
Quick & Dirty 11-stufiges technisches SEO-Audit für die allgemeine Website-Gesundheit
Veröffentlicht: 2020-02-27Technisches SEO ist wichtig, weil es der Ausgangspunkt eines jeden Projekts ist. Aus der Sicht eines SEO-Experten ist jede Website ein neues Projekt. Eine Website sollte ein solides Fundament haben, um gute Ergebnisse zu erzielen und die wichtigsten KPIs in SEO wie Rankings zu erreichen.
Jedes Mal, wenn ich mit einem neuen Projekt beginne, mache ich als erstes ein technisches SEO-Audit. Meistens kann die Behebung technischer Probleme erstaunliche Ergebnisse erzielen, sobald die Website erneut gecrawlt wird.
Ich finde es komisch, wenn Leute über Content und noch mehr Content reden, aber kein Wort über technisches SEO verlieren. Eines ist sicher, Website Health und Technical SEO sind zwei wichtige Dinge, die im Jahr 2020 von entscheidender Bedeutung sein werden. Ich will nicht sagen, dass Inhalte nicht wichtig sind. Das ist es, aber ohne die technischen Probleme einer Website zu beheben, glaube ich nicht, dass Inhalte Ergebnisse bringen können.
Ich habe Fälle gesehen, in denen wichtige Seiten durch Anweisungen in der robots.txt-Datei blockiert wurden oder die wichtigsten Kategorie- oder Serviceseiten von Meta-Robotern wie noindex, nofollow beschädigt oder blockiert wurden. Wie ist es möglich, erfolgreich zu sein, ohne Prioritäten zu setzen, indem man diese Probleme behebt?
Es kann überraschend sein, die Anzahl von SEOs zu sehen, die nicht wissen, wie sie technische Probleme identifizieren und an Webentwicklungsspezialisten melden sollen, um sie zu beheben. Ich erinnerte mich, als ich einmal im Unternehmensbereich arbeitete, erstellte ich eine Tech-SEO-Audit-Checkliste, die von meinem Team verwendet werden sollte. Damals wurde mir klar, dass ein Quick-Fix-Sheet wie dieses einem Team enorm helfen und einen schnellen Schub für einen Kunden generieren kann. Aus diesem Grund halte ich es für äußerst wichtig, in ein Tool / eine Software zu investieren, die Ihnen bei der technischen SEO-Diagnose und den Empfehlungen helfen kann.
Beginnen wir mit dem praktischen Prozess, wie man ein schnelles Tech-SEO-Audit durchführt, das einen großen Unterschied machen wird. Dies ist eine schnelle Übung, für die Sie etwa eine Stunde benötigen, selbst wenn Sie kein Profi sind. Für mich macht es mir das Leben leichter, ein Tech-SEO-Tool wie OnCrawl zu verwenden, um alle Dinge in fünf Minuten vorzuspulen, ohne die ganze manuelle Arbeit erledigen zu müssen.
Ich werde die wichtigsten Dinge durchgehen, die bei der Durchführung eines technischen SEO-Audits zu überprüfen sind. Es gibt noch mehr Dinge, die wir auf On-Page-Probleme überprüfen können, aber ich möchte mich nur auf Dinge konzentrieren, die Indizierungsprobleme verursachen und Budget verschwenden. Durch diese Priorisierung stellen Sie sicher, dass die wichtigsten Seiten vom Googlebot gecrawlt werden.
- Indexierung
- Robots.txt-Datei
- Meta-Roboter-Tag
- 4xx Fehler
- Sitemaps
- HTTP/HTTPS (Website-Sicherheit, gemischte Inhalte und Probleme mit doppelten Inhalten)
- Seitennummerierung
- 404 Seite
- Site-Tiefe und -Struktur
- Lange Umleitungsketten
- Canonical-Tag-Implementierung
1) Indizierung
Dies ist das erste, was zu überprüfen ist. Oft kann die Indizierung durch eine Plugin-Konfiguration oder einen kleinen Fehler beeinträchtigt werden, aber die Auswirkungen auf die Auffindbarkeit können enorm sein, da heute über 6,16 Milliarden Webseiten indiziert sind. Sie müssen verstehen, dass sich jede Suchmaschine Mühe gibt und sogar Google die relevanteste Seite für die Benutzererfahrung priorisieren muss. Wenn Sie nicht daran denken, Googlebot die Dinge zu erleichtern, wird Ihre Konkurrenz es tun und viel mehr Vertrauen gewinnen, das mit einer gesunden Website einhergeht.
Wenn es Indexierungsprobleme gibt, spiegeln sich die Gesundheitsprobleme Ihrer Website im Verlust des organischen Verkehrs wider. Der Prozess der Indexierung bedeutet, dass eine Suchmaschine eine Webseite durchsucht und die Informationen organisiert, die sie später in SERP anbietet. Die Ergebnisse hängen von der Relevanz für die Benutzerabsicht ab. Wenn eine Webseite nicht crawlen kann oder Probleme damit hat, werden andere Seiten in derselben Nische einen Vorteil haben.
Verwendung von Suchoperatoren zum Beispiel:
Website: www.abc.com
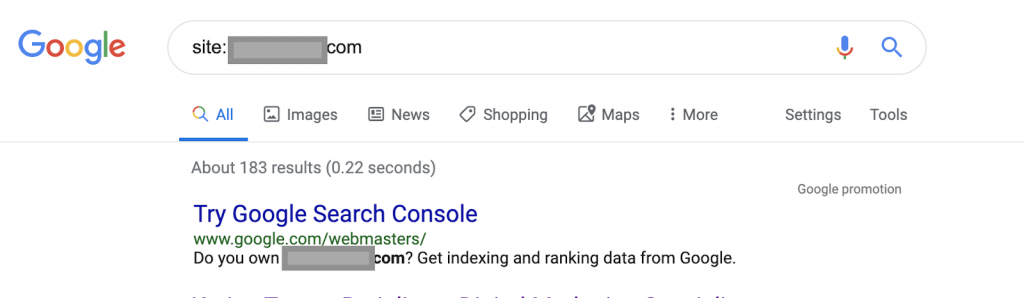
Die Abfrage gibt 183 von Google indexierte Seiten zurück. Dies ist eine grobe Schätzung der Anzahl der Seiten, die Google indexiert hat. Sie können die genaue Zahl in der Google Search Console überprüfen.
Sie sollten auch einen Webcrawler wie OnCrawl verwenden, um alle Seiten aufzulisten, auf die Google Zugriff hat. Dies zeigt eine andere Nummer, wie Sie unten sehen können:
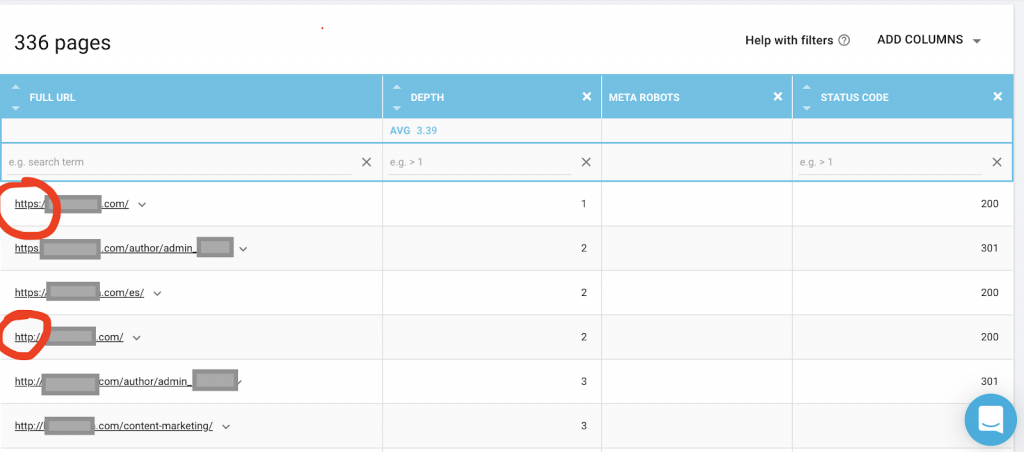
Diese Website hat fast doppelt so viele crawlbare Seiten wie indexierte Seiten.
Dies kann ein Problem mit doppelten Inhalten oder sogar ein Problem mit der Website-Sicherheitsversion zwischen HTTP- und HTTPS-Problem aufdecken. Ich werde später in diesem Artikel darüber sprechen.
In diesem Fall wurde die Website von HTTP auf HTTPS migriert. Wir können in OnCrawl sehen, dass die HTTP-Seiten umgeleitet wurden. Sowohl die HTTP- als auch die HTTPS-Version sind weiterhin für den Googlebot zugänglich, und er kann alle doppelten Seiten crawlen, anstatt die wichtigsten Seiten zu priorisieren, die der Eigentümer ranken möchte, was zu einer Verschwendung von Crawl-Budget führt.
Ein weiteres häufiges Problem bei vernachlässigten Websites oder großen Websites wie E-Commerce-Websites sind Probleme mit gemischten Inhalten. Um es kurz zu machen, die Probleme treten auf, wenn Ihre gesicherte Seite Ressourcen wie Mediendateien (am häufigsten: Bilder) enthält, die aus einer ungesicherten Version geladen werden.
Wie man es repariert:
Sie können einen Webentwickler bitten, alle HTTP-Seiten auf die HTTPS-Version zu zwingen und HTTP-Adressen einmal mit einem 301-Statuscode auf HTTPS umzuleiten.
Bei Problemen mit gemischten Inhalten können Sie die Quelle der Seite manuell überprüfen und nach Ressourcen suchen, die als „src=http://example.com/media/images“ geladen sind, was gerade bei großen Websites fast verrückt ist. Deshalb müssen wir ein technisches SEO-Tool verwenden.
2) Robots.txt-Datei:
Die robots.txt-Datei teilt Crawling-Agenten mit, welche Seiten sie nicht crawlen sollen. Der Robots.txt-Spezifikationsleitfaden gibt an, dass das Dateiformat reiner Text mit einer maximalen Größe von 500 KB sein muss.
Ich empfehle das Hinzufügen der Sitemap zur robots.txt.file. Nicht jeder tut dies, aber ich glaube, es ist eine gute Praxis. Die robots.txt-Datei muss auf Ihrem gehosteten Server in public_html platziert werden und folgt der Root-Domain.
Wir können Anweisungen in der robots.txt-Datei verwenden, um zu verhindern, dass Suchmaschinen unnötige Seiten oder Seiten mit vertraulichen Informationen durchsuchen, z. B. die Admin-Seite, Vorlagen oder den Warenkorb (/cart, /checkout, /login, Ordner wie /tag, die in Blogs verwendet werden). , indem Sie diese Seiten zur robots.txt-Datei hinzufügen.
Hinweis : Stellen Sie sicher, dass Sie den Mediendateiordner nicht blockieren, da dies Ihre Bilder, Videos oder andere selbst gehostete Medien von der Indexierung ausschließt. Medien können sowohl für die Seitenrelevanz als auch für das organische Ranking und den Traffic für Bilder oder Videos sehr wichtig sein.
3) Meta-Robots-Tag
Dies ist ein Stück HTML-Code, der Suchmaschinen anweist, eine Seite mit allen Links auf dieser Seite zu crawlen und zu indizieren. Das HTML-Tag wird in den Kopf Ihrer Webseite eingefügt. Es gibt 4 gängige HTML-Tags für Roboter:
- Nein folgen
- Folgen
- Index
- Kein Index
Wenn keine Meta-Roboter-Tags vorhanden sind, folgen Suchmaschinen standardmäßig dem Inhalt und indizieren ihn.
Sie können jede Kombination verwenden, die Ihren Anforderungen am besten entspricht. Durch die Verwendung von OnCrawl habe ich beispielsweise festgestellt, dass eine „Autorenseite“ dieser Website keine Meta-Roboter enthält. Das bedeutet, dass die Richtung standardmäßig („follow, index“) lautet.
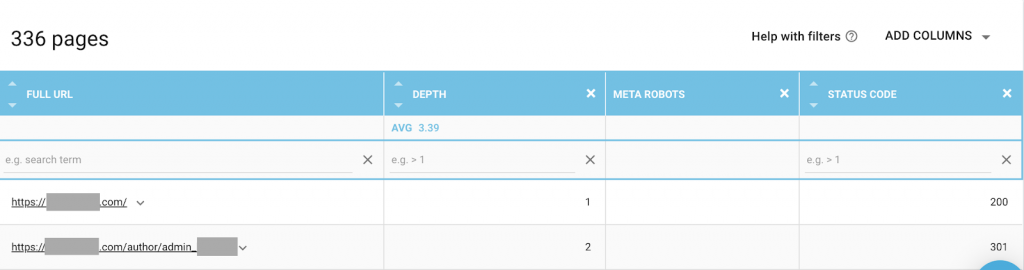
Dieser sollte („noindex, nofollow“) lauten.
Wieso den?
Jeder Fall ist anders, aber diese Website ist ein kleiner persönlicher Blog. Es gibt nur einen Autor, der auf dem Blog veröffentlicht, und die Domain ist der Name des Autors. In diesem Fall bietet die „Autoren“-Seite keine zusätzlichen Informationen, obwohl sie von der Blogging-Plattform generiert werden.
Ein anderes Szenario kann eine Website sein, auf der Kategorien im Blog wichtig sind. Wenn der Eigentümer in seinem Blog nach Kategorien ranken möchte, sollten Meta-Roboter („folgen, indexieren“) oder standardmäßig auf Kategorieseiten sein.
In einem anderen Szenario, für eine große und bekannte Website, auf der große SEO-Experten Artikel schreiben, denen die Community folgt, fungiert der Autorenname in Google als Marke. In diesem Fall möchten Sie wahrscheinlich einige Autorennamen indizieren.
Wie Sie sehen können, können Meta-Roboter auf viele verschiedene Arten verwendet werden.
Wie man es repariert:
Bitten Sie einen Webentwickler, das Meta-Robot-Tag nach Bedarf zu ändern. Im obigen Fall für eine kleine Website kann ich es selbst tun, indem ich zu jeder Seite gehe und sie manuell ändere. Wenn Sie WordPress verwenden, können Sie dies in den RankMath- oder Yoast-Einstellungen ändern.
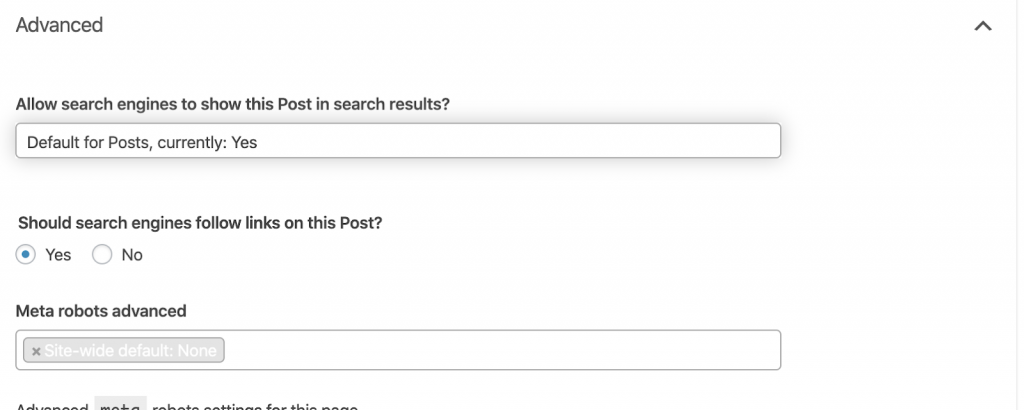
4) 4xx-Fehler:
Dies sind Fehler auf der Clientseite und sie können 401, 403 und 404 sein.
- 404 Seite nicht gefunden:
Dieser Fehler tritt auf, wenn eine Seite unter der indexierten URL-Adresse nicht verfügbar ist. Sie könnte verschoben oder gelöscht worden sein, und die alte Adresse wurde mit der Webserverfunktion 301 nicht ordnungsgemäß umgeleitet. Die 404-Fehler sind eine schlechte Erfahrung für Benutzer und stellen ein technisches SEO-Problem dar, das angegangen werden sollte. Es ist eine gute Sache, häufig nach 404-Fehlern zu suchen und sie zu beheben, und sie nicht immer wieder versuchen zu lassen, damit Crawling-Agenten ihr Budget verschwenden.
Wie man es repariert:
Wir müssen die Adressen finden, die 404-Fehler zurückgeben, und sie mithilfe von 301-Weiterleitungen beheben, wenn der Inhalt noch vorhanden ist. Oder, wenn es sich um Bilder handelt, können sie durch neue ersetzt werden, die den gleichen Dateinamen behalten.
- 401 nicht Autorisiert
Dies ist ein Berechtigungsproblem. Der 401-Fehler tritt normalerweise auf, wenn eine Authentifizierung wie Benutzername und Passwort erforderlich ist.
Wie man es repariert:
Hier sind zwei Optionen: Die erste besteht darin, die Seite mithilfe von robots.txt für Suchmaschinen zu blockieren. Die zweite Option besteht darin, die Authentifizierungsanforderung zu entfernen.
- 403 Verboten
Dieser Fehler ähnelt dem 401-Fehler. Der 403-Fehler tritt auf, weil die Seite Links enthält, die nicht öffentlich zugänglich sind.

Wie man es repariert:
Ändern Sie die Anforderung im Server, um den Zugriff auf die Seite zuzulassen (nur wenn dies ein Fehler ist). Wenn diese Seite nicht zugänglich sein soll, entfernen Sie alle internen und externen Links von der Seite.
- 400 Ungültige Anfrage
Dies tritt auf, wenn der Browser nicht mit dem Webserver kommunizieren kann. Dieser Fehler tritt häufig bei schlechter URL-Syntax auf.
Wie man es repariert:
Finden Sie Links zu diesen URLs und korrigieren Sie die Syntax. Wenn dies nicht behoben werden kann, müssen Sie sich an den Webentwickler wenden, um das Problem zu beheben.
Hinweis: Wir können 400-Fehler mit Tools oder in Google Console finden

5) Sitemaps
Die Sitemap ist eine Liste aller URLs, die die Website enthält. Sitemaps verbessern die Auffindbarkeit, weil sie Crawlern helfen, Ihre Inhalte zu finden und zu verstehen.
Wir haben verschiedene Arten von Sitemaps und müssen sicherstellen, dass sie alle in gutem Zustand sind.
Die Sitemaps, die wir haben sollten, sind:
- HTML-Sitemap: Diese befindet sich auf Ihrer Website und hilft Benutzern beim Navigieren und Auffinden der Seiten auf Ihrer Website
- XML-Sitemap: Dies ist eine Datei, die Suchmaschinen hilft, Ihre Website zu crawlen (als Best Practice sollte sie in Ihre robots.txt-Datei aufgenommen werden).
- XML-Sitemap für Videos: Wie oben.
- Bilder XML-Sitemap: Es ist auch das gleiche wie oben. Es wird empfohlen, separate Sitemaps für Bilder, Videos und Inhalte zu erstellen.
Für große Websites empfiehlt es sich, mehrere Sitemaps für eine bessere Crawlbarkeit zu haben, da Sitemaps nicht mehr als 50.000 URLs enthalten sollten.
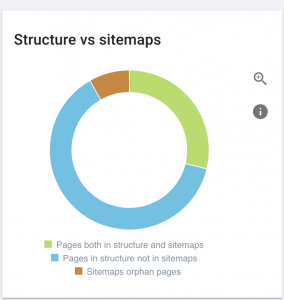
Diese Website hat Sitemap-Probleme.
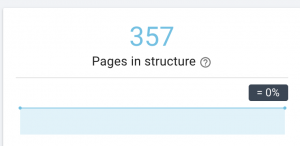
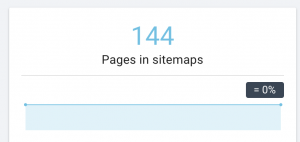
Wie wir es beheben:
Wir beheben dies, indem wir verschiedene Sitemaps generieren für: Inhalte, Bilder und Videos. Dann reichen wir sie über die Google Search Console ein und erstellen auch eine HTML-Sitemap für die Website. Dafür brauchen wir keinen Webentwickler. Wir können jedes kostenlose Online-Tool verwenden, um Sitemaps zu erstellen.
6) HTTP/HTTPS (doppelter Inhalt)
Viele Websites haben diese Probleme als Folge der Migration von HTTP zu HTTPS. Wenn dies der Fall ist, zeigt die Website HTTP- und HTTPS-Versionen in Suchmaschinen an. Als Folge dieses allgemeinen technischen Problems werden die Rankings verwässert. Diese Probleme führen auch zu Duplicate Content-Problemen.
![]()

Wie man es repariert:
Bitten Sie einen Webentwickler, dieses Problem zu beheben, indem Sie alle HTTP auf HTTPS zwingen.
Hinweis : Leiten Sie niemals das gesamte HTTP auf die HTTPS-Homepage um, da dies einen Soft 404-Fehler generiert. (Sie sollten dies dem Webentwickler sagen; denken Sie daran, dass sie keine SEOs sind.)
7) Paginierung
Dies ist die Verwendung eines HTML-Tags („rel = prev“ und „rel = next“), das Beziehungen zwischen Seiten herstellt und Suchmaschinen zeigt, dass Inhalte, die auf verschiedenen Seiten präsentiert werden, identifiziert oder mit einer einzigen verknüpft werden sollten. Die Paginierung wird verwendet, um den Inhalt für UX und das Gewicht einer Seite für den technischen Teil zu begrenzen und sie unter 3 MB zu halten. Wir können ein kostenloses Tool verwenden, um die Paginierung zu überprüfen.
Die Paginierung sollte selbstkanonische Referenzen haben und ein „rel = prev“ und „rel = next“ angeben. Die einzigen doppelten Informationen sind der Meta-Titel und die Meta-Beschreibung, aber dies kann von Entwicklern geändert werden, um einen kleinen Algorithmus zu erstellen, sodass jede Seite einen generierten Meta-Titel und eine Meta-Beschreibung hat.
Wie man es repariert:
Bitten Sie einen Webentwickler, Paginierungs-HTML-Tags mit Self-Canonical-Tag zu implementieren.
Oncrawl SEO-Crawler
 Dekouvrir
Dekouvrir8) Benutzerdefinierte 404-Seite nicht gefunden
Eine 404-Antwort ist, wie wir bereits besprochen haben, ein „ Not Found “-Fehler, der Benutzer zu einem defekten Link oder einer nicht existierenden Seite führt. Dies ist eine Gelegenheit, Benutzer an die richtige Stelle weiterzuleiten. Es gibt großartige Beispiele für benutzerdefinierte 404-Seiten. Dies ist ein Muss.
Hier ist ein Beispiel für eine großartige benutzerdefinierte 404-Seite:

Wie man es repariert:
Erstellen Sie eine benutzerdefinierte 404-Seite: Denken Sie an etwas Erstaunliches, das Sie hinzufügen können. Machen Sie diesen Fehler zu einer Chance für Ihr Unternehmen.
9) Seitentiefe/-struktur
Die Seitentiefe ist die Anzahl der Klicks, die Ihre Seite von der Root-Domain aus gefunden hat. John Mueller von Google sagte, „Seiten, die näher an der Startseite liegen, haben mehr Gewicht“. Stellen wir uns zum Beispiel vor, dass die Seite hier die folgende Navigation erfordert, um erreicht zu werden:

Die Seite „Teppiche“ ist 4 Klicks von der Startseite entfernt. Es wird empfohlen, Seiten nicht mehr als 4 Klicks von der Startseite entfernt zu haben, da Suchmaschinen Schwierigkeiten haben, tiefere Seiten zu crawlen.
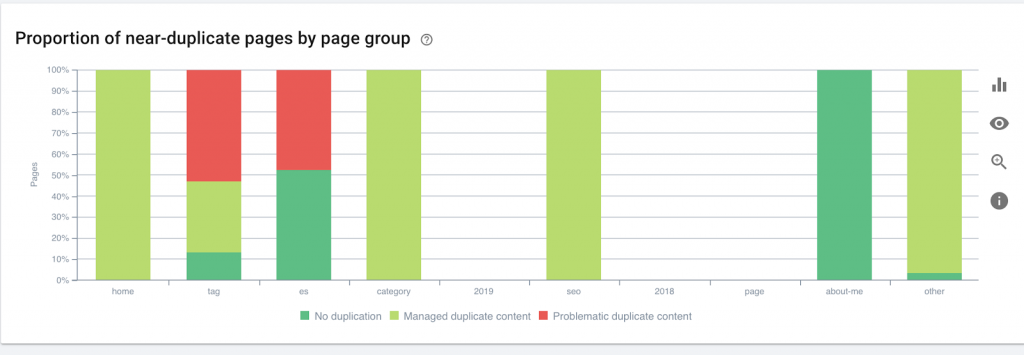
Diese Grafik zeigt die Seitengruppe nach Tiefe. Es hilft uns zu verstehen, ob die Struktur einer Website überarbeitet werden muss.
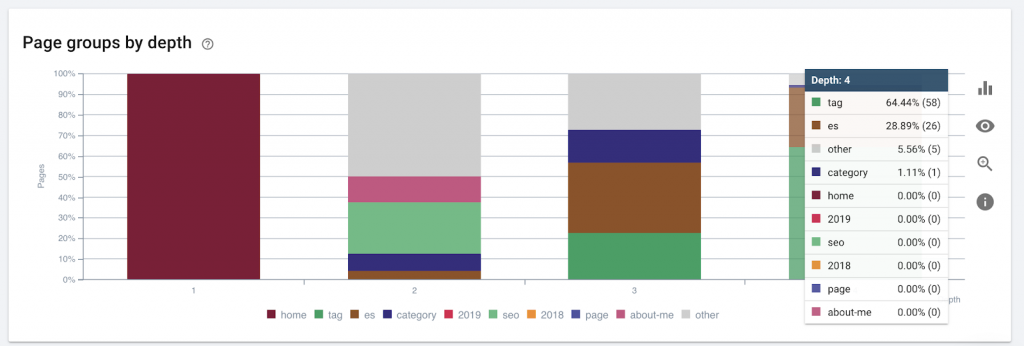
Wie man es repariert:
Die wichtigsten Seiten sollten der Startseite für UX am nächsten sein, um den Benutzern den Zugriff zu erleichtern und die Websitestruktur zu verbessern. Es ist sehr wichtig, dies beim Erstellen einer Website-Struktur oder beim Umstrukturieren einer Website zu berücksichtigen.
10. Weiterleitungsketten
Eine Weiterleitungskette liegt vor, wenn eine Reihe von Weiterleitungen zwischen URLs erfolgt. Diese Umleitungsketten können auch Schleifen erzeugen. Es stellt auch Googlebot vor Probleme und verschwendet das Crawling-Budget.
Wir können Weiterleitungsketten mithilfe der Chrome-Erweiterung Redirect path oder in OnCrawl identifizieren.
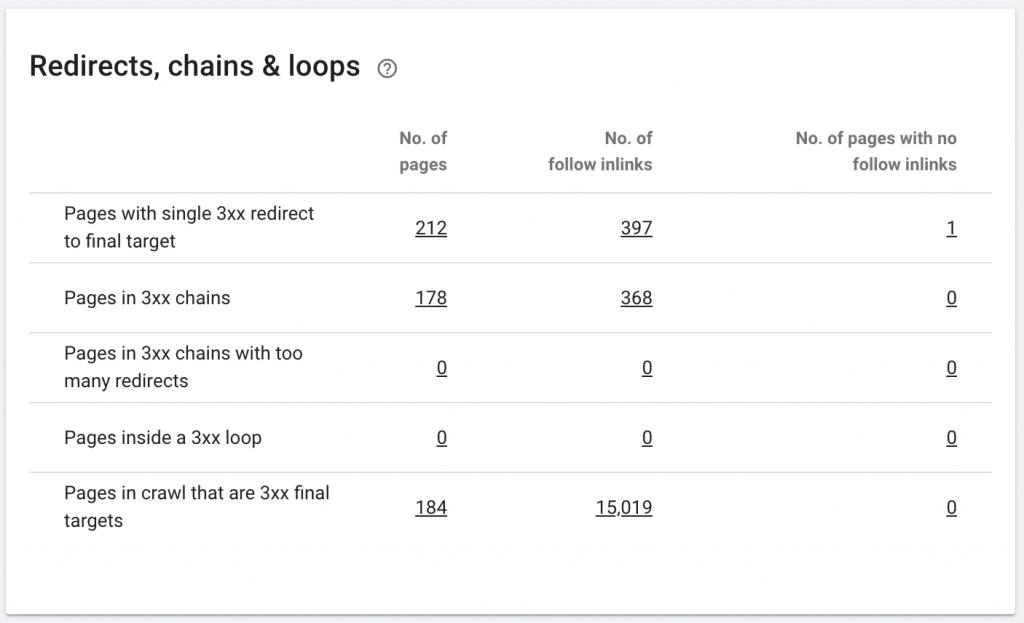
Wie man es repariert:
Dies zu beheben ist wirklich einfach, wenn Sie mit einer WordPress-Website arbeiten. Gehen Sie einfach zur Weiterleitung und suchen Sie nach der Kette. Löschen Sie alle an der Kette beteiligten Links, wenn diese Änderungen mehr als 2-3 Monate zurückliegen, und lassen Sie die letzte Weiterleitung einfach auf die aktuelle URL. Auch Webentwickler können dabei helfen, indem sie bei Bedarf alle erforderlichen Änderungen in der .htaccess-Datei vornehmen. Sie können die langen Weiterleitungsketten in Ihren SEO-Plugins überprüfen und ändern.
11) Kanoniker
Ein Canonical-Tag teilt Suchmaschinen mit, dass die URL eine Kopie einer anderen Seite ist. Dies ist ein großes Problem, das auf vielen Websites vorhanden ist. Wenn Canonicals nicht richtig oder überhaupt nicht implementiert werden, führt dies zu Problemen mit doppelten Inhalten.
Canonicals werden häufig auf E-Commerce-Websites verwendet, auf denen ein Produkt mehrfach in verschiedenen Kategorien wie Größe, Farbe usw. zu finden ist.

Mit OnCrawl können Sie feststellen, ob Ihre Seiten kanonische Tags haben und ob sie korrekt implementiert sind oder nicht. Sie können dann alle Probleme untersuchen und beheben.
Wie wir es beheben:
Wir können kanonische Probleme beheben, indem wir Yoast SEO verwenden, wenn wir in WordPress arbeiten. Wir gehen zum WordPress-Dashboard und dann zu Yoast – Einstellung – Erweitert.
Führen Sie Ihr eigenes Audit durch
SEOs, die in die technische SEO eintauchen möchten, benötigen einen Leitfaden mit schnellen Schritten, um die SEO-Gesundheit zu verbessern. Gespräch über technisches SEO mit John Shehata, dem Vizepräsidenten von Audience Grow bei Conde Nast und Gründer von NewzDash, am Global Marketing Day in NYC im vergangenen Oktober 2019.
Hier ist, was er zu mir sagte:
„Viele Leute in der SEO-Branche sind nicht technisch versiert. Nun, nicht jeder SEO versteht, wie man codiert, und es ist schwer, die Leute dazu zu bringen. Einige Unternehmen stellen Entwickler ein und schulen sie zu SEOs, um die technische SEO-Lücke zu schließen.“
Meiner Meinung nach können SEOs, die nicht über das vollständige Code-Wissen verfügen, bei Tech SEO immer noch großartige Leistungen erbringen, indem sie wissen, wie man ein Audit durchführt, Schlüsselelemente identifiziert, Berichte erstellt, Webentwickler um die Implementierung bittet und schließlich die Änderungen testet.
Bereit anzufangen? Laden Sie die Checkliste für diese Top-Probleme herunter.
