
Verwenden von Python und Sitemaps zum Auditieren von Content-Strategien
Veröffentlicht: 2020-10-08Das Interesse daran, was mit Python Libraries für SEO getan werden kann, ist kein Geheimnis mehr. Die meisten Menschen mit wenig Programmiererfahrung haben jedoch Schwierigkeiten beim Importieren und Verwenden einer großen Anzahl von Bibliotheken oder beim Pushen von Ergebnissen, die über das hinausgehen, was ein gewöhnlicher Crawler oder ein SEO-Tool leisten kann.
Aus diesem Grund ist eine Python-Bibliothek, die speziell für SEO, SEM, SMO, SERP-Check und Inhaltsanalyse erstellt wurde, für alle nützlich.
In diesem Artikel werfen wir einen Blick auf einige der Dinge, die mit der von Elias Dabbas erstellten und entwickelten Advertools Python Library für SEO getan werden können und für die ich ein großes Potenzial in SEO, PPC und Codierungsfunktionen sehe in sehr kurzer Zeit. Außerdem werden wir benutzerdefinierte Python-Skripte zusammen mit anderen Python-Bibliotheken auf lehrreiche und adaptive Weise verwenden.
Wir werden untersuchen, was man dank der sitemap_to_df-Funktion von Elias Dabbas, die beim Herunterladen und Analysieren von XML-Sitemaps hilft, aus einer Sitemap für SEO lernen kann (Eine Sitemap ist ein Dokument im XML-Format, das verwendet wird, um crawlbare und indexierbare URLs an Suchmaschinen zu melden.)
Dieser Artikel zeigt Ihnen, wie Sie benutzerdefinierte Python-Codes schreiben können, um verschiedene Websites nach ihrer unterschiedlichen Struktur zu analysieren, wie Sie Daten in Bezug auf SEO interpretieren und wie Sie wie eine Suchmaschine denken, wenn es um Inhaltsprofile, URLs und Website-Strukturen geht .
Analysieren des Inhaltsumfangs und der Strategie einer Website basierend auf ihrer Sitemap
Eine Sitemap ist eine Komponente einer Website, die viele verschiedene Arten von Daten erfassen kann, z. B. wie oft eine Website Inhalte veröffentlicht, Inhaltskategorien, Veröffentlichungsdaten, Autoreninformationen, Inhaltsthema …
Unter normalen Bedingungen können Sie eine Sitemap mit Scrapy scrapen, mit Pandas in einen DataFrame konvertieren und bei Bedarf mit vielen verschiedenen Hilfsbibliotheken interpretieren.
Aber in diesem Artikel werden wir nur Methoden und Attribute von Advertools und einigen Pandas-Bibliotheken verwenden. Einige Bibliotheken werden aktiviert, um die von uns erfassten Daten zu visualisieren.
Lassen Sie uns gleich eintauchen und eine Website auswählen, um ihre Sitemap zu verwenden, um einige wichtige SEO-Einblicke zu gewinnen.
Extrahieren und Erstellen von Datenrahmen aus Sitemaps mit Advertools
In Advertools können Sie alle Sitemaps einer Website mit nur einer Codezeile entdecken, durchsuchen und kombinieren.
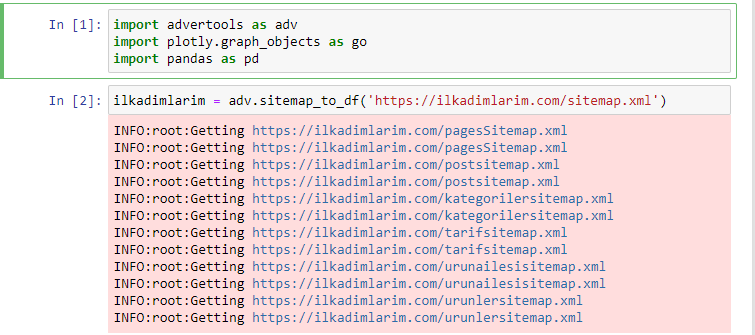
Ich liebe es, Jupyter Notebook anstelle eines normalen Code-Editors oder einer IDE zu verwenden.
In die erste Zelle haben wir Pandas und Advertools zum Sammeln und Organisieren von Daten und Plotly.graph_objects zum Visualisieren von Daten importiert.
Der Befehl adv.sitemap_to_df('Sitemap-Adresse') sammelt einfach alle Sitemaps und vereinheitlicht sie als DataFrame.
Wenn Sie dasselbe mit Pandas und Advertools tun, können Sie herausfinden, welche URL in welcher Sitemap verfügbar ist.
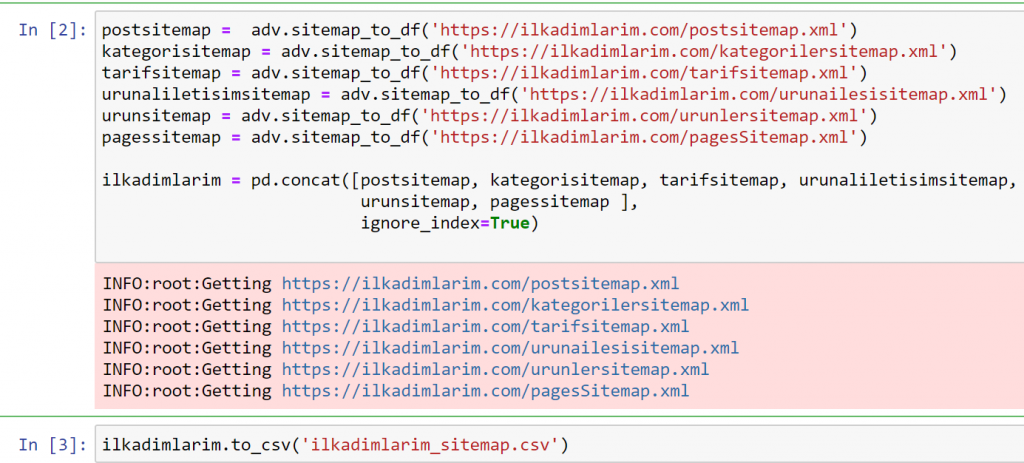
Im obigen Beispiel haben wir dieselben Sitemaps separat gezogen und dann mit dem Befehl pd.concat kombiniert und das Ergebnis in CSV übertragen. Im vorherigen Beispiel wurde die Sitemap-Indexdatei verwendet. In diesem Fall ruft die Funktion alle anderen Sitemaps ab. Sie haben also die Möglichkeit, wie wir es hier getan haben, bestimmte Sitemaps auszuwählen, wenn Sie sich für einen bestimmten Abschnitt der Website interessieren.
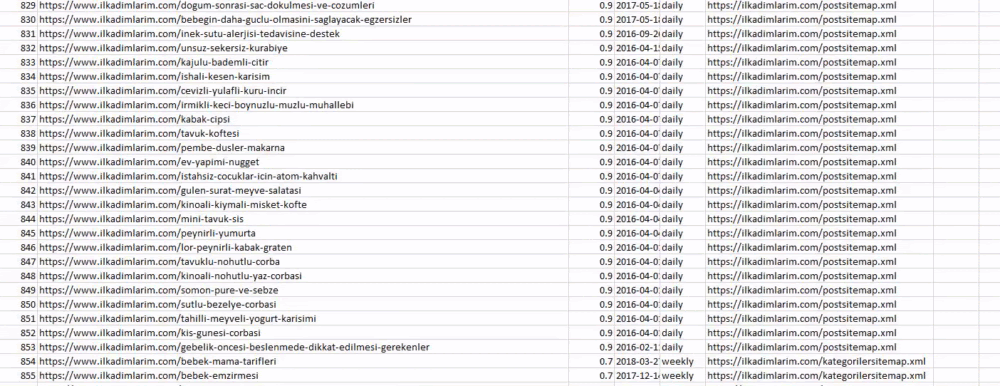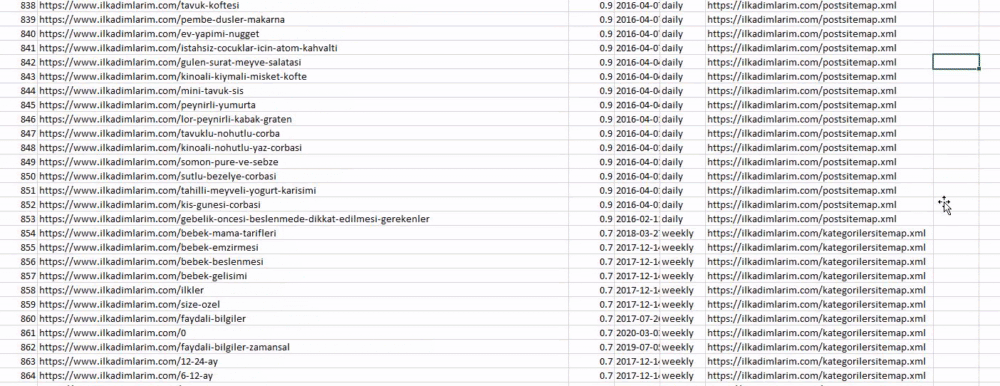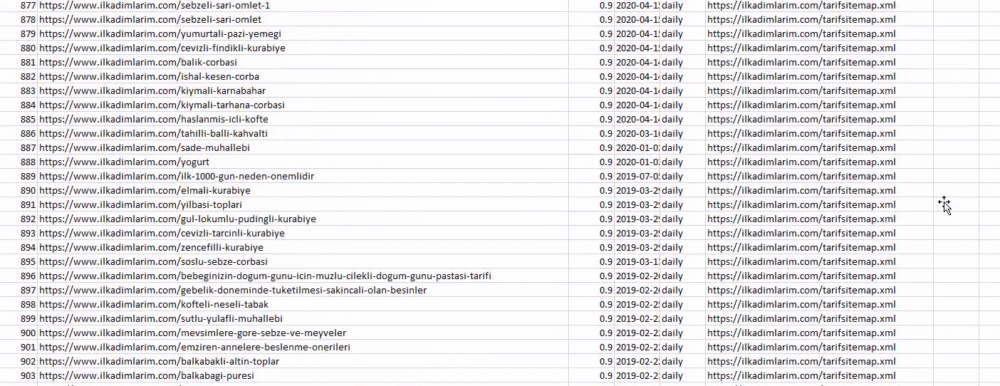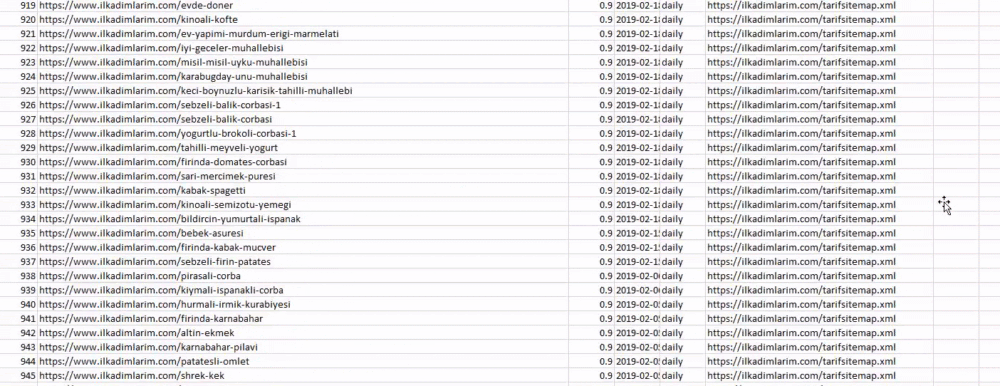
Oben sehen Sie eine Spalte mit verschiedenen Sitemap-Namen. ignore_index=True-Abschnitt ist für die ordentliche Reihenfolge der Indexnummern verschiedener DataFrames, wenn Sie mehrere zusammengeführt haben.
Oncrawl-Daten³
 Mehr erfahren
Mehr erfahrenBereinigen und Vorbereiten des Sitemap-Datenrahmens für die Inhaltsanalyse mit Python
Um das Inhaltsprofil einer Website durch eine Sitemap zu verstehen, müssen wir sie vorbereiten, um den DataFrame zu überprüfen, den wir mit Advertools erhalten haben.
Wir werden einige grundlegende Befehle aus der Pandas-Bibliothek verwenden, um unsere Daten zu formen:
Ilkadimlarim = pd.read_csv('ilkadimlarim_sitemap.csv')
ilkadimlarim = ilkadimlarim.drop(columns = 'Unbenannt: 0')
ilkadimlarim['lastmod'] = pd.to_datetime(ilkadimlarim['lastmod'])
ilkadimlarim = ilkadimlarim.set_index('lastmod')
„Ilkadimlarim“ bedeutet auf Türkisch „meine ersten Schritte“, und wie Sie sich vorstellen können, ist es eine Seite für Babys, Schwangerschaft und Mutterschaft.
Wir haben drei Operationen mit diesen Linien durchgeführt.
- Unbenannte: Wir haben eine leere Spalte mit dem Namen 0 aus dem DataFrame entfernt. Wenn Sie „index = False“ mit der Funktion pd.to_csv() verwenden, sehen Sie diese „Unbenannte 0“-Spalte am Anfang nicht.
- Wir haben die Daten in der Spalte Letzte Änderung in Date Time konvertiert.
- Wir haben die Spalte „lastmod“ auf die Indexposition gebracht.
Unten sehen Sie die endgültige Version des DataFrame.
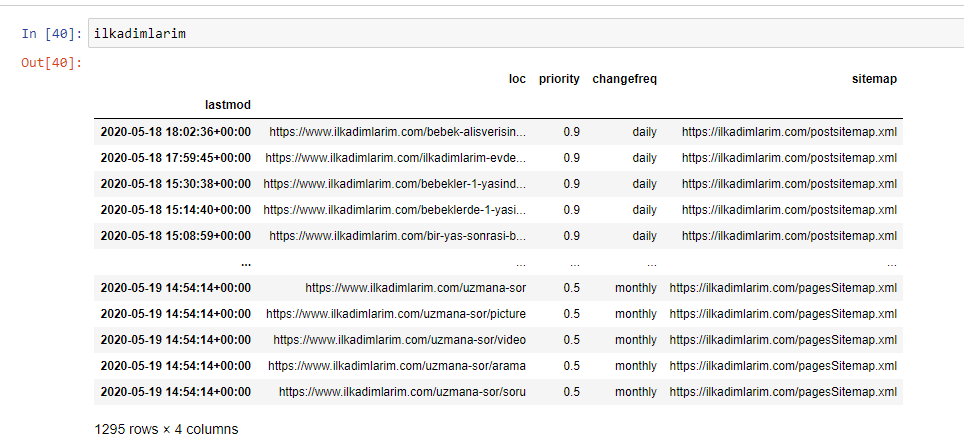
Wir wissen, dass Google keine Prioritäts- und Änderungshäufigkeitsinformationen aus Sitemaps verwendet. Sie nennen es „eine Tüte voller Lärm“. Wenn Sie jedoch Wert auf die Leistung Ihrer Website für andere Suchmaschinen legen, kann es hilfreich sein, diese ebenfalls zu untersuchen. Ich persönlich interessiere mich nicht sehr für diese Daten, aber ich muss sie trotzdem nicht aus dem DataFrame entfernen.
Wir brauchen eine weitere Codezeile, um die Sitemaps in einer anderen Spalte zu kategorisieren.
ilkadimlarim['sitemap_cat'] = ilkadimlarim['sitemap'].str.split('/').str[3]
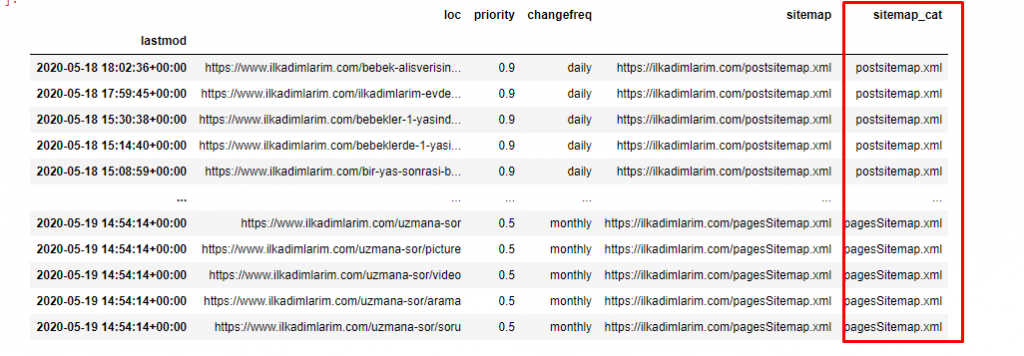
In Pandas können Sie einem DataFrame neue Spalten oder Zeilen hinzufügen oder sie einfach aktualisieren. Wir haben eine neue Spalte mit dem Code-Snippet DataFrame['new_columns'] erstellt . DataFrame['column_name'].str ermöglicht es uns, verschiedene Operationen auszuführen, indem wir den Datentyp in einer Spalte ändern. Wir dividieren die String-Daten in der Spalte, die sich auf .split ('/') bezieht, durch das Zeichen / und fügen sie in eine Liste ein. Mit .str [number] erstellen wir den Inhalt der neuen Spalte, indem wir ein bestimmtes Element in dieser Liste auswählen.
Inhaltsprofilanalyse nach Sitemap-Anzahl und -Arten
Nachdem wir die Sitemaps je nach Typ in eine andere Spalte eingefügt haben, können wir überprüfen, wie viel Prozent des Inhalts in jeder Sitemap enthalten sind. Somit können wir auch einen Rückschluss darauf ziehen, welcher Teil der Website wichtiger ist.
ilkadimlarim['sitemap_cat'].value_counts(normalize = True) * 100
- DataFrame['column_name'] wählt die Spalte aus, für die wir einen Prozess erstellen möchten.
- value_counts() zählt die Häufigkeit von Werten in der Spalte.
- normalize=True nimmt das Verhältnis der Werte in Dezimalzahlen an.
- Wir erleichtern die Lesbarkeit, indem wir die Dezimalzahlen mit *100 vergrößern.
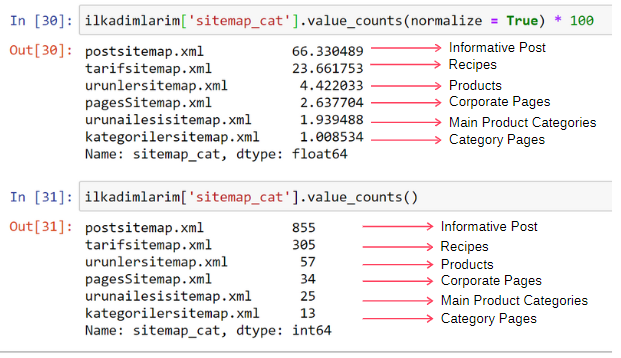
Wir sehen, dass sich 65 % des Inhalts in der Post-Sitemap und 23 % in der Rezept-Sitemap befinden. Die Produkt-Sitemap hat nur 2 % des Inhalts.
Dies zeigt, dass wir eine Website haben, die informative Inhalte für ein breites Publikum erstellen muss, um die eigenen Produkte zu vermarkten. Prüfen wir, ob unsere These richtig ist.
Bevor wir fortfahren, müssen wir den Namen der Spalte ilkadimlarim['sitemap_cat'] mit dem folgenden Code in 'URL_Count' ändern:
ilkadimlarim.rename(columns={'sitemap_cat' : 'URL_Count'}, inplace=True)
- Die Funktion rename() ist nützlich, um den Namen Ihrer Spalten oder Indizes zu ändern, um die Daten und ihre Bedeutung auf einer tieferen Ebene zu verbinden.
- Wir haben den Spaltennamen dank des Attributs „inplace=True“ so geändert, dass er dauerhaft ist.
- Sie können auch die Buchstabenstile Ihrer Spalten und Indizes mit ilkadimlarim.rename(str.capitalize, axis='columns', inplace=True) ändern . Dadurch werden nur die Anfangsbuchstaben jeder Spalte in Ilkadimlarim groß geschrieben.

Jetzt können wir fortfahren.
Um diese Informationen in einem einzigen Frame anzuzeigen, können Sie den folgenden Code verwenden:
(ilkadimlarim['sitemap_cat']
.value_counts()
.einrahmen()
.assign(percentage=lambda df: df['sitemap_cat'].div(df['sitemap_cat'].sum()))
.style.format(dict(sitemap_cat='{:,}', Prozentsatz='{:.1%}')))
- to_frame() wird verwendet, um Werte einzurahmen, die von value_counts() in der ausgewählten Spalte gemessen wurden.
- Assign() wird verwendet, um dem Frame bestimmte Werte hinzuzufügen.
- Lambda bezieht sich auf anonyme Funktionen in Python.
- Hier werden die Lambda-Funktion und die Sitemap-Typen durch die Gesamtzahl der Sitemaps durch die div()- Methode von Pandas dividiert.
- style() bestimmt, wie die angegebenen Endwerte geschrieben werden.
- Hier stellen wir mit der Methode format() ein, wie viele Ziffern nach dem Punkt geschrieben werden.
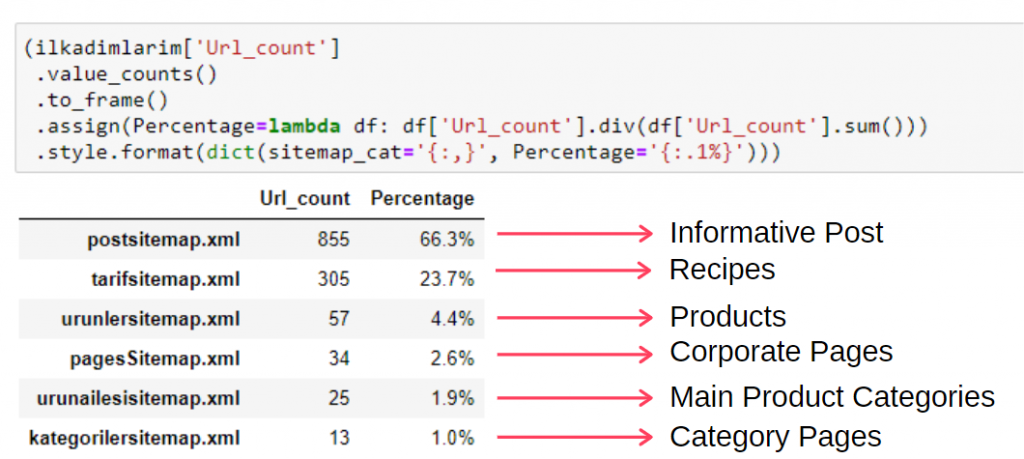
Daher sehen wir die Bedeutung des Content-Marketings für diese Website. Wir können auch ihre Artikelveröffentlichungstrends nach Jahr mit zwei einzelnen Codezeilen überprüfen, um ihre Situation genauer zu untersuchen.
Untersuchen und Visualisieren von Content-Publishing-Trends nach Jahr über Sitemaps und Python
Wir haben den Content- und Intent-Matching der untersuchten Website nach den Sitemap-Kategorien durchgeführt, aber noch keine zeitliche Einordnung vorgenommen. Dazu verwenden wir die Methode resample() .
post_per_month = ilkadimlarim.resample('A')['loc'].count()
post_per_month.to_frame()
Resample ist eine Methode in der Pandas-Bibliothek. resample('A') prüft die Datenreihe auf einen jährlichen DataFrame. Für Wochen können Sie „W“ verwenden, für Monate können Sie „M“ verwenden.
Loc symbolisiert hier den Index; count bedeutet, dass Sie die Summe der Datenbeispiele zählen möchten.
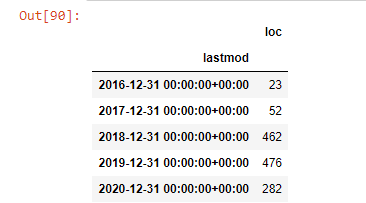
Wir sehen, dass sie 2016 mit der Veröffentlichung von Artikeln begonnen haben, aber ihr Hauptveröffentlichungstrend hat nach 2017 zugenommen. Wir können dies auch mit Hilfe von Plotly Graph Objects in eine Grafik umsetzen.
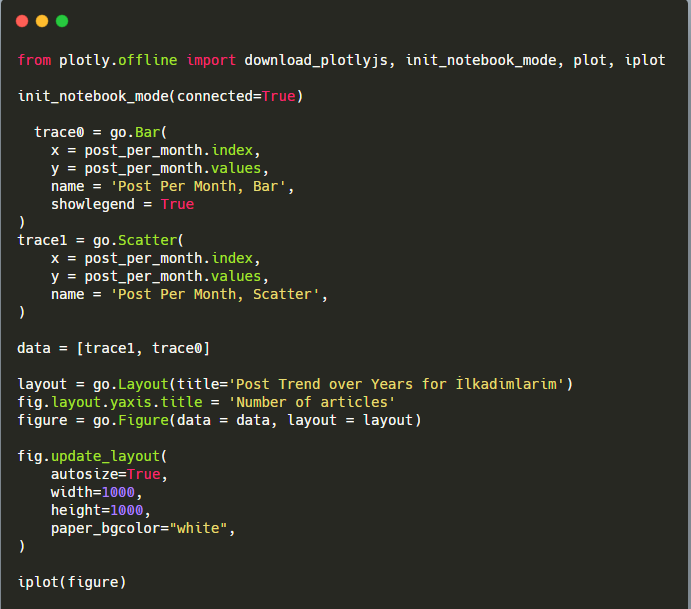
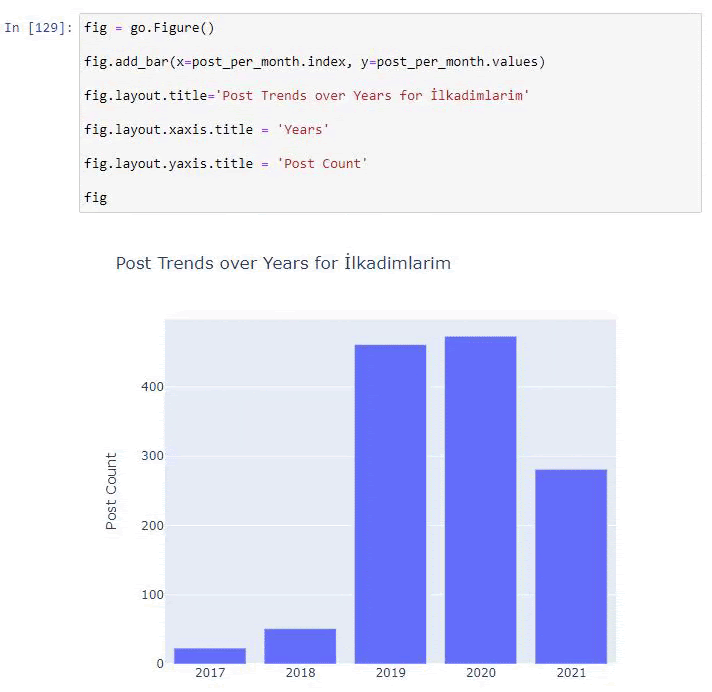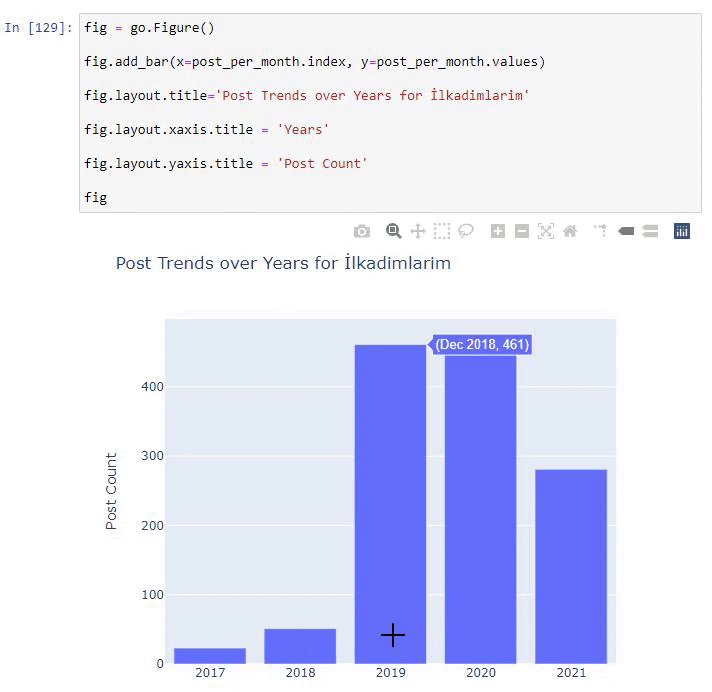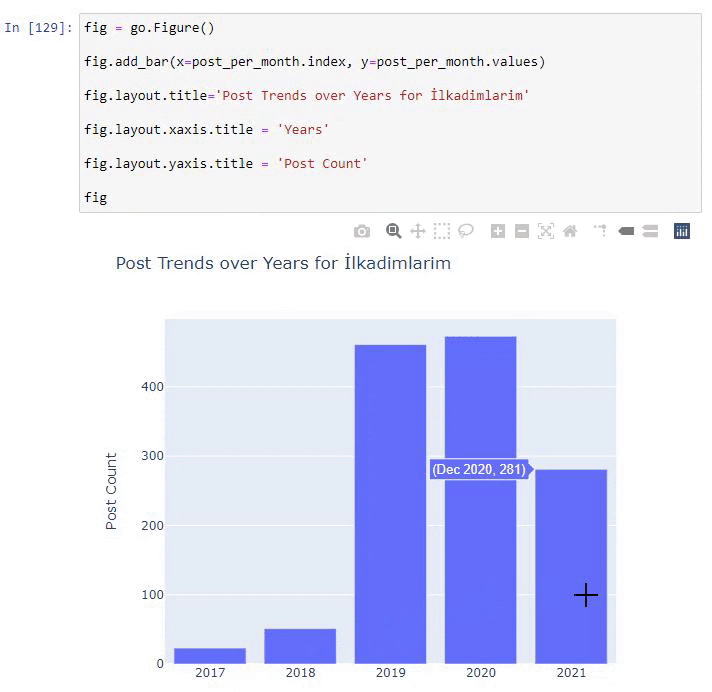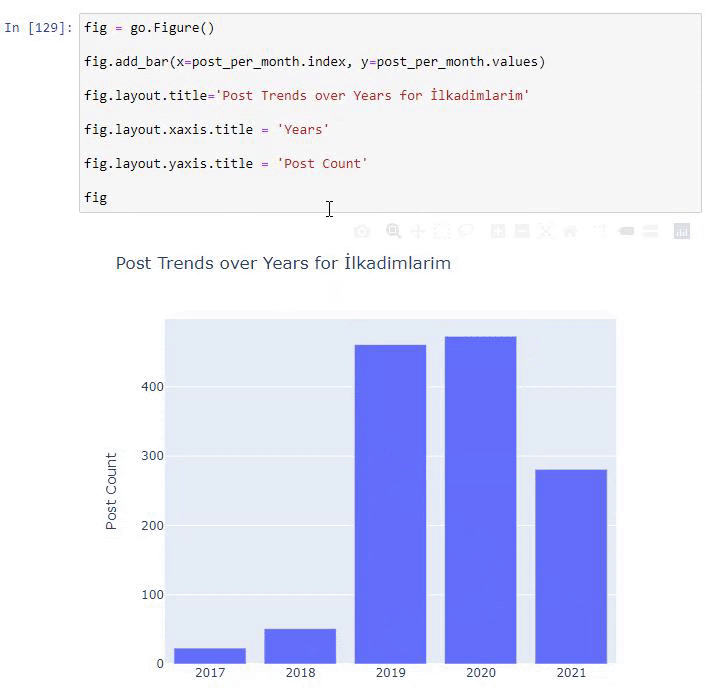
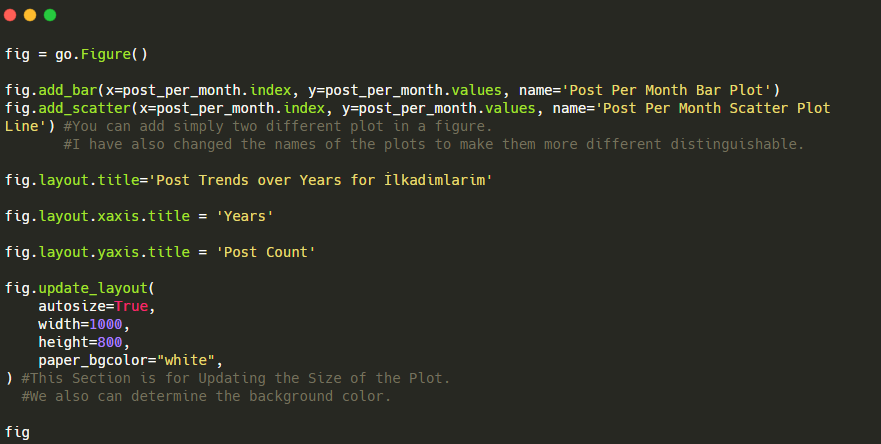
Erläuterung dieses Plotly Bar Plot-Codeausschnitts:
- fig = go.Figure() dient zum Erstellen einer Figur.
- fig.add_bar() dient zum Hinzufügen eines Balkendiagramms in die Abbildung. Wir bestimmen auch, welche X- und Y-Achsen innerhalb der Klammern liegen.
- Fig.layout dient zum Erstellen eines allgemeinen Titels für die Figur und die Achsen.
- In der letzten Zeile rufen wir den Plot auf, den wir mit dem Befehl fig erstellt haben, der gleich go.Figure() ist.
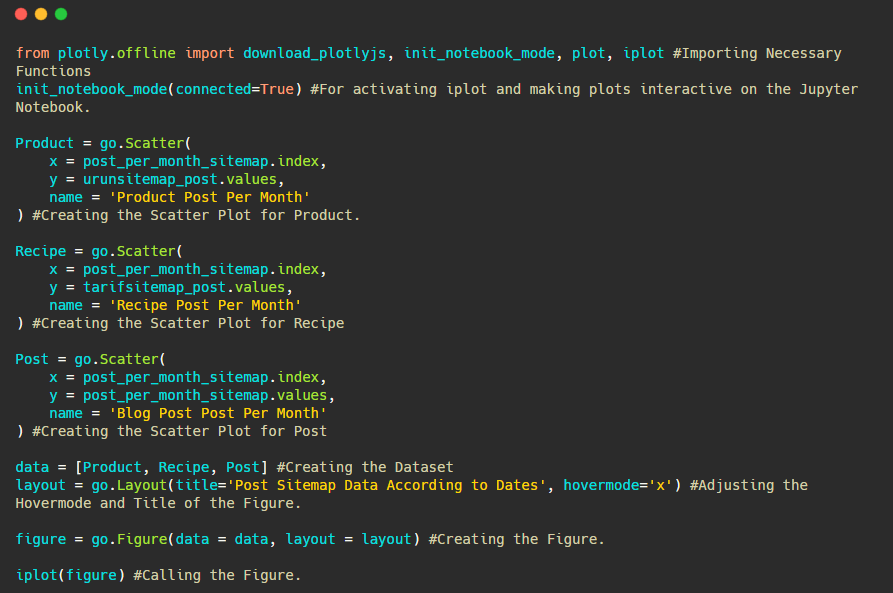
Unten finden Sie die gleichen Daten nach Monat, mit Streudiagramm und Balkendiagramm:
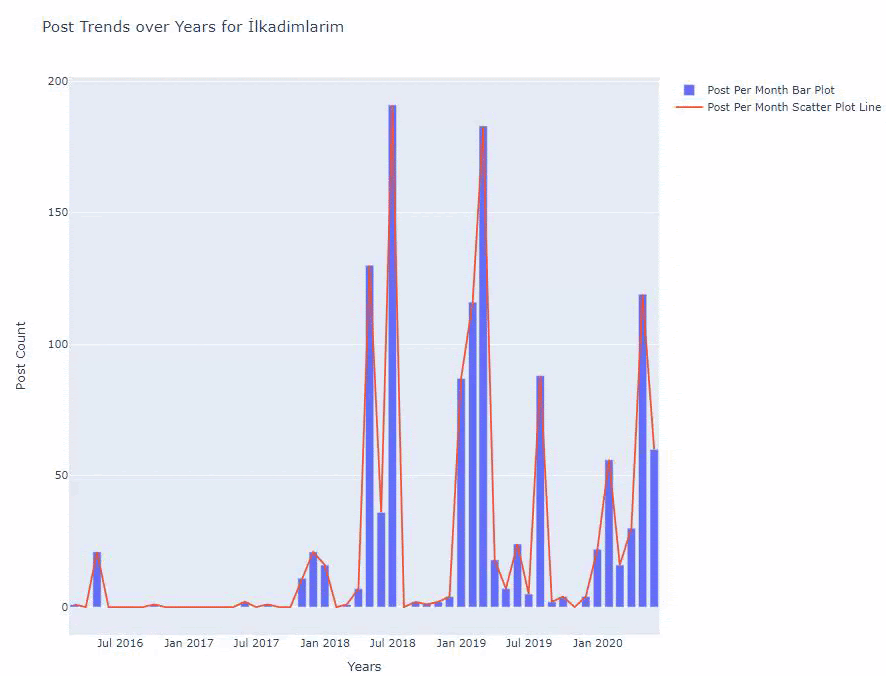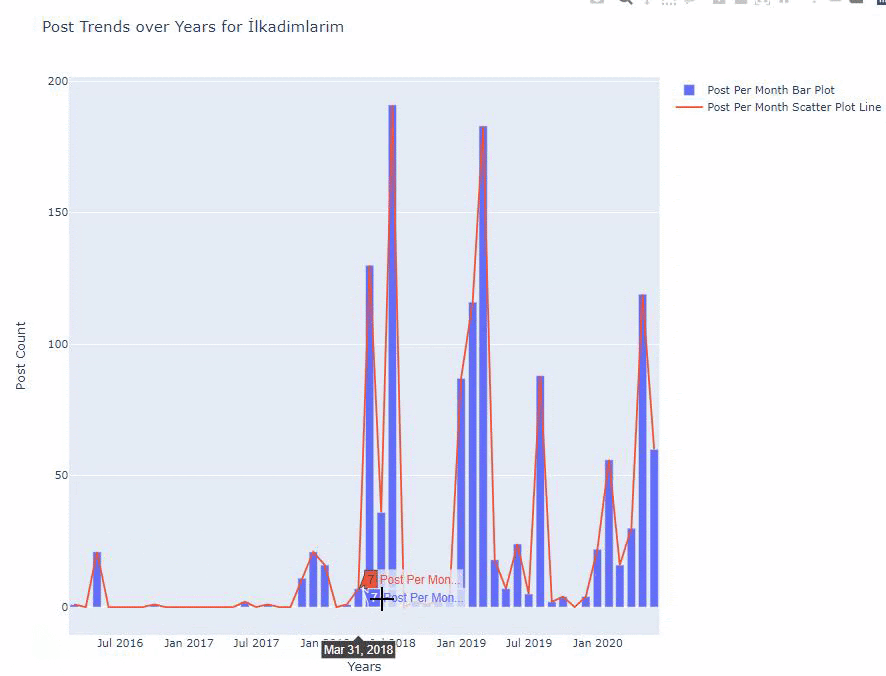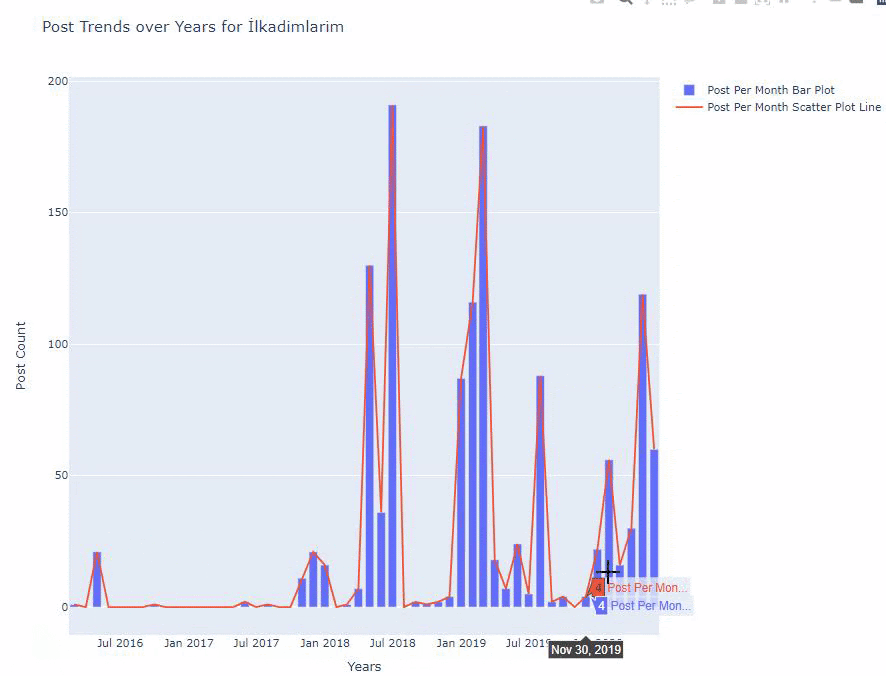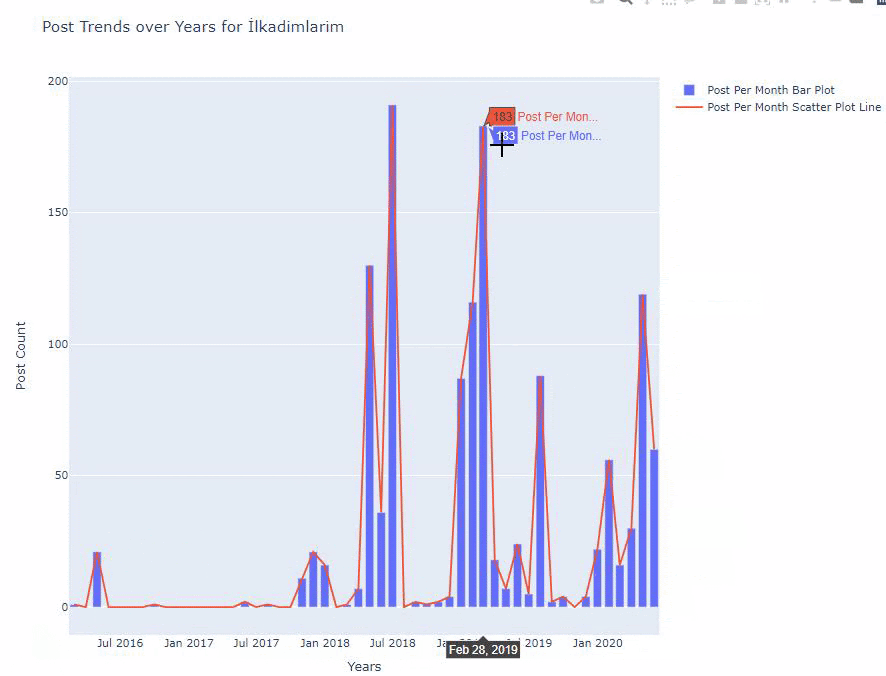
Hier sind die Codes zum Erstellen dieser Figur:
Wir haben einen zweiten Plot mit fig.add_scatter() hinzugefügt, und wir haben auch die Namen mit dem Namensattribut geändert. fig.update_layout() dient zum Ändern der Größe und Hintergrundfarbe des Plots.
Sie können auch den Hover-Modus, den Abstand zwischen Balken und mehr ändern. Ich denke, es reicht aus, nur die Codes zu teilen, da die Erklärung jedes Codes hier dazu führen kann, dass wir uns vom Hauptthema entfernen.
Wir können auch die Content-Publishing-Trends der Wettbewerber nach Kategorien wie den folgenden vergleichen:
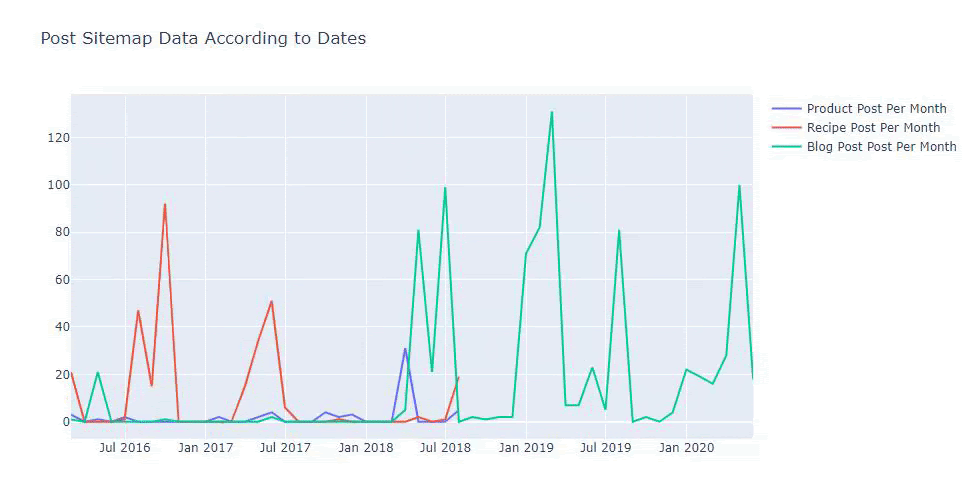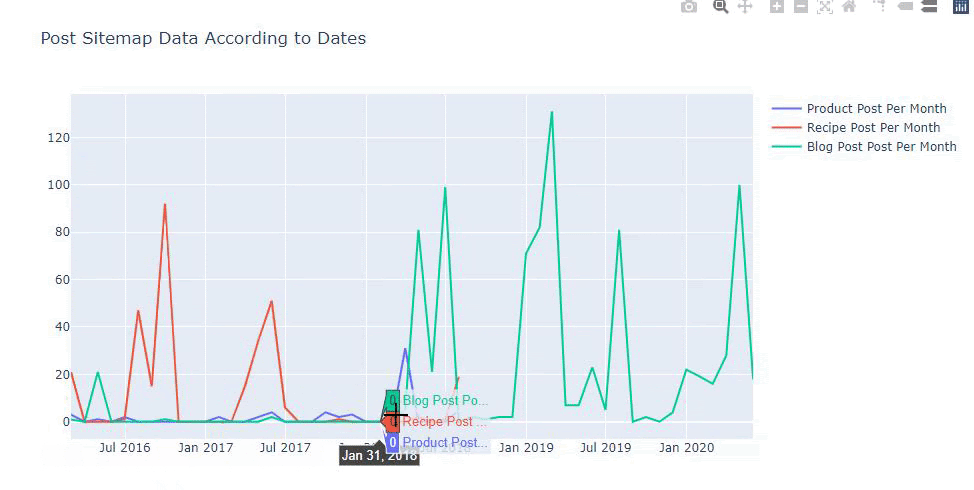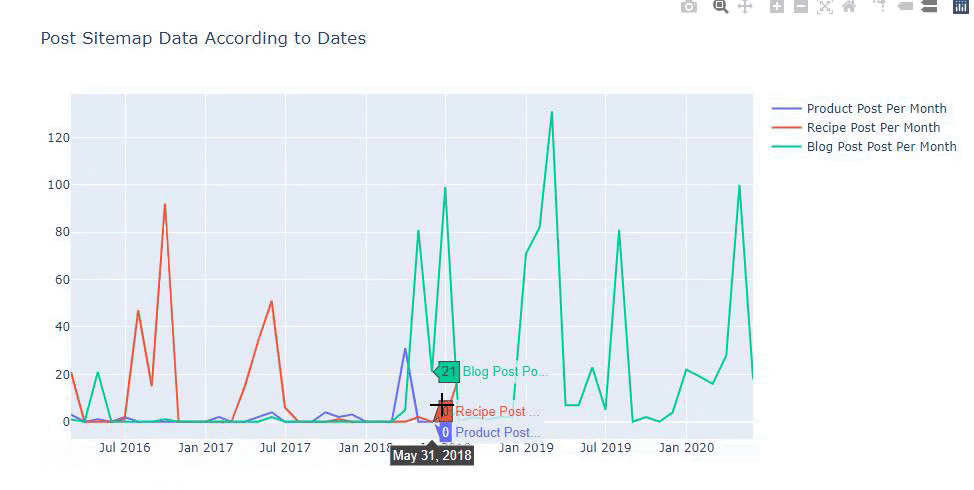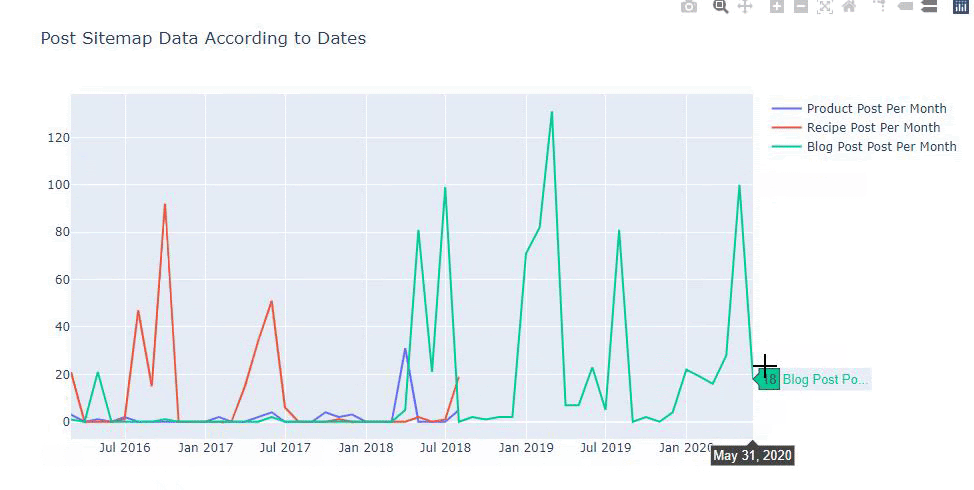
Dieses Diagramm wurde mit der zweiten Methode erstellt, wie Sie vielleicht sehen, gibt es keinen Unterschied, aber eine davon ist ziemlich einfach.
Um die Häufigkeit und den Trend der Veröffentlichung von Inhalten aus drei separaten Sitemaps darzustellen, müssen wir die Sitemap mit dem längsten Intervall auf der X-Achse platzieren. So können wir die Häufigkeit vergleichen, mit der die von uns untersuchte Website unterschiedliche Arten von Inhalten für unterschiedliche Suchabsichten veröffentlicht.
Wenn Sie die relevanten Codes unten untersuchen, werden Sie feststellen, dass sie sich nicht wesentlich von den oben genannten unterscheiden.
Um ein Streudiagramm mit mehreren Y-Achsen zu erstellen, können Sie den folgenden Code verwenden.
Es gibt andere Methoden wie die Vereinheitlichung verschiedener Sitemaps und die Verwendung einer for-Schleife für die Spalten, um mehrere Y-Achsen im Streudiagramm zu verwenden, aber für eine so kleine Site brauchen wir das nicht. In den meisten Fällen wäre es logischer, diese Methode auf Websites mit Hunderten von Sitemaps anzuwenden.
Da die Website klein ist, sieht die Grafik möglicherweise oberflächlich aus, aber wie Sie später in diesem Artikel auf einer Website mit Millionen von URLs sehen werden, sind solche Grafiken eine großartige Möglichkeit, verschiedene Websites sowie verschiedene Kategorien von zu vergleichen gleiche Webseite.
Untersuchen und Visualisieren von Inhaltskategorien, Absichten und Veröffentlichungstrends mit Sitemaps und Python
In diesem Abschnitt werden wir überprüfen, ob sie eine große Anzahl von Inhalten in einem bestimmten Wissensbereich geschrieben haben, um eine kleine Anzahl von Produkten zu vermarkten, was wir am Anfang des Artikels gesagt haben. Dadurch können wir sehen, ob sie eine Content-Partnerschaft mit anderen Marken haben oder nicht.
Um zu zeigen, was sonst noch auf Sitemaps zu finden ist, werden wir ein bisschen weiter graben. Wir können auch einige Informationen aus dem „loc“-Teil der Sitemap erhalten, wie z. B. andere.
In den URLs von Ilkadimlarim gibt es keine Aufschlüsselung nach Kategorien. Wenn eine Website eine Kategorieaufschlüsselung in ihren URLs hat, können wir viel mehr über die Inhaltsverteilung erfahren. Wenn nicht, können wir auf dieselben Daten zugreifen, indem wir zusätzlichen Code schreiben, aber nur mit geringerer Sicherheit.
An diesem Punkt können Sie sich vorstellen, wie viel weniger kostspielig URL-Aufschlüsselungen für Suchmaschinen sind, die Milliarden von Websites durchsuchen, um Ihre Website zu verstehen.
a = ilkadimlarim['loc'].str.contains(“bebek|hamile|haftalik”)
Bebek: Schätzchen
Hamile: schwanger
Haftalik: wöchentlich oder „Wochen schwanger“
baby_post_count = ilkadimlarim[a].resample('M')['loc'].count()
baby_post_count.to_frame()
Die Methode str() erlaubt uns hier wieder, die Spalte festzulegen, in der wir bestimmte Operationen auswählen.
Mit der Methode contains() ermitteln wir die Daten, um zu prüfen, ob sie in den in einen String konvertierten Daten enthalten sind.
Hier „|“ zwischen den Begriffen bedeutet „oder“ .
Dann weisen wir die gefilterten Daten einer Variablen zu und verwenden die zuvor verwendete Methode resample() .
Die Zählmethode hingegen misst, welche Daten wie oft verwendet werden.
Das mit count() erhaltene Ergebnis wird wieder mit to_frame() umschlossen.
Außerdem übernimmt str.contains() standardmäßig Regex-Werte, was bedeutet, dass Sie kompliziertere Filterbedingungen mit weniger Code erstellen können.
Mit anderen Worten, an dieser Stelle weisen wir die URLs, die die Wörter „Baby“, „wöchentlich“, „schwanger“ enthalten, einer Variablen in ilkadimlarim zu und setzen dann das Veröffentlichungsdatum der URLs in die entsprechenden Bedingungen für diesen Filter wir in einem Rahmen erstellt.
Dann machen wir dasselbe für URLs, die das Wort „aptamil“ enthalten. Aptamil ist der Name eines von Ilkadimlarim eingeführten Babynahrungsprodukts. Daher können wir auch auf die Sendedichte informativer und kommerzieller Inhalte achten.
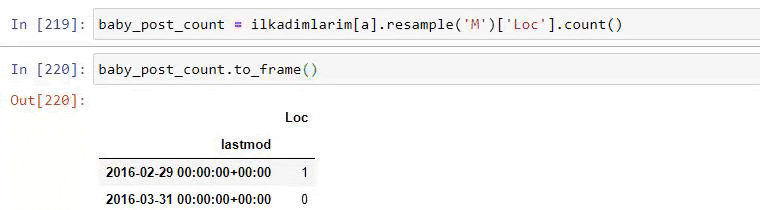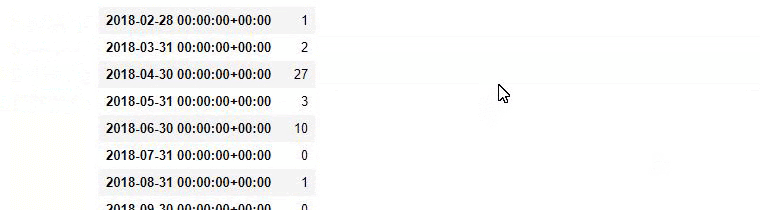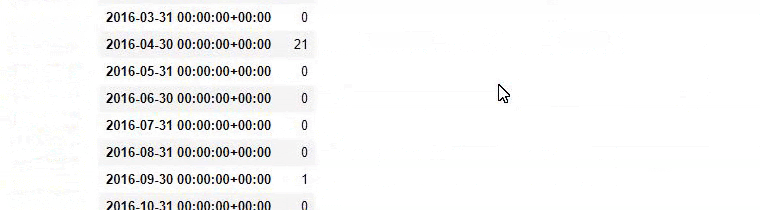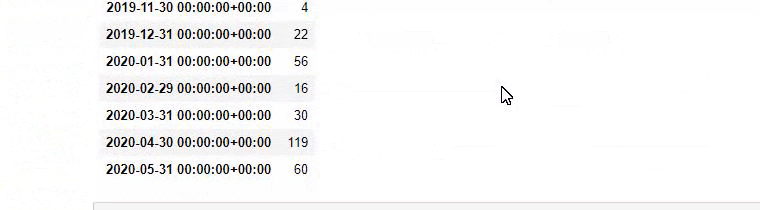
Und Sie können sehen, dass die zwei verschiedenen Inhaltsgruppen über Jahre hinweg Zeitpläne für unterschiedliche Suchabsichten mit mehr Sicherheit und präziseren Informationen von URLs veröffentlichen.
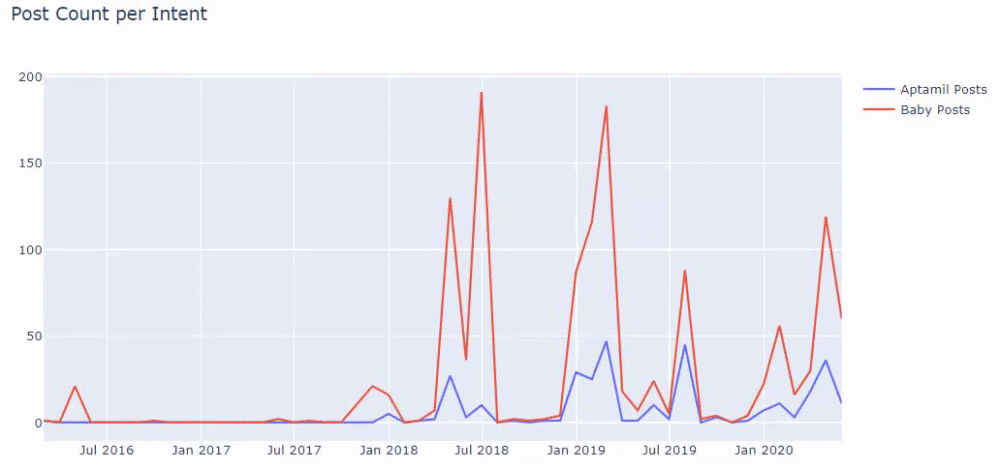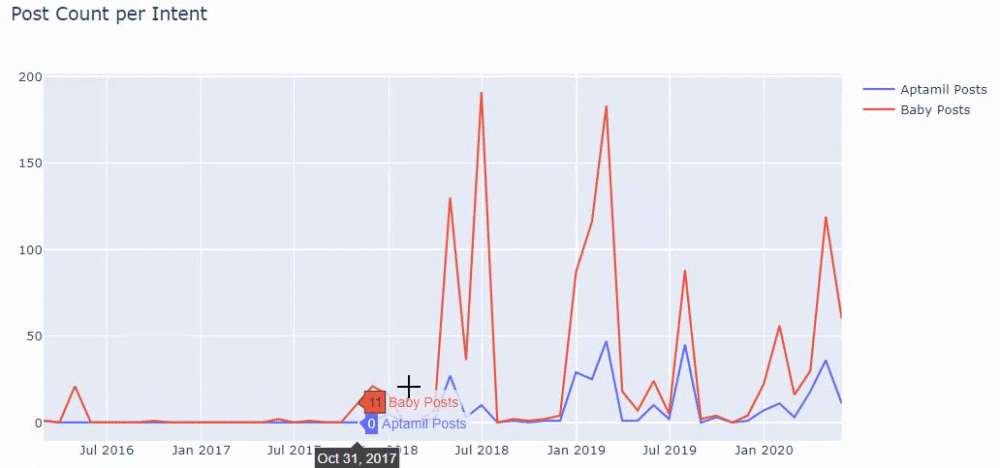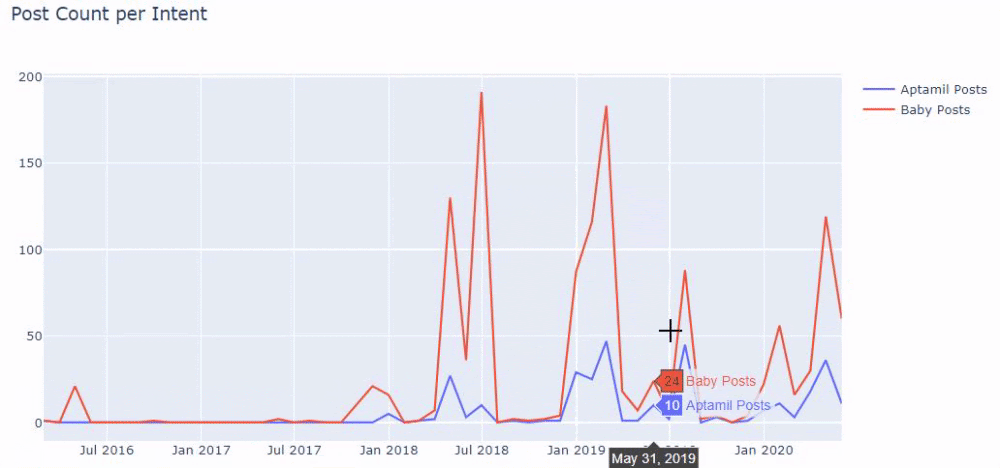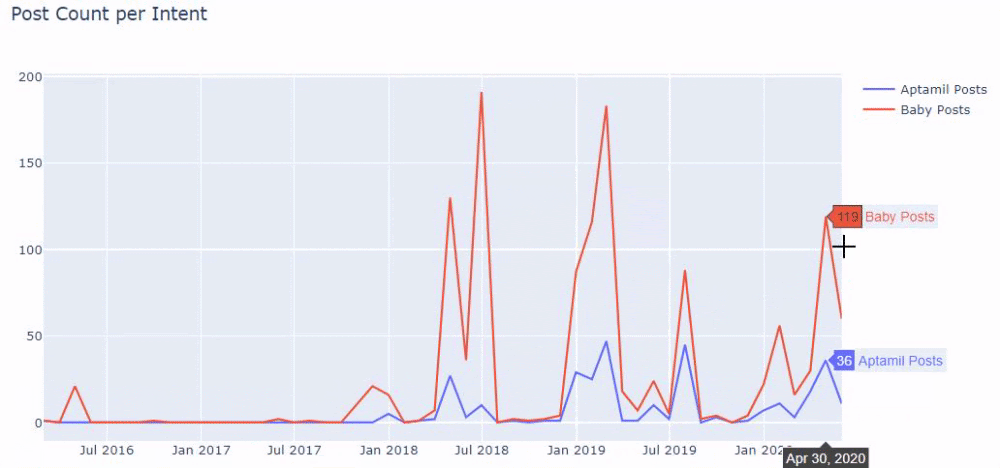
Der Code zum Erstellen dieses Diagramms wurde nicht freigegeben, da er mit dem für das vorherige Diagramm verwendeten identisch ist
Mit Hilfe der Suchoperatoren bei Google erhalte ich 38 Ergebnisse, wenn ich die Seiten abrufen möchte, auf denen das Wort Aptamil im Ankertext bei Ilkadimlarim.com verwendet wird. Eine große Anzahl dieser Seiten sind informativ und verlinken kommerzielle Inhalte.
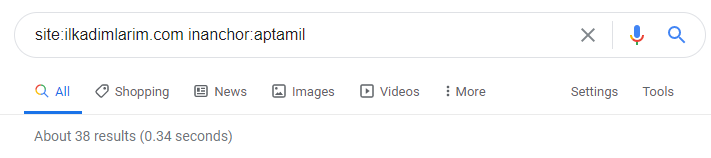
Unsere These ist bewiesen.
„Meine ersten Schritte“ verwendet Hunderte von informativen Inhalten über Mutterschaft, Babypflege und Schwangerschaft, um seine Zielgruppe zu erreichen. „Ilkadimlarim“ verlinkt die Seiten mit Aptamil-Produkten von diesen Inhalten und leitet die Nutzer dorthin weiter.
Vergleichende Inhaltsprofilerstellung und Analyse der Inhaltsstrategie über Sitemaps mit Python
Nun, wenn Sie möchten, lassen Sie uns dasselbe für ein Unternehmen aus derselben Branche tun und einen Vergleich anstellen, um den allgemeinen Aspekt dieser Branche und die strategischen Unterschiede zwischen diesen beiden Marken zu verstehen.

Als zweites Beispiel habe ich Prima.com.tr ausgewählt, das Pampers ist, aber in der Türkei den Markennamen Prima verwendet. Da Prima eine einzelne Sitemap hat, können wir nicht nach Sitemaps klassifizieren, aber zumindest haben sie unterschiedliche Brüche in ihren URLs. Wir haben also großes Glück: Wir müssen weniger Code schreiben.
Stellen Sie sich vor, wie viel teurer die Algorithmen sind, die Google für Sie ausführen muss, wenn Sie eine schwer verständliche Website erstellen! Dies kann dazu beitragen, die Berechnung der Crawling-Kosten für Sie greifbarer zu machen, auch nur in Bezug auf die URL-Struktur.
Um das Volumen des Artikels nicht weiter zu erhöhen, platzieren wir die Codes der Prozesse nicht, die denen ähneln, die wir bereits durchgeführt haben.
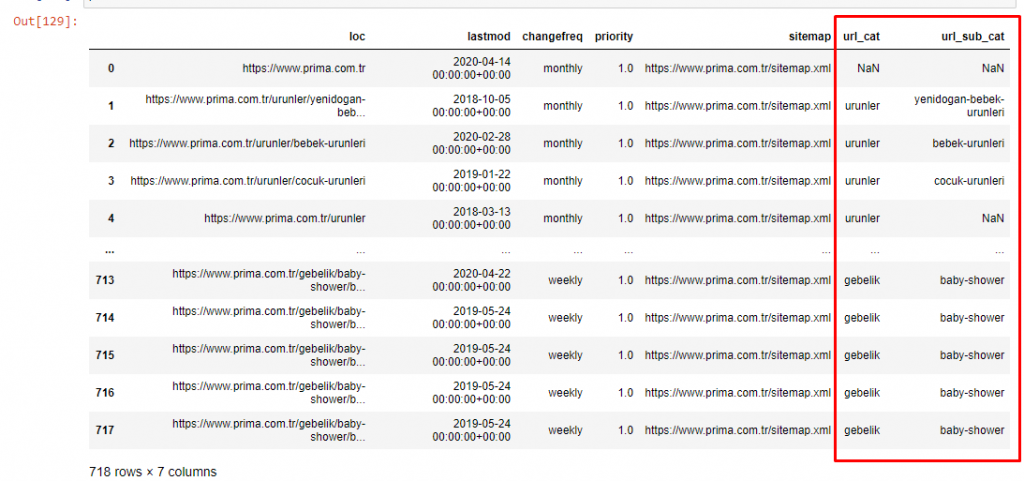
Jetzt können wir ihre Verteilung der Inhaltskategorien nach URL-Kategorien und URL-Unterkategorien untersuchen. Wir sehen, dass sie eine übermäßige Menge an Unternehmens-Webseiten haben. Diese Unternehmenswebseiten werden im Abschnitt „prima-hakkinda“ („Über Prima“) platziert. Aber wenn ich sie mit Python überprüfe, sehe ich, dass sie ihre Produkte und Unternehmenswebseiten in einer Kategorie vereinheitlicht haben. Sie können ihre Inhaltsverteilung unten sehen:

Wir können dasselbe für die folgenden Unterkategorien tun.
Es ist interessant festzustellen, dass Prima „gebelik“ (Schwangerschaft auf Türkisch) verwendet, was eine Variante von „hamilelik“ (Schwangerschaft auf Arabisch) ist, und beide bedeuten Schwangerschaftszeitraum.

Jetzt sehen wir eine tiefere Kategorisierung ihres Inhalts. 9,2 % des Inhalts dreht sich um eine gesunde Schwangerschaft, 7,3 % um den Wachstumsprozess von Babys, 8,3 % des Inhalts um Aktivitäten, die mit Babys gemacht werden können, 0,7 % um die Schlafordnung von Babys. Es gibt sogar Themen wie Kinderkrankheiten mit 3,9 %, Babysicherheit mit 1,9 % und die Bekanntgabe einer Schwangerschaft an die Familie mit 1,4 %. Wie Sie sehen, können Sie eine Branche nur mit URLs und deren Verbreitungsprozentsatz kennenlernen.
Dies ist nicht die perfekte Kategorisierung, aber zumindest können wir die Denkweise und Content-Marketing-Trends unserer Konkurrenten und den Inhalt ihrer Websites nach Kategorien sehen. Lassen Sie uns nun die Häufigkeit der Veröffentlichung von Inhalten nach Monat überprüfen.
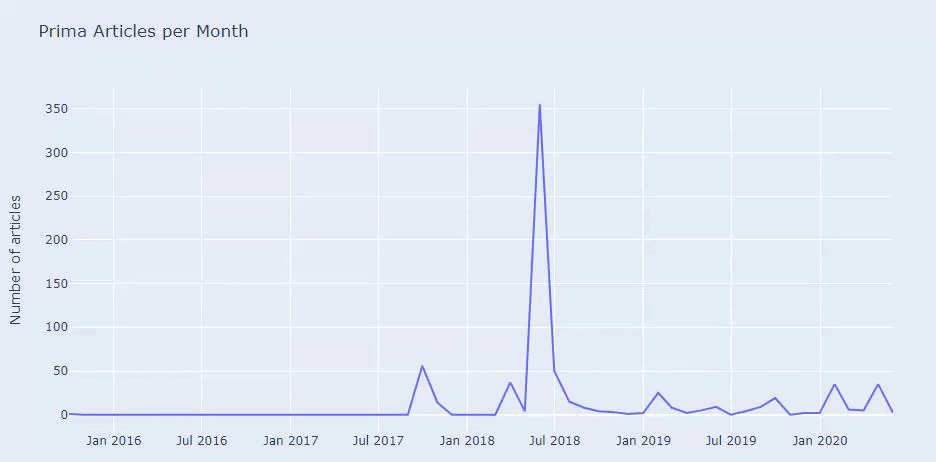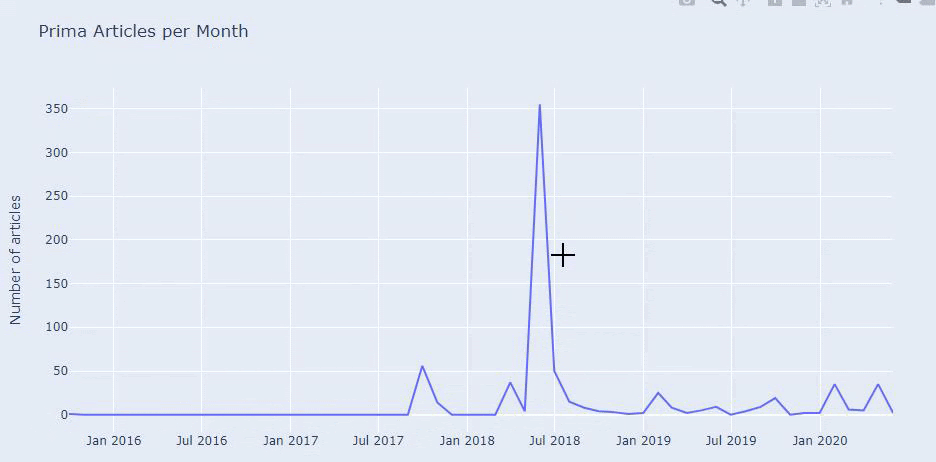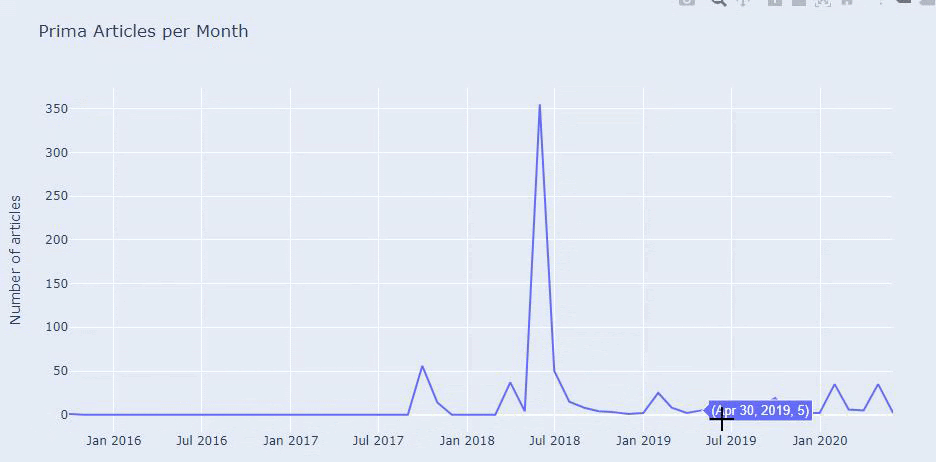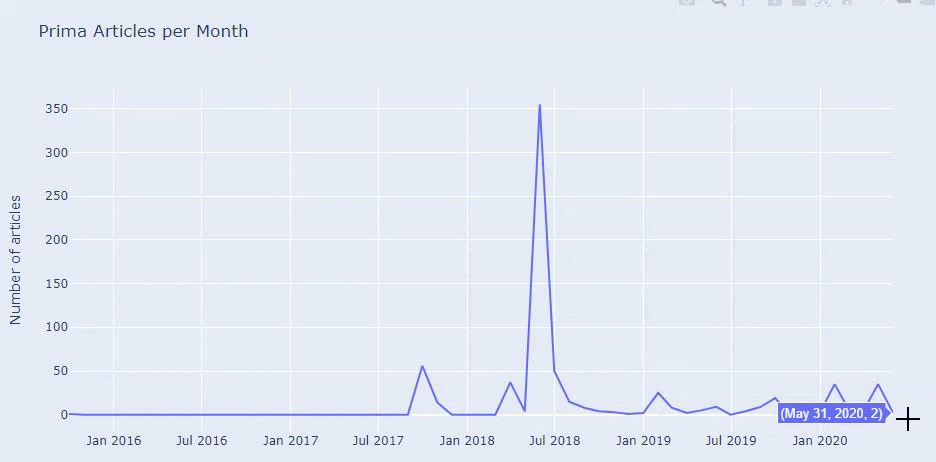
Wir sehen, dass sie im Juli 2018 355 Artikel veröffentlicht haben und ihre Inhalte laut Sitemap seitdem nicht aktualisiert wurden. Wir können auch ihre Content-Publishing-Trends nach Kategorien im Laufe der Jahre vergleichen. Wie Sie sehen können, sind ihre Inhalte hauptsächlich in vier verschiedenen Kategorien angesiedelt und die meisten von ihnen werden im selben Monat veröffentlicht.
Bevor ich fortfahre, muss ich sagen, dass Sitemap-Daten möglicherweise nicht immer korrekt sind. Beispielsweise können die Lastmod-Daten für alle URLs aktualisiert worden sein, weil sie alle Sitemaps an diesem Datum erneuert haben. Um dies zu umgehen, können wir auch überprüfen, ob sie ihre Inhalte seitdem nicht geändert haben, indem wir die Wayback-Maschine verwenden.
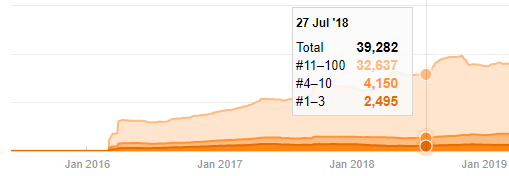
Auch wenn es verdächtig aussieht, können diese Daten echt sein. Viele Unternehmen in der Türkei neigen dazu, eine hohe Anzahl von Aufträgen zu erteilen und Inhalte für einen Moment vorher zu veröffentlichen. Wenn ich ihre Keyword-Anzahl überprüfe, sehe ich einen Sprung in diesem Zeitraum. Wenn Sie also eine vergleichende Inhaltsprofil- und Strategieanalyse durchführen, sollten Sie auch über diese Punkte nachdenken.
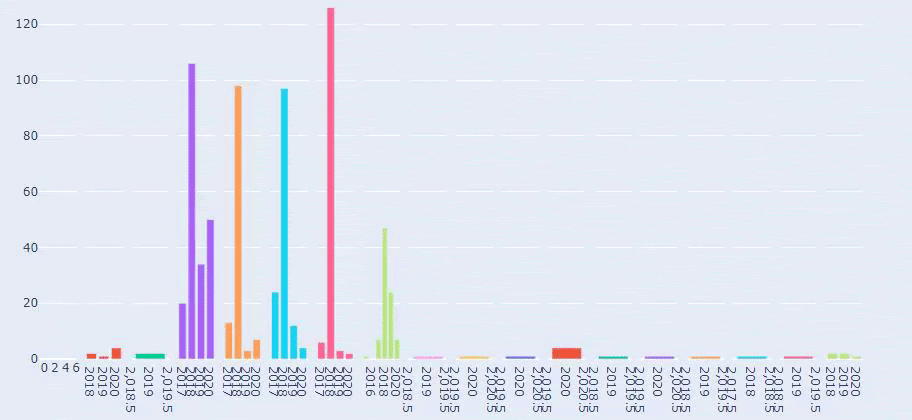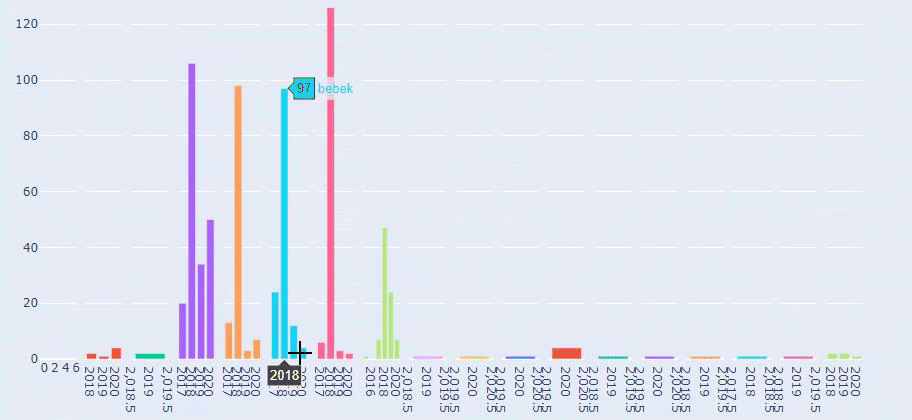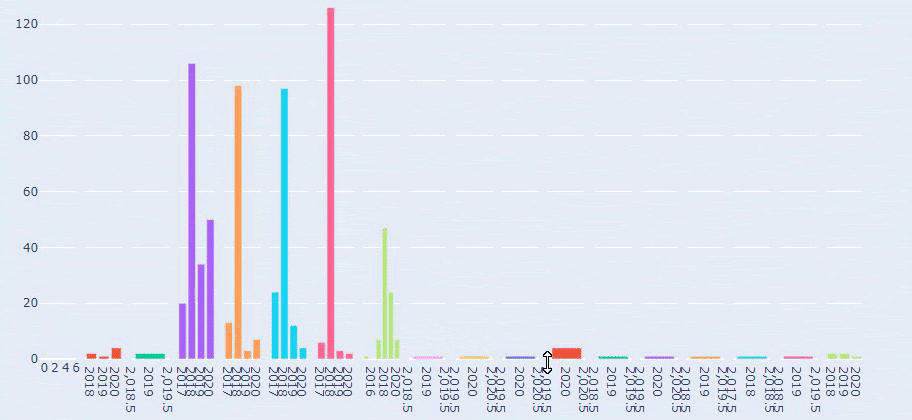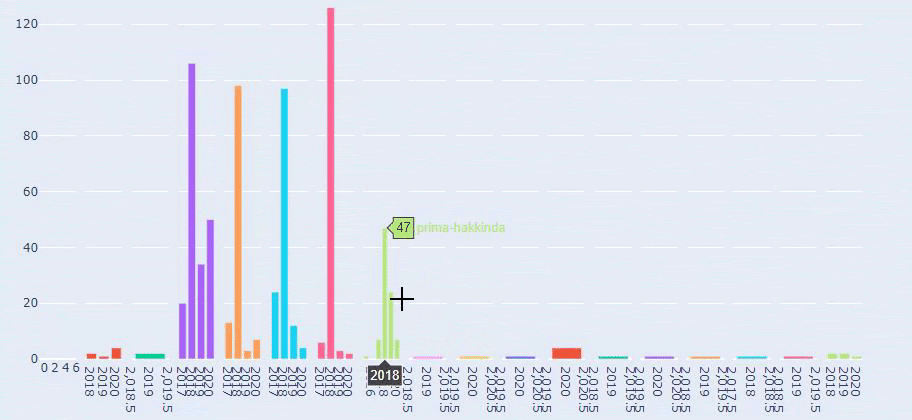
Dies ist ein Vergleich zwischen den Inhaltsveröffentlichungstrends aller Kategorien im Laufe der Jahre für Prima.com.tr
Jetzt können wir die Inhaltskategorien der beiden verschiedenen Websites und ihre Veröffentlichungstrends vergleichen.
Wenn wir uns ansehen, wie oft Prima Artikel über Babywachstum, Schwangerschaft und Mutterschaft veröffentlicht, sehen wir eine Ähnlichkeit mit Ilkadimlarim:
- Die meisten Artikel wurden zu einem bestimmten Zeitpunkt veröffentlicht.
- Sie wurden schon lange nicht mehr aktualisiert.
- Die Anzahl der Produkte und Seiten war im Vergleich zur Anzahl informativer Inhaltsseiten sehr gering.
- Kürzlich haben sie ihren Websites gerade neue Produkte hinzugefügt.
Wir können diese vier Merkmale als die Standardeinstellung der Branche betrachten und diese Schwächen zugunsten unserer Kampagne nutzen. Schließlich verlangt Qualität nach Frische (wie Amit Singhal, Google Fellow, feststellte).
An dieser Stelle sehen wir auch, dass die Branche das Verhalten des Googlebots nicht kennt. Anstatt 250 Inhalte an einem Tag hochzuladen und dann ein Jahr lang keine Änderungen vorzunehmen, ist es besser, regelmäßig neue Inhalte hinzuzufügen und die alten Inhalte regelmäßig zu aktualisieren. So können Sie die Qualität des Inhalts aufrechterhalten, der Googlebot kann Ihre Website besser verstehen und Ihre Crawling-Frequenzwerte werden höher sein als die Ihrer Konkurrenten.
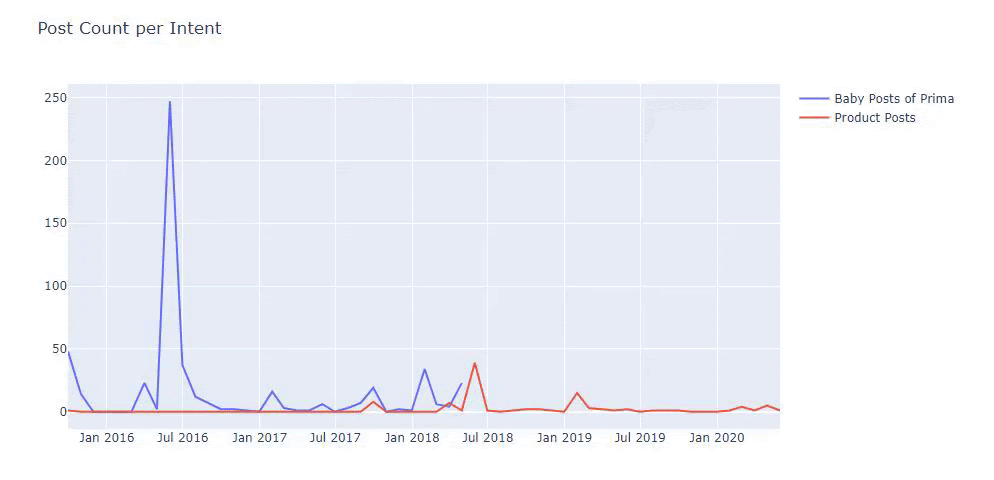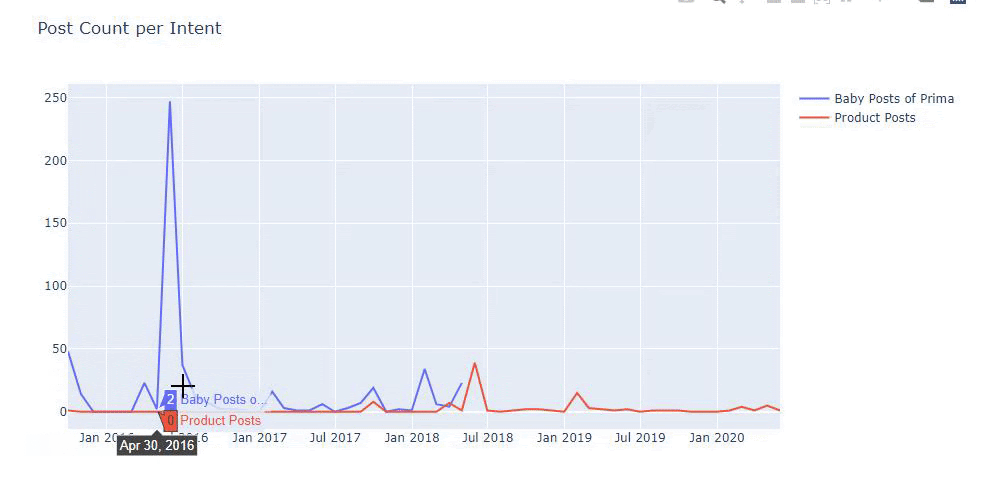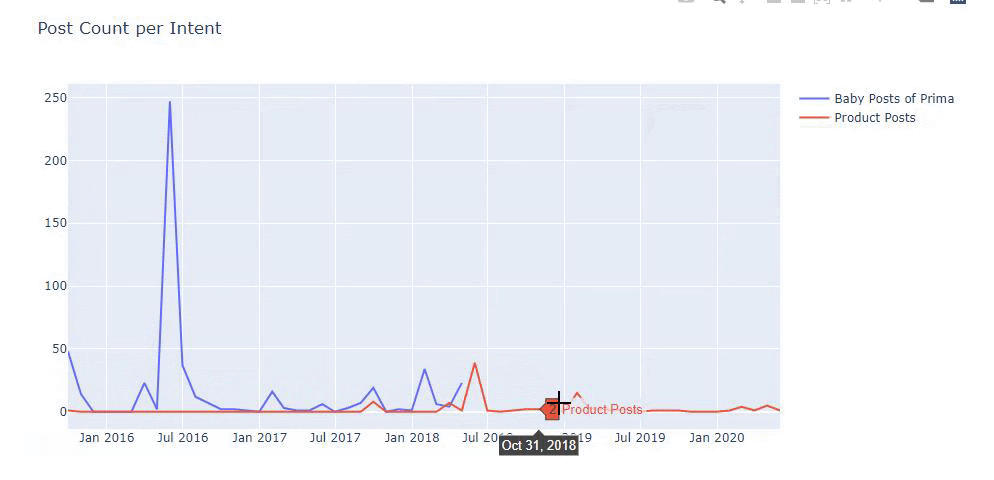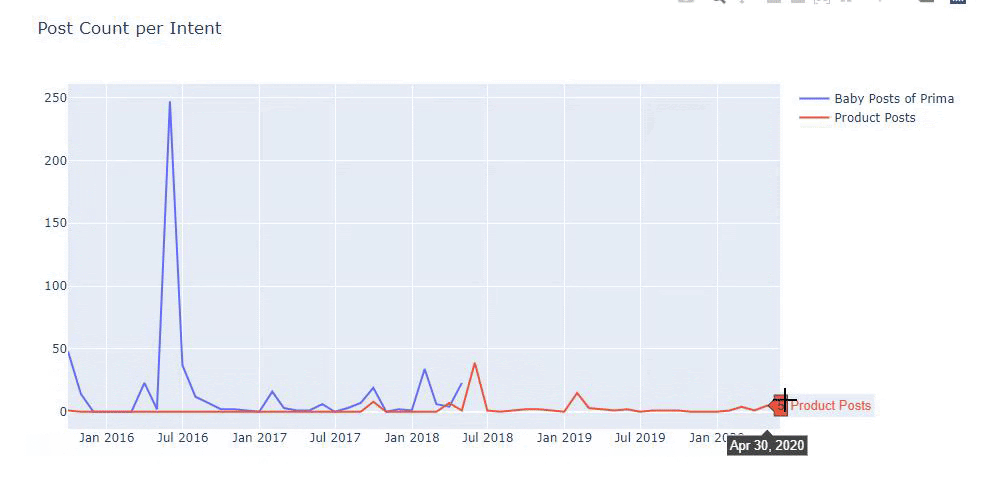
Ich habe die vorherigen Methoden verwendet, um zwischen Produktseiten und informativen Inhaltsseiten zu unterscheiden, und die am häufigsten verwendeten Wörter in den URLs profiliert. Baby Posts bedeutet hier, dass es sich um informative Inhalte handelt.
Wie Sie vielleicht sehen, haben sie an einem Tag 247 Inhalte hinzugefügt. Außerdem haben sie seit über einem Jahr keine informativen Inhalte veröffentlicht oder aktualisiert, und sie fügen nur gelegentlich einige neue Produktseiten hinzu.
Vergleichen wir nun ihre Veröffentlichungstrends in einer einzigen Abbildung, aber mit zwei verschiedenen Diagrammen. Ich habe die folgenden Codes zum Erstellen dieser Figur verwendet:
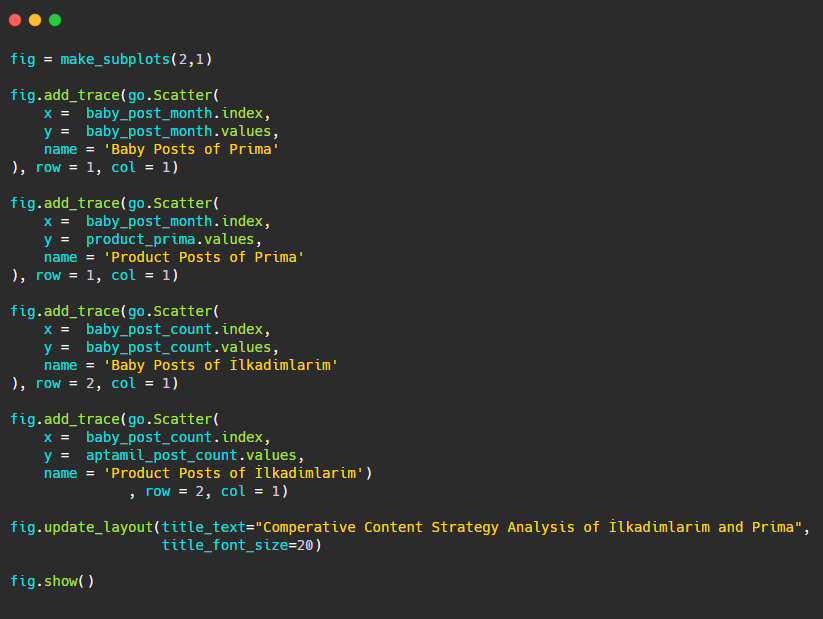
Da sich diese Grafik von den vorherigen unterscheidet, wollte ich Ihnen den Code zeigen. Hier werden zwei getrennte Diagramme in derselben Figur platziert. Dazu wurde die Methode make_subplots mit dem Befehl aus plotly.subplots import make_subplots aufgerufen.
Es wurde als zweizeilige und einspaltige Abbildung mit make_subplots (2,1) erstellt .
Daher werden col und row an das Ende der Spuren geschrieben und ihre Positionen angegeben. Es ist ein System, das jeder, der mit dem Grid-System in CSS vertraut ist, leicht erkennen kann.
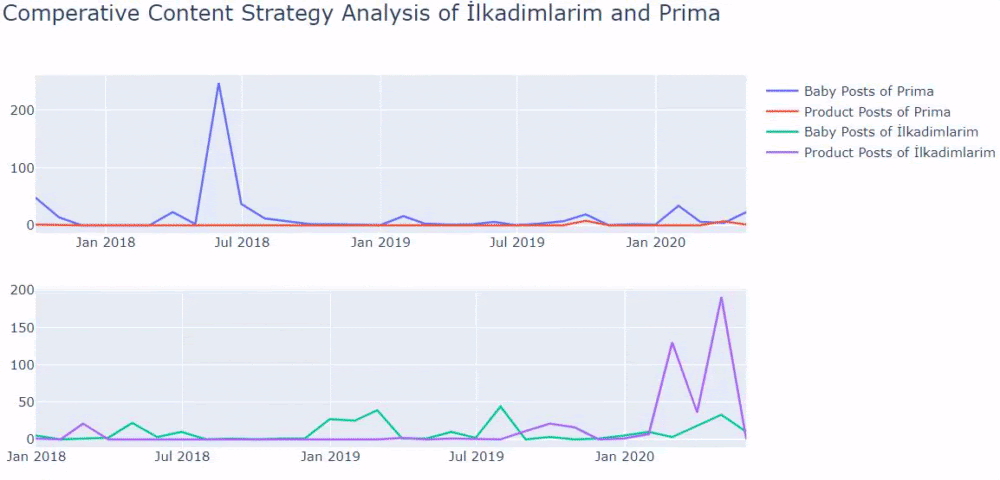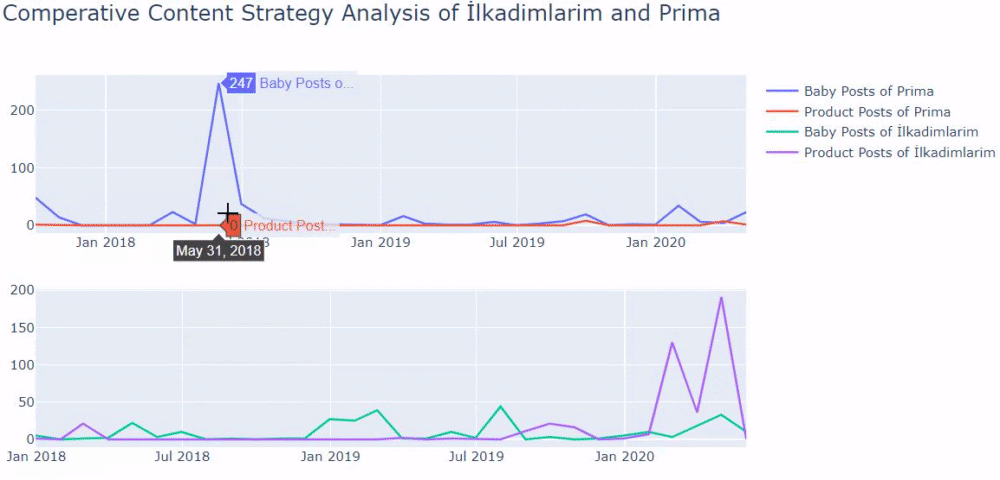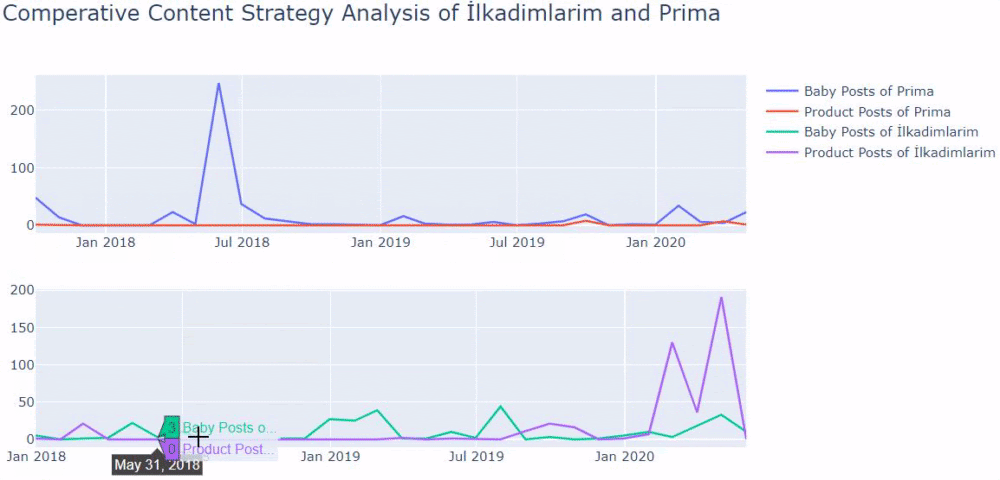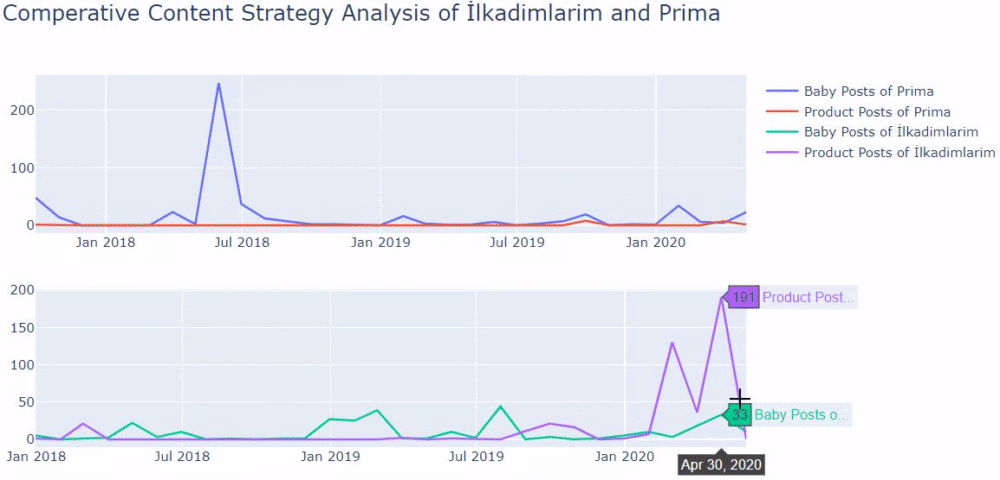
Wenn Sie einen Kunden in der gleichen Branche haben, können Sie diese Daten verwenden, um eine Inhaltsstrategie zu erstellen, um die Schwächen Ihrer Konkurrenten und ihr Abfrage-/Landingpage-Netzwerk über SERP zu sehen. Außerdem können Sie nachvollziehen, welche Menge an Inhalten Sie in derselben Wissensdomäne oder für dieselbe Benutzerabsicht veröffentlichen sollten.
Bevor wir mit dem abschließen, was wir im Rahmen einer Inhaltsstrategieanalyse aus Sitemaps lernen können, können wir eine letzte Website mit einer viel höheren URL-Anzahl aus einer anderen Branche untersuchen.
Content-Strategie-Analyse von News-Web-Entitäten über Währungen mit Python und Sitemaps
In diesem Abschnitt verwenden wir Seaborns Heatmap-Plot und auch einige ausgefallenere Framing- und Datenextraktionsmethoden.

Elias Dabbas hat ein interessantes und wirklich nützliches Kaggle-Archiv in Bezug auf Data Science und SEO. Diesen Monat hat er für mich einen neuen Kaggle-Datensatzabschnitt für türkische Nachrichtenseiten eröffnet, um die erforderlichen Codes zu schreiben und eine Inhaltsstrategieanalyse mit Advertools über Sitemaps durchzuführen.
Bevor ich anfange, diese Techniken auf Kaggle anzuwenden, möchte ich in diesem Artikel einige Beispiele dafür zeigen, was passieren würde, wenn wir dieselben Techniken auf größere Webeinheiten anwenden würden.
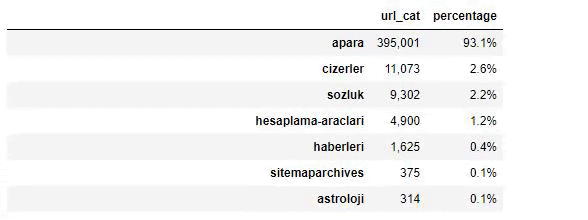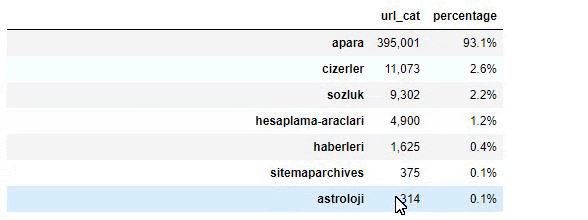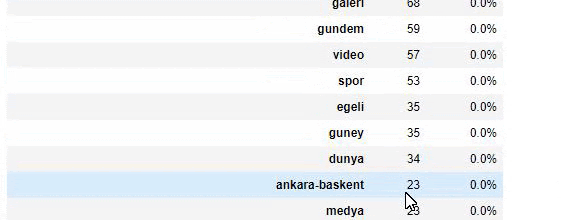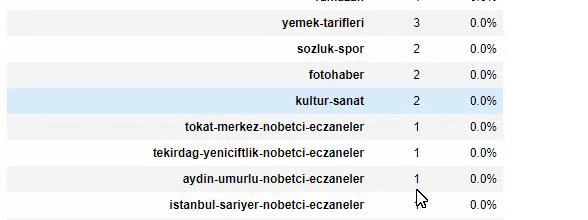
Wenn wir den Inhalt von Sabah Newspaper analysieren, sehen wir, dass ein erheblicher Teil seines Inhalts (81 %) in einer Kategorie namens „Apara“ liegt. Außerdem haben sie einige große Kategorien für Astrologie, Berechnung, Wörterbuch, Wetter und Weltnachrichten. (Para bedeutet das Geld auf Türkisch)
Für Sabah Newspaper können wir auch Inhalte mit Sitemaps analysieren, die wir nur mit Advertools gesammelt haben, aber da die betreffende Zeitung sehr groß ist, habe ich sie wegen der hohen Anzahl von Sitemaps und den Inhalten verschiedener Sitemaps mit derselben URL nicht bevorzugt Kategorie.
Unten sehen Sie auch den Überschuss an Sitemaps mit Advertools.
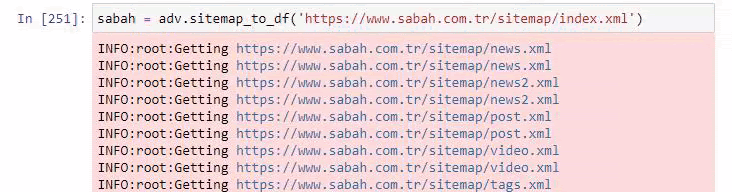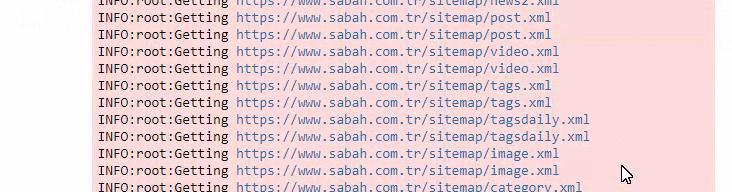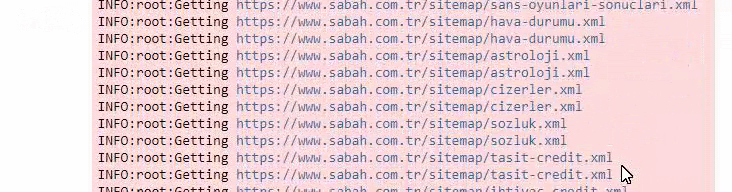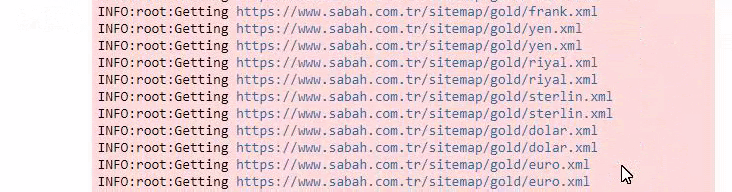
Wir können sehen, dass sie unterschiedliche Sitemaps für dieselben URL-Kategorien wie Gold, Kredit, Währungen, Tags, Gebetszeiten und Apothekenarbeitszeiten usw. haben.
Kurz gesagt, wir können diese Details erreichen, indem wir uns auf Unterkategorien von URLs konzentrieren. Anstatt verschiedene Sitemaps über Variablen zu vereinheitlichen. Also habe ich alle Sitemaps mit der Methode sitemap_to_df() von Advertools vereinheitlicht, wie am Anfang des Artikels.
Wir können auch einen anderen Satz von Funktionen verwenden, die von Elias Dabbas erstellt wurden, um bessere Datenrahmen zu erstellen. Wenn Sie die dataset_utilites-Funktionen überprüfen, können Sie einige Beispiele sehen. Der folgende Code gibt die Gesamtsumme und den Prozentsatz einer bestimmten URL-Regex zusammen mit der kumulativen Summe nach Stilisierung an.
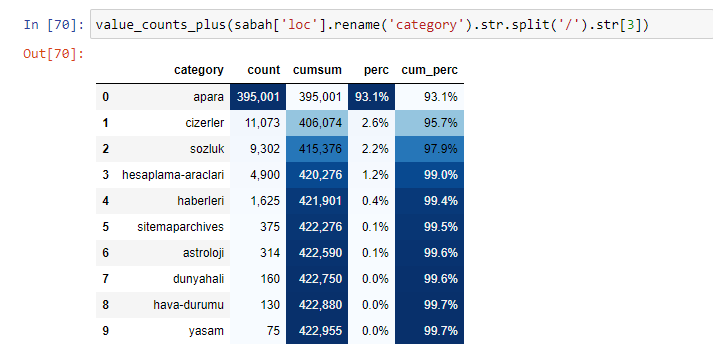
Wenn wir dasselbe mit einer Unter-URL-Aufschlüsselung von Sabah Newspaper machen, erhalten wir das folgende Ergebnis.
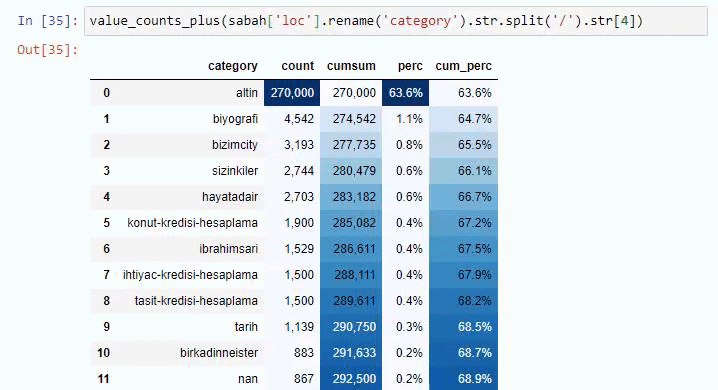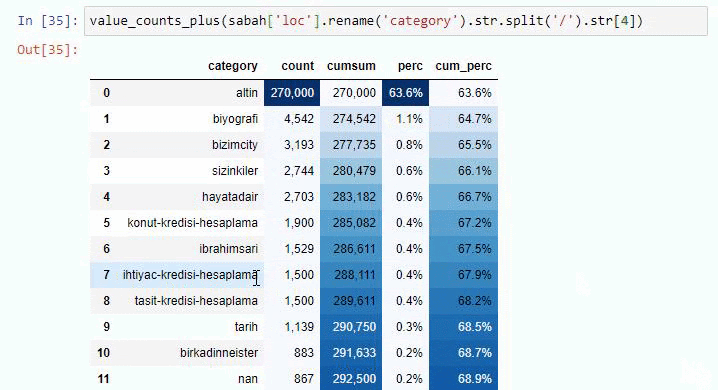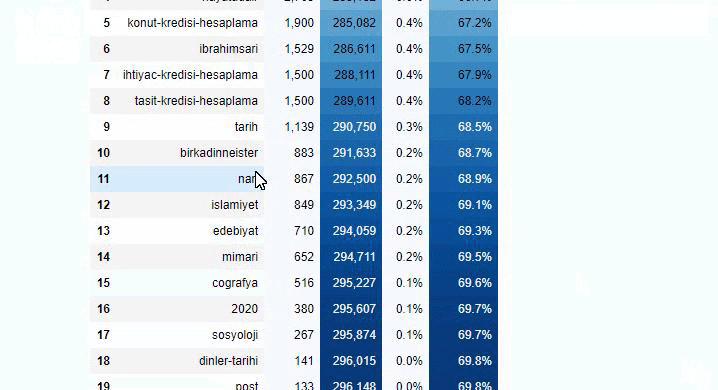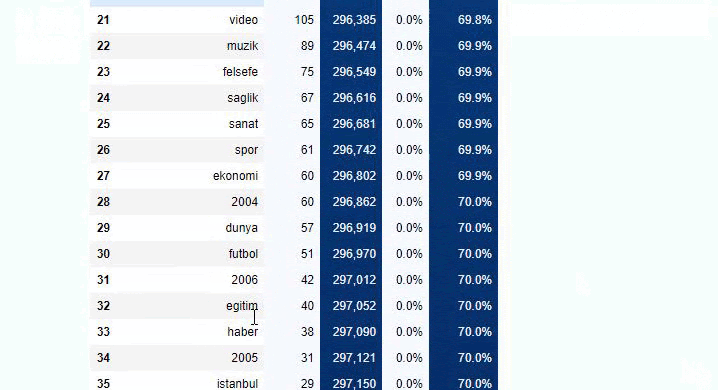
Sie können die Anzahl der Zeilen erhöhen, die die betreffende Funktion ausgibt, indem Sie die Zeile darunter ändern. Wenn Sie den Inhalt der Funktion untersuchen, werden Sie außerdem feststellen, dass er den zuvor verwendeten ähnlich ist.
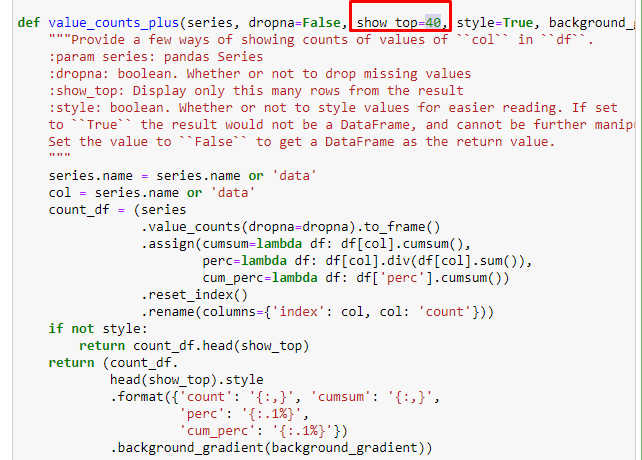
In Sub-Breakings sehen wir verschiedene Aufschlüsselungen wie „Religionsgeschichte“, „Biografie“, „Städtenamen“, „Fußball“, „Bizimcity (Karikatur)“, „Hypothekenkredit“. Die größte Aufschlüsselung findet sich in der Kategorie „Gold“.
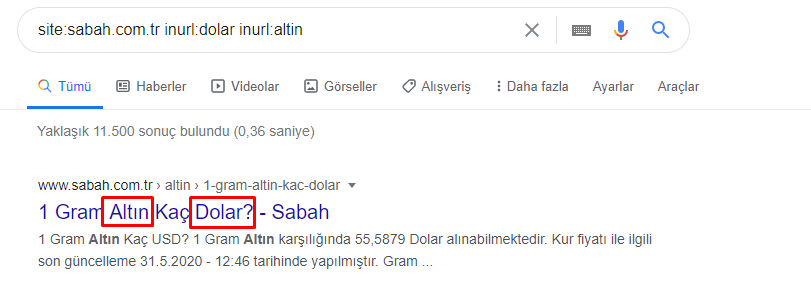
Wie kann eine Zeitung also 295.000 URLs für Goldpreise haben?
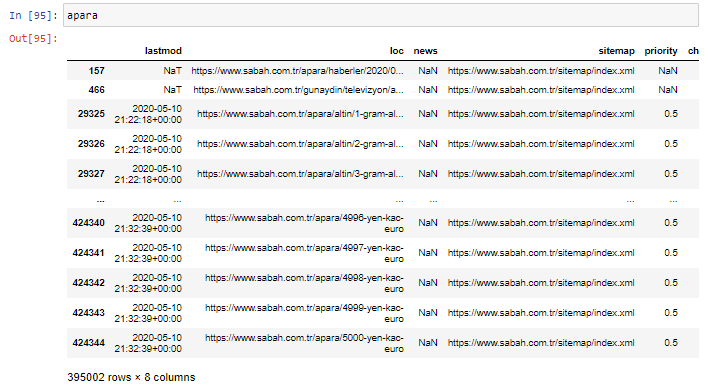
Zunächst werfe ich alle URLs, die das „apara“ in der ersten URL-Aufschlüsselung von Sabah Newspaper enthalten, in eine Variable.
apara = sabah[sabah['loc'].str.contains('apara')]
Hier ist das Ergebnis:
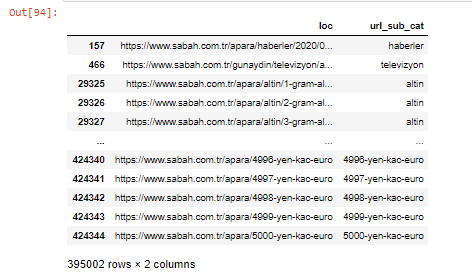
Wir können die Spalten auch mit der Methode .filter() filtern:
Jetzt können wir am Ende des DataFrame sehen, warum Sabah Newspaper eine übermäßige Menge an Apara-URLs hat, weil sie verschiedene Webseiten für jeden Betrag der Währungsberechnung geöffnet haben, wie z. B. 5000 Euro, 4999 Euro, 4998 Euro und mehr…
Aber bevor wir irgendwelche Schlussfolgerungen ziehen, müssen wir sicher sein, denn mehr als 250.000 dieser URLs gehören zur Kategorie „Altin (Gold)“.
apara.filter(['loc', 'url_sub_cat' ]).tail(60) zeigt uns die letzten 60 Zeilen dieses Datenrahmens:

Dasselbe können wir für die Gold-URL-Aufschlüsselung innerhalb der Apara-Gruppe tun.
gold = apara[apara['loc'].str.contains('altin')]
gold.filter(['loc','url_sub_cat']).tail(85)
gold.filter(['loc','url_sub_cat']).head(85)
An diesem Punkt sehen wir, dass die Zeitung Sabah 5000 verschiedene Seiten geöffnet hat, um jede Währung in Dollar, Euro, Gold und TL (Türkische Lira) umzurechnen. Für jede Geldeinheit zwischen 1 und 5000 gibt es eine separate Berechnungsseite. Unten sehen Sie das Beispiel der ersten 85 und letzten 85 Zeilen der Goldgruppe. Für jeden Gramm Goldpreis wurde eine separate Seite geöffnet.


Wir haben keine Zweifel, dass diese Seiten unnötig sind, mit vielen doppelten Inhalten und übermäßig groß sind, aber Sabah Newspaper ist eine so markenstarke Website, dass Google sie weiterhin in fast jeder Abfrage als Top-Ranking anzeigt.
An diesem Punkt können wir auch sehen, dass die Crawl Cost Tolerance für eine alte Nachrichtenseite mit hoher Autorität hoch ist.
Dies erklärt jedoch nicht, warum die Gold-Kategorie mehr URLs hat als andere.
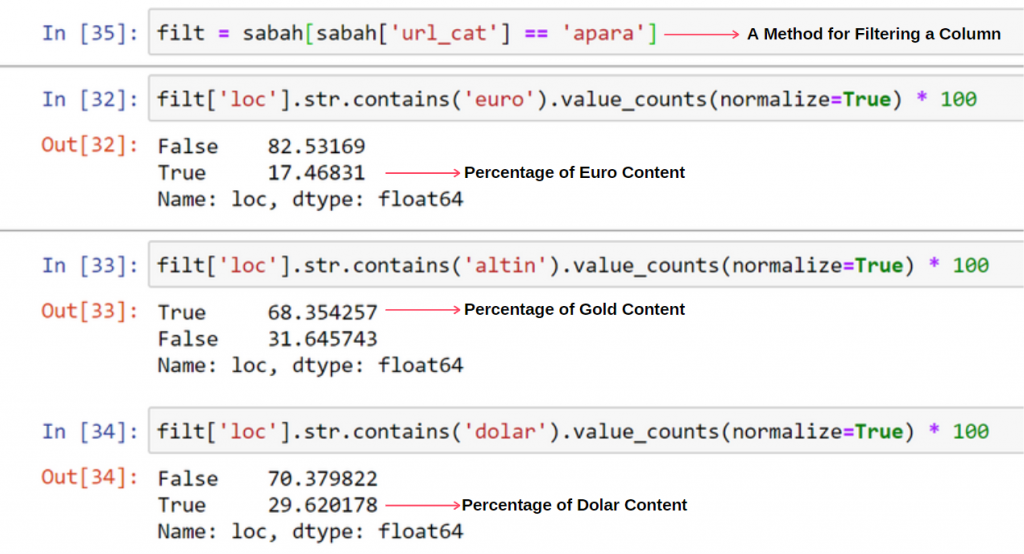
Ich sehe nichts Seltsames an überlappenden Werten, die sich zu mehr als 100% summieren.
Es sei denn, ich vermisse etwas?
Wie Sie feststellen werden, erhalten wir das Ergebnis von 115,16 %, wenn wir alle Wahren Werte addieren. Der Grund dafür ist unten.
Sogar die Hauptgruppe hat eine solche Überschneidung untereinander. Wir könnten diese Schnittpunkte auch analysieren, aber das könnte Gegenstand eines anderen Artikels sein.
Wir sehen, dass 68 % der Inhalte in der Apara-URL-Gruppe mit GOLD zu tun haben.
Um diese Situation besser zu verstehen, müssen wir zunächst die URLs in der Goldbrechung scannen.
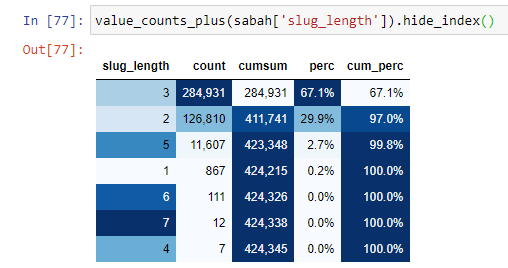
Wenn wir die URLs danach klassifizieren, wie viele '/' sie seit dem Stammabschnitt haben, sehen wir, dass die Anzahl der URLs mit maximal 3 Unterbrechungen hoch ist. Wenn wir diese URLs analysieren, sehen wir, dass 270.000 der 3 slug_length URLs in der Gold-Kategorie sind.
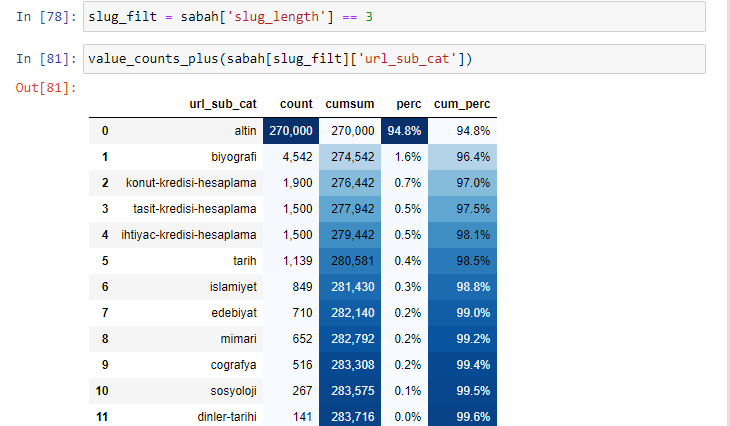
morning_filt = morning ['slug_length'] == 3 Dies bedeutet, dass Sie nur diejenigen erhalten, die gleich 3 aus der Datengruppe des int-Datentyps in einer bestimmten Spalte eines bestimmten Datenrahmens sind. Basierend auf diesen Informationen rahmen wir dann die URLs ein, die für die Bedingung mit der Anzahl, Summen und Aggregationsraten mit kumulierter Summe geeignet sind.
Wenn wir die am häufigsten verwendeten Wörter in den goldenen URLs extrahieren, stoßen wir auf Wörter, die „vollständig“, „Republik“, „Viertel“, „Gramm“, „halb“, „Vorfahr“ darstellen. Die Goldarten Ata und Republic sind einzigartig für die Türkei. Einer von ihnen repräsentiert die türkische Souveränität und der andere ist der Gründer der Republik, Kemal Atatürk. Aus diesem Grund sind ihre Suchvolumina für Suchanfragen hoch.
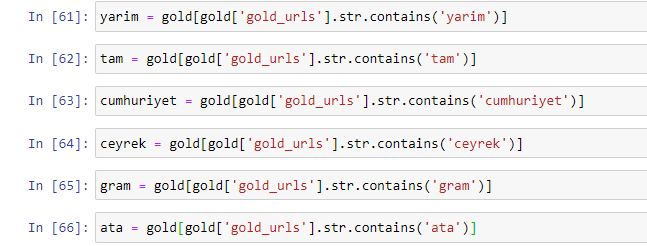
Zunächst einmal haben wir die in den URLs gefundenen gemeinsamen Wörter entfernt und sie separaten Variablen zugewiesen. Als Nächstes verwenden wir diese Variablen im Gold DataFrame, um Spalten zu erstellen, die für ihre Typen spezifisch sind.
Nachdem wir neue Spalten durch Variablen erstellt haben, müssen wir sie zusammen mit booleschen Werten filtern.
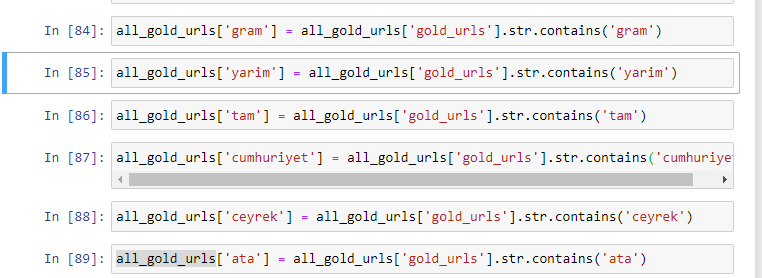
Wie Sie sehen, konnten wir alle Gold-URLs mit 270.000 Zeilen und 6 Spalten kategorisieren. Der Hauptgrund für die hohe Anzahl goldspezifischer Seiten ist, dass der Dollar oder der Euro keine separaten Typen haben, während das Gold separate Typen hat. Gleichzeitig ist die Vielfalt der Kreuzungsseiten zwischen Gold und verschiedenen Währungen aufgrund ihres traditionellen Vertrauens in die Türken höher als bei anderen Währungen.
Meiner Meinung nach sollten alle Arten von Goldseiten gleichmäßig verteilt sein, oder?
Wir können dies leicht mit der Heatmap-Funktion von Seaborn testen.
seegeboren als sns importieren
importiere matplotlib.pyplot als plt
plt.figure(figsize=(10,8))
sns.heatmap(a,yticklabels=False,cbar=False,cmap=”viridis”)
plt.show()
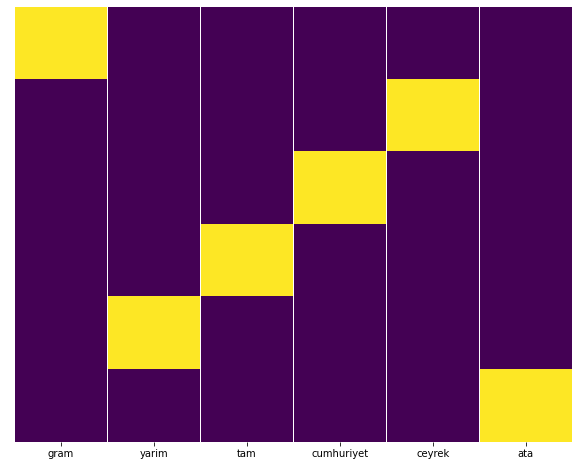
Hier auf der Heatmap sind die Wahren in jeder Spalte einfach markiert. Wie zu sehen ist, ist die Größe jeweils symmetrisch zueinander und ordentlich auf der Karte angeordnet.
Daher haben wir die Inhaltspolitik der Zeitung Sabah.com.tr über Währungen und Währungsberechnungen aus einer breiten Perspektive betrachtet.
In Zukunft werde ich türkische Nachrichten-Websites und ihre Inhaltsstrategien auf der Grundlage von Sitemaps Kaggle schreiben, das von Elias Dabbas ins Leben gerufen wurde, aber in diesem Artikel haben wir genug darüber gesprochen, was auf großen und kleinen Websites mit Sitemaps entdeckt werden kann .
Fazit und Takeaways
Ich denke, wir haben gesehen, wie einfach es ist, eine Website dank einer glatten und semantischen URL-Struktur zu verstehen. Wir sollten auch daran denken, wie wertvoll eine ordentliche URL-Struktur für Google sein kann.
In Zukunft werden wir viele SEOs sehen, die sich zunehmend mit Data Science, Datenvisualisierung, Frontend-Programmierung und mehr auskennen… Ich sehe diesen Prozess als Beginn einer unvermeidlichen Veränderung: Die Lücke zwischen SEOs und Entwicklern wird vollständig geschlossen in ein paar Jahren.
Mit Python können Sie diese Art der Analyse noch weiter vorantreiben: Es ist möglich, Daten zu erhalten, indem Sie die politischen Ansichten einer Nachrichtenseite verstehen, wer über was, wie oft und mit welchen Gefühlen schreibt. Darauf gehe ich hier lieber nicht ein, da es bei diesen Prozessen eher um reine Data Science geht als um SEO (und dieser Artikel ist schon ziemlich lang).
Aber wenn Sie interessiert sind, gibt es viele andere Arten von Audits, die über Sitemaps und Python durchgeführt werden können, z. B. das Überprüfen der Statuscodes von URLs in einer Sitemap.
Ich freue mich darauf, zu experimentieren und andere SEO-Aufgaben zu teilen, die Sie mit Python und Advertools erledigen können.