
Pythonでのデータ分析のためにGoogleSearchConsoleAPIからデータを抽出します
公開: 2022-03-01Google Search Console(GSC)は、SEOスペシャリストにとって間違いなく最も便利なツールの1つです。これにより、インデックスカバレッジ、特に現在ランク付けされているクエリに関する情報を取得できます。 これを知っていると、多くの人がスプレッドシートを使用してGSCデータを分析しますが、プログラミング言語などのツールで改善の余地があることを理解している限り、問題ありません。
残念ながら、GSCインターフェースは、表示される行(わずか5000)と使用可能な期間(わずか16か月)の両方の点でかなり制限されています。 これにより、洞察を得る能力が大幅に制限される可能性があり、より大きなWebサイトには適していないことは明らかです。
Pythonを使用すると、GSCデータを簡単に取得し、従来のスプレッドシートソフトウェアでははるかに手間がかかるより複雑な計算を自動化できます。
これは、Excelの最大の問題の1つ、つまり行の制限と速度の解決策です。 今日では、以前よりもはるかに多くのデータ分析の選択肢があり、そこでPythonが活躍します。
このチュートリアルに従うために高度なコーディングの知識は必要ありません。いくつかの基本的な概念を理解し、GoogleColabでいくつかの練習をするだけです。
Google SearchConsoleAPIの使用を開始する
始める前に、Google SearchConsoleAPIを設定することが重要です。 プロセスは非常に簡単で、必要なのはGoogleアカウントだけです。 手順は次のとおりです。
- GoogleCloudPlatformで新しいプロジェクトを作成します。 あなたはグーグルアカウントを持っているべきです、そして私はあなたがそれを持っていると確信しています。 コンソールに移動すると、上部に新しいプロジェクトを作成するためのオプションが表示されます。
- 左側のメニューをクリックして「APIとサービス」を選択すると、別の画面が表示されます。
- 上部の検索バーから「GoogleSearchConsoleAPI」を探し、有効にします。
- 次に、[資格情報]タブに移動します。APIを使用するには、なんらかの権限が必要です。
- これは必須であるため、「同意」画面を構成します。 公開するかどうかは関係ありません。
- アプリケーションの種類として「デスクトップアプリ」を選択できます
- このチュートリアルではOAuth2.0を使用します。jsonファイルをダウンロードする必要があります。これで完了です。
これは実際、ほとんどの人、特にGoogleAPIに慣れていない人にとって最も難しい部分です。 心配しないでください。次のステップははるかに簡単で問題が少なくなります。
Pythonを使用してGoogleSearchConsoleAPIからデータを取得する
JupyterNotebookやGoogleColabなどのノートブックを使用することをお勧めします。 要件について心配する必要がないため、後者の方が適しています。 したがって、ここで説明するのはGoogleColabに基づいています。
開始する前に、次のコードを使用してjsonファイルをGoogleColabに更新します。
google.colabインポートファイルから files.upload()
次に、分析に必要なすべてのライブラリをインストールし、次のコードスニペットを使用してテーブルの視覚化を改善しましょう。
%%捕獲 #必要なものをロードする !pip install git + https://github.com/joshcarty/google-searchconsole パンダをpdとしてインポートします numpyをnpとしてインポートします matplotlib.pyplotをpltとしてインポートします google.colabからimportdata_table !git clone https://github.com/jroakes/querycat.git !pip install -r querycat / require_colab.txt !pip install umap-learn data_table.enable_dataframe_formatter()#テーブルの視覚化を改善する
最後に、searchconsoleライブラリをロードできます。これは、長い関数に依存せずにロードするための最も簡単な方法を提供します。 私が使用している引数を使用して次のコードを実行し、client_configがアップロードされたjsonファイルと同じ名前であることを確認してください。
searchconsoleをインポートします account = searchconsole.authenticate(client_config ='client_secret_.json'、serialize ='credentials.json'、flow ='console')
アプリケーションを承認するためのGoogleページにリダイレクトされ、Googleアカウントを選択してから、取得したコードをコピーしてGoogleColabバーに貼り付けます。
まだ終了していません。データが必要なプロパティを選択する必要があります。 account.webpropertiesを使用してプロパティを簡単に確認し、何を選択する必要があるかを確認できます。
property_name = input('GSCにリストされているWebサイトの名前を挿入します:') webproperty = account [str(property_name)]
完了したら、カスタム関数を実行して、データを含むオブジェクトを作成します。
def extract_gsc_data(webproperty、start、stop、* args):
webpropertyがNoneでない場合:
print(f'{webproperty}のデータを抽出しています')
gsc_data = webproperty.query.range(start、stop).dimension(* args).get()
gsc_dataを返します
そうしないと:
print('Webプロパティが見つかりません。正しいものを選択してください')
なしを返す
この関数の考え方は、前に定義したプロパティと時間枠を、開始日と終了日の形式で、ディメンションとともに取得することです。
ディメンションを選択できるという選択は、特定のレベルの粒度が必要かどうかを理解できるため、SEOスペシャリストにとって非常に重要です。 たとえば、場合によっては、日付ディメンションの取得に関心がない場合があります。
Google検索コンソールのインターフェースはそれらを別々にエクスポートでき、毎回それらをマージするのは非常に面倒なので、私の提案は常にクエリとページを選択することです。 これは、検索コンソールAPIのもう1つの利点です。
この場合、日付ディメンションを直接取得して、時間を考慮する必要があるいくつかの興味深いシナリオを示すこともできます。
ex = extract_gsc_data(webproperty、 '2021-09-01'、 '2021-12-31'、'query'、'page'、'date')
より大きな物件の場合は多くの時間を待つ必要があることを考慮して、適切な時間枠を選択してください。 この例では、平均してほとんどのデータセットから貴重な洞察を得るのに十分な3か月の期間を検討しています。
大量のデータを扱う場合は、1週間でも選択できます。私たちが気にするのはプロセスです。
ここで紹介するのは、例に適したものにするために、合成データまたは変更された実際のデータに基づいています。 結果として、ここに表示されるものは完全に現実的であり、実際のシナリオを反映することができます。
データクリーニング
知らない人のために、私たちは私たちのデータをそのまま使用することはできません、私たちが正しく働いていることを確認するためにいくつかの追加のステップがあります。 まず、オブジェクトをPandasデータフレームに変換する必要があります。これは、Pythonでのデータ分析の基礎であるため、精通している必要のあるデータ構造です。
df = pd.DataFrame(data = ex) df.head()
headメソッドは、データセットの最初の5行を表示できます。データがどのように見えるかを一目で確認すると、非常に便利です。 簡単な関数を使用して、ページ数を数えることができます。
セットには重複する要素を含めることができないため、重複を削除する良い方法は、オブジェクトをセットに変換することです。
一部のコードスニペットは、Hamlet Batistaのノートブックと、岡沢正樹のノートブックに触発されました。
ブランド用語の削除
最初に行うことは、ブランド化されたキーワードを削除することです。ブランド化された用語が含まれていないクエリを探しています。 これはカスタム関数で行うのは非常に簡単で、通常は一連のブランド用語があります。
実例として、それらすべてを除外する必要はありませんが、実際の分析のために除外してください。 これは、SEOで最も重要なデータクリーニング手順の1つです。そうしないと、誤解を招く結果が表示されるリスクがあります。
domain_name = str(input('ブランド用語をコンマで区切って挿入:'))。replace('、'、'|') 再インポート domain_name = re.sub(r "\ s +"、 ""、domain_name) print('RegExを使用してすべてのスペースを削除:\ n') df['ブランド/非ブランド']=np.where( df ['query']。str.contains(domain_name)、'Brand'、'Non-branded' )。
2つのクラスの違いを認識するために、データセットに新しい列を追加します。 テーブルまたはバープロットを介して、クエリの総数をどれだけ占めるかを視覚化できます。
棒グラフは非常に単純であり、この場合はテーブルの方が適していると思いますので、ここでは示しません。
brand_count_df = df ['Brand / Non-branded']。value_counts()。rename_axis('cats')。to_frame('counts')
brand_count_df ['Percentage'] = brand_count_df ['counts'] / sum(brand_count_df ['counts'])
pd.options.display.float_format ='{:. 2%}'。format
brand_count_df
ブランドキーワードと非ブランドキーワードの比率をすばやく確認して、データセットから削除する量を把握できます。 ここには理想的な比率はありませんが、ブランド化されていないキーワードの割合を高くしたいのは間違いありません。
次に、ブランドとしてマークされたすべての行を削除して、他の手順に進むことができます。
#ブランド化されていないキーワードのみを選択 df = df.loc[df['ブランド/非ブランド']=='非ブランド']
不足している値の入力とその他の手順
データセットに欠測値(または専門用語のNA)が含まれている場合は、いくつかのオプションがあります。 最も一般的なのは、それらをすべて削除するか、0やその列の平均などのプレースホルダー値で埋めることです。
正解はなく、どちらのアプローチにも長所と短所、そしてリスクがあります。 Google検索コンソールのデータの場合、いくつかの指標の効果を過小評価するために、0などのプレースホルダー値を設定することをお勧めします。
df.fillna(0、inplace = True)
実際のデータ分析に進む前に、機能、つまりデータセットの列を調整する必要があります。 いくつかのクールなピボットテーブルに使用したいので、この位置は特に興味深いものです。
位置を整数に丸めることができます。これは目的に役立ちます。
df ['position'] = df ['position']。round(0).astype('int64')
上記の他のすべてのクリーニング手順に従ってから、日付列を調整する必要があります。
私たちはパンダの助けを借りて月と年を抽出しています。 より短い時間枠で作業する場合は、これを具体的にする必要はありません。これは、半年を考慮した例です。
#日付を適切な形式に変換 df ['date'] = pd.to_datetime(df ['date']) #月を抽出 df ['month'] =df['date']。dt.month #年を抽出 df ['year'] =df['date']。dt.year
[電子ブック]データSEO:次の大冒険
 電子ブックを読む
電子ブックを読む探索的データ分析
Pythonの主な利点は、Excelで行うのと同じことを実行できることですが、より多くのオプションがあり、より簡単です。 すべてのアナリストが本当によく知っているもの、つまりピボットテーブルから始めましょう。
ポジショングループごとの平均CTRの分析
平均の分析ポジショングループごとのCTRは、Webサイトの一般的な状況を理解できるため、最も洞察に満ちたアクティビティの1つです。 ピボットを適用してから、プロットしてみましょう。
pd.options.display.float_format ='{:. 2%}'。format
query_analysis = df.pivot_table(index = ['position']、values = ['ctr']、aggfunc = ['mean'])
query_analysis.sort_values(by = ['position']、ascending = True).head(10)
ax = query_analysis.head(10).plot(kind ='bar')
ax.set_xlabel('Avg。Position')
ax.set_ylabel('CTR')
ax.set_title('CTR by avg。position')
ax.grid('on')
ax.get_legend()。remove()
plt.xticks(rotation = 0)
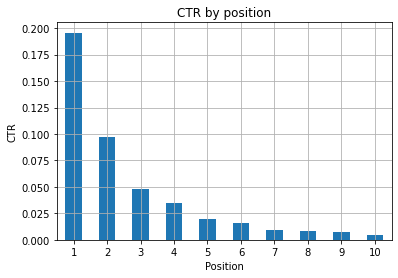
図1:異常を特定するための位置によるCTRの表現。
ここでの理想的なシナリオは、グラフの左側のCTRが向上することです。これは、通常、位置1の結果がはるかに高いCTRを特徴とするためです。 ただし、最初の3つのスポットのクリック率が予想よりも低い場合があり、調査する必要があることに注意してください。
エッジケースも考慮してください。たとえば、位置11が最初よりも優れている場合です。 検索コンソールに関するGoogleのドキュメントで説明されているように、この指標は最初に考えた順序に従っていません。
さらに、リンクの位置は毎回変化し、100%の精度を実現することは不可能であるため、このメトリックは平均であると付け加えています。
時々あなたのページは上位にランクされますが、十分に説得力がないので、タイトルを修正してみることができます。 これは高レベルの概要であるため、詳細な違いは見られません。したがって、この問題が大規模な場合は、迅速に対応することを期待してください。
また、低い位置にあるページのグループの平均クリック率が、良い場所にあるページのグループよりも高い場合にも注意してください。
このため、奇妙なパターンを見つけるために、分析を15位以上まで拡張することをお勧めします。
ポジションごとのクエリ数とSEOの取り組みの測定
ランク付けしているクエリの増加は常に良いシグナルですが、それは必ずしも将来のより良いランク付けを意味するわけではありません。 クエリカウントは、ランク付けしているクエリの数をカウントするプロセスであり、GSCデータで実行できる最も重要なタスクの1つです。
ピボットテーブルは再び大きな助けになり、結果をプロットできます。
ランキングクエリ=df.pivot_table(index = ['position']、values = ['query']、aggfunc = ['count']) ランキング_queries.sort_values(by = ['position'])。head(10)
SEOスペシャリストとして必要なのは、一番左の一番上のスポットでクエリ数を増やすことです。 その理由は非常に自然なことです。高い位置では平均してクリック率が高くなり、ページをクリックする人が増える可能性があります。
ax =ranking_queries.head(10).plot(kind ='bar') ax.set_ylabel('クエリ数') ax.set_xlabel('Position') ax.set_title('ランキング分布') ax.grid('on') ax.get_legend()。remove()
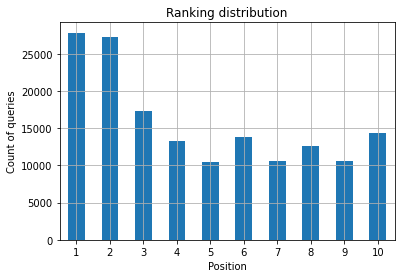
図2:ポジションごとにいくつのクエリがありますか?
気になるのは、時間が経つにつれて上位のクエリ数を増やすことです。
日付ディメンションで遊ぶ
検討した時間間隔でクリック数がどのように変化するかを見てみましょう。最初にクリック数の合計を取得しましょう。
clicks_sum = df.groupby('date')['clicks']。sum()
データを日付ディメンションでグループ化し、それぞれのクリック数の合計を取得しています。これは一種の要約です。
これで、取得したものをプロットする準備が整いました。視覚化を改善するためだけにコードがかなり長くなります。恐れることはありません。
#期間全体のクリック数の合計 %config InlineBackend.figure_format='網膜' matplotlib.pyplotからインポート図 figure(figsize =(8、6)、dpi = 80) ax = clicks_sum.plot(color ='red') ax.grid('on') ax.set_ylabel('クリックの合計') ax.set_xlabel('Month') ax.set_title('クリック数が月ごとにどのように変化したか') xlab = ax.xaxis.get_label() ylab = ax.yaxis.get_label() xlab.set_style('italic') xlab.set_size(10) ylab.set_style('italic') ylab.set_size(10) ttl = ax.title ttl.set_weight('bold') ax.spines ['right']。set_color((。8、.8、.8)) ax.spines ['top']。set_color((。8、.8、.8)) ax.yaxis.set_label_coords(-。15、.50) ax.fill_between(clicks_sum.index、clicks_sum.values、facecolor ='yellow')
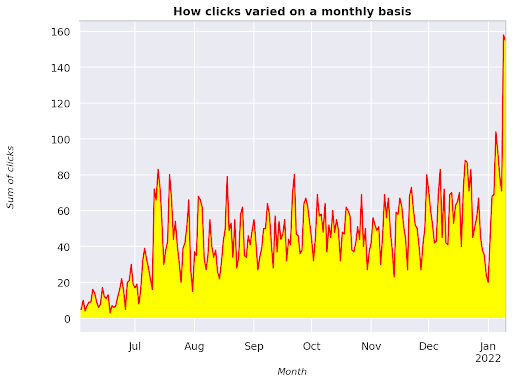

図3:月変数に関連するクリックの合計のプロット
これは、2021年6月から始まり、2022年1月の半分までまっすぐ進む例です。上に表示されているすべての行には、この視覚化をより美しくする役割があります。これを試して、何が起こるかを確認してください。
ポジションごとのクエリ数、月次スナップショット
Pythonでプロットできるもう1つの優れた視覚化は、単純な棒グラフよりもさらに視覚的なヒートマップです。 時間の経過とその位置に応じてクエリ数を表示する方法を紹介します。
海生まれをsnsとしてインポート sns.set_theme() df_new = df.loc [(df ['position'] <= 10)&(df ['year']!= 2022)、:] #サンプルのフライトデータセットを読み込み、長い形式に変換します df_heat = df_new.pivot_table(index = "position"、columns = "month"、values = "query"、aggfunc ='count') #各セルの数値を使用してヒートマップを描画します f、ax = plt.subplots(figsize =(20、12)) x_axis_labels = ["9月"、 "10月"、 "11月"、"12月"] sns.heatmap(df_heat、annot = True、linewidths = .5、ax = ax、fmt ='g'、cmap = sns.cm.rocket_r、xticklabels = x_axis_labels) ax.set(xlabel ='Month'、ylabel ='Position'、title ='位置ごとのクエリ数は時間とともにどのように変化するか') #rotate位置ラベルを読みやすくする plt.yticks(rotation = 0)
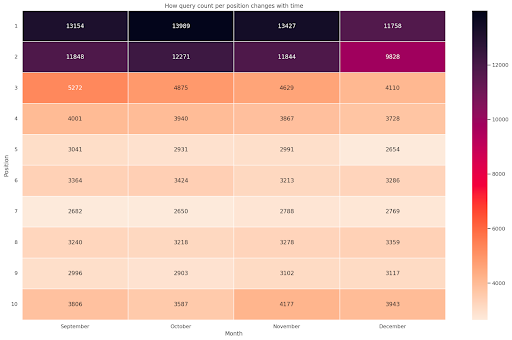
図4:位置と月に応じたクエリカウントの進行状況を示すヒートマップ。
これは私のお気に入りの1つです。ヒートマップは、この例のように、ピボットテーブルを表示するのに非常に効果的です。 期間は4か月以上あり、水平方向に読むと、時間の経過とともにクエリ数がどのように変化するかがわかります。 ポジション10の場合、9月から12月にかけて少し増加しますが、ポジション2の場合、紫色で示されているように、著しく減少します。
次のシナリオでは、クエリの大部分がトップスポットにありますが、これは非常に珍しいことです。 その場合は、データフレームに戻って分析し、ブランド用語の可能性がある場合はそれを探してください。
コードからわかるように、ロジックを理解している限り、複雑なプロットを作成することはそれほど難しくありません。
「正しい」ことをしている場合、クエリ数は時間とともに増加するはずです。2つの異なる時間枠での違いをプロットできます。 私が提供した例では、特にCTRが高いと思われるトップポジションの場合はそうではないことは明らかです。
いくつかの基本的なNLPの概念を紹介します
自然言語処理(NLP)はSEOの天の恵みであり、基本的なアルゴリズムを適用するために専門家である必要はありません。 N-gramは、GSCデータに関する洞察を得ることができる最も強力ですが単純なアイデアの1つです。
Nグラムは、文字、音節、または単語の連続したシーケンスです。 私たちの分析では、単語が測定単位になります。 n-gramは、隣接する要素が2つ(ペア)の場合はバイグラムと呼ばれ、3つの場合はトリグラムと呼ばれます。 さまざまな組み合わせでテストし、最大5グラムにすることをお勧めします。
このようにして、競合他社のページで最も一般的な文章を見つけたり、自分の文章を評価したりすることができます。 Googleはフレーズベースのインデックスに依存している可能性があるため、このトピックに関連するGoogleの特許で示されているように、個々のキーワードよりも文を最適化する方が適切です。
ビル・スラフスキー自身が上のページで述べたように、関連する用語を理解することの価値は、最適化とユーザーにとって非常に価値があります。
nltkライブラリはNLPアプリケーションで非常に有名であり、英語などの特定の言語のストップワードを削除する可能性を提供します。 それらを削除したいノイズと考えてください。実際、記事や非常に頻繁な単語は、テキストを理解する上で何の価値もありません。
nltkをインポートする
nltk.download('ストップワード')
nltk.corpusからインポートストップワード
stoplist = stopwords.words('english')
sklearn.feature_extraction.textからインポートCountVectorizer
c_vec = CountVectorizer(stop_words = stoplist、ngram_range =(2,3))
#ngramの行列
ngrams = c_vec.fit_transform(df ['query'])
#ngramの頻度を数える
count_values = ngrams.toarray()。sum(axis = 0)
#ngramのリスト
vocab = c_vec.vocabulary_
df_ngram = pd.DataFrame(sorted([(count_values [i]、k)for k、i in vocab.items()]、reverse = True)
).rename(columns = {0:'頻度'、1:'バイグラム/トリグラム'})
df_ngram.head(20).style.background_gradient()
クエリ列を取得し、バイグラムの頻度をカウントして、バイグラムとその出現回数を格納するデータフレームを作成します。
このステップは、競合他社のWebサイトを分析するためにも実際には非常に重要です。 毎回nを調整して、上位のページ全体で異なるパターンを見つけるかどうかを確認することで、テキストをスクレイプして最も一般的なn-gramを確認できます。
個々のキーワードはコンテキストについて何も教えてくれないので、少し考えてみると、はるかに理にかなっています。
ぶら下がっている果物
最も素敵なことの1つは、ぶら下がっている果物をチェックすることです。これらのページは、できるだけ早く良い結果を確認するために簡単に改善できます。 これは、すべてのSEOプロジェクトの最初のステップで、利害関係者を説得するために重要です。 したがって、そのようなページを活用する機会がある場合は、それを実行してください。
ページをそのように見なすための基準は、インプレッションとCTRの分位数です。 つまり、インプレッションの上位80%にあるが、クリック率が最も低い20%にある行をフィルタリングしています。 これらの行のクリック率は、残りの行の80%よりも悪くなります。
top_impressions = df [df ['impressions']> = df ['impressions']。quantile(0.8)] (top_impressions [top_impressions ['ctr'] <= top_impressions ['ctr']。quantile(0.2)]。sort_values('impressions'、ascending = False))
これで、すべての商談がインプレッション別に降順で並べ替えられたリストができました。
あなたのウェブサイトのニーズとそのサイズに応じて、ぶら下がっている果物が何であるかを定義するための他の基準を考えることができます。
小規模なWebサイトの場合は、より高いパーセンテージを探すことを検討できますが、大規模なWebサイトでは、私が使用している基準ですでに多くの情報を取得しているはずです。
[電子ブック]非技術的な思想家のための技術的なSEO
 電子ブックを読む
電子ブックを読むquerycatの紹介:分類と関連付け
Querycatは、キーワードをクラスタリングするための相関ルールマイニングなどを備えたシンプルで強力なライブラリです。 このタイプの分析では関連性の方が価値があるため、関連性のみを示します。
querycat GitHubリポジトリを見ると、このすばらしいライブラリについて詳しく知ることができます。
相関ルール学習についての簡単な紹介
相関ルール学習は、アイテムのセット全体での関連付けと共起を定義するルールを見つける方法です。 これは、別の教師なし機械学習方法、いわゆるクラスタリングとは少し異なります。
ただし、最終的な目標は同じですが、キーワードのクラスターを取得して、一部のトピックについて当社のWebサイトがどのように機能しているかを理解します。
Querycatは、AprioriとFP-Growthの2つのアルゴリズムから選択する可能性を提供します。 パフォーマンスを向上させるために後者を選択するので、前者は無視してかまいません。
FP-Growthは、データセット内の頻繁なパターンを見つけるためのAprioriの改良版です。 相関ルールの学習は、eコマーストランザクションにも非常に役立ちます。たとえば、人々が一緒に何を購入するかを理解することに興味があるかもしれません。
この場合、私たちの焦点はすべてクエリにありますが、私が言及した他のアプリケーションは、GoogleAnalyticsデータのもう1つの有用なアイデアになる可能性があります。
データ構造の観点からこれらのアルゴリズムを説明することは非常に困難であり、私の意見ではSEOタスクには必要ありません。 パラメータの意味を理解するために、いくつかの基本的な概念を説明します。
2つのアルゴリズムの3つの主要な要素は次のとおりです。
- サポート–アイテムまたはアイテムセットの人気を表します。 技術的には、クエリXとクエリYが一緒に表示されるトランザクションの数をトランザクションの総数で割ったものです。
さらに、まれなアイテムを削除するためのしきい値として使用できます。 統計的有意性とパフォーマンスを向上させるのに非常に役立ちます。 適切な最小サポートを設定することは非常に良いことです。 - 信頼度–用語の共起の確率と考えることができます。
- リフト–(用語1と用語2)のサポートと用語1のサポートの比率。その値を調べて、用語間の関係についての洞察を得ることができます。 1より大きい場合、用語は相関しています。 1未満の場合、用語に関連付けがない可能性があります。リフトが正確に1(または近い)の場合、有意な関係はありません。
ライブラリの作成者によって作成されたquerycatに関する詳細は、この記事に記載されています。
これで、実用的な部分に進む準備ができました。
querycatをインポートする query_cat = querycat.Categorize(df、'query'、min_support = 10、alg ='fpgrowth') dfgrouped = df.groupby('category')。agg(sumclicks =('clicks'、'sum'))。sort_values('sumclicks'、ascending = False) #15回未満のクリックでカテゴリをフィルタリングするグループを作成(任意の数) filtergroup = dfgrouped [dfgrouped ['sumclicks']> 15] フィルタグループ #apply filter df = df.merge(filtergroup、on = ['category'、'category']、how ='inner')
その過程で頻度の低いカテゴリをフィルタリングしました。私の場合、ベンチマークとして15を選択しました。 これは単なる任意の数であり、その背後に基準はありません。
次のスニペットでカテゴリを確認しましょう。
df ['category']。value_counts()
最もクリックされた10のカテゴリはどうですか? それぞれについてクエリがいくつあるかを確認しましょう。
df.groupby('category')。sum()['clicks']。sort_values(ascending = False).head(10)
選択する数は任意です。グループのかなりの割合を除外するものを必ず選択してください。 考えられるアイデアの1つは、小グループを除外する場合に、インプレッションの中央値を取得し、最低50%を下げることです。
クラスターの取得と出力の処理
FP-Growthが再度実行されないように、新しいデータフレームをエクスポートすることをお勧めします。時間を節約するためにエクスポートしてください。
クラスターができたらすぐに、どの領域で最も改善が必要かを評価するために、各クラスターのクリック数とインプレッション数を知りたいと思います。
grouped_df = df.groupby('category')[['clicks'、'impressions']]。agg('sum')
いくつかのデータ操作により、関連付けの結果を改善し、クラスターごとにクリック数とインプレッション数を増やすことができます。
group_ex = df.groupby(['category'])['query']。apply('|' .join).reset_index() #重複するクエリを削除してから、アルファベット順に並べ替えます group_ex ['query'] = group_ex ['query']。apply(lambda x:'|' .join(sorted(list(set(x.split('|')))))) df_final = group_ex.merge(grouped_df、on = ['category'、'category']、how ='inner') df_final.head()
これで、クリック数と表示回数に加えて、すべてのキーワードクラスターを含むCSVファイルが作成されました。
#csvファイルを保存し、ローカルマシンにダウンロードします。 Safariを使用している場合は、動作しない可能性があるため、これらのファイルをダウンロードするためにChromeに切り替えることを検討してください。 df_final.to_csv('clusters_queries.csv') files.download('clusters_queries.csv')
実際、クラスタリングにはより良い方法があります。これは、querycatを使用して複数のタスクを実行してすぐに使用する方法の例にすぎません。 ここでの主な目標は、特に知識があまりない新しいWebサイトについて、できるだけ多くの洞察を得ることです。
現在、最良のアプローチにはセマンティクスが含まれているため、クラスタリングに焦点を当てたい場合は、グラフまたは埋め込みの学習を検討することをお勧めします。
ただし、初心者の場合、これらは高度なトピックであり、オンラインで利用できるビルド済みのStreamlitアプリを簡単に試すことができます。
オンクロールデータ³
 もっと詳しく知る
もっと詳しく知る結論と次のこと
Pythonは、Webサイトの分析に大きな助けを提供し、データクリーニング、視覚化、分析を1か所にまとめるのに役立ちます。 GSC APIからデータを抽出することは、より高度なタスクには間違いなく必要であり、データ自動化の「穏やかな」入門書です。
Pythonを使用すると、より高度な計算を行うことができますが、SEO値の観点から何が理にかなっているのかを確認することをお勧めします。
たとえば、Webサイトでより多くのクエリを検討する必要があるため、長期的にはクエリ数が全体としてはるかに重要になります。
ノートブックを使用することは、コメント付きのコードをパックするための大きな助けになります。これが、GoogleColabに慣れることをお勧めする主な理由です。
最良のアイデアはさまざまなデータセットをマージすることから得られるため、これはデータ分析が提供できるもののほんの始まりにすぎません。
Google Search Consoleはそれ自体が強力なツールであり、完全に無料です。そこから取得できる実用的な情報の量は、手元にある限りほぼ無制限です。