
10の一般的な技術的なSEOの問題–そしてそれらを見つける方法
公開: 2019-06-04さまざまな業界でSEOサービスを実施してきたため、特にWordPress、Shopify、SquareSpaceなどの一般的なCMSで作業しているときに、一般的な問題に気付くことができる場合があります。
ここでは、ウェブサイトを最適化するときに遭遇する可能性のある10の非常に一般的な技術的なSEOの問題について概説しました。
これらの問題があなたやあなたのクライアントにとって間違いなく問題になると言っているのではありません。多くの場合、コンテキストは依然として非常に重要です。 常に1つのサイズですべてのソリューションに対応できるとは限りませんが、以下に概説するシナリオに注意することはおそらく良いことです。
1 –GooglebotへのアクセスをブロックするRobots.txtファイル
これはほとんどの技術的なSEOにとって目新しいことではありませんが、技術的な監査を実行する時点だけでなく、定期的なチェックとして、ロボットファイルのチェックを怠ることは非常に簡単です。
Search Console(旧バージョン)などのツールを使用して、Googleにアクセスの問題があるかどうかを確認するか、OnCrawlなどのツールを使用してサイトをGooglebotとしてクロールしてみてください(ユーザーエージェントを選択するだけです)。 特に指定がない限り、OnCrawlはrobots.txtに従います。
クロール結果をエクスポートし、サイトの既知のページリストと比較して、クローラーの死角がないことを確認します。
これがまだかなり頻繁に発生していることを示すために、そしていくつかのかなり大きなサイトでは、数週間前、PingdomのスピードテストツールがGoogle内でブロックされていることに気づきました。
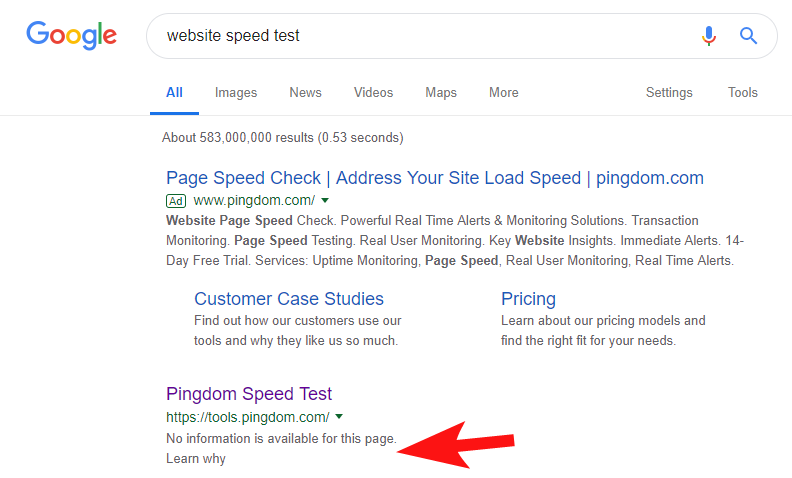
彼らのロボットファイルを見ると(そしてその後、GooglebotとしてOnCrawlから彼らのページをクロールしようとすると)、彼らが彼らのサイトへのアクセスをブロックしているという私の疑いを確認しました。
有罪のrobots.txtファイルを以下に示します。

「FYI」で連絡を取りましたが、返事がありませんでしたが、数日後、すべてが正常に戻ったことがわかりました。 ふぅ–また簡単に眠れました!
彼らの場合、速度監査の一環としてサイトをスキャンするたびに、上記のロボットファイルで強調表示されているハッシュ文字を含むURLが作成されているように見えました。
おそらく、これらはクロールされ、何らかの形でインデックスが作成されていて、それを制御したいと考えていました(これは非常に理解しやすいでしょう)。 この場合、彼らはおそらく潜在的な影響を完全にテストしていませんでした–それはおそらく最終的には最小限でした。
興味のある人のための現在のロボットは次のとおりです。

場合によっては、インターネットウェイバックマシンを使用して、過去のrobots.txtファイルの変更にアクセスできることに注意してください。 私の経験から、これはご想像のとおり、より大きなサイトで最適に機能します。これらのサイトは、WaybackMachineのアーカイバによってはるかに頻繁にクロールされます。
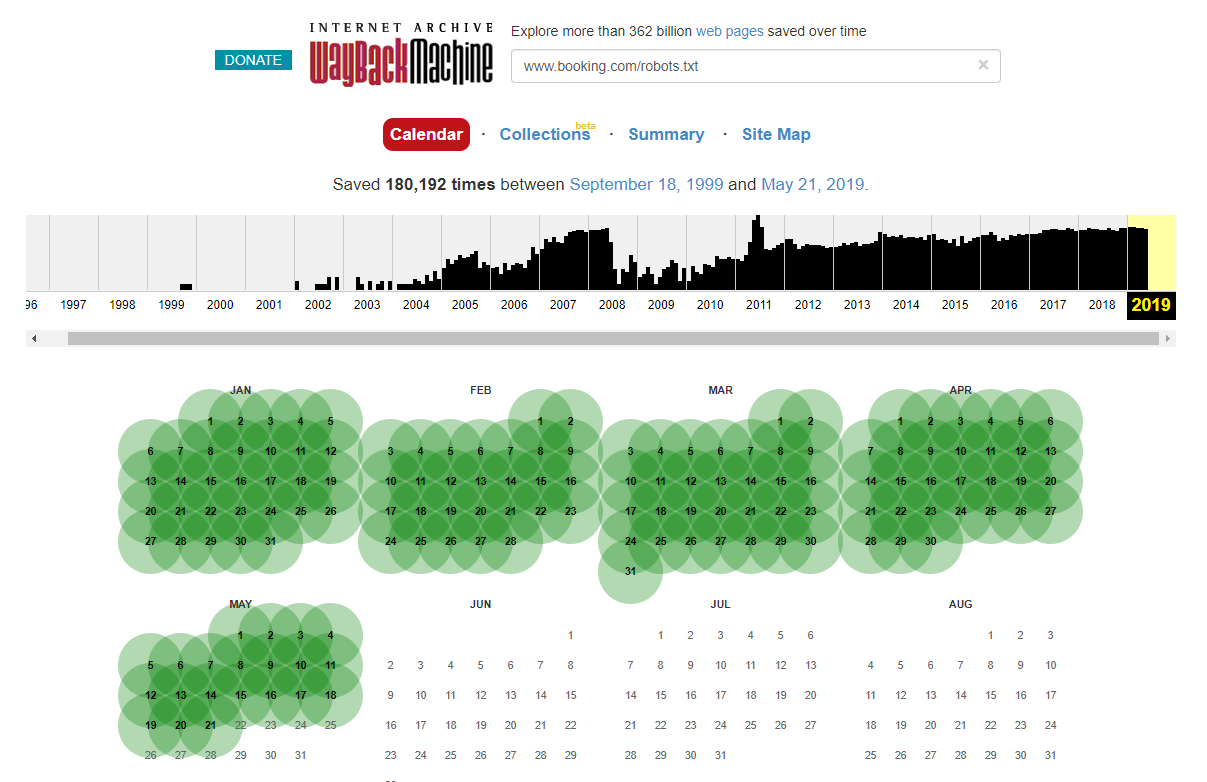
ライブrobots.txtが野生で出て、SERPSに少し大混乱を引き起こしているのを見たのはこれが初めてではありません。 そしてそれは間違いなく最後ではありません-それは無視するのはとても簡単なことです(結局のところ文字通り1つのファイルです)が、それをチェックすることはすべてのSEOの進行中の作業スケジュールの一部でなければなりません。
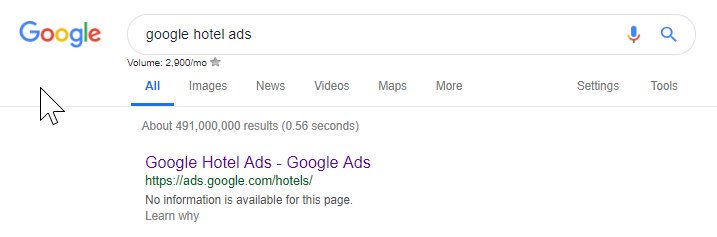
上記から、Googleでさえロボットファイルを台無しにして、コンテンツへのアクセスをブロックしていることがわかります。 これは意図的なものだったかもしれませんが、以下のロボットファイルの言語を見るとどういうわけか疑わしいです。
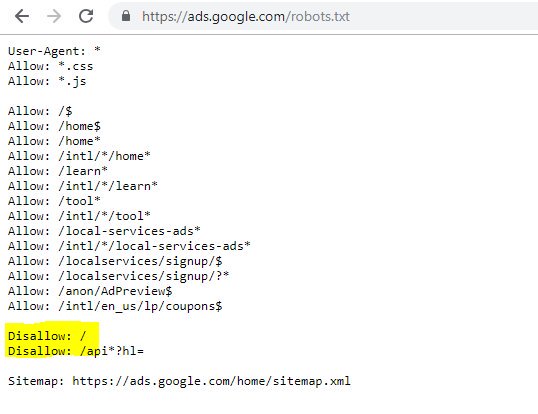
強調表示されたDisallow:/この場合、URLパスへのアクセスを禁止しました。 代わりにクロールすべきではないサイトの特定のセクションをリストする方が安全でした。
2 –DNSレベルでのドメイン構成の問題
これは驚くほど一般的なものですが、通常は簡単に修正できます。 これは、技術的なSEOが大好きな、低コストで*潜在的に*影響の大きいSEOの変更の1つです。
SSL実装では、302が次のURLにリダイレクトしてチェーンを形成したり、最悪の場合のシナリオがまったく読み込まれなかったりするなど、WWW以外のドメインバージョンが正しく構成されていないことがよくあります。
ここでの良い例は、ホテルフットボールのウェブサイトです。
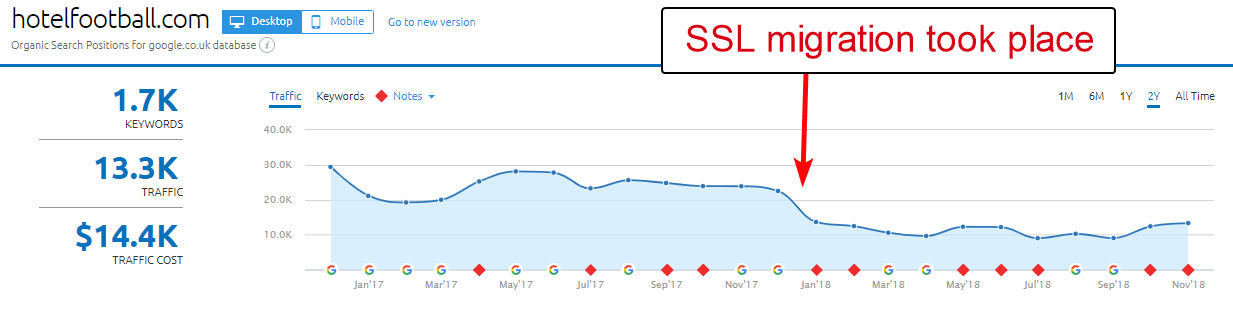
彼らは昨年初めにSSL移行を行いましたが、上記のSEMRushのドメイン概要レポートから判断すると、それほどうまくいきませんでした。
旅行やホスピタリティ業界で多くの仕事をしてきたので、しばらく前にこれに気づきました。サッカーが大好きで、彼らのウェブサイトがどのようなものか(そしてもちろん有機的にどのように機能しているか)に興味がありました。 )。
これは実際には非常に簡単に診断できました。サイトには非常に優れたバックリンクが大量にあり、すべてがhttp://www.hotelfootball.com/の非SSLのWWWドメインを指しています。
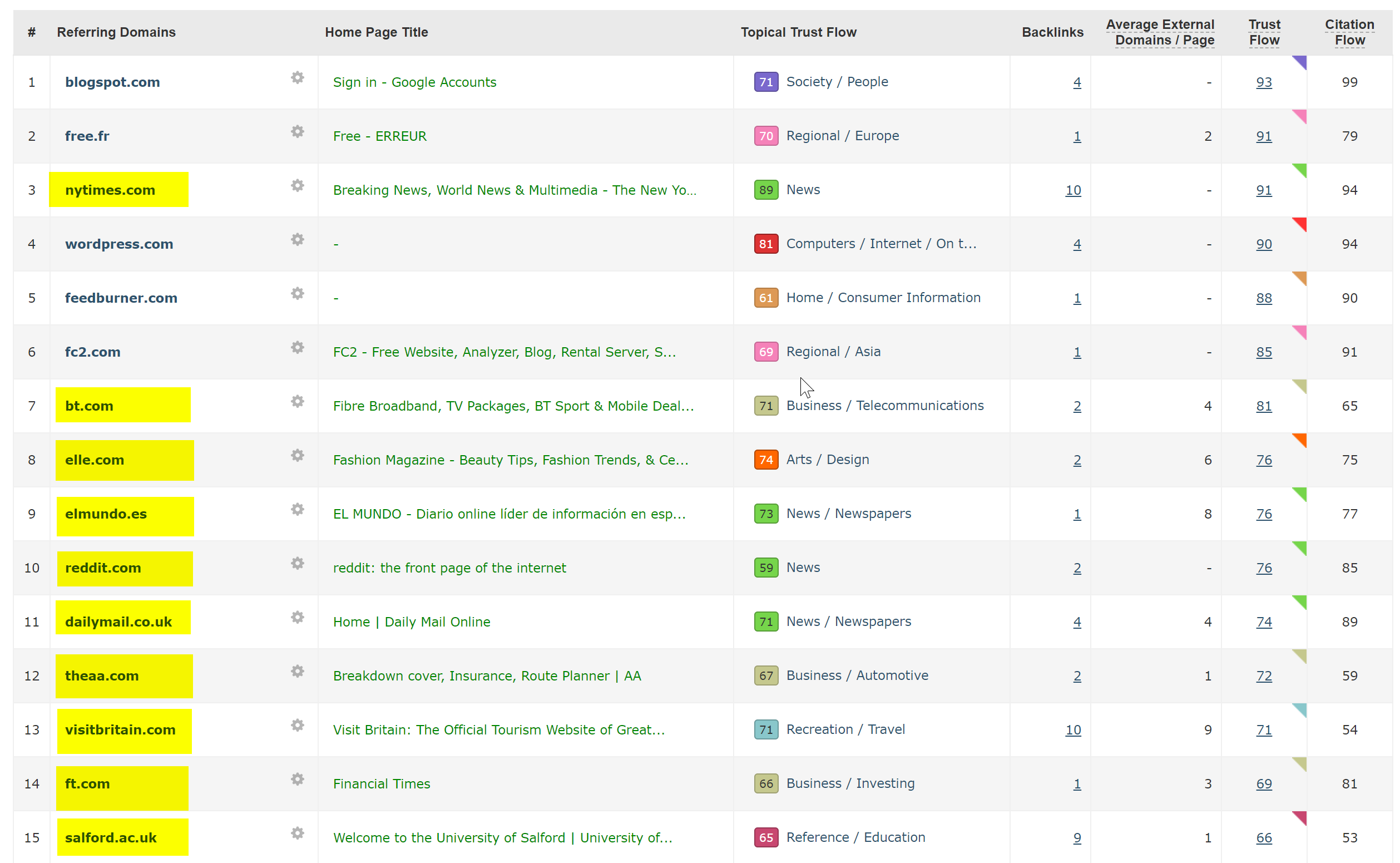
ただし、上記のURLにアクセスしようとしても、読み込まれません。 おっと。 そして、少なくとも今から約18か月はこのようになっています。 ツイッターでサイトを運営しているエージェンシーに連絡して知らせたが、返事がなかった。
これで彼らがする必要があるのは、DNSゾーン設定が正しいことを確認することです。ドメインの「WWW」バージョンの「A」レコードが正しいIPアドレスを指します(CNAMEも機能します)。 これにより、ドメインが解決されなくなります。
唯一の欠点、またはこれを解決するのに非常に時間がかかる理由は、サイトのドメイン管理パネルにアクセスするのが難しい場合や、パスワードが失われた場合、または優先度が高くないと見なされる場合があることです。
ドメイン名の鍵を持っている技術者以外の人に修正の指示を送ることも、必ずしも良い考えではありません。
特に、マンチェスター・ユナイテッドの元サッカー選手であるライアン・ギグスがホテルを立ち上げて以来、WWW以外のドメインが構築したすべてのバックリンクを考慮すると、上記の調整を行うことができれば、有機的な影響を確認したいと思います。と会社。
彼らはホテル名でGoogleで1位にランクされていますが(ご想像のとおり)、より競争力のある非ブランド検索用語のランキングはまったく高くないようです(現在は10位です)。 Googleで「オールドトラフォード近くのホテル」を検索)。
彼らは上記で少しオウンゴールを決めましたが、この問題を修正することは、それを解決するのに少なくとも何らかの方法で役立つかもしれません。
オンクロールSEOクローラー
 もっと詳しく知る
もっと詳しく知る3 –XMLサイトマップ内の不正なページ
繰り返しになりますが、これはかなり基本的なものですが、奇妙なことに一般的です。サイトのXMLサイトマップ(ほとんどの場合、domain.com / sitemap.xmlまたはdomain.com/sitemap_index.xmlにあります)を確認すると、実際にはそうではないページがここにリストされている場合があります。インデックスを作成する必要はありません。
典型的な原因には、非表示のありがとうページ(お問い合わせフォームを送信していただきありがとうございます)、重複コンテンツの問題を引き起こしている可能性のあるPPCランディングページ、または他の場所ですでにインデックスに登録されていない他の形式のページ/投稿/分類法が含まれます。
それらをXMLサイトマップに再度含めると、競合するシグナルが検索エンジンに送信される可能性があります。実際には、検索してインデックスを作成するページのみをリストする必要があります。これは主にサイトマップのポイントです。
検索コンソール内の便利なレポートを使用して、[URLの検査]オプションを使用して、ページがサイトのXMLサイトマップに含まれているかどうかを確認できるようになりました。
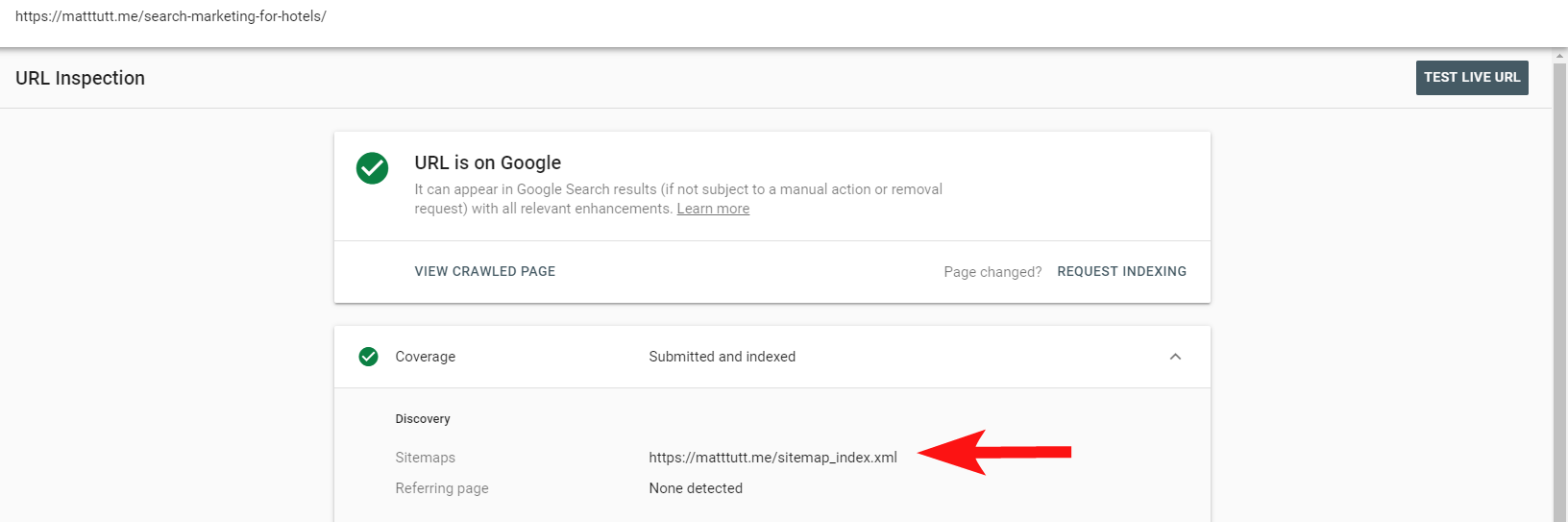
かなり小さなサイトがある場合は、ブラウザ内でXMLサイトマップを手動で確認できます。それ以外の場合は、ダウンロードして、インデックス可能なURLの完全なクロールと比較します。
多くの場合、Googleでsite:domain.com検索を実行して、インデックスに登録されているすべてのものを返すことにより、この種の低品質で貴重なコンテンツを見つけることができます。
ここで注目に値するのは、これには古いコンテンツが含まれている可能性があり、100%最新であると信頼すべきではないということですが、SEOの取り組みを膨らませたり、クロールの予算を使い果たしたりするコンテンツが大量にないことを確認するのは簡単です。
4 –Googlebotによるコンテンツのレンダリングに関する問題
これはそれに捧げられた記事全体に値するものであり、私は個人的に、Googleのフェッチおよびレンダリングツールで一生遊んだような気がします。
これについて(そしてJavaScriptについて)すでにいくつかの非常に有能なSEOによって多くのことが言われているので、これについてはあまり深く掘り下げませんが、Googlebotがサイトをどのようにレンダリングしているかをチェックすることは常にあなたの時間の価値があります。
オンラインツールを介していくつかのチェックを実行すると、Googlebotのブラインドスポット(サイト上のアクセスできない領域)、ホスティング環境の問題、問題のあるJavaScriptのリソースの焼き尽くし、さらには画面のスケーリングの問題を明らかにするのに役立ちます。
通常、これらのサードパーティツールは問題の診断に非常に役立ちます(たとえば、ロボットファイルが原因でリソースがブロックされた場合でもGoogleが通知します)が、場合によっては円を描くように動き回ることがあります。
問題のあるサイトの実例を示すために、私は自分の足で自分自身を撮影し、自分の個人的なWebサイトを参照します-そして私が使用している特にイライラするWordPressテーマ。
検索コンソールからURL検査を実行すると、「ページはモバイルフレンドリーではありません」という警告が表示されることがあります(以下を参照)。
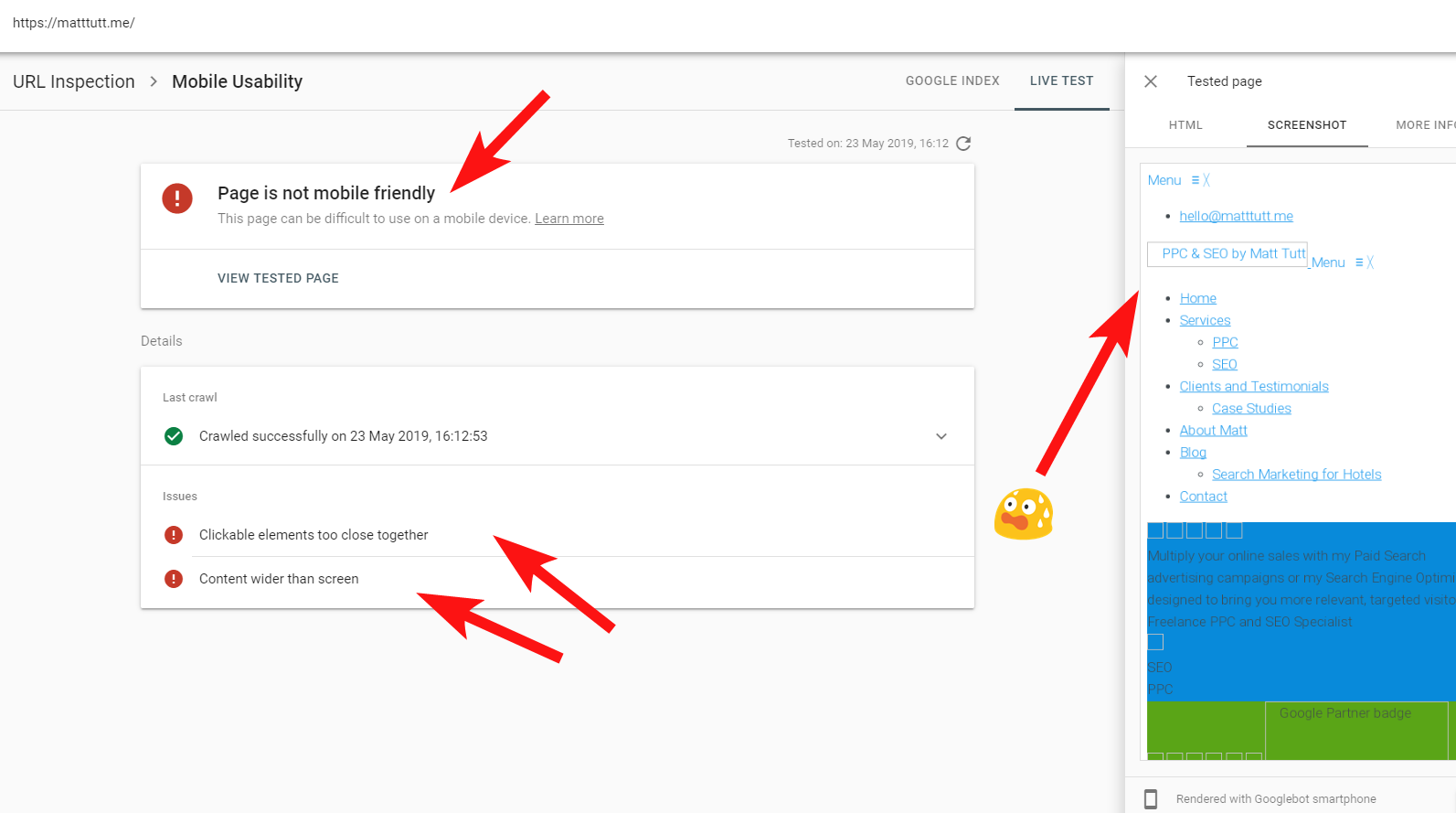
[詳細情報]タブ(右上)をクリックすると、Googlebotがアクセスできなかったリソースのリストが表示されます。これは主にCSSファイルと画像ファイルです。
これは、Googlebotがページのレンダリングに常に完全な「エネルギー」を与えることができないためである可能性があります。これは、Googleが私のサイト(一種のサイト)のクラッシュを警戒しているためである場合もあれば、使用したために制限される場合もあります。すでに私のサイトをフェッチしてレンダリングするための多くのリソース。
上記の理由から、より正確なストーリーを得るために、これらのテストを分散した間隔で数回実行する価値がある場合があります。 また、可能であればサーバーログを確認して、Googlebotがサイトのコンテンツにどのようにアクセスしたか(またはアクセスしなかったか)を確認することをお勧めします。
これらのリソースの404またはその他の悪いステータスは、特に一貫している場合は、明らかに悪い兆候です。
私の場合、Googleはサイトをモバイルフレンドリーではないと呼びかけています。これは主に、レンダリング中に特定のCSSスタイルファイルが失敗した結果であり、これは当然のことながら警告音を鳴らす可能性があります。
さらに紛らわしいことに、Googleによるモバイルフレンドリーテストを実行しているとき、または他のサードパーティツールを使用しているときは、問題は検出されません。サイトはモバイルフレンドリーです。
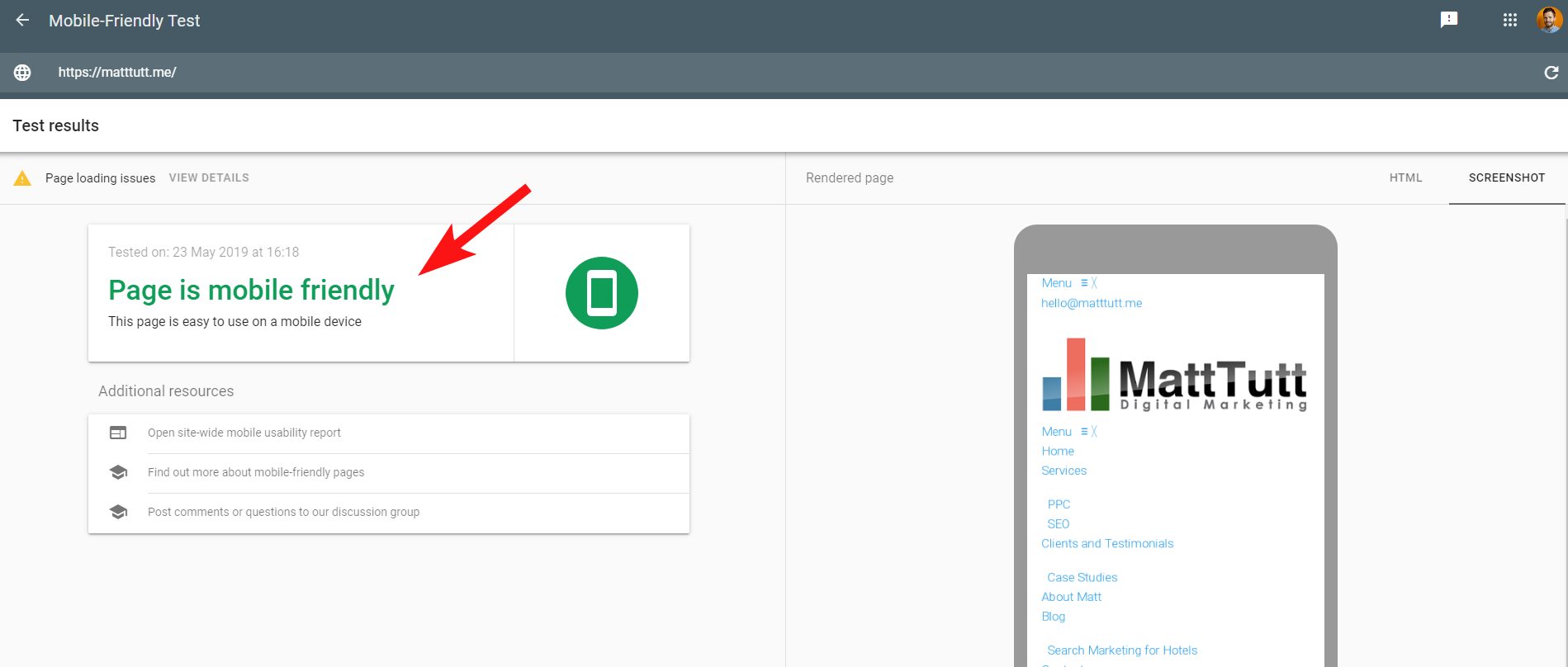
Googleからのこれらの矛盾するメッセージは、SEOやWeb開発者がデコードするのが難しい場合があります。 さらに理解するために、私は自分のWebホストをチェックすること(問題なし)とCSSファイルが実際にGoogleによってキャッシュできることを提案したJohnMuellerに連絡しました。
Search Consoleは、モバイルフレンドリーツールと比較して古いWebレンダリングサービス(WRS)を使用しているため、最近は後者に重点を置く傾向があります。
Googleが最新のレンダリング機能を備えた新しいGooglebotを発表したことで、これはすべて変更される可能性があるため、レンダリングチェックに使用するのに最適なツールを最新の状態に保つ価値があります。
ここでのもう1つのヒント–ページの完全なスクロール可能なレンダリングを表示したい場合は、Googleのモバイルテストツールから[HTML]タブに切り替え、CTRL + Aを押してレンダリングされたすべてのHTMLコードを強調表示してから、コピーしてテキストエディターに貼り付けます。 HTMLファイルとして保存します。
それをブラウザで開くと(指が交差している場合もありますが、使用するCMSによって異なります!)、スクロール可能なレンダリングが表示されます。 また、これの利点は、サイトがどのようにレンダリングされるかを確認できることです。検索コンソールにアクセスする必要はありません。
5 –ハッキングされたサイトとスパムのバックリンク
これは非常に楽しいものであり、古いバージョンのWordPressや定期的なセキュリティ更新が必要な他のCMSプラットフォームで実行されているサイトに忍び寄ることがよくあります。
このクライアント(ビューティースパ)では、検索コンソール内に奇妙な検索用語が表示されていることに気づきました。
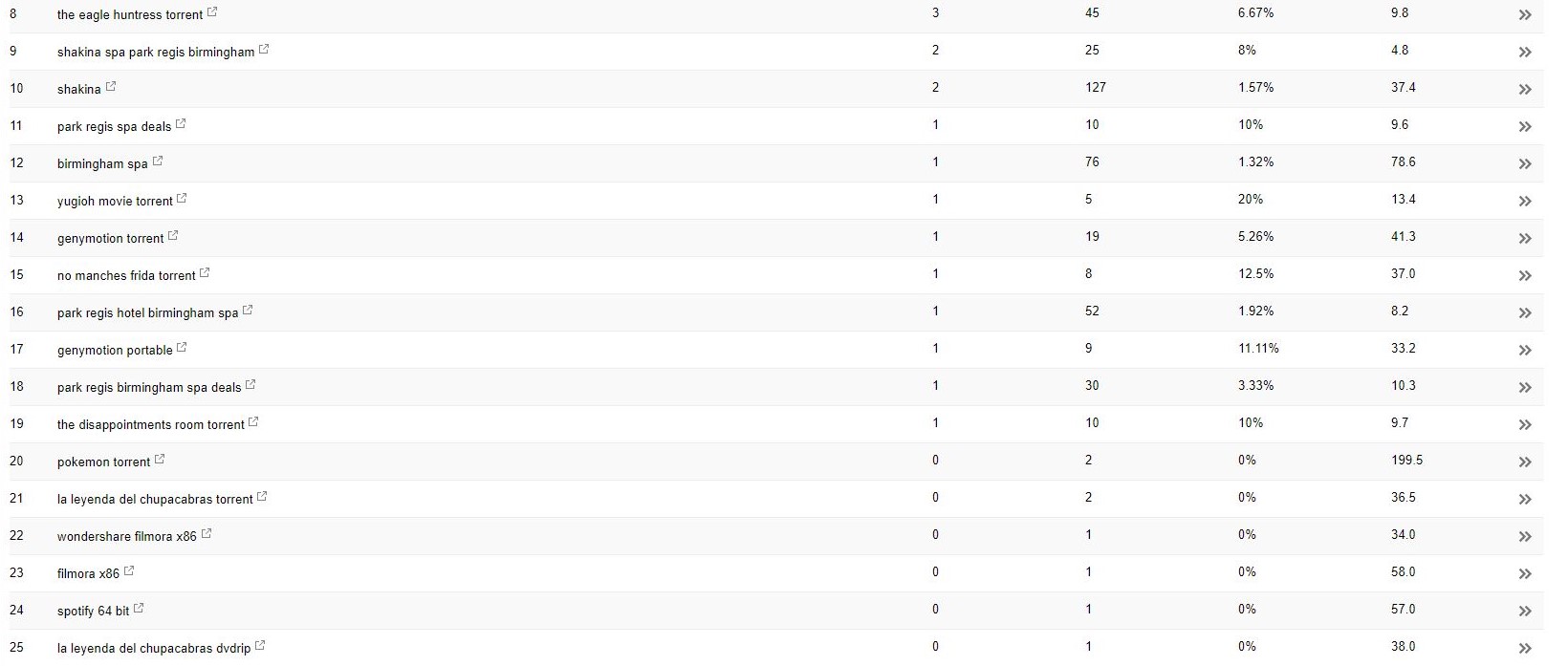
驚いたことに、検索コンソール内のインプレッションだけでなく、クリック数もありました。つまり、ドメインで何かがインデックスに登録されている必要があります。
クエリから判断すると、それは明らかに非常にスパムであり、クライアントがビジネスに関連付けたいものではありませんでした。
Googleで簡単な「site:domain.com」検索を実行すると、クライアントがサイトでホストしていると思われる数百ページのトレントが見つかりました。
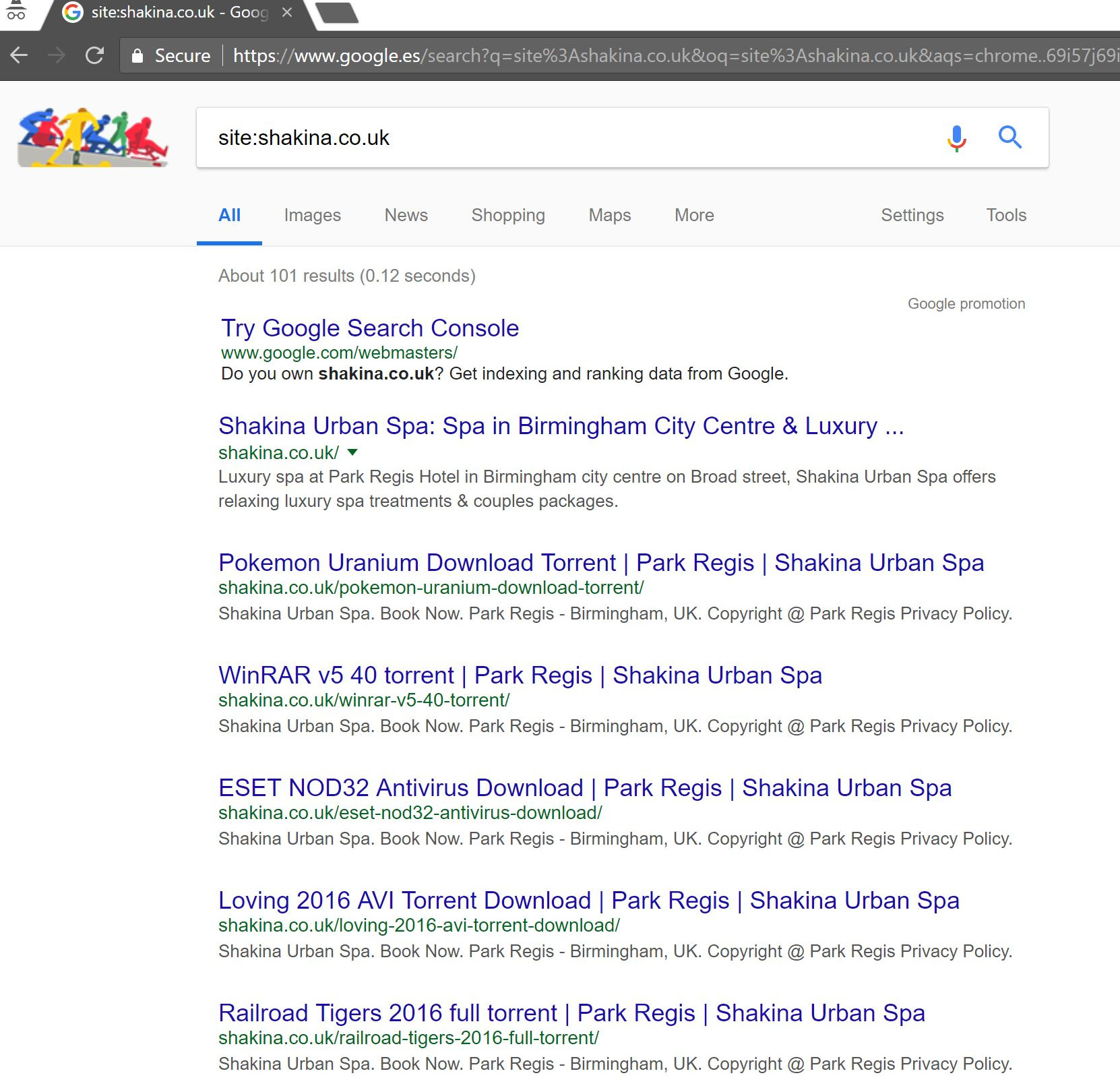
これらのURLのいずれかにアクセスすると、実際には404になりましたが、それでもインデックスが作成されていました(さまざまなユーザーエージェントもチェックしましたが、すべて同じ404エラーが発生しました)。

次に、Majesticのバックリンクチェッカーを介してドメインを実行すると、クライアントサイトのこれらのページを指す非常に低品質のバックリンクの長いリストが表示されました。これは、インデックスを作成するのに役立つ可能性があります。
バックリンクのマジェスティックのアンカークラウドを見ると、問題の範囲が実際にわかりました。

ここでの唯一の修正は、ドメインごとにこれらすべてのバックリンクを否認し、コードインジェクションをクリアすることを期待してWordPressインストールのクリーンスイープを実行するか、WordPressの新しいコピーをインストールすることでした。
上記のような場合にインデックス付きコンテンツが本当に心配な場合は、410ステータスコードを提供して、検索クローラーで物事を明確にすることもできます。
上記は、映画プロデューサーからの著作権侵害の申し立てにより法的な警告が出されたサイトに適しています。このような状況では、問題がすぐに解決されない場合に発生する可能性があります。
6 –悪い国際SEO設定
スペインに拠点を置いていますが、母国語の英語でインターネットを閲覧していると、スペイン語版のWebサイトに自動的にリダイレクトされることがよくあります。
私はロジックを理解していますが(私はスペインに拠点を置いているため、スペイン語でサイトを閲覧したい)、ユーザーエクスペリエンスの観点からはかなり面倒であり、正しく行わないと、国際的なSEOに多少の混乱を引き起こす可能性があります。
Google広告のようなサイトは、これを別のレベルに引き上げます。AngularJavaScriptを利用して、現在地に基づいてコンテンツを動的に生成します。いかなる種類のページリダイレクトも通過せず、DOMにコンテンツをロードしません。
複数の言語が利用可能な場合に選択する私の好ましい方法は、インターネットブラウザの設定に基づいてユーザーを言語にリダイレクトすることです。
したがって、誰かがGoogle Chromeのデフォルト言語としてドイツ語を使用している場合、物理的な場所に関係なく、ドイツ語でサイトを読むことに慣れている可能性があります。
これは、フランス語、イタリア語、ドイツ語、ロマンシュ語がすべて使用されているスイスのように、さまざまな言語が話されている地域に誰かが拠点を置いている場合にも、問題を解決するのに役立ちます。
また、使いやすさの観点から、ユーザーが切り替えたい場合に備えて、好みに基づいて言語を切り替えるオプションがあることを確認することも重要です。
あるケースでは、バルセロナに拠点を置くホテルで働いていました。そこでは、JavaScript言語のリダイレクトスクリプトが、SEOの影響を考慮せずにサイトに追加されました。
このスクリプトは、クライアント側のJavaScriptリダイレクトを介して、ブラウザーの言語設定(それ自体はそれほど悪くはありません)に基づいてユーザーをリダイレクトしました。
残念ながら、この場合、サイトのパーマリンクの設定がおかしいため、スクリプトが正しく設定されませんでした。また、サイトのすべてのページにHTML langタグがないという事実と組み合わせると、Googlebotは少しおかしくなりました…
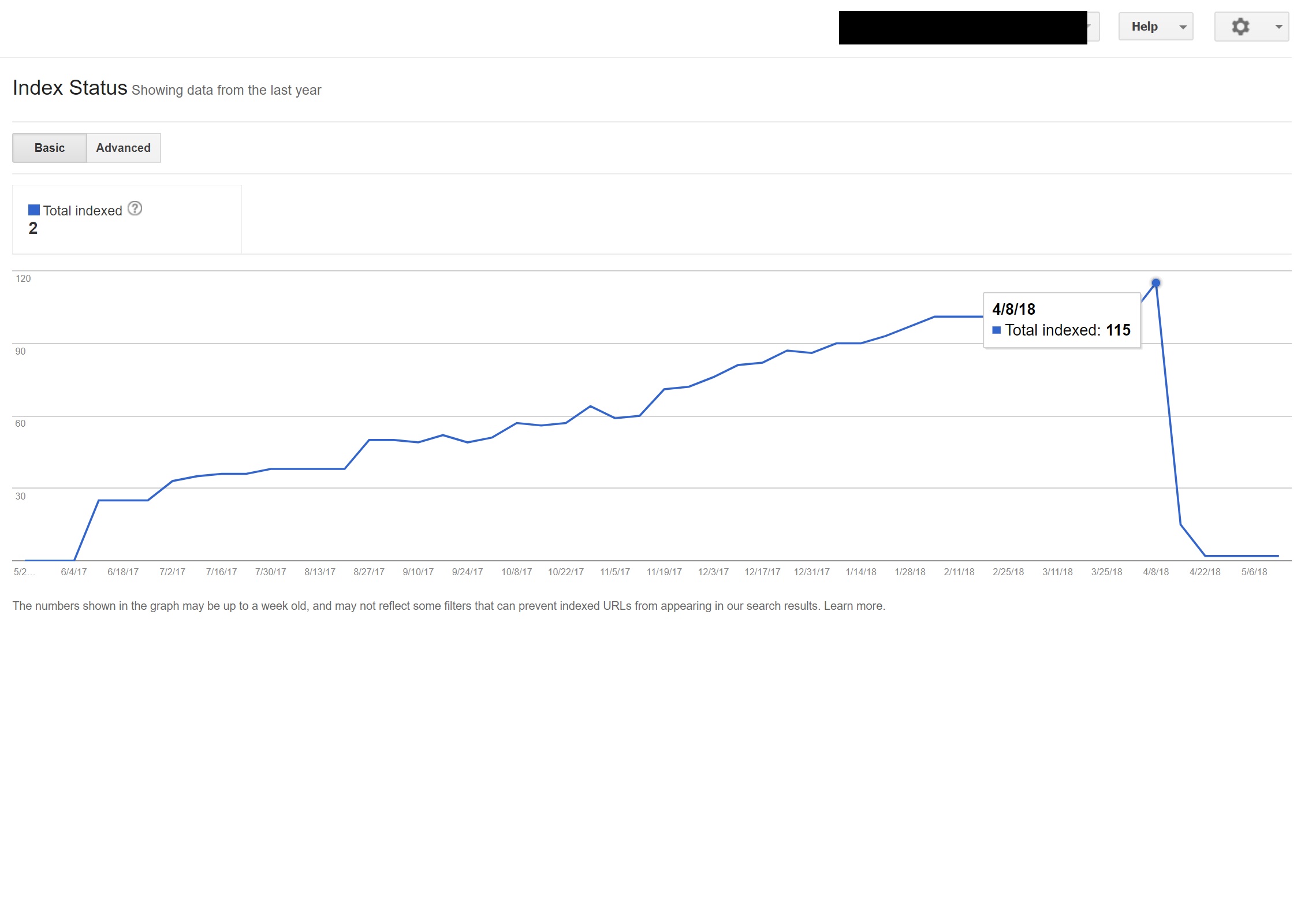
この例では、サイト上の英語以外のコンテンツのほぼすべてがGoogleによってインデックス解除されました。これは、存在しないページにリダイレクトされ、複数の404エラーが発生したためです。
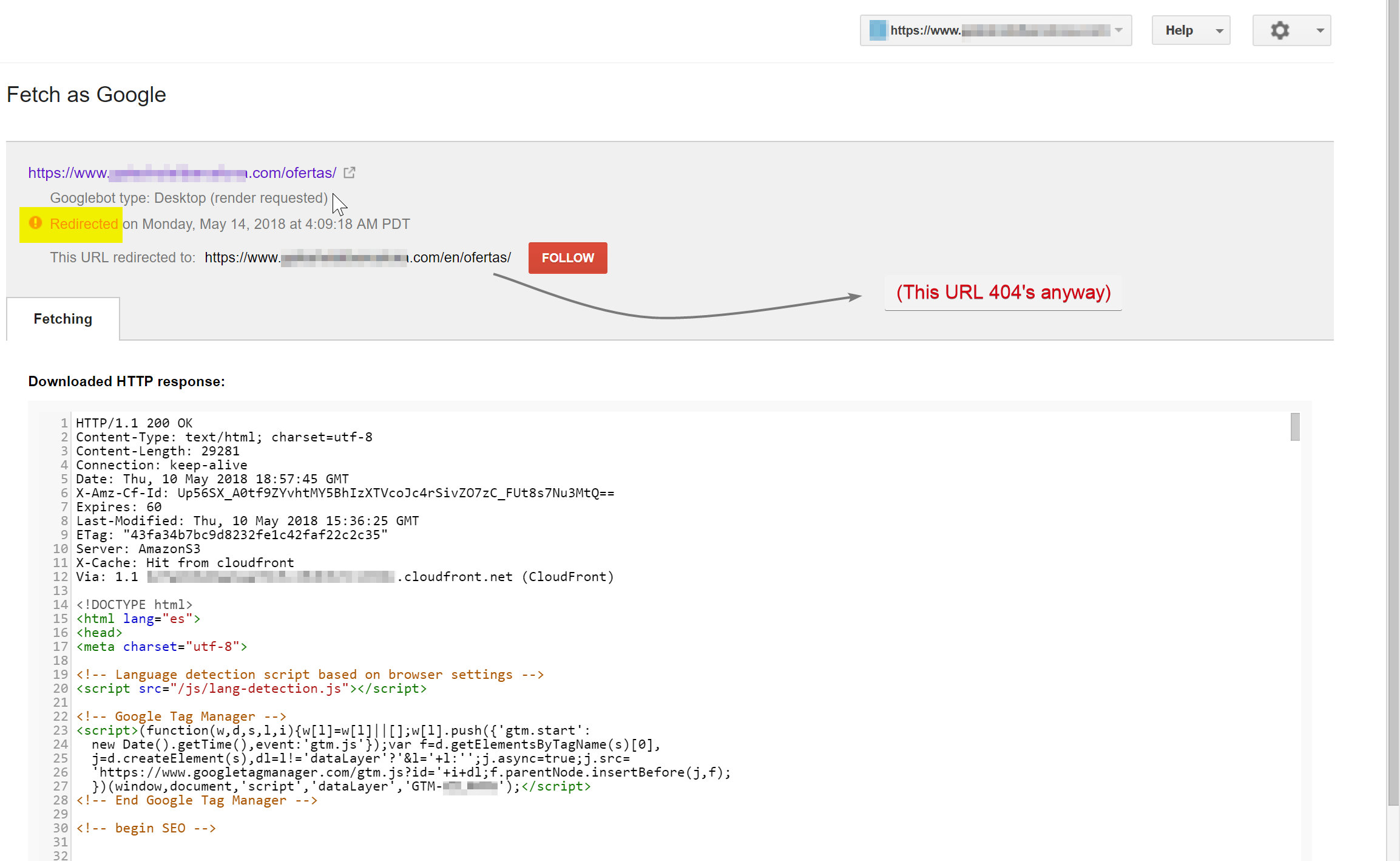
Googlebotはスペイン語のコンテンツ(hotelname.com/ofertasに存在)をクロールしようとしていて、存在しないURLであるhotelname.com/en/ofertasにリダイレクトされていました。
驚いたことに、この場合、GooglebotはこれらすべてのJavaScriptリダイレクトを追跡しており、これらのURLを見つけることができなかったため、インデックスからそれらを削除することを余儀なくされました。
上記の場合、サイトのサーバーログにアクセスし、Googlebotにフィルターをかけて、404が提供されている場所を確認することで、これを確認できました。
欠陥のあるJavaScriptリダイレクトスクリプトを削除することで問題が解決し、幸いなことに、翻訳されたページのインデックスが解除されることはありませんでした。
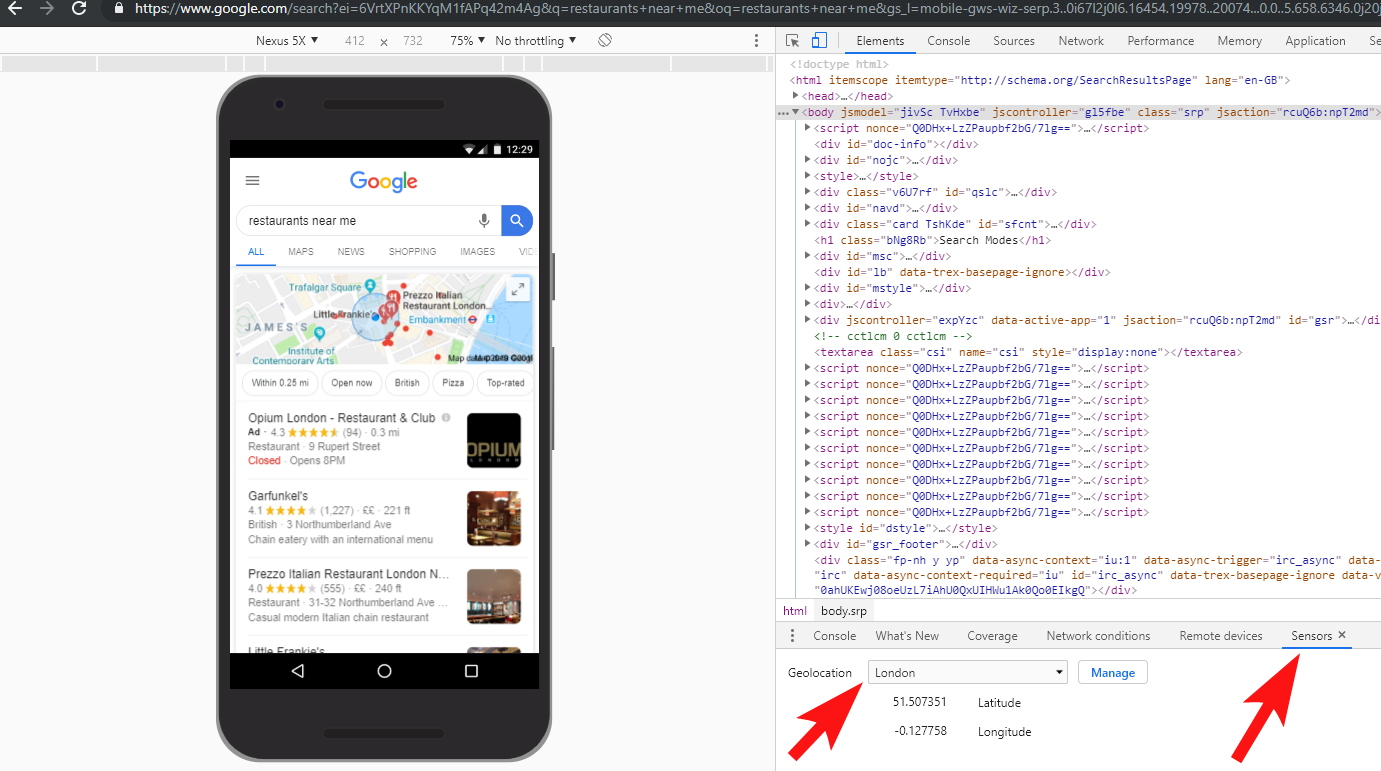
物事を完全にテストすることは常に良い考えです。VPNに投資することで、これらのタイプのシナリオを診断したり、Chromeブラウザ内の場所や言語を変更したりすることができます。
[ケーススタディ]複数のサイト監査の処理
 ケーススタディを読む
ケーススタディを読む7 –重複コンテンツ
重複コンテンツは非常に一般的でよく議論されている問題であり、サイトで重複コンテンツをチェックする方法はたくさんあります。RichardBaxterは最近、このトピックに関するすばらしい記事を書きました。
私の場合、問題はおそらくかなり単純です。 多くの場合ブログ投稿として優れたコンテンツを公開しているサイトを定期的に見ていますが、その一部のコンテンツをMedium.comなどのサードパーティのWebサイトでほぼ瞬時に共有しています。
Mediumは、既存のコンテンツを転用してより多くの視聴者にリーチするのに最適なサイトですが、このアプローチには注意が必要です。
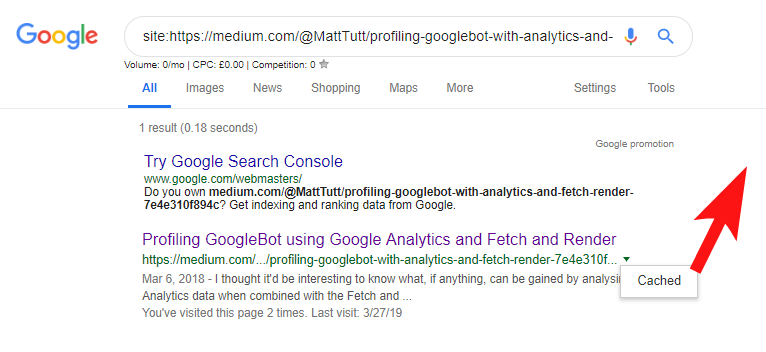
WordPressからMediumにコンテンツをインポートする場合、このプロセス中、MediumはWebサイトのURLを正規タグとして使用します。 したがって、理論的には、元のソースとして、Webサイトにコンテンツのクレジットを与えるのに役立つはずです。
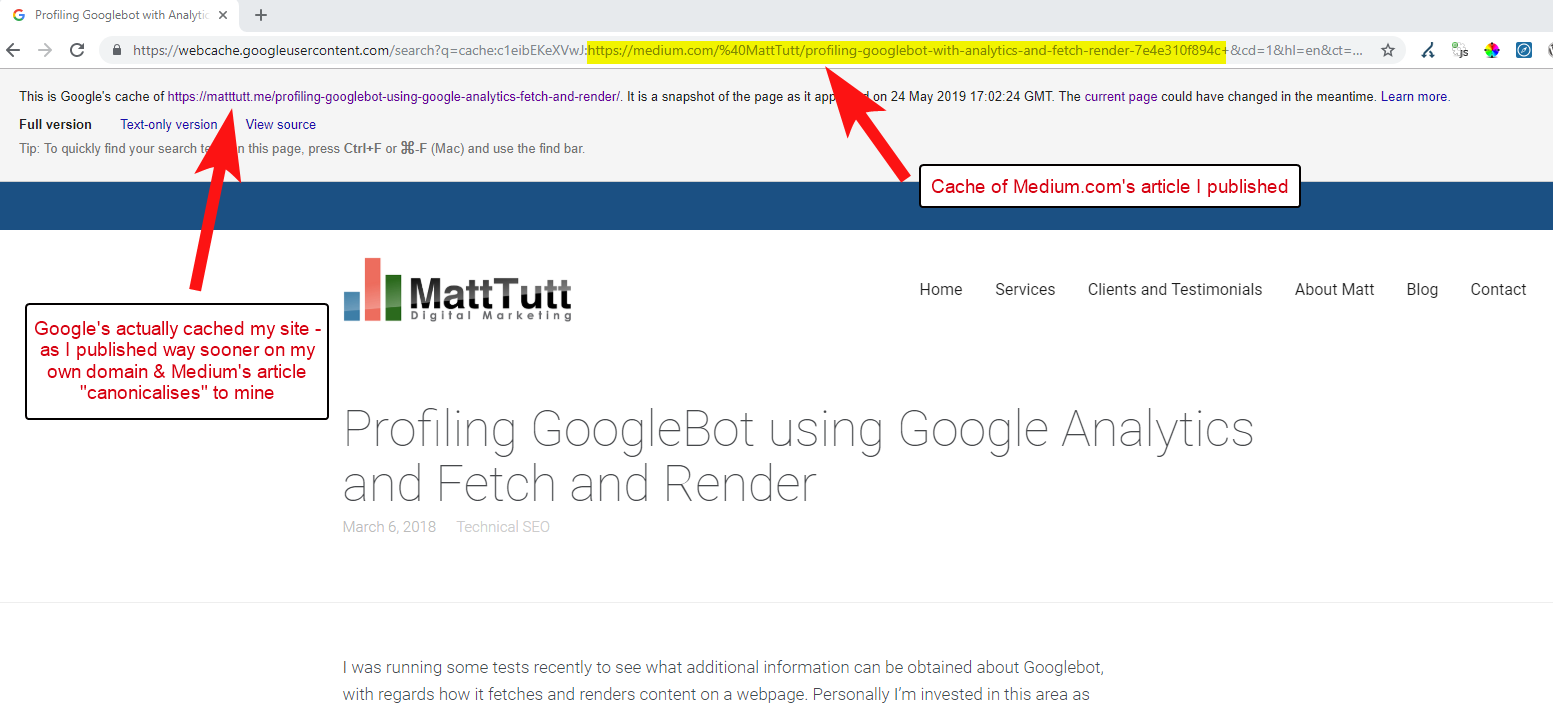
私の分析のいくつかから、それは常にこのように機能するとは限りませんが。
これが当てはまると思うのは、最初にGoogleがドメインで記事をクロールしてインデックスに登録する時間を許可せずに、記事がMediumで公開された場合、記事がMediumでうまく機能しなくなった場合(少しヒットまたはミス)、コンテンツが取得されるためです。正規のあなたのサイトを指しているにもかかわらず、インデックスが作成され、Mediumのサイトに関連付けられています。
コンテンツがMediumに追加されると(特に人気がある場合)、その作品がほぼ瞬時にスクレイプされてWebで再公開されることをほぼ保証できます。したがって、コンテンツは他の場所で複製されます。
これはすべて進行中ですが、ドメインが権限の点で非常に小さい場合、Googleは公開したコンテンツをクロールしてインデックスに登録する機会さえなかった可能性があります。また、クロール/インデックス作成がまだ完了していないか、JavaScriptが重いため、そのコンテンツのクロール、レンダリング、インデックス作成の間に大きなタイムラグが発生します。
大企業が素晴らしい記事を公開する状況を見てきましたが、翌日、彼らはそれを大規模な業界ニュースブログの思考記事として公開します。 これに加えて、彼らのサイトには、https://domain.comとhttps://www.domain.comでコンテンツが複製(およびインデックス付け)されるという問題がありました。
公開から数日後、Google内で引用符で囲まれた記事の正確なフレーズを検索したところ、会社のWebサイトはどこにも表示されませんでした。 代わりに、権威ある業界のブログが最初にあり、他の再発行者が次の位置を占めていました。
その場合、コンテンツは業界のブログに関連付けられているため、作品が獲得するリンクは、元の発行元ではなく、そのWebサイトに利益をもたらします。
ウェブ上のどこかでコンテンツを転用する場合は、インデックスに登録される可能性があります。自分のドメインでGoogleによってインデックスに登録されていることを完全に確認できるまで、実際に待つ必要があります。
あなたはおそらくあなたのコンテンツを作成して作成するために一生懸命働いています-他の場所で再公開することに熱心すぎてそれをすべて捨てないでください!
8 –不正なAMP構成(AMP URL宣言がありません)
私が支援したほんの一握りのクライアントだけが、おそらくその使用に関する多くのGoogle資金によるケーススタディのいくつかに基づいて、AMPを試してみることにしました。
クライアントが自分のサイトのAMPバージョンを持っていることに気付かないこともありました。Analyticsの参照レポートに奇妙なトラフィックが表示され、AMPバージョンのサイトが非AMPサイトのバージョンにリンクしていました。
その場合、非AMPページの先頭からのURL参照がなかったため、AMPページのバージョンが正しく設定されていませんでした。

AMPページが特定のURLに存在することを検索エンジンに通知しなければ、AMPを設定してもあまり意味がありません。重要なのは、AMPページがインデックスに登録され、モバイルユーザーのSERPSに返されるということです。
非AMPページへの参照を追加することは、AMPページについてGoogleに伝える重要な方法です。また、AMPページの正規タグは自己参照であってはならず、非AMPページにリンクしていることを覚えておくことが重要です。
また、実際には技術的なSEOの考慮事項ではありませんが、トラフィックやユーザーの行動情報をレポートできるようにする場合は、AMPページにトラッキングコードを含める必要があることに注意してください。
通常、SEO監査の一環として、分析実装の基本的なチェックも実行するのが好きです。そうしないと、提供されたデータが実際にはそれほど役に立たない場合があります。
9 –リダイレクトまたはリダイレクトのチェーンを形成するレガシードメイン
過去数年間にいくつかのブランド変更が行われた米国の大規模な独立系ホテルブランド(ホスピタリティ業界ではかなり一般的)と連携する場合、以前のドメイン名リクエストがどのように動作するかを監視することが重要です。
これは忘れがちですが、OnCrawlなどのツールを使用して古いサイトをクロールしようとする単純な半定期的なチェック、またはステータスコードとリダイレクトをチェックするサードパーティのサイトでさえあり得ます。
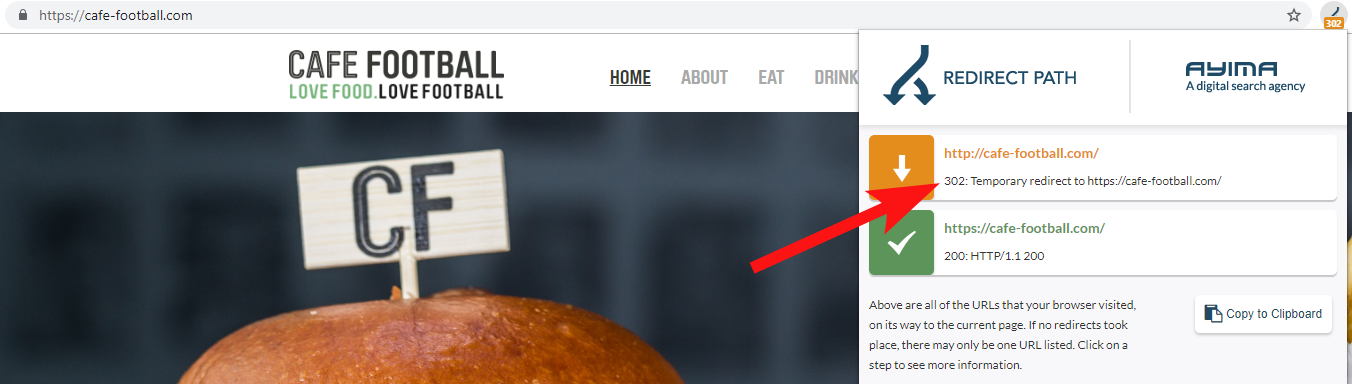
多くの場合、ドメイン302は最終的な宛先にリダイレクトするか(301は常にここで最善の策です)、または302は、最終的なURLに到達する前にさらにいくつかのリダイレクトをジャンプする前に、非WWWバージョンのURLにリダイレクトします。
グーグルのジョン・ミューラーは以前、あきらめる前に5つのリダイレクトしかたどらないと述べていましたが、渡されたリダイレクトごとにリンク値の一部が失われることも知られています。 これらの理由から、私は可能な限りクリーンな301リダイレクトに固執することを好みます。
Ayimaによるリダイレクトパスは、ウェブを閲覧しているときにリダイレクトステータスを表示する優れたChromeブラウザ拡張機能です。
クライアントに属する古いドメイン名を検出するもう1つの方法は、Googleで電話番号を検索するか、完全一致の引用符またはアドレスの一部を使用することです。
ホテルのようなビジネスでは、住所(少なくともその一部)は変更されないことが多く、古いドメインにリンクしている古いディレクトリ/ビジネスプロファイルが見つかる場合があります。
MajesticやAhrefsなどのバックリンクツールを使用すると、以前のドメインからの古いリンクも表示される可能性があるため、特にクライアントと直接連絡していない場合は、これも優れた呼び出しポートです。
10 –内部検索コンテンツの不適切な取り扱い
これは実際、私が以前OnCrawlで書いたトピックですが、問題のある内部コンテンツが「実際に」頻繁に発生しているのをまだ見ているので、再度含めます。
この記事は、Pingdomのrobots.txtディレクティブの問題について話し始めました。これは、外部からは、出力されているコンテンツがクロールされてインデックスに登録されないようにするための修正であるように見えました。
内部検索結果をコンテンツとしてGoogleに提供するサイト、またはユーザーが生成したコンテンツを大量に出力するサイトは、その方法に細心の注意を払う必要があります。
サイトが非常に直接的な方法でGoogleに内部検索結果を提供している場合、これはある種の手動ペナルティにつながる可能性があります。 Googleは、ユーザーエクスペリエンスが悪いと見なす可能性があります。つまり、Xを検索してからサイトにアクセスし、必要なものを手動でフィルタリングする必要があります。
場合によっては、内部コンテンツを提供することは問題ないと思いますが、それはコンテキストと状況によって異なります。 たとえば、求人サイトでは、ほぼ毎日更新される最新の求人結果を提供したい場合があります。そのため、ほとんどの場合、これに対処する必要があります。
確かに、これをやりすぎて、人気のある検索クエリに基づいてあらゆる種類のコンテンツを生成する求人サイトの有名な例です(この戦術を使用した場合に何が起こるかについては、以下を参照してください)。
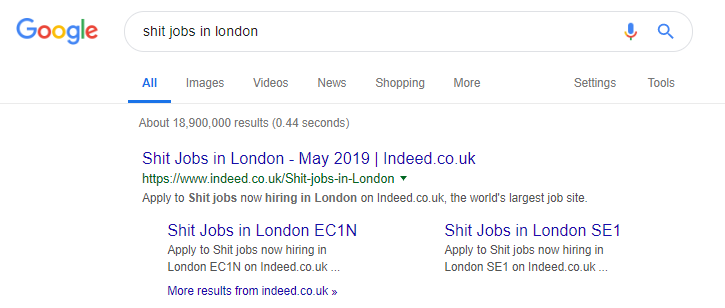
それにもかかわらず、SEMRushデータによると、彼らのオーガニックトラフィックは順調に進んでいますが、これらは細い線であり、このように動作すると、Googleのペナルティのリスクが高くなります。
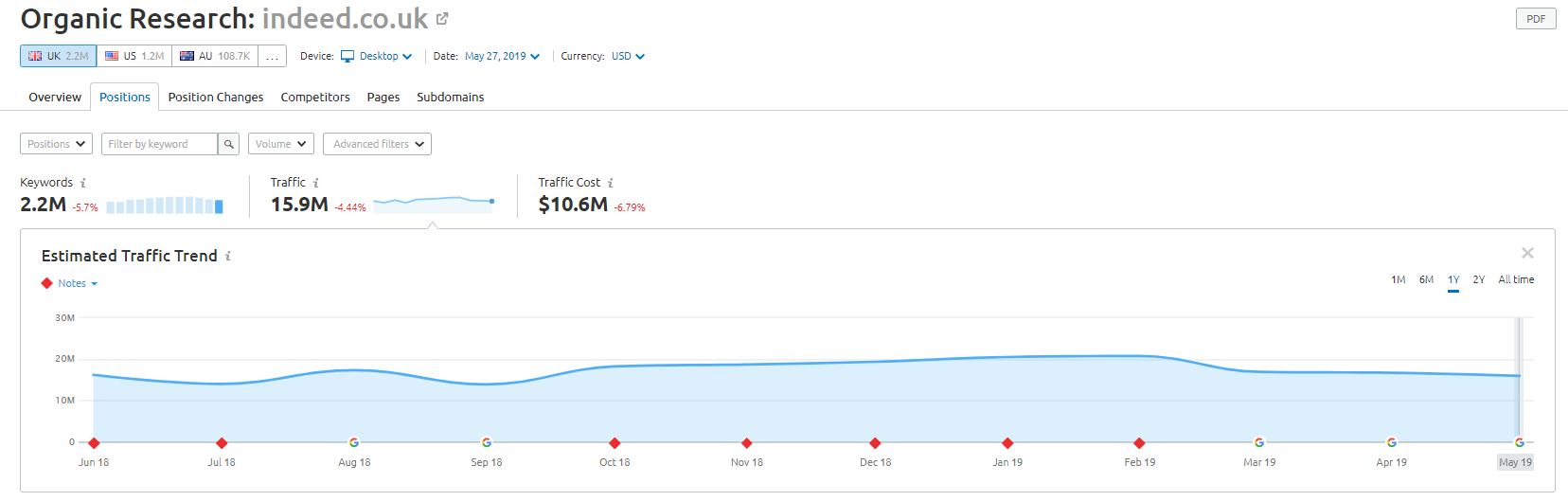
オンライン小売業者のWayfair.comは、風の近くを航行するのが好きなもう1つのブランドです。 何百万ものインデックス付きURL(および自動生成されたキーワードURLがたくさんある)は、オーガニックトラフィックの点で優れていますが、検索エンジンにこの方法でコンテンツを提供するとペナルティを受けるリスクが高くなります。
すべてのコンテンツの分類、さまざまな親/子階層の構築、タグやその他のカスタム分類法の使用を含む適切なサイト構造を実装することで、顧客や検索クローラーのナビゲーションを支援できます。
上記のようなトリックを使用すると、短期的には勝つ可能性がありますが、長期的にはあまり効果がありません。 これにより、サイト構造を最初から正しく理解するか、少なくとも事前に適切に計画することが重要になります。
まとめ
この記事で説明する10個のエラーは、サイト監査中に発生する最も一般的な技術的な問題の一部です。
サイトでこれらのエラーを修正することは、サイトが技術的に正常であることを確認するための最初のステップです。 これらの問題が修正されると、技術監査はサイトに固有の問題に集中できます。