
Warum wir auf serverloses Computing umgestiegen sind, um benutzerdefinierte Builds bereitzustellen
Veröffentlicht: 2018-11-22
Foto von panumas nikhomkhai von Pexels
Als Teil unseres Engagements, Leistungsvermarkter in die Lage zu versetzen, mehr zu tun, mit weniger, sorgenfrei , suchen die Teams von TUNE ständig nach neuen Wegen, um unsere Kunden zu bedienen. In diesem Fall entdeckte unser Solutions Engineering-Team eine Technologie, die die Bereitstellung und Unterstützung benutzerdefinierter Builds auf unserer Plattform vereinfacht. Infolgedessen können sie jetzt mehr Zeit (und weniger Geld) aufwenden, um mit mehr Kunden zusammenzuarbeiten, um die Lösungen zu entwickeln, die sie benötigen.
Wir bei TUNE sind stolz darauf, eine flexible, umfassende Performance-Marketing-Plattform bereitzustellen, die es Netzwerken und Werbetreibenden ermöglicht, ihre digitalen Marketingkampagnen, Publisher-Beziehungen, Auszahlungen und mehr zu verwalten – sofort einsatzbereit, ohne eine einzige Codezeile schreiben zu müssen . Aber manchmal, wie bei anderen vollständig verwalteten SaaS-Systemen, benötigen unsere Kunden benutzerdefinierte Konfigurationen, Funktionen oder Integrationen, die nur erreicht werden können, indem wir die Ärmel hochkrempeln und den alten Code-Editor starten. Vor kurzem haben wir auf eine neue Technologie umgestellt, die die Art und Weise verändert, wie wir diese Lösungen erstellen: Serverless Computing.
In diesem Beitrag werde ich die Probleme durchgehen, auf die wir bei der benutzerdefinierten Entwicklung gestoßen sind, die Schritte, die wir unternommen haben, um unseren serverlosen Build-Prozess einzurichten, und wie diese neue Methodik die Herausforderungen von Kosten und Umfang löst.
Herausforderung: Mit der Nachfrage nach kundenspezifischen Lösungen Schritt halten
Als wir das Solutions Engineering-Team bei TUNE gegründet haben, behandelten wir jeden kundenspezifischen Build als separaten Build. Die meisten dieser Builds hatten eine Front-End-Komponente, die normalerweise als benutzerdefinierte Seite auf unserer Plattform bereitgestellt wurde, und eine Back-End-Komponente, die aus einem Server, einer Datenbank und jeder anderen Infrastruktur bestand, die erforderlich war, um die Server auf dem neuesten Stand zu halten -Datum und betriebsbereit.
Anfangs hat diese Methode für uns funktioniert. Da wir ein kleines, schlankes Team mit einigen komplexen benutzerdefinierten Builds haben, hat unsere Methode, für jeden Build einen anderen Server bereitzustellen und zu konfigurieren, für uns funktioniert. Es ermöglichte uns, erstaunliche Erlebnisse für unsere Kunden zu schaffen.
Aber als die Anzahl der Builds zunahm, fingen wir an, auf Probleme zu stoßen:
- Zu viele Server! Wie Sie sich vorstellen können, führte die Bereitstellung von mindestens zwei Boxen pro Build dazu, dass wir zu viele Server hatten. Die schiere Anzahl der Server und all die damit verbundenen Probleme (wie Sicherheitsupdates und Backups) haben uns mehr Zeit gekostet, als wir zugeben möchten.
- Halten Sie diese Server in Betrieb. Da jeder Server eine eigene Einheit ist, waren wir dafür verantwortlich sicherzustellen, dass jeder Server immer aktiv und betriebsbereit war.
- PHP ist nichts für mich. Die meisten unserer Builds basieren auf einem Basis-Docker-PHP-Image. Aber als unser Team wuchs, wussten wir, dass es keinen Sinn machte, Leute zu zwingen, ihre Kunden-Builds in PHP 5.0 zu schreiben, wenn sie ein Python-Experte waren.
- Das wird teuer. Da alle unsere Server auf ec2/RDS bereitgestellt wurden, sahen wir allmählich erhebliche monatliche Kosten.
- Sicherheit zuerst. Da diese Dienste vertrauliche Kundendaten verarbeiteten, mussten wir eine Authentifizierungsmethode für unsere öffentlichen URLs bereitstellen, um die Sicherheit dieser Daten zu gewährleisten.
- Crons sind hart. Viele Back-End-Dienste bestanden aus Cron-Skripten, und wir hatten keine effiziente Möglichkeit, diese zu verwalten.
Angesichts dieser Herausforderungen wussten wir, dass wir einen einfacheren und kostengünstigeren Weg finden mussten, um unseren Kunden-Builds Back-End-Funktionalität bereitzustellen. Aber nach vielen Diskussionen und ohne klaren Vorreiter für eine Lösung gingen uns allmählich die Ideen aus. (Außerdem war die Zeit definitiv nicht auf unserer Seite, da die Nachfrage nach neuen kundenspezifischen Builds wie verrückt wuchs.)
Lösung: Serverless Computing zur Rettung
Wenn Sie noch nie von Serverless Computing gehört haben, fragen Sie sich vielleicht dasselbe wie wir, als wir zum ersten Mal davon hörten. Wie können Sie Code ohne Server ausführen? (Keine Sorge; Ihr grundlegendes Verständnis von Programmierung ist immer noch richtig, und nein, wir haben das Happy-Hour-Special nicht missbraucht, bevor wir dies geschrieben haben.)
„Serverless“ ist ein wirklich verwirrender Begriff für eine neue Technologie, denn – seien wir nicht albern – es gibt definitiv immer noch einen Server, der Code ausführt. Was genau ist serverlos?
Serverless Computing ist ein Cloud-Computing- Ausführungsmodell, bei dem der Cloud-Anbieter als Server fungiert und die Zuweisung von Maschinenressourcen dynamisch verwaltet. – Wikipedia
Serverlose Cloud-Lösungen ermöglichen es Ihnen, Anwendungen und Dienste zu erstellen und auszuführen, ohne sich Gedanken über die mit Servern verbundenen Probleme machen zu müssen. Im Wesentlichen ermöglicht Serverless Computing Ihnen, das zu tun, was Sie am besten können: Code schreiben.
Der serverlose Einrichtungsprozess
Um Ihnen das Wesentliche der serverlosen Technologie zu zeigen, gehe ich die Schritte durch, mit denen wir diese Funktionalität eingerichtet haben.
Hinweis: Es gibt viele Cloud-Anbieter mit serverloser Funktionalität. In diesem Beispiel verwenden wir AWS Lambda .
- Erstellen Sie zunächst eine neue Lambda-Funktion und wählen Sie „ Blueprints “ aus. Geben Sie dann „ http “ in das Schlüsselwortfeld ein und wählen Sie entweder Python oder Node microservice-http-endpoint aus. (Blueprints sind vorgefertigte Codeblöcke, die die Entwicklung beschleunigen sollen. Wie großartig ist das denn?) Wenn Sie eine Auswahl getroffen haben, klicken Sie auf „ Konfigurieren “.
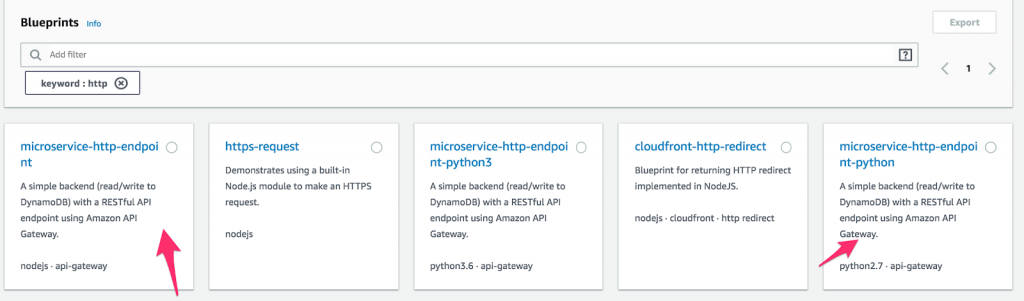
So konfigurieren Sie eine Funktion auf AWS Lambda.

- Fügen Sie einen Funktionsnamen und eine Rolle hinzu. Wählen Sie dann einen API-Gateway - Trigger mit der Sicherheitsoption „ Mit API-Schlüssel öffnen “ aus. Dieses API-Gateway stellt eine öffentliche URL bereit, die Ihre Lambda-Funktion auslöst. Das Hinzufügen des API-Schlüssels bietet eine Authentifizierungsmethode, die dringend empfohlen wird.
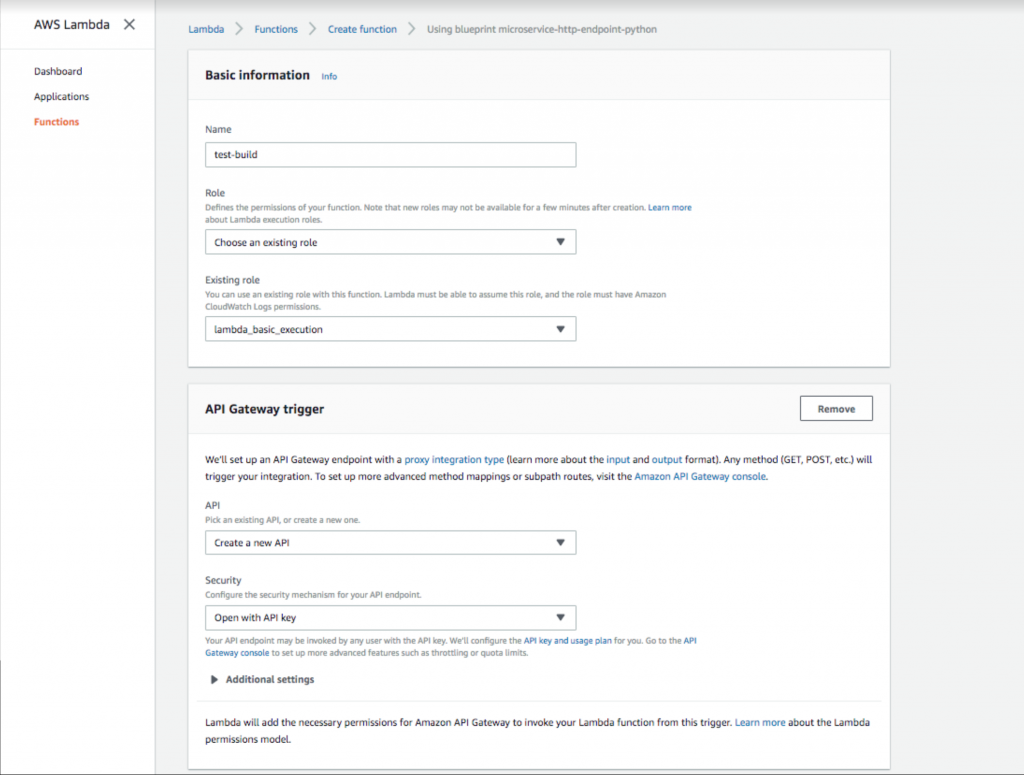
Einrichten eines offenen API-Gateway-Schlüssels in AWS Lambda.
- Nachdem Sie die Funktion erstellt haben, können Sie nun Konfigurationen an Ihrem Code vornehmen. Wie Sie sehen können, hat Ihnen die Blaupause bereits einen coolen Einstiegspunkt-Hook gegeben, der es Ihnen ermöglicht, mit einer Dynamo-Tabelle zu interagieren (wenn Sie eine Datenbank hinzufügen möchten). Alles, was sich unter dem lambda_handler befindet, wird ausgeführt, wenn die öffentliche URL geladen wird. Da wir auch eine Datenbank hinzufügen, gehen wir zu Dynamo und erstellen eine.
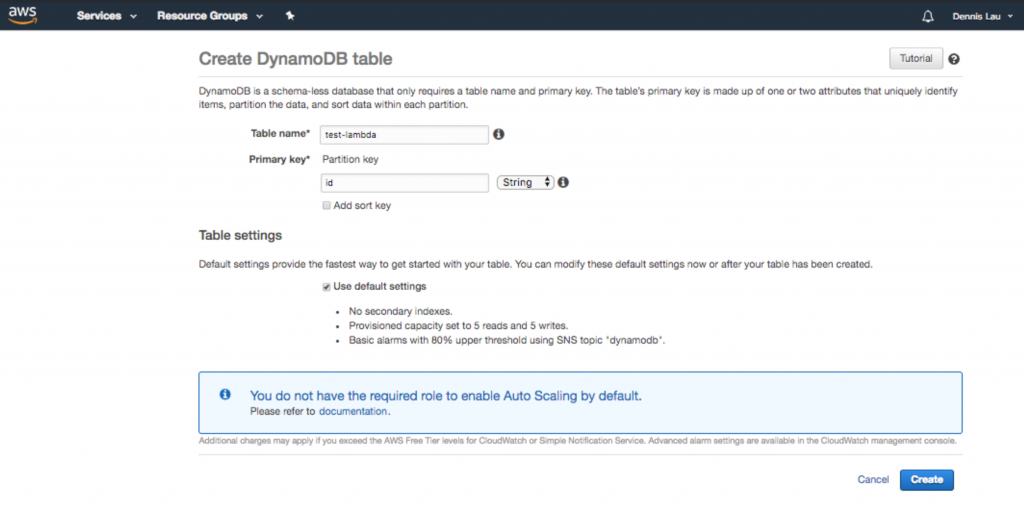
Erstellen einer Dynamo-Datenbanktabelle in AWS Lambda.
- Sobald die Dynamo-Tabelle erstellt ist, rufen wir diese Lambda-Funktion von einer öffentlichen URL aus auf. Gehen Sie zurück zu Ihrer Funktion und klicken Sie oben auf das Symbol „ API Gateway “. Sie sollten sehen, dass der Endpunkt und der API-Schlüssel bereits für Sie erstellt wurden.
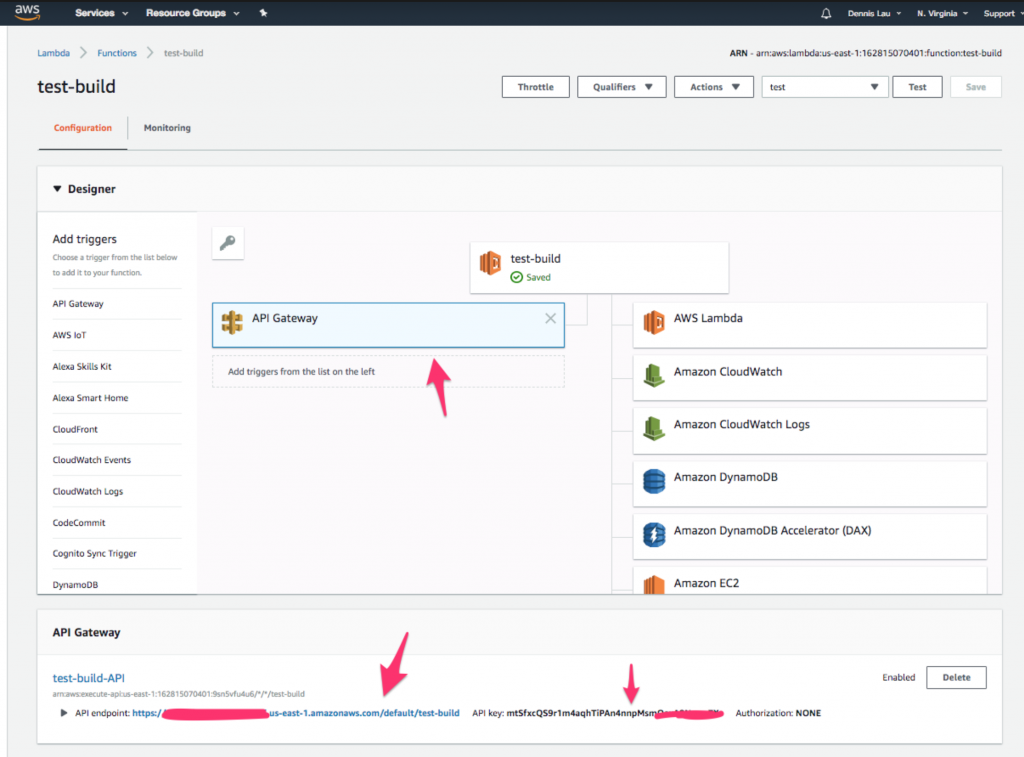
Wo Sie das API Gateway-Symbol in AWS Lambda-Funktionen finden.
- Öffnen Sie nun das Terminal und fügen Sie den API-Schlüssel unter der Überschrift „ x-api-key“ hinzu, und fügen Sie dann den von Ihnen erstellten Tabellennamen unter dem Abfragezeichenfolgenparameter TableName hinzu .

Geben Sie zum Abschluss Ihren Schlüssel und den Datenbanknamen im Terminal ein.
- Erstellen Sie zunächst eine neue Lambda-Funktion und wählen Sie „ Blueprints “ aus. Geben Sie dann „ http “ in das Schlüsselwortfeld ein und wählen Sie entweder Python oder Node microservice-http-endpoint aus. (Blueprints sind vorgefertigte Codeblöcke, die die Entwicklung beschleunigen sollen. Wie großartig ist das denn?) Wenn Sie eine Auswahl getroffen haben, klicken Sie auf „ Konfigurieren “.
Das ist es! Sie haben jetzt ein funktionierendes, sicheres Backend, das mit einer Datenbank verbunden ist. Alles, was es brauchte, waren fünf einfache Schritte.
Wie Serverless Computing unsere Herausforderungen angegangen ist
Nachdem wir Ihnen nun gezeigt haben, wie Sie serverlose Builds einrichten, werfen wir einen Blick darauf, wie dieses Cloud-basierte Modell im Vergleich zu unserer Checkliste von Problemen abschneidet.
- Zu viele Server! Serverlos … bedeutet keine Server mehr, richtig?
- Halten Sie diese Server in Betrieb. Da Serverless Computing vom Cloud-Anbieter verwaltet wird, haben Sie den Vorteil, dass diese Anbieter (zusammen mit ihren kampferprobten, bewährten Methoden) Ihre Server überwachen. Für diejenigen unter Ihnen, die Sherlock Holmes spielen möchten, können Sie auch alle Serverprotokolle sehen, die von Ihrer Funktion auf Cloudwatch ausgegeben werden .
- PHP ist nichts für mich. Mit serverlosen Modellen können Sie in C#, Python, NodeJS, Go und sogar Java schreiben.
- Das wird teuer. Bei serverlosen Lösungen werden die Kosten basierend auf der Ausführungszeit (pro 100 Millisekunden) und der übertragenen Datenmenge gemessen. Im Gegensatz zur monatlichen Zahlung, die die Leerlaufzeit Ihrer Server umfasst, zahlen Sie nur für das, was Sie nutzen. Mit Kosten von nur 0,000000208 $ pro 100 ms Ausführung können Sie mit serverlosem Computing einen erheblichen Teil des Geldes sparen.
- Sicherheit zuerst. Ist Serverless sicher? Mit einem integrierten API-Schlüsselauthentifizierungssystem können Sie darauf wetten.
- Crons sind hart. Mit einem Cron-Verwaltungssystem, das nativ auf Cloudwatch aufgebaut ist, legen Sie einfach ein Zeitfenster fest und vergessen Sie es. Cloudwatch übernimmt die gesamte Protokollierung und Ausführung.
Abschließende Gedanken
Für das Solutions Engineering-Team hier bei TUNE war die Umstellung auf serverloses Computing ein Wendepunkt. Seine Benutzerfreundlichkeit, Kosteneinsparungen und agilen Funktionen haben die Art und Weise verändert, wie wir mit allen neuen Kunden-Builds umgehen. Serverlose Cloud-basierte Lösungen werden die Welt des Server-Side-Computing verändern. Ich weiß nicht, wie es Ihnen geht, aber eines ist sicher: Das Team von TUNE Solutions Engineering ist bereit.
Um mehr über die TUNE-Plattform und die von uns angebotenen kundenspezifischen Entwicklungsdienste zu erfahren, besuchen Sie unsere Seite Professional Services .