
SEOのためのセマンティックネットワークの重要性:クエリおよびドキュメントテンプレートを使用したセマンティックコンテンツネットワークの作成–ケーススタディ
公開: 2022-01-11セマンティックネットワークは、リレーショナル接続を持つものの実際の情報を表すことができる知識ベースの概念に接続されています。 ナレッジベースには、数十億のエンティティと数兆のファクトを持つ数千の関係タイプがあります。 セマンティックネットワークは、重量、サイズ、タイプ、匂い、色などの相互の特徴を備えた現実世界の存在から作成できます。 セマンティックネットワークとセマンティックWebの関係は、セマンティック検索エンジンと最適化によって作成されます。
セマンティックネットワークは、セマンティック解析、語義の曖昧性解消、WordNet作成、グラフ理論、自然言語処理、理解、および生成で使用されます。 セマンティックネットワークのパースペクティブは、セマンティックコンテンツネットワークを提供することにより、セマンティック検索エンジン最適化内で使用できます。
このSEOケーススタディでは、クエリ、ドキュメント、インテントテンプレート、およびその背後にあるエンティティと属性のペアに基づいて、同じ視点を持つ2つの異なるメソッドを持つ2つの異なるWebサイトについて説明します。
検索エンジンが知識をどのように表現するか、そして検索エンジンが知識の表現をどのように拡張するかを理解することで、それを活用して信じられないほどのランキング結果を生み出すことができます。 基本的な概念を理解したら、それらを2つの異なるWebサイトにどのように適用したかを説明し、次に使用した方法について詳しく説明します。
セマンティックネットワークはどのようにあなたのウェブサイトのランキングを助けることができますか?
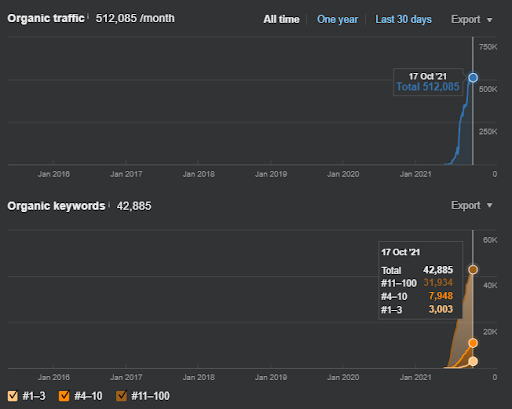
以下に、プロジェクトIの全体的な生の結果を示します。
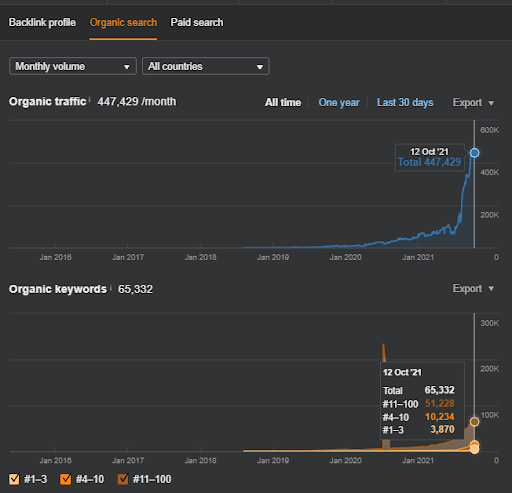
プロジェクト1の結果はIstanbulBogaziciEnstitu.comです。 「セマンティックネットワーク」がクエリおよびドキュメントテンプレートを使用したSEOに使用できることを証明するために、ProjectOneの2つの異なるコンテンツネットワークを紹介します。 プロジェクト1は、セマンティックコンテンツネットワーク2のおかげで、近い将来、はるかに良い結果が得られるでしょう。 この2番目のネットワークの展開はクライアントが担当しますが、そのロジックについても説明します。
17日後、プロジェクトIの進捗状況は次のとおりです。 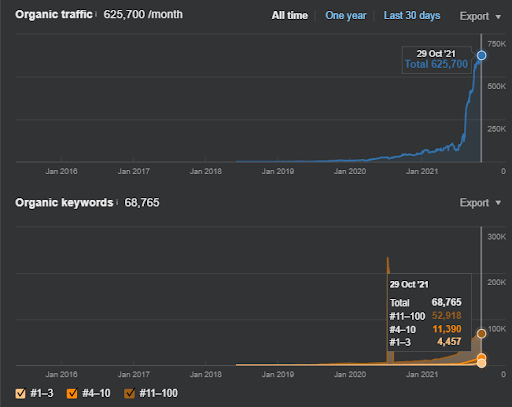
17日後、セマンティックコンテンツネットワークの再ランク付けプロセスがより明確になりました。
セマンティックコンテンツネットワークの概念は、同じタイプのエンティティのクエリ、検索意図、動作、およびドキュメントテンプレートの価値を理解するのに役立ちます。 このセマンティックネットワークに焦点を当てたSEOケーススタディでは、以前のトピックオーソリティとセマンティックSEOケーススタディが、同じエンティティタイプの周りにセマンティックに作成されたコンテンツネットワークを使用する2つの新しいWebサイトを介して深められます。
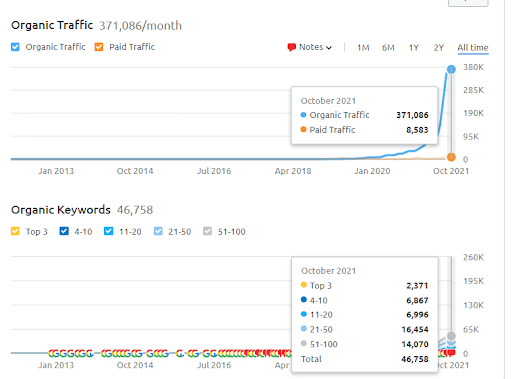
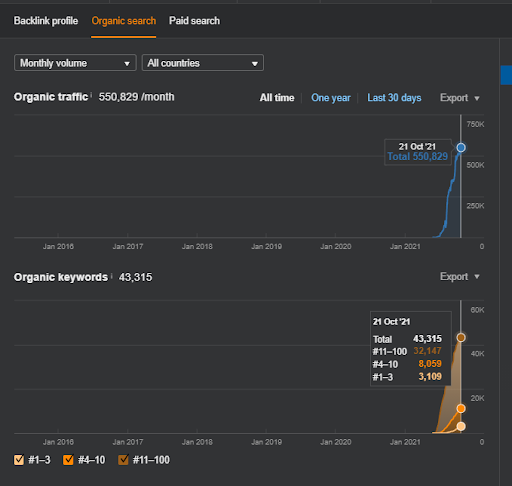
これは、最初のプロジェクトのSEMRushグラフィックです。 また、このWebサイトは6月のBroad Core Algorithm Updateを失いました。「ランク付け可能性」が失われなければ、結果はより良くなります。 トピックの権限、カバレッジ、および履歴データが改善された次のBroad Core Algorithm Updateでは、「ランク付け可能性」を簡単に回復できます。
2番目のプロジェクトの名前はVizem.netです。 Project Oneとは異なり、Vizem.netの増加は遅いですが着実に増加していることがわかります。 これは、セマンティックコンテンツネットワークをわずかに異なる視点で使用しているためです。 以下に、2番目のプロジェクトのAhrefsの結果を示します。
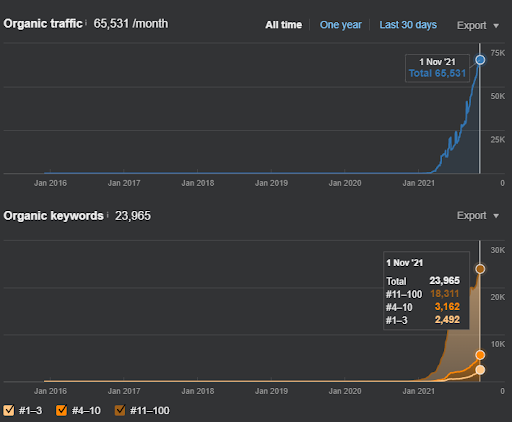
2番目のプロジェクトの結果は、トピックの範囲と権限を徐々に改善することによる「遅い再ランク付けプロセス」を表しています。 「再ランク付け」および「初期ランク付け」という用語は、セマンティックコンテンツネットワークに関連する概念の後に説明されます。 グラフィック内の「安定性」に気付いた場合、それは私がソースでの新しいコンテンツの公開を停止したためです。 また、上位3つのクエリカウントのカウントからわかるように、再ランク付けプロセスに影響します。 「勢い」と「再ランク付け」の関係は、基本的な概念の説明の後に見つけることができます。
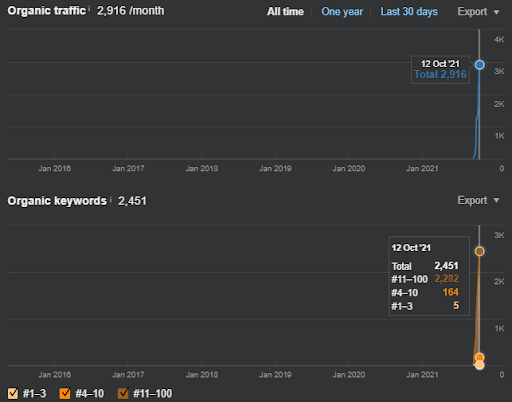
以下に、Vizem.netのSEMRushの結果を示します。
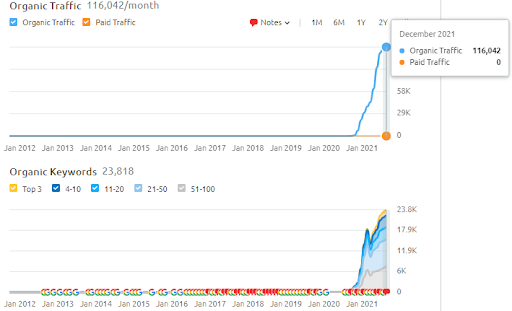
このウェブサイトの実際のトラフィックは、SEMRush内に記載されている数の3倍です。 これらのグラフ内でも、同じ「安定性」と「勢い」の概念を実現できます。
Topical Authority SEOのケーススタディを書いている間、私は自分の見方を教えてくれたBillSlawskiに感謝しました。 セマンティックコンテンツネットワークのSEOケーススタディでも同じことを繰り返します。 「再ランク付け」と「初期ランク付け」の概念を理解するには、「検索エンジンが検索結果を再ランク付けする方法」を読む必要があります。
2021年3月18日、Oncrawl、RankSense、Holistic SEO&Digitalは、PythonSEOとデータサイエンスのウェビナーを公開しました。 ウェビナーでは、結果の違いをアニメーション化するためにSERPが記録されています。 検索エンジンが特定のソースのランキングを同じ頻度で他のソースと変更していることがわかります。
先に進む前に、これは長い記事であることを知っています。 しかし、実際にはこれは非常に複雑なSEO方法論の簡単な説明です。 セマンティックコンテンツネットワークは、それらを設計する際にあまりにも多くの思考を必要とし、クライアント、作成者、およびオンボーディングのための数ヶ月の教育を必要とします。 したがって、この記事では、可能な限り最良の実行可能な簡単な提案と重要なGoogle、および他の検索エンジンの特許、研究論文、およびそれらの概念を含む概念の定義に焦点を当てたいと思います。 ロングバージョン(基本的には本)では、セマンティックコンテンツネットワークの「初期ランキング」と「再ランキング」に焦点を当ててきました。
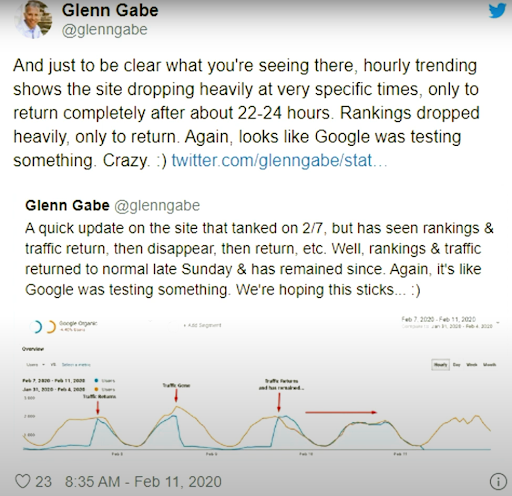
2020年2月11日から、Glenn Gabeは、検索エンジンの視覚的な再ランク付けとテストの方法論の良い例を示しています。
詳細については、「SEOの初期ランキングと再ランキングの重要性」をお読みください。
SEOケーススタディの実際のデータを深く掘り下げるには、セマンティックコンテンツネットワークを理解するための概念を、検索エンジンの理解-コミュニケーションの観点から処理する必要があります。
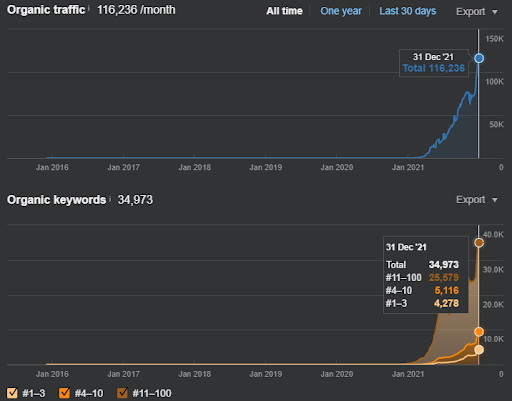
Vizem.netの再ランク付けの例として、更新された状況を上に示します。 SEOケーススタディの今後のセクションでは、SEOのためのGoogleの再ランク付けアルゴリズムについてさらに説明する予定です。
セマンティックネットワークとは何ですか?
セマンティックネットワークは、モノのインターネットに接続して分析するために使用できます。 これは、テクノロジー市場の潜在的な購入者を認識するため、またはキーワードネットワークの作成とクラスタリングのための共同単語分析に役立つ可能性があります。 セマンティックネットワークは、ナビゲーションをサポートし、関係の構造、またはあるものと別のものの相対的な重要性を明らかにするために使用できます。 セマンティックネットワークには、以下のコンポーネントがあります。
- 語彙意味論:どの単語と概念が他のどの単語と概念にリンクされているかを理解し、どのような違いがあるかを理解します。
- 構造コンポーネント:どのノードがどのエッジにどの情報で接続されているかを理解します。
- セマンティックコンポーネント:事実の定義。
- 手続き型パート:コンポーネント間の接続をさらに作成するのに役立ちます。
セマンティックネットワークは多目的であるため、NLPアルゴリズムは、複雑な健康問題の特定を支援するなど、非常に多様な目的にも使用できます。 同じセマンティックネットワーク構造は、これらの他の領域が互いにセマンティックな関係を持っている限り、他の複数の領域に実装できます。
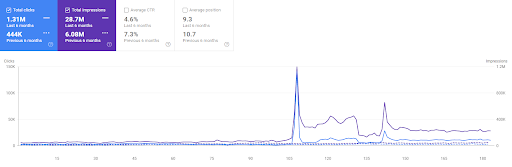
最初のプロジェクトの過去6か月の比較。
ナレッジベースとは何ですか?
ナレッジベースは、機械可読形式で分類された情報ライブラリです。 ナレッジベースは、クエリに基づいて絞り込んだり深めたりできる百科事典として使用できます。 知識ベースは、命題、事実の抽出、および情報の抽出に基づいて形成できます。 セマンティックネットワークとナレッジベースの関係は、セマンティックネットワークにあるすべてのものが、事実を抽出しながらナレッジベースに配置されるということです。
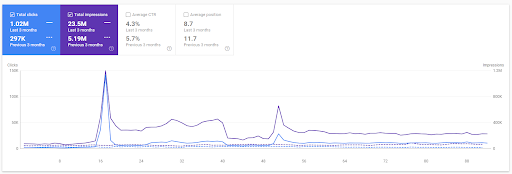
最初のプロジェクトの過去3か月の比較
セマンティックコンテンツネットワークとは何ですか?
セマンティックコンテンツネットワークは、セマンティックネットワークコンポーネントと理解に基づいて作成されたコンテンツネットワークを表します。 セマンティックコンテンツネットワークには、ナレッジベースに詳細を提供するために、1つまたは複数の同じグループのエンティティからの複数の属性を含めることができます。
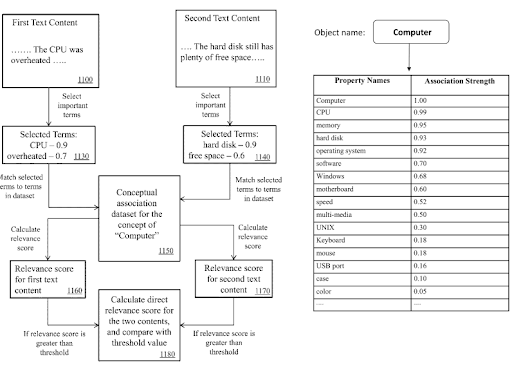
セマンティックコンテンツネットワーク内では、ナレッジドメイン用語、およびトリプルを使用して、ドキュメントの主な目的、および可能性のある近隣コンテンツの断片を通知できます。
検索エンジンは、独自のナレッジベースをWebサイトのコンテンツから生成できるナレッジベースと比較できます。 ウェブサイトがさまざまなコンテキストレイヤーに対して高レベルの精度と包括性を備えている場合、検索エンジンはウェブサイトのコンテンツから独自の知識ベースを向上させることができます。 検索エンジンがオープンウェブ上の別のソースから独自の知識ベースを改善および拡張する場合、それは高レベルの知識ベースの信頼のシグナルです。
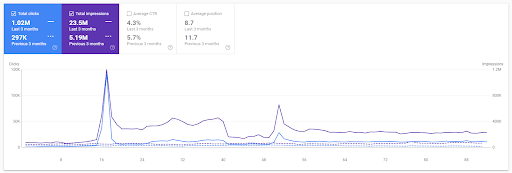
最初のプロジェクトに基づく過去3か月の前年比。
知識ベースの信頼とは何ですか?
ナレッジベースの信頼は、「PageRank」ではなく「情報の正確性」に基づくオープンなWebベースに焦点を当てています。 これは、RankMergeに似たアルゴリズムです。 知識ベースの信頼には、テキストのあいまいさを取り除くことによるトリプレット、事実の抽出、正確性のチェック、およびテキストの理解が含まれます。 知識ベースの信頼は、異なるが関連するコンテキストレイヤーに基づいて、記事内に強力に接続されたコンポーネントを持つセマンティックコンテンツネットワークを提供することによって取得できます。
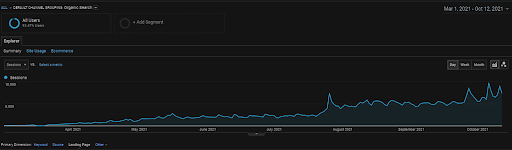
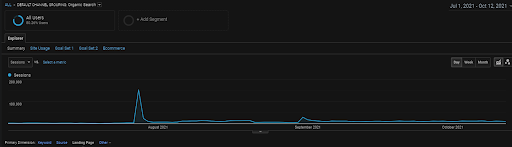
過去6か月間のGAからのVizem.netのオーガニックセッション。
以下に、ルナドンによる知識ベースの信頼のプレゼンテーションの例を示します。 これは、検索エンジンが外因性のランキング要素ではなく「内部のランキング要素」にどのように焦点を合わせることができるかを示しています。 それは、高いPageRankだけでは、コンテンツの高品質と正確さを表すことができないことを説明しています。 したがって、KBT(知識ベースの信頼)を持つことが重要です。
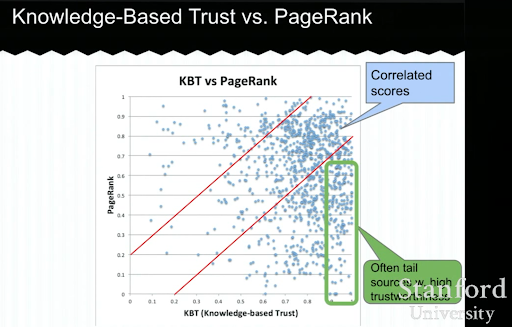
プライベートSEOチャット中にこの教育講義を私と共有してくれたArnoutHellemansに感謝します。 ナレッジベースの信頼について詳しく知りたい場合:スタンフォードセミナー–ナレッジボールトとナレッジベースの信頼
コンテキストカバレッジとは何ですか?
コンテキストカバレッジとトピックカバレッジはナレッジドメインと同じではなく、コンテキストドメインは同じではありません。 コンテキストカバレッジは、概念の処理角度を表します。 概念は、他のものへの相互のポイントに基づいて処理できます。 実体が国である場合など、環境危機に対するそのスタンスを処理することができます。 他の国が同じ角度から処理されている場合、それは私たちが文脈領域をカバーしていることを意味します。

Google検索エンジンは、時間をかけて研究論文と特許を構築します。 上のセクションの右の引用は「コンテキストベクトル」の属性であり、左のセクションは「フレーズ分類」の属性です。 おもしろいのは、例も同じ「デジタルカメラ」です。
これらの組み合わせの詳細とサブパートは、コンテキストドメイン内のコンテキストレイヤーを表しています。 名前が付けられているかどうかに関係なく、すべてのエンティティには多くのコンテキストドメインがあります。 したがって、Googleはより多くのコンテキストドメインを抽出し、ユーザーは毎年より長いクエリを検索します。 自然言語処理と自然言語理解が開発されると、クエリとドキュメントは詳細とコンテキストの観点から一緒に拡張されます。
BogaziciEnstituプロジェクトの最後の4か月間のGAOrganicSessionsグラフィック。 プロジェクトの「履歴データ取得段階」のため、増加した詳細が線形として表示されることは明確ではありません。
コンテキストカバレッジは、「コンテキスト修飾子」によって理解できます。 文脈修飾子は、形容詞、副詞、または「for、in、at、during、while」で始まる句などの他の前置詞にすることができます。 以下のエンティティ関連の質問は、コンテキストドメインに関して同じではありません。
- 不眠症の子供にとって最も有用な果物は何ですか?
- 不安のある子供にとって最も有用な果物は何ですか?
以下のエンティティ関連の質問は、コンテキストレイヤーに関して同じではありません。
- 6歳以上の重度の不眠症の子供にとって最も有用な果物は何ですか?
- 6歳未満の低レベルの不安を持つ子供にとって最も有用な果物は何ですか?
以下のエンティティ関連の質問は、知識ドメインに関して同じではありません。
- 6歳以上の重度の不眠症の子供たちにとって最も役立つ本は何ですか?
- 6歳未満の低レベルの不安を持つ子供にとって最も有用なゲームは何ですか?
ただし、これらの質問はすべて同じセマンティックコンテンツネットワークに含まれる可能性があります。これは、これらの質問がすべて同じ「概念」、「関心領域」であり、同様の検索アクティビティと検索関連の実世界のアクティビティがあるためです。
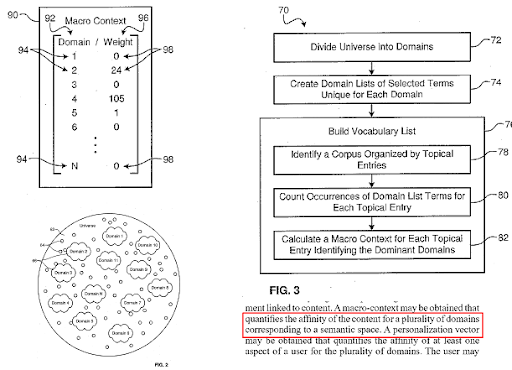
検索エンジンは、Webをさまざまな知識ドメインに分割し、ソース、Webページ、およびWebページセクションのマクロおよびマイクロコンテキストスコアを同時に計算します。
私はあなたのためにたくさんの新しい概念を持っていることを知っています、そしてこれはこの記事の短いバージョンなので、ここですべてについて話すことはできませんが、将来のセマンティックSEOコースでは、次のようなものを処理します「検索アクティビティ」と「検索関連の実世界のアクティビティ」の違い。
もっと具体的なことを少し続けましょう。
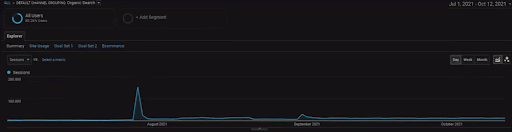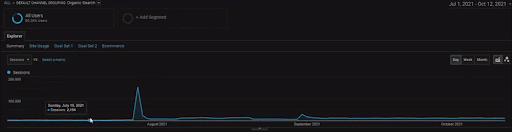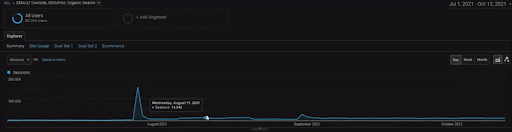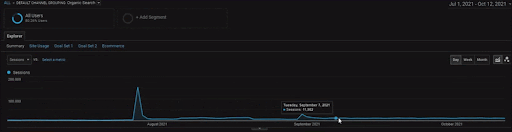
BogaziciEnstituプロジェクトの詳細を表示するには、インタラクティブな画像バージョンを確認できます。 検索エンジンのテストと再ランク付けのプロセスは、過去のデータソースイベントの後、このプロジェクトでより明確になります。
MuMはセマンティックコンテンツネットワークとどのように関連していますか?
UnifiedTransformerまたはMultitaskUnifiedModelを使用したマルチタスク学習は、テキストだけでなく視覚的な入力も評価するために言語モデルをトレーニングします。 理解とともにテキストを生成することができます。 さらに、MuMは言語に依存しません。つまり、セマンティックSEOは言語スキルに依存しますが、言語に限定されません。 エンティティには言語がなく、意味は普遍的であるため、MuMは複数の言語と複数のコンテキストからの情報を単一のナレッジベースに活用します。
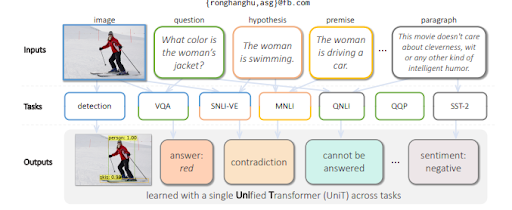
ビジュアルから質問に答えるために、MuMは画像内で検出されたオブジェクトに基づいて質問を生成します。 近い将来、オーディオおよびビデオ関連の質問も生成できるようになります。
MuMは、トランスエンコーダー-デコーダー構造を使用して、オブジェクト検出と自然言語理解にさまざまなドメインを使用します。 すべての入力はオープンウェブの異なる領域から来ますが、それらはすべて単一の共有デコーダーから評価されます。 以下に、研究論文からのさらなる例を見ることができます。
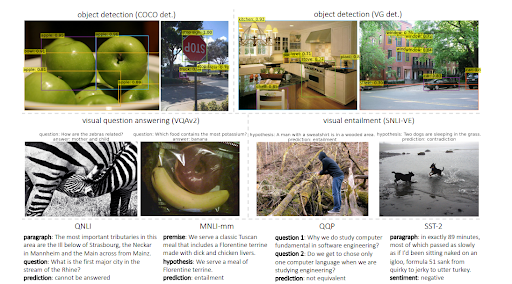
注意として、MuMはBERTよりも1000倍強力ですが、BERTはMuMのテキストエンコーダー内で引き続き使用されます。 MuMの主な利点は、ビジュアルとオーディオに直接使用できることです。そのため、MuMは「マルチタスク」モデルと呼ぶことができます。 2番目の利点は、すべての言語の壁を直接取り除くことです。 3番目の利点は、追加の仲介者を必要とせずに、すべてを別のものに接続できることです。 4番目の利点は、BERTとは異なり、MuMでもテキストを生成できることです。
MuM、ナレッジベース、セマンティックネットワーク、およびコンテキストカバレッジの間の接続は、検索エンジンがコンテキスト修飾子と可能なナレッジドメインとの組み合わせを介してはるかに多くのコンテキストドメインを見つけることができるということです。 したがって、適切なトピックマップとソースコンテキストで形成された適切に構造化されたセマンティックコンテンツネットワークは、トピックオーソリティとともにナレッジベースの信頼を向上させることができます。
ソースのコンテキストは何ですか?
ソースのコンテキストは2つのことを表しています。 ソースの中央検索インターネット、および関連する検索アクティビティで実行できる中央検索アクティビティ。 eコマースWebサイトの場合、ソースコンテキストは、特定の製品または特定のタイプの製品を購入することです。 それが旅行ウェブサイトである場合、ソースのコンテキストは、さまざまな種類の食品、風景、または単にビジネスのために別の場所からどこかに行きます。 ソースのコンテキストに基づいて、セマンティックコンテンツネットワークの設計、およびトピックマップをさらに構成する必要があります。 これには、トピックマップ内の中央セクションとトピックマップ内の補足セクションを選択する必要があります。
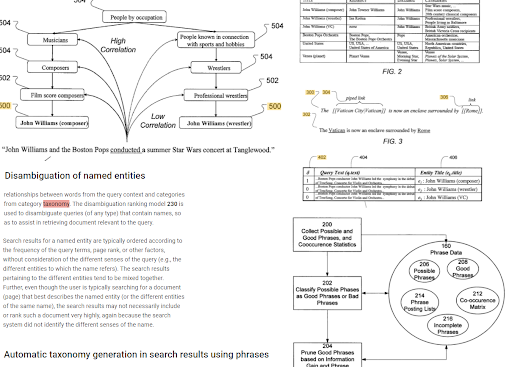
フレーズベースの索引付けとエンティティ指向の検索理解は、セマンティクスに基づいて相互に接続されています。 上記では、「コンテキスト」を決定するために、「名前付きエンティティの曖昧さの解消」と「フレーズを使用した検索結果での自動分類法の生成」を一緒に見ることができます。 良いフレーズ、およびトピックの一意であるが相関する情報は、初期および再ランク付けを改善するのに役立ちます。
繰り返しになりますが、これらの概念のいくつか、「トピックマップ構成」、「セマンティックコンテンツネットワーク設計」はまだ定義されておらず、これは適切な場所ではありません。 ただし、関連する検索アクティビティは、正規の検索意図、およびこれらの正規の検索意図の代表的なフレーズとともに説明されています。
セマンティックネットワークに焦点を当てたSEOのケーススタディの背景
上記の概念に基づいて、セマンティックネットワークを使用してSEOケーススタディを作成しました。 この記事の冒頭で述べた2つのWebサイトプロジェクトを見て、その結果と、それらを作成するためにセマンティックネットワークをどのように実装したかを調べます。
これらのネットワークがどれほど強力であるかを理解するために、セマンティックネットワークに焦点を当てたSEOケーススタディのSEO関連の結果を以下に示します。
- セマンティックネットワークの理解は、適切な地形図を作成するために必要です。
- どちらのプロジェクトでも、セマンティックSEOの影響を分離するためにテクニカルSEOは使用されていません。
- 同じ理由で、ページ速度の最適化は使用されません。
- デザインとWUX(Webサイトのユーザーエクスペリエンス)の最適化は使用されません。
- バックリンク(外部参照とPageRankフロー)は使用されません。
- どちらのブランドにも履歴データはありません。 Vizem.netは完全に新しく、BogaziciEnstitusuは古い歴史がありますが、実際の会社よりも低かったです。
- OnPageSEOまたはSEOの他の業種は使用されません。
- どちらのブランドも、前のTopicalAuthorityのケーススタディの例よりも優れたサーバーを備えています。
このセマンティックネットワークに焦点を当てたSEOケーススタディは、2つの異なるWebサイトに焦点を当てた2つの異なる方法論と概念を使用して、セマンティックSEOの視点を改善したい人々を支援します。
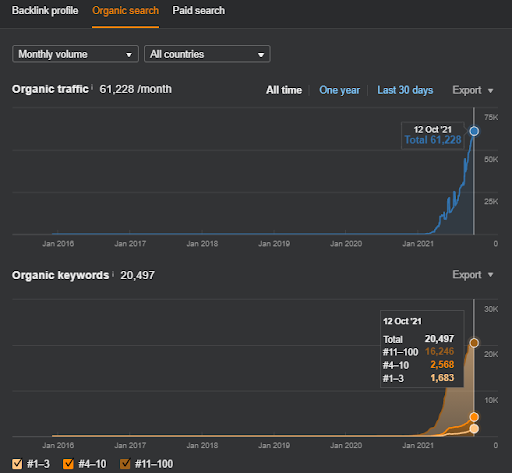
プロジェクト2:Vizem.netはビザ申請プロセスに焦点を当てています。 これらのプロジェクトを書いたり、公開したり、立ち上げたりする前に、私はこれらのWebサイトの両方を他のクライアントやパートナーに何度も見せてきました。 そして、Vizem.netは最近「TopicalAuthority」の旅を始めました。
セマンティックネットワークのケーススタディに基づくSEOは、2つの異なるバージョンで作成されています。 検索エンジンの意思決定ツリーをさらに理解しながら、関連するすべての特許、研究論文、および詳細な調査、検索エンジンの観点からの解釈を読みたい場合は、初期ランク付けおよび再ランク付けSEOの重要性を読むことができます30.000語より長いケーススタディ記事。 SEOと歴史的背景について十分な理論的知識がない場合は、エグゼクティブサマリーを読み続けることができます。
以下に、SEMRushの2番目のプロジェクト(Vizem.net)のグラフィックを示します。
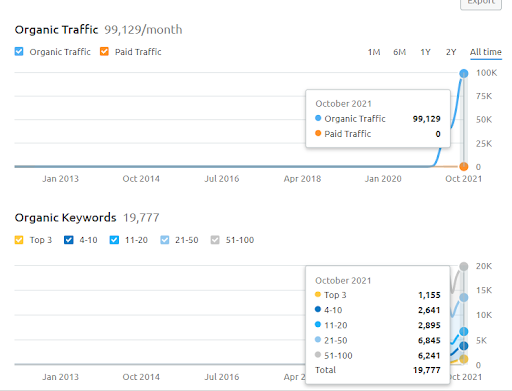
2番目のWebサイトのSEMRushグラフィック。 Vizem.netは、「ビザ申請」などの根強い競争相手がいる業界を対象としたまったく新しい情報源です。 特に、トルコでの最新のイベントにより、業界の競争レベルは高まっています。 したがって、コンテンツネットワークを作成するためにセマンティックネットワークパースペクティブを使用すると便利です。
最初のプロジェクト:Istanbul Bogazici Enstitusu:3か月で600%のオーガニッククリックの増加–活用された履歴データと初期ランキング
イスタンブールボガジチエンスティトゥスは、検索エンジンのためではなく、人々と私の健康上の問題のために、私が行った中で最も難しいSEOケーススタディの1つです。 したがって、私はプロジェクトを離れ、ソースのコンテキストに基づいてセマンティック関係を完成させるように設計された3番目のセマンティックコンテンツネットワークを公開しませんでした。 ナレッジドメインの用語がなく、コンテキストフレーズが適切に実装されている場合でも、十分なレベルのセマンティック接続と精度で構成されているため、3番目のコンテンツネットワークが将来公開され、2番目のセマンティックコンテンツネットワークの効果の増加も考慮に入れます。
以下に、過去12か月間のGSCでのIstanbulBogaziciEnstitusuの変化するグラフィックを示します。 このプロジェクトは、2021年5月に適切な方法で開始され、2つのセマンティックコンテンツネットワークを公開することで2021年9月に終了しました。
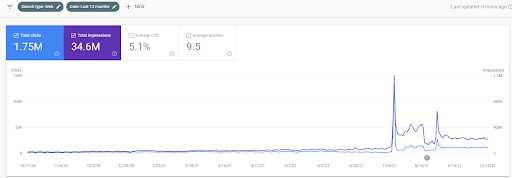
以下に、より詳細なバージョンを示します。 1日あたり1400回のクリックから140000回のクリックまで、その後、OrganicSearchのパフォーマンス内で1日あたり通常の10.000回以上のクリックを確認できます。
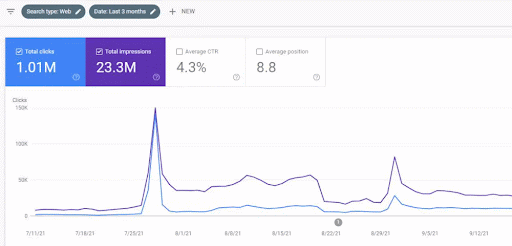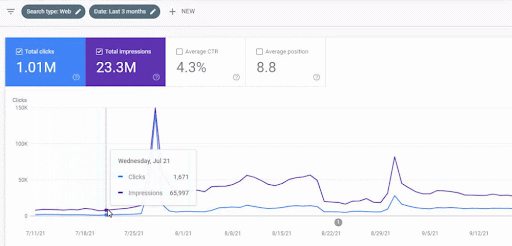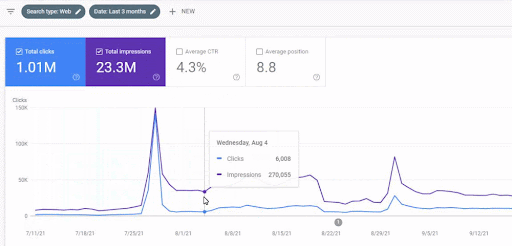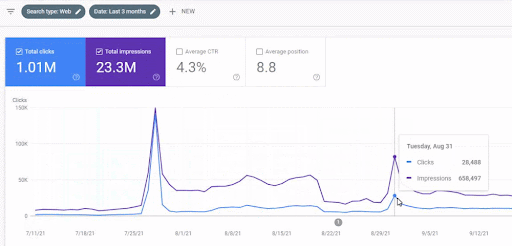
立ち上げ後の最初のコンテンツネットワークのトラフィックの増加を以下に示します。
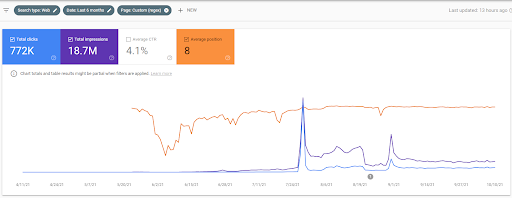
このスクリーンショットは、最初のセマンティックコンテンツネットワークの4か月目を示しています。
グラフィックからわかるように、Webサイト全体のトラフィックは、「教育部門」に焦点を当てたFirst Semantic Content Networkによって支配され、影響を受けています。 私がこのウェブサイトで立ち上げた2番目のコンテンツネットワークは、Google検索コンソールから以下に見ることができます。 以下のスクリーンショットは、2番目のセマンティックコンテンツネットワークの16日目のものです。
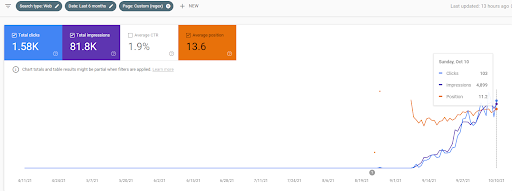
最初のランク付けと再ランク付けは、ソースをテストする前に、ランク付けアルゴリズムのフェーズとそのタイプと目的を定義し、人気のあるより重要なクエリのSERP内のソースからのWebページを定義するため、記事内で使用されています。 。
焦点を当てた最初のプロジェクトの最初のセマンティックコンテンツネットワークとは何ですか?
「セマンティックコンテンツネットワーク」は、ナレッジベースのセマンティックネットワークを使用して、ナレッジベース内のもの間の主、二次、および三次の関係を説明します。 したがって、セマンティックコンテンツネットワークを作成するには、Webサイトの主な機能であるソースのコンテキストに基づいて次のセマンティックコンテンツネットワークを設計する必要があります。 これに関連して、最初のセマンティックコンテンツネットワークは、「大学の学部、教育部門、および特定の組織と部門内の大学教育の必需品」に焦点を当てています。
以下に、First SemanticContentNetworkのAhrefsグラフィックを示します。
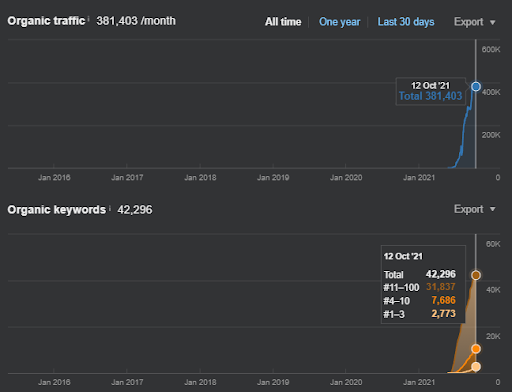
これは、前のスクリーンショットから5日後です。
「ルート:istanbulbogazicienstitu.com/bolum」、最初の初期ランク付けフェーズの後、再ランク付けプロセスはより効率的で生産的です。
「再ランク付け」の性質をサポートするために、以下の4日後のバージョンを見ることができます。
焦点を当てた最初のプロジェクトの2番目のセマンティックコンテンツネットワークとは何ですか?
2番目のセマンティックコンテンツネットワークは、職業、仕事、スキル、およびこれらのスキルまたはルーチンに必要な教育に焦点を当てています。 最初のセマンティックコンテンツネットワークに基づいて、2番目のセマンティックコンテンツネットワークがサポートされています。 また、「クエリテンプレート-インテントテンプレート」によると、さらに2つの異なるセマンティックサブコンテンツネットワークが作成され、上位の類似した階層レベルに接続された状態で「リレーショナル接続」が配置されます。
以下の定義がまだ表示されていないため、これらのセクションは複雑です。
- セマンティックコンテンツネットワーク
- ソースコンテキスト
- セマンティックサブコンテンツネットワーク
- 知識ベース
- リレーショナル接続
- 初期ランキング
- 再ランク付け
- コンテキストカバレッジ
- 比較ランキング
- 事実の抽出
2番目のウェブサイトを説明した後、これらの概念と文章を理解しやすくなります。
Vizem.net:6か月間の1日あたりのクリック数が0から9.000以上–コンテキストカバレッジを使用したレバレッジ比較ランキング
過去12か月間のVizem.netのグラフを見ることができます。 このプロジェクトでは、Covid-19のおかげで、投資家がジム業界から来ているため、多くの経済的問題を経験しました。 このように、経済的な問題がプロジェクトを遅らせ、「再ランク付けプロセス」にいくらかの待ち時間が生じたことがわかります。
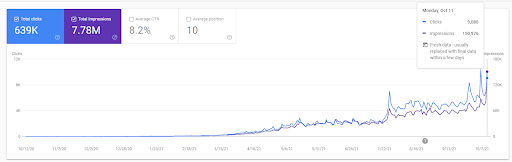
最初のランキングを理解し、もう少しランクを付け直すには、以下のグラフを使用できます。
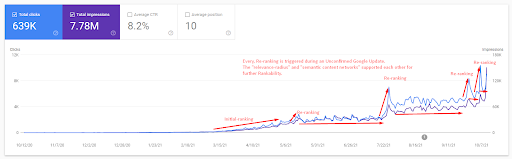
上の図の初期ランク付けと再ランク付けに関連する定義のいくつかを以下に示します。
- 未確認のGoogleアップデート中に、ランキングが大幅に上昇しました。 いくつかのテストはいくつかの注目のスニペットを与え、人々はまた質問をしました。
- グーグルからのいくつかのテストはFSとPAAの収入を削除しました。
- 毎回、2つの再ランク付けプロセス間のタイムラインは短くなりました。
- 再ランク付けプロセスにより、ソースのランク付け性が毎回向上しました。
- ソースは、クエリクラスターを拡張しながら、常に関連性の半径を改善しました。
ちなみに、以下に文章を残しておくことができます。
検索エンジンがWebページのインデックスを作成する場合、検索エンジンがWebページを理解したことを意味するわけではありません。 インデックス作成は理解よりも速く行われ、ほとんどの場合、検索エンジンは「最初に」予測を使用してWebページをランク付けします。 理解した後、「再ランク付け」が行われます。 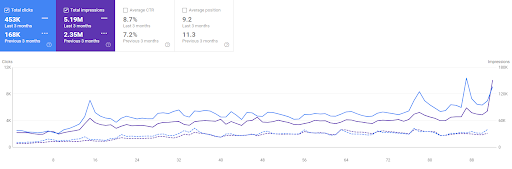
Vizem.netの過去3か月の比較
Vizem.netのセマンティックコンテンツネットワークはどうですか?
私のクライアント、友人、または秘密のSEOグループの多くにとって、会議中に、「爆発する」と言って、これらのWebサイトの両方をデモンストレーションしたことを覚えています。 そして、この記事を書いている間、私はあなたにこれを言っています:
「istanbulbogazicienstitu.com/meslek」セマンティックコンテンツネットワークは爆発するので、ご覧ください。 そして、この記事を書く前に私が公開したビデオを見つけることができます。季節のイベントからの「履歴データ」と、それが初期および再ランク付けプロセスに与える影響を示しています。 あなたはそれを下で見ることができます。
これに基づいて、Vizem.netのセマンティックコンテンツネットワークはIstanbulBogazici Enstitusuと類似していないため、「トピックカバレッジと履歴データの大幅な増加」を使用しませんでした。特定の関連する権限を作成する必要がありました。エンティティのタイプ、それらの属性、およびこれらのエンティティと属性のペアのクエリの背後にある可能なアクション。 Vizem.netには、「教育大学の支部」や「職業、オンラインコース」だけが含まれているわけではありません。 「ビザ申請国」があります。 したがって、十分なレベルのトピック権限を作成するには、少なくとも190の異なるセマンティックコンテンツネットワークとの長期にわたる一貫性が必要です。
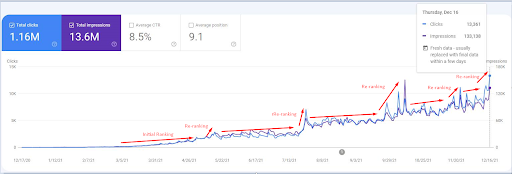
2021年12月18日のスクリーンショット。継続的な再ランク付けと、インプレッション数とクリック数の増加を確認できます。これは、前のスクリーンショットから4週間後です。
再ランク付けイベントを確認するには、セマンティックSEOの効果を示すオーガニック検索パフォーマンスグラフィックのネイキッドバージョンを比較できます。 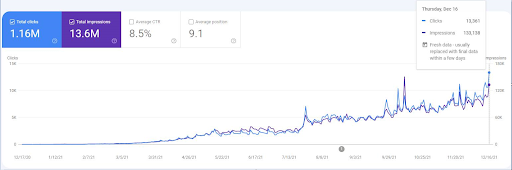
これらの190の異なるセマンティックコンテンツネットワークは、「国」自体に基づいて形成され、国は、検索アクティビティのカバレッジを向上させるために、考えられるすべてのコンテキストレイヤーとともにトピックマップの中央に配置されます。
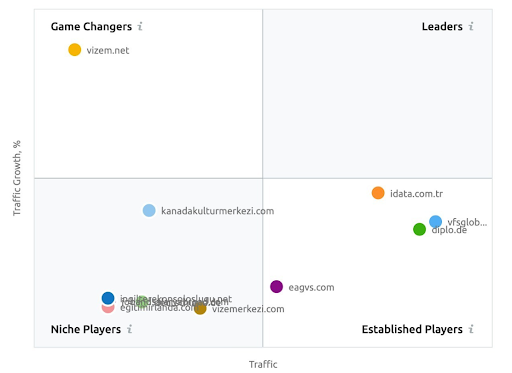
他の業界プレーヤーとは異なり、Vizem.netに対する彼らの認識を示すSEMRushのスクリーンショット。
Vizem.netのためだけに別のビデオも公開しました。 このビデオでは、ウェブサイトの最後の状況は存在しないので、今日とその日の良い比較にもなっていると思います。
最後に、無関係な記事、Webサイトのセグメント、またはソース内で無関係なものを公開すると、特定の知識ドメインに対するWebエンティティの全体的な関連性が低下する可能性があります。 Vizem.netはその真の価値を示し、将来のランク付けははるかに良くなるでしょう。
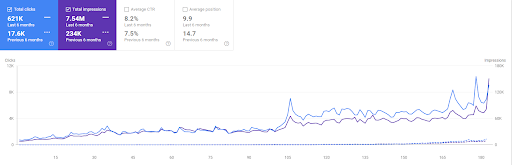
Vizem.netの過去6か月間の比較。
先に進む前に、これは長い記事であることを知っています。 しかし、実際にはこれは非常に複雑なSEO方法論の簡単な説明です。 セマンティックコンテンツネットワークは、それらを設計する際にあまりにも多くの思考を必要とし、クライアント、作成者、およびオンボーディングのための数ヶ月の教育を必要とします。 したがって、この記事では、可能な限り最良の実行可能な簡単な提案と重要なGoogle、および他の検索エンジンの特許、研究論文、およびそれらの概念を含む概念の定義に焦点を当てたいと思います。 ロングバージョン(基本的には本)では、セマンティックコンテンツネットワークの「初期ランキング」と「再ランキング」に焦点を当ててきました。
詳細については、「SEOの初期ランキングと再ランキングの重要性」をお読みください。
これまで、以下の処理を行ってきました。
- セマンティックネットワーク
- 知識ベース
- セマンティックコンテンツネットワーク
- 知識ベース-信頼
- コンテキストカバレッジ
- コンテキストドメインとレイヤー
- セマンティックコンテンツネットワークに対するMuMの関連性
- ソースのコンテキスト
これらの概念は、セマンティックコンテンツネットワークがどのように機能し、トピックマップでどのように使用できるかを理解するためのものです。 次のセクションでは、検索エンジンがセマンティックコンテンツネットワークを最初にランク付けする方法と、後で変更する方法について説明します。 これに関連して、以下のものが処理されます。
- 初期ランキング
- 再ランク付け
- クエリテンプレート
- ドキュメントテンプレート
- 検索インテントテンプレート
- セマンティックコンテンツネットワークを活用するためにすべきこと
SEOの初期ランキングとは何ですか?
これはSEOの新しい用語と概念ですが、検索エンジンの古い用語です。 「セマンティックネットワークに焦点を当てたSEOケーススタディ」の長いバージョンは、クエリ依存、ドキュメント依存、ソース依存のアルゴリズム、および複数の特許に基づくランキングアルゴリズムに焦点を当てています。 予測情報検索または予測ランキングアルゴリズムは、計算のコストを削減しようとします。 また、インデックス作成が1日で行われたとしても、ドキュメントの理解には数か月から数年かかる場合があります。 したがって、初期ランキングを計算することは、コストを削減しながらSERP品質を向上させる方法です。 一部の検索エンジン関連のタスクは、インデックスを存続させ、新鮮で、十分に高品質に保つために、他のタスクよりも優先度が高くなっています。

初期ランキングという用語は、検索エンジンビルダーの間の古典的な見方であるため、何万もの異なるGoogle特許や研究論文に登場します。 したがって、上記では、同じ段落が続くさまざまな特許文書と、用語の初期ランク付けの周りに小さな変更が加えられた用語を見ることができます。
初期ランキングは、インデックスが作成された直後のSERP上のドキュメントのランクを表します。 ドキュメントの最初のランク付けは、全体的な権限、およびソースと特定のトピック、クエリテンプレート、および検索意図との関連性を表します。 同じコンテンツは、異なるソース間の最初のランク付けに関して異なるランク付けを行うことができます。 セマンティックコンテンツネットワークを使用してソースの全体的な品質と権限の向上を確認する場合、最初のランク付けは重要です。 セマンティックコンテンツネットワークの設計が正しく構成されている場合、新しいドキュメントごとに初期ランキングが上がり、インデックス作成の遅延が減ります。
初期ランク付けは、ソースの再ランク付けプロセスとその効率をサポートします。 また、「ソースのランク付け可能性」は、初期と再ランク付けの2つの用語で処理する必要があります。
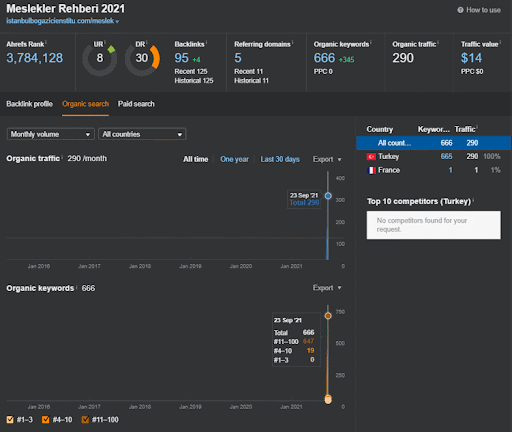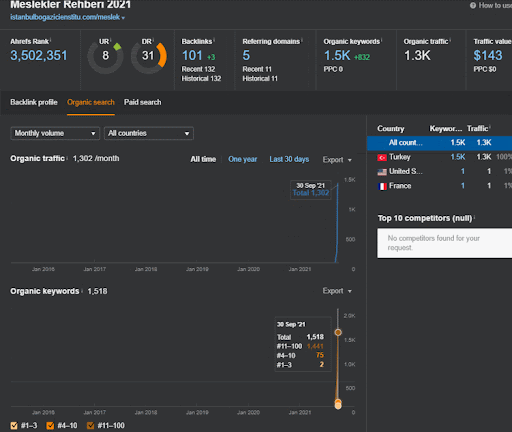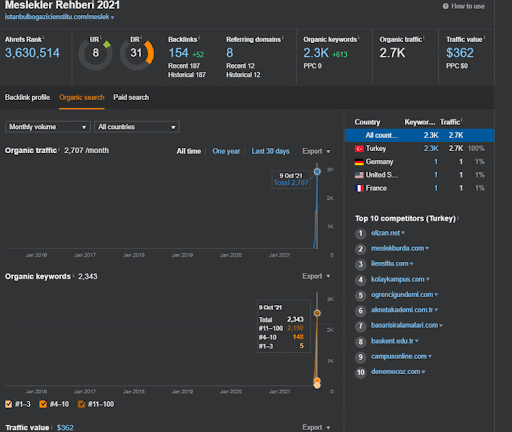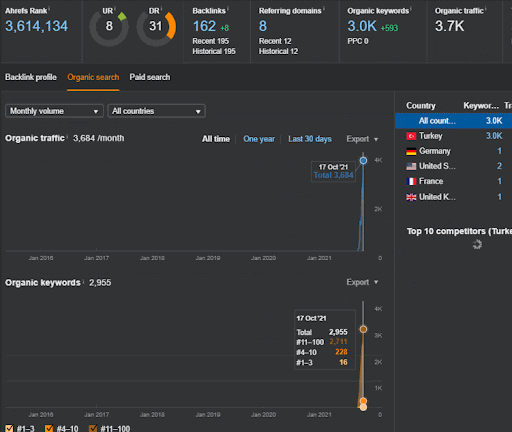
プロジェクトIからのセカンドコンテンツネットワークの有機的なパフォーマンスの変化の最初の20日間を見ることができます。
このコンテキストでは、Vizem.netが新しいドキュメントを公開するとき、またはIstanbulBogazici Enstituが新しいセマンティックコンテンツネットワークを公開するときはいつでも、コンテンツのインデックス作成が速くなる一方で、初期ランキングは以前よりも良くなります。
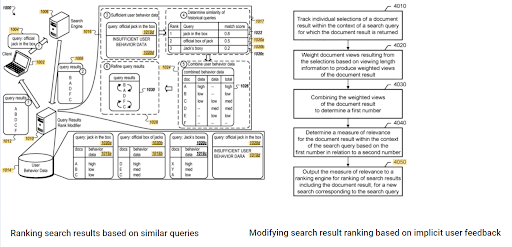
初期ランキングと過去のデータの卓越性は、これら2つの補完的なGoogle特許の間に見ることができます。 1つは、暗黙的なユーザーフィードバックに基づいてドキュメントを初期および再ランク付けするためのものです。 The other one is for doing the same if enough level of user data doesn't exist, based on the similar queries. The similar queries are also the point that relate the Semantics. Creating a Semantic Content Network will decrease the energy for reading the mind of the website owner from the search engine's point of view.
What is Re-ranking for SEO?
The re-ranking is the process of changing a document's ranking on the SERP based on the feedback of the users, or relevance, and quality evaluation algorithms. Re-ranking frequency can signal an algorithm update, or an update on the document, or a site-wide update for a source. Re-ranking is affected by the historical data which is explained in the previous SEO Case Study that focuses on the Topical Authority. Examining the re-ranking processes and the feedback from the search engines help for the configuration of the semantic content network design. Re-ranking timelines can be shortened with the help of the actual traffic, as well as with historical data if the contextual and topical coverage is improved.
The re-ranking processes are affected by the initial ranking and the quality of the neighborhood content. The neighborhood content will affect the ranking of any strongly connected components. Re-ranking processes can signal the weak spots, and the ability of the search engine to understand certain sections of the semantic content network. If the design is correctly created, the semantic content network will continue to rise and rise in terms of organic search performance over time, and any Google Updates will confirm these processes.
Below, you can see the comparison of the Semantic Content Network 1 and Semantic Content Network 2 of the IstanbulBogazici Enstitu in terms of the initial and re-ranking. 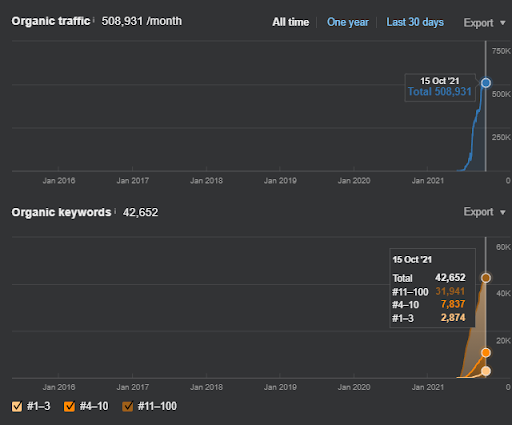
15 October 2021, performance of the first semantic content network of the IstanbulBogaziciEnstitusu which is the 124th day of the launch. 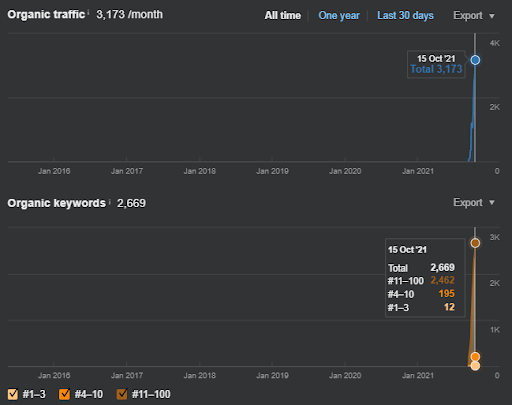
15 October 2021, performance of the Second Semantic Content Network of IstanbulBogazici Enstitu which is the 19th day of the launch. 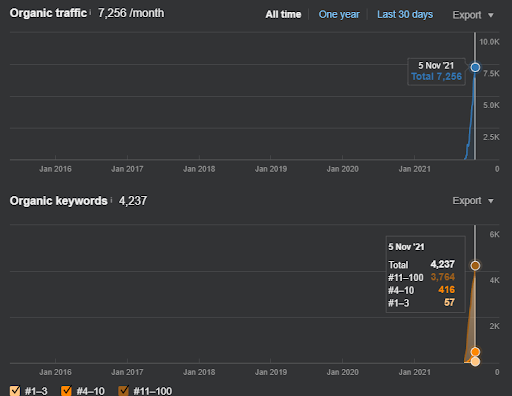
As you see, the second content network increases the organic query count and the rankings much faster than the first one. The Semantic Content Network 1 has the benefit of the “seasonal SEO” which gives enough level of historical data in a positive way. If there is a seasonal SEO event, the search engine will re-rank the pages, and assign the new relevance-radius and search activity coverage scores to the documents and the sources. Thus, I have chosen to use a “sudden launch” for the “university branches” first. It was the first step of the Topical Authority Building which is equal to the “historical data * topical coverage”. 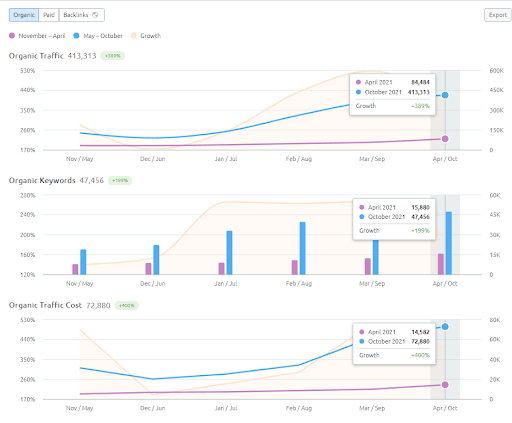
The 6 Months of Growth Comparison of the IstanbulBogazici Enstitu from SEMRush.
Note: To compensate for weaknesses in the execution, I designed a Semantic Content Network 3 to unite the first two using conceptual connections by providing the source's context. If I launched it, you would see that the source would acquire more than 1,2M organic traffic based on the Ahrefs graphic, in reality, it can be more than 2M. You can see my prediction's validity from the performance of the Second Content Network. Whenever you check it, you will see that it has thousands of new queries with higher rankings.
In the first Semantic Content Network, the first 3 ranking queries appeared after 2 months' for the second one, they appeared on the 15th day. You can imagine the increase in authority. Since the knowledge base of the website is left partially incomplete, after the source loses its momentum for semantic network completion, the search engine can prioritize other sources, and it can decrease the re-ranking positivity along with the relevance-radius and Rankability.
Implementing Semantic Networks on these sites makes use of a few concepts and “templates” used by search engines. Before I tell you about the method for setting up a Semantic Network, you should also understand what these templates are and how they work. This will help you understand how search patterns and document structure impact ranking, and therefore why the method I used in this case study is so effective.

The Initial Ranking, and Re-ranking are two different ranking algorithm types for a search engine based on timing. Search engines have other types of ranking algorithms such as query-dependent, query-independent, content-based, link-based, usage-based. To be able to understand the ranking systems, and clustering-associating technology of the search engines, the query-document-intent templates, and their relation to each other should be understood.
オンクロールデータ³
 もっと詳しく知る
もっと詳しく知るWhat is a query template?
A query template represents a search pattern with ordered phrases that cover an entity for seeking factual information. A query template can have a question format, a proposition format, or an order of word types such as one adjective and one noun. A query template is useful for generating seed and synthetic queries from the point of view of a search engine. A seed query can help a search engine to choose centroids for the query clusters while helping the clustering web page documents, their types, and possible search activities for them. 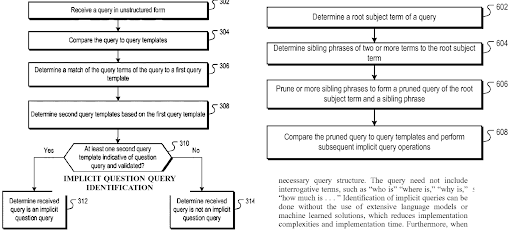
Another Google Patent about “Implicit Question Query Identification” which Nitin Gupta invented along with Steven Baker. “Implicit Question Query Identification” is also related to the question generation which is connected to the “K2Q System”.
In this context, a query template can be used for feeding the search engines' historical data for creating trust. Even if a search engine doesn't understand all aspects of a query, or a document for it, still some certain sources can be ranked earlier and better than others because of the document templates. If a source satisfies queries from a template, the search engine will rank the specific source for these types of queries from the same template better initially and during the re-ranking processes. Thus, on the web, we have sources that only focus on a single vertical with a single query template, like Wikihow, or GiftIdeas. 
“Query Suggestion Templates” is one of the documents that explains how a search engine can generate query templates based on query logs. Since, Nitin Gupta is one of the inventors of this patent, it has more value for me.
A query template can be used for creating a successful semantic content network, but in page contextual domains, and connections should be configured properly for connecting multiple semantic content networks for multiple query templates.
Note: The topic Query Templates, Intent Templates and the Document Templates are closely related, and another SEO Case Study will be published to demonstrate further details about it. 
A section from the Representation Learning for Information Extraction
from Form-like Documents of Google for extracting information from templatic content.
What is a document template?
A document template can signal the purpose of a web page based on the design elements, or even the request size, count and types. If a web page has too much JS, it can be a js-dependent website, or the interactivity needs can be higher than others. This can be confirmed easily by just checking the event-listeners on the web page, or input types, and API endpoints. When it comes to thinking like a search engine, remember that the web is a chaotic place. And, everything possible for understanding the users, especially if the users are Markovian , meaning that they are more influenced by the current page than their history of navigation. 
A section that explains how a search engine can use the document templates to see a user's interest area.
Did you know that Prabhakar Raghavan, the VP of Search on Google, also has a research that asks the same question? “Are Web Users Markovian?”. 
A section from the “Are web users Markovian?” research paper.
はい、そうです。 確率的ランキングと関連性の低下ランキングは、ユーザーを理解し、可能性の状態に備えて可能な限り最高品質のSERPを作成するためのセマンティック検索エンジンのメイン列です。 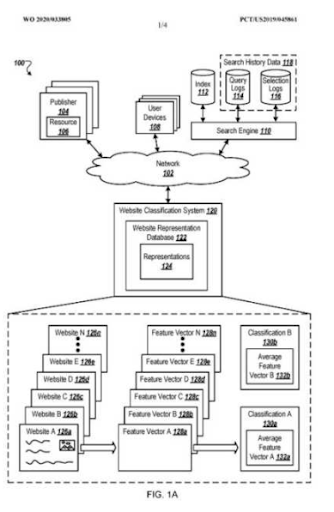
以前は、「Webサイトのデザイン、外観、または調性」をWebサイトの表現学習の議論にするために、BillSlawskiは「Webサイト表現ベクトル」を作成しました。
検索インテントテンプレートとは何ですか?
検索意図テンプレートは、クエリテンプレートの背後にあるニーズによって表すことができます。 クエリドキュメントテンプレートは、インテントテンプレートに基づいて統合できます。 「関連性の低下したランキング」と「確率的なランキング」を理解した検索意図テンプレートを用意しておくと、可能な限り最高の検索アクティビティを作成し、正しい順序で検索意図をカバーするのに役立ちます。 セマンティックコンテンツネットワークを作成する際に最も重要なことは、ソースのコンテキストに基づいてドキュメントクエリインテントテンプレートを調整し、コンテキストカバレッジを改善して知識ベースの信頼とトピックの権限を改善することにより、知識ドメインに基づいてセマンティックネットワークを完成させることです。 。 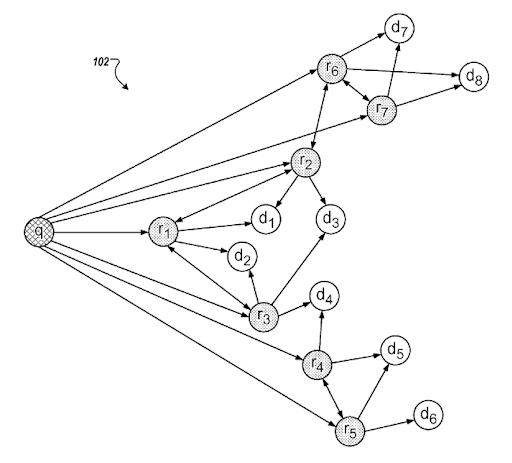
Googleの「推測された意図に基づくクエリの改良」のセクション。 これは、セマンティック接続を備えたクエリクラスターとインテントテンプレートを介して機能します。 さまざまなフレーズ分類レベルでそれを体験できます。
いくつかの具体的な例と、より良いセマンティックコンテンツネットワークの作成を支援するための提案に移る前に、このSEOケーススタディの単純なバージョンでさえ、高度な検索エンジンの理解とコミュニケーションスキルが必要であることを伝えなければなりません。 したがって、私は高レベルの情報を提供していると感じていますが、私が作成するセマンティックSEOコースでは、より具体的な例がいくつか示されることを知っています。 
同じ特許が、異なる「クエリパス」と「コンテキストシフト」の間の適切な接続を説明しています。
セマンティックコンテンツネットワークの活用について知っておくべきことは何ですか?
セマンティックコンテンツネットワークを作成するために、語彙セマンティクス、またはエンティティとフレーズ間の関係タイプに基づいて関連するすべての詳細を入力すると、単純なセマンティックコンテンツの概要とデザインでさえ1時間かかる場合があります。 フレーズベースのインデックス付け、単語ベクトル、またはコンテキストドメインに対するコンテンツ全体のコンテキスト関連性、または個々のサブコンテンツタイプに基づく関連性を計算するためのコンテキストベクトルなど、複数の角度を同時に使用します。高度なセマンティック検索エンジンの理解が必要です。
したがって、生成的方法論を使用すると、上記で説明した概念ですべてが簡単になります。すべてのセマンティックコンテンツネットワークパーツを完全に準備しても、作成者と作成者はそれを作成できず、コンテンツマネージャーも作成できないためです。あなたのビジョンに従うことができなくなります。 したがって、それはあなたを無駄にするかもしれません、そして私が十分に活発で監査可能な方法で概念を証明した後、私がこれらのSEOケーススタディプロジェクトのいくつかのためにしたようにあなたをプロジェクトから去らせます。
以下の提案は、簡単に実行できる簡単な手順のみを対象としています。
1.すべてのセマンティックコンテンツネットワークネットからの固定サイドバーリンクを使用しないでください
すべてのリンクには、Webページ内のすべての単語のような2つのハイパーテキストドキュメント間の接続の説明が必要です。 セマンティックHTMLの使用法は、Webページ上のドキュメントの位置と機能を指定するのに役立ち、検索エンジンがコンテキストの観点からセクションに異なる重みを付けるのに役立ちます。
Vizem.netの例では、同じサイドバーのデザインを使用していません。 サイドバーには、最新の投稿や最も重要な投稿は表示されませんでした。 サイドバーには中央のエンティティの属性のみが表示され、固定されておらず、動的です。 つまり、トピックマップ内の階層に基づいて、セマンティックコンテンツネットワークネットは、サイドバーにある場合でも変化します。 
ReasonableSurferモデルとCautiousSurferモデルについて考えると、SEOがさまざまなハイパーテキストドキュメント間の関連性を高めるのに役立ちます。
さらに、リンクは目立つように流れ、人気は可能な限り最良の接続からのソースのコンテキストに従う必要があります。 以下に、調整されたセマンティックHTMLコードを含むサイドバーセクションを示します。 
ユーザーのセッションでアクティブな記事の階層、タブ、タブの順序、タブ内のリンクが変更されます。 上記の例は、以下のブレッドクラム階層からのものです。 ![]()
2.PageRankでセマンティックコンテンツネットワークをサポートする
外部のPageRankが外部ソースからの必須ではない場合でも、それを使用できれば、最初のランク付けと再ランク付けの方が優れていることがわかります。 これらのプロジェクトの両方で、私はそれらを使用しませんでしたが、今回はそれが目的ではありませんでした。 Vizem.netの場合、経済的な問題があり、デジタルPRとアウトリーチに予算を費やしたくありませんでした。 イスタンブールBogaziciEnstitusuの場合、特定のトピックのソースの信頼性をサポートするために、いくつかの「ローカルに相互接続されたソース」を配置しましたが、予算と組織の規律の問題により、会社はこれを実装できませんでした。 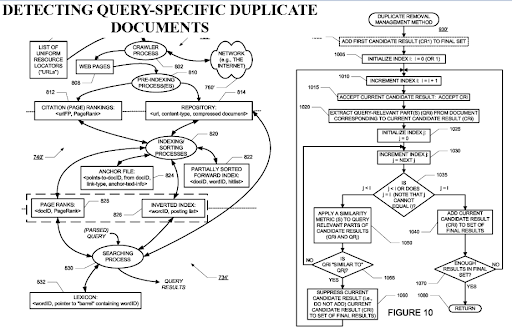
PageRankは、ドキュメントが重複している場合でも、ドキュメントを価値のあるものとしてフィルタリングするのに役立つため、クエリ固有の重複ドキュメントを検出することは、検索エンジンからの重要な観点です。 高度に編成されたセマンティックコンテンツネットワークは互いに類似している可能性があるため、PageRankフロー、および履歴データが役立ちます。
これらのタイプのセマンティックコンテンツネットワークの外部PageRankフローポイントを選択する場合は、履歴データを含むソースを使用してください。 私の場合、最初のセマンティックコンテンツネットワークを立ち上げて公開する前に、これらのPageRankエンドポイントを以前に配置していました。 このようにして、直接の競合他社から外部参照を取得することができましたが、セマンティックコンテンツネットワークを公開したとき、競合他社は、ソースの大量の増加を競合他社として見たため、ソースのリンクをあきらめました。
この状況は私たちに3番目の提案をもたらします。 外部参照からのPageRankフローを使用できる場合は、再ランク付けのプロセスが速くなり、初期ランク付けが高くなります。
3.著名なセマンティックコンテンツネットワークパーツに、フッター、ヘッダー、メインコンテンツとは異なるアンカーテキストを使用する
検索エンジンの観点から見たアンカーテキストまたは「リンクテキスト」は、ハイパーテキストドキュメントと別のドキュメントとの関連性を示します。 PageRankの元のドキュメントによると、リンク数はPageRankフローに比例します。 しかし、後でGoogleはこれを変更して「リンクの詰め込み」を防ぎ、実際にPageRankを通過できるリンクを制限しました。 これに基づいて、TrustRank、Cautious Surfer、Hilltop Algorithm、またはReasonableSurferモデルが開発されます。 
これらは、BogaziciEnstitusuの2つの異なるセマンティックコンテンツネットワークへの2つのリンクですが、技術的なSEOやUXの改善を実装しなかったため、ボタンデザインの「安さ」を実感できます。
Googleによると、同じリンクが2回目にPageRankを別のWebページに渡すことはできませんが、PageRankは最初のリンクからのみ渡されます。 また、PageRankアルゴリズムの元の形式では、ハイパーテキストドキュメントをリンクしてPageRankを改善したり、301リダイレクトを使用してリンクターゲットドキュメントのPageRankを取得したりできます。 これらの状況は両方とも、PageRankを取得するために、Webページを一時的に別のページにリダイレクトするなどの古いブラックハットテクニックを作成しました。 これは、SEOがGoogle検索コンソールまたはSERPからWebページのPageRankを見ることができた日からのものでした。 その後、GoogleはリダイレクトごとにPageRankを抑制し始め、DannySullivanは301リダイレクトがPageRankを完全に通過すると説明しました。 これらすべての変更に加えて、ここで重要なことは、2番目のリンクがPageRankを通過しなくても、リンクテキストの関連性を通過することです。 
セマンティックコンテンツネットワークの著名なセクションは、「動詞、述語」、または「検索者の活動」を含む「中間クエリの改良」に基づいてホームページからリンクされています。
したがって、セマンティックコンテンツネットワークの目立つセクションは、ヘッダーおよびフッターメニューから上位の分類セクションにリンクする必要があり、リンクテキストは互いに異なる必要があります。 これらの例では、フッターの例を長く保ちながら、目立つが短いリンクテキストのヘッダーリンクを使用しました。 
「Webクローラーシステムでのアンカータグのインデックス作成」のセクションでは、クエリクラスターおよびWebページクラスター内にWebページを配置するためのアンカーテキストと注釈テキストの重要性を要約しています。
セマンティックコンテンツネットワークセクションが目立つ場合、PageRankとクロールの優先順位を適切に渡すには、最も重要なセクションを適切なリンクテキストと、関連するN-Gramsのさまざまなバリエーションを持つ目立つ属性を含む説明段落にリンクしました。 
これは、Vizem.netのホームページから2番目にリンクされた領域であり、アコーディオンの背後にあり、クエリ内の国に焦点を当てており、セマンティックコンテンツネットワークの中央セクションにリンクしています。
注:アンカーテキストの周囲では、リンクの目的の精度を向上させるために、常に計画された「注釈テキスト」が使用されています。
4.リンク数の制限を制限し、デスクトップリンクとモバイルリンクおよびメインコンテンツを一致させる
どちらのプロジェクトも、Webページごとに150未満の内部リンクを持つように制限されています。 セマンティックHTMLの助けを借りて、リンクの場所とリンクの機能がクローラーに明確になります。 イスタンブールボガジチエンスティトゥスには、ウェブページごとに450以上のリンクがあり、これらのいくつかは自己リンク(同じページから同じページへのリンク)でした。 最悪の部分は、これらのリンクの半分がコンテンツのモバイルバージョン内に存在しなかったことです。 
URLキープスコア、クロールスコア、およびその他のタイプのスコアを使用して、内部URLマップ内のリンクの目立ちを判断できます。また、さまざまな層内のドキュメント識別タグを使用して、クエリに依存しない関連性スコアに基づいてインデックスを並べ替えることができます。
Googleはモバイルのみのインデックスを使用しているため、コンテンツがモバイルバージョン内に存在しない場合、コンテンツは無視され、関連性の評価やランキングの目的には使用されません。 したがって、モバイルコンテンツとデスクトップコンテンツは、互いに一致するように構成されています。 Googleがデスクトップバージョンとモバイルバージョンの間のコンテンツの不一致を許容しているとしても、それでも検索エンジンにとってWebページの理解とランク付けが難しくなります。 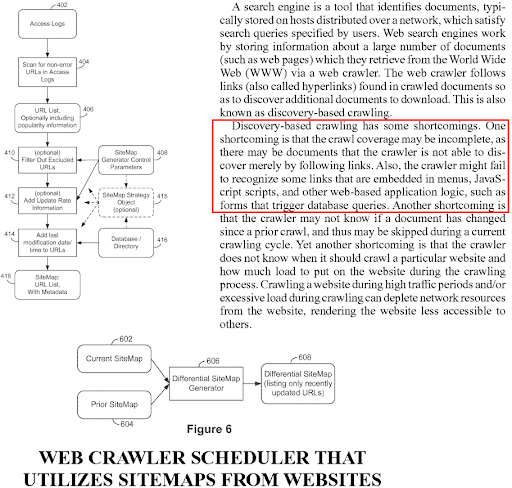
検索エンジンはWebサイトのサイトマップを生成でき、リンクとURLメタデータがユーザーエージェント間またはタイムライン間で一致しない場合、このサイトマップはループで再生成できます。 したがって、クロールパスを短くし、クロールキューを短くし、内部リンクの一貫性を保つことが重要です。
異なるWebページ間のリンクに加えて、Webページのサブセクションへのリンクも「コンテンツの表」および「URLフラグメント」で使用されます。 これらのURLフラグメントは、適切な名前を付けながらWebページの特定のサブセクションを対象とし、特定のセクションはh2でセクションタグに配置されています。 「ページ内ナビゲーションリンク」を備えたURLフラグメントの助けを借りて、SERPからWebページの特定のセクションにユーザーを誘導するのが簡単になり、コンテンツの下部セクションがより目立つようになり、背後のニーズを満たすことができました。クエリ。
5.SEOプロジェクトに軍事レベルの規律を持たせる
これはまったく別のトピックであり、軍レベルの規律が何を意味するのか、またはそれがSEOプロジェクトに役立つ理由を定義するために別の記事を書くことができます。 ただし、この2か月間、コースの設計がうまくいくかどうかを確認するために、他の機関のCEOやSEOをチームとともにトレーニングしてきました。
私が成功し、私が行う教育セッションを高いレベルで把握しているのを見るときはいつでも、強い意志と忍耐力があります。 主な問題は、セマンティックSEOが他のSEOバーティカルよりもはるかに難しいことです。 テクニカルSEOは普遍的であり、すべてのステップのガイドも書かれています。 OnPage SEO、またはWUXとレイアウトデザインは、数値測定で追跡できます。 セマンティクスに関して言えば、機械がどのように機能するかを理解していないホモサピエンスと複雑な適応システムに基づいて機能する機械の視点を統合することです。
この区別には、プロジェクトの初日から配置する必要があるコンクリートの土台が必要です。 ほとんどの場合、私は以下のルールを使用します。
- コンテンツデザインとセマンティックコンテンツネットワークは、作成者または作成者にとって論理的である必要はありません。
- コンテンツマネージャーのタスクは、コンテンツとコンテンツデザインの互換性を監査することです。
- 作者の仕事は、高レベルの正確さと詳細を含む関連情報でコンテンツを書くことです。
- リンク、定義、証拠、比較、提案、参照は、綿毛ではなく、具体的な例で行う必要があります。
- 不必要な言葉はすべて、文脈と概念の希薄化です。
読むと、実装は簡単に聞こえるかもしれませんが、それほど簡単ではありません。 このように、私は自分の従業員の何人かを解雇しようとしていたことさえわかります。 少なくとも今のところ、そうしなかったことを嬉しく思います。 通常の状態では、多くの質問があります。質問の所有者がSEOまたは会社の所有者でない場合は、回答しないでください。 ランキングへの冗長で無関係なフィードバックではなく、正のフィードバックを保存する検索エンジンのデータストレージにエネルギーを節約します。
6.コンテキストに関連するソースを展開します
このセクションは、MuMを作成するためのGoogleの必要性を完全に理解することについてです。 トピックマップを設計するとき、より良いサイトレベルのナレッジベースを提供する多くのセマンティックコンテンツネットワークが含まれます。 したがって、これらのサブセクションを公開している間、ソースのコンテキストに接続できる必要があります。そうしないと、検索エンジンがソースを認識する方法が変わり、Webサイトのテーマが別のナレッジドメインに切り替わる可能性があります。 たとえば、概念や関心領域の周りのものを可能なアクションと結び付けるには、複雑な意味の相互のつながりを理解する必要があります。 これらの接続をユーザー、ライター、そしてマシンに同時に明確にすることは、セマンティックコンテンツネットワークの作成プロセスです。 
これを実現するには、Webサイトのすべての新しいセクションを、トピックマップの中央セクションに接続できる必要があります。 これらのコンテキストブリッジは、Google独自のLaMDAの設計と説明から見ることができます。
「別のトピックについて書くべきか」、「2つの異なるニッチがある場合、それは害を及ぼすか」など、多くの質問に遭遇します。 これらすべてのサブセクション、強力に接続されたコンポーネントとしてのWebサイトセグメントを接続すると、これらのセマンティックコンテンツネットワークは、ブランドアイデンティティと、2つの異なる無関係なトピックのトピック権限を分割するのではなく、より良いランキングのために相互にサポートします。
7.実際のトラフィックを作成し、GoogleAnalyticsカスタムセグメンテーションで監査します
実際のトラフィックは、ナレッジベースの信頼がPageRankに接続されているのと同じ方法でRankMergeに接続されます。 すぐに、検索エンジンがサイドシグナルでPageRankに影響を与えようとする理由を説明するために、「PageRankが嘘をつくとき…」というタイトルの別の記事を書くことを考えています。 実際、PageRankは、情報源の権威、専門知識、信頼性を示す決定的なシグナルではありません。 それはランキングのシグナルであり、要因である可能性がありますが、それだけで信頼することはできません。 RankMergeは、Webサイトが検索エンジンにとって意味のある方法で、WebサイトのトラフィックとPageRankを統合するプロセスです。 PageRankが高く、トラフィックが少ない場合は、「人気のないトラフィック」または「PageRankの操作」を示す可能性があります。
したがって、ソースの履歴データを改善するために、季節ごとのSEOイベントを使用し、「ブランド+一般用語」クエリを増やしました。 直接のトラフィック、およびブックマークされたWebページは、実際のトラフィックと本物のトラフィックで増加します。
これらのタイプのデータは、検索エンジンがSERPで上位にランク付けするためにデータを信頼するのに役立ちます。
セマンティックコンテンツネットワークからのこれらの実際のトラフィックを監査できるようにするために、SEOはGoogle Analyticsからカスタムセグメントを作成して、それらが直接トラフィックとしてどのように発生するかを確認できます。 また、最初のセマンティックコンテンツネットワークから2番目のコンテンツネットワークへの可能な検索ジャーニーを作成するなど、カスタム目標を作成することもできます。 これは、セマンティックネットワークが関心、概念、および可能な検索関連アクションを中心に構築されているという概念実証です。
以下に、有機トラフィックを介して取得された直接トラフィックを示すために、最初のセマンティックコンテンツネットワーク内に配置されたWebページの1つの例のみを示します。 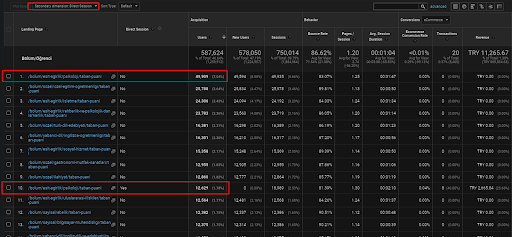
過去3か月で、最初のセマンティックコンテンツネットワークの1つのWebページのみが49.000人のオーガニックユーザーによって使用されました。 そして、12.900人の追加ユーザーが、初めてオーガニック検索によって獲得された直接トラフィックとして来ました。 また、セッション/ページの指標と平均セッション期間は、これらのユーザーセグメントの方が高くなっています。
前に述べたように、検索エンジンはクエリ、ドキュメント、インテント、コンセプト、興味、アクションをクラスター化できますが、ユーザーをクラスター化することもできます。 ユーザーグループが、これらのWebページをブックマークに追加し、アドレスバーを直接入力し、ブランド名とともに一般的な用語を検索することによってブランド価値を作成する際に肯定的なフィードバックを残す場合、ソースがその権限を向上させていることを示し、検索エンジンSERP、Chrome、および独自のDNSアドレスからすべてを認識できます。 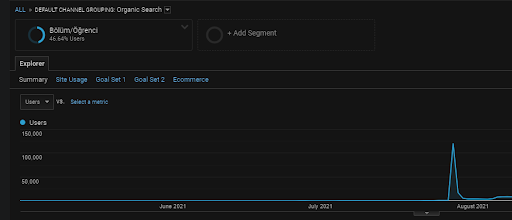
上に、FirstContentNetworkのユーザーセグメントが表示されています。 カスタム目標を使用して、すべてのセマンティックコンテンツネットワークのユーザーセグメントを作成できます。また、セマンティックサブコンテンツネットワークのサブユーザーセグメントを追加することもできます。
8.検索アクティビティに基づくサブセクションでセマンティックコンテンツネットワークをサポートする
このセクションでは、エンティティ属性の解決と、別のトピックである分析についても説明します。 ただし、簡単に言えば、コンテキストドメインに基づくこれらのエンティティの一部の属性は、上位階層ではなく下位階層に配置する必要があります。 この場合、「Vizem.net」はより良い例を示すことができますが、Bogazici Enstitusuの場合は、「SalariesofOccupations」と「ExamPointsofUniversities」で示すことができます。 これらの2つの顕著な属性は、セマンティックサブコンテンツネットワークへのクエリおよびドキュメントテンプレートに基づいて配置されています。 
検索クエリ内からのセマンティックユニットの識別は、フレーズをさまざまなセマンティックカテゴリに分割し、クエリのすべてのバリエーションへの近さに基づいてドキュメントの関連性を集約する別のGoogle特許です。
以前のSEOのケーススタディでは、このタイプの構造には従わず、「年表」と厳密に制限された内部リンクに基づいてクロールパスを作成しました。 これらの記事では、メインコンテンツの配置された内部リンクの量が前のものよりも多くなっています。
9.URL内でテーマ別の単語を使用する
Googleは、正規化シグナルのない同じコンテンツの2つの異なるURLに遭遇した場合、正規のURLとして短いURLを選択します。 なぜなら、短いURLは解析、解決、要求が簡単だからです。 毎日何十億回も更新する何兆ものWebページがある場合、URLの文字でさえ、Webサイトの「コスト/品質のバランス」を示すことができます。 前にも言ったように、「取得するコスト」は「取得しないコスト」よりも低くする必要があります。 検索エンジンに理解してもらいたい場合は、URLを含むすべてのレベルに「順序付けられた補完的なコンテキストシグナル」を配置する必要があります。 
エビデンスの集約による「エビデンスに基づく」ランキングのセクション。 答えを質問と一致させる方法を説明します。
このコンテキストでは、ほとんどの場合、URL内で1つの単語を使用します。 これらは、セマンティックコンテンツネットワークの階層と構造を反映できます。 URL内の「レイヤー数」がクロール頻度に影響を与えると考える人もいますが、2019年以前はそれは真実でした。 ただし、コンテンツが意味をなし、人気のあるトピックや著名なトピックのユーザーを満足させる限り、そのような状況の影響を受けることはありません。
それを実証するために、以下の例に従うことができます。
- ルートドメイン/セマンティックコンテンツネットワーク-1/タイプ-1/サブコンテンツ-ネットワーク-パート-フォー-タイプ-1
- ルートドメイン/セマンティックコンテンツネットワーク-2/タイプ2/サブコンテンツネットワークパートフォータイプ2
これらの2つのセマンティックコンテンツネットワークは、同じ階層から相互にリンクでき、関連性に基づいて相互にリンクすることもできます。 「エンティティグルーパーコンテンツ–ハブタイプコンテンツ」など、ここで話すことができることは他にもありますが、別の日のトピックです。
注:計画されているサードセマンティックコンテンツネットワークは、「概念的なハタコンテンツネットワーク」としても処理できます。 そして、それが公開された場合、セマンティックコンテンツネットワークの効果により、全体的なオーガニックトラフィックは月に300万セッションを超える可能性があります。
10.ネストと接続の違いを理解する
実用的な方法論の違いとして、接続とは、コンテキストドメインに基づいて類似したものを相互に接続することであり、ネストとは、同じ目的を持つ類似したコンテンツをグループ化することです。 このクラスタリングは、検索エンジンが互いに類似したコンテンツをより速く見つけ、これらのグループのソース品質スコアを作成するのに役立ちます。または、セマンティックネットワークに基づくこれらのネストされたコンテンツがより簡単になります。 
以下のように2つの異なるクロールパスがあると想像してください。
- クロールパス1:テンプレート、類似性、コンテキスト関連性なしで、URLにランダムに遭遇します。
- クロールパス2:URL自体からでも意味のあるURLに遭遇します。テンプレート、コンテキストに基づく高レベルの類似性と関連性があります。
クロールパスからでもコンテンツに意味がある場合は、「検索エンジンのカバレッジ理解に基づく再ランク付けトリガー」のおかげで、「初期ランク付け」と「再ランク付け」の方が優れています。
注:ネストと接続には、フレーズ分類法を使用した内部リンクを適切な方法で使用することが重要です。
これにより、最後の2つの実用的な方法論を簡単に共有できます。 そして、このセクションもまた、高レベルの規律と組織の十分性に関連しています。 
HTMLリスト内で共起する用語を認識するためのTrystanUpstillとStevenD.Bakerの特許。 この特許の卓越性は、トピックまたはフレーズ分類の一部の同時発生用語リストを決定するための単一のHTMLリストの値を示していることです。
11.調整された頻度でセマンティックコンテンツネットワークを公開するタイミングを理解する
これは以前に説明されていますが、これらのSEOケーススタディプロジェクトの1つで、私は1日に400近くのコンテンツを公開しました。 もう1つは、突然10〜15のコンテンツしか公開しなくなり、その後、Covid関連の経済問題が始まるまで着実に速度を上げていきました。
新しいソースが新しいセマンティックコンテンツネットワークを作成する場合、初日に公開するのは思ったより少し難しいかもしれません。Webページ上のすべての内部リンク、文法、および情報を確認するのはそれほど簡単ではありません。 ただし、すべてのコンテンツが単一のトピックとクエリテンプレートからのものであり、ソースにそのトピックに関する履歴がない場合、セマンティックコンテンツネットワークの大部分を公開すると、インデックス作成、理解、再ランク付け。
私の状況では、季節性のある歴史的な出来事もありました。 したがって、私の目的は、検索エンジンによって特定のエンティティをテストし、古いソースに対して検索アクティビティを実行できるようになるまで、十分なレベルの平均位置を確保することでした。 このように、私は季節のイベントから45日前に、高度な準備を備えた最初のセマンティックコンテンツネットワークを公開しました。
次に、検索エンジンがソースを繰り返しテストした方法を以下のように確認できます。 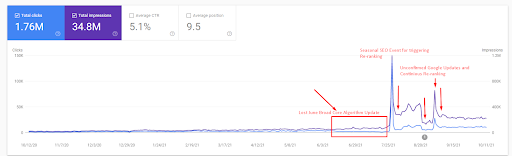
より詳細な説明は以下にあります。 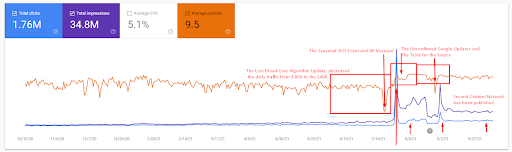
上記のスクリーンショットの説明については、簡単なファクトチェックを以下に示します。
- Broad Core Algorithm Updateにより、Webサイトのトラフィックが200%以上減少しました。
- ウェブサイトも15.000以上のクエリを失いました。
- これは、詳細なSEOケーススタディの記事でよりよく説明されているように、新しいセマンティックコンテンツネットワークのソースの全体的なインデックス作成に影響を与えました。
- 季節的なSEOイベントのおかげで、再ランク付けは以前に行われ、季節的なSEOイベントの後、検索エンジンは未確認の更新中の実際のトラフィックに基づいてソースのランク付けを正規化しました。
- First Semantic ContentNetworkとSeasonalEventのおかげで取得されたクエリとランキングは保護され、さらに改善されました。
- 最初のセマンティックコンテンツネットワークは、新しい2番目のセマンティックコンテンツネットワークもサポートしていました。
クエリの損失と平均ランキングの損失も、以下のようにAhrefsから確認できます。 2021年6月のGoogleBroadCore Algorithm Update(GBCAU)の効果と、未確認の更新の効果を確認できます。 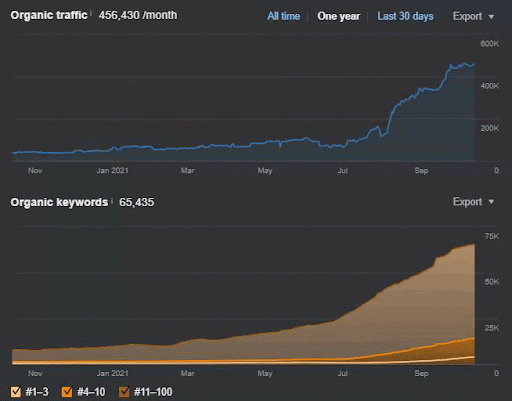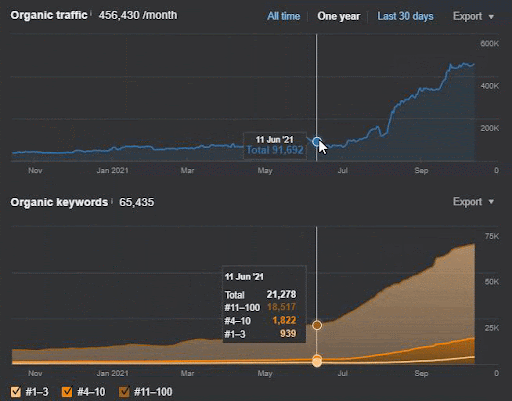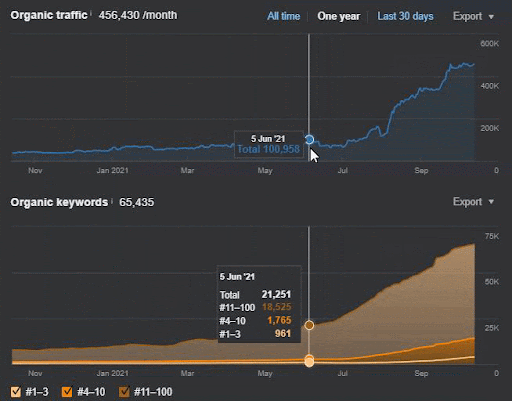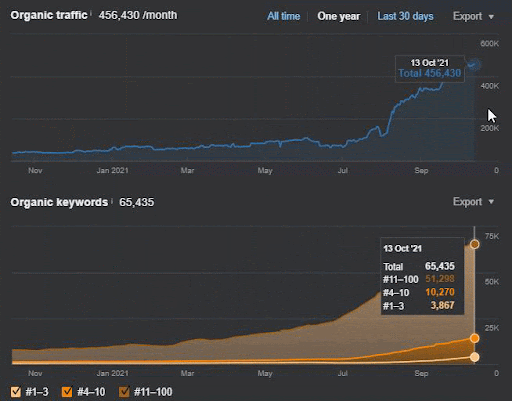
したがって、複数の可能な戦略でセマンティックコンテンツネットワークを使用することが必要です。 GCBAUが失われたとしても、検索エンジンに関連する他の要因のおかげで、ナチュラはSEOを助けることができます。 したがって、著者やクライアントにこれらのことを説明することがテクニカルSEOよりも難しい理由を想像するかもしれません。 セマンティックSEOは数値を使用せず、特許、研究論文、経験、および歴史的発表を介して検索エンジンの理解から得られる理論的知識を使用します。
12.より良い事実構造のためにページ内文の最適化を使用する
正直なところ、10番目のリストでさえまったく新しいトピックであり、ここに20.000語を書く必要がある場合もあります。 しかし、私は簡単な例から始めます。
- XはYです。
- YはXです。
上記の例文では、以下のことを理解できます。
- 上記の文章は重複コンテンツではありません。
- 上記の提案は重複しています。
- 2つの文の間の関係の説明は同じです。
- セマンティックロールラベルは100%異なります。
- 固有表現抽出の出力は100%同じです。
ページ内文の最適化は、質問生成アルゴリズムと質問と回答のペアリングテクノロジーに関連しています。 質問形式には、特定の種類の文が必要です。 また、特定の種類の質問には、特定の種類の文で回答する必要があります。 コンテンツ形式、NER、およびファクト抽出は、文型の最適化の影響を受けます。 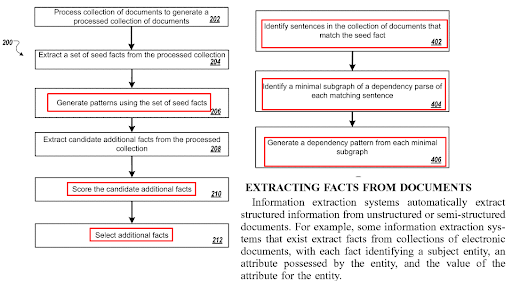
トリプレット(1つのオブジェクト、2つのサブジェクト)を抽出して、精度の観点からより速くチェックできます。 2つの類似した文は、それらが重複していることを意味するのではなく、文の構造の点で互いに近いことを意味します。 命題が異なる限り、異なるクエリインテントペアの類似したドキュメントテンプレート間で類似した文を使用することは、セマンティックコンテンツネットワークの作成に必要です。 
適切なパターンの明確な文の構造は、検索エンジンが名前付きのエンティティ、件名、属性、およびそれらの値を相互に認識できるようにしながら、テキスト部分を相互に関連性の高いものにするのに役立ちます。
また、記事のどのセクションをより良くすることができるか、そしてトピックネットで、どのタイプの単語ペア、単語ベクトル、およびインテントに対してコンテンツがより良くランク付けされるかを確認するのにも役立ちます。 なぜなら、特定の種類の質問に対する特定の種類の文の構造を複数のWebページで観察できる場合、無限の量のデータサンプルとテストサンプルを使用した高度なSEO A/Bテストに役立つからです。 複数のページ内文のデザインを作成して、検索エンジンがファクトを抽出して比較する方法を確認できます。 
事実を伝えることになると、「知識の保管庫」とルナドンを覚えておく必要があります。
13.綿毛の意見ではなく、正確で一貫性のある実世界の情報を提供する
ここでの精度とは、数値または概念的な具体的な関係と比較できることを意味します。 一貫性とは、特定の提案に対するスタンスを保護することを意味します。 たとえば、Yに関連するすべての製品レビューで「X製品がYに最適」とは言わないでください。サイト全体で矛盾する提案をしないでください。 そして、製品が最高である場合、それの証拠は何ですか? 素材、サイズ、それとも色や匂い? テキスト内の綿毛は、不要なブリッジワードを使用したり、証明できないことや真実と矛盾したりしないことを意味します。
いくつかの例でサポートされているこれらの非定義的な命令のコンテキストでは、KeALMであるGoogleの言語モデルの1つを確認できます。
これは、データからテキストへのモデルを使用してデータベースからテキストを生成するためのものであり、コンテンツの正確性をチェックするためのものです。 
KELMは、テキストからデータへのメソッドを使用した提案の精度監査の例です。
これは、「トリプレット」と「未知のエンティティのオープン情報抽出」の定義についても少し説明していますが、ご存知のように、これは簡単なバージョンであり、十分に説明したと思います。 基本的に、ウェブサイトで間違った情報を提供する場合は、Googleがそれを理解して、情報源の知識ベースの信頼を低下させることができることを確認してください。 ここで、ナレッジベースを拡張できるため、PageRankとの相関ソースとナレッジベースの信頼がある場合、検索エンジンは情報に基づいて独自のナレッジベースを変更できることも知っておく必要があります。高精度で、ユニークなトリプレット。
14.エンティティのセマンティック依存関係ツリーを理解する
セマンティック依存関係ツリーとは、他のエンティティとの関係を示す属性が、それらの間に階層的な依存関係を持っていることを意味します。 セマンティック依存関係ツリーは、国が組織のメンバーになることができるなど、複数のエンティティプロファイルと角度をチェックすることで観察できます。また、別のエンティティとして、この組織は、推論された関係を持つ接続された国に起因する可能性のある他の属性を持つことができます。
以下に、検索エンジンからの簡単な例を直接見ることができます。 
REALMは、セマンティック依存ツリーを使用して、あいまいなテキストから情報を抽出する方法です。
オープンウェブでは、オープン情報抽出は新しい名前付きエンティティを認識し、他のエンティティと同時発生するものとしてこれらの同じエンティティを抽出できます。 記事内のこれらの共起と相互属性は、エンティティ間のコンテキストと候補関係タイプを割り当てることができます。 接続とエンティティのタイプに基づいて、セマンティック依存関係ツリーを作成できます。 語彙意味論についても同じ論理が発生します。 「男の子」という言葉には、いくつかの可能な意味といくつかの正確な他の意味があります。 たとえば、男の子は男性で、おそらく結婚していない10代の若者です。 学生の近くでも使用できます。 一方、「女王」という言葉には、「女性」や「知事であること」など、他の側面や正確な意味が含まれています。 したがって、管理するものがあることは、「Queenof…」や「ForQuen」などの特定のタイプのクエリテンプレートに信号を送ることができる自然なセマンティック依存関係ツリー階層です。 These contextual layers with context qualifiers should be united naturally with contextual domains and knowledge domains for improving the topical and contextual coverage together. 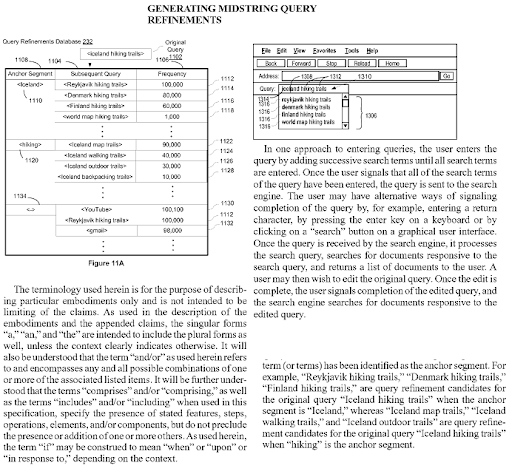
Generating Midstring Query Refinements is another Google Patent that shows the Semantic Content Network's connections to each other. Every midstring query refinement is a part of the topic's sub-topical net. A semantic content network that focuses on all these query refinement candidates with the correct semantic annotations will have the advantage of better re-ranking and initial ranking.
Last Thoughts on Semantic Content Network
I know that this content was highly technical in terms of Semantic SEO. And, before publishing my Semantic SEO Course, I still want to increase the knowledge, so that the first theoretical lessons can be digested by our minds faster than usual. The Semantic Content Networks can be defined as the sum of topical map, and individual content designs that include all of the headings, questions, heading levels, anchor texts, content hierarchy, and positions within the site-tree, or anything related to the content piece, including the featured images and in-page detailed images.
Here, besides the in-page sentence structure designs, or question-answer formats, or synonym sentence formats, we can also talk about the contextual vectors, contextual hierarchies, sequential sentences with bridged contexts, or evidence-based ranking by evidence aggregation. All these things would make this SEO Case Study and Guide more complicated but yet detailed. Thus, like in the previous, Importance of Topical Authority SEO Case Study and Guide, explaining Semantic Networks would make that article more complicated but yet detailed.
The future SEO Case Studies will include more and more details by supporting the previous ones. Lastly, I have gotten lots of screenshots and thank you messages from all of you that show the positive results that you have gotten thanks to Topical Authority understanding. I hope, Initial-ranking, and Re-ranking along with the Semantic Content Network understanding help you further.
See you in the next SEO Case Studies.
“The acquisition of knowledge is always of use to
the intellect, because it may thus drive out useless
things and retain the good. For nothing can be
loved or hated unless it is first known.”
– Leonardo da Vinci.