
Den Abdeckungsbericht der Search Console verstehen
Veröffentlicht: 2019-08-15Einführung in den Abdeckungsbericht und wie die Daten zu interpretieren sind
Der Bericht zur Abdeckung durch die Search Console enthält Informationen darüber, welche Seiten Ihrer Website indexiert wurden, und listet URLs auf, bei denen Probleme aufgetreten sind, während der Googlebot versucht, sie zu crawlen und zu indexieren.
Die Hauptseite im Abdeckungsbericht zeigt die URLs Ihrer Website gruppiert nach Status:
- Fehler: Die Seite ist nicht indexiert. Dafür gibt es mehrere Gründe, unter anderem Seiten, die mit 404 antworten, weiche 404-Seiten.
- Gültig mit Warnungen: Die Seite ist indexiert, hat aber Probleme.
- Gültig: Die Seite ist indexiert.
- Ausgeschlossen: Die Seite ist nicht indexiert, Google befolgt Regeln auf der Website wie Noindex-Tags in der robots.txt oder Meta-Tags, Canonical-Tags usw., die verhindern, dass die Seiten indexiert werden.
Dieser Abdeckungsbericht enthält viel mehr Informationen als die alte Google-Suchkonsole. Google hat die Daten, die es teilt, wirklich verbessert, aber es gibt noch einige Dinge, die verbessert werden müssen.
Wie Sie unten sehen können, zeigt Google ein Diagramm mit der Anzahl der URLs in jeder Kategorie. Wenn es eine plötzliche Zunahme von Fehlern gibt, können Sie die Balken sehen und dies sogar mit Impressionen korrelieren, um festzustellen, ob eine Zunahme von URLs mit Fehlern oder Warnungen die Impressionen verringern kann.

Nachdem eine Website gestartet oder neue Abschnitte erstellt wurden, möchten Sie eine zunehmende Anzahl gültiger indizierter Seiten sehen. Es dauert ein paar Tage, bis Google neue Seiten indexiert, aber Sie können das URL-Inspektionstool verwenden, um die Indexierung anzufordern und die Zeit zu verkürzen, die Google benötigt, um Ihre neue Seite zu finden.

Wenn Sie jedoch eine abnehmende Anzahl gültiger URLs oder plötzliche Spitzen feststellen, ist es wichtig, die URLs im Abschnitt „Fehler“ zu identifizieren und die im Bericht aufgeführten Probleme zu beheben. Google bietet eine gute Zusammenfassung von Aktionspunkten, die auszuführen sind, wenn Fehler oder Warnungen zunehmen.
Google gibt Auskunft darüber, was die Fehler sind und wie viele URLs dieses Problem haben:

Denken Sie daran, dass die Google Search Console keine 100 % genauen Informationen anzeigt. Tatsächlich gab es mehrere Berichte über Fehler und Datenanomalien. Darüber hinaus braucht die Google Search Console Zeit zum Aktualisieren, es ist bekannt, dass die Daten 16 Tage bis 20 Tage im Rückstand sind. Außerdem zeigt der Bericht manchmal mehr als 1000 Seiten in Fehler- oder Warnkategorien an, wie Sie im Bild oben sehen können, aber er erlaubt Ihnen nur, ein Beispiel von 1000 URLs anzuzeigen und herunterzuladen, damit Sie es prüfen und überprüfen können.
Nichtsdestotrotz ist dies ein großartiges Tool, um Indexierungsprobleme auf Ihrer Website zu finden:
Wenn Sie auf einen bestimmten Fehler klicken, können Sie die Detailseite sehen, die Beispiele für URLs auflistet:

Wie Sie auf dem obigen Bild sehen können, ist dies die Detailseite für alle URLs, die mit 404 antworten. Jeder Bericht hat einen „Weitere Informationen“-Link, der Sie zu einer Google-Dokumentationsseite mit Details zu diesem spezifischen Fehler führt. Google stellt auch eine Grafik zur Verfügung, die die Anzahl der betroffenen Seiten im Zeitverlauf zeigt.
Sie können auf jede URL klicken, um die URL zu überprüfen, die der alten Funktion „Als Googlebot abrufen“ aus der alten Google Search Console ähnelt. Sie können auch testen, ob die Seite von Ihrer robots.txt blockiert wird
Nachdem Sie URLs korrigiert haben, können Sie Google bitten, sie zu validieren, damit der Fehler aus Ihrem Bericht verschwindet. Sie sollten die Behebung von Problemen mit dem Validierungsstatus „Fehlgeschlagen“ oder „Nicht gestartet“ priorisieren.
Es ist wichtig zu erwähnen, dass Sie nicht erwarten sollten, dass alle URLs auf Ihrer Website indexiert werden. Google gibt an, dass das Ziel des Webmasters darin bestehen sollte, alle kanonischen URLs indexiert zu bekommen. Doppelte oder alternative Seiten werden als ausgeschlossen kategorisiert, da sie ähnliche Inhalte wie die kanonische Seite haben.
Es ist normal, dass Websites mehrere Seiten in der ausgeschlossenen Kategorie enthalten. Die meisten Websites haben mehrere Seiten ohne Index-Meta-Tags oder werden durch die robots.txt blockiert. Wenn Google eine doppelte oder alternative Seite identifiziert, sollten Sie sicherstellen, dass diese Seiten ein kanonisches Tag haben, das auf die richtige URL verweist, und versuchen, das kanonische Äquivalent in der gültigen Kategorie zu finden.
Google hat oben links im Bericht einen Dropdown-Filter eingefügt, sodass Sie den Bericht nach allen bekannten Seiten, allen eingereichten Seiten oder URLs in einer bestimmten Sitemap filtern können. Der Standardbericht enthält alle bekannten Seiten, einschließlich aller von Google entdeckten URLs. Alle eingereichten Seiten enthalten alle URLs, die Sie über eine Sitemap gemeldet haben. Wenn Sie mehrere Sitemaps eingereicht haben, können Sie in jeder Sitemap nach URLs filtern.
[Fallstudie] Erhöhen Sie das Crawl-Budget auf strategischen Seiten
 Lesen Sie die Fallstudie
Lesen Sie die FallstudieFehler, Warnungen, gültige und ausgeschlossene URLs
Fehler
- Serverfehler (5xx): Der Server hat einen 500-Fehler zurückgegeben, als der Googlebot versuchte, die Seite zu crawlen.
- Weiterleitungsfehler: Beim Crawlen der URL durch den Googlebot ist ein Weiterleitungsfehler aufgetreten, entweder weil die Kette zu lang war, eine Weiterleitungsschleife vorhanden war, die URL die maximale URL-Länge überschritten hatte oder die Weiterleitungskette eine fehlerhafte oder leere URL enthielt.
- Eingesendete URL von robots.txt blockiert: Die URLs in dieser Liste werden von Ihrer robts.txt-Datei blockiert.
- Eingereichte URL mit der Kennzeichnung „noindex“: Die URLs in dieser Liste haben ein „noindex“-Tag oder einen HTTP-Header von Meta-Robotern.
- Die übermittelte URL scheint ein Soft 404 zu sein: Ein Soft 404-Fehler tritt auf, wenn eine Seite, die nicht existiert (entfernt oder umgeleitet wurde), dem Benutzer die Meldung „Seite nicht gefunden“ anzeigt, aber keinen HTTP 404-Statuscode zurückgibt. Weiche 404-Fehler treten auch auf, wenn Seiten auf nicht relevante Seiten umgeleitet werden, z. B. eine Seite, die auf die Startseite umgeleitet wird, anstatt einen 404-Statuscode zurückzugeben oder auf eine relevante Seite umzuleiten.
- Gesendete URL gibt nicht autorisierte Anfrage zurück (401): Die zur Indexierung übermittelte Seite gibt eine nicht autorisierte HTTP-Antwort 401 zurück.
- Eingereichte URL nicht gefunden (404): Die Seite hat mit einem 404 Not Found-Fehler geantwortet, als der Googlebot versucht hat, die Seite zu crawlen.
- Crawling-Problem bei eingereichter URL: Der Googlebot hat beim Crawlen dieser Seiten einen Crawling-Fehler festgestellt, der in keine der anderen Kategorien fällt. Sie müssen jede URL überprüfen und feststellen, was das Problem gewesen sein könnte.
Warnung
- Indexiert, obwohl von robots.txt blockiert: Die Seite wurde indexiert, weil der Googlebot über externe Links darauf zugegriffen hat, die auf die Seite verweisen, die Seite wird jedoch von Ihrer robots.txt blockiert. Google markiert diese URLs als Warnungen, da sie sich nicht sicher sind, ob die Seite tatsächlich für die Anzeige in den Suchergebnissen blockiert werden sollte. Wenn Sie eine Seite blockieren möchten, sollten Sie ein „noindex“-Meta-Tag oder einen noindex-HTTP-Antwortheader verwenden.
Wenn Google Recht hat und die URL fälschlicherweise blockiert wurde, sollten Sie Ihre robots.txt-Datei aktualisieren, damit Google die Seite crawlen kann.
Gültig
- Eingereicht und indexiert: URLs, die Sie Google über die sitemap.xml zur Indexierung übermittelt haben und die indexiert wurden.
- Indexiert, nicht in Sitemap eingereicht: Die URL wurde von Google entdeckt und indexiert, aber nicht in Ihre Sitemap aufgenommen. Es wird empfohlen, Ihre Sitemap zu aktualisieren und jede Seite einzubeziehen, die Google crawlen und indexieren soll.
Ausgeschlossen
- Ausgeschlossen durch „noindex“-Tag: Als Google versuchte, die Seite zu indizieren, fand es ein „noindex“-Meta-Robots-Tag oder einen HTTP-Header.
- Blockiert durch Tool zum Entfernen von Seiten: Jemand hat eine Anfrage an Google gesendet, diese Seite nicht zu indexieren, indem er die URL-Entfernungsanfrage in der Google Search Console verwendet hat. Wenn Sie möchten, dass diese Seite indexiert wird, melden Sie sich bei der Search Console von Google an und entfernen Sie sie aus der Liste der entfernten Seiten.
- Von robots.txt blockiert: Die robots.txt-Datei enthält eine Zeile, die die URL vom Crawlen ausschließt. Sie können überprüfen, welche Zeile dies tut, indem Sie den robots.txt-Tester verwenden.
- Blockiert wegen nicht autorisierter Anfrage (401): Genau wie in der Fehlerkategorie werden die Seiten hier mit einem 401-HTTP-Header zurückgegeben.
- Crawl-Anomalie: Dies ist eine Art Catch-all-Kategorie, URLs hier antworten entweder mit 4xx- oder 5xx-Antwortcodes; Diese Antwortcodes verhindern die Indexierung der Seite.
- Gecrawlt – derzeit nicht indexiert: Google gibt keinen Grund an, warum die URL nicht indexiert wurde. Sie schlagen vor, die URL erneut zur Indexierung einzureichen. Es ist jedoch wichtig zu überprüfen, ob die Seite dünnen oder doppelten Inhalt hat, auf eine andere Seite kanonisiert ist, eine noindex-Direktive hat, Metriken eine schlechte Benutzererfahrung zeigen, eine hohe Seitenladezeit usw. Es kann mehrere Gründe geben, warum Google möchte die Seite nicht indizieren.
- Entdeckt – derzeit nicht indexiert: Die Seite wurde gefunden, aber Google hat sie nicht in seinen Index aufgenommen. Sie können die URL zur Indexierung einreichen, um den Prozess wie oben erwähnt zu beschleunigen. Google gibt an, dass der typische Grund dafür darin besteht, dass die Website überlastet war und Google den Crawl verschoben hat.
- Alternative Seite mit dem richtigen kanonischen Tag: Google hat diese Seite nicht indexiert, weil sie ein kanonisches Tag hat, das auf eine andere URL verweist. Google hat die kanonische Regel befolgt und die kanonische URL korrekt indexiert. Wenn diese Seite nicht indexiert werden soll, gibt es hier nichts zu korrigieren.
- Duplizieren ohne vom Benutzer ausgewählte kanonische Tags: Google hat Duplikate für die in dieser Kategorie aufgeführten Seiten gefunden und keine verwendet kanonische Tags. Google hat eine andere Version als Canonical Tag ausgewählt. Sie müssen diese Seiten überprüfen und ein kanonisches Tag hinzufügen, das auf die richtige URL verweist.
- Doppelt, Google hat andere kanonische URLs als Benutzer ausgewählt: URLs in dieser Kategorie wurden von Google ohne explizite Crawl-Anfrage entdeckt. Google hat diese über externe Links gefunden und festgestellt, dass es eine andere Seite gibt, die einen besseren Canonical macht. Google hat diese Seiten aus diesem Grund nicht indexiert. Google empfiehlt, diese URLs als Duplikate der kanonischen zu markieren.
- Nicht gefunden (404): Wenn der Googlebot versucht, auf diese Seiten zuzugreifen, antwortet er mit einem 404-Fehler. Google gibt an, dass diese URLs nicht eingereicht wurden, diese URLs wurden über externe Links gefunden, die auf diese URLs verweisen. Es ist eine gute Idee, diese URLs auf ähnliche Seiten umzuleiten, um den Linkwert zu nutzen und sicherzustellen, dass Benutzer auf einer relevanten Seite landen.
- Seite wegen rechtlicher Beschwerde entfernt: Jemand hat diese Seiten aufgrund rechtlicher Probleme, z. B. einer Urheberrechtsverletzung, beanstandet. Gegen die eingereichte Rechtsbeschwerde können Sie hier Einspruch erheben.
- Seite mit Weiterleitung: Diese URLs leiten weiter und werden daher ausgeschlossen.
- Soft 404: Wie oben erklärt, werden diese URLs ausgeschlossen, da sie mit einem 404 antworten sollten. Überprüfen Sie die Seiten und stellen Sie sicher, dass sie mit einem 404-HTTP-Header antworten, wenn sie eine „nicht gefunden“-Meldung haben.
- Doppelte, eingereichte URL nicht als kanonisch ausgewählt: Ähnlich wie bei „Google hat eine andere kanonische URL als der Benutzer ausgewählt“, wurden die URLs in dieser Kategorie jedoch von Ihnen eingereicht. Es ist eine gute Idee, Ihre Sitemaps zu überprüfen und sicherzustellen, dass keine doppelten Seiten enthalten sind.
Verwendung der Daten und Aktionselemente zur Verbesserung der Website
Da ich in einer Agentur arbeite, habe ich Zugriff auf viele verschiedene Websites und deren Berichterstattungsberichte. Ich habe viel Zeit damit verbracht, die Fehler zu analysieren, die Google in den verschiedenen Kategorien meldet.
Es war hilfreich, Probleme mit der Kanonisierung und doppelten Inhalten zu finden, aber manchmal stoßen Sie auf Diskrepanzen wie die von @jroakes gemeldete:

Sieht so aus, als ob Google Search Console > URL-Prüfung > Live-Test alle JS- und CSS-Dateien fälschlicherweise als Crawl erlaubt meldet: Nein: blockiert durch robots.txt. Testen Sie etwa 20 Dateien in 3 Domänen. pic.twitter.com/fM3WAcvK8q
— JR%20Oakes ???? (@jroakes) 16. Juli 2019
AJ Koh schrieb einen großartigen Artikel, kurz nachdem die neue Google Search Console verfügbar wurde, in dem er erklärt, dass der wahre Wert der Daten darin besteht, sie zu verwenden, um ein Bild der Gesundheit für jede Art von Inhalten auf Ihrer Website zu zeichnen:
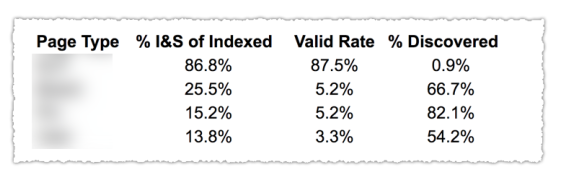
Wie Sie im obigen Bild sehen können, wurden die URLs aus den verschiedenen Kategorien im Abdeckungsbericht nach Seitenvorlage wie Blog, Serviceseite usw. klassifiziert. Die Verwendung mehrerer Sitemaps für verschiedene URL-Typen kann bei dieser Aufgabe hilfreich sein, da Google dies zulässt Sie können Abdeckungsinformationen nach Sitemap filtern. Dann fügte er drei Spalten mit den folgenden Informationen hinzu: % der indizierten und eingereichten Seiten, Gültigkeitsrate und % der entdeckten Seiten.
Diese Tabelle gibt Ihnen wirklich einen großartigen Überblick über den Zustand Ihrer Website. Wenn Sie sich nun mit den verschiedenen Abschnitten befassen möchten, empfehle ich, die Berichte zu überprüfen und die von Google angezeigten Fehler zu überprüfen.
Sie können alle in verschiedenen Kategorien präsentierten URLs herunterladen und OnCrawl verwenden, um ihren HTTP-Status, kanonische Tags usw. zu überprüfen und eine Tabelle wie diese zu erstellen:
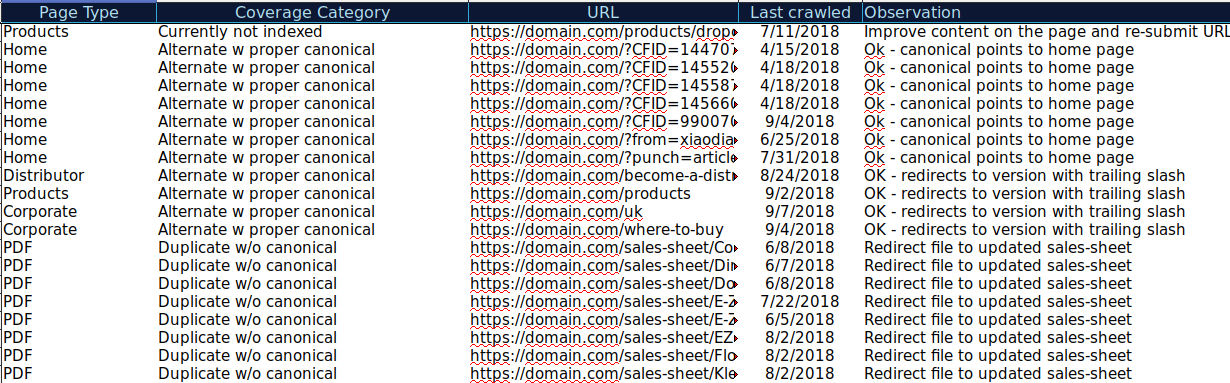
Wenn Sie Ihre Daten auf diese Weise organisieren, können Sie Probleme nachverfolgen und Aktionselemente für URLs hinzufügen, die verbessert oder behoben werden müssen. Außerdem können Sie URLs abhaken, die korrekt sind, und bei URLs mit Parametern mit korrekter kanonischer Tag-Implementierung sind keine Aktionselemente erforderlich.
Starten Sie Ihre kostenlose 14-Tage-Testversion
 Starten Sie Ihre Testversion
Starten Sie Ihre TestversionSie können dieser Tabelle sogar weitere Informationen aus anderen Quellen wie ahrefs, Majestic und Google Analytics mit OnCrawl-Integrationen hinzufügen. Auf diese Weise könnten Sie Linkdaten sowie Verkehrs- und Konversionsdaten für jede der URLs in der Google Search Console extrahieren. All diese Daten können Ihnen dabei helfen, bessere Entscheidungen darüber zu treffen, was für jede Seite zu tun ist. Wenn Sie beispielsweise eine Liste mit Seiten mit 404-Fehlern haben, können Sie diese mit Backlinks verknüpfen, um festzustellen, ob Sie Link-Eigenkapital von verlinkten Domains verlieren defekte Seiten auf Ihrer Website. Oder Sie können indizierte Seiten überprüfen und wie viel organischen Traffic sie erhalten. Sie könnten indizierte Seiten identifizieren, die keinen organischen Traffic erhalten, und daran arbeiten, sie zu optimieren (Verbesserung von Inhalt und Benutzerfreundlichkeit), um mehr Traffic auf diese Seite zu lenken.
Mit diesen zusätzlichen Daten können Sie eine Übersichtstabelle in einer anderen Tabelle erstellen. Sie können die Formel =ZÄHLENWENN(Bereich, Kriterien) verwenden, um die URLs in jedem Seitentyp zu zählen (diese Tabelle kann die Tabelle ergänzen, die AJ Kohn oben vorgeschlagen hat). Sie können auch eine andere Formel verwenden, um Backlinks, Besuche oder Conversions hinzuzufügen, die Sie für jede URL extrahiert haben, und sie in Ihrer Übersichtstabelle mit der folgenden Formel anzeigen =SUMIF (Bereich, Kriterien, [sum_range]). Sie würden so etwas bekommen:
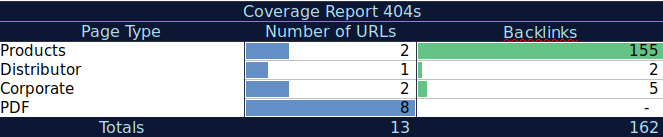
Ich arbeite sehr gerne mit Übersichtstabellen, die mir eine zusammengefasste Ansicht der Daten geben und mir helfen können, die Abschnitte zu identifizieren, auf die ich mich zuerst konzentrieren muss.
Abschließende Gedanken
Folgendes müssen Sie bedenken, wenn Sie an der Behebung von Problemen arbeiten und sich die Daten in diesem Bericht ansehen: Ist meine Website für das Crawlen optimiert? Nehmen meine indizierten und gültigen Seiten zu oder ab? Seiten mit Fehlern nehmen sie zu oder ab? Erlaube ich Google, Zeit mit den URLs zu verbringen, die meinen Nutzern mehr Wert bringen, oder findet es viele wertlose Seiten? Mit den Antworten auf diese Fragen können Sie beginnen, Verbesserungen an Ihrer Website vorzunehmen, sodass der Googlebot sein Crawling-Budget für Seiten ausgeben kann, die Ihren Nutzern einen Mehrwert bieten, anstatt für wertlose Seiten. Sie können Ihre robots.txt verwenden, um die Crawling-Effizienz zu verbessern, wertlose URLs nach Möglichkeit zu entfernen oder kanonische oder noindex-Tags zu verwenden, um doppelte Inhalte zu verhindern.
Google fügt den verschiedenen Berichten in der Google Search Console ständig Funktionalitäten hinzu und aktualisiert die Datengenauigkeit. Wir hoffen also, dass wir weiterhin mehr Daten in jeder der Kategorien im Abdeckungsbericht sowie in anderen Berichten in der Google Search Console sehen werden.