
Bewertung der Qualität von Kausalwirkungsvorhersagen
Veröffentlicht: 2022-02-15CausalImpact ist eines der beliebtesten Pakete, das bei SEO-Experimenten verwendet wird. Seine Popularität ist verständlich.
SEO-Experimente bieten spannende Einblicke und Möglichkeiten für SEOs, über den Wert ihrer Arbeit zu berichten.
Die Genauigkeit eines maschinellen Lernmodells hängt jedoch von den Eingabeinformationen ab, die es erhält.
Einfach ausgedrückt, die falsche Eingabe kann zu einer falschen Schätzung führen.
In diesem Beitrag zeigen wir, wie zuverlässig (und unzuverlässig) CausalImpact sein kann. Wir werden auch lernen, wie Sie mehr Vertrauen in die Ergebnisse Ihrer Experimente gewinnen können.
Zunächst geben wir einen kurzen Überblick über die Funktionsweise von CausalImpact. Anschließend diskutieren wir die Zuverlässigkeit von CausalImpact-Schätzungen. Schließlich lernen wir eine Methodik kennen, mit der Sie die Ergebnisse Ihrer eigenen SEO-Experimente schätzen können.
Was ist CausalImpact und wie funktioniert es?
CausalImpact ist ein Paket, das die Bayes'sche Statistik verwendet, um die Wirkung eines Ereignisses ohne Experiment abzuschätzen. Diese Schätzung wird als kausale Inferenz bezeichnet.
Kausalschlussschätzungen, wenn eine beobachtete Änderung durch ein bestimmtes Ereignis verursacht wurde.
Es wird häufig verwendet, um die Leistung von SEO-Experimenten zu bewerten.
Wenn beispielsweise das Datum eines Ereignisses angegeben wird, verwendet CausalImpact (CI) die Datenpunkte vor der Intervention, um die Datenpunkte nach der Intervention vorherzusagen. Anschließend vergleicht es die Vorhersage mit den beobachteten Daten und schätzt die Differenz mit einem bestimmten Konfidenzschwellenwert.
Darüber hinaus können Kontrollgruppen verwendet werden, um die Vorhersagen genauer zu machen.
Verschiedene Parameter wirken sich auch auf die Genauigkeit der Vorhersage aus:
- Größe der Testdaten.
- Länge des Zeitraums vor dem Experiment.
- Wahl der Kontrollgruppe, mit der verglichen werden soll.
- Hyperparameter der Saisonalität.
- Anzahl der Iterationen.
Alle diese Parameter tragen dazu bei, dem Modell mehr Kontext zu geben und seine Zuverlässigkeit zu verbessern.
Oncrawl-BI
 Entdecken
EntdeckenWarum ist die Bewertung der Genauigkeit von SEO-Experimenten wichtig?
In den vergangenen Jahren habe ich viele SEO-Experimente analysiert und etwas ist mir aufgefallen.
Oft führte die Verwendung unterschiedlicher Kontrollgruppen und Zeitrahmen bei identischen Testsets und Interventionsdaten zu unterschiedlichen Ergebnissen.
Zur Veranschaulichung sind unten zwei Ergebnisse derselben Veranstaltung aufgeführt.
Die erste zeigte einen statistisch signifikanten Rückgang. 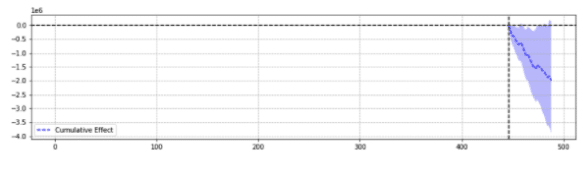
Die zweite war statistisch nicht signifikant. 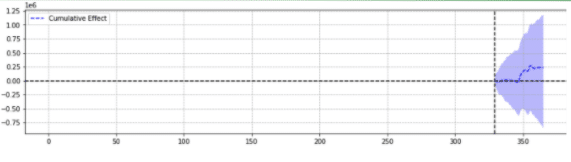
Einfach ausgedrückt, für dasselbe Ereignis wurden basierend auf den ausgewählten Parametern unterschiedliche Ergebnisse zurückgegeben.
Man muss sich fragen, welche Vorhersage richtig ist.
Soll „statistisch signifikant“ nicht am Ende das Vertrauen in unsere Schätzungen stärken?
Definitionen
Um die Welt der SEO-Experimente besser zu verstehen, sollte sich der Leser der Grundkonzepte von SEO-Experimenten bewusst sein:
- Experiment : ein Verfahren, das durchgeführt wird, um eine Hypothese zu testen. Im Falle einer kausalen Inferenz hat sie ein bestimmtes Startdatum.
- Testgruppe : eine Teilmenge der Daten, auf die eine Änderung angewendet wird. Dabei kann es sich um eine ganze Website oder einen Teil der Website handeln.
- Kontrollgruppe : eine Teilmenge der Daten, auf die keine Änderung angewendet wurde. Sie können eine oder mehrere Kontrollgruppen haben. Dies kann ein separater Standort in derselben Branche oder ein anderer Teil derselben Website sein.
Das folgende Beispiel soll diese Konzepte veranschaulichen:
Die Änderung des Titels (Experiment) sollte die organische CTR um 1 % (Hypothese) der Produktseiten in fünf Städten (Testgruppe) erhöhen. Bei allen anderen Städten (Kontrollgruppe) werden die Schätzungen mit unverändertem Titel verbessert.
Säulen der genauen Vorhersage von SEO-Experimenten
- Der Einfachheit halber habe ich ein paar interessante Einblicke für SEO-Profis zusammengestellt, die lernen, wie man die Genauigkeit von Experimenten verbessert:
- Einige Eingaben in CausalImpact geben falsche Schätzungen zurück, selbst wenn sie statistisch signifikant sind. Das nennen wir „Falsch-Positive“ und „Falsch-Negative“.
- Es gibt keine allgemeine Regel, die bestimmt, welches Steuerelement für einen Testsatz verwendet werden soll. Ein Experiment ist erforderlich, um die besten Kontrolldaten für einen bestimmten Testsatz zu definieren.
- Die Verwendung von CausalImpact mit der richtigen Steuerung und der richtigen Länge der Daten vor der Periode kann sehr präzise sein, wobei der durchschnittliche Fehler nur 0,1 % beträgt.
- Alternativ kann die Verwendung von CausalImpact mit der falschen Steuerung zu einer starken Fehlerrate führen. Persönliche Experimente zeigten statistisch signifikante Schwankungen von bis zu 20 %, obwohl es tatsächlich keine Veränderung gab.
- Nicht alles kann getestet werden. Einige Testgruppen geben fast nie genaue Schätzungen zurück.
- Experimente mit oder ohne Kontrollgruppen benötigen vor der Intervention unterschiedliche Datenlängen.
Nicht alle Testgruppen liefern genaue Schätzungen
Einige Testgruppen werden immer ungenaue Vorhersagen zurückgeben. Sie sollten nicht zum Experimentieren verwendet werden.
Testgruppen mit großen anormalen Verkehrsschwankungen geben häufig unzuverlässige Ergebnisse zurück.
Zum Beispiel hatte eine Website im selben Jahr eine Website-Migration, war von einer Covid-Pandemie betroffen und ein Teil der Website war aufgrund eines technischen Fehlers für 2 Wochen „noindexed“. Experimente auf dieser Website führen zu unzuverlässigen Ergebnissen.
Die obigen Erkenntnisse wurden durch eine umfangreiche Reihe von Tests gesammelt, die unter Verwendung der unten beschriebenen Methodik durchgeführt wurden.
Wenn keine Kontrollgruppen verwendet werden
- Die Verwendung eines Steuerelements anstelle eines einfachen Pre-Post kann die Genauigkeit der Schätzung um das bis zu 18-fache erhöhen.
- Die Verwendung von Daten aus 16 Monaten davor war so genau wie die Verwendung von 3 Jahren.
Bei Verwendung von Kontrollgruppen
- Die Verwendung des richtigen Steuerelements ist oft besser als die Verwendung mehrerer Steuerelemente. Ein einziges Steuerelement erhöht jedoch das Risiko einer falschen Vorhersage in Fällen, in denen der Verkehr des Steuerelements stark variiert.
- Die Wahl des richtigen Steuerelements kann die Genauigkeit um das 10-fache erhöhen (z. B. meldet das eine +3,1 % und das andere +4,1 %, obwohl es in Wirklichkeit +3 % waren).
- Die meisten korrelierten Verkehrsmuster zwischen Testdaten und Kontrolldaten bedeuten nicht notwendigerweise bessere Schätzungen.
- Die Verwendung von Daten aus 16 Monaten davor war NICHT so genau wie die Verwendung von 3 Jahren.
Achten Sie vor Experimenten auf die Länge der Daten
Interessanterweise kann beim Experimentieren mit Kontrollgruppen die Verwendung von Daten aus 16 Monaten zuvor eine sehr hohe Fehlerrate verursachen.
Tatsächlich können Fehler so groß sein wie die Schätzung eines 3-fachen Anstiegs des Datenverkehrs, wenn es keine tatsächlichen Änderungen gab.
Durch die Verwendung von Daten aus 3 Jahren wurde diese Fehlerrate jedoch entfernt. Dies steht im Gegensatz zu einfachen Vorher-Nachher-Experimenten, bei denen diese Fehlerrate nicht erhöht wurde, indem die Länge von 16 auf 36 Monate erhöht wurde.
Das bedeutet nicht, dass die Verwendung von Steuerelementen schlecht ist. Ganz im Gegenteil.
Es zeigt einfach, wie sich das Hinzufügen von Kontrolle auf die Vorhersagen auswirkt.

Dies ist der Fall, wenn es große Schwankungen in der Kontrollgruppe gibt.
Dies ist besonders wichtig für Websites, die im vergangenen Jahr ungewöhnliche Traffic-Schwankungen hatten (kritischer technischer Fehler, COVID-Pandemie usw.).
Wie bewertet man die CausalImpact-Vorhersage?
Jetzt gibt es in der CausalImpact-Bibliothek keine Genauigkeitsbewertung. Es muss also auf etwas anderes geschlossen werden.
Man kann sich ansehen, wie andere maschinelle Lernmodelle die Genauigkeit ihrer Vorhersagen schätzen, und erkennen, dass die Summe der Quadratfehler (SSE) eine sehr verbreitete Metrik ist.
Die Quadratsummenfehler oder Residualsumme der Quadrate berechnet die Summe aller (n) Abweichungen zwischen den Erwartungen (yi) und den tatsächlichen Ergebnissen (f(xi)) zum Quadrat. 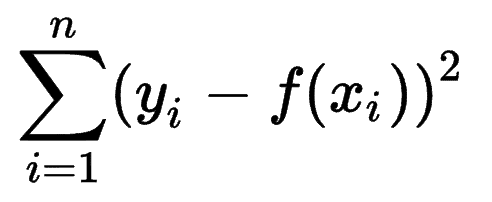
Je niedriger der SSE, desto besser das Ergebnis.
Die Herausforderung besteht darin, dass es bei Pre-Post-Experimenten zum SEO-Traffic keine tatsächlichen Ergebnisse gibt.
Obwohl vor Ort keine Änderungen vorgenommen wurden, können einige Änderungen außerhalb Ihrer Kontrolle stattgefunden haben (z. B. Aktualisierung des Google-Algorithmus, neuer Wettbewerber usw.). Der SEO-Traffic variiert auch nicht um eine feste Zahl, sondern variiert progressiv nach oben und unten.
SEO-Spezialisten fragen sich vielleicht, wie sie die Herausforderung meistern können.
Einführung gefälschter Variationen
Um sicher zu sein, wie groß die durch ein Ereignis verursachte Variation ist, kann der Experimentator feste Variationen zu verschiedenen Zeitpunkten einführen und sehen, ob CausalImpact die Änderung erfolgreich geschätzt hat.
Noch besser, der SEO-Experte kann den Vorgang für verschiedene Test- und Kontrollgruppen wiederholen.
Unter Verwendung von Python wurden zu verschiedenen Interventionsdaten für die Nachperiode feste Variationen in die Daten eingeführt.
Die Summe der Fehlerquadrate wurde dann zwischen der von CausalImpact gemeldeten Variation und der eingeführten Variation geschätzt.
Die Idee geht so:
- Wählen Sie einen Test und Kontrolldaten.
- Führen Sie gefälschte Eingriffe in die realen Daten zu unterschiedlichen Zeitpunkten ein (z. B. 5 % Steigerung).
- Vergleichen Sie die CausalImpact-Schätzungen mit jeder der eingeführten Variationen.
- Berechnen Sie die Summe der Quadratfehler (SSE).
- Wiederholen Sie Schritt 1 mit mehreren Steuerelementen.
- Wählen Sie die Steuerung mit der kleinsten SSE für reale Experimente
Die Methodik
Mit der unten stehenden Methodik habe ich eine Tabelle erstellt, mit der ich feststellen konnte, welche Kontrolle zu verschiedenen Zeitpunkten die besten und schlechtesten Fehlerquoten hatte.
Wählen Sie zunächst Test- und Kontrolldaten aus und führen Sie Variationen von -50 % bis 50 % ein.
Führen Sie dann CausalImpact (CI) aus und subtrahieren Sie die von CI gemeldeten Variationen von der tatsächlich eingeführten Variation.
Berechnen Sie danach die Quadrate dieser Differenzen und summieren Sie alle Werte zusammen.
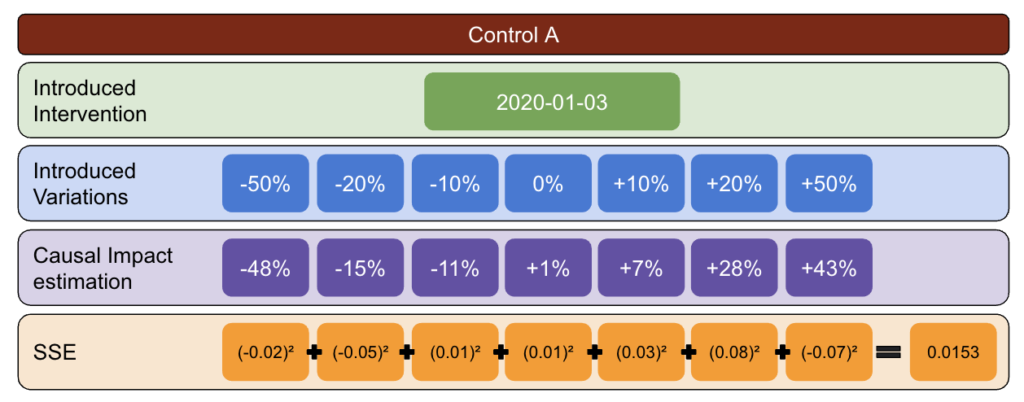
Wiederholen Sie als Nächstes denselben Vorgang an verschiedenen Daten, um das Risiko einer Verzerrung zu verringern, die durch eine tatsächliche Abweichung an einem bestimmten Datum verursacht wird.
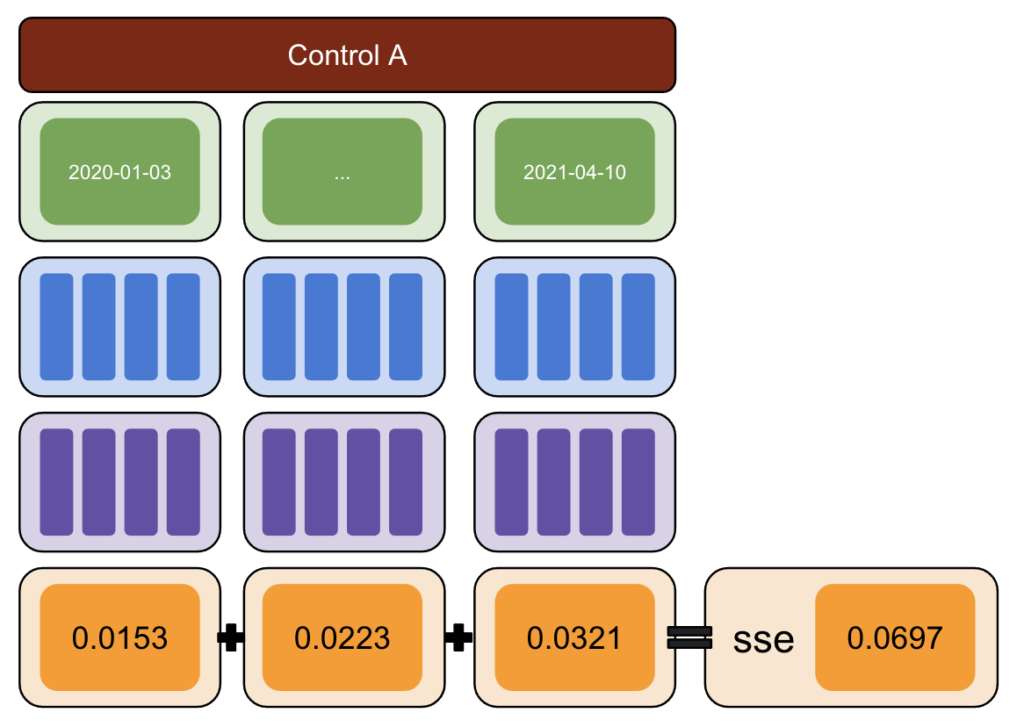
Wiederholen Sie dies erneut mit mehreren Kontrollgruppen.
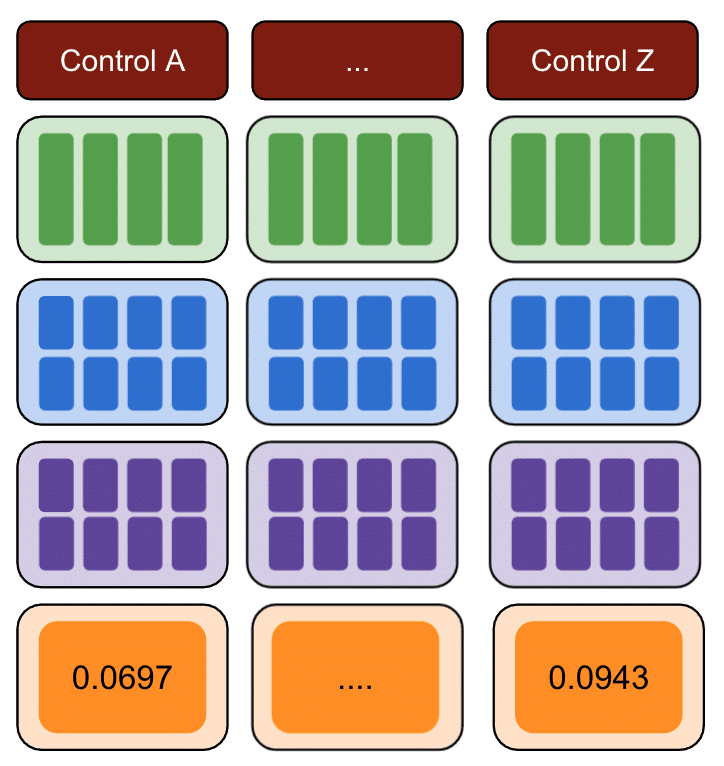
Schließlich ist die Kontrolle mit den kleinsten Quadratsummenfehlern die beste Kontrollgruppe, die Sie für Ihre Testdaten verwenden können.
Wenn Sie jeden der Schritte für alle Ihre Testdaten wiederholen, wird das Ergebnis variieren.
In der resultierenden Tabelle stellt jede Zeile eine Kontrollgruppe dar, jede Spalte eine Testgruppe. Die darin enthaltenen Daten sind die SSE.
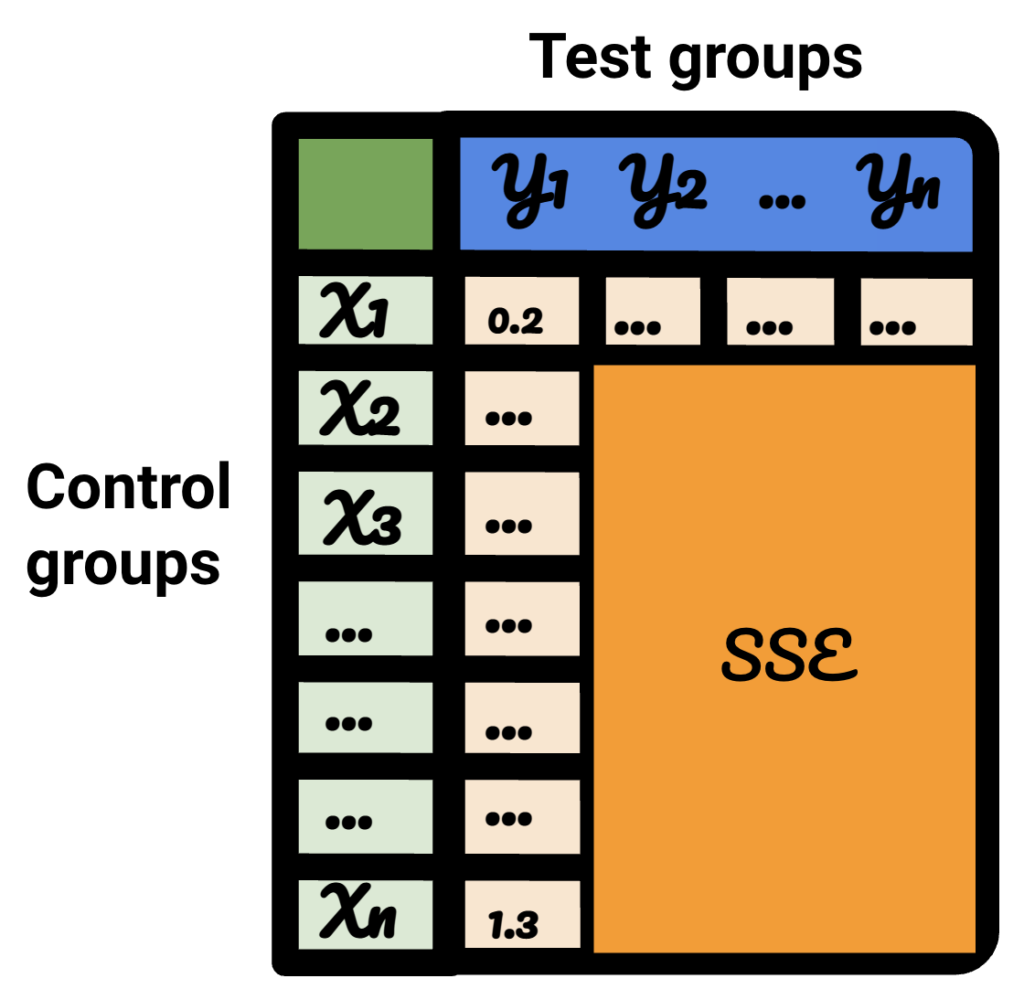
Beim Sortieren dieser Tabelle bin ich jetzt zuversichtlich, dass ich für jede der Testgruppen die beste Kontrollgruppe dafür auswählen kann.
Sollen wir Kontrollgruppen verwenden oder nicht?
Es gibt Hinweise darauf, dass die Verwendung von Kontrollgruppen zu besseren Schätzungen beiträgt als eine einfache Vor- und Nachbereitung.
Dies gilt jedoch nur, wenn wir die richtige Kontrollgruppe auswählen.
Wie lange sollte der Schätzzeitraum sein?
Die Antwort darauf hängt von den Steuerelementen ab, die wir auswählen.
Wenn keine Kontrolle verwendet wird, scheint ein 16-monatiger vorheriger Versuch ausreichend zu sein.
Bei Verwendung einer Kontrolle kann die Verwendung von nur 16 Monaten zu massiven Fehlerquoten führen. Die Verwendung von 3 Jahren trägt dazu bei, das Risiko einer Fehlinterpretation zu verringern.
Sollten wir 1 Steuerelement oder mehrere Steuerelemente verwenden?
Die Antwort auf diese Frage hängt von den Testdaten ab.
Sehr stabile Testdaten können im Vergleich zu mehreren Kontrollen gut abschneiden. In diesem Fall ist dies gut, da das Modell durch die Verwendung von viel Steuerung weniger von unerwarteten Schwankungen in einer der Steuerungen beeinflusst wird.
Bei anderen Datensätzen kann die Verwendung mehrerer Steuerelemente das Modell 10- bis 20-mal ungenauer machen als die Verwendung eines einzelnen.
Interessante Arbeit in der SEO-Community
CausalImpact ist nicht die einzige Bibliothek, die für SEO-Tests verwendet werden kann, noch ist die obige Methodik die einzige Lösung, um ihre Genauigkeit zu testen.
Um alternative Lösungen zu erfahren, lesen Sie einige der unglaublichen Artikel, die von Menschen in der SEO-Community geteilt werden.
Zunächst hat Andrea Volpini einen interessanten Artikel über die Messung der SEO-Effektivität mithilfe der CausalImpact-Analyse geschrieben.
Dann hat Daniel Heredia das Prophet-Paket von Facebook zur Vorhersage von SEO-Traffic mit Prophet und Python behandelt.
Während die Prophet-Bibliothek eher für Vorhersagen als für Experimente geeignet ist, lohnt es sich, verschiedene Bibliotheken kennenzulernen, um einen soliden Überblick über die Welt der Vorhersagen zu erhalten.
Schließlich war ich sehr erfreut über Sandy Lees Präsentation bei Brighton SEO, wo er Einblicke in Data Science für SEO-Tests teilte und einige der Fallstricke von SEO-Tests aufzeigte.
Dinge, die bei SEO-Experimenten zu beachten sind
- SEO-Split-Testing-Tools von Drittanbietern sind großartig, können aber auch ungenau sein. Seien Sie gründlich bei der Auswahl Ihrer Lösung.
- Obwohl ich in der Vergangenheit darüber geschrieben habe, können Sie mit Google Tag Manager keine SEO-Split-Testing-Experimente durchführen, es sei denn, sie sind serverseitig. Der beste Weg ist die Bereitstellung über CDNs.
- Seien Sie mutig beim Testen. Kleine Änderungen werden normalerweise nicht von CausalImpact erkannt.
- SEO-Tests sollten nicht immer Ihre erste Wahl sein.
- Es gibt Alternativen zum Testen kleinerer Änderungen wie Titel-Tags. Google Ads-A/B-Tests oder A/B-Tests auf der Plattform. Echte A/B-Tests sind genauer als SEO-Split-Tests und liefern in der Regel mehr Einblicke in die Qualität Ihrer Titel.
Reproduzierbare Ergebnisse
In diesem Tutorial wollte ich mich darauf konzentrieren, wie man die Genauigkeit von SEO-Experimenten verbessern kann, ohne sich mit Programmierkenntnissen auskennen zu müssen. Darüber hinaus kann die Quelle für die Daten variieren und jeder Standort ist anders.
Daher war der Python-Code, den ich zum Erstellen dieses Inhalts verwendet habe, nicht Teil des Umfangs dieses Artikels.
Mit der Logik können Sie jedoch die obigen Experimente reproduzieren.
Fazit
Wenn Sie aus diesem Artikel nur eines mitnehmen könnten, wäre es, dass die CausalImpact-Analyse sehr genau sein kann, aber immer weit daneben liegen kann.
Für SEOs, die dieses Paket verwenden möchten, ist es sehr wichtig zu verstehen, womit sie es zu tun haben. Das Ergebnis meiner eigenen Reise ist, dass ich CausalImpact nicht vertrauen würde, ohne zuerst die Genauigkeit des Modells anhand der Eingabedaten zu testen.