
OnCrawlのSplunk統合でSEOログ分析を改善する5つの方法
公開: 2019-01-03OnCrawlは最近、Splunkユーザーのログ監視を容易にするSplunk統合をリリースしました。 企業は、プロセスの自動化と高度なセキュリティ制御という2つの主な目的でSplunk統合を使用していることがわかりました。 しかし、ツールの利点はそれだけではありません。 OnCrawlSplunk統合を使用して技術的なSEOを改善する5つの方法を次に示します。
SEOログ分析:基本
SEOログ分析とは何ですか?
ログファイルは、Webサイトのサーバー自体によって記録されたWebサイト上のすべてのアクティビティを表します。 それはあなたのウェブサイトで何が起こっているかに関する最も完全で最も信頼できる情報源です。 これには、ボットヒットの数と頻度、SERPからのSEOオーガニックヒットの数と頻度、デバイスタイプ(デスクトップとモバイル)またはURLタイプ(ページとリソース)別の内訳、正確なページサイズ、実際のHTTPステータスが含まれます。コード。
SEOログ分析によって提供される多くの利点のいくつか:
- Googleによるサイトの処理方法の変更を示すピークまたはクロール動作の変化を発見する
- 新しいページがインデックスに登録され、最初のオーガニックビジターを受け取るまでに平均してどれくらいの時間がかかるかを知っています
- ボットとユーザーのアクティビティがページのランキングにどのように影響するかを監視する
- ボットとユーザーの行動が他のSEO要因とどのように相関しているかを理解する

Splunkとは何ですか?
Splunkは、マシンデータ集約のためのエンタープライズソリューションです。 大規模な複数のソースからのデータのインデックス作成と管理が可能で、サイトのセキュリティとレポートの目的でサーバーログを処理する機能が含まれています。
Splunkの利点のいくつか:
- 改善されたデータ相関の索引付けと検索
- より良いレポートのためのドリルダウンおよびピボット機能
- リアルタイムアラート
- データダッシュボード
- 高度にスケーラブル
- 柔軟な展開オプション
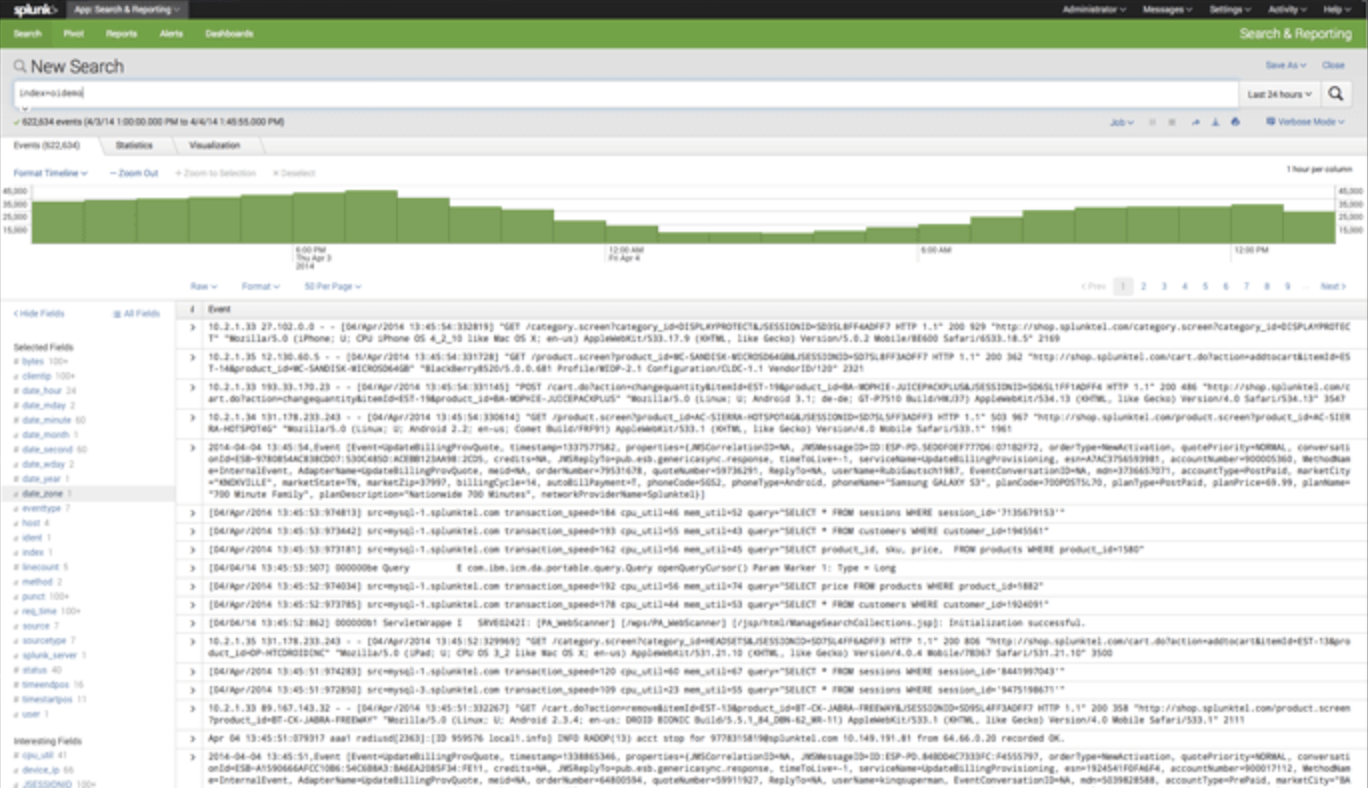
Splunkでのログモニタリング
Splunkユーザーは、OnCrawl統合の恩恵を受けて、Splunkで管理されているサーバーログデータをOnCrawlプラットフォームのSEOデータに接続します。
オンクロールログアナライザ
 もっと詳しく知る
もっと詳しく知るOnCrawl+Splunkで技術的なSEOを改善する
1.詳細なSEO分析にログを使用する
Splunkは、ログデータのアラートを集約、検索、監視、および設定する機能を証明します。 サーバーログのコンテンツを解析してインデックスを再作成します。 強力な検索とフィルターを使用して、ログファイルのデータに関する質問への回答を提供します。 この処理ステップは、ログデータで明らかにされた傾向の統計を提供します。
ただし、これをSEOデータに適用する場合は、生データから始めるのが最善です。 そして、それはまさにOnCrawlSplunk統合が行うことです。
これにより、ログデータの個別の統計を表示するだけでなく、ログの情報をOnCrawlプラットフォームの他のすべてのデータソースと統合できます。 次に、これにより、SEOメトリックと、ログファイル内のユーザーおよびボットの動作に関する情報との関係を調べることができます。

ページクリック深度別のオーガニック訪問数。
このクロスデータ分析には、SEOに役立つ軸を含めることができます。
- 個々のボットによるクロール動作の内訳
- 最初のクロールから最初のオーガニック訪問までの時間
- ユーザーとボットに提供されたページと、監査クロール中に提供されたページの比較
- 孤立したページの発見
- クロール頻度とランキング、インプレッション、クリック率の相関関係
- ユーザー/ボットのアクティビティに対する内部リンク戦略の影響
- ページのクリック深度とユーザー/ボットのアクティビティの関係
- 内部ページの人気とユーザー/ボットのアクティビティの関係
- SEOパフォーマンス別にグループ化されたページ全体のユーザーとボットのアクティビティの内訳
2.セットアップを簡単にします
データセキュリティの自動化やより細かい制御が必要かどうかにかかわらず、Splunkユーザーの場合は、
セットアップがいかに簡単かというように。

システム管理者でない場合、SEOのログ監視を設定することは複雑な作業のように思えるかもしれません。
私たちの提案は、単に難しい部分をスキップすることです。 これで、すべてをSplunkで直接セットアップし、生成したキーを使用してOnCrawlとの接続を作成できます。
それでおしまい。 あなたは行く準備ができています。 これは簡単なことではありません。
3.Splunkでプロセスの自動化を活用する
Splunkで収集されたログデータを手動で使用するには、複数の手順が必要です。
- フィルタを作成して、ログデータの正しい選択を検索します
- 保存された検索を作成する
- 検索を実行するための自動化を設定する
- CSVに出力
- SSHでSplunkインスタンスに接続します
- CSV出力フォルダーに移動します
- ファイルをコンピューターに転送する
- OnCrawlftpスペースに接続します
- ファイルをOnCrawlに転送します…
ログデータのギャップを回避するために、このプロセスを定期的に繰り返す必要があります。 多くの場合、これは日常業務になります。
OnCrawlにSplunk統合を使用することを選択した場合、タスクを定期的に起動する必要がなくなります。 プロセスを設定するだけで済みます(前述のように、これは簡単なことではありません)。 スクリプトの起動、さらに悪いことに、一連の手動アクションを毎日心配する必要はありません。 統合はあなたのためにそれを処理します。
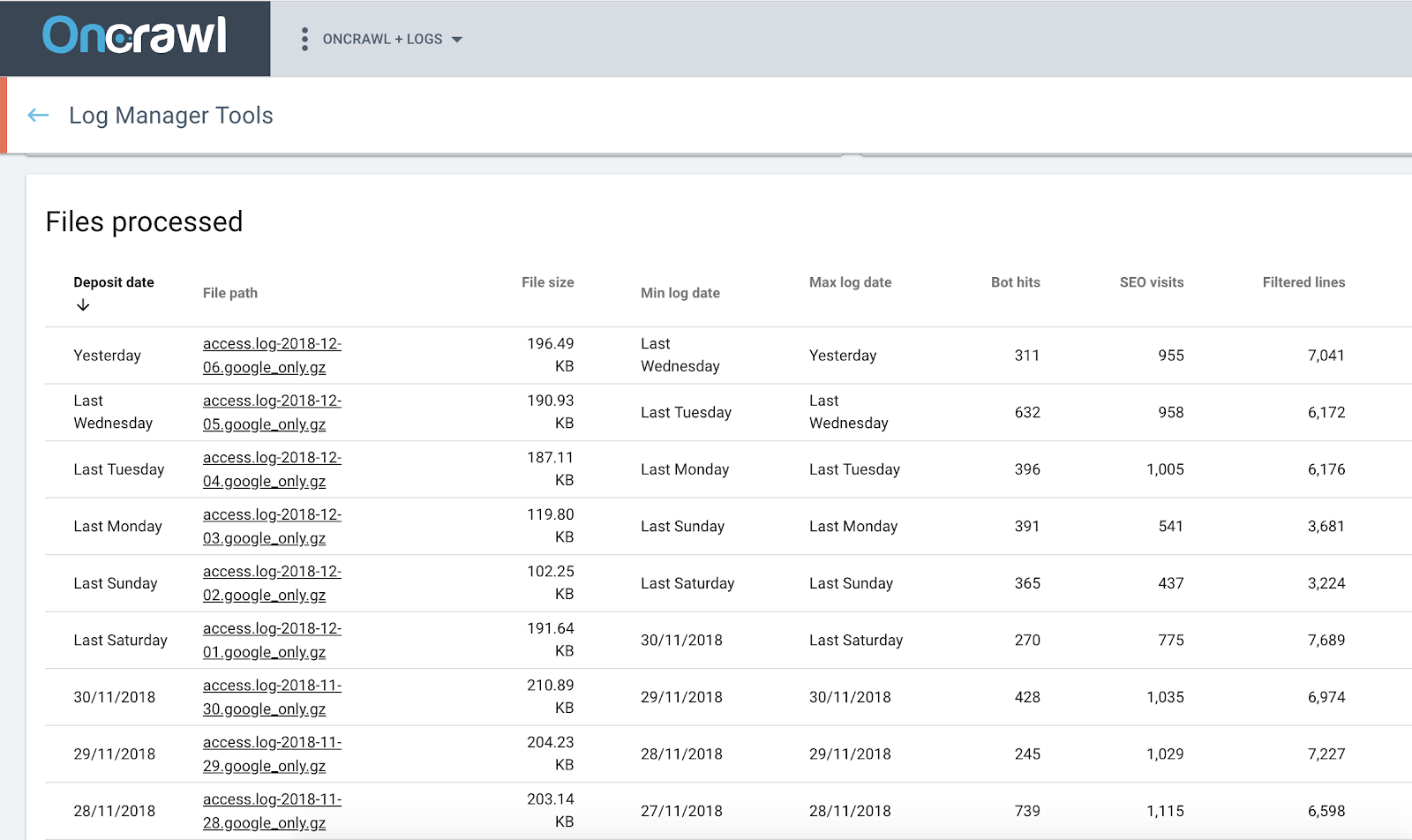
4.プロセスを保護します
問題が発生したときにデータが失われるのを防ぎます。 ログの監視はデータの継続的なストリームに依存しているため、ギャップがあると誤った結論につながる可能性があります。 次のような質問をする必要はありません。Googleで起こったことが原因で、今朝のオーガニック訪問が明らかにないのか、それともデータが不足しているだけなのか。
OnCrawl Splunk統合は、サーバーがダウンしたり接続が失われたりした場合にユーザーを保護し、時間がない場合やデータのアップロードを忘れた場合の人為的エラーを防ぎます。 サーバーに接続できない場合でも、データにギャップが生じることはありません。 少し後で収集します。 Splunkに追加するのを忘れた以前の日付のデータのセットを見つけた場合、OnCrawl統合も自動的にそれを取得します。
5.データセキュリティを管理する
OnCrawlでは、お客様のデータのセキュリティを非常に重要視しています。
いつものように、ログ内の機密データは、プライベートで安全なFTPスペースに置いた場所に保持され、他の場所で利用できるようになることはありません。 たとえば、Googlebotのアクセスの信頼性を検証する際に処理する個人データは、IPアドレスのみです。 使用されたIPアドレスの記録は保持せず、検証の結果のみを記録します。 必要に応じて、FTPスペースからファイルを削除することにより、いつでも分析に利用できる機密情報を削除できます。
Splunkの統合はさらに進んでいます。 プロセス全体を通じて、データの管理を維持できるようにします。 OnCrawlで、アクセス権、共有するデータ、および更新の頻度を定義します。 Splunk統合を通じてOnCrawlとデータを共有する場合、標準の安全なプロトコルを使用してSplunkと通信し、設定したパスワードとキーで保護されます。
セットアップはSplunkで行われるため、OnCrawlはユーザーが表示できないものを表示することはありません。 OnCrawlと共有する情報を選択します。 それだけでなく、セットアップを管理するため、ロギングプロセスや会社の基準に変更があった場合は、いつでも変更を加えることができます。