
Hacking The Topic Graph mit Wikipedia und der Google Language API
Veröffentlicht: 2019-08-27Eines meiner Lieblings-Slide-Decks der letzten zehn Jahre wurde 2014 von Mark Johnstone gemacht, als er noch bei Distilled war. Das Deck hieß How to Produce Better Content Ideas und ich benutzte es einige Jahre lang als meine Bibel, während ich Teams zusammenstellte, um die harte Arbeit der Content-Promotion zu erledigen.
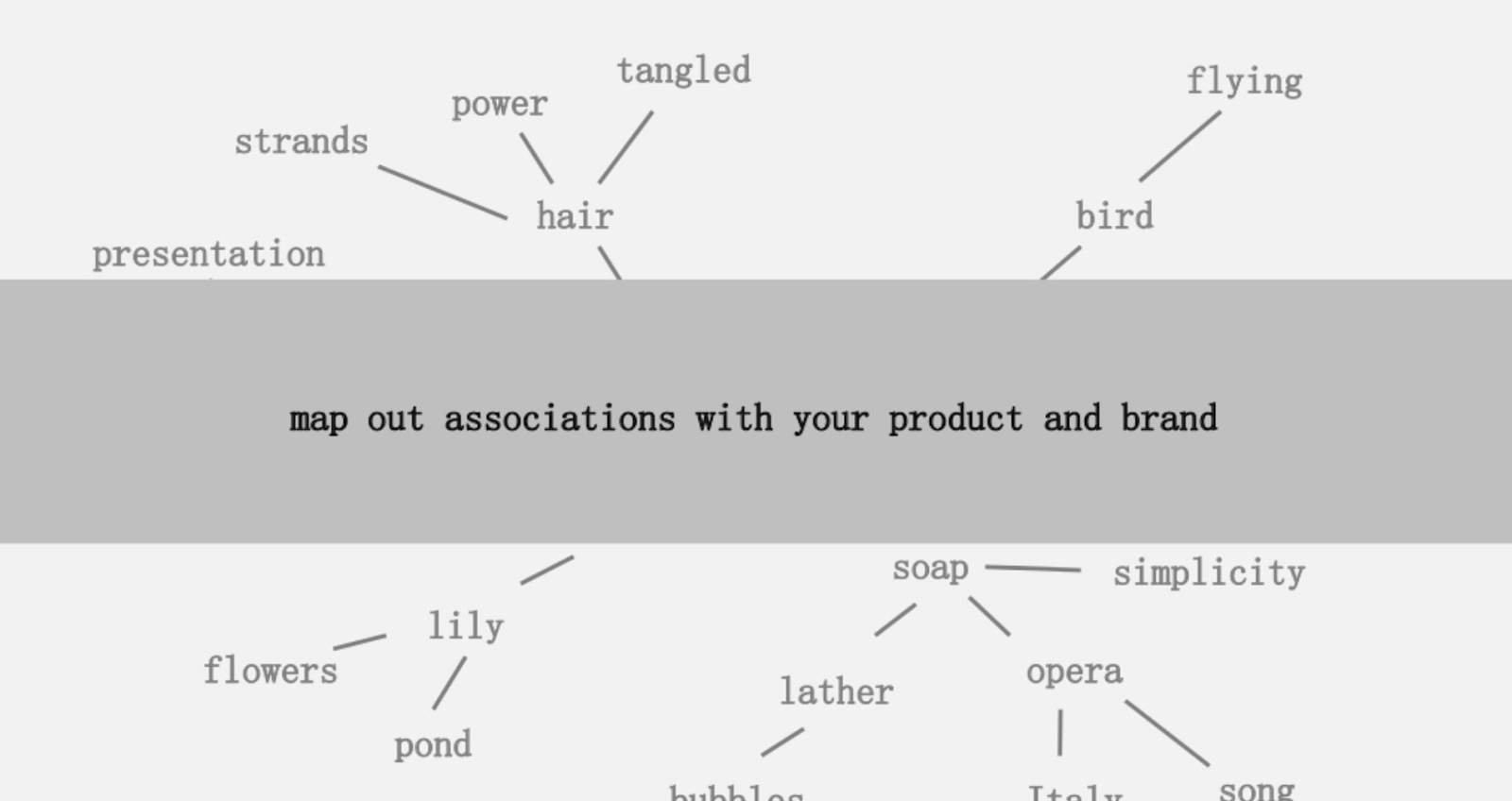
Eine der angebotenen Ideen bestand darin, eine visuelle Abbildung der Verbundenheit von Wörtern zu erstellen, die mit Ihrem Produkt oder Ihrer Marke verbunden sind, damit Sie zurücktreten und nach Möglichkeiten suchen können, die Assoziationen zu etwas Interessantem zu kombinieren. Das Ziel ist die Produktion von Ideen, die er definiert als „ eine neuartige Kombination von bisher unverbundenen Elementen in einer Weise, die einen Mehrwert bringt“.
In diesem Artikel verfolgen wir einen weitaus linkeren Ansatz, indem wir Python, die Sprach-API von Google, zusammen mit Wikipedia verwenden, um Entitätsassoziationen zu untersuchen, die aus einem Seed-Thema bestehen. Das Ziel ist eine allgemeine Ansicht der Entitätsbeziehungen entlang des Themendiagramms. Dieser Artikel ist nichts für den Durchschnittsleser. Leser, die mit Python vertraut sind und zumindest über grundlegende Programmierkenntnisse verfügen, werden es viel lehrreicher finden.
Die Idee
In Anlehnung an die Mapping-Idee von Mark Johnstone dachte ich, es wäre interessant, Google und Wikipedia eine Themenstruktur definieren zu lassen, die von einem Seed-Thema oder einer Webseite ausgeht. Das Ziel ist es, die Zuordnung von Beziehungen zum Hauptthema visuell in einem baumartigen Diagramm aufzubauen, das überprüft werden kann, um nach Verbindungen zu suchen und möglicherweise Inhaltsideen zu generieren. Das folgende Bild stellt die anfängliche Designidee dar.
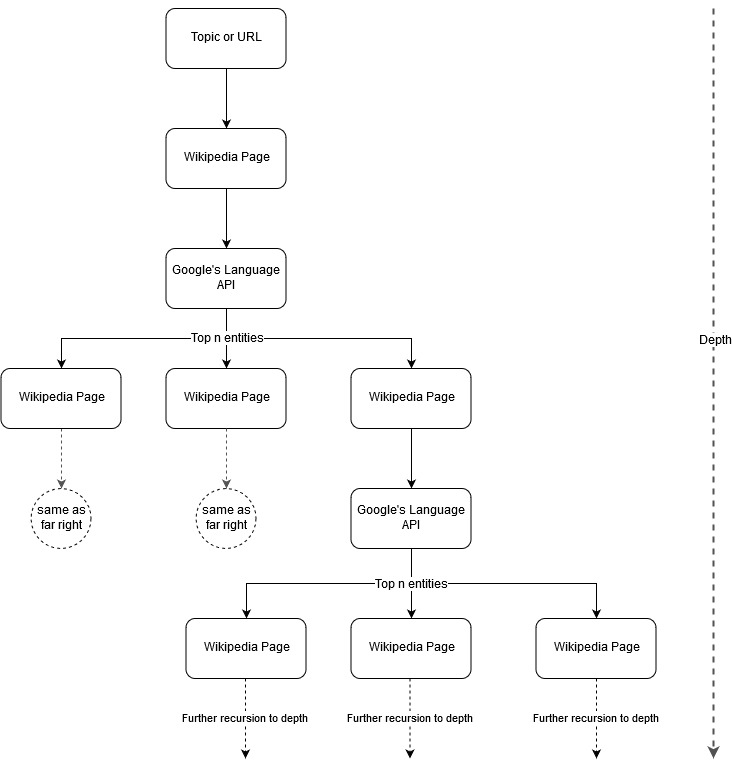
Im Wesentlichen geben wir dem Tool ein Thema oder eine URL und lassen die Sprach-API von Google die obersten n (3 in unseren Beispielen) Entitäten (einschließlich Wikipedia-URLs) für jede Entitätsseite auswählen, und wir bauen rekursiv ein Netzwerkdiagramm für jede gefundene Entität auf bis zu einer maximalen Tiefe.
Hintergrund der verwendeten Tools
Google Sprach-API
Die Sprach-API von Google ermöglicht es Ihnen, entweder einfachen Text oder HTML zu übergeben, und es gibt auf magische Weise alle verschiedenen Entitäten zurück, die mit dem Inhalt verbunden sind. Die API tut mehr als das, aber für diese Analyse werden wir uns nur auf diesen Teil konzentrieren. Hier ist eine Liste der Arten von Entitäten, die zurückgegeben werden:
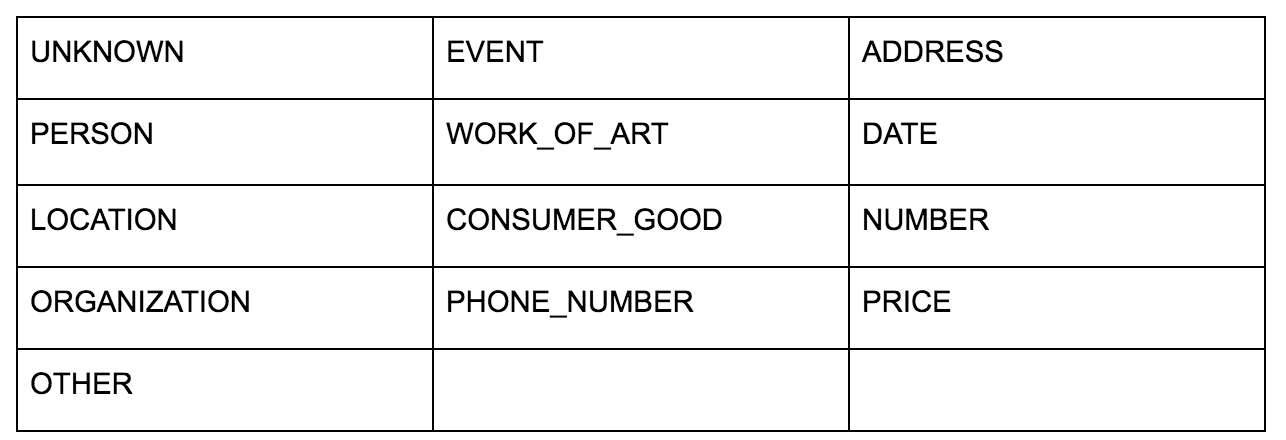
Die Entitätsidentifikation ist seit langem ein grundlegender Bestandteil der Verarbeitung natürlicher Sprache (NLP), und die korrekte Terminologie für diese Aufgabe ist Named Entity Recognition (NER). NER ist eine schwierige Aufgabe, da viele Wörter je nach verwendetem Kontext unterschiedliche Bedeutungen haben, sodass NLP-Tools oder APIs den vollständigen Kontext der Begriffe verstehen müssen, um sie richtig als eine bestimmte Entität identifizieren zu können.
Ich habe in einem Artikel auf opensource.com einen ziemlich detaillierten Überblick über diese API und insbesondere Entitäten gegeben, falls Sie sich vor Abschluss dieses Artikels über etwas Kontext informieren möchten.
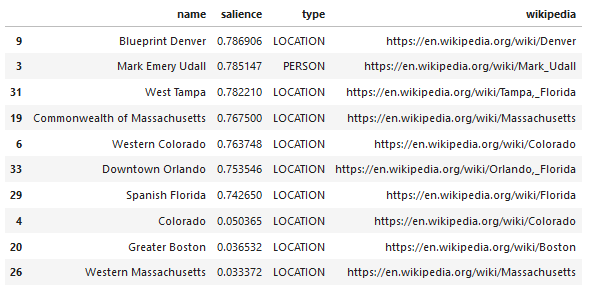
Ein interessantes Feature der Sprach-API von Google besteht darin, dass es nicht nur relevante Entitäten findet, sondern auch markiert, in welcher Beziehung sie zum Gesamtdokument stehen (Salience), und für einige einen verwandten Wikipedia-Artikel (Knowledge Graph) liefert, der die Entität darstellt.
Hier ist eine Beispielausgabe dessen, was die API zurückgibt (sortiert nach Hervorhebung):
Oncrawl-Entwickler
 Mehr erfahren
Mehr erfahrenPython
Python ist eine Softwaresprache, die im Data-Science-Bereich aufgrund einer großen und wachsenden Reihe von Bibliotheken, die es einfach machen, große Datensätze aufzunehmen, zu bereinigen, zu manipulieren und zu analysieren, populär geworden ist. Es profitiert auch von einer kollaborativen Umgebung namens Jupyter Notebooks, die es Benutzern ermöglicht, ihren Code mühelos zu testen und zu kommentieren.
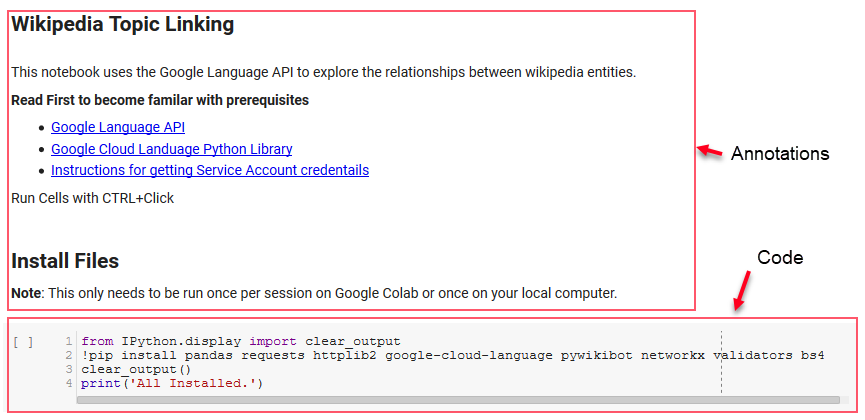
Für diese Überprüfung werden wir einige Schlüsselbibliotheken verwenden, die es uns ermöglichen, einige interessante Dinge mit den NLP-Daten von Google zu tun.
- Pandas: Stellen Sie sich vor, Sie könnten Microsoft Excel schreiben, um Tabellenkalkulationen zu lesen, zu speichern, zu parsen oder neu anzuordnen, und Sie bekommen eine Vorstellung davon, was Pandas tut. Pandas ist erstaunlich. (Verknüpfung)
- Networkx: Networkx ist ein Werkzeug zum Erstellen von Graphen von Knoten und Kanten, die die Beziehungen zwischen den Knoten definieren. Es hat auch eine eingebaute Unterstützung für das Plotten der Diagramme, so dass sie einfach zu visualisieren sind. (Verknüpfung)
- Pywikibot: Pywikibot ist eine Bibliothek, mit der Sie mit Wikipedia interagieren können, um mit allen Inhalten für jede Wikipedia-Site zu suchen, zu bearbeiten, Beziehungen zu finden usw. (Verknüpfung)
Der Prozess
Wir teilen hier ein Google Colab-Notizbuch, das zum Mitverfolgen verwendet werden kann. (Besonderer Dank gilt Tyler Reardon für eine Plausibilitätsprüfung des Artikels und dieses Notizbuchs.)
Einrichten
Die ersten paar Zellen im Notebook befassen sich mit der Installation einiger Bibliotheken, der Bereitstellung dieser Bibliotheken für Python und der Bereitstellung von Anmeldeinformationen und einer Konfigurationsdatei für Googles Sprach-API bzw. Pywikibot. Hier sind alle Bibliotheken, die wir installieren müssen, um sicherzustellen, dass das Tool ausgeführt werden kann:
- Pandas
- Anfragen
- httplib2
- Google-Cloud-Sprache
- pywikibot
- Netzwerkx
- Validatoren
- Bs4
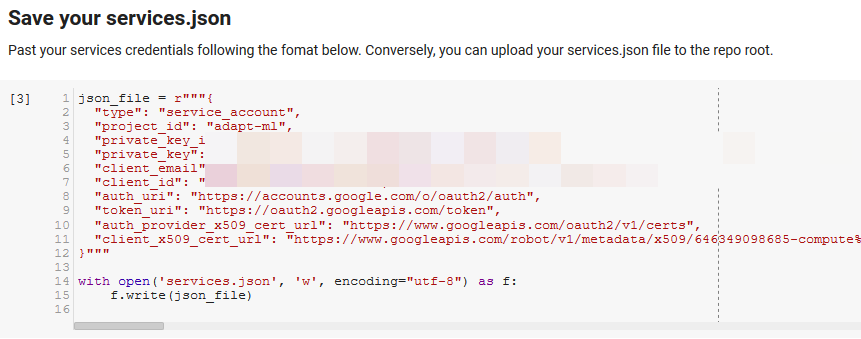
Hinweis: Der schwierigste Teil beim Ausführen dieses Notebooks besteht darin, Anmeldeinformationen von Google für den Zugriff auf ihre APIs zu erhalten. Für diejenigen, die damit nicht vertraut sind, wird dies ungefähr eine Stunde dauern, um es herauszufinden. Wir haben die Anweisungen zum Abrufen der Dienstkonto-Anmeldeinformationen oben im Notizbuch verlinkt, um Ihnen zu helfen. Unten sehen Sie ein Beispiel dafür, wie wir unsere eingefügt haben.
Funktionen für den Gewinn
In der Zelle, die durch „Einige Funktionen für Google NLP definieren“ gekennzeichnet ist, entwickeln wir acht Funktionen, die Dinge wie das Abfragen der Sprach-API, die Interaktion mit Wikipedia, das Extrahieren von Webseitentext und das Erstellen und Zeichnen von Diagrammen handhaben. Funktionen sind im Wesentlichen kleine Codeeinheiten, die einige Einstellungsdaten aufnehmen, etwas Arbeit erledigen und etwas produzieren. Alle Funktionen sind kommentiert, um die Variablen anzugeben, die sie aufnehmen, und was sie produzieren.

Testen der API
Die folgenden zwei Zellen nehmen eine URL, extrahieren den Text aus der URL und ziehen die Entitäten aus der Sprach-API von Google. Einer zieht nur Entitäten, die Wikipedia-URLs haben, und der andere zieht alle Entitäten von dieser Seite.
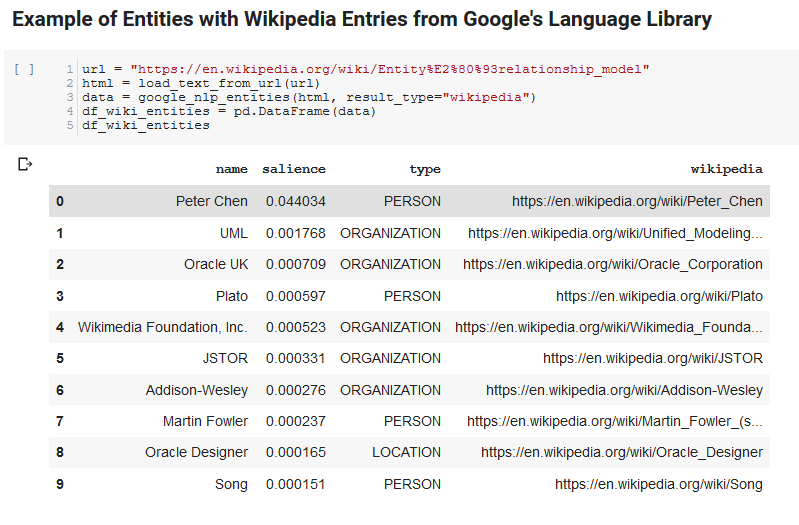
Dies war ein wichtiger erster Schritt, um den Inhaltsextraktionsteil korrekt zu machen und zu verstehen, wie die Sprach-API funktionierte und Daten zurückgab.
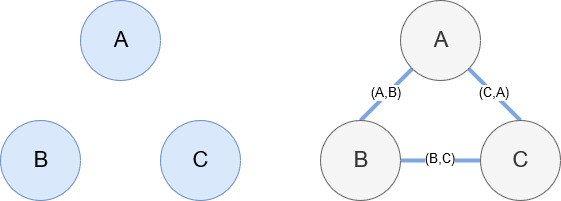
Netzwerkx
Networkx ist, wie bereits erwähnt, eine wunderbare Bibliothek, mit der man ziemlich intuitiv spielen kann. Im Wesentlichen müssen Sie ihm mitteilen, was Ihre Knoten sind und wie die Knoten verbunden sind. In der Abbildung unten geben wir Networkx beispielsweise drei Knoten (A, B, C). Dann teilen wir Networkx mit, dass sie durch Kanten (A, B), (B, C), (C, A) verbunden sind, die die Beziehungen zwischen den Knoten definieren. Für unsere Verwendung sind die Entitäten mit Wikipedia-URLs die Knoten und die Kanten werden durch neue Entitäten definiert, die auf einer aktuellen Entitätsseite gefunden werden. Wenn wir also die Wikipedia-Seite für Entität A überprüfen und auf dieser Seite Entität B entdeckt wird, dann ist das eine Kante zwischen Entität A und Entität B.
Alles zusammenfügen
Der nächste Abschnitt des Notizbuchs heißt Wikipedia Topic Branching by URL. Hier geschieht die Magie. Wir hatten zuvor eine spezielle Funktion (recurse_entities) definiert, die durch Seiten auf Wikipedia rekursiert und neuen Entitäten folgt, die von Googles Sprach-API definiert wurden. Wir haben auch eine wirklich umständlich zu verstehende Funktion (hierarchy_pos) hinzugefügt, die wir aus Stack Overflow übernommen haben und die einen guten Job macht, ein baumartiges Diagramm mit vielen Knoten darzustellen. In der Zelle darunter definieren wir die Eingabe als „Suchmaschinenoptimierung“ und geben eine Tiefe von 3 (so viele Seiten folgt sie rekursiv) und ein Limit von 3 (so viele Entitäten zieht sie pro Seite) an.
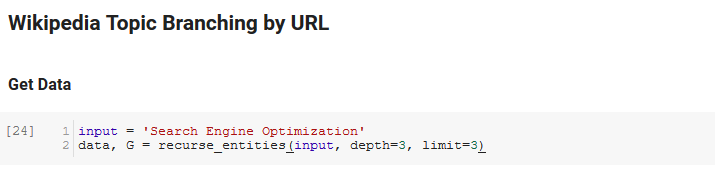
Wenn wir es für den Begriff „Search Engine Optimization“ ausführen, können wir den folgenden Pfad sehen, den das Tool genommen hat, beginnend mit der Search Engine Optimization-Seite von Wikipedia (Ebene 0) und den Seiten rekursiv bis zur angegebenen maximalen Tiefe folgend (3).

Wir nehmen dann alle gefundenen Entitäten und fügen sie einem Pandas DataFrame hinzu, was das Speichern als CSV wirklich einfach macht. Wir sortieren diese Daten nach Hervorhebung (was bedeutet, wie wichtig die Entität für die Seite ist, auf der sie gefunden wurde), aber diese Punktzahl ist in diesem Zusammenhang etwas irreführend, da sie Ihnen nicht sagt, wie verwandt die Entität mit Ihrem ursprünglichen Begriff ist („ Suchmaschinenoptimierung"). Diese weitere Arbeit überlassen wir dem Leser.

Schließlich zeichnen wir den vom Tool erstellten Graphen, um die Verbundenheit aller Entitäten zu zeigen. In der Zelle darunter sind die Parameter, die Sie an die Funktion übergeben können: ( G : der zuvor von der Funktion recurse_entities erstellte Graph, w: die Breite des Plots, h: die Höhe des Plots, c: der prozentuale Kreis der Plot und Dateiname: die PNG-Datei, die im Bilderordner gespeichert wird.)

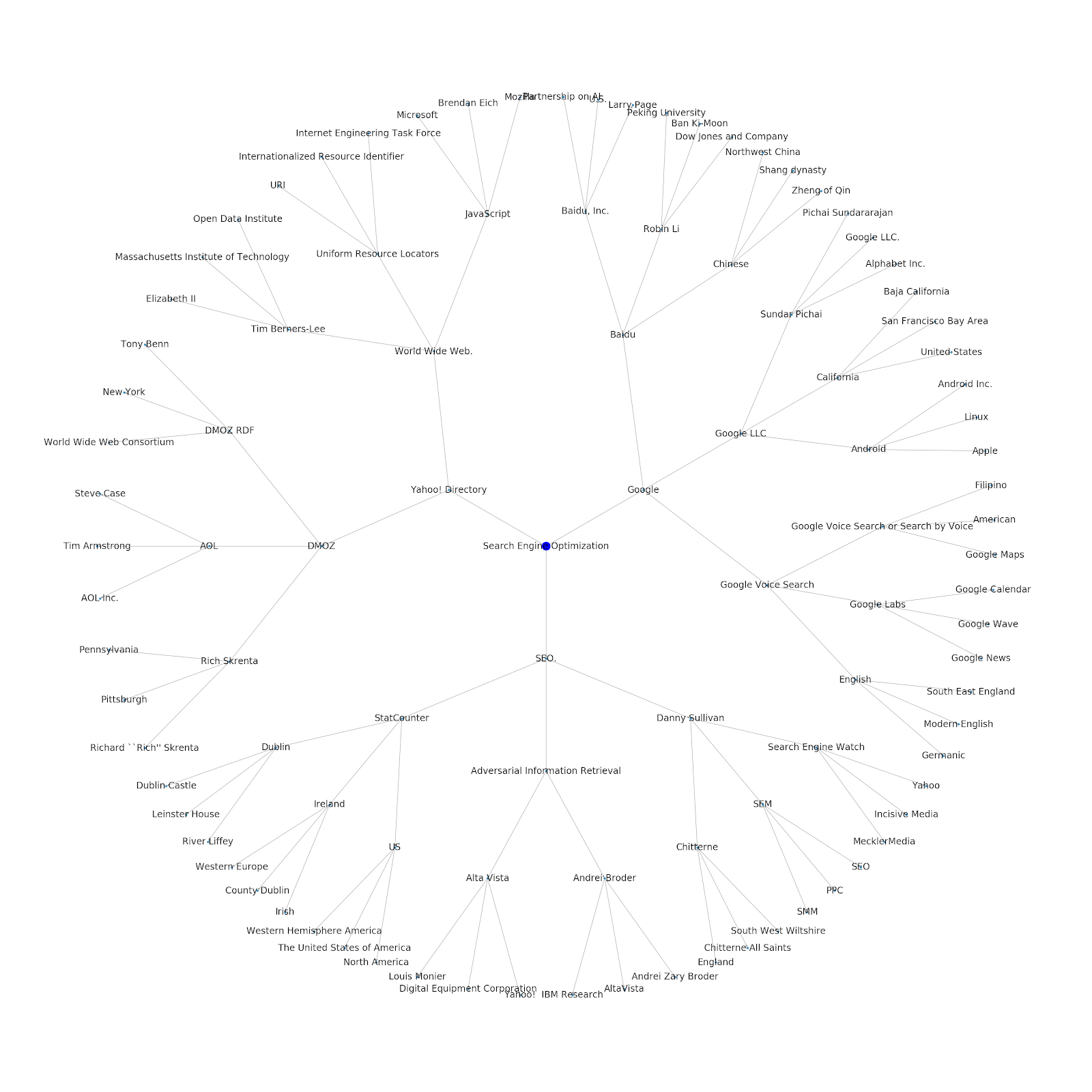
Wir haben die Möglichkeit hinzugefügt, ihm entweder ein Seed-Thema oder eine Seed-URL zu geben. In diesem Fall sehen wir uns die Entitäten an, die mit dem Artikel Google's Indexing Issues Continue But This One Is Different verknüpft sind
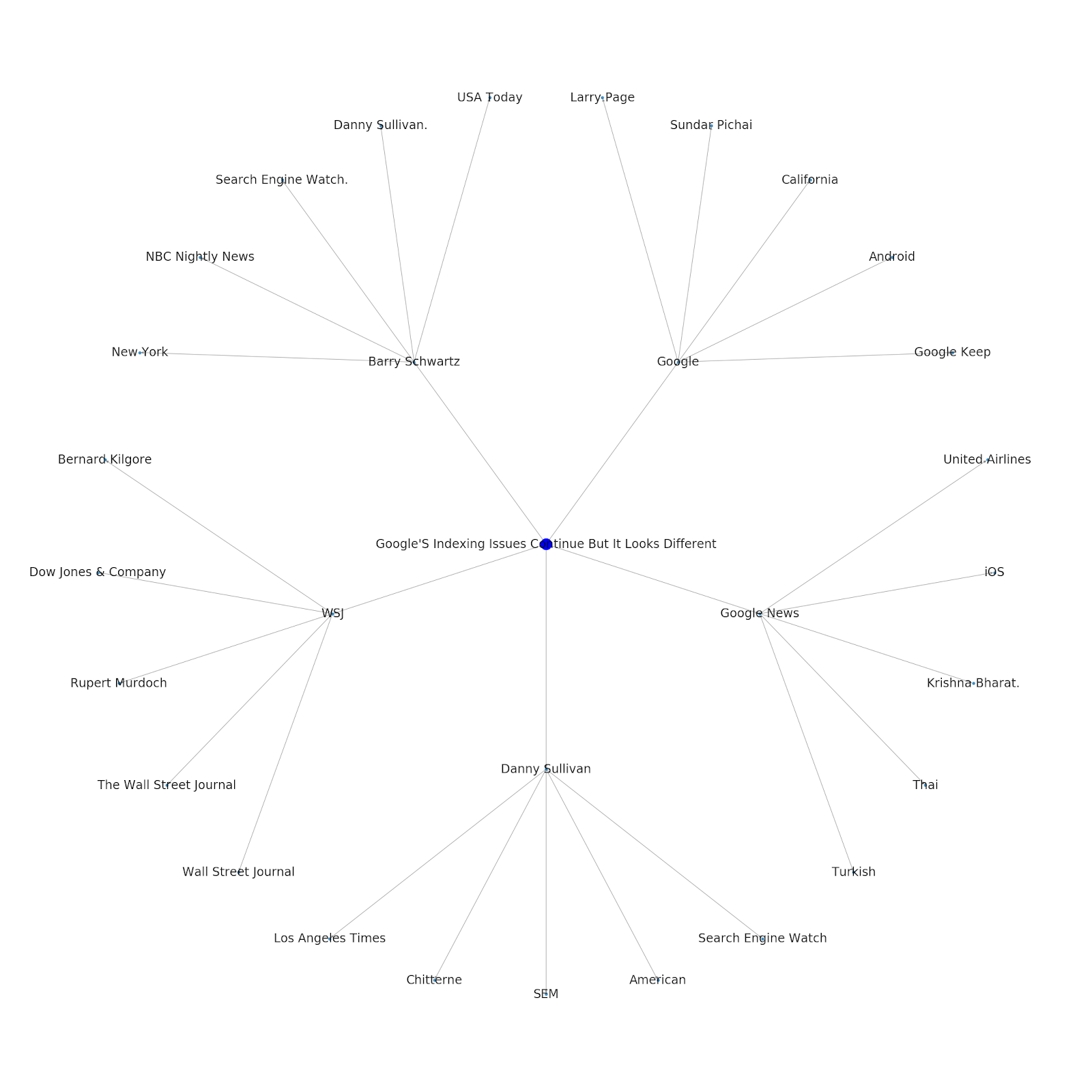
Hier ist das Google/Wikipedia-Entitätsdiagramm für Python.
Was das bedeutet
Das Verständnis der Themenebene des Internets ist aus SEO-Sicht interessant, da es Sie zwingt, in Bezug auf die Zusammenhänge und nicht nur auf einzelne Abfragen zu denken. Da Google diese Ebene verwendet, um individuelle Benutzeraffinitäten mit Themen abzugleichen, wie in der Wiedereinführung von Google Discover erwähnt, könnte dies zu einem wichtigeren Arbeitsablauf für datenorientierte SEOs werden. Aus dem obigen „Python“-Diagramm kann gefolgert werden, dass die Vertrautheit eines Benutzers mit den Themen, die sich auf ein Seed-Thema beziehen, ein vernünftiges Maß für sein Fachwissen in Bezug auf das Seed-Thema sein kann.
Das folgende Beispiel zeigt zwei Benutzer, wobei die grünen Hervorhebungen ihr historisches Interesse oder ihre Affinität zu verwandten Themen zeigen. Der Benutzer auf der linken Seite, der versteht, was eine IDE ist und was PyPy und CPython bedeuten, wäre ein viel erfahrenerer Benutzer mit Python als jemand, der weiß, dass es eine Sprache ist, aber nicht viel mehr. Dies ließe sich leicht in numerische Punktzahlen für jedes Thema und für jeden Benutzer umwandeln.

Fazit
Mein Ziel heute war es, einen ziemlich standardmäßigen Prozess zu teilen, den ich durchlaufe, um die Effektivität verschiedener Tools oder APIs mit Jupyter Notebooks zu testen und zu überprüfen. Das Erkunden des Themendiagramms ist unglaublich interessant, und wir hoffen, dass Sie feststellen, dass die freigegebenen Tools Ihnen den Vorsprung verschaffen, den Sie benötigen, um mit der Erkundung für sich selbst zu beginnen. Mit diesen Tools sind Sie in der Lage, Themendiagramme zu erstellen, die viele Beziehungsebenen untersuchen, nur begrenzt durch das Kontingent der Sprach-API von Google (das 800.000 pro Tag beträgt). (Aktualisierung: Die Preise basieren auf Einheiten von 1.000 Unicode-Zeichen, die an die API gesendet werden, und sind bis zu 5.000 Einheiten kostenlos. Da Wikipedia-Artikel lang werden können, sollten Sie Ihre Ausgaben im Auge behalten. Hut ab vor John Murch für den Hinweis.) Wenn Sie das Notizbuch erweitern oder interessante Fälle finden, lassen Sie es mich bitte wissen. Sie finden mich unter @jroakes auf Twitter.