
[Webinar Digest] SEO in Orbit: Neue Perspektiven auf Duplicate Content
Veröffentlicht: 2019-11-20Das Webinar „Neue Perspektiven zu doppelten Inhalten“ ist die letzte Folge der Reihe „SEO in Orbit“ und wurde am 24. Juni 2019 ausgestrahlt. Schließen Sie sich in dieser Folge OnCrawl-Botschafter Omi Sido und Alexis Sanders an, wenn sie die Frage nach doppelten Inhalten untersuchen. Sie beschäftigen sich mit Fragen wie: Wie wirken sich Ranking-Faktoren und sich entwickelnde Suchtechnologien auf die Art und Weise aus, wie wir mit Duplicate Content umgehen? Und: Wie sieht die Zukunft für ähnliche Inhalte im Web aus?
SEO in Orbit ist die erste Webinar-Reihe, die SEO in den Weltraum schickt. Während der gesamten Serie haben wir mit einigen der besten SEO-Spezialisten über die Gegenwart und die Zukunft der technischen SEO diskutiert und ihre Top-Tipps am 27. Juni 2019 ins All geschickt.
Sehen Sie sich hier die Wiederholung an:
Wir präsentieren Alexis Sanders
Alexis Sanders arbeitet als Technical SEO Account Manager bei Merkle. Das technische SEO-Team stellt die Genauigkeit, Durchführbarkeit und Skalierbarkeit der technischen Empfehlungen der Agentur in allen Branchen sicher. Sie ist Mitarbeiterin des Moz-Blogs und Schöpferin der TechnicalSEO.expert-Challenge und des SEO in the Lab-Podcasts.
Diese Folge wurde von Omi Sido moderiert. Omi ist ein erfahrener internationaler Redner und in der Branche für seinen Humor und seine Fähigkeit bekannt, umsetzbare Erkenntnisse zu liefern, die das Publikum sofort nutzen kann. Von der SEO-Beratung mit einigen der weltweit größten Telekommunikations- und Reiseunternehmen bis hin zur Verwaltung der internen SEO bei HostelWorld und Daily Mail, Omi liebt es, in komplexe Daten einzutauchen und die Lichtblicke zu finden. Derzeit ist Omi Senior Technical SEO bei Canon Europe und OnCrawl Ambassador.
Was ist doppelter Inhalt?
Omi bietet die folgende Definition von Duplicate Content:
Duplizieren von Inhalten, die Inhalten ähnlich oder nahezu ähnlich sind, die sich unter einer anderen URL auf derselben (oder einer anderen) Website befinden.
Der Mythos der Duplicate Content Penalty
Es gibt keine Strafe für doppelte Inhalte.
Dies ist ein Leistungsproblem. Wir wollen nicht, dass ein Bot sich zwei bestimmte URLs ansieht und denkt, dass es sich um zwei unterschiedliche Inhalte handelt, die nebeneinander gerankt werden können.
Alexis vergleicht das Verständnis eines Bots Ihrer Website mit Joeys Bildern aus 10 Dinge, die ich an dir hasse: Es ist für einen Bot unmöglich, einen wesentlichen Unterschied zwischen den beiden Versionen zu finden.

Sie möchten vermeiden, dass zwei genau dieselben Dinge in einer Suchmaschinen-Ranking-Situation miteinander konkurrieren müssen. Stattdessen möchten Sie eine einzige, konsolidierte Erfahrung haben, die in Suchmaschinen ranken und performen kann.
Unterschied zwischen dem, was Benutzer und Bots sehen
Ein Benutzer sieht möglicherweise eine einzige überzeugende URL, aber ein Bot sieht möglicherweise immer noch mehrere Versionen, die für ihn im Wesentlichen gleich aussehen.
– Auswirkungen auf das Crawling-Budget für sehr große Websites
Bei sehr großen Websites wie Zillow oder Walmart kann das Crawling-Budget für verschiedene Seiten variieren.
Wie Alexis in einem Artikel aus dem Jahr 2018 auf der Grundlage einer Präsentation von Frederic Dubut auf der SMX East erläuterte, werden Budgets auf unterschiedlichen Ebenen festgelegt – auf Subdomain-Ebenen, auf verschiedenen Serverebenen. Suchmaschinen, ob Google oder Bing, wollen höfliche Crawler sein; Sie möchten die Leistung für tatsächliche Benutzer nicht verlangsamen. Wann immer sie eine Leistungsänderung spüren, werden sie sich zurückziehen. Dies kann auf verschiedenen Ebenen geschehen, nicht nur auf Site-Ebene.
Wenn Sie eine riesige Website haben, möchten Sie sicherstellen, dass Sie die konsolidierteste Erfahrung bieten, die für Ihre Benutzer relevant ist.
Ist Duplicate Content ein inhaltliches oder ein technisches Problem?
Trotz des Wortes „Content“ in „Duplicate Content“ handelt es sich teilweise um ein technisches Problem.
– Vervielfältigungsquellen – [07:50]
Es gibt viele Faktoren, die zu Duplikaten führen können. Sogar eine unvollständige Liste kann scheinbar ewig weitergehen:
- Sich wiederholende Seiten
- Staging-Sites
- HTTP vs. HTTPS-URLs
- Verschiedene Subdomains
- Verschiedene Fälle
- Verschiedene Dateierweiterungen
- Schrägstrich
- Indexseiten
- URL-Parameter
- Facetten
- Sortiert
- druckerfreundliche Version
- Doorway-Seite
- Inventar
- Syndizierter Inhalt
- PR-Veröffentlichungen
- Neuveröffentlichung von Inhalten
- Plagiate Inhalte
- Lokalisierte Inhalte
- Dünner Inhalt
- Nur-Bilder
- Interne Seitensuche
- Separate mobile Website
- Nicht eindeutige Inhalte
- …
– Aufteilung der Probleme zwischen technischem SEO und Inhalt
Tatsächlich können diese Quellen von doppelten Inhalten in technische und Entwicklungsquellen und inhaltsbasierte Quellen aufgeteilt werden, und einige, die in eine Überschneidungszone zwischen den beiden fallen.
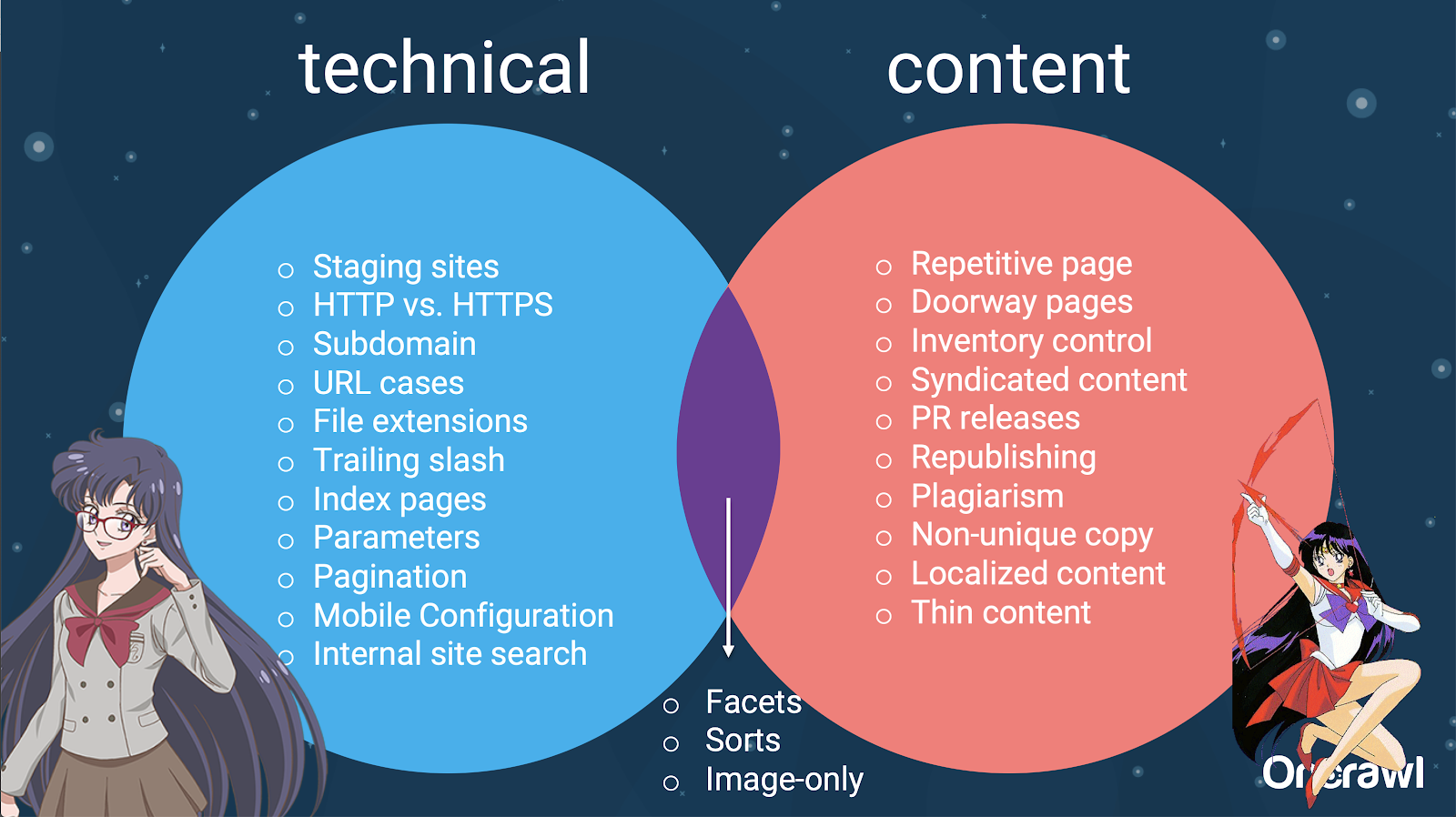
Das macht Duplicate Content zu einem teamübergreifenden Thema, was es so interessant macht.
So finden Sie Duplicate Content
Die meisten doppelten Inhalte sind unbeabsichtigt. Für Omi bedeutet dies, dass es eine gemeinsame Verantwortung zwischen Inhalts- und technischen Teams gibt, doppelte Inhalte zu finden und zu beheben.
– Omis Lieblingstool: Grammarly
Grammarly ist Omis Lieblingstool zum Auffinden doppelter Inhalte – und es ist nicht einmal ein SEO-Tool. Er nutzt die Plagiatsprüfung. Er bittet den Inhaltsherausgeber zu prüfen, ob ein neuer Inhalt bereits woanders veröffentlicht wurde.
– Umfang unbeabsichtigter doppelter Inhalte
Das Problem unbeabsichtigter doppelter Inhalte ist Ingenieuren bestens vertraut. In einem Buch mit dem Titel Introduction to Information Retrieval (2008), das eindeutig veraltet ist, schätzten sie, dass etwa 40 % des Webs zu dieser Zeit dupliziert waren.

– Priorisierung von Strategien zum Umgang mit Duplicate Content
Um mit doppelten Inhalten umzugehen, sollten Sie:
- Beginnen Sie damit, Ihre Benutzerreise zu kennen, die Ihnen hilft zu verstehen, wo jeder Inhalt passt. Dies kann äußerst schwierig sein, insbesondere wenn Websites vor 20 Jahren erstellt wurden, als wir nicht wussten, wie groß sie werden oder wie sie skalieren würden. Wenn Sie wissen, wo sich Ihr Benutzer an einem bestimmten Punkt seiner Reise befindet, können Sie bei einigen der nächsten Schritte Prioritäten setzen.
- Sie benötigen eine funktionierende Hierarchie, um für jeden Inhaltstyp einen Platz bereitzustellen. Das Verständnis Ihrer Informationsarchitektur steht ganz oben in den Schritten zum Umgang mit Duplicate Content.
- Priorisieren Sie doppelte Inhalte, die sich auf die Leistung auswirken. Die unvollständige Liste der obigen Quellen ist viel zu lang, um etwas zu sein, das Sie realistisch auf einmal angreifen können.
- Gehen Sie mit 100% Duplizierung um
- Duplicate Content signalisieren
- Treffen Sie strategische Entscheidungen zum Umgang mit Duplikaten: konsolidieren, erstellen, löschen, optimieren
- Gehen Sie mit gestohlenen Inhalten um

– Tools: Segmentierung in OnCrawl verwenden
Alexis mag die Möglichkeit, Ihre Website in OnCrawl zu segmentieren, was es Ihnen ermöglicht, in Dinge einzutauchen, die für Sie von Bedeutung sind.
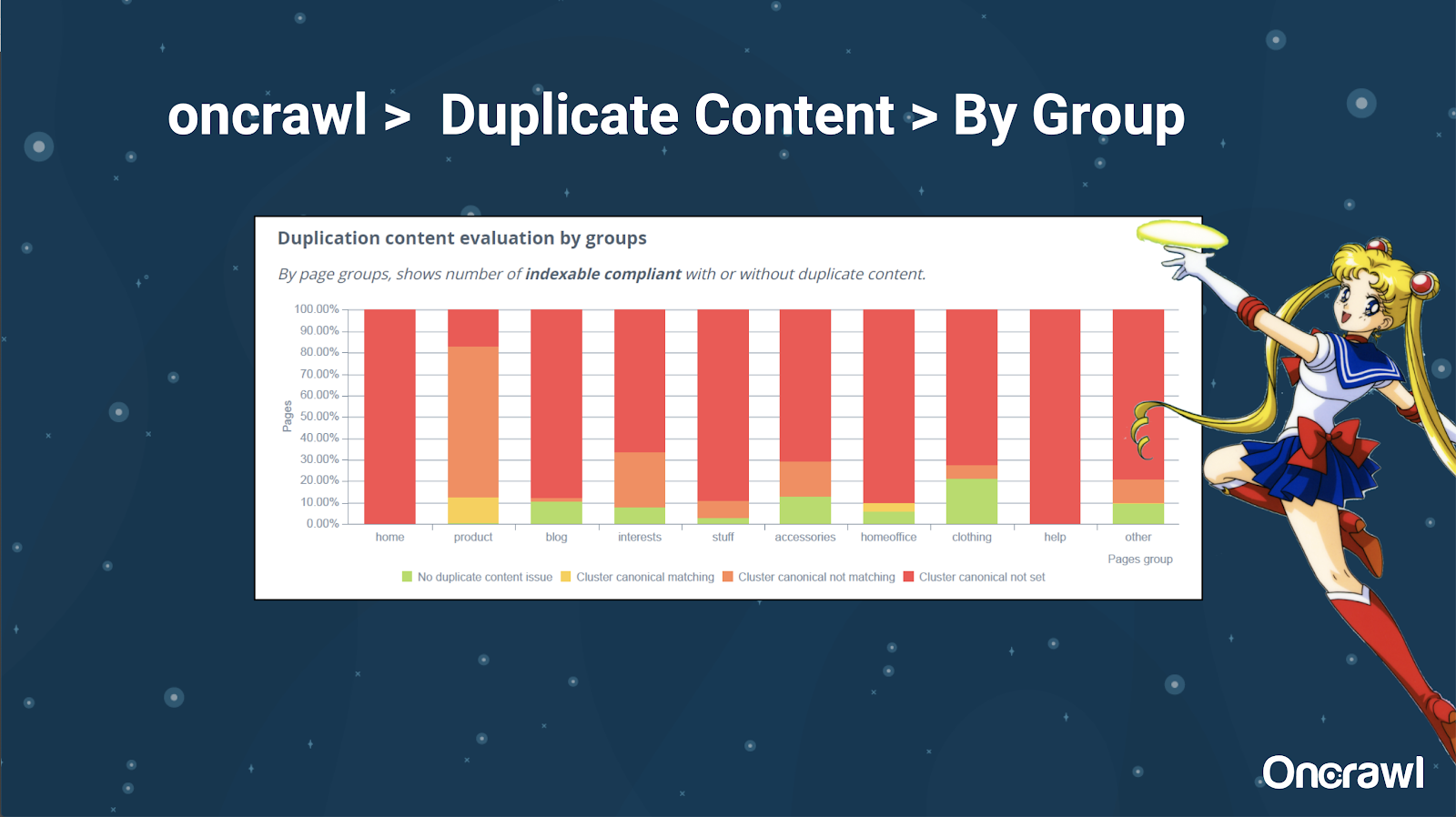
Verschiedene Arten von Seiten haben unterschiedliche Duplizierungsmengen; Auf diese Weise erhalten Sie einen Überblick über die Abschnitte mit den meisten Problemen. Im obigen Beispiel benötigt die Website viel Aufmerksamkeit.
– Tools: Google-Suche und GSC
Sie können auch mit der Suchmaschine selbst nach Duplicate Content suchen. Bei Google können Sie:
- Verwenden Sie direkte Anführungszeichen
- Website verwenden: sucht
- Verwendung zusätzlicher Operatoren wie inurl:, intitle: oder filetype:

Die Google Search Console hat auch einen Duplicate-Content-Bericht hinzugefügt, der sehr nützlich ist, um zu identifizieren, was Google von ihrer Seite aus für Duplicate Content hält.
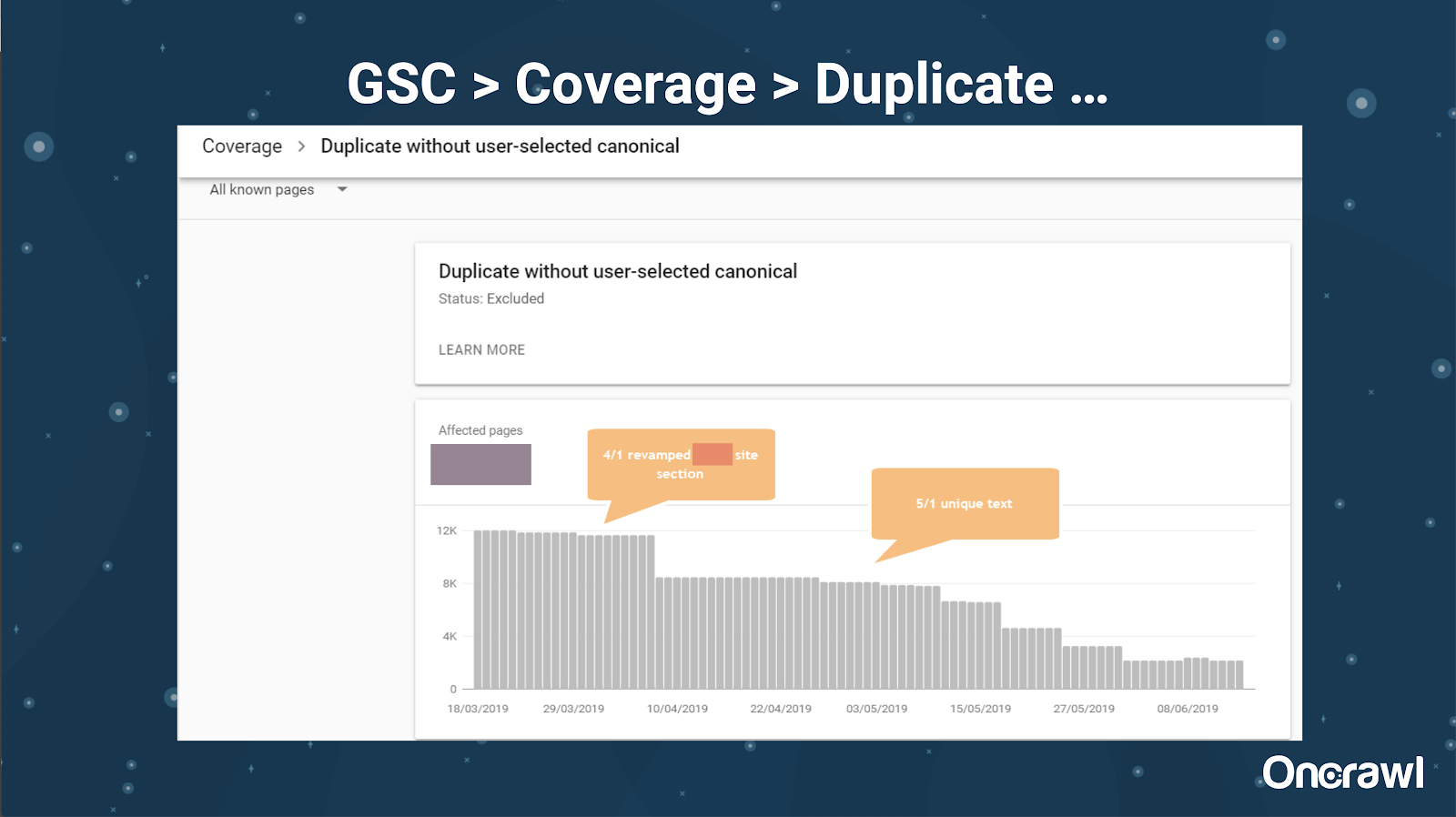
– Tools: Plagiatstools
Wie Omi verwendet auch Alexis verschiedene Plagiatstools:
Quetext
Noplag
PaperRater
Grammatik
CopyScape
Sie möchten sicherstellen, dass Ihre Inhalte nicht nur originell sind, sondern auch aus der Sicht eines Bots nicht als aus einer anderen Quelle stammend wahrgenommen werden.
Diese können Ihnen auch dabei helfen, Segmente innerhalb eines Artikels zu finden, die möglicherweise anderen Inhalten im Internet ähneln.
Alexis liebt es, dass wir diese Tools haben, die es uns ermöglichen, „Suchmaschinen-Bots gegenüber empathisch zu sein“, da keiner von uns Roboter sind. Wenn Tools uns signalisieren, dass Inhalte zu ähnlich sind, auch wenn wir wissen, dass es einen Unterschied gibt, ist das ein gutes Zeichen dafür, dass es etwas zu entdecken gibt.
– Tools: Keyword-Dichte-Tools
Zwei Beispiele für Keyword-Dichte-Tools, die Alexis verwendet, sind:
TagCrowd
SEObook

Probleme abhängig von der Art der Website
Die Lösung doppelter Inhalte hängt wirklich von der Art des Inhalts ab, den Sie veröffentlichen, und der Art des Problems, mit dem Sie konfrontiert sind. Blogs sind beispielsweise nicht mit denselben Fällen von doppelten Inhalten konfrontiert wie E-Commerce-Websites.
Denkwürdige Fälle
Alexis teilt aktuelle Kundenfälle, in denen sie denkwürdige Probleme mit doppelten Inhalten gefunden hat.
– Extrem große Website: Ergebnisse nach dem Hinzufügen einzigartiger Inhalte
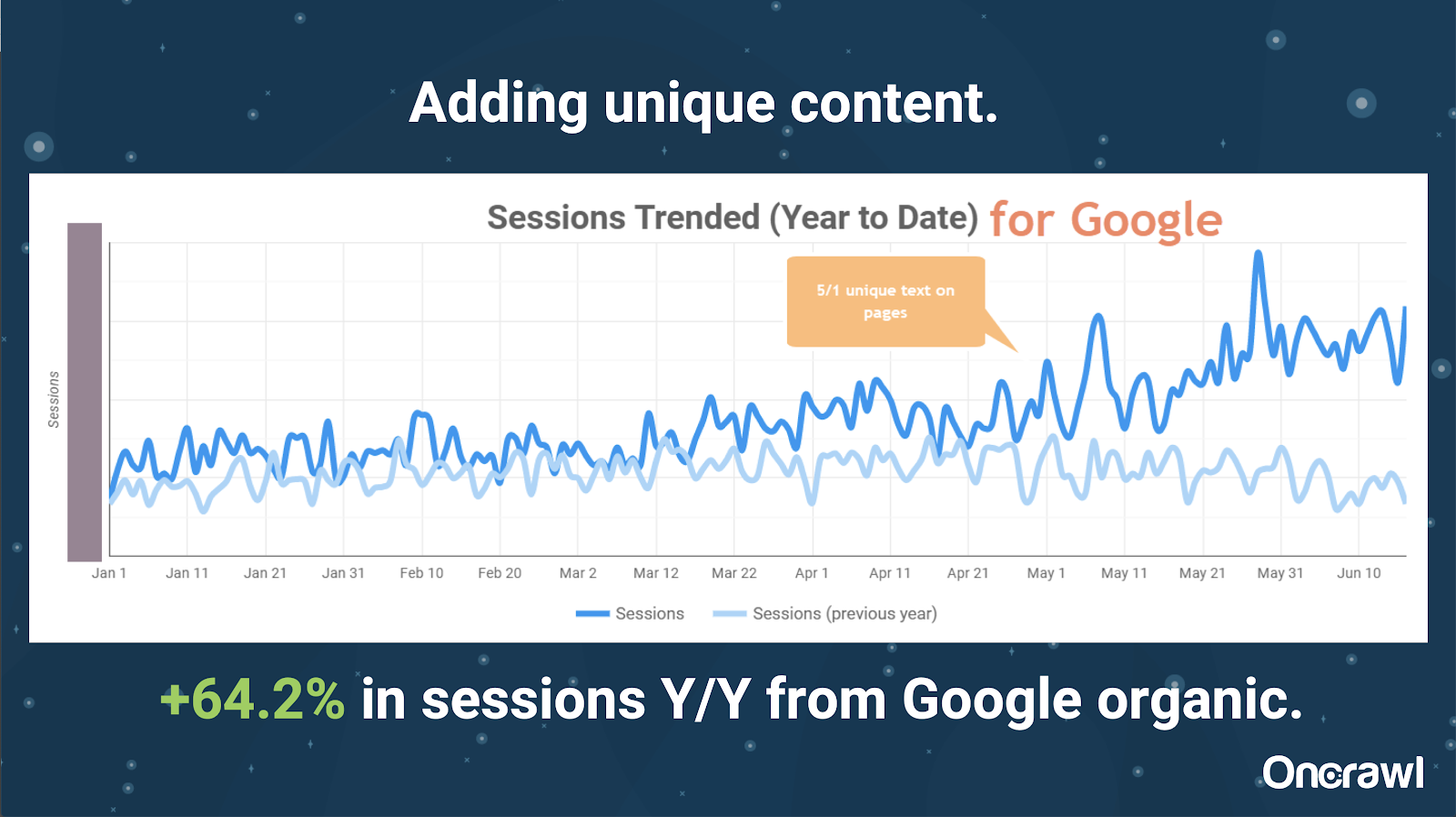
Diese Seite war enorm groß und hat Probleme mit dem Crawl-Budget. Es hat 86 Millionen Seiten, die noch nicht indiziert wurden, und nur etwa 1 % seiner Seiten wurden indiziert.
Dies ist eine Immobilienseite, so dass ein Großteil des Inhalts nicht besonders einzigartig ist und viele ihrer Seiten sehr, sehr ähnlich sind. Alexis fügte schließlich Inhalte zur Seite hinzu, um standortspezifische Informationen hinzuzufügen, um Seiten zu differenzieren. Es war überraschend, wie schnell dies zu Ergebnissen führte. (Dies sind nur organische Daten von Google.)
Für Alexis ist dies eine ziemlich allgemeine Fallstudie. So oft wir heute über EAT und ähnliche Dinge sprechen, zeigt dies, dass Inhalte, die Suchmaschinen als einzigartig und wertvoll ansehen, immer noch belohnt werden.

Auf dieser Website wurden aufgrund eines versehentlichen Canonical-Tag-Problems etwa 250 Seiten an das falsche Protokoll gesendet.
Dies ist ein Fall, in dem kanonische Tags die falsche Hauptseite anzeigten und die HTTP-Seiten anstelle der HTTPS-Seite pushten.
Änderungen in den letzten 18 Monaten
Alexis hat etwa 18 Monate vor diesem Webinar einen sehr vollständigen Artikel mit dem Titel Duplicate Content and Strategic Resolution geschrieben. SEO ändert sich schnell, und Sie müssen Ihr Wissen ständig erneuern und neu bewerten.
Für Alexis ist das meiste, was im Artikel erwähnt wird, auch heute noch relevant, mit Ausnahme von rel=next/prev. Sie hofft jedoch, dass es in den nächsten fünf bis zehn Jahren keine Relevanz mehr haben wird.
Technische Probleme, die von Entwicklern behandelt werden: zu manuell
Viele der Probleme im Zusammenhang mit doppelten Inhalten, die von Entwicklern behandelt werden, sind viel zu manuell. Alexis glaubt, dass sie stattdessen von CMS und Adobe gehandhabt werden sollten. Zum Beispiel sollten Sie nicht manuell durchgehen und sicherstellen müssen, dass alle Canonicals gesetzt und kohärent sind.
– Automatisierungs-/Benachrichtigungsmöglichkeiten
Im Bereich technischer Probleme mit Duplicate Content gibt es viele Automatisierungsmöglichkeiten. Um ein Beispiel zu nennen: Wir sollten in der Lage sein, sofort zu erkennen, ob Links zu HTTP gehen, wenn sie zu HTTPS gehen sollten, und sie zu korrigieren.
– Standortalter und veraltete Infrastruktur als Hindernis
Einige Backend-Systeme sind viel zu alt, um bestimmte Änderungen und Automatisierungen zu unterstützen. Es ist extrem schwierig, ein altes CMS auf ein neues zu migrieren. Omi nennt als Beispiel die Migration von Canon-Websites auf ein neues, kundenspezifisches CMS. Es war nicht nur teuer, sondern es dauerte 12 Monate.
Rel prev/next und Kommunikation von Google
Manchmal ist die Kommunikation von Google etwas verwirrend. Omi nennt ein Beispiel, bei dem sein Kunde 2018 durch die Anwendung von rel=prev/next eine deutliche Leistungssteigerung verzeichnete, obwohl Google 2019 angekündigt hatte, dass diese Tags seit Jahren nicht mehr verwendet werden.
– Mangel an Einheitslösungen
Die Schwierigkeit bei SEO besteht darin, dass das, was eine Person auf ihrer Website beobachtet, nicht unbedingt mit dem übereinstimmt, was ein anderer SEO auf ihrer eigenen Website sieht. es gibt kein One-size-fits-all-SEO.
Die Fähigkeit von Google, Ankündigungen zu machen, die für alle SEOs relevant sind, sollte als große Leistung anerkannt werden, selbst einige ihrer Aussagen sind ein Fehlschlag, wie im Fall von rel=next/prev.
Hoffnungen für die Zukunft des Duplicate Content Managements
Alexis Hoffnungen für die Zukunft:
- Weniger technisch basierte doppelte Inhalte (wie CMSs klüger werden).
- Mehr Automatisierung (Unit-Tests und externe Tests). Beispielsweise können Tools wie OnCrawl Ihre Website regelmäßig crawlen und Sie benachrichtigen, sobald sie bestimmte Fehler bemerken.
- Automatische Erkennung von Seiten mit hoher Ähnlichkeit und Seitentypen für Autoren und Content-Manager. Dies würde einige der Überprüfungen automatisieren, die derzeit manuell in Tools wie Grammarly durchgeführt werden: Wenn jemand versucht zu veröffentlichen, sollte das CMS sagen: „Das ist irgendwie ähnlich – sind Sie sicher, dass Sie das veröffentlichen möchten?“ Es ist sehr wertvoll, sich einzelne Websites sowie den Vergleich zwischen Websites anzusehen.
- Google verbessert weiterhin seine bestehenden Systeme und die Erkennung.
- Vielleicht ein Warnsystem, um das Problem zu eskalieren, dass Google nicht das richtige Canonical verwendet. Es wäre hilfreich, Google auf das Problem aufmerksam zu machen und es lösen zu lassen.
Wir brauchen bessere Tools, bessere interne Tools, aber wenn Google seine Systeme entwickelt, werden sie hoffentlich Elemente hinzufügen, die uns ein wenig helfen.
Alexis' technische Lieblingstricks
Alexis hat mehrere technische Lieblingstricks:
- EC2-Remotecomputerinstanz. Dies ist eine wirklich großartige Möglichkeit, für sehr große Crawls oder alles, was viel Rechenleistung erfordert, auf einen echten Computer zuzugreifen. Es ist extrem schnell, wenn Sie es einmal eingerichtet haben. Stellen Sie nur sicher, dass Sie es beenden, wenn Sie fertig sind, da es Geld kostet.
- Überprüfen Sie zuerst das Mobile-First-Testtool. Google hat erwähnt, dass dies das genaueste Bild dessen ist, was sie sehen. Es betrachtet das DOM.
- User-Agent auf Googlebot umstellen. Dadurch erhalten Sie eine Vorstellung davon, was Googlebots wirklich sehen.
- Verwenden des robots.txt-Tools von TechnicalSEO.com. Dies ist eines von Merkles Tools, aber Alexis liebt es wirklich, weil robots.txt manchmal wirklich verwirrend sein kann.
- Verwenden Sie einen Protokollanalysator.
- Made with Loves htaccess-Checker.
- Verwenden von Google Data Studio zum Melden von Änderungen (Synchronisieren von Tabellen mit Updates, Filtern jeder Seite nach relevanten Updates).
Technische SEO-Schwierigkeiten: robots.txt
Robots.txt ist wirklich verwirrend.
Es ist eine archaische Datei, die so aussieht, als sollte sie RegEx unterstützen können, tut es aber nicht.
Es gibt unterschiedliche Vorrangregeln für das Verbieten und das Zulassen von Regeln, was verwirrend sein kann.
Verschiedene Bots können verschiedene Dinge ignorieren, obwohl sie das nicht sollten.
Ihre Annahmen darüber, was richtig ist, sind nicht immer richtig.

Fragen und Antworten
– HSTS: Split-Protokoll erforderlich?
Sie müssen alle HTTPS für Duplicate Content haben, wenn Sie HSTS haben.
– Ist übersetzter Inhalt Duplicate Content?
Wenn Sie hreflang verwenden, verwenden Sie es häufig, um zwischen lokalisierten Versionen innerhalb derselben Sprache zu unterscheiden, z. B. einer US-amerikanischen und einer irisch-englischsprachigen Seite. Alexis würde diesen doppelten Inhalt nicht in Betracht ziehen, aber sie würde auf jeden Fall empfehlen, sicherzustellen, dass Sie Ihre hreflang-Tags korrekt eingerichtet haben, um anzuzeigen, dass dies dieselbe Erfahrung ist, die für verschiedene Zielgruppen optimiert ist.
– Können Sie Canonical Tags anstelle von 301-Weiterleitungen für eine HTTP/HTTPS-Migration verwenden?
Es wäre nützlich zu überprüfen, was tatsächlich in den SERPs passiert. Alexis' Instinkt sagt, dass dies in Ordnung wäre, aber es hängt davon ab, wie sich Google tatsächlich verhält. Wenn es sich um genau dieselbe Seite handelt, würden Sie im Idealfall einen 301 verwenden, aber sie hat in der Vergangenheit gesehen, dass kanonische Tags für diese Art der Migration funktionieren. Sie hat das tatsächlich sogar zufällig gesehen.
Nach Omis Erfahrung würde er dringend empfehlen, 301 zu verwenden, um Probleme zu vermeiden: Wenn Sie die Website migrieren, können Sie sie genauso gut korrekt migrieren, um aktuelle und zukünftige Fehler zu vermeiden.
– Auswirkung von doppelten Seitentiteln
Angenommen, Sie haben einen Titel, der für verschiedene Standorte sehr ähnlich ist, aber der Inhalt ist sehr unterschiedlich. Für Alexis ist dies zwar kein Duplicate Content, aber sie betrachtet dies als etwas „Allgemeines“, das von Suchmaschinen behandelt wird, und Titel sind etwas, das verwendet werden kann, um Bereiche mit möglichen Problemen zu identifizieren.
An dieser Stelle möchten Sie vielleicht eine [site: + intitle: ]-Suche verwenden.
Nur weil Sie denselben Titel-Tag haben, wird dies jedoch kein Problem mit doppelten Inhalten verursachen.
Sie sollten dennoch auf eindeutige Titel und Meta-Beschreibungen abzielen, selbst auf paginierten oder anderen sehr ähnlichen Seiten. Das liegt nicht an Duplicate Content, sondern betrifft vielmehr die Art und Weise, wie Sie Ihre Seiten in den SERPs optimieren wollen.
Top Tipp
„Duplicate Content ist sowohl eine technische als auch eine Content-Marketing-Herausforderung.“
SEO in Orbit ging in den Weltraum
Wenn Sie unsere Reise ins All am 27. Juni verpasst haben, sehen Sie sie sich hier an und entdecken Sie alle Tipps, die wir ins All geschickt haben.