
Was sind Wortvektoren und wie strukturiertes Markup sie auflädt?
Veröffentlicht: 2021-07-28Wie definiert man Wortvektoren? In diesem Beitrag stelle ich Ihnen das Konzept der Wortvektoren vor. Wir werden verschiedene Arten von Wörterinbettungen durchgehen und, was noch wichtiger ist, wie Wortvektoren funktionieren. Wir werden dann in der Lage sein, die Auswirkungen von Wortvektoren auf SEO zu sehen, was uns dazu bringt zu verstehen, wie Schema.org-Markup für strukturierte Daten Ihnen helfen kann, Wortvektoren in SEO zu nutzen.
Lesen Sie diesen Beitrag weiter, wenn Sie mehr über diese Themen erfahren möchten.
Lassen Sie uns gleich eintauchen.
Was sind Wortvektoren?
Wortvektoren (auch Worteinbettungen genannt) sind eine Art der Wortdarstellung, die es Wörtern mit ähnlicher Bedeutung ermöglicht, eine gleiche Darstellung zu haben.
Einfach ausgedrückt: Ein Wortvektor ist eine vektorielle Darstellung eines bestimmten Wortes.
Laut Wikipedia:
Es ist eine Technik, die in der Verarbeitung natürlicher Sprache (NLP) zur Darstellung von Wörtern für die Textanalyse verwendet wird, typischerweise als reellwertiger Vektor, der die Bedeutung des Wortes codiert, sodass Wörter, die im Vektorraum nahe beieinander liegen, wahrscheinlich ähnliche Bedeutungen haben.
Das folgende Beispiel hilft uns, dies besser zu verstehen:
Sehen Sie sich diese ähnlichen Sätze an:
Haben Sie einen guten Tag . und einen schönen Tag.
Sie haben kaum eine andere Bedeutung. Wenn wir ein erschöpfendes Vokabular konstruieren (nennen wir es V), hätte es V = {Have, a, good, great, day}, das alle Wörter kombiniert. Wir könnten das Wort wie folgt codieren.
Die Vektordarstellung eines Wortes kann ein One-Hot-codierter Vektor sein, wobei 1 die Position darstellt, an der das Wort existiert, und 0 den Rest darstellt
Haben = [1,0,0,0,0]
a=[0,1,0,0,0]
gut=[0,0,1,0,0]
großartig=[0,0,0,1,0]
tag=[0,0,0,0,1]
Angenommen, unser Vokabular hat nur fünf Wörter: König, Königin, Mann, Frau und Kind. Wir könnten die Wörter wie folgt codieren:
König = [1,0,0,0,0]
Dame = [0,1,0,0,0]
Mann = [0,0,1,00]
Frau = [0,0,0,1,0]
Kind = [0,0,0,0,1]
Arten von Wörterinbettungen (Wortvektoren)
Word Embedding ist eine solche Technik, bei der Vektoren Text darstellen. Hier sind einige der beliebtesten Arten von Wörterinbettungen:
- Frequenzbasierte Einbettung
- Vorhersagebasierte Einbettung
Wir werden hier nicht weiter auf die frequenzbasierte Einbettung und die prädiktionsbasierte Einbettung eingehen, aber die folgenden Leitfäden könnten hilfreich sein, um beide zu verstehen:
Ein intuitives Verständnis von Worteinbettungen und eine schnelle Einführung in Bag-of-Words (BOW) und TF-IDF zum Erstellen von Features aus Text
Eine kurze Einführung in WORD2Vec
Während die frequenzbasierte Einbettung an Popularität gewonnen hat, gibt es immer noch eine Lücke im Verständnis des Kontexts von Wörtern und begrenzt in ihrer Wortdarstellung.
Prediction-based Embedding (WORD2Vec) wurde 2013 von einem Forscherteam unter der Leitung von Tomas Mikolov bei Google erstellt, patentiert und der NLP-Community vorgestellt.
Laut Wikipedia verwendet der word2vec-Algorithmus ein neuronales Netzwerkmodell, um Wortassoziationen aus einem großen Textkorpus (großer und strukturierter Satz von Texten) zu lernen.
Einmal trainiert, kann ein solches Modell synonyme Wörter erkennen oder zusätzliche Wörter für einen Teilsatz vorschlagen. Mit Word2Vec können Sie beispielsweise problemlos solche Ergebnisse erstellen: König – Mann + Frau = Königin, was als fast magisches Ergebnis galt.
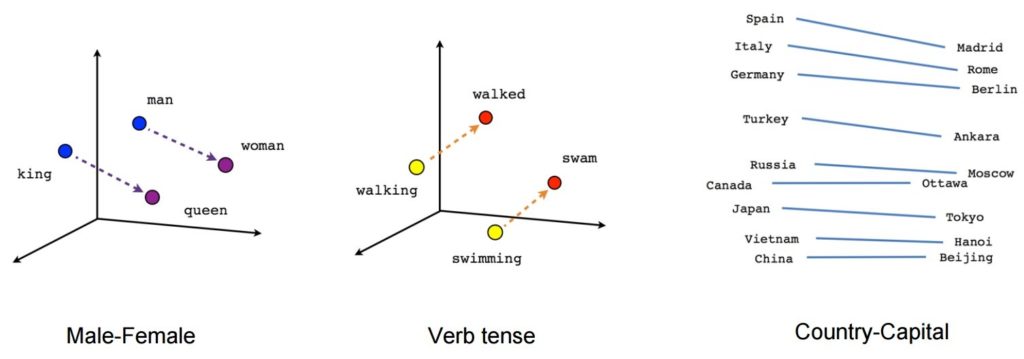 Bildquelle: Tensorflow
Bildquelle: Tensorflow
- [König] – [Mann] + [Frau] ~= [Königin] (eine andere Art, darüber nachzudenken, ist, dass [König] – [Königin] nur den geschlechtsspezifischen Teil von [Monarch] codiert)
- [walking] – [swimming] + [swam] ~= [walked] (oder [swam] – [swimming] codiert nur die „Vergangenheit“ des Verbs)
- [madrid] – [spanien] + [frankreich] ~= [paris] (oder [madrid] – [spanien] ~= [paris] – [frankreich] was vermutlich ungefähr „hauptstadt“ ist)
Quelle: Brainslab Digital
Ich weiß, das ist ein wenig technisch, aber Stitch Fix hat einen fantastischen Beitrag über semantische Beziehungen und Wortvektoren zusammengestellt.
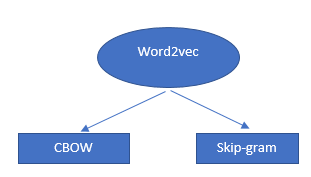
Der Word2Vec-Algorithmus ist kein einzelner Algorithmus, sondern eine Kombination aus zwei Techniken, die einige KI-Methoden verwenden, um das menschliche Verständnis und das maschinelle Verständnis zu überbrücken. Diese Technik ist für die „Lösung“ vieler NLP-Probleme unerlässlich.
Diese beiden Techniken sind:
- – CBOW (Continuous bag of words) oder CBOW-Modell
- – Skip-Gramm-Modell.
Beides sind flache neuronale Netze, die Wahrscheinlichkeiten für Wörter liefern und sich bei Aufgaben wie Wortvergleich und Wortanalogie als hilfreich erwiesen haben.
Funktionsweise von Wortvektoren und word2vecs
Word Vector ist ein von Google entwickeltes KI-Modell, das uns hilft, sehr komplexe NLP-Aufgaben zu lösen.
„Wortvektormodelle haben ein zentrales Ziel, das Sie kennen sollten:
Es ist ein Algorithmus, der Google hilft, semantische Beziehungen zwischen Wörtern zu erkennen.“
Jedes Wort wird in einem Vektor codiert (als Zahl, die in mehreren Dimensionen dargestellt wird), um Vektoren von Wörtern zu entsprechen, die in einem ähnlichen Kontext erscheinen. Somit wird für den Text ein dichter Vektor gebildet.
Diese Vektormodelle bilden semantisch ähnliche Phrasen auf benachbarte Punkte ab, basierend auf Äquivalenz, Ähnlichkeiten oder Verwandtschaft von Ideen und Sprache
[Fallstudie] Förderung des Wachstums in neuen Märkten mit On-Page-SEO
 Lesen Sie die Fallstudie
Lesen Sie die FallstudieWord2Vec – Wie funktioniert es?
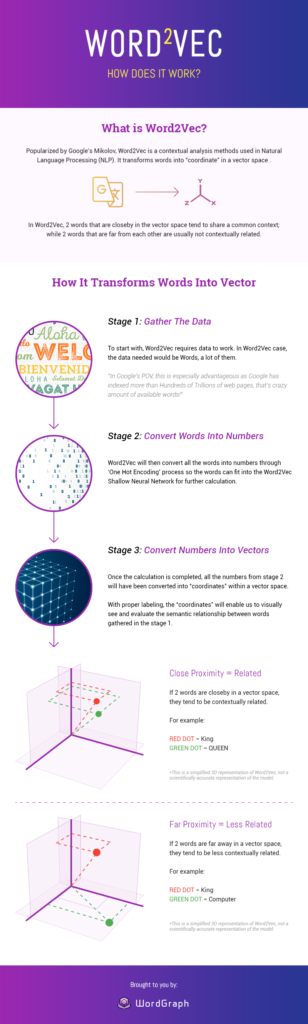
Bildquelle: Seopressor
Vor- und Nachteile von Word2Vec
Wir haben gesehen, dass Word2vec eine sehr effektive Technik ist, um Verteilungsähnlichkeit zu erzeugen. Einige seiner weiteren Vorteile habe ich hier aufgelistet:
- Es gibt keine Schwierigkeiten, Word2vec-Konzepte zu verstehen. Word2Vec ist nicht so komplex, dass Sie nicht wissen, was hinter den Kulissen passiert.
- Die Architektur von Word2Vec ist sehr leistungsfähig und einfach zu bedienen. Im Vergleich zu anderen Techniken ist es schnell zu trainieren.
- Das Training ist hier fast vollständig automatisiert, sodass keine von Menschen markierten Daten mehr erforderlich sind.
- Diese Technik funktioniert sowohl für kleine als auch für große Datensätze. Als Ergebnis ist es ein einfach zu skalierendes Modell.
- Wenn Sie die Konzepte kennen, können Sie das gesamte Konzept und den Algorithmus problemlos replizieren.
- Es erfasst semantische Ähnlichkeiten außergewöhnlich gut.
- Präzise und recheneffizient
- Da dieser Ansatz unüberwacht ist, ist er sehr zeitsparend in Bezug auf den Aufwand.
Herausforderungen von Word2Vec
Das Word2vec-Konzept ist sehr effizient, aber einige Punkte könnten Sie etwas herausfordernd finden. Hier sind einige der häufigsten Herausforderungen.
- Bei der Entwicklung eines word2vec-Modells für Ihren Datensatz kann das Debuggen eine große Herausforderung darstellen, da das word2vec-Modell einfach zu entwickeln, aber schwer zu debuggen ist.
- Auf Mehrdeutigkeiten wird nicht eingegangen. Im Fall von Wörtern mit mehreren Bedeutungen spiegelt die Einbettung also den Durchschnitt dieser Bedeutungen im Vektorraum wider.
- Unbekannte oder OOV-Wörter können nicht verarbeitet werden: Das größte Problem mit word2vec ist die Unfähigkeit, unbekannte oder nicht im Vokabular (OOV) enthaltene Wörter zu verarbeiten.
Wortvektoren: Ein Wendepunkt in der Suchmaschinenoptimierung?
Viele SEO-Experten glauben, dass Word Vector das Ranking einer Website in den Suchmaschinenergebnissen beeinflusst.
In den letzten fünf Jahren hat Google zwei Algorithmus-Updates eingeführt, die einen klaren Fokus auf die Qualität der Inhalte und die Vollständigkeit der Sprache legen.
Lassen Sie uns einen Schritt zurücktreten und über die Updates sprechen:
Kolibri
2013 gab Hummingbird Suchmaschinen die Fähigkeit zur semantischen Analyse. Durch die Nutzung und Einbeziehung der Semantiktheorie in ihre Algorithmen eröffneten sie einen neuen Weg in die Welt der Suche.
Google Hummingbird war die größte Änderung an der Suchmaschine seit Caffeine im Jahr 2010. Es hat seinen Namen, weil es „präzise und schnell“ ist.
Laut Search Engine Land schenkt Hummingbird jedem Wort in einer Suchanfrage mehr Aufmerksamkeit und stellt sicher, dass die gesamte Suchanfrage berücksichtigt wird und nicht nur bestimmte Wörter.

Das Hauptziel von Hummingbird war es, bessere Ergebnisse zu liefern, indem der Kontext der Abfrage verstanden wird, anstatt Ergebnisse für bestimmte Schlüsselwörter zurückzugeben.
„Google Hummingbird wurde im September 2013 veröffentlicht.“
RankBrain
Im Jahr 2015 kündigte Google RankBrain an, eine Strategie, die künstliche Intelligenz (KI) einbezog.
RankBrain ist ein Algorithmus, der Google hilft, komplexe Suchanfragen in einfachere zu zerlegen. RankBrain wandelt Suchanfragen aus der „menschlichen“ Sprache in eine Sprache um, die Google leicht verstehen kann.
Google bestätigte die Nutzung von RankBrain am 26. Oktober 2015 in einem von Bloomberg veröffentlichten Artikel.
Bert
Am 21. Oktober 2019 wurde BERT im Suchsystem von Google eingeführt
BERT steht für Bidirectional Encoder Representations from Transformers, eine auf neuronalen Netzwerken basierende Technik, die von Google für das Vortraining in der Verarbeitung natürlicher Sprache (NLP) verwendet wird.
Kurz gesagt, BERT hilft Computern, Sprache besser wie Menschen zu verstehen, und es ist die größte Veränderung in der Suche, seit Google RankBrain eingeführt hat.
Es ist kein Ersatz für RankBrain, sondern eine zusätzliche Methode zum Verständnis von Inhalten und Abfragen.
Als Ergänzung verwendet Google BERT in seinem Ranking-System. Der RankBrain-Algorithmus existiert noch für einige Abfragen und wird es auch weiterhin geben. Aber wenn Google der Meinung ist, dass BERT eine Abfrage besser verstehen kann, werden sie das verwenden.
Weitere Informationen zu BERT finden Sie in diesem Beitrag von Barry Schwartz sowie in Dawn Andersons ausführlichem Tauchgang.
Ordnen Sie Ihre Website mit Word-Vektoren
Ich gehe davon aus, dass Sie bereits einzigartige Inhalte erstellt und veröffentlicht haben, und selbst wenn Sie diese immer wieder aufpolieren, verbessert dies weder Ihr Ranking noch Ihren Traffic.
Fragst du dich, warum dir das passiert?
Es könnte daran liegen, dass Sie Word Vector: Googles KI-Modell nicht eingebunden haben.
- Der erste Schritt besteht darin, die Wortvektoren der 10 besten SERP-Rankings für Ihre Nische zu identifizieren.
- Wissen Sie, welche Keywords Ihre Konkurrenten verwenden und was Sie möglicherweise übersehen.
Durch die Anwendung von Word2Vec, das fortschrittliche Techniken zur Verarbeitung natürlicher Sprache und ein Framework für maschinelles Lernen nutzt, können Sie alles im Detail sehen.
Aber diese sind möglich, wenn Sie die Techniken des maschinellen Lernens und des NLP kennen, aber wir können Wortvektoren im Inhalt mit dem folgenden Tool anwenden:
WordGraph, das weltweit erste Wort-Vektor-Tool
Dieses Tool für künstliche Intelligenz wird mit neuronalen Netzwerken für die Verarbeitung natürlicher Sprache erstellt und mit maschinellem Lernen trainiert.
Basierend auf künstlicher Intelligenz analysiert WordGraph Ihre Inhalte und hilft Ihnen, ihre Relevanz für die Top-10-Ranking-Websites zu verbessern.
Es schlägt Schlüsselwörter vor, die mathematisch und kontextuell mit Ihrem Hauptschlüsselwort zusammenhängen.
Persönlich kombiniere ich es mit BIQ, einem leistungsstarken SEO-Tool, das gut mit WordGraph zusammenarbeitet.
Fügen Sie Ihre Inhalte dem in Biq integrierten Content-Intelligence-Tool hinzu. Es zeigt Ihnen eine ganze Liste von On-Page-SEO-Tipps , die Sie hinzufügen können, wenn Sie an der Spitze stehen möchten.
In diesem Beispiel können Sie sehen, wie Content Intelligence funktioniert. Die Listen helfen Ihnen, On-Page-SEO zu meistern und mit umsetzbaren Methoden zu ranken!
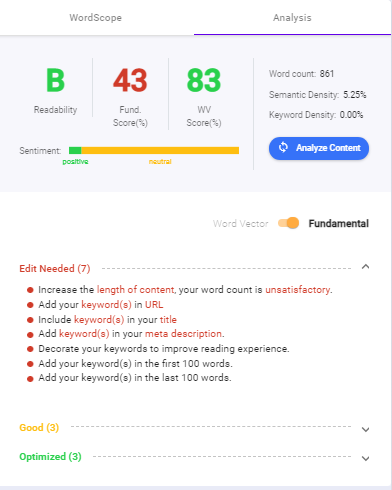
So laden Sie Wortvektoren auf: Verwenden von strukturiertem Daten-Markup
Schema-Markup oder strukturierte Daten sind eine Art von Code (geschrieben in JSON, Java-Script Object Notation), der mithilfe des schema.org-Vokabulars erstellt wurde und Suchmaschinen dabei hilft, Ihre Inhalte zu crawlen, zu organisieren und anzuzeigen.
So fügen Sie strukturierte Daten hinzu
Strukturierte Daten können einfach zu Ihrer Website hinzugefügt werden, indem Sie ein Inline-Skript in Ihren HTML-Code einfügen
Ein Beispiel unten zeigt, wie Sie die strukturierten Daten Ihrer Organisation im einfachsten möglichen Format definieren.
Um das Schema-Markup zu generieren, verwende ich diesen Schema-Markup-Generator (JSON-LD).
Hier ist das Live-Beispiel für Schema-Markup für https://www.telecloudvoip.com/. Überprüfen Sie den Quellcode und suchen Sie nach JSON.
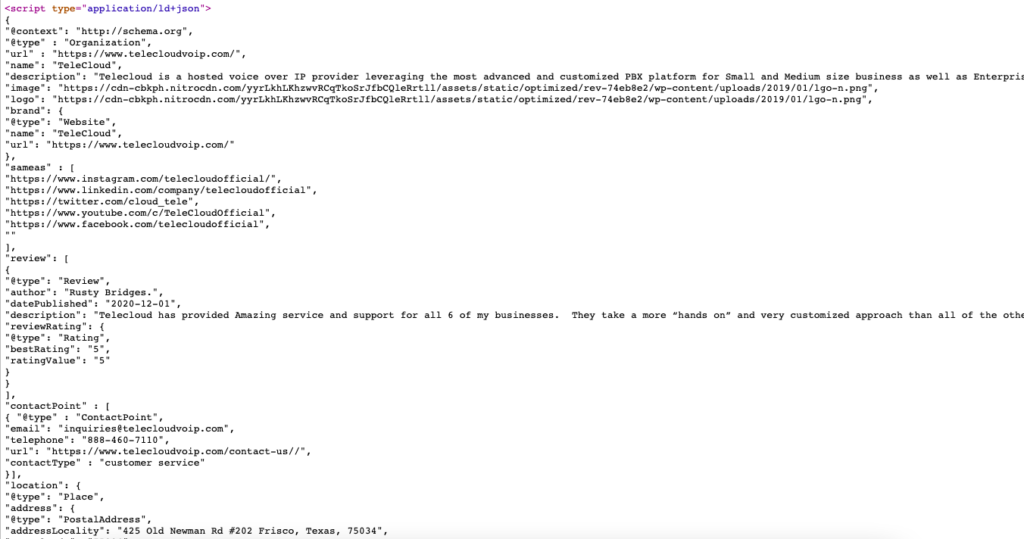
Verwenden Sie nach der Erstellung des Schema-Markup-Codes den Test für Rich-Suchergebnisse von Google, um festzustellen, ob die Seite Rich-Suchergebnisse unterstützt.
Sie können auch das Semrush-Site-Audit-Tool verwenden, um strukturierte Datenelemente für jede URL zu untersuchen und festzustellen, welche Seiten für Rich-Suchergebnisse geeignet sind. 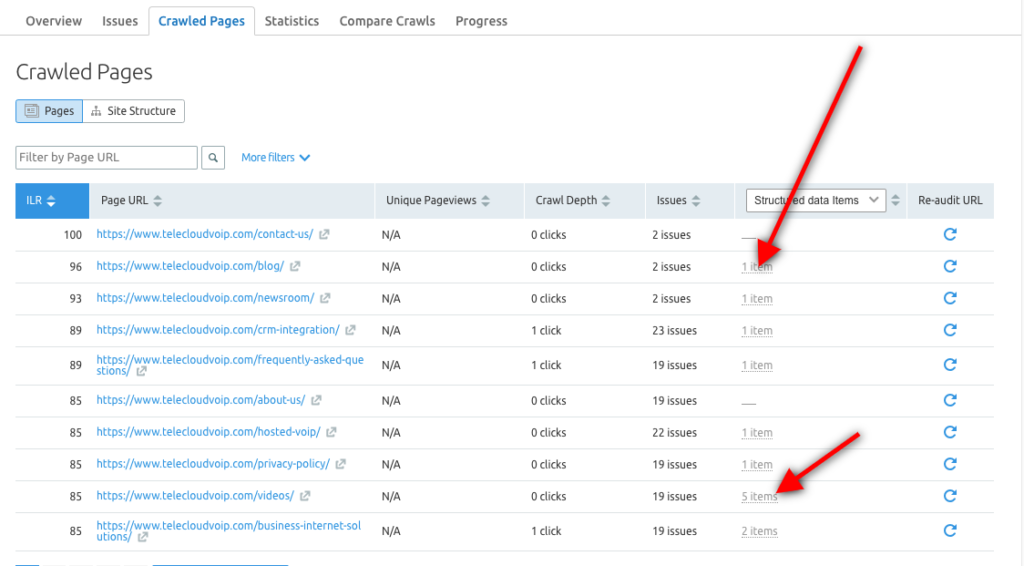
Warum sind strukturierte Daten wichtig für SEO?
Strukturierte Daten sind wichtig für SEO, da sie Google helfen zu verstehen, worum es auf Ihrer Website und Ihren Seiten geht, was zu einem genaueren Ranking Ihrer Inhalte führt.
Strukturierte Daten verbessern sowohl die Erfahrung des Suchbots als auch die Erfahrung des Benutzers, indem sie die SERP (Suchmaschinen-Ergebnisseiten) mit mehr Informationen und Genauigkeit verbessern.
Um die Auswirkungen auf die Google-Suche zu sehen, gehen Sie zur Search Console und unter Leistung > Suchergebnis > Suchdarstellung können Sie eine Aufschlüsselung aller Rich-Ergebnistypen wie „Videos“ und „FAQs“ anzeigen und die organischen Impressionen und Klicks sehen, die sie ausgelöst haben für Ihre Inhalte.
Im Folgenden sind einige Vorteile von strukturierten Daten aufgeführt:
- Strukturierte Daten unterstützen die semantische Suche
- Es unterstützt auch Ihr E-AT (Expertise, Autorität und Vertrauen)
- Strukturierte Daten können auch die Konversionsraten erhöhen, da mehr Personen Ihre Angebote sehen, was die Wahrscheinlichkeit erhöht, dass sie bei Ihnen kaufen.
- Durch strukturierte Daten können Suchmaschinen Ihre Marke, Ihre Website und Ihre Inhalte besser verstehen.
- Suchmaschinen können leichter zwischen Kontaktseiten, Produktbeschreibungen, Rezeptseiten, Veranstaltungsseiten und Kundenbewertungen unterscheiden.
- Mit Hilfe strukturierter Daten erstellt Google einen besseren, genaueren Knowledge Graph und ein Knowledge Panel über Ihre Marke.
- Diese Verbesserungen können zu mehr organischen Impressionen und organischen Klicks führen.
Strukturierte Daten werden derzeit von Google verwendet, um die Suchergebnisse zu verbessern. Wenn Nutzer mithilfe von Schlüsselwörtern nach Ihren Webseiten suchen, können strukturierte Daten Ihnen dabei helfen, bessere Ergebnisse zu erzielen. Suchmaschinen werden Ihre Inhalte besser bemerken, wenn wir Schema-Markup hinzufügen.
Sie können Schema-Markup für eine Reihe verschiedener Elemente implementieren. Nachfolgend sind einige Bereiche aufgeführt, in denen Schemata angewendet werden können:
- Artikel
- Blogeinträge
- Zeitungsartikel
- Veranstaltungen
- Produkte
- Videos
- Dienstleistungen
- Bewertungen
- Aggregierte Bewertungen
- Restaurants
- Regionale Unternehmen
Hier ist eine vollständige Liste der Elemente, die Sie mit Schemas auszeichnen können.
Strukturierte Daten mit Entitätseinbettungen
Der Begriff „Entität“ bezieht sich auf eine Darstellung jeglicher Art von Objekt, Konzept oder Subjekt. Eine Entität kann eine Person, ein Film, ein Buch, eine Idee, ein Ort, ein Unternehmen oder ein Ereignis sein.
Während Maschinen Wörter nicht wirklich verstehen können, sind sie mit Einbettungen von Entitäten in der Lage, die Beziehung zwischen König – Königin = Ehemann – Ehefrau leicht zu verstehen
Entitätseinbettungen sind leistungsfähiger als One-Hot-Codierungen
Der Wortvektoralgorithmus wird von Google verwendet, um semantische Beziehungen zwischen Wörtern zu entdecken, und in Kombination mit strukturierten Daten erhalten wir ein semantisch verbessertes Web.
Durch die Verwendung strukturierter Daten tragen Sie zu einem semantischeren Web bei. Dies ist ein erweitertes Web, in dem wir die Daten in einem maschinenlesbaren Format beschreiben.
Strukturierte semantische Daten auf Ihrer Website helfen Suchmaschinen dabei, Ihre Inhalte mit der richtigen Zielgruppe abzugleichen. Der Einsatz von NLP, maschinellem Lernen und Deep Learning trägt dazu bei, die Lücke zwischen dem, wonach Menschen suchen, und den verfügbaren Titeln zu verringern.
Abschließende Gedanken
Da Sie nun das Konzept von Wortvektoren und seine Bedeutung verstehen, können Sie Ihre organische Suchstrategie effektiver und effizienter gestalten, indem Sie Wortvektoren, Einbettungen von Entitäten und strukturierte semantische Daten verwenden.
Um das höchste Ranking, den höchsten Traffic und die höchsten Conversions zu erzielen, müssen Sie Wortvektoren, Einbettungen von Entitäten und strukturierte semantische Daten verwenden, um Google zu zeigen, dass der Inhalt Ihrer Webseite korrekt, präzise und vertrauenswürdig ist.