネットワークをアクティブにしました。
- 競合他社と私たちの間のコンテンツのギャップを調査し、80を超える新しいコンテンツを作成しました。
- Google Analytics、Search Console、およびGoogle Data Studioを使用して、バウンス率が高くトラフィックが少ないパフォーマンスの低いページを特定しました。
- 注目のスニペットとそのキーワードおよびコンテンツ構造について調査しました。 関連するコンテンツに同じ見出しとコンテンツ構造を追加しました。これにより、注目のスニペットが増えました。
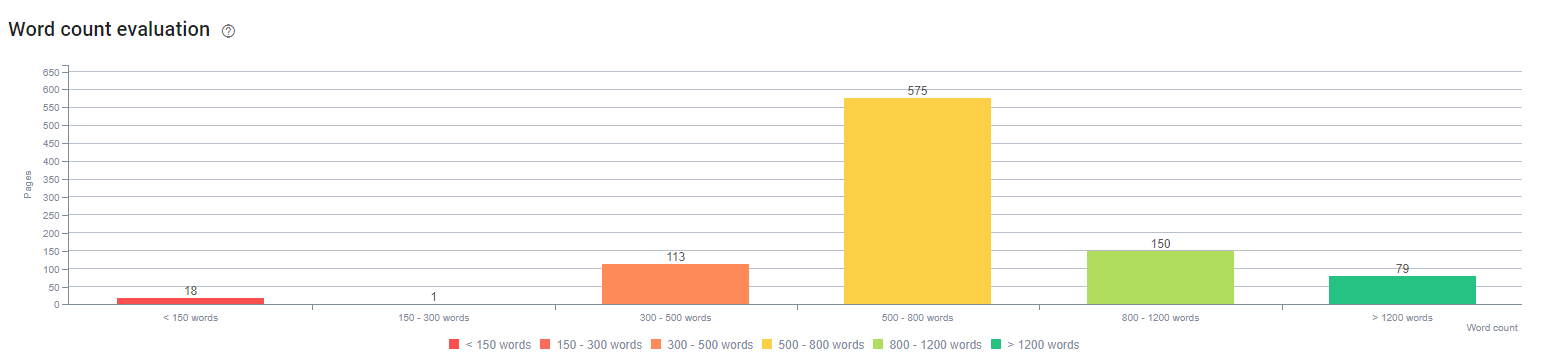
このプロセスの開始時、私たちのコンテンツは主に150〜300語で構成されていました。 サイト全体の平均コンテンツ長は350語増加しました。
4.問題:インデックスの汚染、膨満感、標準的なタグ
グーグルはインデックス汚染について声明を出したことがなく、実際、誰かが以前にそれをSEO用語として使用したかどうかはわかりません。 より効率的なインデックススコアのためにGoogleにとって意味をなさないすべてのページは、Googleインデックスページから削除する必要があります。 インデックスの汚染を引き起こすページは、何ヶ月もトラフィックを生成していないページです。 クリック率とオーガニックキーワードはゼロです。 彼らがいくつかの有機的なキーワードを持っている場合、彼らは同じキーワードのためにあなたのサイトの他のページの競争相手になる必要があります。
また、インデックスの肥大化について調査を行ったところ、さらに多くの不要なインデックス付きページが見つかりました。 これらのページは、サイト情報の構造が間違っているか、URLの構造が間違っているために存在していました。
この問題のもう1つの理由は、正規タグが誤って使用されていたことです。 2年以上の間、正規タグはGooglebotの単なるヒントとして扱われてきました。 それらが誤って使用されている場合、Googlebotはそれらを計算したり、サイトを評価する際に注意を払ったりしません。 また、この計算では、クロール予算を非効率的に消費する可能性があります。 正規タグの使用法が正しくないため、重複コンテンツを含む300を超えるコメントページがインデックスに登録されました。
私の理論の目的は、クリックを獲得してユーザーに価値を生み出す可能性のある、質の高い必要なページのみをGoogleに表示することです。
解決策:インデックスの汚染と膨満感の修正
まず、グーグルのジョン・ミューラーからアドバイスを受けました。 これらのページにnoindexタグを使用するかどうかを尋ねましたが、それでもGooglebotに「リンクの公平性とクロールの効率を失うでしょうか?」
ご想像のとおり、彼は最初は「はい」と答えましたが、その後、内部リンクを使用することでこの障害を克服できると提案しました。
また、dofollowと同時にnoindexタグを使用すると、これらのページでGooglebotによるクロール率が低下することもわかりました。 これらの戦略により、Googlebotに製品と重要なガイドラインページをより頻繁にクロールさせることができました。 John Muellerのアドバイスに従って、内部リンク構造も変更しました。
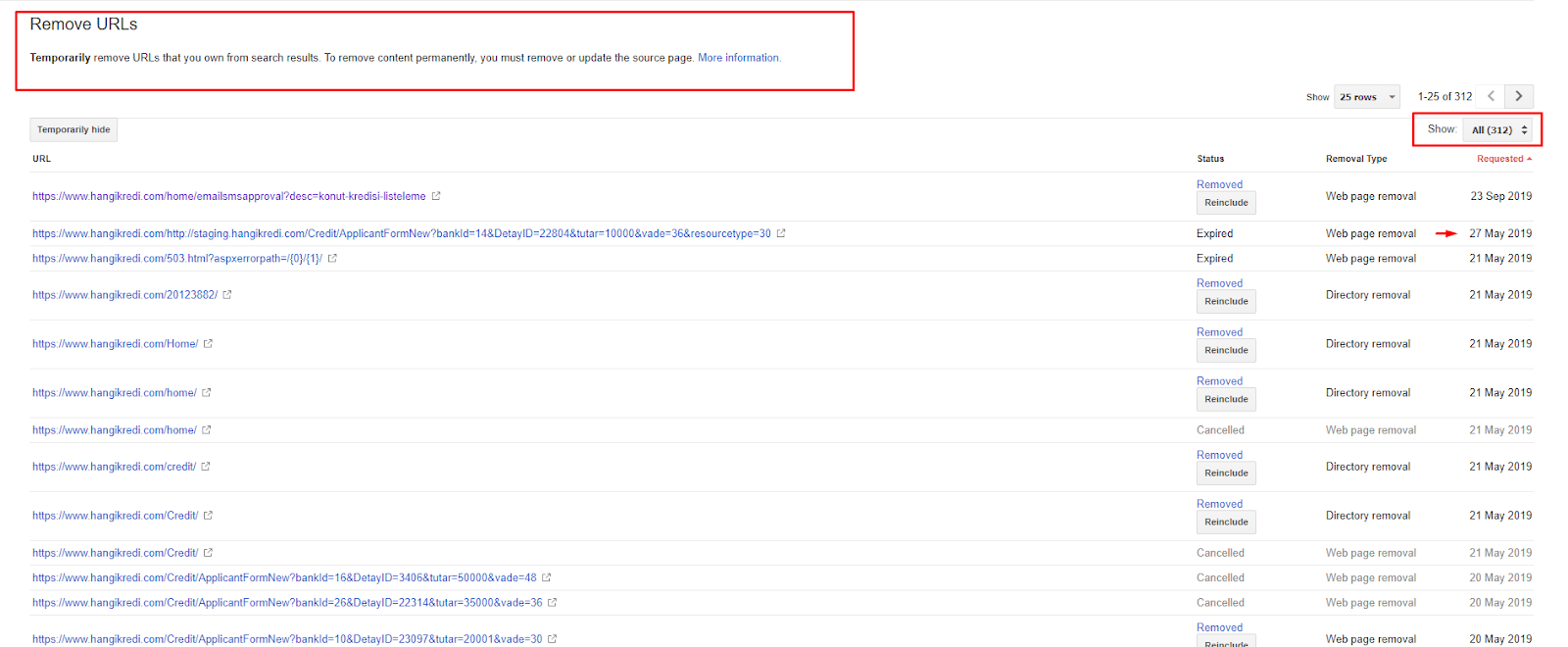
短い時間で:
- 不要なインデックス付きページが発見されました。
- 300ページ以上がインデックスから削除されました。
- Noindexタグが実装されました。
- インデックスから削除されたページからリンクを受け取ったページの内部リンク構造が変更されました。
- クロールの効率と品質を経時的に調べました。
5.問題:間違ったステータスコード
最初に、Googlebotが過去から削除された多くのコンテンツにアクセスしていることに気づきました。 8年前のページでさえまだクロールされていました。 これは、特に削除されたコンテンツに対して誤ったステータスコードが使用されていたことが原因でした。
404と410の機能には大きな違いがあります。 1つはコンテンツが存在しないエラーページ用で、もう1つは削除されたコンテンツ用です。 さらに、有効なページは、削除された多くのソースURLとコンテンツURLも参照していました。 一部の削除された画像とCSSまたはJSアセットも、有効な公開ページでリソースとして使用されました。 最後に、多くのソフト404ページ、複数のリダイレクトチェーン、および永続的にリダイレクトされたページの302-307一時リダイレクトがありました。
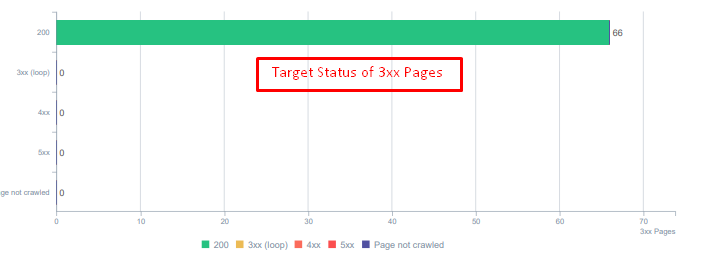
今日のリダイレクトされたアセットのステータスコード。
解決策:間違ったステータスコードを修正する
- 404ステータスコードはすべて410ステータスコードに変換されました。 (30000以上)
- ステータスコードが404のすべてのリソースは、新しい有効なリソースに置き換えられました。 (500以上)
- すべての302-307リダイレクトは301永続リダイレクトに変換されました。 (1500以上)
- リダイレクトチェーンは、使用中のアセットから削除されました。
- 毎月、ログ分析で404ステータスコードのページとリソースで25,000を超えるヒットを受け取りました。 現在、1か月あたり404ステータスコードの場合は50未満であり、410ステータスコードの場合はヒット数がゼロです…
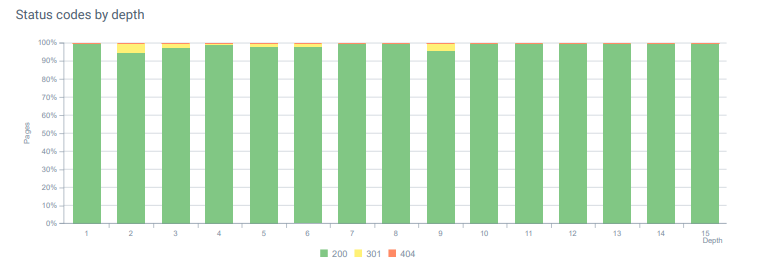
今日のページ深度全体のステータスコード。
6.問題:セマンティックHTML
セマンティクスとは、何かが何を意味するかを指します。 セマンティックHTMLには、階層内のページコンポーネントに意味を与えるタグが含まれています。 この階層コード構造を使用すると、コンテンツの一部の目的が何であるかをGoogleに伝えることができます。 また、Googlebotがページを完全にレンダリングするために必要なすべてのリソースをクロールできない場合は、少なくともWebページのレイアウトとコンテンツパーツの機能をGooglebotに指定できます。
Hangikredi.comでは、3月12日のGoogleコアアルゴリズムの更新後、ウェブサイトの構造が最適化されていないため、クロールの予算が十分でないことがわかりました。 そこで、Googlebotがウェブページの目的、機能、コンテンツ、有用性をより簡単に理解できるようにするために、セマンティックHTMLを使用することにしました。
解決策:セマンティックHTMLの使用
Googleの品質評価ガイドラインによると、すべての検索者には意図があり、すべてのWebページにはその意図に従った機能があります。 これらの機能をGooglebotに証明するために、Googlebotによってクロールされない一部のページのHTML構造にいくつかの改善を加えました。
- ページのメインコンテンツと機能を表示するために<main>タグを使用しました。
- ナビゲーション部分に<nav>を使用しました。
- サイトのフッターに<footer>を使用しました。
- 記事に<article>を使用しました。
- すべての見出しタグに<section>タグを使用しました。
- コンテンツ内の画像、表、引用符に<picture>、<table>、<citation>タグを使用しました。
- 補足コンテンツの<aside>タグを使用します。
- H1-H6階層の問題を修正しました(Googleの最新の「2つのH1を使用することは問題ではありません」というステートメントにもかかわらず、正しい構造を使用すると、Googlebotに役立ちます)。
- コンテンツ構造のセクションと同様に、注目のスニペットにもセマンティックHTMLを使用し、注目のスニペットの結果にはテーブルとリストを使用しました。

私たちにとって、これはサイト全体で現実的に実装可能な開発ではありませんでした。 それでも、デザインが更新されるたびに、追加のWebページにセマンティックHTMLタグを実装し続けます。
7.問題:構造化されたデータの使用
セマンティックHTMLの使用法と同様に、構造化データを使用して、ウェブページパーツの機能と定義をGooglebotに表示できます。 さらに、豊富な結果を得るには、構造化データが必須です。 私たちのWebサイトでは、構造化データは3月末まで使用されなかったか、より一般的には誤って使用されていました。 ウェブサイト上のエンティティやオフページアカウントとのより良い関係を構築するために、構造化データの実装を開始しました。
解決策:構造化データの使用法を修正してテストしました
金融機関やYMYLWebサイトの場合、構造化データは多くの問題を修正できます。 たとえば、ブランドのアイデンティティやコンテンツの種類を表示したり、より適切なスニペットビューを作成したりできます。 サイト全体および個々のページには、次の構造化データ型を使用しました。
- FAQ主な製品ページの構造化データ
- Webページの構造化データ
- 組織構造化データ
- ブレッドクラム構造化データ
8.サイトマップとRobots.txtの最適化
Hangikredi.comには、動的サイトマップはありません。 当時の既存のサイトマップには、必要なすべてのページが含まれていなかったほか、削除されたコンテンツも含まれていました。 また、Robots.txtファイルでは、何千もの外部リンクを含むアフィリエイトリファラーページの一部が禁止されていませんでした。 これには、コンテンツやGooglebotに不要なその他の追加リソースとは関係のないサードパーティのJSファイルも含まれていました。
次の手順が適用されました。
- より良いクロール信号とより良いカバレッジ検査のためにサイトカテゴリに従って作成された複数のサイトマップのsitemap_index.xmlを作成しました。
- サードパーティのJSファイルの一部と不要なJSファイルの一部は、robots.txtファイルで許可されていませんでした。
- PagerankまたはInternalLinkSculptingのセクションで説明したように、外部リンクがあり、ランディングページの値がないアフィリエイトページは許可されませんでした。
- 500を超えるカバレッジの問題を修正しました。 (それらのほとんどは、Robots.txtによって許可されていないにもかかわらずインデックスが作成されたページでした。)
下のグラフから、クロールレート、負荷、および需要の増加を確認できます。
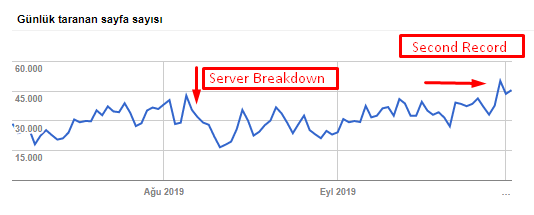
Googlebotによる1日あたりのクロールされたページ数。 8月1日まで、1日あたりのクロールページ数は着実に増加していました。 8月初旬に攻撃によりサーバー障害が発生した後、1か月強で安定性が回復しました。

Googlebotによる1日あたりのクロールされた負荷は、1日あたりにクロールされたページ数と並行して進化しました。
9.AMPの問題の修正
同社のWebサイトでは、すべてのブログページにAMPバージョンがあります。 コードの実装が正しくなく、AMPカノニカルが欠落しているため、すべてのAMPページがインデックスから繰り返し削除されました。 これにより、インデックススコアが不安定になり、Webサイトに対する信頼が失われました。 さらに、AMPページには、トルコ語のコンテンツにデフォルトで英語の用語と単語が含まれていました。
- 正規タグは400以上のAMPページで修正されました。
- 誤ったコードの実装が見つかり、修正されました。 (これは主に、AMP-AnalyticsおよびAMP-Canonicalタグの誤った実装が原因でした。)
- デフォルトでは、英語の用語はトルコ語に翻訳されていました。
- インデックスとランキングの安定性は、会社のWebサイトのブログ側で作成されました。
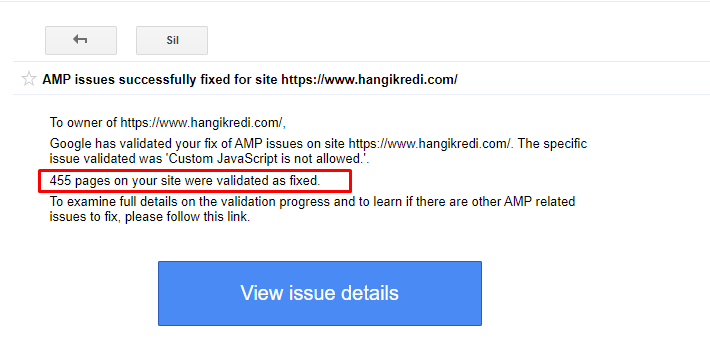
AMPの改善に関するGSCのメッセージ例
10.メタタグの問題と解決策
クロール予算の問題のため、重要な主要製品ページの重要な検索クエリで、Googleはメタタグのコンテンツをインデックスに登録したり表示したりしませんでした。 メタタイトルの代わりに、SERPリストには2つの単語から構築された会社名のみが表示されていました。 スニペットの説明は表示されませんでした。これにより、クリック率が低下し、ブランドアイデンティティが損なわれていました。 以下に示すように、メタタグをソースコードの先頭に移動することで、この問題を修正しました。
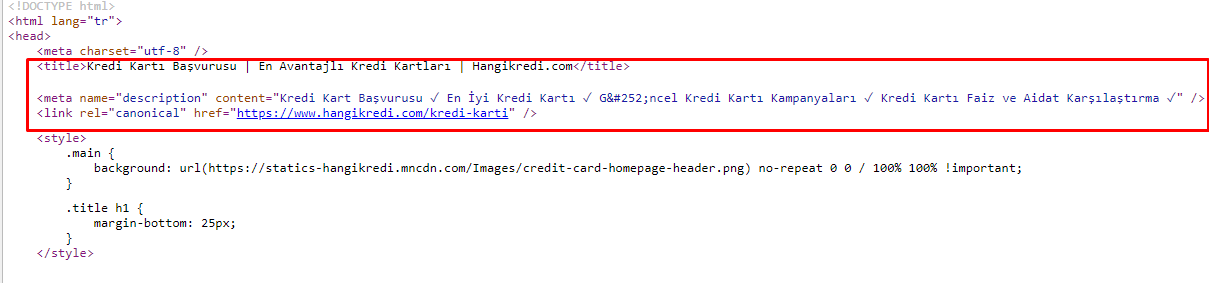
クロール予算に加えて、トランザクションページと有益なページ用に600を超えるメタタグも最適化しました。
- モバイルデバイス用に最適化された文字長。
- タイトルでより多くのキーワードを使用
- さまざまなスタイルのメタタグを使用し、クリック率、キーワードギャップ、ランキングの変化を調べました
- これらの最適化プロセスのおかげで、セカンダリキーワードをより適切にターゲティングするために、正しいサイトツリー構造でより多くのページを作成しました。
- 私たちのサイトには、Googleのアルゴリズムをテストし、ユーザーのCTRを検索するための、さまざまなメタタイトル、説明、見出しがあります。
11.画像パフォーマンスの問題と解決策
画像の問題は2つのタイプに分けることができます。 コンテンツの利便性とページ速度のため。 どちらの場合も、会社のWebスティルサイトにはやるべきことがたくさんあります。
ネガティブな3月12日のコアアルゴリズムアップデートに続く3月と4月:
- 画像にaltタグがないか、間違ったaltタグがありました。
- 彼らにはタイトルがありませんでした。
- 彼らは正しいURL構造を持っていませんでした。
- 彼らは次世代の拡張機能を持っていませんでした。
- それらは圧縮されませんでした。
- すべてのデバイスの画面サイズに適した解像度ではありませんでした。
- キャプションはありませんでした。
次のGoogleコアアルゴリズムアップデートの準備をするには:
- 画像は圧縮されました。
- それらの拡張子は部分的に変更されました。
- それらのほとんどにAltタグが書かれています。
- タイトルとキャプションはユーザー向けに修正されました。
- ユーザーのURL構造が部分的に修正されました。
- ブラウザによってまだロードされている未使用の画像がいくつか見つかり、システムから削除されました。
サイトインフラストラクチャのため、画像SEO補正を部分的に実装しました。
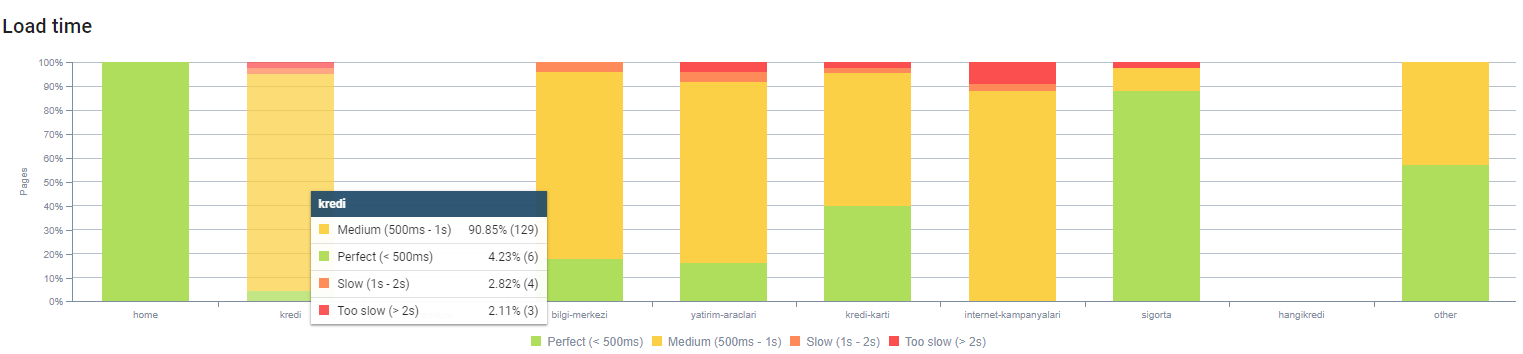
上記のページの深さでページの読み込み時間を確認できます。 ご覧のとおり、ほとんどの製品ページはまだ重いです。
12.キャッシュ、プリフェッチ、プリロードの問題と解決策
3月12日のコアアルゴリズムアップデートの前は、会社のWebサイトに緩いキャッシュシステムがありました。 一部のコンテンツ部分はキャッシュにありましたが、一部はキャッシュにありませんでした。 これは、競合他社の製品ページより2倍遅いため、製品ページで特に問題になりました。 Webページのほとんどのコンポーネントは実際には静的なソースですが、それでもキャッシュ範囲を示すためのEtagがありませんでした。
次のGoogleコアアルゴリズムアップデートの準備をするには:
- すべてのWebページのいくつかのコンポーネントをキャッシュし、それらを静的にしました。
- これらのページは重要な製品ページでした。
- サイトのインフラストラクチャのため、まだEタグを使用していません。
- 特に画像、静的リソース、およびいくつかの重要なコンテンツ部分は、サイト全体で完全にキャッシュされるようになりました。
- 忘れられたアウトソーシングリソースに対して、dns-prefetchコードの使用を開始しました。
- 私たちはまだプリロードコードを使用していませんが、将来それを実装するためにサイトでユーザージャーニーに取り組んでいます。
13. HTML、CSS、JSの最適化と縮小
サイトインフラストラクチャの問題のため、サイトの速度を上げるために行うことはそれほど多くありませんでした。 いくつかのページコンポーネントを削除するなど、可能な限りすべての方法でギャップを埋めようとしました。 重要な製品ページについては、HTMLコード構造をクリーンアップし、縮小して圧縮しました。
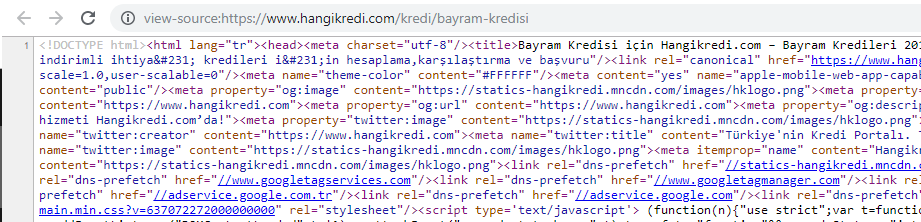
季節限定で重要な製品ページのソースコードのスクリーンショット。 FAQ構造化データ、HTMLミニファイ、画像最適化、コンテンツの更新、内部リンクを使用することで、適切なタイミングで1位になりました。 (キーワードはトルコ語で「BayramKredisi」で、「ホリデークレジット」を意味します)
また、CSSファクタリング、リファクタリング、JS圧縮を部分的に小さなステップで実装しました。 ランキングが下がったとき、競合他社のページと私たちのページの間のサイト速度のギャップを調べました。 スピードアップできる緊急のページをいくつか選びました。 また、これらのページの重要なCSSファイルを部分的に精製および圧縮しました。 会社のさまざまな部門で使用されているサードパーティのJSファイルの一部を削除するプロセスを開始しましたが、まだ削除されていません。 一部の製品ページでは、リソースの読み込み順序を変更することもできました。
競合他社の調査
すべての技術的なSEOの改善に加えて、競合他社を検査することは、コアアルゴリズムアップデートの性質と目的を理解するための私の最良のガイドでした。 私は、競合他社のデザイン、コンテンツ、ランク、およびテクノロジーの変更を追跡するために、いくつかの有用で役立つプログラムを使用しました。
- キーワードランキングの変更には、Wincher、Semrush、Ahrefsを使用しました。
- ブランドの言及には、Googleアラート、BuzzSumo、Talkwalkerを使用しました。
- 新しいリンクと新しいキーワード獲得レポートには、AhrefsAlertを使用しました。
- コンテンツとデザインの変更には、Visualpingを使用しました。
- テクノロジーの変更には、SimilarTechを使用しました。
- Google Update News and Inspectionでは、主にSemrush Sensor、Algoroo、CognitiveSEOSignalsを使用しました。
- 競合他社のURL履歴を調べるために、WaybackMachineを使用しました。
- 競合他社のサーバー速度については、ChromeDevToolsとByteCheckを使用しました。
- クロールとレンダリングのコストには、「サイトのコストは?」を使用しました。 (Since last month, I have started using Onely's new JS Tools like WWJD or TL:DR..)

A screenshot from SimilarTech for my main competitor.
A screenshot from Visualping which shows the layout changes for my secondary competitor.
Testing the value of the changes
With all of these problems identified and solutions in place, I was ready to see whether the website would hold up to the next Google core algorithm updates.
In the next article, I'll look at the major core algorithm updates over the next several months, and how the site performed.