
Was ist Latent Semantic Indexing und wie funktioniert es?
Veröffentlicht: 2020-04-02Latent Semantic Indexing (LSI) ist seit langem Anlass für Diskussionen unter Suchmaschinenvermarktern. Googlen Sie den Begriff „latent semantic indexing“ und Sie werden gleichermaßen auf Befürworter und Skeptiker stoßen. Es gibt keinen klaren Konsens über die Vorteile der Berücksichtigung von LSI im Kontext des Suchmaschinenmarketings. Wenn Sie mit dem Konzept nicht vertraut sind, fasst dieser Artikel die Debatte über LSI zusammen, damit Sie hoffentlich verstehen können, was es für Ihre SEO-Strategie bedeutet.
Was ist Latent Semantic Indexing?
LSI ist ein Prozess, der in der Verarbeitung natürlicher Sprache (NLP) zu finden ist. NLP ist ein Teilbereich der Linguistik und Informationstechnik, der sich darauf konzentriert, wie Maschinen menschliche Sprache interpretieren. Ein wichtiger Teil dieser Studie ist die Verteilungssemantik. Dieses Modell hilft uns, Wörter mit ähnlichen kontextuellen Bedeutungen in großen Datensätzen zu verstehen und zu klassifizieren.
LSI wurde in den 1980er Jahren entwickelt und verwendet eine mathematische Methode, die den Informationsabruf genauer macht. Diese Methode funktioniert, indem sie die verborgenen kontextuellen Beziehungen zwischen Wörtern identifiziert. Es kann Ihnen helfen, es wie folgt aufzuschlüsseln:
- Latent → Versteckt
- Semantik → Beziehungen zwischen Wörtern
- Indizierung → Informationsabruf
Wie funktioniert Latent Semantic Indexing?
LSI arbeitet mit der partiellen Anwendung der Singular Value Decomposition (SVD). SVD ist eine mathematische Operation, die eine Matrix für einfache und effiziente Berechnungen auf ihre Bestandteile reduziert.
Bei der Analyse einer Wortfolge entfernt LSI Konjunktionen, Pronomen und allgemeine Verben, die auch als Stoppwörter bekannt sind. Dadurch werden die Wörter isoliert, die den Hauptinhalt eines Satzes bilden. Hier ein kurzes Beispiel, wie das aussehen könnte:
![]()
Diese Wörter werden dann in eine Term Document Matrix (TDM) platziert. Ein TDM ist ein 2D-Raster, das die Häufigkeit auflistet, mit der jedes bestimmte Wort (oder jeder Begriff) in den Dokumenten innerhalb eines Datensatzes vorkommt.
Wägefunktionen werden dann auf das TDM angewendet. Ein einfaches Beispiel ist die Klassifizierung aller Dokumente, die das Wort enthalten, mit dem Wert 1 und aller, die es nicht enthalten, mit dem Wert 0. Wenn Wörter in diesen Dokumenten mit der gleichen allgemeinen Häufigkeit vorkommen, spricht man von Kookkurrenz . Nachfolgend finden Sie ein einfaches Beispiel für ein TDM und wie es das gleichzeitige Auftreten mehrerer Phrasen bewertet:
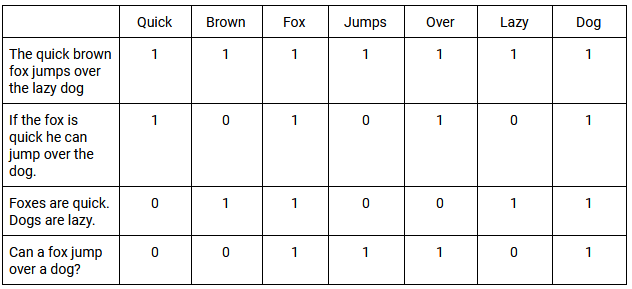
Die Verwendung von SVD ermöglicht es uns, die Muster in der Wortverwendung in allen Dokumenten anzunähern. Die von LSI erzeugten SVD-Vektoren sagen die Bedeutung genauer voraus als die Analyse einzelner Begriffe. Letztendlich kann LSI die Beziehungen zwischen Wörtern nutzen, um ihren Sinn oder ihre Bedeutung in einem bestimmten Kontext besser zu verstehen.
[Fallstudie] Förderung des Wachstums in neuen Märkten mit On-Page-SEO
 Lesen Sie die Fallstudie
Lesen Sie die FallstudieWie wurde Latent Semantic Indexing mit SEO in Verbindung gebracht?
In seinen Gründungsjahren stellte Google fest, dass Suchmaschinen Websites basierend auf der Häufigkeit eines bestimmten Schlüsselworts einordneten. Dies garantiert jedoch nicht das relevanteste Suchergebnis. Stattdessen begann Google damit, Websites zu bewerten, die sie als vertrauenswürdige Entscheidungsträger für Informationen betrachteten.
Im Laufe der Zeit würden die Algorithmen von Google minderwertige und irrelevante Websites mit größerer Genauigkeit herausfiltern. Daher müssen Vermarkter die Bedeutung hinter einer Suche verstehen, anstatt sich auf die genauen Wörter zu verlassen, die verwendet werden. Aus diesem Grund beschrieb Roger Montti LSI in einem Artikel über veraltete SEO-Glaubenssätze als „Stützräder für Suchmaschinen“ und fügte hinzu, dass LSI „wenig bis gar keine Relevanz dafür hat, wie Suchmaschinen Websites heute bewerten“.
Die Bedeutung einer Suchanfrage ist eng mit der dahinter stehenden Absicht verknüpft. Google pflegt ein Dokument mit dem Namen Search Quality Evaluator Guidelines. In diesen Richtlinien führen sie vier hilfreiche Kategorien für die Benutzerabsicht ein:
- Know-Abfrage – Dies stellt die Suche nach Informationen zu einem Thema dar. Eine Variante davon ist die „Know Simple“-Abfrage, bei der Benutzer mit einer bestimmten Antwort im Hinterkopf suchen.
- Abfrage durchführen – Dies spiegelt den Wunsch wider, sich an einer bestimmten Aktivität zu beteiligen, z. B. einem Online-Kauf oder Download. Alle diese Abfragen können durch ein Gefühl der „Interaktion“ definiert werden.
- Website-Abfrage – Dies ist, wenn Benutzer nach einer bestimmten Website oder Seite suchen. Diese Suchanfragen weisen auf eine vorherige Bekanntheit einer bestimmten Website oder Marke hin.
- Visit-in-Person Query – Der Benutzer sucht nach einem physischen Standort, z. B. einem stationären Geschäft oder einem Restaurant.
Die Theorie hinter LSI – die Definition der kontextuellen Bedeutung eines Wortes innerhalb eines Satzes – verschaffte Google einen Wettbewerbsvorteil. Allerdings begann sich die Idee zu verbreiten, dass „LSI-Keywords“ plötzlich ein goldenes Ticket zum SEO-Erfolg seien.

Gibt es eigentlich „LSI-Keywords“?
Viele bemerkenswerte Veröffentlichungen bleiben entschiedene Befürworter von LSI-Schlüsselwörtern. Doch mehrere Quellen, wie Googles Webmaster Trends Analyst John Mueller, behaupten, dass sie ein Mythos sind. Diese Quellen begannen, die folgenden Punkte anzusprechen:
- LSI wurde vor dem World Wide Web entwickelt und sollte nicht auf einen so großen und dynamischen Datensatz angewendet werden.
- Das US-Patent für Latent Semantic Indexing, das 1989 einer Organisation namens Bell Communications Research Inc. erteilt wurde, wäre 2008 abgelaufen. Laut Bill Slawski wäre die Verwendung von LSI durch Google daher vergleichbar mit der Verwendung eines intelligenten Telegrafengeräts zur Verbindung das mobile Web.'
- Google verwendet RankBrain, eine maschinelle Lernmethode, die Textmengen in „Vektoren“ umwandelt – mathematische Einheiten, die Computern helfen, geschriebene Sprache zu verstehen. RankBrain nimmt das Web als ständig wachsenden Datensatz auf und macht es im Gegensatz zu LSI für Google nutzbar.
Letztendlich enthüllt LSI eine Wahrheit, an die sich Marketingfachleute halten sollten: Die Untersuchung des einzigartigen Kontexts eines Wortes hilft uns, die Benutzerabsicht besser zu verstehen als Schlüsselwörter, die in Inhalte gestopft werden. Dies bestätigt jedoch nicht unbedingt, dass Google nach LSI rankt. Kann man daher mit Sicherheit sagen, dass LSI im Bereich SEO eher eine Philosophie als eine exakte Wissenschaft ist?
Kehren wir zu dem Zitat von Roger Montti über LSI als „Stützräder für Suchmaschinen“ zurück. Sobald Sie das Fahrradfahren gelernt haben, neigen Sie dazu, die Stützräder abzunehmen. Können wir davon ausgehen, dass Google im Jahr 2020 keine Stützräder mehr verwendet?
Wir können das jüngste Algorithmus-Update von Google in Betracht ziehen. Im Oktober 2019 gab Pandu Nayak, Vice President of Search, bekannt, dass Google damit begonnen hat, ein KI-System namens BERT (Bidirectional Encoder Representations from Transformers) zu verwenden. Mit über 10 % aller Suchanfragen ist dies eines der größten Google-Updates der letzten Jahre.
Bei der Analyse einer Suchanfrage betrachtet BERT ein einzelnes Wort im Verhältnis zu allen Wörtern in diesem bestimmten Satz. Diese Analyse ist bidirektional, da sie alle Wörter vor oder nach einem bestimmten Wort berücksichtigt. Das Entfernen eines einzelnen Wortes könnte sich drastisch darauf auswirken, wie BERT den einzigartigen Kontext eines Satzes versteht.
Dies steht im Gegensatz zu LSI, das alle Stoppwörter aus seiner Analyse auslässt. Das folgende Beispiel zeigt, wie das Entfernen von Stoppwörtern das Verständnis eines Satzes verändern kann:
![]()
Obwohl es sich um ein Stoppwort handelt, ist „finden“ der Kern der Suche, die wir als eine „Besuch-in-Person“-Abfrage definieren würden.
Was sollten Marketer also tun?
Ursprünglich wurde angenommen, dass LSI Google helfen könnte, Inhalte mit relevanten Suchanfragen abzugleichen. Es scheint jedoch, dass die Debatte im Marketing um die Verwendung von LSI noch zu einer einzigen Schlussfolgerung gelangt ist. Trotzdem können Marketer noch viele Schritte unternehmen, um sicherzustellen, dass ihre Arbeit strategisch relevant bleibt.
Erstens sollten Artikel, Webtexte und bezahlte Kampagnen so optimiert werden, dass sie Synonyme und Varianten enthalten. Dies erklärt die Art und Weise, wie Menschen mit ähnlichen Absichten Sprache unterschiedlich verwenden.
Vermarkter müssen weiterhin mit Autorität und Klarheit schreiben. Dies ist ein absolutes Muss, wenn sie möchten, dass ihre Inhalte ein bestimmtes Problem lösen. Dieses Problem kann ein Mangel an Informationen oder der Bedarf an einem bestimmten Produkt oder einer bestimmten Dienstleistung sein. Sobald Marketer dies tun, zeigt dies, dass sie die Absicht der Nutzer wirklich verstehen.
Schließlich sollten sie auch häufig von strukturierten Daten Gebrauch machen. Ob es sich um eine Website, ein Rezept oder eine FAQ handelt, strukturierte Daten liefern den Kontext für Google, um zu verstehen, was gecrawlt wird.