
ディープ ラーニングと機械学習の違い – 違いを見分ける方法は?
公開: 2020-03-10近年、機械学習、深層学習、人工知能がバズワードになっています。 その結果、ますます多くの企業のマーケティング資料や広告でそれらを見つけることができます。
しかし、機械学習と深層学習とは何ですか? また、それらの違いは何ですか? この記事では、これらの質問に答え、深層学習と機械学習のアプリケーションのいくつかのケースを紹介します。
機械学習とは
機械学習は、データに基づいて数学モデルを使用して現実世界のイベントやオブジェクトを表現することを扱うコンピューター サイエンスの一部です。 これらのモデルは、トレーニング データに適合するようにモデルの一般的な構造を適応させる特別なアルゴリズムで構築されています。 解決する問題の種類に応じて、教師ありおよび教師なしの機械学習および機械学習アルゴリズムを定義します。
教師ありと教師なしの機械学習
教師あり機械学習は、手元のデータについて既に持っている知識を新しいデータに移すことができるモデルの作成に焦点を当てています。 新しいデータは、トレーニング フェーズ中のモデル構築 (トレーニング) アルゴリズムには表示されません。 特徴のデータと、アルゴリズムがそれらから推測するために学習する必要がある対応する値 (いわゆるターゲット変数) をアルゴリズムに提供します。
教師なし機械学習では、アルゴリズムに機能のみを提供します。 これにより、構造や依存関係を独自に把握できます。 明確なターゲット変数が指定されていません。 教師なし学習の概念は、最初は理解しにくいかもしれませんが、以下の 4 つのグラフに示されている例を見ると、この考えが明確になるはずです。
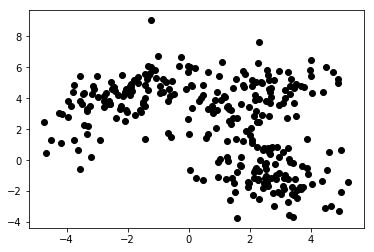
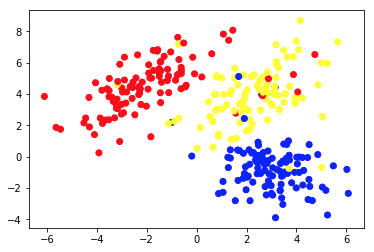
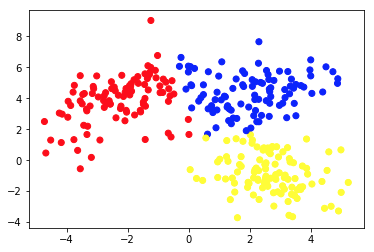

チャート 1a は、軸xおよびy上の 2 つの特徴で記述されたいくつかのデータを示しています。 1b としてマークされているものは、同じデータを色付けして示しています。 K-meansクラスタリング アルゴリズムを使用して、これらのポイントを 3 つのクラスターにグループ化し、それに応じて色を付けました。 これは、教師なし機械学習アルゴリズムの例です。 アルゴリズムには特徴のみが与えられ、ラベル (クラスター番号) が計算されました。
2 番目の図は、ラベル付けされた (それに応じて色が付けられた) データの別のセットを示すグラフ 2a を示しています。 各データポイントがアプリオリに属しているグループを知っています。 SVMアルゴリズムを使用して、これらのグループに最適にデータ ポイントを分割する方法を示す 2 つの直線を見つけます。 この分割は完璧ではありませんが、直線でできる最高の分割です。 グループを新しいラベルのないデータ ポイントに割り当てたい場合は、それが平面上のどこにあるかを確認するだけで済みます。 これは、教師あり機械学習アプリケーションの例です。
機械学習モデルの応用
表形式のデータを処理するために、標準の機械学習アルゴリズムが作成されます。 これは、それらを使用するために何らかのテーブルが必要であることを意味します。 このようなテーブルの行は、モデル化されたオブジェクト (ローンなど) のインスタンスと考えることができます。 同時に、列は、この特定のインスタンスの特徴 (特性) と見なす必要があります (たとえば、ローンの毎月の支払い、借り手の毎月の収入)。

機械学習の開発に興味がありますか?
もっと詳しく知る表 1 は、そのようなデータの非常に短い例です。 もちろん、純粋なデータ自体が表形式で構造化されていなければならないという意味ではありません。 しかし、あるデータセットに標準の機械学習アルゴリズムを適用したい場合は、通常、それをきれいにし、混合し、テーブルに変換する必要があります。 教師あり学習では、目標値 (ローンが債務不履行になった場合の情報など) を含む特別な列も 1 つあります。
トレーニング アルゴリズムは、モデルの一般的な構造をこれらのデータに適合させようとします。 このアルゴリズムは、モデルのパラメーターを微調整することによってそれを行います。 これにより、指定されたデータとターゲット変数の間の関係を可能な限り正確に記述するモデルが得られます。
モデルが与えられたトレーニング データにうまく適合するだけでなく、一般化できることも重要です。 一般化とは、モデルを使用して、トレーニング中に使用されないインスタンスのターゲットを推測できることを意味します。 これは、有用なモデルの重要な機能でもあります。 十分に一般化されたモデルを構築するのは簡単なことではありません。 多くの場合、高度な検証手法と徹底的なモデル テストが必要になります。
| ローン_id | 借り手_年齢 | 収入_月額 | ローン金額 | 毎月の支払額 | デフォルト |
| 1 | 34 | 10,000 | 100,000 | 1,200 | 0 |
| 2 | 43 | 5,700 | 25,000 | 800 | 0 |
| 3 | 25 | 2,500 | 24,000 | 400 | 0 |
| 4 | 67 | 4,600 | 40,000 | 2,000 | 1 |
| 5 | 38 | 35,000 | 2,500,000 | 10,000 | 0 |
表 1. 表形式のローン データ
人々はさまざまなアプリケーションで機械学習アルゴリズムを使用しています。 表 2. ディープではない機械学習アルゴリズムとモデル アプライアンスを可能にするいくつかのビジネス ユース ケースを示します。 潜在的なデータ、ターゲット変数、および選択された適用可能なアルゴリズムの簡単な説明もあります。
| 使用事例 | データ例 | 目標 (モデル化) 値 | 使用アルゴリズム/モデル |
| ブログサイトの記事のおすすめ | ユーザーが読んだ記事のID、記事ごとの滞在時間 | 記事に対するユーザーの好み | 最小二乗法を交互に使用する協調フィルタリング |
| 住宅ローンのクレジットスコアリング | 潜在的な借り手の取引および与信履歴、収入データ | ローンが全額返済されるか、債務不履行になるかを示すバイナリ値 | ライトGBM |
| モバイル ゲームのプレミアム ユーザーの離脱を予測する | 毎日のプレイ時間、初回起動からの時間、ゲームの進行状況 | ユーザーが来月サブスクリプションをキャンセルするかどうかを示すバイナリ値 | XGBoost |
| クレジットカード詐欺の検出 | 過去のクレジット カード取引データ – 金額、場所、日時 | クレジットカード取引が不正かどうかを示すバイナリ値 | ランダムフォレスト |
| インターネット ストアの顧客のセグメンテーション | ポイントプログラム会員の購入履歴 | 顧客ごとに割り当てられたセグメント番号 | K平均法 |
| マシンパークの予知保全 | 性能、温度、湿度などのセンサーからのデータ | 次のいずれかのクラス – 「良い」、「観察する」、「メンテナンスが必要」 | 決定木 |
表 2. 機械学習のユース ケースの例
ディープ ラーニングとディープ ニューラル ネットワーク
ディープ ラーニングは、深層人工ニューラル ネットワーク (ANN) と呼ばれる特定のタイプのモデルを使用する機械学習の一部です。 導入以来、人工ニューラル ネットワークは広範な進化プロセスを経てきました。 その結果、多くのサブタイプが生まれ、そのうちのいくつかは非常に複雑です。 しかし、それらを紹介するには、基本的な形式の 1 つである多層パーセプトロン (MPL) について説明するのが最善です。
多層パーセプトロン
簡単に言えば、MLP は頂点 (ニューロンとも呼ばれる) とエッジ (重みと呼ばれる数値で表される) のグラフ (ネットワーク) の形式を持っています。 ニューロンは層状に配置されており、連続する層のニューロンは互いに接続されています。 データは入力層から出力層までネットワークを流れます。 次に、データはニューロンとそれらの間のエッジで変換されます。 データ ポイントがネットワーク全体を通過すると、出力層のニューロンに予測値が含まれます。
トレーニング データのチャンクがネットワークを通過するたびに、予測を対応する真の値と比較します。 これにより、モデルのパラメーター (重み) を調整して、予測を改善できます。 バックプロパゲーションと呼ばれるアルゴリズムでそれを行うことができます。 何度か反復した後、目前の機械学習の問題に取り組むためにモデルの構造が適切に設計されているかどうか。
高精度モデルの取得
十分なデータがネットワークを複数回通過すると、高精度のモデルが得られます。 実際には、ニューロンに適用できる変換はたくさんあります。 これにより、ANN は非常に柔軟で強力になります。 ただし、ANN の威力には代償が伴います。 通常、モデルの構造が複雑になるほど、モデルを高精度にトレーニングするには、より多くのデータと時間が必要になります。
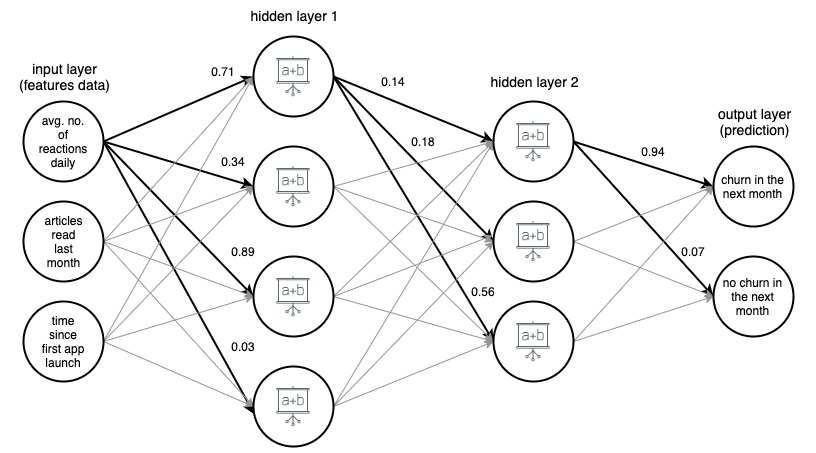
画像 1. (draw.io) 4 層の人工ニューラル ネットワークの構造。ニュース アプリのユーザーが来月解約するかどうかを、3 つの単純な機能に基づいて予測します。
わかりやすくするために、重みは選択された (太字の) エッジのみにマークされていますが、すべてのエッジには独自の重みがあります。 データは入力層から出力層に流れ、中間の 2 つの隠れ層を通過します。 各エッジで、入力値にエッジの重みが乗算され、結果の積がエッジの終了ノードに送られます。 次に、隠れ層の各ノードで、エッジからの入力信号が合計され、何らかの関数で変換されます。 これらの変換の結果は、次の層への入力として扱われます。
出力層では、受信データが再度合計されて変換され、2 つの数値の形式で結果が得られます。つまり、ユーザーが翌月にアプリを離れてしまう確率と、離れない確率です。
高度なタイプのニューラル ネットワーク
より高度なタイプのニューラル ネットワークでは、レイヤーの構造がはるかに複雑になります。 それらは、MLP で知られている 1 つの操作のニューロンを含む単純な高密度層だけでなく、畳み込み層や再帰層などのはるかに複雑な複数操作の層で構成されています。
畳み込み層と再帰層
畳み込み層は主にコンピューター ビジョンアプリケーションで使用されます。 それらは、画像のピクセル表現上をスライドする数値の小さな配列で構成されています。 ピクセル値はこれらの数値で乗算されてから集計され、新しい圧縮された画像の表現が生成されます。
再帰レイヤーは、時系列やテキストなどの順序付けられたシーケンシャル データをモデル化するために使用されます。 これらは、非常に複雑な複数引数の変換を受信データに適用し、シーケンス項目間の依存関係を把握しようとします。 それにもかかわらず、ネットワークのタイプと構造に関係なく、常にいくつか (1 つ以上) の入力層と出力層があり、データがネットワークを流れるパスと方向が厳密に定義されています。
一般に、ディープ ニューラル ネットワークは複数のレイヤーを持つ ANN です。 以下の画像 1、2、および 3 は、選択された深層人工ニューラル ネットワークのアーキテクチャを示しています。 それらはすべて Google で開発およびトレーニングされ、一般に公開されています。 それらは、今日使用されている高精度の深層人工ネットワークがどれほど複雑であるかについてのアイデアを与えてくれます。

これらのネットワークは巨大なサイズを持っています。 たとえば、画像 3 に部分的に示されているように、InceptionResNetV2 には 572 のレイヤーがあり、合計で 5500 万以上のパラメーターがあります。 それらはすべて画像分類モデルとして開発され (特定の画像に「車」などのラベルを割り当てます)、1,400 万を超えるラベル付き画像で構成される ImageNet セットの画像でトレーニングされています。
図 2. NASNetMobile の構造 (keras パッケージ)

図 3. XCeption の構造 (keras パッケージ)

図 4. InceptionResNetV2 (keras パッケージ) の一部 (約 25%) の構造
近年、深層学習とその応用の大きな発展が見られます。 スマートフォンやアプリケーションの「スマート」機能の多くは、この進歩の成果です。 ANN のアイデアは新しいものではありませんが、この最近のブームはいくつかの条件を満たした結果です。 まず、GPU コンピューティングの可能性を発見しました。 グラフィカル プロセッシング ユニットのアーキテクチャは、並列計算に最適で、効率的なディープ ラーニングに非常に役立ちます。
さらに、クラウド コンピューティング サービスの台頭により、高効率のハードウェアへのアクセスがはるかに簡単かつ安価になり、はるかに大規模に利用できるようになりました。 最後に、最新のモバイル デバイスの計算能力は、ディープ ラーニング モデルを適用するのに十分な大きさであり、DNN 主導の機能の潜在的なユーザーの巨大な市場を生み出しています。
深層学習モデルの応用
ディープ ラーニング モデルは通常、画像分類や言語翻訳など、単純な行と列の構造を持たないデータを扱う問題に適用されます。これは、これらのタスクで処理される構造化されていない複雑な構造のデータ (画像、テキスト) の操作に優れているためです。 、および音。 従来の機械学習アルゴリズムでこれらのタイプとサイズのデータを処理するには問題があり、いくつかのディープ ニューラル ネットワークを作成してこれらの問題に適用することで、画像認識、音声認識、テキスト分類、および言語翻訳の分野で大きな発展がもたらされました。ここ数年。
これらの問題への深層学習の適用が可能になったのは、DNN が入力と出力の両方としてテンソルと呼ばれる数値の多次元テーブルを受け入れ、要素間の空間的および時間的関係を追跡できるためです。 たとえば、画像を 3 次元テンソルとして表すことができます。ここで、次元 1 と 2 はデジタル画像の解像度を表し (それぞれ画像の幅と高さのサイズを持っています)、3 番目の次元は RGB カラーを表します。各ピクセルのコーディング (したがって、3 番目の次元はサイズ 3 です)。
これにより、画像に関するすべての情報をテンソルで表すだけでなく、ピクセル間の空間関係を維持することもできます。これは、いわゆる畳み込み層の適用において重要であることが判明し、画像分類および認識ネットワークの成功に不可欠です。
入力構造と出力構造におけるニューラル ネットワークの柔軟性は、言語翻訳などの他のタスクにも役立ちます。 テキスト データを処理する場合、ディープ ニューラル ネットワークに、テキスト内での出現順に並べられた単語の数値表現を入力します。 各単語は、異なる単語に対応するベクトル間の関係が単語自体の関係を模倣するように (通常は別のニューラル ネットワークを使用して) 計算された 100 または数百の数値のベクトルで表されます。 埋め込みと呼ばれるこれらのベクトル言語表現は、一度トレーニングされると、多くのアーキテクチャで再利用でき、ニューラル ネットワーク言語モデルの中心的なビルディング ブロックです。
ディープ ラーニング モデルの使用例
表 3. には、深層学習モデルを実際の問題に適用する例が含まれています。 ご覧のとおり、ディープ ラーニング アルゴリズムによって対処および解決される問題は、表 1 に示されているような標準の機械学習手法によって解決されるタスクよりもはるかに複雑です。
とはいえ、今日のビジネスで機械学習が役立つユースケースの多くは、そのような洗練された方法を必要とせず、標準モデルによってより効率的に (そしてより高い精度で) 解決できることを覚えておくことが重要です。 表 3. は、人工ニューラル ネットワーク層の種類と、それらを使用して構築できるさまざまな有用なアーキテクチャの数についてのアイデアも示しています。
| 使用事例 | データ | モデルの目標/結果 | 使用アルゴリズム/モデル |
| 画像分類 | 画像 | 画像に割り当てられたラベル | 畳み込みニューラル ネットワーク (CNN) |
| 自動運転車による画像検出 | 画像 | 画像上で識別されたオブジェクトのラベルと境界ボックス | 高速 R-CNN |
| 感情 の分析 オンラインストアのコメント | オンライン コメントのテキスト | 各コメントに割り当てられた感情ラベル (ポジティブ、ニュートラル、ネガティブなど) | 双方向長短期記憶 (LSTM) ネットワーク |
| メロディーのハーモナイゼーション | メロディー付きのMIDIファイル | このメロディーをハーモニーにしたMIDIファイル | 敵対的生成ネットワーク |
| 次の単語の予測 で オンライン Eメール 編集者 | 非常に大きなテキストの塊 (例: ウィキペディアのすべての記事の英語版のダンプ) | 今まで書いた文章の次に当てはまる言葉 | 埋め込みレイヤーを使用したリカレント ニューラル ネットワーク (RNN) |
| 別の言語へのテキスト翻訳 | ポーランド語のテキスト | 同じテキストを英語に翻訳 | エンコーダ – 再帰型ニューラル ネットワーク (RNN) 層で構築されたデコーダ ネットワーク |
| モネのスタイルをあらゆる画像に転写 | モネの絵画の画像のセット、およびその他の画像のセット | モネが描いたように見えるように修正された画像 | 敵対的生成ネットワーク |
表 3. 深層学習のユース ケースの例
ディープ ラーニング モデルの利点
敵対的生成ネットワーク
ディープ ニューラル ネットワークの最も印象的なアプリケーションの 1 つは、Generative Adversarial Networks (GAN) の台頭に伴います。 それらは 2014 年に Ian Goodfellow によって導入され、彼のアイデアはその後多くのツールに組み込まれ、驚くべき結果をもたらしたものもあります。
GAN は、写真で私たちを老けさせたり、ゴッホが描いたかのように画像を変換したり、複数の楽器バンドのメロディーを調和させたりするアプリケーションの存在に関与しています。 GAN のトレーニング中に、2 つのニューラル ネットワークが競合します。 ジェネレーター ネットワークはランダムな入力から出力を生成しますが、ディスクリミネーターは生成されたインスタンスと実際のインスタンスを区別しようとします。 トレーニング中に、ジェネレーターはディスクリミネーターをうまく「だます」方法を学習し、最終的には本物であるかのように見える出力を作成することができます。
モバイル アプリの強力なディープ ニューラル ネットワーク
ディープ ニューラル ネットワークのトレーニングは計算コストが非常に高く、長時間かかる可能性がありますが、特定のタスクを実行するためにトレーニング済みネットワークを適用する必要はありません。一度にいくつかのケース。 実際、今日ではスマートフォンのモバイル アプリケーションで強力なディープ ニューラル ネットワークを実行できます。
モバイル デバイスに適用した場合に効率的になるように特別に設計されたネットワーク アーキテクチャもあります (たとえば、図 1 に示す NASNetMobile など)。 最先端のネットワークに比べてサイズがはるかに小さいにもかかわらず、高精度の予測性能を得ることができます。
転移学習
ディープ ラーニング モデルの幅広い使用を可能にする、人工ニューラル ネットワークのもう 1 つの非常に強力な機能は、転移学習です。 一部のデータ (自分で作成したもの、またはパブリック リポジトリからダウンロードしたもの) でモデルをトレーニングしたら、そのすべてまたは一部を基に構築して、特定のユース ケースを解決するモデルを取得できます。 たとえば、巨大な ImageNet データセットでトレーニングされた、事前トレーニング済みの NASNetLarge モデルを使用して、画像にラベルを割り当て、その構造の上にいくつかの小さな変更を加え、ラベル付き画像の新しいセットでさらにトレーニングし、これを使用して、特定のタイプのオブジェクトにラベルを付けます (たとえば、葉のイメージに基づいた木の種類)。
転移学習の特典
通常、実用的で有用なタスクを実行するディープ ニューラル ネットワークをトレーニングするには、膨大な量のデータと膨大な計算能力が必要になるため、転移学習は非常に便利です。 これは多くの場合、数百万のラベル付きデータ インスタンスと、数週間実行される数百のグラフィックス プロセッシング ユニット (GPU) を意味します。
誰もがそのようなアセットを購入できるわけではなく、アクセスできるわけでもありません。そのため、たとえば画像分類用に高精度のカスタム ソリューションをゼロから構築することは非常に困難です。 幸いなことに、一部の事前トレーニング済みモデル (特に、画像分類用のネットワークと言語モデル用の事前トレーニング済み埋め込み行列) はオープンソース化されており、簡単に適用できる形式で無料で利用できます (たとえば、Keras のモデル インスタンス、ニューラルネットワーク API)。
アプリケーションに適した機械学習モデルを選択して構築する方法
ビジネス上の問題を解決するために機械学習を適用する場合、おそらくモデルのタイプをすぐに決定する必要はありません。 通常、テストできるアプローチはいくつかあります。 最初は最も複雑なモデルから始めたいと思うことがよくありますが、単純なものから始めて、適用するモデルの複雑さを徐々に増やしていく価値があります。 通常、単純なモデルは、セットアップ、計算時間、およびリソースの点で安価です。 さらに、その結果は、より高度なアプローチを評価するための優れたベンチマークです。
このようなベンチマークがあると、データ サイエンティストは、モデルを開発する方向が正しいかどうかを評価するのに役立ちます。 別の利点は、以前に構築されたモデルの一部を再利用し、それらを新しいモデルとマージして、いわゆるアンサンブル モデルを作成できることです。 異なるタイプのモデルを混合すると、各モデルを組み合わせた場合よりも高いパフォーマンス メトリックが得られることがよくあります。 また、転移学習を介してビジネス ケースに使用および適応できる事前トレーニング済みのモデルがあるかどうかを確認します。
より実用的なヒント
何よりもまず、使用するモデルが何であれ、データが適切に処理されていることを確認してください。 「ガベージ イン、ガベージ アウト」のルールに注意してください。 モデルに提供されたトレーニング データの品質が低いか、適切にラベル付けおよびクリーニングされていない場合、結果のモデルもパフォーマンスが低下する可能性が非常に高くなります。 また、モデルがどのような複雑さであっても、モデリング フェーズで広範囲に検証され、最終的には目に見えないデータにうまく一般化されるかどうかをテストする必要があります。
より実際的な注意として、作成されたソリューションが利用可能なインフラストラクチャで本番環境に実装できることを確認してください。 また、ビジネスが将来的にモデルを改善するために使用できるデータをさらに収集できる場合は、簡単に更新できるように再トレーニング パイプラインを準備する必要があります。 このようなパイプラインは、定義済みの時間間隔でモデルを自動的に再トレーニングするように設定することもできます。
最終的な考え
ビジネス環境は非常に動的であるため、本番環境への展開後にモデルのパフォーマンスと使いやすさを追跡することを忘れないでください。 データ内の一部の関係は時間の経過とともに変化する可能性があり、新しい現象が発生する可能性があります。 したがって、それらはモデルの効率を変える可能性があるため、適切に処理する必要があります。 さらに、新しい強力なタイプのモデルを発明することができます。 一方で、それらはソリューションを比較的弱くする可能性がありますが、他方では、ビジネスをさらに改善し、最新のテクノロジーを活用する機会を与えてくれます。
さらに、機械学習モデルと深層学習モデルは、ビジネスとアプリケーション向けの強力なツールを構築し、顧客に優れたエクスペリエンスを提供するのに役立ちます。 これらの「スマートな」機能を作成するにはかなりの労力が必要ですが、潜在的なメリットはそれだけの価値があります。 あなたとデータ サイエンス チームが適切なモデルを試し、優れたプラクティスに従っていることを確認してください。そうすれば、最先端の機械学習ソリューションを使用してビジネスとアプリケーションを強化するための正しい軌道に乗ることができます。
ソース:
- https://en.wikipedia.org/wiki/Unsupervised_learning
- https://keras.io/
- https://developer.nvidia.com/deep-learning
- https://keras.io/applications/
- https://arxiv.org/abs/1707.07012
- http://yifanhu.net/PUB/cf.pdf
- https://towardsdatascience.com/detecting-financial-fraud-using-machine-learning-three-ways-of-win-the-war-against-imbalanced-a03f8815cce9
- https://scikit-learn.org/stable/modules/tree.html
- https://aws.amazon.com/deepcomposer/
- https://blog.keras.io/a-ten-minute-introduction-to-sequence-to-sequence-learning-in-keras.html
- https://keras.io/examples/nlp/bidirectional_lstm_imdb/
- https://towardsdatascience.com/how-do-self-driving-cars-see-13054aee2503
- https://towardsdatascience.com/r-cnn-fast-r-cnn-faster-r-cnn-yolo-object-detection-algorithms-36d53571365e
- https://towardsdatascience.com/building-a-next-word-predictor-in-tensorflow-e7e681d4f03f
- https://keras.io/applications/
- https://arxiv.org/pdf/1707.07012.pdf