
AWS サービスに基づくビジネスインテリジェンスパイプライン – ケーススタディ
公開: 2019-05-16近年、ビッグデータ分析への関心が高まっています。 エグゼクティブ、マネージャー、およびその他のビジネス関係者は、ビジネス インテリジェンス (BI) を使用して、十分な情報に基づいた意思決定を行います。 重要な情報を即座に分析し、直感だけでなく、顧客の実際の行動から学べることに基づいて意思決定を行うことができます。
効果的で有益な BI ソリューションを作成することを決定した場合、開発チームが行う必要がある最初のステップの 1 つは、データ パイプライン アーキテクチャを計画することです。 このようなパイプラインの構築に適用できるクラウドベースのツールはいくつかありますが、すべてのビジネスに最適なソリューションは 1 つではありません。 特定のオプションを決定する前に、現在の技術スタック、ツールの価格、開発者のスキル セットを考慮する必要があります。 この記事では、Timesheets アプリケーションの一部として正常にデプロイされたAWS ツールで構築されたアーキテクチャを紹介します。
アーキテクチャの概要
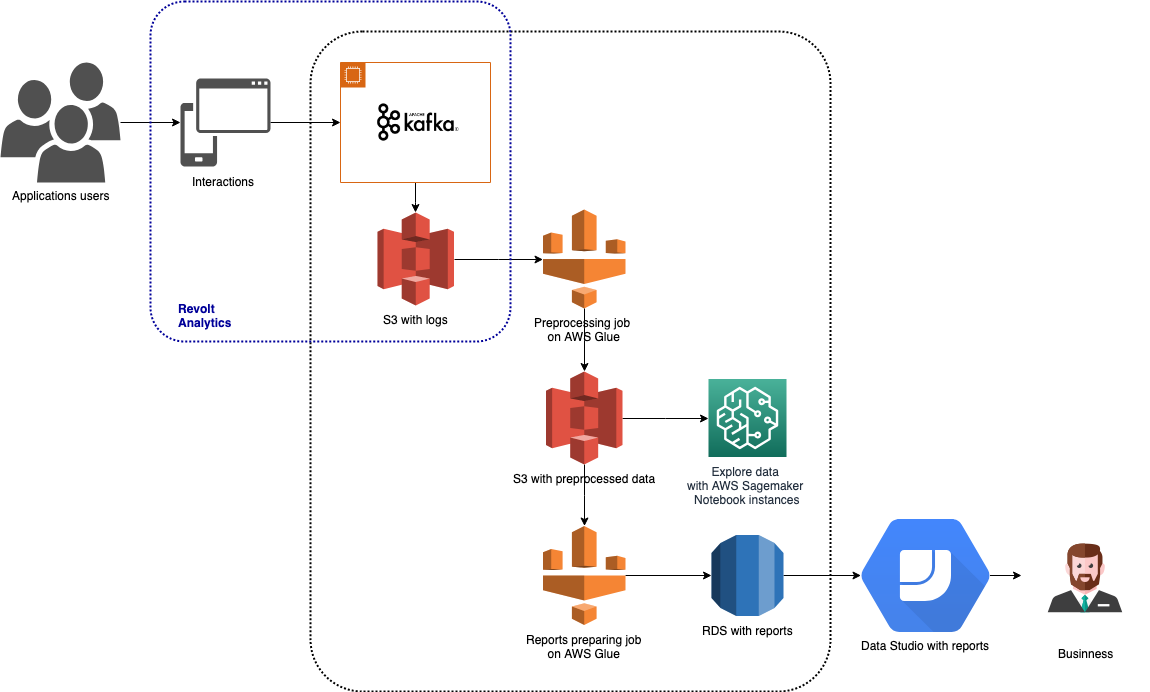
タイムシートは、従業員の時間を追跡および報告するためのツールです。 Web、iOS、Android、デスクトップ アプリケーション、ハングアウトや Slack と統合されたチャットボット、Google アシスタントでの操作を介して使用できます。 利用可能なアプリの種類が多いため、追跡するデータも多種多様です。 データは Revolt Analytics で収集され、Amazon S3 に保存され、AWS Glue と Amazon SageMaker で処理されます。 分析の結果は Amazon RDS に保存され、Google Data Studio で視覚的なレポートを作成するために使用されます。 このアーキテクチャは、上のグラフに示されています。
以下の段落では、このアーキテクチャで使用される各ビッグ データ ツールについて簡単に説明します。
反乱分析
Revolt Analytics は、あらゆるタイプのアプリケーションからのデータを追跡および分析するために Miquido によって開発されたツールです。 クライアント システムでの Revolt の実装を簡素化するために、iOS、Android、JavaScript、Go、Python、および Java SDK が構築されています。 Revolt の重要な機能の 1 つはそのパフォーマンスです。すべてのイベントはキューに入れられ、保存され、パケットで送信されるため、迅速かつ効率的に配信されます。 Revolt により、アプリケーションの所有者は、ユーザーを識別し、アプリ内での行動を追跡することができます。 これにより、完全にパーソナライズされたレコメンデーション システムやチャーン予測モデルなどの価値をもたらす機械学習モデルや、ユーザーの行動に基づく顧客プロファイリングを構築できます。 Revolt は、セッション化機能も提供します。 アプリケーションでのユーザー パスと動作に関する知識は、顧客の目標とニーズを理解するのに役立ちます。
Revolt は、選択したインフラストラクチャにインストールできます。 このアプローチにより、コストと追跡されたイベントを完全に制御できます。 この記事で紹介した Timesheets のケースでは、AWS インフラストラクチャ上に構築されました。 データ ストレージへのフル アクセスのおかげで、製品の所有者はアプリケーションを簡単に把握し、そのデータを他のシステムで使用できます。
Revolt SDK は、タイムシート システムのすべてのコンポーネントに追加されます。
- Android & iOS アプリ (Flutter で構築)
- デスクトップアプリ (Electron でビルド)
- Web アプリ (React で作成)
- バックエンド (Golang で作成)
- ハングアウトと Slack のオンライン チャット
- Action on Google アシスタント
Revolt は、Timesheets 管理者に、アプリの顧客が使用するデバイス (デバイスのブランド、モデルなど) とシステム (OS のバージョン、言語、タイムゾーンなど) に関する情報を提供します。 さらに、アプリでのユーザーのアクティビティに関連するさまざまなカスタム イベントを送信します。 その結果、管理者はユーザーの行動を分析し、ユーザーの目的と期待をよりよく理解できます。 また、実装された機能の使いやすさを検証し、これらの機能が製品所有者の使用方法に関する想定を満たしているかどうかを評価することもできます。

AWS グルー
AWS Glue は、分析タスク用のデータの準備を支援する ETL (抽出、変換、ロード) サービスです。 Apache Spark サーバーレス環境で ETL ジョブを実行します。 通常、次の 3 つの要素で構成されます。
- クローラー定義– クローラーは、あらゆる種類のリポジトリとソースのデータをスキャンし、分類し、それらからスキーマ情報を抽出し、それらに関するメタデータを Data Catalog に保存するために使用されます。 たとえば、Amazon S3 の JSON ファイルに保存されたログをスキャンし、そのスキーマ情報を Data Catalog に保存できます。
- ジョブスクリプト– AWS Glue ジョブは、データを目的の形式に変換します。 AWS Glue は、データをロード、クリーニング、および変換するためのスクリプトを自動的に生成できます。 また、必要な変換を実行する Python または Scala で記述された独自の Apache Spark スクリプトを提供することもできます。 null 値の処理、セッション化、集計などのタスクを含めることができます。
- トリガー– クローラーとジョブは、オンデマンドで実行したり、指定したトリガーが発生したときに開始するように設定したりできます。 トリガーは、時間ベースのスケジュールまたはイベント (指定されたジョブの正常な実行など) です。 このオプションを使用すると、レポートのデータの鮮度を簡単に管理できます。
タイムシート アーキテクチャでは、パイプラインのこの部分は次のようになります。
- 時間ベースのトリガーによって前処理ジョブが開始され、データ クリーニングが実行され、セッションに適切なイベント ログが割り当てられ、初期集計が計算されます。 このジョブの結果データは AWS S3 に保存されます。
- 2 番目のトリガーは、前処理ジョブが正常に完了した後に実行されるように設定されています。 このトリガーは、製品所有者によって分析されたレポートで直接使用されるデータを準備するジョブを開始します。
- 2 番目のジョブの結果は、AWS RDS データベースに保存されます。 これにより、Google Data Studio、PowerBI、Tableau などのビジネス インテリジェンス ツールで簡単にアクセスして使用できるようになります。
AWS SageMaker
Amazon SageMaker は、機械学習モデルを構築、トレーニング、デプロイするためのモジュールを提供します。
あらゆる規模でのモデルのトレーニングとチューニングが可能になり、AWS が提供する高性能アルゴリズムを使用できるようになります。 それにもかかわらず、適切な Docker イメージを提供した後、カスタム アルゴリズムを使用することもできます。 また、AWS SageMaker は、さまざまなモデル パラメータ セットのメトリクスを比較する設定可能なジョブを使用して、ハイパーパラメータの調整を簡素化します。
Timesheets では、SageMaker Notebook Instances は、データの調査、ETL スクリプトのテスト、およびレポート作成用の BI ツールで使用される視覚化チャートのプロトタイプの準備に役立ちます。 このソリューションは、データ サイエンティストが同じ開発環境で作業できるようにするため、データ サイエンティストのコラボレーションをサポートおよび改善します。 さらに、ノートブックは AWS S3 バケットにのみ保存され、同僚間で作業を共有するために git リポジトリは必要ないため、機密データ (ノートブックのセルの出力の一部である可能性があります) が AWS インフラストラクチャを超えて保存されないようにするのに役立ちます。 .
要約
ビジネス インテリジェンス ソリューションのパイプライン アーキテクチャを設計するには、どのビッグ データ ツールと機械学習ツールを使用するかを決定することが重要です。 この選択は、システムの機能、コスト、および将来の新機能の追加の容易さに大きな影響を与える可能性があります。 AWS ツールは確かに検討する価値がありますが、現在の技術スタックと開発チームのスキルに合った技術を選択する必要があります。
未来志向のソリューションを構築する当社の経験を活用して、お問い合わせください!