
KI verstehen: Wie wir Computern natürliche Sprache beigebracht haben
Veröffentlicht: 2023-11-28Der Begriff „künstliche Intelligenz“ wird in Bezug auf Computer seit den 1950er Jahren verwendet, aber bis zum vergangenen Jahr dachten die meisten Menschen wahrscheinlich, dass KI immer noch eher Science-Fiction als technische Realität sei.
Die Einführung von OpenAIs ChatGPT im November 2022 veränderte plötzlich die Wahrnehmung der Menschen darüber, wozu maschinelles Lernen in der Lage war – aber was genau hat ChatGPT genau dazu gebracht, die Welt aufhorchen zu lassen und zu erkennen, dass künstliche Intelligenz in großem Umfang vorhanden ist?
Mit einem Wort: Sprache – der Grund, warum sich ChatGPT wie ein so bemerkenswerter Sprung nach vorne anfühlte, lag darin, dass es die natürliche Sprache auf eine Art und Weise fließend beherrschte, wie es noch nie zuvor ein Chatbot getan hatte.
Dies markiert eine bemerkenswerte neue Stufe der „Verarbeitung natürlicher Sprache“ (NLP), der Fähigkeit von Computern, natürliche Sprache zu interpretieren und überzeugende Antworten auszugeben. ChatGPT basiert auf einem „Large Language Model“ (LLM), einer Art neuronalem Netzwerk, das Deep Learning nutzt, das auf riesigen Datensätzen trainiert wird und Inhalte verarbeiten und generieren kann.
„Wie konnte ein Computerprogramm eine solche Sprachkompetenz erreichen?“
Aber wie sind wir hierher gekommen? Wie konnte ein Computerprogramm eine solche Sprachkompetenz erreichen? Wie kommt es, dass es so treffsicher menschlich klingt?
ChatGPT entstand nicht im luftleeren Raum – es baute auf unzähligen verschiedenen Innovationen und Entdeckungen der letzten Jahrzehnte auf. Die Reihe von Durchbrüchen, die zu ChatGPT führten, waren allesamt Meilensteine in der Informatik, aber man kann sie auch als Nachahmung der Phasen betrachten, in denen Menschen Sprache erwerben.
Wie lernen wir Sprache?
Um zu verstehen, wie die KI dieses Stadium erreicht hat, lohnt es sich, die Natur des Sprachenlernens selbst zu betrachten: Wir beginnen mit einzelnen Wörtern und beginnen dann, sie zu längeren Sequenzen zu kombinieren, bis wir komplexe Konzepte, Ideen und Anweisungen kommunizieren können.
Einige häufige Phasen des Spracherwerbs bei Kindern sind beispielsweise:
- Holophrastisches Stadium: Im Alter zwischen 9 und 18 Monaten lernen Kinder, einzelne Wörter zu verwenden, die ihre Grundbedürfnisse oder Wünsche beschreiben. Mit einem einzigen Wort zu kommunizieren bedeutet, dass der Schwerpunkt auf Klarheit statt auf konzeptioneller Vollständigkeit liegt. Wenn ein Kind hungrig ist, sagt es nicht „Ich möchte etwas essen“ oder „Ich habe Hunger“, sondern einfach „Essen“ oder „Milch“.
- Zwei-Wort-Stadium: Im Alter von 18 bis 24 Monaten beginnen Kinder, einfache Zwei-Wort-Gruppierungen zu verwenden, um ihre Kommunikationsfähigkeiten zu verbessern. Jetzt können sie ihre Gefühle und Bedürfnisse mit Ausdrücken wie „mehr Essen“ oder „Buch lesen“ mitteilen.
- Telegraphisches Stadium: Im Alter zwischen 24 und 30 Monaten beginnen Kinder, mehrere Wörter aneinanderzureihen, um komplexere Phrasen und Sätze zu bilden. Die Anzahl der verwendeten Wörter ist immer noch gering, aber es zeigt sich eine korrekte Wortreihenfolge und eine zunehmende Komplexität. Kinder beginnen, den grundlegenden Satzbau zu erlernen, wie zum Beispiel „Ich will es Mama zeigen“.
- Mehrwortstadium: Nach 30 Monaten beginnen Kinder mit dem Übergang in die Mehrwortphase. In dieser Phase beginnen Kinder, grammatikalisch korrektere und komplexere Sätze mit mehreren Sätzen zu verwenden. Dies ist die letzte Phase des Spracherwerbs und Kinder kommunizieren schließlich mit komplexen Sätzen wie „Wenn es regnet, möchte ich drinnen bleiben und Spiele spielen.“
Einer der ersten wichtigen Schritte beim Spracherwerb ist die Fähigkeit, auf sehr einfache Weise mit der Verwendung einzelner Wörter zu beginnen. Das erste Hindernis, das KI-Forscher überwinden mussten, bestand darin, Modelle so zu trainieren, dass sie einfache Wortassoziationen lernen.
Modell 1 – Einzelne Wörter lernen mit Word2Vec (Aufsatz 1 und Aufsatz 2)
Eines der frühen neuronalen Netzwerkmodelle, das auf diese Weise versuchte, Wortassoziationen zu lernen, war Word2Vec, entwickelt von Tomaš Mikolov und einer Gruppe von Forschern bei Google. Es wurde 2013 in zwei Artikeln veröffentlicht (was zeigt, wie schnell sich die Dinge auf diesem Gebiet entwickelt haben).
Diese Modelle wurden trainiert, indem man lernte, häufig verwendete Wörter zu assoziieren. Dieser Ansatz baute auf der Intuition früher Sprachpioniere wie John R. Firth auf, der feststellte, dass Bedeutung aus der Wortassoziation abgeleitet werden könne: „Man erkennt ein Wort an der Gesellschaft, die es hat.“
Die Idee dahinter ist, dass Wörter, die eine ähnliche semantische Bedeutung haben, tendenziell häufiger zusammen vorkommen. Die Wörter „Katzen“ und „Hunde“ würden im Allgemeinen häufiger zusammen vorkommen als Wörter wie „Äpfel“ oder „Computer“. Mit anderen Worten: Das Wort „Katze“ sollte dem Wort „Hund“ ähnlicher sein als „Katze“ dem Wort „Apfel“ oder „Computer“.
Das Interessante an Word2Vec ist, wie es darauf trainiert wurde, diese Wortassoziationen zu lernen:
- Erraten Sie das Zielwort: Dem Modell wird eine feste Anzahl von Wörtern als Eingabe gegeben, bei denen das Zielwort fehlt, und es musste das fehlende Zielwort erraten. Dies wird als Continuous Bag Of Words (CBOW) bezeichnet.
- Erraten Sie die umgebenden Wörter: Das Modell erhält ein einzelnes Wort und wird dann damit beauftragt, die umgebenden Wörter zu erraten. Dies ist als Skip-Gram bekannt und stellt den entgegengesetzten Ansatz zu CBOW dar, da wir die umgebenden Wörter vorhersagen.
Ein Vorteil dieser Ansätze besteht darin, dass Sie zum Trainieren des Modells keine gekennzeichneten Daten benötigen – die Kennzeichnung von Daten, beispielsweise die Beschreibung von Text als „positiv“ oder „negativ“, um die Stimmungsanalyse zu lehren, ist schließlich eine langsame und mühsame Arbeit.
Eines der überraschendsten Dinge an Word2Vec waren die komplexen semantischen Beziehungen, die es mit einem relativ einfachen Trainingsansatz erfasste. Word2Vec gibt Vektoren aus, die das Eingabewort darstellen. Durch die Durchführung mathematischer Operationen an diesen Vektoren konnten die Autoren zeigen, dass die Wortvektoren nicht nur syntaktisch ähnliche Elemente, sondern auch komplexe semantische Beziehungen erfassen.
Diese Beziehungen hängen davon ab, wie die Wörter verwendet werden. Als Beispiel nannten die Autoren die Beziehung zwischen Wörtern wie „König“ und „Königin“ sowie „Mann“ und „Frau“.
Aber obwohl es ein Fortschritt war, hatte Word2Vec Grenzen. Es gab nur eine Definition pro Wort – wir alle wissen zum Beispiel, dass „Bank“ unterschiedliche Bedeutungen haben kann, je nachdem, ob Sie vorhaben, eine Bank hochzuhalten oder von einer Bank aus zu angeln. Word2Vec war das egal, es hatte nur eine Definition des Wortes „Bank“ und würde diese in allen Kontexten verwenden.
Vor allem konnte Word2Vec weder Anweisungen noch gar Sätze verarbeiten. Es konnte nur ein Wort als Eingabe verwenden und eine „Worteinbettung“ oder Vektordarstellung ausgeben, die es für dieses Wort gelernt hatte. Um auf dieser Einzelwort-Grundlage aufzubauen, mussten die Forscher einen Weg finden, zwei oder mehr Wörter in einer Reihenfolge aneinanderzureihen. Wir können uns dies ähnlich wie die Zwei-Wörter-Phase des Spracherwerbs vorstellen.
Modell 2 – Lernen von Wortsequenzen mit RNNs und Textsequenzen
Sobald Kinder begonnen haben, die Verwendung einzelner Wörter zu beherrschen, versuchen sie, Wörter zusammenzusetzen, um komplexere Gedanken und Gefühle auszudrücken. Ebenso bestand der nächste Schritt in der Entwicklung von NLP darin, die Fähigkeit zu entwickeln, Wortfolgen zu verarbeiten. Das Problem bei der Verarbeitung von Textsequenzen besteht darin, dass sie keine feste Länge haben. Die Länge eines Satzes kann von wenigen Wörtern bis zu einem langen Absatz variieren. Nicht die gesamte Reihenfolge wird für die Gesamtbedeutung und den Gesamtzusammenhang von Bedeutung sein. Wir müssen jedoch in der Lage sein, die gesamte Sequenz zu verarbeiten, um zu wissen, welche Teile am relevantesten sind.
Hier kamen Recurrent Neural Networks (RNNs) auf den Markt.
Ein in den 1990er Jahren entwickeltes RNN funktioniert, indem es seine Eingaben in einer Schleife verarbeitet, in der die Ausgaben der vorherigen Schritte durch das Netzwerk übertragen werden, während es jeden Schritt in der Sequenz durchläuft.
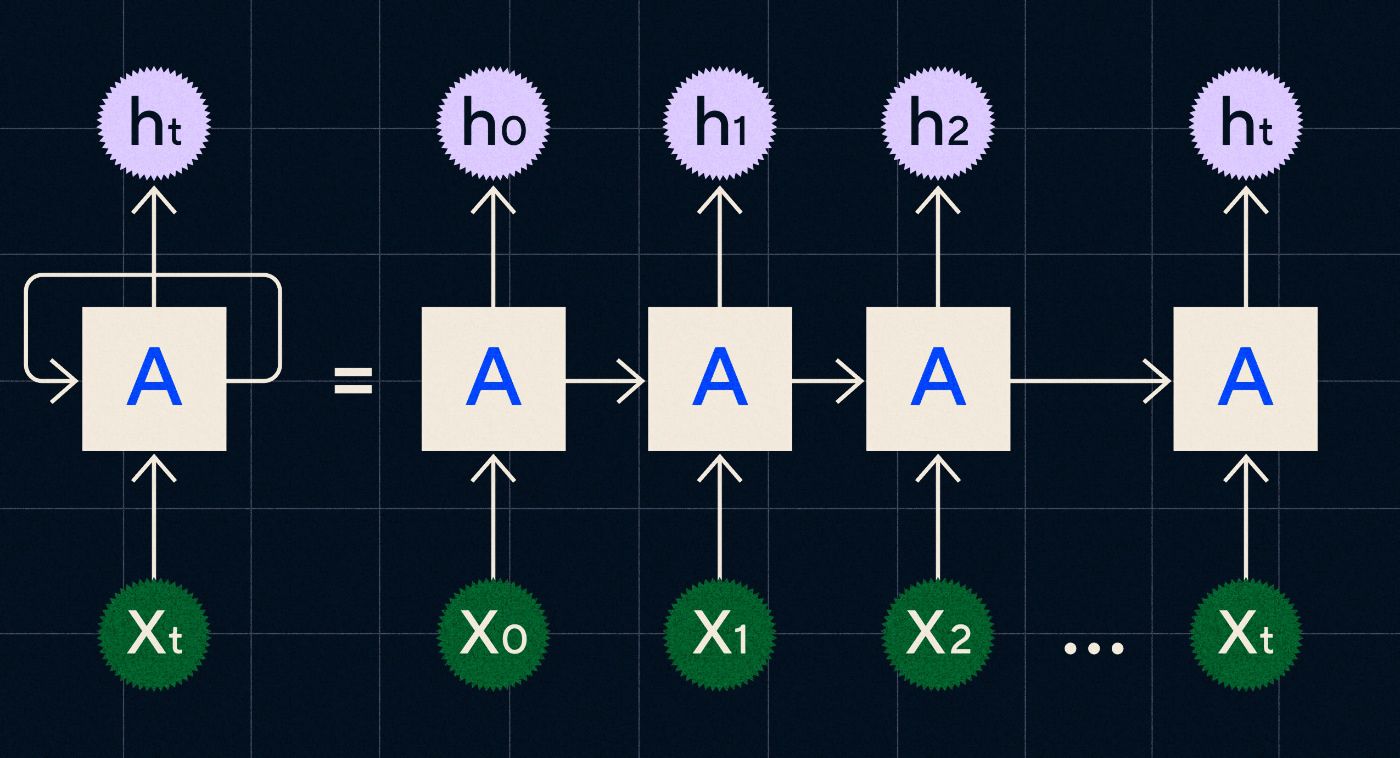
Quelle: Christopher Olahs Blogbeitrag über RNNs
Das obige Diagramm zeigt, wie man sich ein RNN als eine Reihe neuronaler Netze (A) vorstellt, bei denen die Ausgabe des vorherigen Schritts (h0, h1, h2…ht) in den nächsten Schritt übernommen wird. In jedem Schritt wird auch eine neue Eingabe (X0, X1, X2 … Xt) vom Netzwerk verarbeitet.
RNNs (und insbesondere Long Short Term Memory Networks oder LSTMs, eine spezielle Art von RNN, die 1997 von Sepp Hochreiter und Jürgen Schmidhuber eingeführt wurde) ermöglichten es uns, neuronale Netzwerkarchitekturen zu schaffen, die komplexere Aufgaben wie die Übersetzung ausführen konnten.
Im Jahr 2014 wurde von Ilya Sutskever (Mitbegründer von OpenAI), Oriol Vinyals und Quoc V Le bei Google ein Artikel veröffentlicht, in dem Sequence-to-Sequence-Modelle (Seq2Seq) beschrieben wurden. In diesem Artikel wurde gezeigt, wie Sie einem neuronalen Netzwerk beibringen können, einen Eingabetext zu übernehmen und eine Übersetzung dieses Textes zurückzugeben. Sie können sich dies als ein frühes Beispiel eines generativen neuronalen Netzwerks vorstellen, bei dem Sie eine Eingabeaufforderung geben und eine Antwort zurückgeben. Die Aufgabe war jedoch behoben, sodass Sie sie, wenn sie auf Übersetzung trainiert war, nicht zu etwas anderem „veranlassen“ konnten.
Denken Sie daran, dass das Vorgängermodell Word2Vec nur einzelne Wörter verarbeiten konnte. Wenn Sie ihm also einen Satz wie „Der Zahnarzt hat mir den Zahn gezogen“ übergeben würden, würde einfach ein Vektor für jedes Wort generiert, als ob sie nichts miteinander zu tun hätten.
Bei Aufgaben wie der Übersetzung sind jedoch Reihenfolge und Kontext wichtig. Sie können nicht nur einzelne Wörter übersetzen, sondern müssen Wortfolgen analysieren und dann das Ergebnis ausgeben. Hier ermöglichten RNNs Seq2Seq-Modellen, Wörter auf diese Weise zu verarbeiten.
Der Schlüssel zu Seq2Seq-Modellen war das neuronale Netzwerkdesign, bei dem zwei RNNs hintereinander verwendet wurden. Einer war ein Encoder, der die Eingabe von Text in eine Einbettung umwandelte, und der andere war ein Decoder, der die vom Encoder ausgegebenen Einbettungen als Eingabe nahm:
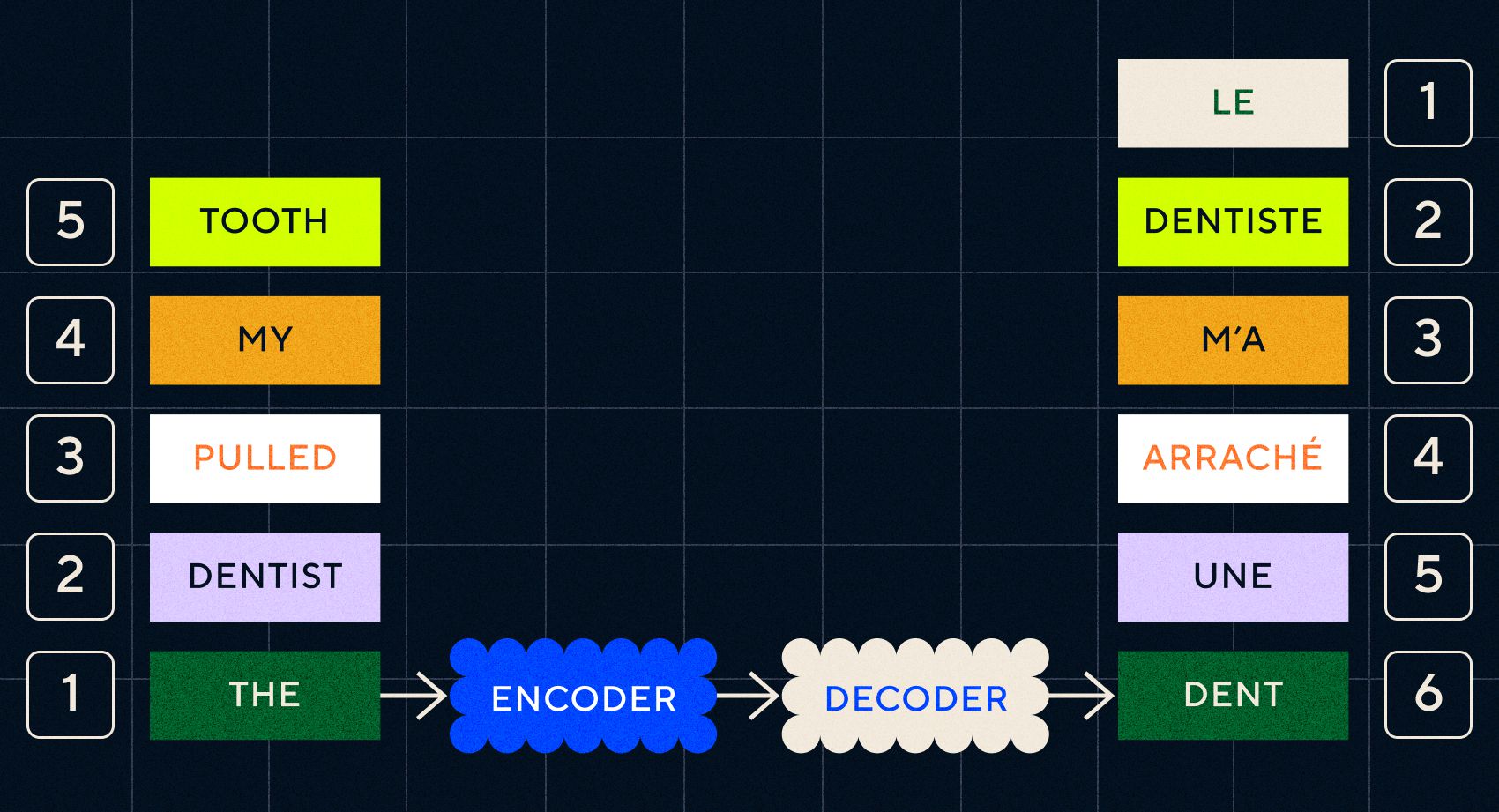
Sobald der Encoder die Eingaben in jedem Schritt verarbeitet hat, beginnt er, die Ausgabe an den Decoder weiterzuleiten, der die Einbettungen in einen übersetzten Text umwandelt.
Wir können an der Entwicklung dieser Modelle erkennen, dass sie in einer einfachen Form beginnen, dem zu ähneln, was wir heute bei ChatGPT sehen. Wir können jedoch auch sehen, wie begrenzt diese Modelle im Vergleich waren. Wie bei unserer eigenen Sprachentwicklung müssen wir, um unsere sprachlichen Fähigkeiten wirklich zu verbessern, genau wissen, worauf wir achten müssen, um komplexere Phrasen und Sätze zu bilden.
Modell 3 – Lernen durch Aufmerksamkeit und Skalierung mit Transformers
Wir haben bereits erwähnt, dass die Kinder in der telegrafischen Phase begannen, kurze Sätze mit zwei oder mehr Wörtern zu bilden. Ein wichtiger Aspekt dieser Phase des Spracherwerbs besteht darin, dass Kinder beginnen zu lernen, wie man richtige Sätze bildet.
RNNs und Seq2Seq-Modelle halfen Sprachmodellen bei der Verarbeitung mehrerer Wortsequenzen, waren jedoch immer noch in der Länge der Sätze, die sie verarbeiten konnten, begrenzt. Mit zunehmender Satzlänge müssen wir auf die meisten Dinge im Satz achten.
Nehmen Sie zum Beispiel den folgenden Satz: „Es herrschte so viel Spannung im Raum, dass man sie mit einem Messer zerschneiden könnte.“ Da ist viel los. Um zu wissen, dass wir hier nicht buchstäblich etwas mit einem Messer schneiden, müssen wir „Schnitt“ mit „Spannung“ weiter oben im Satz verknüpfen.
Mit zunehmender Satzlänge wird es schwieriger zu wissen, welche Wörter sich auf welches beziehen, um daraus die richtige Bedeutung abzuleiten. Hier stießen RNNs an ihre Grenzen und wir brauchten ein neues Modell, um zur nächsten Stufe des Spracherwerbs überzugehen.
„Stellen Sie sich vor, Sie versuchen, ein Gespräch zusammenzufassen, das mit einer festen Wortbeschränkung immer länger wird. Mit jedem Schritt gehen mehr und mehr Informationen verloren.“
Im Jahr 2017 veröffentlichte eine Forschergruppe bei Google einen Artikel, in dem eine Technik vorgeschlagen wurde, mit der Modelle besser auf den wichtigen Kontext in einem Text achten können.
Sie entwickelten eine Möglichkeit für Sprachmodelle, den benötigten Kontext bei der Verarbeitung einer Eingabetextsequenz einfacher nachzuschlagen. Sie nannten diesen Ansatz „Transformer-Architektur“ und stellten den bislang größten Fortschritt in der Verarbeitung natürlicher Sprache dar.
Dieser Suchmechanismus erleichtert dem Modell die Identifizierung, welche der vorherigen Wörter mehr Kontext für das aktuell verarbeitete Wort lieferten. RNNs versuchen, Kontext bereitzustellen, indem sie einen aggregierten Zustand aller Wörter übergeben, die bei jedem Schritt bereits verarbeitet wurden. Stellen Sie sich vor, Sie versuchen, ein Gespräch zusammenzufassen, das mit einer festen Wortbeschränkung immer länger wird. Mit jedem Schritt beginnen Sie, mehr und mehr Informationen zu verlieren. Stattdessen gewichteten Transformatoren Wörter (oder Token, bei denen es sich nicht um ganze Wörter, sondern um Wortteile handelt) basierend auf ihrer Bedeutung für das aktuelle Wort im Hinblick auf seinen Kontext. Dies machte es einfacher, immer längere Wortfolgen zu verarbeiten, ohne den bei RNNs beobachteten Engpass. Dieser neue Aufmerksamkeitsmechanismus ermöglichte auch die parallele Verarbeitung des Textes statt sequentiell wie bei einem RNN.
Stellen Sie sich also einen Satz vor wie „Das Tier ist nicht über die Straße gegangen, weil es zu müde war“. Für ein RNN müsste es bei jedem Schritt alle vorherigen Wörter darstellen. Je mehr Wörter zwischen „es“ und „Tier“ stehen, desto schwieriger wird es für das RNN, den richtigen Kontext zu identifizieren.

Mit der Transformer-Architektur ist das Modell nun in der Lage, das Wort nachzuschlagen, das sich am ehesten auf „es“ bezieht. Das folgende Diagramm zeigt, wie Transformatormodelle sich bei der Verarbeitung eines Satzes auf den „tierischen“ Teil des Textes konzentrieren können.
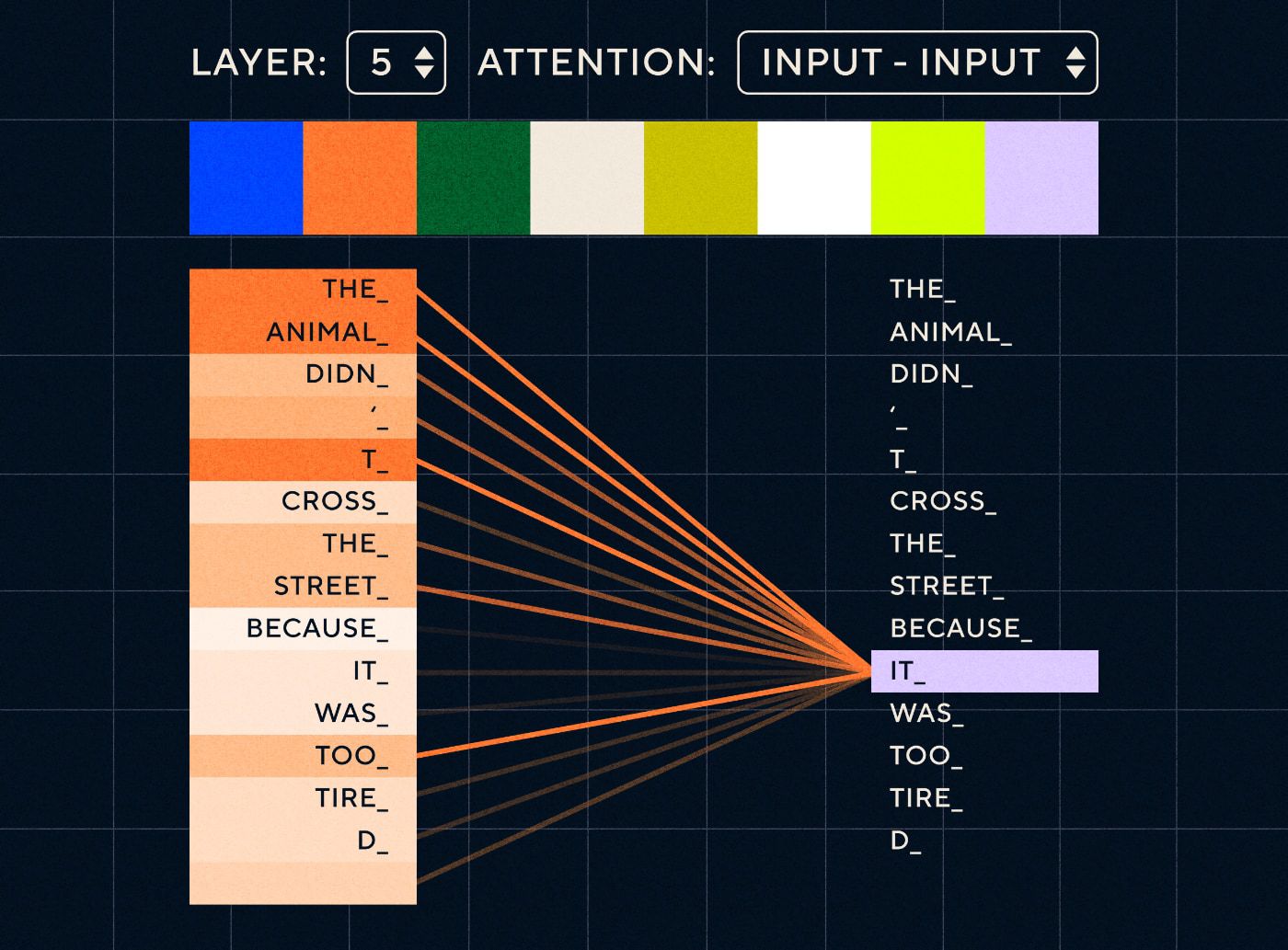
Quelle: The Illustrated Transformer
Das obige Diagramm zeigt die Aufmerksamkeit auf Schicht 5 des Netzwerks. Auf jeder Ebene baut das Modell sein Verständnis des Satzes auf und „achtet“ auf einen bestimmten Teil der Eingabe, der seiner Meinung nach für den Schritt, den es gerade verarbeitet, relevanter ist, d. h. es schenkt „dem“ mehr Aufmerksamkeit „Tier“ für das „Es“ in dieser Ebene. Quelle: Der illustrierte Transformer
Stellen Sie es sich wie eine Datenbank vor, in der das Wort mit der höchsten Punktzahl abgerufen werden kann, das am wahrscheinlichsten mit „es“ zusammenhängt.
Mit dieser Entwicklung beschränkten sich Sprachmodelle nicht mehr auf das Parsen kurzer Textsequenzen. Stattdessen könnten Sie längere Textsequenzen als Eingaben verwenden. Wir wissen, dass es ihre Sprachentwicklung verbessert, wenn Kinder durch „engagierte Gespräche“ mehr Wörtern ausgesetzt werden.
In ähnlicher Weise waren Sprachmodelle mit dem neuen Aufmerksamkeitsmechanismus in der Lage, mehr und vielfältigere Arten von Texttrainingsdaten zu analysieren. Dazu gehörten Wikipedia-Artikel, Online-Foren, Twitter und alle anderen Textdaten, die Sie analysieren konnten. Wie bei der kindlichen Entwicklung half der Umgang mit all diesen Wörtern und deren Verwendung in unterschiedlichen Kontexten den Sprachmodellen dabei, neue und kompliziertere sprachliche Fähigkeiten zu entwickeln.
In dieser Phase begann ein Skalierungswettlauf, bei dem die Leute immer mehr Daten auf diese Modelle werfen, um zu sehen, was sie lernen könnten. Diese Daten mussten nicht von Menschen gekennzeichnet werden – Forscher konnten einfach das Internet durchsuchen, sie dem Modell zuführen und sehen, was es gelernt hat.
„Modelle wie BERT haben jeden verfügbaren Rekord in der Verarbeitung natürlicher Sprache gebrochen. Tatsächlich waren die für diese Aufgaben verwendeten Testdatensätze für diese Transformatormodelle viel zu einfach.“
Das BERT-Modell (Bidirektionale Encoder-Repräsentationen von Transformers) verdient aus mehreren Gründen eine besondere Erwähnung. Es war eines der ersten Modelle, das die Aufmerksamkeitsfunktion nutzte, die den Kern der Transformer-Architektur darstellt. Erstens war BERT insofern bidirektional, als es Text sowohl links als auch rechts von der aktuellen Eingabe betrachten konnte. Dies unterschied sich von RNNs, die Text nur der Reihe nach von links nach rechts verarbeiten konnten. Zweitens verwendete BERT auch eine neue Trainingstechnik namens „Maskierung“, die das Modell in gewisser Weise dazu zwang, die Bedeutung verschiedener Eingaben zu lernen, indem zufällige Token „versteckt“ oder „maskiert“ wurden, um sicherzustellen, dass das Modell nicht „schummeln“ konnte Konzentrieren Sie sich in jeder Iteration auf einen einzelnen Token. Und schließlich könnte BERT feinabgestimmt werden, um verschiedene NLP-Aufgaben auszuführen. Für diese Aufgaben musste es nicht von Grund auf trainiert werden.
Die Ergebnisse waren erstaunlich. Modelle wie BERT haben jeden verfügbaren Rekord in der Verarbeitung natürlicher Sprache gebrochen. Tatsächlich waren die für diese Aufgaben verwendeten Testdatensätze für diese Transformatormodelle viel zu einfach.
Jetzt hatten wir die Möglichkeit, große Sprachmodelle zu trainieren, die als Grundmodelle für neue Aufgaben der Verarbeitung natürlicher Sprache dienten. Früher trainierten die Leute ihre Modelle meist von Grund auf. Aber jetzt waren vorab trainierte Modelle wie BERT und die frühen GPT-Modelle so gut, dass es keinen Sinn mehr machte, es selbst zu machen. Tatsächlich waren diese Modelle so gut, dass die Leute entdeckten, dass sie neue Aufgaben mit relativ wenigen Beispielen lösen konnten – sie wurden als „Few-Shot-Lerner“ beschrieben, ähnlich wie die meisten Menschen nicht zu viele Beispiele brauchen, um neue Konzepte zu verstehen.
Dies war ein gewaltiger Wendepunkt in der Entwicklung dieser Modelle und ihrer sprachlichen Fähigkeiten. Jetzt mussten wir nur noch die Bastelanleitungen verbessern.
Modell 4 – Lernanweisungen mit InstructGPT
Eines der Dinge, die Kinder in der letzten Phase des Spracherwerbs, der Mehrwortphase, lernen, ist die Fähigkeit, Funktionswörter zu verwenden, um die informationstragenden Elemente in einem Satz zu verbinden. Funktionswörter geben Auskunft über die Beziehung zwischen verschiedenen Wörtern in einem Satz. Wenn wir Anweisungen erstellen wollen, müssen Sprachmodelle in der Lage sein, Sätze mit Inhaltswörtern und Funktionswörtern zu erstellen, die komplexe Beziehungen erfassen. In der folgenden Anweisung sind beispielsweise die Funktionswörter fett hervorgehoben:
- „ Ich möchte, dass du einen Brief schreibst …“
- „Sagen Sie mir , was Sie über den obigen Text denken.“
Aber bevor wir versuchen konnten, Sprachmodelle so zu trainieren, dass sie Anweisungen befolgen, mussten wir genau verstehen, was sie bereits über Anweisungen wussten.
GPT-3 von OpenAI wurde im Jahr 2020 veröffentlicht. Es war ein Einblick in die Leistungsfähigkeit dieser Modelle, aber wir mussten noch verstehen, wie wir die zugrunde liegenden Fähigkeiten dieser Modelle freischalten können. Wie könnten wir mit diesen Modellen interagieren, um sie dazu zu bringen, verschiedene Aufgaben auszuführen?
GPT-3 zeigte beispielsweise, dass die Vergrößerung der Modellgröße und der Trainingsdaten das ermöglichte, was die Autoren „Meta-Lernen“ nannten – dabei entwickelt das Sprachmodell eine breite Palette sprachlicher Fähigkeiten, von denen viele unerwartet waren, und kann diese nutzen Fähigkeiten, um eine gegebene Aufgabe zu verstehen.
„Wäre das Modell in der Lage, die Absicht der Anweisung zu verstehen und die Aufgabe auszuführen, anstatt nur das nächste Wort vorherzusagen?“
Denken Sie daran, dass GPT-3 und frühere Sprachmodelle nicht darauf ausgelegt sind, diese Fähigkeiten zu entwickeln – sie wurden hauptsächlich darauf trainiert, nur das nächste Wort in einer Textsequenz vorherzusagen. Aber durch Fortschritte bei RNNs, Seq2Seq und Aufmerksamkeitsnetzwerken waren diese Modelle in der Lage, mehr Text in längeren Sequenzen zu verarbeiten und sich besser auf den relevanten Kontext zu konzentrieren.
Sie können sich GPT-3 als einen Test vorstellen, um zu sehen, wie weit wir damit kommen können. Wie groß könnten wir die Modelle machen und mit wie viel Text könnten wir sie füttern? Anschließend könnten wir, anstatt dem Modell nur einen Eingabetext zur Vervollständigung zuzuführen, den Eingabetext als Anweisung verwenden. Wäre das Modell in der Lage, die Absicht der Anweisung zu verstehen und die Aufgabe auszuführen, anstatt nur das nächste Wort vorherzusagen? In gewisser Weise war es so, als würde man versuchen zu verstehen, welches Stadium des Spracherwerbs diese Modelle erreicht hatten.
Wir bezeichnen dies heute als „anregend“, aber im Jahr 2020, als das Papier herauskam, war das ein völlig neues Konzept.
Halluzinationen und Ausrichtung
Das Problem mit GPT-3 bestand, wie wir jetzt wissen, darin, dass es sich nicht besonders gut an die Anweisungen im Eingabetext halten konnte. GPT-3 kann Anweisungen befolgen, verliert aber leicht die Aufmerksamkeit, kann nur einfache Anweisungen verstehen und neigt dazu, Dinge zu erfinden. Mit anderen Worten: Die Modelle entsprechen nicht unseren Absichten. Das Problem besteht nun also nicht so sehr darin, die Sprachfähigkeit der Modelle zu verbessern, sondern vielmehr in ihrer Fähigkeit, Anweisungen zu befolgen.
Es ist erwähnenswert, dass GPT-3 nie wirklich auf Anweisungen trainiert wurde. Es wurde nicht gesagt, was eine Anweisung war, wie sie sich von anderen Texten unterschied oder wie sie den Anweisungen folgen sollte. In gewisser Weise wurde es dazu „ausgetrickst“, Anweisungen zu befolgen, indem es eine Eingabeaufforderung wie andere Textsequenzen „vervollständigte“. Daher musste OpenAI ein Modell trainieren, das Anweisungen wie ein Mensch besser befolgen konnte. Und das taten sie in einem Anfang 2022 veröffentlichten Artikel mit dem treffenden Titel „Sprachmodelle trainieren, um Anweisungen mit menschlichem Feedback zu befolgen“. InstructGPT sollte sich später im selben Jahr als Vorläufer von ChatGPT erweisen.
Die in diesem Dokument beschriebenen Schritte wurden auch zum Trainieren von ChatGPT verwendet. Die Schulung erfolgte im Wesentlichen in drei Schritten:
- Schritt 1 – Feinabstimmung von GPT-3: Da GPT-3 mit dem Lernen mit wenigen Schüssen so gut zu funktionieren schien, dachte man, dass es besser wäre, wenn es anhand hochwertiger Unterrichtsbeispiele feinabgestimmt würde. Das Ziel bestand darin, es einfacher zu machen, die Absicht in der Anweisung mit der generierten Antwort in Einklang zu bringen. Zu diesem Zweck ließ OpenAI menschliche Labeler Antworten auf einige Eingabeaufforderungen erstellen, die von Personen übermittelt wurden, die GPT-3 verwenden. Durch die Verwendung realer Anweisungen wollten die Autoren eine realistische „Verteilung“ der Aufgaben erfassen, die Benutzer von GPT-3 ausführen lassen wollten. Diese wurden zur Feinabstimmung von GPT-3 verwendet, um ihm zu helfen, seine Fähigkeit zur schnellen Reaktion zu verbessern.
- Schritt 2 – Bringen Sie Menschen dazu, den neuen und verbesserten GPT-3 zu bewerten: Um den neuen, an Anweisungen fein abgestimmten GPT-3 zu bewerten, bewerteten die Labeler nun die Leistung des Modells bei verschiedenen Eingabeaufforderungen ohne vordefinierte Reaktion. Das Ranking bezog sich auf wichtige Ausrichtungsfaktoren wie Hilfsbereitschaft, Ehrlichkeit und nicht giftig, voreingenommen oder schädlich. Geben Sie dem Modell also eine Aufgabe und bewerten Sie seine Leistung anhand dieser Metriken. Die Ausgabe dieser Ranking-Übung wurde dann verwendet, um ein separates Modell zu trainieren, um vorherzusagen, welche Ausgaben die Etikettierer wahrscheinlich bevorzugen würden. Dieses Modell ist als Belohnungsmodell (RM) bekannt.
- Schritt 3 – Verwenden Sie den RM, um weitere Beispiele zu trainieren: Schließlich wurde der RM verwendet, um das neue Instruktionsmodell zu trainieren, um Antworten besser zu generieren, die auf menschliche Vorlieben abgestimmt sind.
Es ist schwierig, vollständig zu verstehen, was hier mit Reinforcement Learning From Human Feedback (RLHF), Belohnungsmodellen, Richtlinienaktualisierungen usw. vor sich geht.
Eine einfache Möglichkeit, es sich vorzustellen, ist, dass es lediglich eine Möglichkeit ist, Menschen in die Lage zu versetzen, bessere Beispiele dafür zu generieren, wie man Anweisungen befolgt. Überlegen Sie zum Beispiel, wie Sie einem Kind beibringen würden, sich zu bedanken:
- Elternteil: „Wenn dir jemand X gibt, sagst du Danke.“ Dies ist Schritt 1, ein Beispieldatensatz mit Eingabeaufforderungen und entsprechenden Antworten
- Elternteil: „Was sagst du jetzt zu Y?“ Dies ist Schritt 2, bei dem wir das Kind bitten, eine Antwort zu generieren, und der Elternteil wird diese dann bewerten. "Ja das ist gut."
- Schließlich wird der Elternteil das Kind in späteren Begegnungen anhand guter oder schlechter Beispiele für Reaktionen in ähnlichen künftigen Szenarien belohnen. Dies ist Schritt 3, in dem das Verstärkungsverhalten stattfindet.
OpenAI seinerseits behauptet, dass es lediglich Funktionen freischaltet, die bereits in Modellen wie GPT-3 vorhanden waren, „aber nur schwer durch zeitnahes Engineering hervorzurufen waren“, wie es in dem Papier heißt.
Mit anderen Worten: Bei ChatGPT geht es nicht darum, „ neue “ Fähigkeiten zu erlernen, sondern lediglich eine bessere sprachliche „ Schnittstelle “ zu erlernen, um diese zu nutzen.
Die Magie der Sprache
ChatGPT fühlt sich wie ein magischer Sprung nach vorne an, ist aber tatsächlich das Ergebnis eines jahrzehntelangen sorgfältigen technologischen Fortschritts.
Wenn wir uns einige der wichtigsten Entwicklungen im Bereich KI und NLP im letzten Jahrzehnt ansehen, können wir sehen, wie ChatGPT „auf den Schultern von Giganten steht“. Frühere Modelle lernten zunächst, die Bedeutung von Wörtern zu erkennen. Nachfolgende Modelle setzten diese Wörter dann zusammen und wir konnten ihnen beibringen, Aufgaben wie die Übersetzung auszuführen. Sobald sie Sätze verarbeiten konnten, entwickelten wir Techniken, die es diesen Sprachmodellen ermöglichten, immer mehr Text zu verarbeiten und die Fähigkeit zu entwickeln, diese Erkenntnisse auf neue und unvorhergesehene Aufgaben anzuwenden. Und dann haben wir mit ChatGPT endlich die Möglichkeit entwickelt, besser mit diesen Modellen zu interagieren, indem wir unsere Anweisungen in einem natürlichen Sprachformat angeben.
„Da Sprache das Vehikel unserer Gedanken ist, wird es dann, nun ja, zu unabhängiger künstlicher Intelligenz führen, wenn man Computern die volle Leistungsfähigkeit der Sprache beibringt?“
Die Entwicklung von NLP offenbart jedoch eine tiefere Magie, für die wir normalerweise blind sind – die Magie der Sprache selbst und wie wir als Menschen sie erwerben.
Es gibt noch viele offene Fragen und Kontroversen darüber, wie Kinder überhaupt Sprache lernen. Es stellt sich auch die Frage, ob allen Sprachen eine gemeinsame Grundstruktur zugrunde liegt. Hat sich der Mensch dazu entwickelt, Sprache zu verwenden, oder ist es umgekehrt?
Das Merkwürdige ist, dass diese Modelle dabei helfen können, einige dieser wichtigen Fragen zu beantworten, da ChatGPT und seine Nachkommen ihre sprachliche Entwicklung verbessern.
Da die Sprache schließlich das Vehikel unserer Gedanken ist, stellt sich die Frage, ob es zu einer unabhängigen künstlichen Intelligenz führen wird, wenn man Computern die volle Leistungsfähigkeit der Sprache beibringt. Wie immer im Leben gibt es noch so viel zu lernen.
