
A / Bテストの統計的有意性:テストを終了する方法と時期
公開: 2020-05-22
Convertの顧客が実行した28,304の実験の最近の分析では、実験の20%のみが95%の統計的有意水準に達していることがわかりました。 Econsultancyは、2018年の最適化レポートで同様の傾向を発見しました。 回答者の3分の2は、実験の30%以下で「明確で統計的に有意な勝者」と見なしています。
したがって、ほとんどの実験(70〜80%)は決定的ではないか、早期に停止されます。
これらのうち、早期に停止したものは、オプティマイザーが適切と見なしたときに実験を終了するように呼びかけるため、奇妙なケースになります。 彼らは、明確な勝者(または敗者)または明らかに取るに足らないテストを「見る」ことができるときにそうします。 通常、彼らはそれを正当化するためのいくつかのデータも持っています。
オプティマイザーの50%が実験の標準的な「停止点」を持っていないことを考えると、これはそれほど驚くべきことではないかもしれません。 ほとんどの場合、特定のテスト速度(XXXテスト/月)を維持する必要があるというプレッシャーと、競争を支配するための競争のおかげで、そうすることが必要です。
次に、否定的な実験が収益を損なう可能性もあります。 私たち自身の調査によると、勝てない実験では、平均してコンバージョン率が26%低下する可能性があります。
とにかく、実験を早期に終了することはまだ危険です…
…適切なサンプルサイズを使用して、実験が意図した長さで実行された可能性が残るため、結果は異なる可能性があります。
では、実験を早期に終了するチームは、実験を終了する時期をどのようにして知るのでしょうか。 ほとんどの場合、その答えは、品質を損なうことなく、意思決定をスピードアップする停止ルールを考案することにあります。
従来の停止ルールからの脱却
Web実験の場合、0.05のp値が標準として機能します。 この5%の許容誤差または95%の統計的有意水準は、オプティマイザーがテストの整合性を維持するのに役立ちます。 彼らは、結果が実際の結果であり、まぐれではないことを保証できます。
固定期間テストの従来の統計モデル(テストデータが固定時間または特定のエンゲージメントユーザー数で1回だけ評価される)では、p値が0.05未満の場合、結果を有意なものとして受け入れます。 この時点で、対照群と治療法は同じであり、観察された結果は偶然ではないという帰無仮説を棄却することができます。
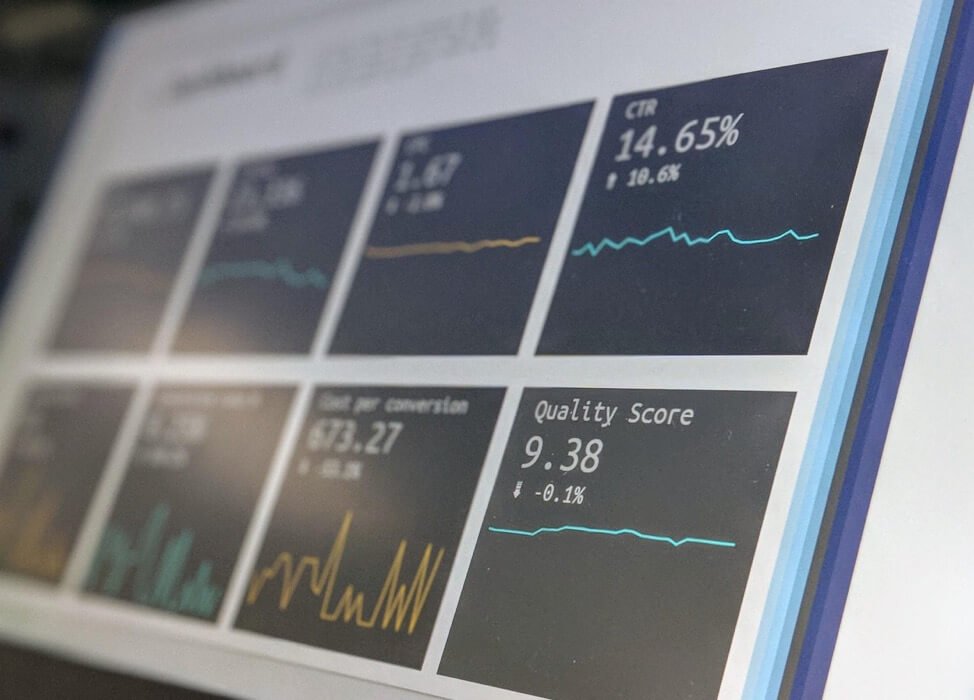
収集されているデータを評価するためのプロビジョニングを提供する統計モデルとは異なり、このようなテストモデルでは、実行中に実験のデータを確認することはできません。 このようなモデルでは、p値がほぼ毎日変動するため、この方法(ピークとも呼ばれます)は推奨されません。 ある日は実験が有意であり、翌日はそのp値が有意ではなくなるまで上昇することがわかります。
100回(20日)の実験でプロットされたp値のシミュレーション。 20日目で実際に重要になる実験は5つだけですが、その間に多くの実験が0.05未満のカットオフに達することもあります。
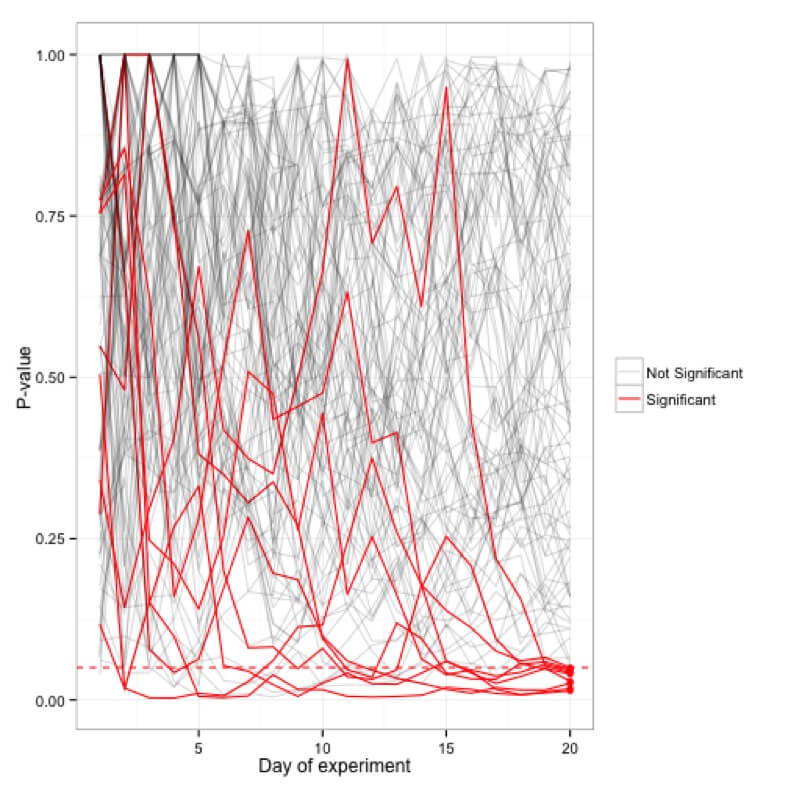
暫定的に実験を覗いてみると、存在しない結果が表示される可能性があります。 たとえば、以下では、有意水準0.1を使用したA/Aテストがあります。 A / Aテストなので、コントロールと治療の間に違いはありません。 ただし、進行中の実験中に500回の観測を行った後、50%以上の確率で、それらが異なり、帰無仮説を棄却できると結論付けることができます。
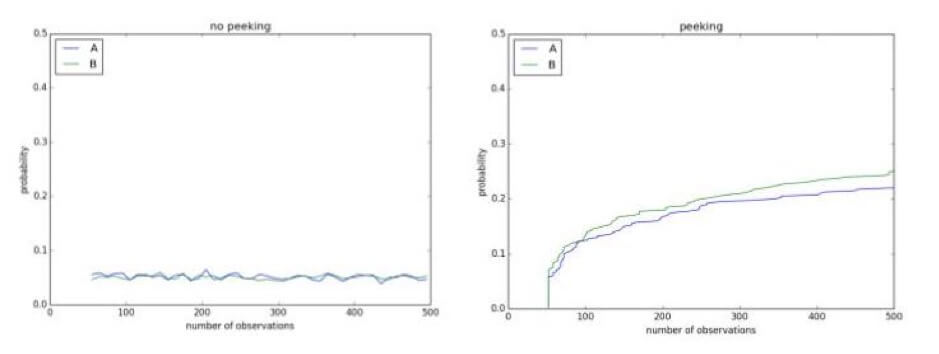
これは、30日間のA / Aテストのもう1つです。このテストでは、p値が暫定的に重要ゾーンに複数回ディップし、最終的にカットオフをはるかに超えます。
固定期間の実験からp値を正しく報告するということは、固定のサンプルサイズまたはテスト期間に事前にコミットする必要があることを意味します。 一部のチームは、この実験の停止基準と意図された長さに一定数のコンバージョンを追加します。
ただし、ここでの問題は、この標準的な方法を使用して最適停止するためにすべての実験に燃料を供給するのに十分なテストトラフィックを確保することは、ほとんどのWebサイトでは難しいことです。
ここで、オプションの停止ルールをサポートする順次テスト方法を使用すると役立ちます。
より迅速な決定を可能にする柔軟な停止ルールへの移行
シーケンシャルテスト方法では、表示されたとおりに実験データを利用し、独自の統計的有意性モデルを使用して、柔軟な停止ルールを使用して勝者をより早く見つけることができます。
最高レベルのCRO成熟度の最適化チームは、多くの場合、そのようなテストをサポートするために独自の統計手法を考案します。 一部のA/Bテストツールにもこれが組み込まれており、バージョンが勝っているように見えるかどうかを示唆する可能性があります。 また、カスタム値などを使用して、統計的有意性の計算方法を完全に制御できるものもあります。 そのため、進行中の実験でも勝者をのぞき見することができます。

A / Bテスト統計に関する人気のあるCXLコースの統計家、著者、およびインストラクターであるGeorgi Georgievは、中間分析の数とタイミングに柔軟性を持たせることができるような逐次テスト方法にすべて対応しています。
「シーケンシャルテストでは、勝者のバリアントを早期に展開することで利益を最大化するだけでなく、勝者を生み出す可能性がほとんどないテストをできるだけ早く停止することができます。 後者は、劣ったバリアントによる損失を最小限に抑え、バリアントがコントロールを上回る可能性が低い場合のテストを高速化します。 統計的に厳密性はすべての場合に維持されます。 」
Georgievは、実験の実行中に勝者を検出できるモデルの固定サンプルテストモデルをチームが捨てるのに役立つ計算機にも取り組んできました。 彼のモデルは多くの統計を考慮に入れており、品質を犠牲にすることなく、標準の統計的有意性の計算よりも約20〜80%速くテストを呼び出すのに役立ちます。
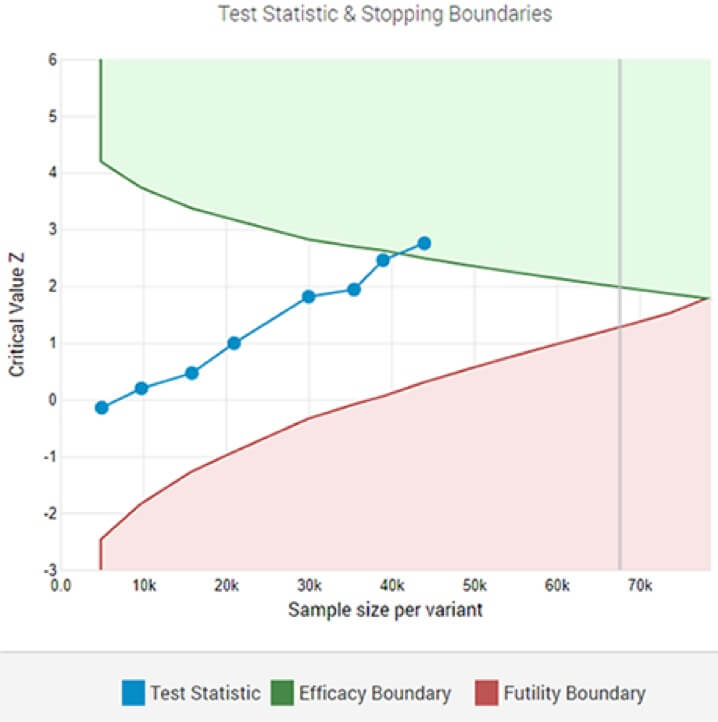
8回目の中間分析後、指定された有意水準で統計的に有意な勝者を示す適応A/Bテスト。
このようなテストは意思決定プロセスを加速する可能性がありますが、対処する必要のある重要な側面が1つあります。それは、実験の実際の影響です。 途中で実験を終了すると、過大評価する可能性があります。
効果量の未調整の推定値を見るのは危険な場合がある、とゲオルギエフは警告します。 これを回避するために、彼のモデルは、中間監視によって発生したバイアスを考慮に入れた調整を適用する方法を使用しています。 彼は、彼らのアジャイル分析が「停止段階と統計の観測値(もしあればオーバーシュート)に応じて」推定をどのように調整するかを説明します。 以下に、上記のテストの分析を示します:(推定リフトが観測値よりも低く、間隔がその中心にないことに注意してください)。
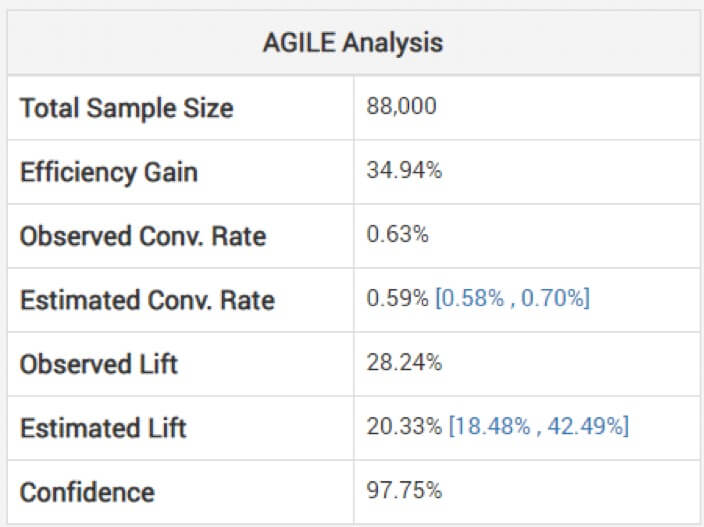
したがって、意図したよりも短い実験に基づいた場合、勝利は見た目ほど大きくない可能性があります。
誤って勝者に電話をかけるのが早すぎる可能性があるため、損失も考慮する必要があります。 ただし、このリスクは、固定期間のテストでも存在します。 ただし、外部の妥当性は、長時間実行される固定ホライズンテストと比較して、実験を早期に呼び出す場合に大きな懸念事項になる可能性があります。 しかし、これは、Georgievが説明しているように、「サンプルサイズが小さく、したがってテスト期間が短いという単純な結果です。 「「
結局のところ…それは勝者や敗者についてではありません…
…しかし、Chris Stucchioが言うように、より良いビジネス上の意思決定についてです。
または、トム・レッドマン(データドリブンの著者:最も重要なビジネス資産からの利益)がビジネスにおいて次のように主張しているように、「統計的有意性よりも重要な基準がしばしばあります。 重要な質問は、「結果は、短期間だけでも、市場で立ち上がるのでしょうか? 」」
そして、それはおそらく、短期間ではなく、「統計的に有意であり、外部の妥当性の考慮事項が設計段階で満足のいく方法で対処された場合」とGeorgiev氏は述べています。
実験の本質は、チームがより多くの情報に基づいた決定を下せるようにすることです。 では、実験のデータが示す結果をもっと早く渡すことができれば、それではどうでしょうか。
これは、実際には「十分な」サンプルサイズを取得できない小さなUI実験である可能性があります。 それはまた、あなたの挑戦者がオリジナルを粉砕し、あなたがその賭けをすることができる実験かもしれません!
ジェフ・ベゾスがアマゾンの株主に宛てた手紙の中で書いているように、大きな実験は大きな時間を費やします。
「 100倍のペイオフの10%の確率を考えると、毎回その賭けをする必要があります。 しかし、あなたはまだ10回のうち9回間違っているでしょう。 柵に向かってスイングすると、三振が多くなることは誰もが知っていますが、ホームランも打つことになります。 ただし、野球とビジネスの違いは、野球の結果の分布が切り捨てられていることです。 あなたがスイングするとき、あなたがボールとどれだけうまく接続しても、あなたが得ることができる最も多くのランは4つです。 ビジネスでは、たまにプレートにステップアップすると、1,000ランを獲得できます。 このロングテールのリターンの分布が、大胆であることが重要である理由です。 大きな勝者は非常に多くの実験にお金を払います。 「「
実験を早期に呼び出すことは、かなりの程度、結果を毎日覗き見し、良い賭けを保証するポイントで停止するようなものです。

