
Die Schlüssel zum Erstellen einer funktionierenden Robots.txt
Veröffentlicht: 2020-02-18Bots, auch als Crawler oder Spider bekannt, sind Programme, die automatisch von Website zu Website über das Web „reisen“, indem sie die Links als Straße verwenden. Obwohl sie schon immer gewisse Kuriositäten präsentiert haben, können robot.txt-Dateien sehr effektive Werkzeuge sein. Suchmaschinen wie Google und Bing verwenden Bots, um den Inhalt des Webs zu crawlen. Die robots.txt-Datei bietet den verschiedenen Bots eine Anleitung, welche Seiten sie auf Ihrer Website nicht crawlen sollten. Sie können auch von der robots.txt auf Ihre XML-Sitemap verlinken, sodass der Bot eine Karte jeder Seite hat, die er crawlen soll.
Warum ist robots.txt nützlich?
robots.txt begrenzt die Anzahl der Seiten, die ein Bot im Fall von Suchmaschinen-Bots crawlen und indizieren muss. Wenn Sie verhindern möchten, dass Google Verwaltungsseiten crawlt, können Sie sie in Ihrer robots.txt-Datei blockieren, um zu versuchen, eine Seite von den Google-Servern fernzuhalten.
Abgesehen davon, dass verhindert wird, dass Seiten indexiert werden, eignet sich die robots.txt-Datei hervorragend zur Optimierung des Crawl-Budgets. Das Crawling-Budget ist die Anzahl der Seiten, die Google auf Ihrer Website crawlen möchte. Normalerweise haben Websites mit mehr Autorität und mehr Seiten ein größeres Crawl-Budget als Websites mit einer geringen Seitenzahl und geringer Autorität. Da wir nicht wissen, wie viel Crawling-Budget unserer Website zugewiesen ist, möchten wir diese Zeit optimal nutzen, indem wir dem Googlebot erlauben, auf die wichtigsten Seiten zuzugreifen, anstatt Seiten zu crawlen, die wir nicht indexieren möchten.
Ein sehr wichtiges Detail, das Sie über robots.txt wissen müssen, ist, dass Google Seiten, die durch robots.txt blockiert werden, zwar nicht crawlt, diese aber trotzdem indiziert werden können, wenn die Seite von einer anderen Website verlinkt wird. Um zu verhindern, dass Ihre Seiten indexiert werden und in den Google-Suchergebnissen erscheinen, müssen Sie die Dateien auf Ihrem Server mit einem Passwort schützen, das Meta-Tag noindex oder den Response-Header verwenden oder die Seite vollständig entfernen (mit 404 oder 410 antworten). Weitere Informationen zum Crawlen und Steuern der Indexierung finden Sie im robots.txt-Leitfaden von OnCrawl.
[Fallstudie] Verwaltung des Bot-Crawlings von Google
 Lesen Sie die Fallstudie
Lesen Sie die FallstudieRichtige Robots.txt-Syntax
Die robots.txt-Syntax kann manchmal etwas knifflig sein, da verschiedene Crawler die Syntax unterschiedlich interpretieren. Außerdem sehen einige nicht seriöse Crawler robots.txt-Anweisungen als Vorschläge und nicht als definitive Regel, die sie befolgen müssen. Wenn Sie vertrauliche Informationen auf Ihrer Website haben, ist es wichtig, neben dem Blockieren von Crawlern, die die robots.txt verwenden, einen Passwortschutz zu verwenden
Nachfolgend habe ich ein paar Dinge aufgelistet, die Sie bei der Arbeit an Ihrer robots.txt beachten müssen:
- Die robots.txt-Datei muss sich unter der Domain und nicht in einem Unterverzeichnis befinden. Crawler suchen nicht nach robots.txt-Dateien in Unterverzeichnissen.
- Jede Subdomain benötigt eine eigene robots.txt-Datei:
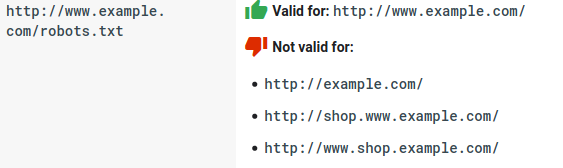
- Bei Robots.txt wird zwischen Groß- und Kleinschreibung unterschieden:
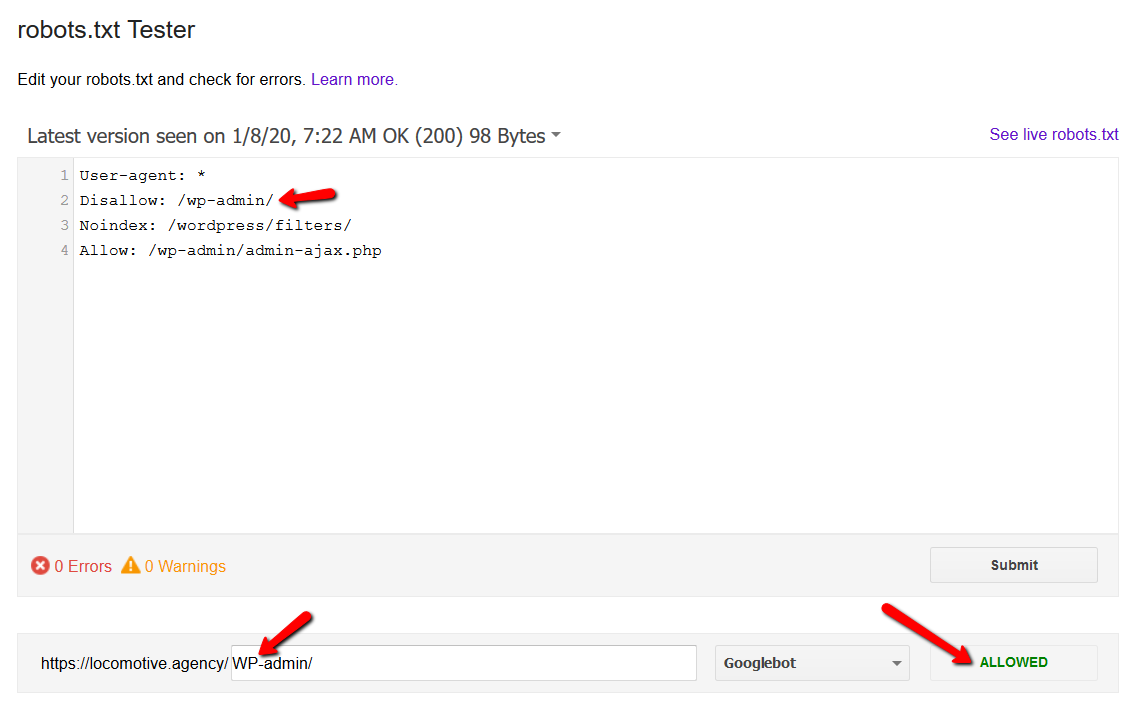
- Die noindex-Anweisung: Wenn Sie noindex in der robots.txt verwenden, funktioniert dies genauso wie disallow. Google hört auf, die Seite zu crawlen, behält sie aber in seinem Index. @jroakes und ich haben einen Test erstellt, bei dem wir die Noindex-Anweisung für den Artikel /wordpress/filters/ verwendet und die Seite bei Google eingereicht haben. Sie können auf dem Screenshot unten sehen, dass die URL blockiert wurde:
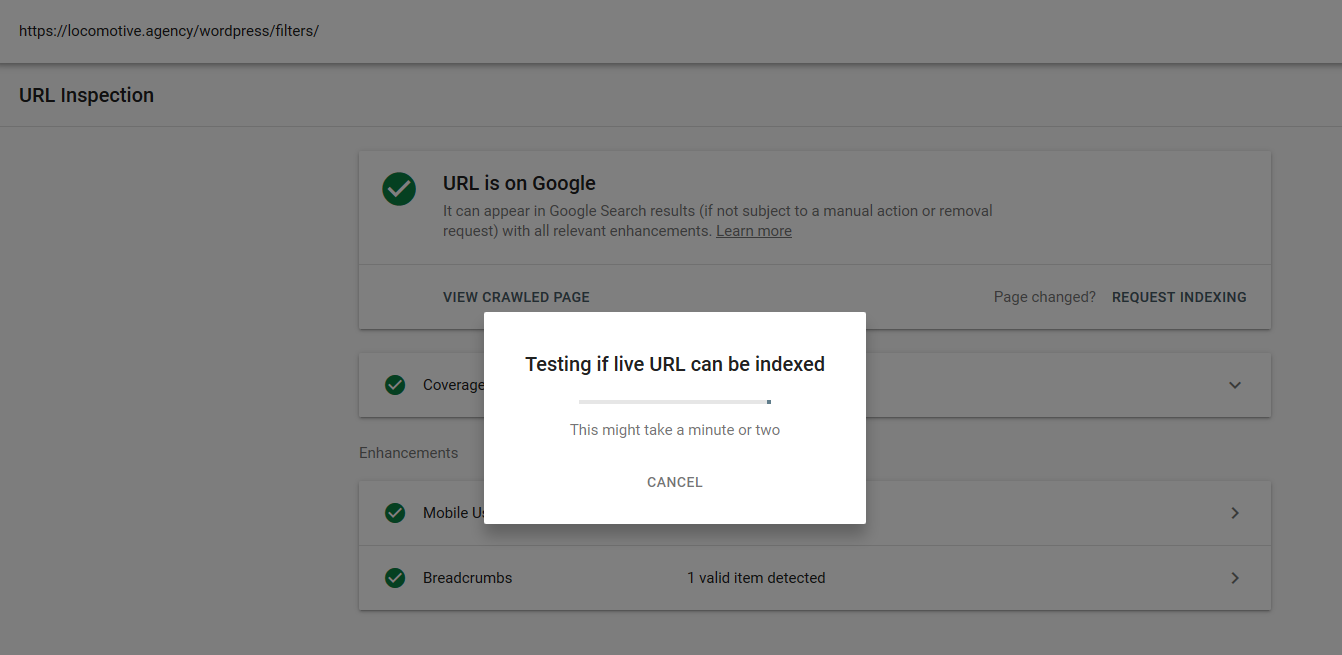
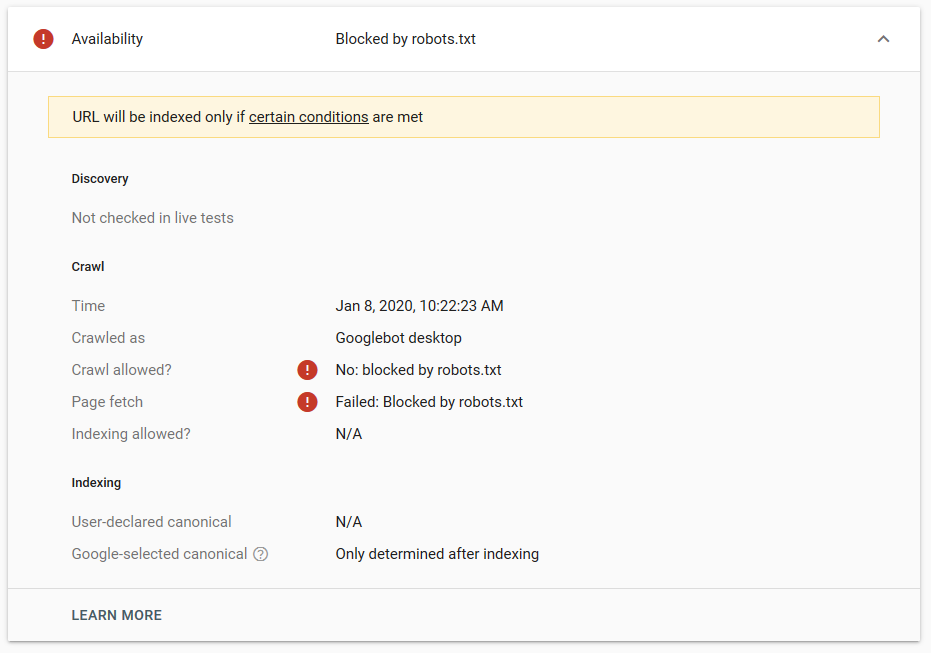
Wir haben mehrere Tests in Google durchgeführt und die Seite wurde nie aus dem Index entfernt:
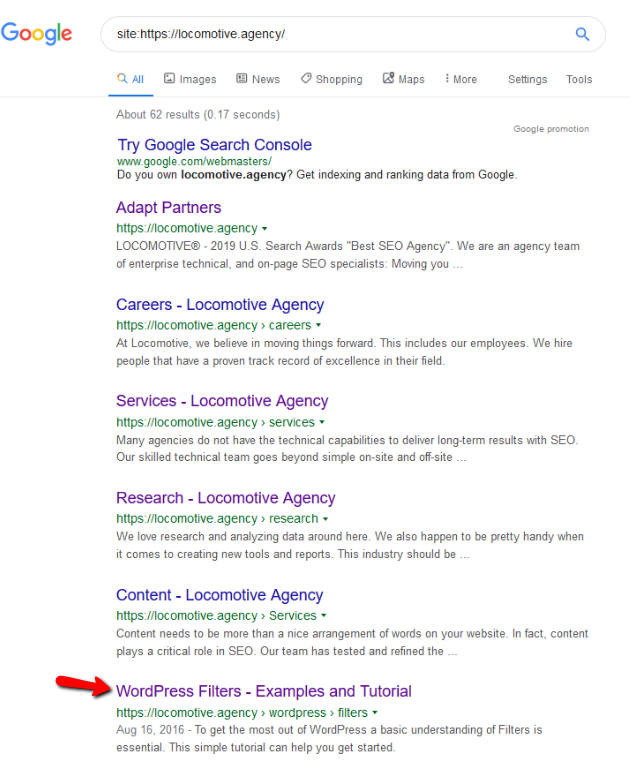

Letztes Jahr gab es eine Diskussion über die noindex-Anweisung, die in der robots.txt funktioniert und Seiten außer Google entfernt. Hier ist ein Thread, in dem Gary Illyes sagte, dass es verschwinden würde. Bei diesem Test können wir sehen, dass die Lösung von Google vorhanden ist, da die noindex-Anweisung die Seite nicht aus den Suchergebnissen entfernt hat.
Kürzlich gab es auf Twitter einen weiteren interessanten Thread von Christian Oliveira, in dem er mehrere Details mitteilte, die bei der Arbeit an Ihrer robots.txt berücksichtigt werden sollten.
- Wenn wir generische Regeln und Regeln nur für den Googlebot haben möchten, müssen wir alle generischen Regeln unter dem User-Agent: Google-Bot-Regelsatz duplizieren. Wenn sie nicht enthalten sind, ignoriert der Googlebot alle Regeln:

- Ein weiteres verwirrendes Verhalten ist, dass die Priorität der Regeln (innerhalb derselben User-Agent-Gruppe) nicht durch ihre Reihenfolge bestimmt wird, sondern durch die Länge der Regel.
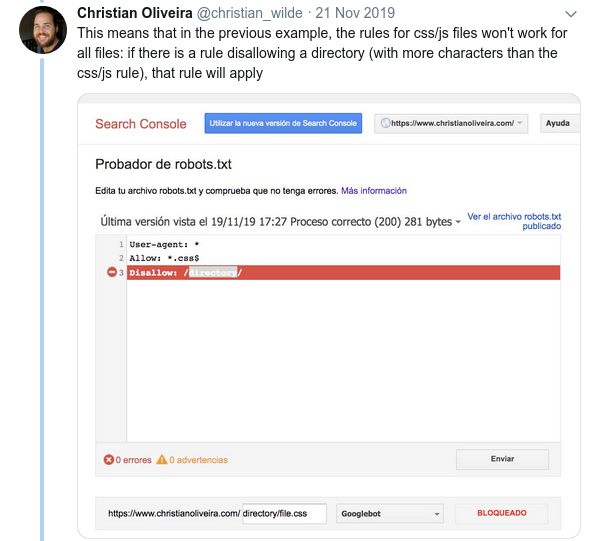
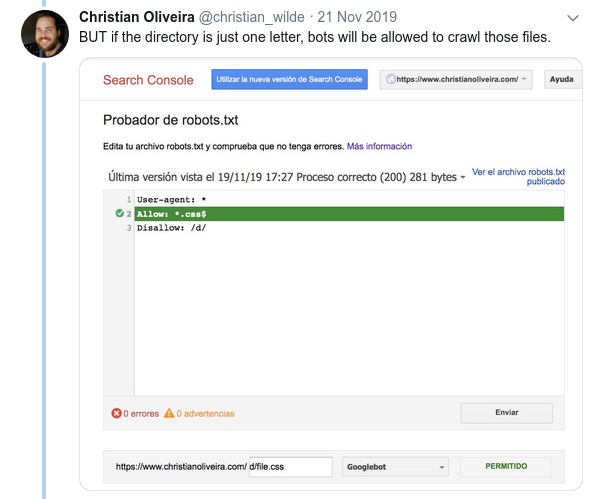
- Wenn Sie nun zwei Regeln mit derselben Länge und entgegengesetztem Verhalten haben (eine erlaubt das Crawlen und die andere verbietet es), gilt die weniger restriktive Regel:
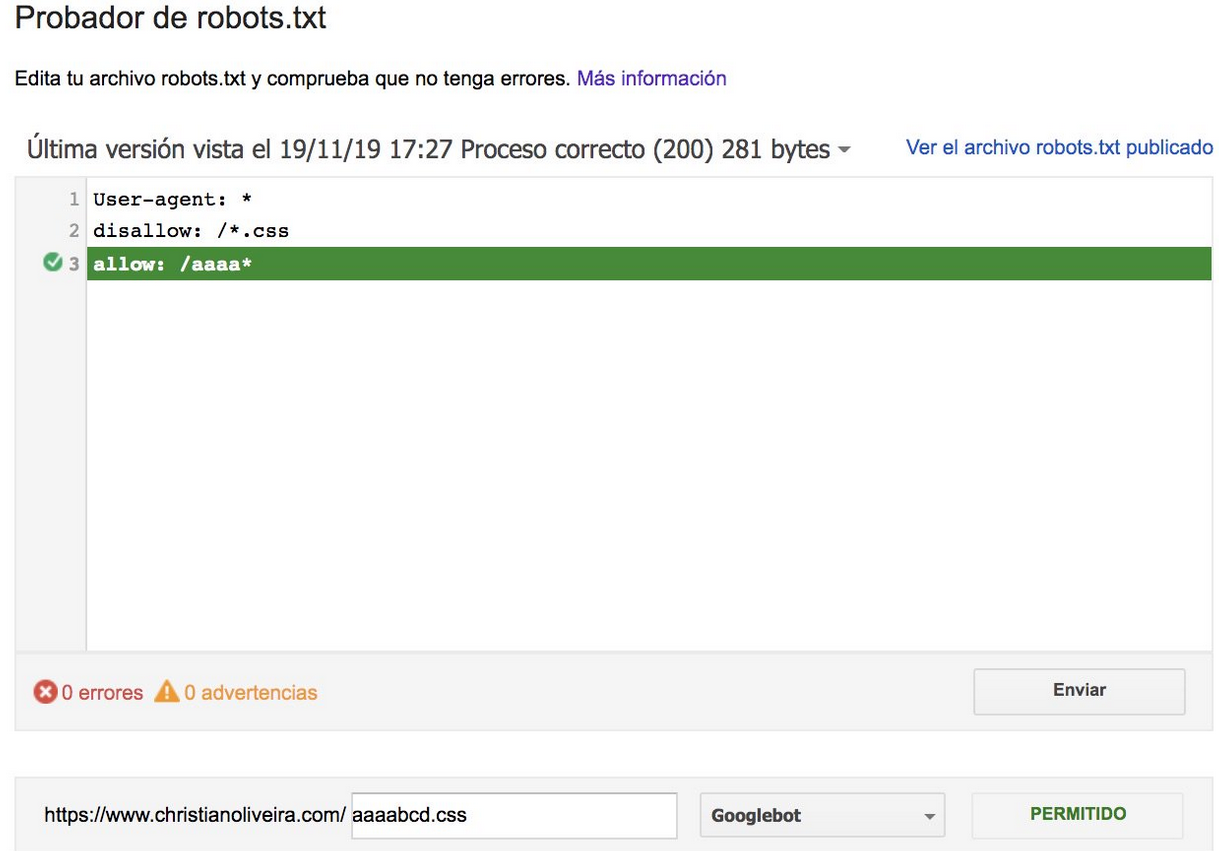
Weitere Beispiele finden Sie in den von Google bereitgestellten robots.txt-Spezifikationen.
Tools zum Testen Ihrer Robots.txt
Wenn Sie Ihre robots.txt-Datei testen möchten, gibt es mehrere Tools, die Ihnen helfen können, und auch ein paar Github-Repositories, wenn Sie Ihre eigene erstellen möchten:
- Destilliert
- Google hat das robots.txt-Tester-Tool aus der alten Google Search Console hier gelassen
- Auf Python
- Auf C++
Beispielergebnisse: effektive Nutzung einer Robots.txt für E-Commerce
Unten habe ich einen Fall aufgeführt, in dem wir mit einer Magento-Site gearbeitet haben, die keine robots.txt-Datei hatte. Magento und andere CMS haben Admin-Seiten und Verzeichnisse mit Dateien, die Google nicht crawlen soll. Unten haben wir ein Beispiel für einige der Verzeichnisse eingefügt, die wir in die robots.txt eingefügt haben:
# # Allgemeine Magento-Verzeichnisse Nicht zulassen: / app / Nicht zulassen: / downloader / Nicht zulassen: / Fehler / Nicht zulassen: / enthält / Nicht zulassen: / lib / Nicht zulassen: / pkginfo / Nicht zulassen: / Shell / Nicht zulassen: / var / # # Indizieren Sie nicht die Suchseite und nicht optimierte Linkkategorien Nicht zulassen: /catalog/product_compare/ Nicht zulassen: /catalog/category/view/ Nicht zulassen: /catalog/product/view/ Nicht zulassen: /catalog/product/gallery/ Nicht zulassen: /catalogsearch/
Die riesige Menge an Seiten, die nicht gecrawlt werden sollten, wirkte sich auf ihr Crawling-Budget aus und der Googlebot konnte nicht alle Produktseiten auf der Website crawlen.
Auf dem Bild unten können Sie sehen, wie die indexierten Seiten nach dem 25. Oktober gestiegen sind, als die robots.txt-Datei implementiert wurde:
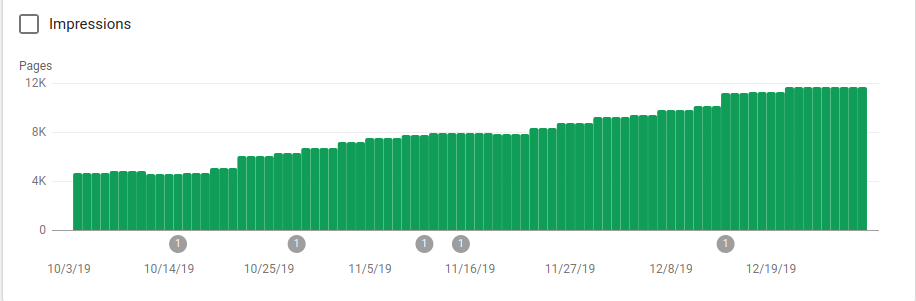
Neben dem Blockieren mehrerer Verzeichnisse, die nicht gecrawlt werden sollten, enthielten die Roboter einen Link zu den Sitemaps. Auf dem Screenshot unten können Sie sehen, wie die Anzahl der indexierten Seiten im Vergleich zu den ausgeschlossenen Seiten gestiegen ist:
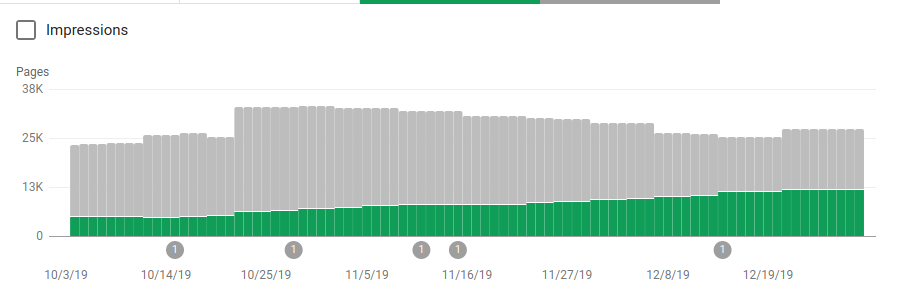
Es gibt einen positiven Trend auf indizierten gültigen Seiten, wie durch die grünen Balken dargestellt, und einen negativen Trend auf den ausgeschlossenen Seiten, dargestellt durch die grauen Balken.
Einpacken
Die Bedeutung von robots.txt kann manchmal unterschätzt werden und wie Sie diesem Beitrag entnehmen können, gibt es viele Details, die bei der Erstellung berücksichtigt werden müssen. Aber die Arbeit zahlt sich aus: Ich habe einige der positiven Ergebnisse gezeigt, die Sie erzielen können, wenn Sie eine robots.txt richtig einrichten.