
Oncrawl以外のOncrawlデータで複雑なデータの質問に答える方法
公開: 2022-01-04エンタープライズSEO向けのOncrawlの利点の1つは、生データに完全にアクセスできることです。 SEOデータをBIまたはデータサイエンスワークフローに接続する場合でも、独自の分析を実行する場合でも、組織のデータセキュリティガイドラインの範囲内で作業する場合でも、生のSEOおよびWebサイトの監査データは多くの目的に役立ちます。
今日は、Oncrawlデータを使用して複雑なデータの質問に答える方法を見ていきます。
複雑なデータの質問とは何ですか?
複雑なデータの質問は、単純なデータベース検索では答えられない質問ですが、答えを得るためにデータ処理が必要です。
SEOがよく行う「複雑な」データの質問の一般的な例を次に示します。
- ステータスが404の他のページにリダイレクトするページを指すすべてのリンクのリストを作成する
- URL以外の指標に基づいて、セグメンテーション内のページを指すすべてのリンクとそのアンカーテキストのリストを作成する
Oncrawlで複雑なデータの質問に答える方法
Oncrawlのデータ構造は、ほぼすべてのサイトがほぼリアルタイムでデータを検索できるように構築されています。 これには、インターフェイスでのルックアップ時間を最小限に抑えるために、さまざまなタイプのデータをさまざまなデータセットに保存することが含まれます。 たとえば、URLに関連付けられたすべてのデータを1つのデータセットに保存します:応答コード、送信リンクの数、存在する構造化データのタイプ、単語の数、オーガニック訪問の数…そしてリンクに関連するすべてのデータを別のデータセットに保存します。リンクターゲット、リンクオリジン、アンカーテキスト…
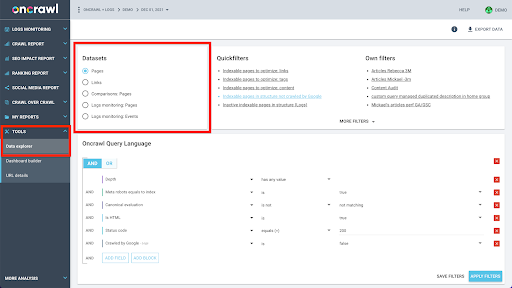
これらのデータセットの結合は計算が複雑であり、Oncrawlアプリケーションのインターフェースで常にサポートされているわけではありません。 別のデータセットで何かを検索するために1つのデータセットをフィルタリングする必要がある何かを検索することに興味がある場合は、生データを自分で操作することをお勧めします。
すべてのOncrawlデータを利用できるため、データセットを結合して複雑なクエリを表現する方法はたくさんあります。
この記事では、Google CloudとBigQueryを使用して、そのうちの1つを見ていきます。これは、大量のページがあるサイトのデータを調べるときに多くのクライアントが遭遇するような非常に大きなデータセットに適しています。
必要なもの
この記事で説明する方法に従うには、次のツールにアクセスする必要があります。
- オンクロール
- ビッグデータエクスポートを使用したOncrawlのAPI
- Google Cloud Storage
- BigQuery
- OncrawlからBigQueryにデータを転送するためのPythonスクリプト(これは記事の中で作成します)。
開始する前に、Oncrawlで完了したクロールレポートにアクセスできる必要があります。
GoogleBigQueryでOncrawlデータを活用する方法
本日の記事の予定は以下の通りです。
- まず、Oncrawlからデータを受信するようにGoogleCloudStorageが設定されていることを確認します。
- 次に、Pythonスクリプトを使用して、Oncrawlのビッグデータエクスポートを実行し、特定のクロールからGoogleCloudStorageバケットにデータをエクスポートします。 ページとリンクの2つのデータセットをエクスポートします。
- これが完了すると、GoogleBigQueryでデータセットが作成されます。 次に、BigQueryデータセット内の2つのエクスポートのそれぞれからテーブルを作成します。
- 最後に、個々のデータセットをクエリしてから、両方のデータセットを一緒にクエリして、複雑な質問に対する答えを見つけます。
Oncrawlデータを受信するためのGoogleCloud内での設定
このガイドを専用のサンドボックス環境で実行するには、新しいGoogle Cloudプロジェクトを作成して、既存の進行中のプロジェクトから分離することをお勧めします。
GoogleCloudの本拠地から始めましょう。
Google Cloudホームページから、CloudStorageに加えて多くのものにアクセスできます。 GoogleCloudPlatformのクラウドストレージ階層内で利用できるクラウドストレージバケットに関心があります。 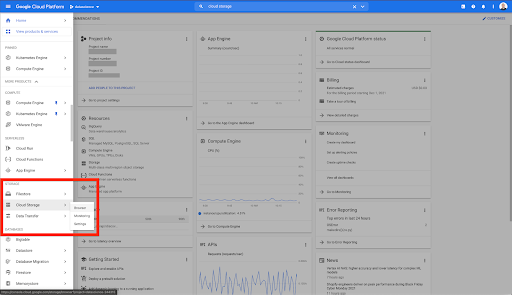
https://console.cloud.google.com/storage/browserから直接CloudStorageブラウザにアクセスすることもできます。
次に、クラウドストレージバケットを作成し、適切な権限を付与して、Oncrawlのサービスアカウントが選択したプレフィックスで書き込みできるようにする必要があります。
Google Cloud Storageバケットは、GoogleBigQueryにロードする前にOncrawlからのビッグデータエクスポートを保持するための一時的なストレージとして機能します。
このバケットには、「リンク」と「ページ」の2つのフォルダーも作成しました。 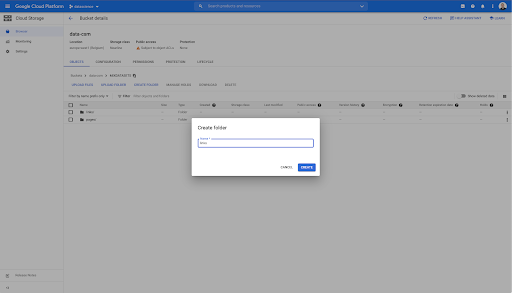
Oncrawlからのデータセットのエクスポート
データを保存するスペースを設定したので、Oncrawlからデータをエクスポートする必要があります。 Oncrawlを使用してGoogleCloudStorageバケットにエクスポートするのは特に簡単です。これは、データを適切な形式でエクスポートして、バケットに直接保存できるためです。 これにより、余分な手順が不要になります。
APIキーの作成
OncrawlからBigQueryのParquet形式でデータをエクスポートするには、Oncrawlアカウントの所有者に代わって、プログラムでAPIを操作するためにAPIキーを使用する必要があります。 Oncrawlアプリケーションを使用すると、ユーザーは名前付きAPIキーを作成できるため、アカウントは常に適切に整理され、クリーンになります。 APIキーは、さまざまな権限(スコープ)にも関連付けられているため、キーとその目的を管理できます。
新しいキーに「ナレッジセッションキー」という名前を付けましょう。 データエクスポートを作成しているため、ビッグデータエクスポート機能にはアカウントへの書き込み権限が必要です。 これを実行するには、プロジェクトへの読み取りアクセス権と、アカウントへの読み取りおよび書き込みアクセス権が必要です。
これで、新しいAPIキーができました。これをクリップボードにコピーします。
セキュリティ上の理由から、キーをコピーできるのは1回だけであることに注意してください。 キーのコピーを忘れた場合は、キーを削除して新しいキーを作成する必要があります。
Pythonスクリプトの作成
このためにGoogleColabノートブックを作成しましたが、独自のツールまたは独自のノートブックを作成できるように、以下のコードを共有します。
1.APIキーをグローバル変数に保存します
まず、環境をブートストラップし、「OncrawlToken」という名前のグローバル変数でAPIキーを宣言します。 次に、残りの実験の準備をします。
#@ titleOncrawlAPIにアクセスします
#@ markdownこのノートブックがOncrawlデータにアクセスできるようにするには、以下にAPIトークンを入力してください。
#ONCRAWLAPIのトークン
ONCRAWL_TOKEN = ""#@ param {type: "string"}
!pipインストール刑務所
IPython.displayからimportclear_output
clear_output()
print('すべてロードされました。') 
2.ドロップダウンリストを作成して、操作するOncrawlプロジェクトを選択します
次に、そのキーを使用して、プロジェクトのリストを取得し、そのリストからドロップダウンウィジェットを作成することで、操作したいプロジェクトを選択できるようにします。 2番目のコードブロックを実行して、次の手順を実行します。
- Oncrawl APIを呼び出して、送信されたばかりのAPIキーを使用してアカウントのプロジェクトのリストを取得します。
- API応答からプロジェクトのリストを取得したら、プロジェクトの名前とプロジェクトの開始URLを使用して、リストとしてフォーマットします。
- 回答で提供されたプロジェクトのIDを保存します。
- ドロップダウンメニューを作成し、コードブロックの下に表示します。
#@ title対応するOncrawlプロジェクトを選択して、分析するWebサイトを選択します
インポートリクエスト
輸入刑務所
ipywidgetsをウィジェットとしてインポートする
jsonをインポートする
#プロジェクトのリストを取得する
response = requests.get( "https://app.oncrawl.com/api/v2/projects?limit= {limit}&sort = {sort}"。format(
limit = 1000、
sort ='name:asc'
)、
headers = {'Authorization':'Bearer' + ONCRAWL_TOKEN}
)。
json_res = response.json()
ユーザーがプロジェクトを選択できるようにするための#prepareドロップダウン
プロジェクト=[]
json_res ['projects']のアイテムの場合:
projects.append(('{}-{}'。format(item ['name']、item ['start_url'])、item ['id']))
output = widgets.Output()
dropdown_purpose = widgets.Dropdown(options = projects、description = "Project:")
def dropdown_project_eventhandler(change):
output.clear_output()
出力付き:
表示(プロジェクト)
dropdown_purpose.observe(dropdown_project_eventhandler、names ='value')
display(dropdown_purpose) これが作成するドロップダウンメニューから、APIキーがアクセスできるプロジェクトの完全なリストを確認できます。 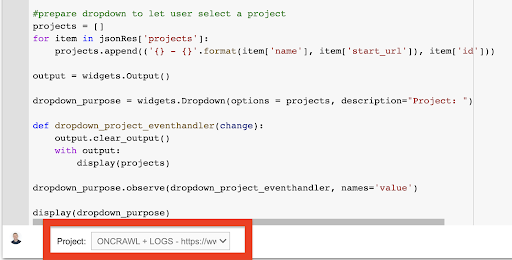
今日のデモンストレーションでは、OncrawlWebサイトに基づくデモプロジェクトを使用しています。
3.ドロップダウンリストを作成して、作業するプロジェクト内のクロールプロファイルを選択します
次に、使用するクロールプロファイルを決定します。 このプロジェクト内でクロールプロファイルを選択します。 デモプロジェクトには、さまざまなクロール構成があります。 
この場合、Oncrawlチームが実験によく使用するプロジェクトを見ているので、OncrawlWebサイトのパフォーマンスを監視するためにマーケティングチームが使用するクロールプロファイルを選択します。 これは最も安定したクロールプロファイルであると考えられているため、今日の実験には適しています。
クロールプロファイルを取得するには、Oncrawl APIを使用して、プロジェクト内のすべてのクロールプロファイル内の最後のクロールを要求します。
- 指定されたプロジェクトのOncrawlAPIをクエリする準備をします。
- 「作成日」の日付に従って降順で返されるすべてのクロールを要求します。
インポートリクエスト
jsonをインポートする
ipywidgetsをウィジェットとしてインポートする
project_id = dropdown_purpose.value
#プロジェクトの詳細を取得します(プロジェクト内のすべてのクロールを含みます)
プロジェクト=requests.get( "https://app.oncrawl.com/api/v2/projects/ {}"。format(project_id)、
params = dict(include_nested_resources = True、sort = "created_at:desc")、
headers = {'Authorization':'Bearer' + ONCRAWL_TOKEN})。json()
#クロールプロファイル(クロール名)でグループクロール
scrolls_by_config = {}
試す:
プロジェクトでのクロールの場合['crawls']:
["done"]のcrawl['status']の場合:
クロール['crawl_config']['name']がcrawls_by_config.keys()にない場合:
scrolls_by_config [crawl ['crawl_config'] ['name']] = {'crawl_ids':[]、'is_crawl_archived':False}
if len(crawls_by_config [crawl ['crawl_config'] ['name']] ['crawl_ids'])== 0:
scrolls_by_config [crawl ['crawl_config'] ['name']] ['crawl_ids']。append(crawl ['id'])
クロール['ステータス']=="アーカイブ"の場合:
scrolls_by_config [crawl ['crawl_config'] ['name']] ['is_crawl_archived'] = True
eとしての例外を除く:
Exception( "error {}、{}"。format(e、project))を発生させます
#ドロップダウン選択のリストを作成します
list = [( "{}({})"。format(k、len(v ['crawl_ids']))、k)for k、v in scrolls_by_config.items()]
dropdown_crawl_configs = widgets.Dropdown(options = list、description = "Crawl configs:")
def dropdown_cc_eventhandler(change):
output.clear_output()
出力付き:
display(crawls_by_config)
len(crawls_by_config.values())== 0の場合:
print('このプロジェクトでライブクロールが見つかりません')
dropdown_crawl_configs.observe(dropdown_cc_eventhandler、names ='value')
display(dropdown_crawl_configs)このコードが実行されると、Oncrawl APIは、「createdat」プロパティを降順でクロールのリストで応答します。
次に、終了したクロールのみに焦点を当てたいので、クロールのリストを確認します。 ステータスが「完了」のクロールごとに、クロールプロファイルの名前を保存し、クロールIDを保存します。
あまり多くのクロールを公開したくないように、クロールプロファイルごとに最大で1つのクロールを保持します。
その結果、プロジェクト内のクロールプロファイルのリストから作成されたこの新しいドロップダウンメニューが作成されます。 欲しいものを選びます。 これにより、マーケティングチームが最後に実行したクロールが実行されます。 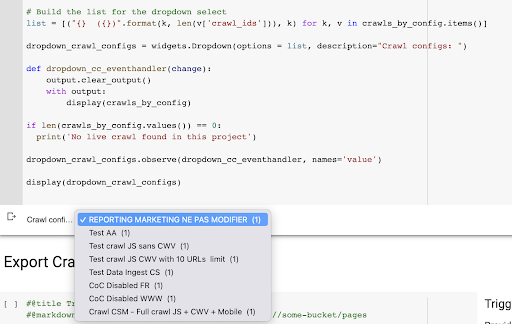
4.使用するプロファイルで最後のクロールを特定します
選択したプロファイルの最後のクロールに関連付けられたクロールIDがすでにあります。 これは、「crawl_by_config」オブジェクトディクショナリに隠されています。 
これはインターフェースで簡単に確認できます。このプロファイル分析で最後に完了したクロールを見つけます。 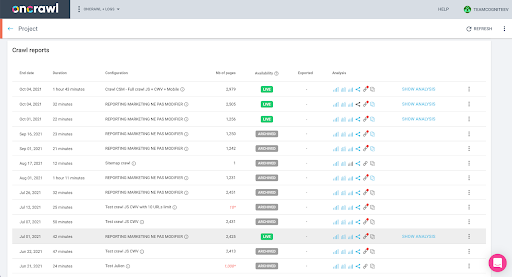
クリックして分析を表示すると、クロールIDがE617で終わることがわかります。 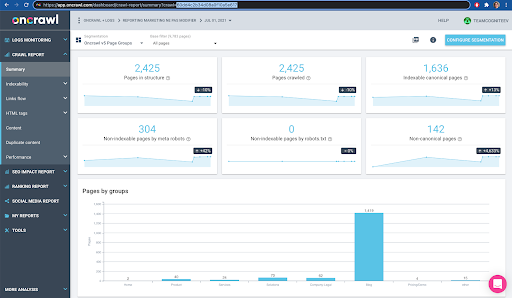
今日のデモンストレーションのために、クロールIDに注意してみましょう。
もちろん、何をしているのかをすでに知っている場合は、プロジェクトのリストとクロールプロファイルごとのクロールのリストを取得するために、OncrawlAPIを呼び出すために説明した手順をスキップできます。インターフェイス、およびこのIDは、エクスポートを実行するために必要なすべてです。
これまでに実行した手順は、APIキーがアクセスできるものを指定して、特定のプロジェクトの特定のクロールプロファイルの最後のクロールを取得するプロセスを簡単にすることです。 これは、このソリューションを他のユーザーに提供している場合、または自動化する場合に役立ちます。
5.クロール結果をエクスポートする
次に、exportコマンドを見てみましょう。
#@titleビッグデータのエクスポートをトリガーする
#@ markdown GCSバケットとプレフィックスgs:// some-bucket/pagesを提供します
#あなたのGCSバケット
gcs_bucket =#@ param {type: "string"}
gcs_prefix =#@ param {type: "string"}
#指定されたプロジェクト/クロールプロファイルから最後のクロールIDを取得します
list_crawl_ids = scrolls_by_config [dropdown_crawl_configs.value] ['crawl_ids']
last_crawl_id = list_crawl_ids [0]
#データエクスポートクエリのテンプレートペイロード
ペイロード={
"data_export":{
"data_type":'ページ'、
"resource_id":last_crawl_id、
"output_format":'寄木細工'、
"ターゲット":'gcs'、
"target_parameters":{
"gcs_bucket":gcs_bucket、
"gcs_prefix":gcs_prefix
}
}
}
#エクスポートをトリガーする
export = requests.post( "https://app.oncrawl.com/api/v2/account/data_exports"、json =payload、headers = {'Authorization':'Bearer' + ONCRAWL_TOKEN})。json()
#API応答を表示する
表示(エクスポート)
#将来の使用のためにエクスポートIDを保存します
export_id = export ['data_export'] ['id']以前に設定したCloudStorageバケットにエクスポートしたいと思います。
その中で、最後のクロールIDのページをエクスポートします。
- 最後のクロールIDは、クロールIDのリストから取得されます。このリストは、手順3で作成した「crawls_by_config」ディクショナリのどこかに格納されています。
- 手順4のドロップダウンメニューに対応するものを選択したいので、ドロップダウンメニューのvalue属性を使用します。
- 次に、crawl_ID属性を抽出します。 これはリストです。 リストの上位50項目を保持します。 これを行う必要があるのは、ステップ2で、覚えているように、crawls_by_configディクショナリを作成したときに、構成名ごとに1つのクロールIDしか保存しなかったためです。
エクスポートを送信するGoogleCloudStorageバケットとプレフィックス、またはフォルダーを簡単に提供できるように、入力フィールドを設定しました。 
デモンストレーションの目的で、今日は、私がすでに設定したフォルダーの1つにある「混合データセット」フォルダーに書き込みます。 Google Cloud Storageでバケットを設定すると、「リンク」のエクスポートと「ページ」のエクスポート用にフォルダを準備したことを思い出してください。
最初のエクスポートでは、Parquetファイル形式を使用して、最後のクロールIDの「pages」フォルダーにページをエクスポートします。 
以下の結果では、データエクスポートエンドポイントに送信されるペイロードが表示されます。これは、APIキーを使用してビッグデータのエクスポートをリクエストするエンドポイントです。
#データエクスポートクエリのテンプレートペイロード
ペイロード={
"data_export":{
"data_type":'ページ'、
"resource_id":last_crawl_id、
"output_format":'寄木細工'、
"ターゲット":'gcs'、
"target_parameters":{
"gcs_bucket":gcs_bucket、
"gcs_prefix":gcs_prefix
}
}
}
これには、エクスポートするデータセットのタイプなど、いくつかの要素が含まれています。 ページデータセット、リンクデータセット、クラスターデータセット、または構造化データデータセットをエクスポートできます。 何ができるかわからない場合は、ここにエラーを入力できます。APIを呼び出すと、データ型の選択はページ、リンク、クラスター、または構造化データのいずれかである必要があることを示すメッセージが表示されます。 メッセージは次のようになります。

{'fields':[{'message':'有効な選択ではありません。 「page」、「link」、「cluster」、「structured_data」のいずれかである必要があります。
'name':'data_type'、
'type':'invalid_choice'}]、
'type':'invalid_request_parameters'}
今日の実験の目的で、ページデータセットとリンクデータセットを別々のエクスポートでエクスポートします。
ページデータセットから始めましょう。 このコードブロックを実行すると、次のようなAPI呼び出しの出力が出力されます。
{'data_export':{'data_type':'ページ'、
'export_failure_reason':なし、
'id':'XXXXXXXXXXXXXX'、
'output_format':'寄木細工'、
'output_format_parameters':なし、
'output_row_count':なし、
'output_size_in_bytes:1634460016000、
'resource_id': '60dd4c2b34d08a0f10a5e617'、
'ステータス':'リクエスト済み'、
'ターゲット':'gcs'、
'target_parameters':{'gcs_bucket':'data-cms'、
'gcs_prefix':'MIXDATASETS / pages /'}}}
これにより、エクスポートが要求されたことがわかります。
エクスポートのステータスを確認したい場合は、非常に簡単です。 このコードブロックの最後に保存したエクスポートIDを使用して、次のAPI呼び出しでいつでもエクスポートのステータスをリクエストできます。
#輸出の状況
export_status = requests.get( "https://app.oncrawl.com/api/v2/account/data_exports/ {}"。format(export_id)、headers = {'Authorization':'Bearer' + ONCRAWL_TOKEN})。json ()
display(export_status)
これは、返されたJSONオブジェクトの一部としてステータスを示します。
{'data_export':{'data_type':'ページ'、
'export_failure_reason':なし、
'id':'XXXXXXXXXXXXXX'、
'output_format':'寄木細工'、
'output_format_parameters':なし、
'output_row_count':なし、
'output_size_in_bytes':なし、
'requested_at':1638350549000、
'resource_id': '60dd4c2b34d08a0f10a5e617'、
'ステータス':'エクスポート'、
'ターゲット':'gcs'、
'target_parameters':{'gcs_bucket':'data-csm'、
'gcs_prefix':'MIXDATASETS / pages /'}}} エクスポートが完了すると( 'status': 'DONE' )、GoogleCloudStorageに戻ることができます。
バケットを調べて「links」フォルダに移動すると、ページをエクスポートしたため、ここにはまだ何もありません。 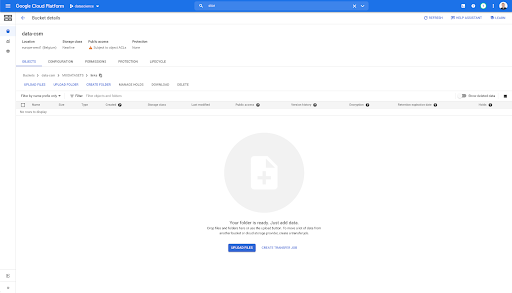
ただし、「pages」フォルダを見ると、エクスポートが成功していることがわかります。 寄木細工のファイルがあります: 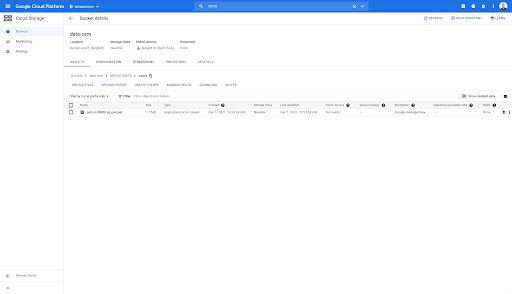
この段階で、ページデータセットをBigQueryにインポートする準備ができていますが、最初に上記の手順を繰り返して、リンクのParquetファイルを取得します。
- リンクプレフィックスを必ず設定してください。
- 「リンク」データ型を選択します。
- このコードブロックを再度実行して、2番目のエクスポートを要求します。

これにより、「links」フォルダにParquetファイルが作成されます。
BigQueryデータセットの作成
エクスポートの実行中に、BigQueryでデータセットの作成を開始し、Parquetファイルを別のテーブルにインポートできます。 次に、テーブルを結合します。
ここでやりたいのは、GoogleCloudPlatformの一部として利用できるGoogleBigQueryで遊ぶことです。 画面上部の検索バーを使用するか、https://console.cloud.google.com/bigqueryに直接アクセスできます。
作業用のデータセットを作成する
GoogleBigQuery内にデータセットを作成する必要があります。 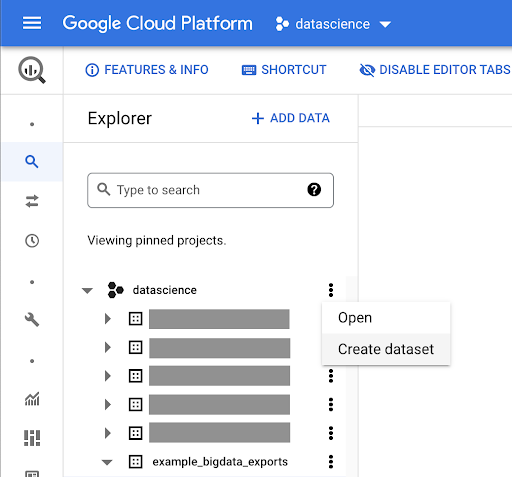
データセットに名前を付けて、データを保存する場所を選択する必要があります。 これは、データが処理される場所を条件付け、変更できないため、重要です。 GDPRまたはその他のプライバシー法の対象となる情報がデータに含まれている場合、これは影響を与える可能性があります。 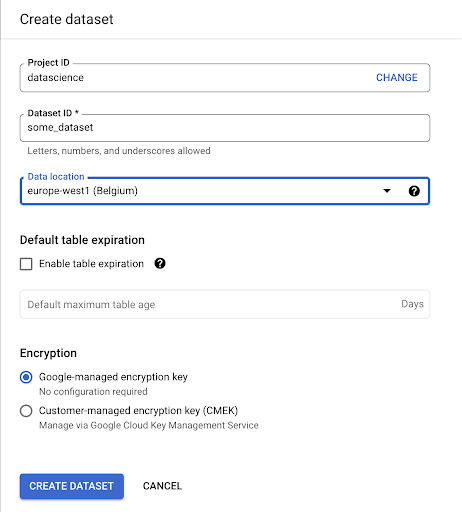
このデータセットは最初は空です。 それを開くと、テーブルの作成、データセットの共有、コピー、削除などを行うことができます。
データのテーブルを作成する
このデータセットにテーブルを作成します。 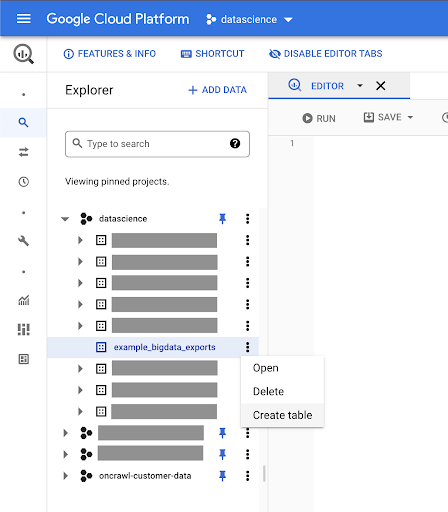
空のテーブルを作成してから、スキーマを指定することができます。 スキーマは、テーブルの列の定義です。 独自に定義することも、GoogleCloudStorageを参照してファイルからスキーマを選択することもできます。
この最後のオプションを使用します。 バケットに移動してから、「pages」フォルダに移動します。 ページファイルを選択しましょう。 ファイルは1つしかないため、1つしか選択できませんが、エクスポートによって複数のファイルが生成された場合は、それらすべてを選択できたはずです。 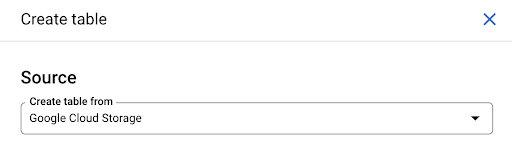
ファイルを選択すると、Parquetファイル形式であることを自動的に検出します。 「pages」という名前のテーブルを作成します。スキーマはソースファイルによって定義されます。 
Parquetファイルをロードすると、スキーマが埋め込まれます。 つまり、作成するテーブルの列の定義は、Parquetファイル内にすでに存在するスキーマから推測されます。 これは実際に魔法の一部が起こる場所です。
先に進んで、Parquetファイルからテーブルを作成してみましょう。 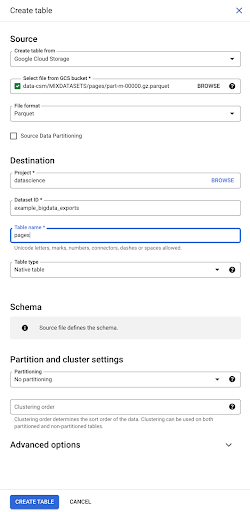
左側のサイドバーで、データセット内にテーブルが表示されていることがわかります。これはまさに私たちが望んでいることです。
これで、Parquetファイルから自動的に推測されたすべてのフィールドを含むpagesテーブルのスキーマができました。 インランク、ページの深さ、ページがリダイレクトである場合などがあります。 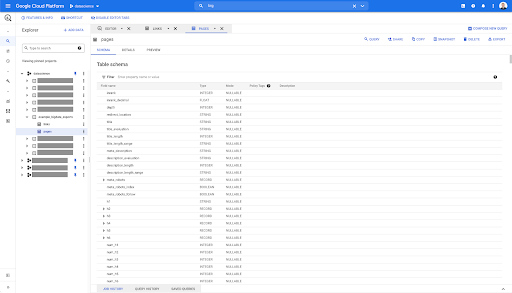
これらのフィールドのほとんどは、Oncrawl DataStudioコネクタを介してDataStudio内で使用できるフィールドと同じであり、Oncrawlインターフェイスのデータエクスプローラに表示されるフィールドと同じです。 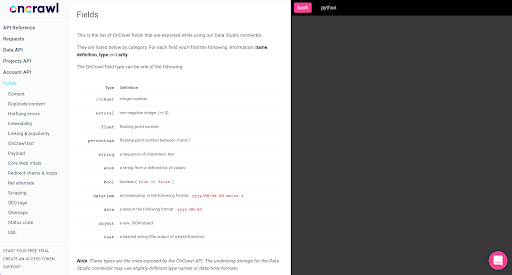
ただし、いくつかの違いがあります。 生のビッグデータのエクスポートで遊ぶとき、あなたはすべての生データを持っています。
- Data Studioでは、一部のフィールドの名前が変更され、一部のフィールドが非表示になり、ステータスなどの一部のフィールドが追加されます。
- データエクスプローラーでは、一部のフィールドは「仮想フィールド」と呼ばれます。これは、基になるフィールドへの一種のショートカットである可能性があることを意味します。 データエクスプローラーで使用可能なこれらの仮想フィールドはスキーマにリストされませんが、Parquetファイルで使用可能なものに基づいて再作成できます。
このテーブルを閉じて、リンクに対してもう一度実行してみましょう。
リンクテーブルの場合、スキーマは少し小さくなります。 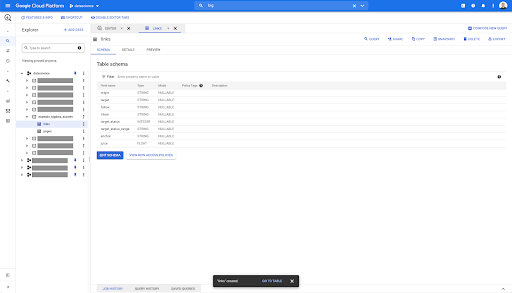
次のフィールドのみが含まれます。
- リンクの起源、
- リンクのターゲット、
- フォロープロパティ、
- 内部プロパティ、
- ターゲットステータス、
- ターゲットステータスの範囲、
- アンカーテキスト、および
- リンクで購入したジュースまたはエクイティ。
BigQueryの任意のテーブルで、[プレビュー]タブをクリックすると、データベースにクエリを実行せずにテーブルのプレビューが表示されます。 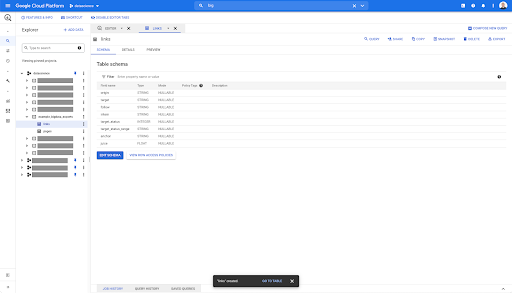
これにより、何が利用できるかをすばやく確認できます。 上記のリンクテーブルのプレビューには、すべての行とすべての列のプレビューがあります。
一部のOncrawlデータセットでは、複数の行にまたがる行が表示される場合があります。 例はありませんが、これが当てはまる場合は、一部のフィールドに値のリストが含まれているためです。 たとえば、ページのh2見出しのリストでは、BigQueryの1つの行が複数の行にまたがっています。 例があれば、後でそれを見ていきます。
クエリの作成
BigQueryでクエリを作成したことがない場合は、今度はそれを試して、その動作に慣れてください。 BigQueryはSQLを使用してデータを検索します。
クエリのしくみ
例として、すべてのURLとそのランクを見てみましょう…
SELECT URL、inrank..。
ページデータセットから…
SELECT url、inrank FROM`datascience-oncrawl.example_bigdata_exports.pages`..。
ここで、ページのステータスコードは200です…
SELECT url、inrank FROM `datascience-oncrawl.example_bigdata_exports.pages` WHERE status_code = 200 ..。
最初の10件の結果のみを保持します。
SELECT url、inrank FROM `datascience-oncrawl.example_bigdata_exports.pages` WHERE status_code = 200 LIMIT 10
このクエリを実行すると、ステータスコードが200であるページのリストの最初の10行が取得されます。
これらのプロパティはどれでも変更できます。 f 10行ではなく1000行が必要な場合、1000行を設定できます。
SELECT url、inrank FROM `datascience-oncrawl.example_bigdata_exports.pages` WHERE status_code = 200 LIMIT 1000
並べ替える場合は、「order-by」を使用して行うことができます。これにより、すべての行がInrankの降順で並べ替えられます。
SELECT url、inrank FROM `datascience-oncrawl.example_bigdata_exports.links` ORDER BY inrank DESC LIMIT 1000
これが私の最初のクエリです。 必要に応じて保存できます。これにより、後で必要に応じてこのクエリを再利用できるようになります。 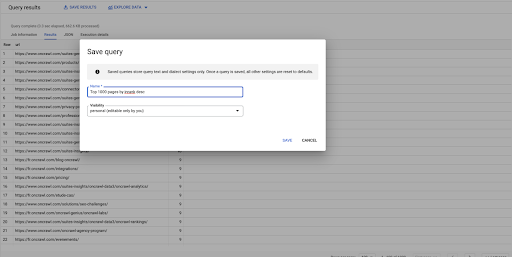
クエリを使用して簡単な質問に回答する:ステータスが301のページへのすべての内部リンクを一覧表示する
クエリの作成方法がわかったので、元の問題に戻りましょう。
単純であろうと複雑であろうと、データの質問に答えたかったのです。 「301(リダイレクト)ステータスのページを指すすべての内部リンクは何ですか、どこにありますか?」などの簡単な質問から始めましょう。
新しいクエリの作成
これがどのように機能するかを調べることから始めます。
「リンク」データベースから次の要素の列が必要になります。
- 元
- 目標
- ターゲットステータスコード
SELECT origin、target、target_status FROM `datascience-oncrawl.example_bigdata_exports.links`
これらを内部リンクのみに制限したいのですが、列の名前や、リンクが内部か外部かを示す値を覚えていないことを想像してみてください。 スキーマに移動して検索し、プレビューを使用して値を表示できます。 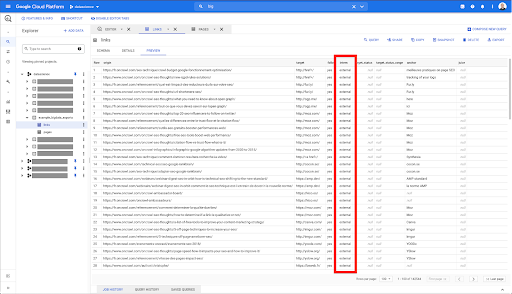
これは、列の名前が「intern」であり、可能な値の範囲が「external」または「internal」であることを示しています。
私のクエリでは、「インターンが内部にいる場所」を指定し、今のところ結果を最初の100に制限したいと思います。
SELECT origin、target、target_status FROM `datascience-oncrawl.example_bigdata_exports.links` WHERE intern LIKE'internal' LIMIT 100
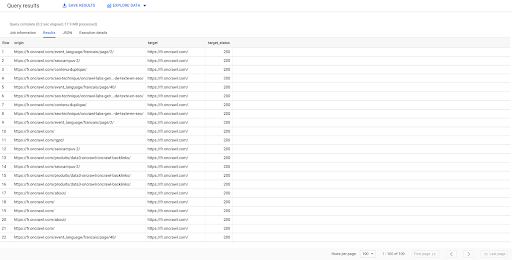
上記の結果は、リンクのリストとそのターゲットステータスを示しています。 内部リンクのみがあり、クエリで指定されているように100個あります。
リダイレクトされたページへのそのポイントへの内部リンクのみが必要な場合は、「内部およびターゲットステータスのようなインターンは301に等しい」と言うことができます。
SELECT origin、target、target_status FROM `datascience-oncrawl.example_bigdata_exports.links` WHERE intern LIKE'internal' AND target_status = 301
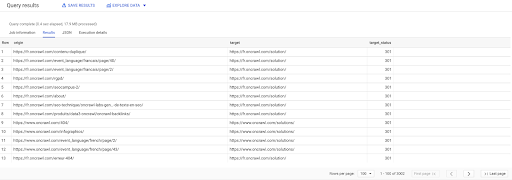
それらがいくつ存在するかわからない場合は、この新しいクエリを実行すると、ターゲットステータスが301の3002の内部リンクがあることがわかります。
テーブルの結合:リダイレクトされたページを指すリンクの最終的なステータスコードを見つける
Webサイトには、リダイレクトされるページへのリンクがあることがよくあります。 リダイレクト先のページのステータスコード(または最終的なターゲットURL)を知りたい。
1つのデータセットには、リンクに関する情報があります。元のページ、ターゲットページ、およびそのステータスコード(301など)ですが、リダイレクトされたページが指すURLはありません。 もう1つは、リダイレクトとその最終的なターゲットに関する情報はありますが、リダイレクトへのリンクが見つかった元のページはありません。
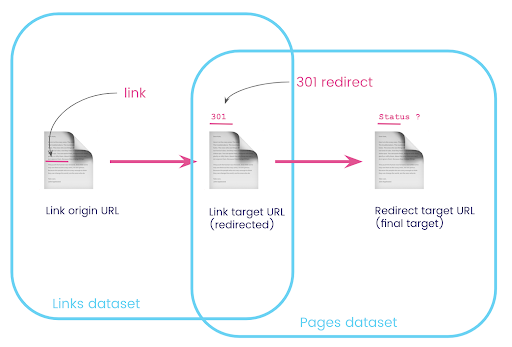
これを分解してみましょう:
まず、リダイレクトへのリンクが必要です。 これを書き留めましょう。 私たちが欲しい:
- 起源。
- ターゲット。 ターゲットには301ステータスコードが必要です。
- リダイレクトの最終ターゲット。
つまり、リンクデータセットでは、次のことが必要です。
- リンクの起源
- リンクのターゲット
ページデータセットでは、次のものが必要です。
- リダイレクトされるすべてのターゲット
- リダイレクトの最終ターゲット
これにより、次のようなクエリが得られます。
SELECT url、final_redirect_location、final_redirect_status FROM `datascience-oncrawl.example_bigdata_exports.pages` AS pages WHERE status_code = 301 OR status_code = 302
これは私に方程式の最初の部分を与えるはずです。
ここで、作成したクエリの結果であるページにリンクするすべてのリンクが必要です。データセットのエイリアスを使用し、それらをリンクターゲットURLとページURLに結合します。 これは、このセクションの冒頭の図にある2つのデータセットの重複領域に対応しています。
選択する links.origin、 pages.url、 pages.final_redirect_location、 pages.final_redirect_status から `datascience-oncrawl.example_bigdata_exports.pages`ASページ 加入 `datascience-oncrawl.example_bigdata_exports.links`ASリンク オン links.target = pages.url どこ pages.status_code = 301 またはpages.status_code=302 注文者 オリジンASC
クエリ結果では、列の名前を変更してわかりやすくすることができますが、最初の列のページから2番目の列のページにリンクされ、次にリダイレクトされるリンクがあることはすでにわかります。 3列目のページ。 4番目の列には、最終ターゲットのステータスコードがあります。 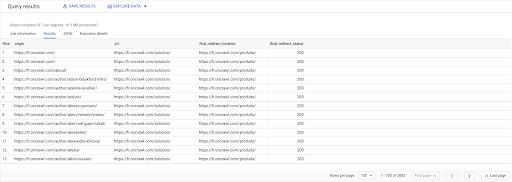
これで、200ページに解決されないリダイレクトされたページを指すリンクがわかります。 たとえば、404である可能性があります。これにより、修正するリンクの優先リストが表示されます。
クエリを保存する方法については前に説明しました。 最大16000行の結果について、結果を保存することもできます。 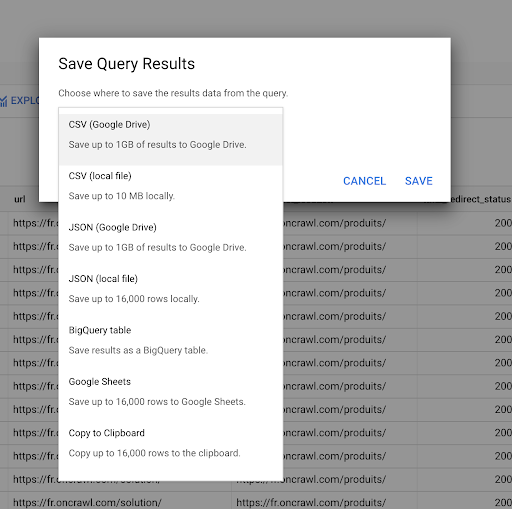
その後、これらの結果をさまざまな方法で使用できます。 次にいくつかの例を示します。
- これをCSVまたはJSONファイルとしてローカルに保存できます。
- Googleスプレッドシートとして保存し、チームの他のメンバーと共有できます。
- DataStudioに直接エクスポートすることもできます。
戦略的利点としてのデータ
これらすべての可能性があるため、複雑な質問への回答を戦略的に使用するのは簡単です。 BigQueryの結果をデータスタジオやその他のデータ視覚化プラットフォームに接続した経験がある場合や、情報をエンジニアリングチームにプッシュしたり、ビジネスインテリジェンスやデータ分析ワークフローにプッシュしたりするプロセスがすでにある場合があります。
この記事の手順をプロセスの一部として含めた場合は、BigQueryのすべての手順を自動化できることを忘れないでください。この記事で実行したすべてのアクションには、BigQueryAPIを介してアクセスすることもできます。 これは、スクリプトまたはカスタムツールの一部としてプログラムで実行できることを意味します。
次のステップが何であれ、最初のステップは常に生のSEOとウェブサイトのデータにアクセスすることです。 このデータへのアクセスは、テクニカル分析の最も重要な部分の1つであると信じています。Oncrawlを使用すると、生データに常に完全にアクセスできます。
データへのアクセスは、Oncrawlインターフェースで可能なことを超えて、質問がどれほど複雑であっても、データ間のすべての関係を調査できることも意味します。