
Semantisches Keyword-Clustering in Python
Veröffentlicht: 2021-04-19In einer Welt voller digitaler Marketingmythen glauben wir, dass wir praktische Lösungen für alltägliche Probleme finden müssen.
Bei PEMAVOR teilen wir immer unser Fachwissen und Wissen, um die Bedürfnisse von Enthusiasten des digitalen Marketings zu erfüllen. Daher posten wir oft kostenlose Python-Skripte, um Ihnen zu helfen, Ihren ROI zu steigern.
Unser SEO Keyword Clustering mit Python hat den Weg geebnet, mit nur weniger als 50 Zeilen Python-Code neue Erkenntnisse für große SEO-Projekte zu gewinnen.
Die Idee hinter diesem Skript war es, Ihnen zu ermöglichen, Keywords zu gruppieren, ohne „übertriebene Gebühren“ zu zahlen, um … nun, wir wissen, wer …
Aber wir haben festgestellt, dass dieses Skript allein nicht ausreicht. Es wird ein weiteres Skript benötigt, damit Sie Ihre Schlüsselwörter besser verstehen können: Sie müssen in der Lage sein, Schlüsselwörter nach Bedeutung und semantischen Beziehungen zu gruppieren. ”
Jetzt ist es an der Zeit, Python für SEO einen Schritt weiter zu bringen.
Oncrawl-Daten³
 Mehr erfahren
Mehr erfahrenDie traditionelle Art des semantischen Clusterings
Wie Sie wissen, besteht die traditionelle Methode für Semantik darin, word2vec-Modelle aufzubauen und dann Schlüsselwörter mit Word Mover's Distance zu gruppieren.
Aber diese Modelle erfordern viel Zeit und Mühe, um sie zu bauen und zu trainieren. Deshalb möchten wir Ihnen eine einfachere Lösung anbieten. 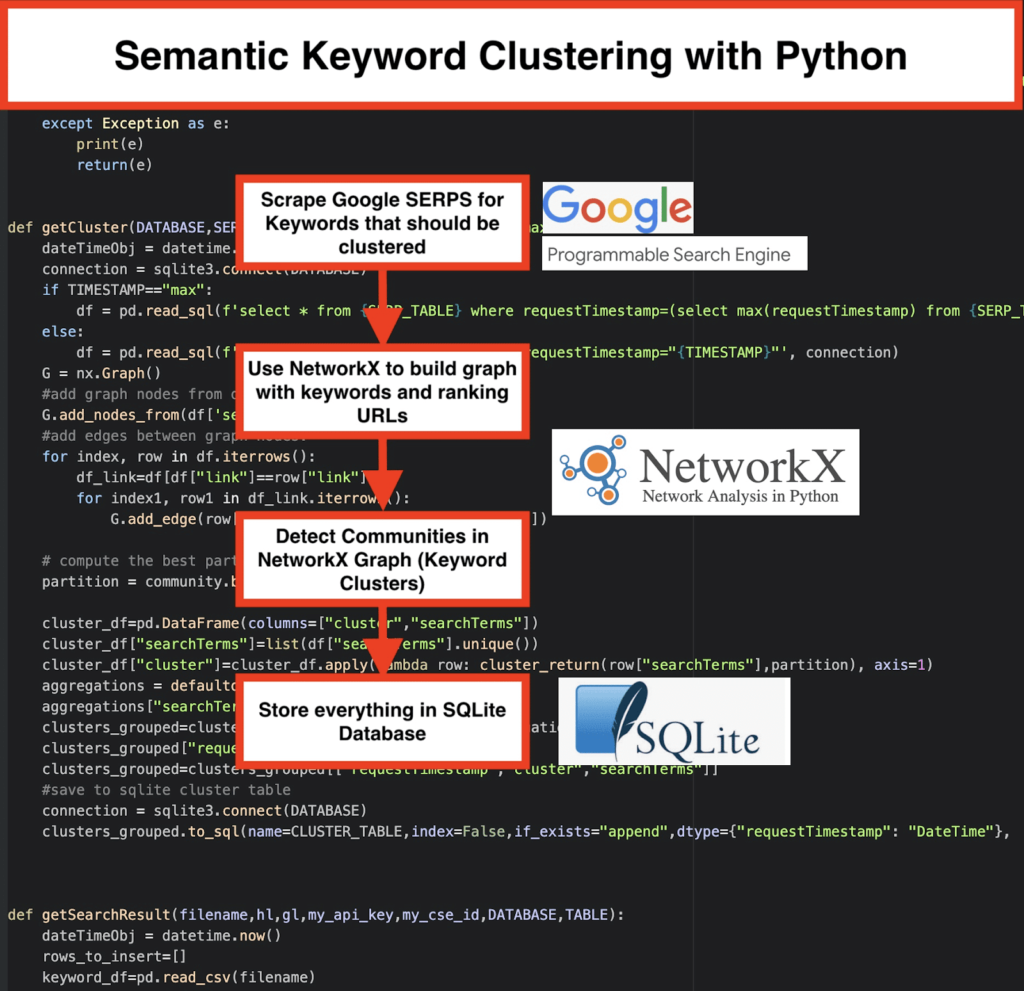
Google SERP-Ergebnisse und Entdeckung der Semantik
Google verwendet NLP-Modelle, um die besten Suchergebnisse anzubieten. Es ist wie die Büchse der Pandora, die geöffnet werden muss, und wir wissen es nicht genau.
Anstatt unsere Modelle zu erstellen, können wir dieses Feld jedoch verwenden, um Schlüsselwörter nach ihrer Semantik und Bedeutung zu gruppieren.
So machen wir es:
️ Erstellen Sie zunächst eine Liste mit Schlüsselwörtern für ein Thema.
️ Kratzen Sie dann die SERP-Daten für jedes Keyword.
️ Als nächstes wird ein Diagramm mit der Beziehung zwischen rankenden Seiten und Schlüsselwörtern erstellt .
️ Solange dieselben Seiten für unterschiedliche Keywords ranken, bedeutet dies, dass sie miteinander verwandt sind. Dies ist das Kernprinzip hinter der Erstellung semantischer Keyword-Cluster.
Zeit, alles in Python zusammenzufügen
Das Python-Skript bietet die folgenden Funktionen:
- Laden Sie die SERPs für die Keyword-Liste herunter, indem Sie die benutzerdefinierte Suchmaschine von Google verwenden. Die Daten werden in einer SQLite-Datenbank gespeichert . Hier sollten Sie eine benutzerdefinierte Such-API einrichten.
- Dann nutzen Sie das kostenlose Kontingent von 100 Anfragen täglich. Aber sie bieten auch einen kostenpflichtigen Plan für 5 US-Dollar pro 1000 Quests an, wenn Sie nicht warten möchten oder wenn Sie große Datensätze haben.
- Es ist besser, sich für die SQLite-Lösungen zu entscheiden, wenn Sie es nicht eilig haben – SERP-Ergebnisse werden bei jedem Durchlauf an die Tabelle angehängt. (Nehmen Sie einfach eine neue Serie von 100 Keywords, wenn Sie am nächsten Tag wieder ein Kontingent haben.)
- In der Zwischenzeit müssen Sie diese Variablen im Python-Skript einrichten.
- CSV_FILE="keywords.csv" => speichern Sie hier Ihre Keywords
- SPRACHE = „en“
- LAND = „de“
- API_KEY=" xxxxxxx"
- CSE_ID="xxxxxxx"
- Durch Ausführen
getSearchResult(CSV_FILE,LANGUAGE,COUNTRY,API_KEY,CSE_ID,DATABASE,SERP_TABLE)werden die SERP-Ergebnisse in die Datenbank geschrieben. - Das Clustering wird von networkx und dem Community-Erkennungsmodul durchgeführt. Die Daten werden aus der SQLite-Datenbank geholt – das Clustering wird aufgerufen mit
getCluster(DATABASE,SERP_TABLE,CLUSTER_TABLE,TIMESTAMP) - Die Clustering-Ergebnisse finden Sie in der SQLite-Tabelle – solange Sie nichts ändern, lautet der Name standardmäßig „keyword_clusters“.
Unten sehen Sie den vollständigen Code:
# Semantisches Keyword-Clustering von Pemavor.com # Autor: Stefan Neefischer ([email protected]) aus googleapiclient.discovery import build pandas als pd importieren Levenshtein importieren from datetime import datetime von fuzzywuzzy import fuzz aus urllib.parse import urlparse aus tld import get_tld träge importieren json importieren pandas als pd importieren importiere numpy als np import networkx als nx Gemeinschaft importieren SQLite3 importieren Mathematik importieren importieren io aus Sammlungen import defaultdict def cluster_return(Suchbegriff,Partition): Rückgabepartition[Suchbegriff] def Spracherkennung (str_lan): lan=langid.classify(str_lan) rückkehrlan[0] def extract_domain(url, remove_http=True): uri = urlparse(url) wenn remove_http: domain_name = f"{uri.netloc}" anders: domain_name = f"{uri.netloc}://{uri.netloc}" Domänenname zurückgeben def_extract_mainDomain(url): res = get_tld(url, as_object=True) Rücklauf res.fld def fuzzy_ratio(str1,str2): return fuzz.ratio(str1,str2) def fuzzy_token_set_ratio(str1,str2): Rückgabe fuzz.token_set_ratio(str1,str2) def google_search(search_term, api_key, cse_id,hl,gl, **kwargs): Versuchen: service = build("customsearch", "v1", developerKey=api_key,cache_discovery=False) res = service.cse().list(q=search_term,hl=hl,gl=gl,fields='queries(request(totalResults,searchTerms,hl,gl)),items(title,displayLink,link,snippet)' ,num=10, cx=cse_id, **kwargs).execute() Rückgabe res außer Ausnahme wie z. B.: drucken Rückkehr (e) def google_search_default_language(Suchbegriff, api_key, cse_id,gl, **kwargs): Versuchen: service = build("customsearch", "v1", developerKey=api_key,cache_discovery=False) res = service.cse().list(q=search_term,gl=gl,fields='queries(request(totalResults,searchTerms,hl,gl)),items(title,displayLink,link,snippet)',num=10 , cx=cse_id, **kwargs).execute() Rückgabe res außer Ausnahme wie z. B.: drucken Rückkehr (e) def getCluster(DATABASE,SERP_TABLE,CLUSTER_TABLE,TIMESTAMP="max"): dateTimeObj = datetime.now() Verbindung = sqlite3.connect (DATENBANK) if TIMESTAMP=="max": df = pd.read_sql(f'select * from {SERP_TABLE} where requestTimestamp=(select max(requestTimestamp) from {SERP_TABLE})', connection) anders: df = pd.read_sql(f'select * from {SERP_TABLE} where requestTimestamp="{TIMESTAMP}"', connection) G = nx.Graph() #Grafikknoten aus der Datenrahmenspalte hinzufügen G.add_nodes_from(df['searchTerms']) #Kanten zwischen Graphknoten hinzufügen: für Index, Zeile in df.iterrows(): df_link=df[df["link"]==row["link"]] für index1, row1 in df_link.iterrows(): G.add_edge(row["searchTerms"], row1['searchTerms']) # Berechnen Sie die beste Partition für die Community (Cluster) partition = community.beste_partition(G) cluster_df=pd.DataFrame(columns=["cluster","searchTerms"]) cluster_df["Suchbegriffe"]=Liste(df["Suchbegriffe"].unique()) cluster_df["cluster"]=cluster_df.apply(lambda row: cluster_return(row["searchTerms"],partition), axis=1) Aggregationen = defaultdict() aggregations["searchTerms"]=' | '.beitreten clusters_grouped=cluster_df.groupby("cluster").agg(aggregations).reset_index() clusters_grouped["requestTimestamp"]=dateTimeObj clusters_grouped=clusters_grouped[["requestTimestamp","cluster","searchTerms"]] #in SQLite-Cluster-Tabelle speichern Verbindung = sqlite3.connect (DATENBANK) clusters_grouped.to_sql(name=CLUSTER_TABLE,index=False,if_exists="append",dtype={"requestTimestamp": "DateTime"}, con=connection) def getSearchResult(filename,hl,gl,my_api_key,my_cse_id,DATABASE,TABLE): dateTimeObj = datetime.now() rows_to_insert=[] keyword_df=pd.read_csv(Dateiname) keywords=keyword_df.iloc[:,0].tolist() für Abfrage in Stichworten: if hl=="Standard": result = google_search_default_language(query, my_api_key, my_cse_id,gl) anders: result = google_search(query, my_api_key, my_cse_id,hl,gl) if "items" im result und "queries" im result : for position in range(0,len(result["items"])): result["items"][position]["position"]=position+1 result["items"][position]["main_domain"]= extract_mainDomain(result["items"][position]["link"]) result["items"][position]["title_matchScore_token"]=fuzzy_token_set_ratio(result["items"][position]["title"],query) result["items"][position]["snippet_matchScore_token"]=fuzzy_token_set_ratio(result["items"][position]["snippet"],query) result["items"][position]["title_matchScore_order"]=fuzzy_ratio(result["items"][position]["title"],query) result["items"][position]["snippet_matchScore_order"]=fuzzy_ratio(result["items"][position]["snippet"],query) result["items"][position]["snipped_language"]=language_detection(result["items"][position]["snippet"]) for position in range(0,len(result["items"])): rows_to_insert.append({"requestTimestamp":dateTimeObj,"searchTerms":query,"gl":gl,"hl":hl, "totalResults":result["queries"]["request"][0]["totalResults"],"link":result["items"][position]["link"], "displayLink":result["items"][position]["displayLink"],"main_domain":result["items"][position]["main_domain"], "position":result["items"][position]["position"],"snippet":result["items"][position]["snippet"], "snipped_language":result["items"][position]["snipped_language"],"snippet_matchScore_order":result["items"][position]["snippet_matchScore_order"], "snippet_matchScore_token":result["items"][position]["snippet_matchScore_token"],"title":result["items"][position]["title"], "title_matchScore_order":result["items"][position]["title_matchScore_order"],"title_matchScore_token":result["items"][position]["title_matchScore_token"], }) df=pd.DataFrame(rows_to_insert) #serp-Ergebnisse in der SQLite-Datenbank speichern Verbindung = sqlite3.connect (DATENBANK) df.to_sql(name=TABLE,index=False,if_exists="append",dtype={"requestTimestamp": "DateTime"}, con=connection) ################################################## ################################################## ########################################## #Liesmich: # ################################################## ################################################## ########################################## #1- Sie müssen eine benutzerdefinierte Google-Suchmaschine einrichten. # # Bitte geben Sie den API Key und die SearchId an. # # Legen Sie auch Ihr Land und Ihre Sprache fest, in denen Sie die SERP-Ergebnisse überwachen möchten. # # Wenn Sie noch keinen API-Schlüssel und keine Such-ID haben, # # Sie können den Schritten im Abschnitt "Voraussetzungen" auf dieser Seite folgen https://developers.google.com/custom-search/v1/overview#prerequisites # # # #2- Sie müssen auch Datenbank-, Serp-Tabellen- und Cluster-Tabellennamen eingeben, die zum Speichern von Ergebnissen verwendet werden sollen. # # # #3- Geben Sie den Namen der CSV-Datei oder den vollständigen Pfad ein, der Schlüsselwörter enthält, die für Serp verwendet werden # # # #4- Geben Sie für das Keyword-Clustering den Zeitstempel für die Serp-Ergebnisse ein, die für das Clustering verwendet werden. # # Wenn Sie die letzten Serp-Ergebnisse gruppieren müssen, geben Sie "max" als Zeitstempel ein. # # oder Sie können einen bestimmten Zeitstempel wie "2021-02-18 17:18:05.195321" eingeben # # # #5- Durchsuchen Sie die Ergebnisse über den DB-Browser nach dem Sqlite-Programm # ################################################## ################################################## ########################################## #csv-Dateiname mit Schlüsselwörtern für serp CSV_FILE="Schlüsselwörter.csv" # Sprache bestimmen SPRACHE = "en" #stadt bestimmen LAND = "de" #JSON-API-Schlüssel für die benutzerdefinierte Google-Suche API_KEY="SCHLÜSSEL HIER EINGEBEN" #Suchmaschinen-ID CSE_ #sqlite-Datenbankname DATABASE="Schlüsselwörter.db" #table name, um Serp-Ergebnisse darin zu speichern SERP_TABLE="keywords_serps" # Führen Sie serp für Schlüsselwörter aus getSearchResult(CSV_FILE,LANGUAGE,COUNTRY,API_KEY,CSE_ID,DATABASE,SERP_TABLE) #Tabellenname, in dem die Clusterergebnisse gespeichert werden. CLUSTER_TABLE="keyword_clusters" #Bitte geben Sie den Zeitstempel ein, wenn Sie Cluster für einen bestimmten Zeitstempel erstellen möchten #Wenn Sie Cluster für das letzte Serp-Ergebnis erstellen müssen, senden Sie es mit dem Wert "max". #TIMESTAMP="2021-02-18 17:18:05.195321" TIMESTAMP="max" # Führen Sie Keyword-Cluster gemäß Netzwerken und Community-Algorithmen aus getCluster(DATABASE,SERP_TABLE,CLUSTER_TABLE,TIMESTAMP)

Google SERP-Ergebnisse und Entdeckung der Semantik
Wir hoffen, dass Ihnen dieses Skript mit seiner Verknüpfung zum Gruppieren Ihrer Schlüsselwörter in semantischen Clustern gefallen hat, ohne sich auf semantische Modelle zu verlassen. Da diese Modelle oft sowohl komplex als auch teuer sind, ist es wichtig, nach anderen Wegen zu suchen, um Schlüsselwörter mit gemeinsamen semantischen Eigenschaften zu identifizieren.
Durch die gemeinsame Behandlung semantisch verwandter Keywords können Sie ein Thema besser abdecken, die Artikel auf Ihrer Seite besser miteinander verlinken und den Rang Ihrer Website für ein bestimmtes Thema erhöhen.