
So automatisieren Sie die Marketing-Mix-Modellierung mit einer MMM-Datenfeed-Tabelle
Veröffentlicht: 2022-06-16Marketing-Mix-Modellierung oder MMM erlebt eine Renaissance, mehr als 60 Jahre nachdem es allgemein verwendet wurde. Im Gegensatz zu den meisten Marketing-Zuordnungsmethoden erfordert MMM keine Daten auf Benutzerebene, anstatt zu modellieren, welche Kanäle eine Anerkennung für Verkäufe verdienen, indem Ausgabenspitzen und -einbrüche statistisch Aktionen und Ereignissen in Ihren Marketingkanälen zugeordnet werden. Die Marketing-Mix-Modellierung wird von der einfachen linearen Regression auf Techniken wie die Ridge-Regression oder Bayes'sche Methoden umgestellt und für die Moderne neu erfunden.

Möchten Sie mehr über MMM erfahren?
Lesen Sie die Vor- und Nachteile der Marketing-Mix-Modellierung im Vergleich zur Attributionsmodellierung
Allerdings sind dabei große Hürden zu nehmen. Der Aufbau eines Modells kann laut Meta/Facebook, das seit Oktober 2021 an seiner Open-Source-MMM-Bibliothek arbeitet, 3 bis 6 Monate dauern. Schätzungen zufolge werden etwa 50 % der Zeit damit verbracht, Daten zu sammeln und zu bereinigen, bevor die Modellierung beginnt . Dies entspricht meiner Erfahrung bei Recast – und zuvor Harrys – sowie den Ergebnissen einer CrowdFlower-Studie, die herausfand, dass 60 % der Data-Science-Zeit mit dem Bereinigen und Organisieren von Daten verbracht wird.
Schneller Vorlauf >>
- Datenreinigung
- Aufbau eines Marketing-Mix-Modells
- Automatisierte Modellierung
Datenreinigung macht 60 % der Arbeit aus, und wie man sie macht, 0 %
Um ein genaues Modell zu erstellen, benötigen Sie Ihre Daten in einem bestimmten Format. Die Bereitstellung der Daten ist zeitaufwändig, daher dauern MMM-Projekte länger als nötig. Dies macht MMM zu einer spezialisierten und teuren Fähigkeit, sodass die meisten Unternehmen nur ein bis zwei Modelle pro Jahr bauen können. Wenn Sie den Prozess mit einem Tool wie Supermetrics automatisieren können, um einen MMM-Datenfeed zu erstellen, können Sie Ihr Modell regelmäßig aktualisieren lassen, sodass Sie Ihr Marketingbudget besser optimieren können.
Tabellarisches Datenformat
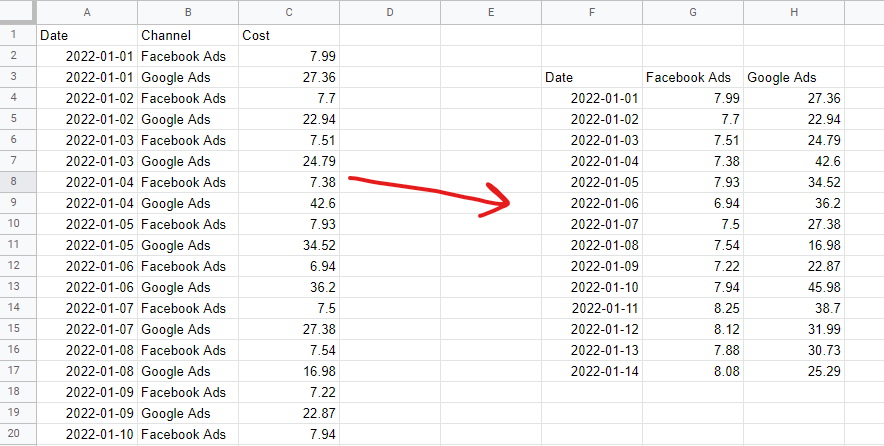
Um ein Marketing-Mix-Modell zu erstellen, müssen Sie Ihre Daten in einem nicht gestapelten, tabellarischen Format haben. Dies bedeutet eine Zeile pro Beobachtung – in der Regel Tage oder Wochen – und eine Spalte pro „Feature“ des Modells – typischerweise Medienausgaben und organische oder externe Variablen. Kategoriale Daten – beispielsweise eine Liste nationaler Feiertage – müssen in Dummy-Variablen kodiert werden – 1, wenn es sich um diesen Feiertag handelt, 0, wenn dies nicht der Fall ist.
Verbundene Datenquellen
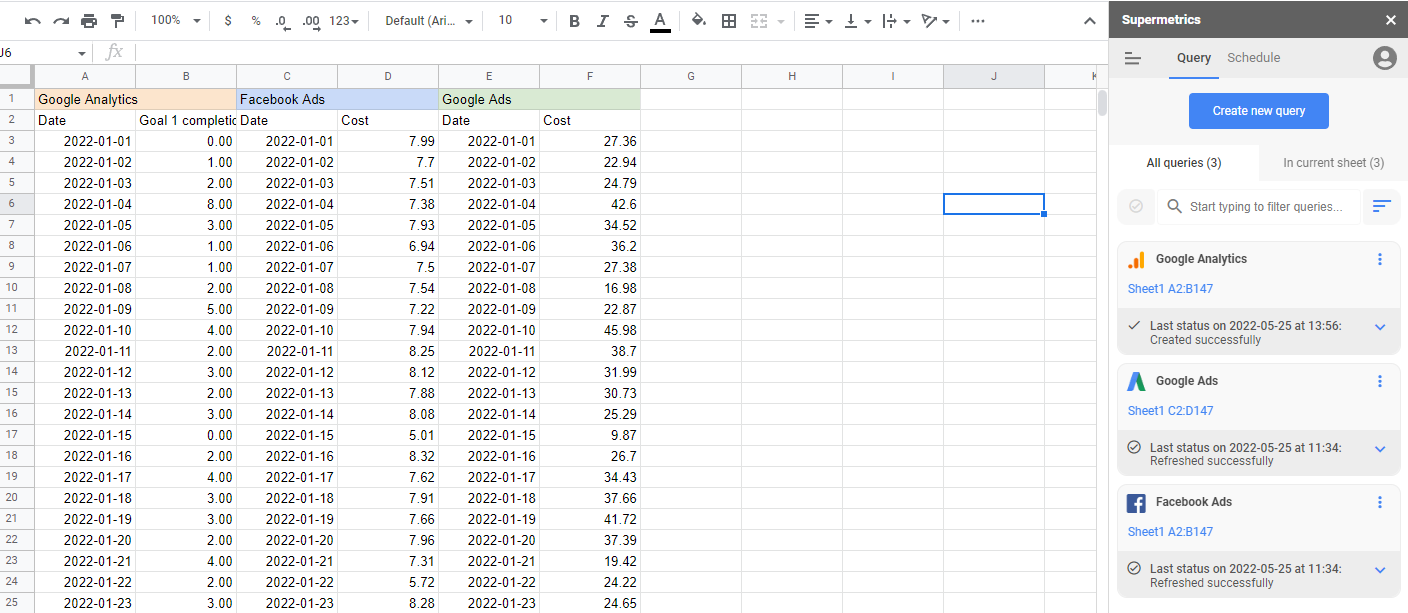
Um ein Marketingzuordnungsmodell zu erstellen, müssen Sie alle Ihre Marketingdaten an einem Ort haben. Das erledigt Supermetrics automatisch für Sie. Mit über 90 Konnektoren können alle Ihre Marketingausgaben, Veranstaltungen und Aktivitäten an einem Ort zusammengeführt, nach Bedarf bearbeitet und dann in das gewünschte Format und an den gewünschten Ort exportiert werden.
Exportieren in Google Sheets
Sobald Sie ein Supermetrics-Konto haben, müssen Sie einfach zu Erweiterungen > Add-ons > Add-ons abrufen gehen und es installieren. Sie werden aufgefordert, sich mit Ihrem Google-Konto zu authentifizieren, das mit Ihrem Supermetrics-Konto verknüpft ist, und dann wird die Seitenleiste im Erweiterungsmenü angezeigt.
Sobald dies erledigt ist, können Sie die Seitenleiste starten – falls sie noch nicht gestartet ist – und klicken, um eine neue Abfrage zu erstellen. Mit Abfragen entscheiden Sie, welche Daten von welchen Konten abgerufen werden sollen. Wenn Sie eine der Werbeplattformen wie Facebook Ads und Google Ads auswählen, werden Sie aufgefordert, sich zu authentifizieren und Supermetrics Zugriff zu gewähren.
Dann wählen Sie das Konto, von dem Sie Daten abrufen möchten, und den Datumsbereich aus. Wählen Sie schließlich Ihre Metriken – normalerweise Kosten oder Impressionen für MMM – und Dimensionen aus – wählen Sie nur das Datum aus, das mit dem Tabellenformat übereinstimmt.
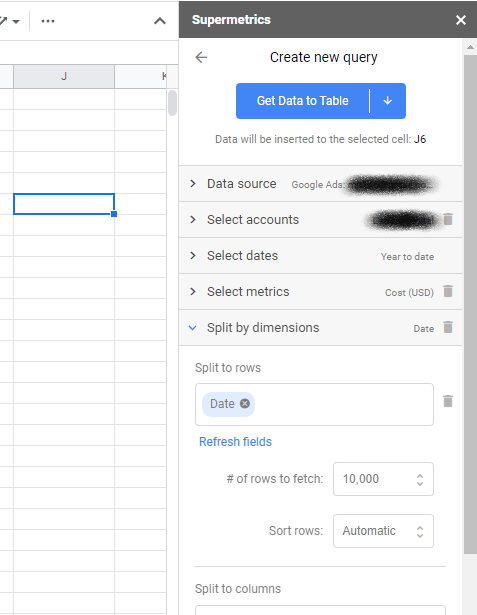
Optional können Sie einen Filter hinzufügen, wenn Sie eine bestimmte Gruppe von Kampagnen auswählen müssen. Wenn Sie beispielsweise "YT: " im Namen Ihrer YouTube-Kampagnen hatten, möchten Sie diese möglicherweise als separate Quelle auswählen und dann die Abfrage duplizieren und nach jedem Ihrer anderen Kampagnentypen filtern.
Wenn Sie Ihre Abfrage beendet haben, vergewissern Sie sich, dass Sie die Zelle ausgewählt haben, in die Sie die Daten ziehen möchten, und klicken Sie auf „Get Data to Table“. Wenn Sie einen Fehler machen, duplizieren Sie einfach die Abfrage und platzieren Sie sie an der richtigen Stelle, indem Sie die andere löschen.
Ich finde es hilfreich, den Namen jeder Quelle in eine Zelle über der Tabelle zu setzen, damit ich weiß, woher ich die Daten ziehe. Das Ergebnis sollte so aussehen:
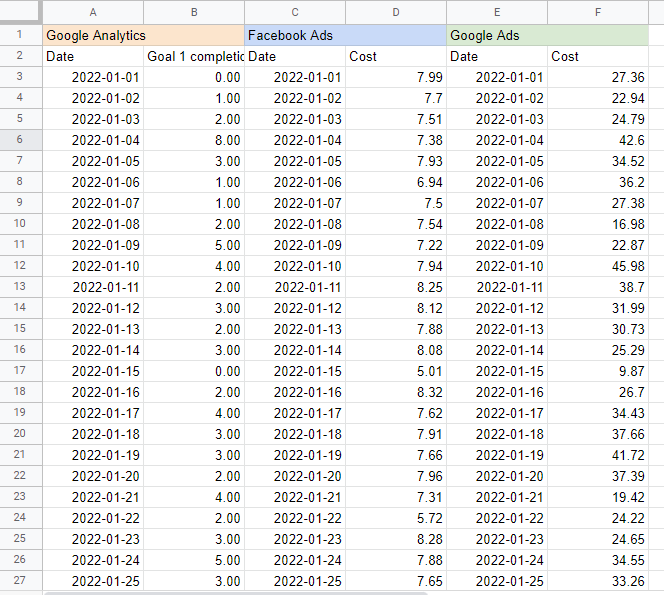
Erstellen eines Marketing-Mix-Modells in Google Sheets
Die Marketing-Mix-Modellierung ist ein leistungsstarkes Tool für die Attribution, aber tatsächlich zugänglicher, als Sie vielleicht denken. Die meisten Praktiker verwenden benutzerdefinierten Code und erweiterte Statistiken, aber Sie können die Grundlagen an einem Nachmittag mit nichts anderem als Excel oder Google Sheets erledigen.
Lineare Regression mit der RGP-Funktion
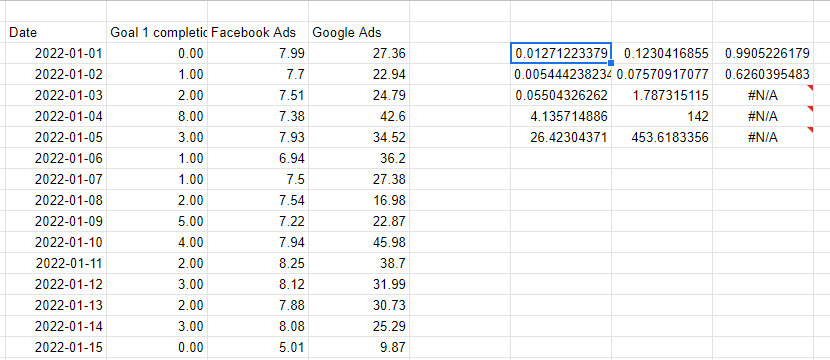
Excel und Google Sheets bieten beide eine einfache Methode, die RGP-Funktion, um eine lineare Regression mit mehreren Variablen durchzuführen. RGP funktioniert, indem die Spalte übergeben wird, die wir vorherzusagen versuchen, und dann mehrere Spalten, die die Variablen darstellen, die wir verwenden, um die Vorhersage zu treffen. Die letzten beiden Parameter sind, ob wir eine Schnittlinie wollen – normalerweise 1 für ja – und ob die Ausgabe ausführlich sein soll – die alle Statistiken für das Modell enthält, nicht nur die Koeffizienten.
Beachten Sie, dass die X-Variablen, die wir für die Vorhersage verwenden, fortlaufend sein müssen, also habe ich nur auf die Spalten auf der linken Seite verwiesen, um die Werte nebeneinander zu wiederholen.
Neuprognose mit Modellkoeffizienten
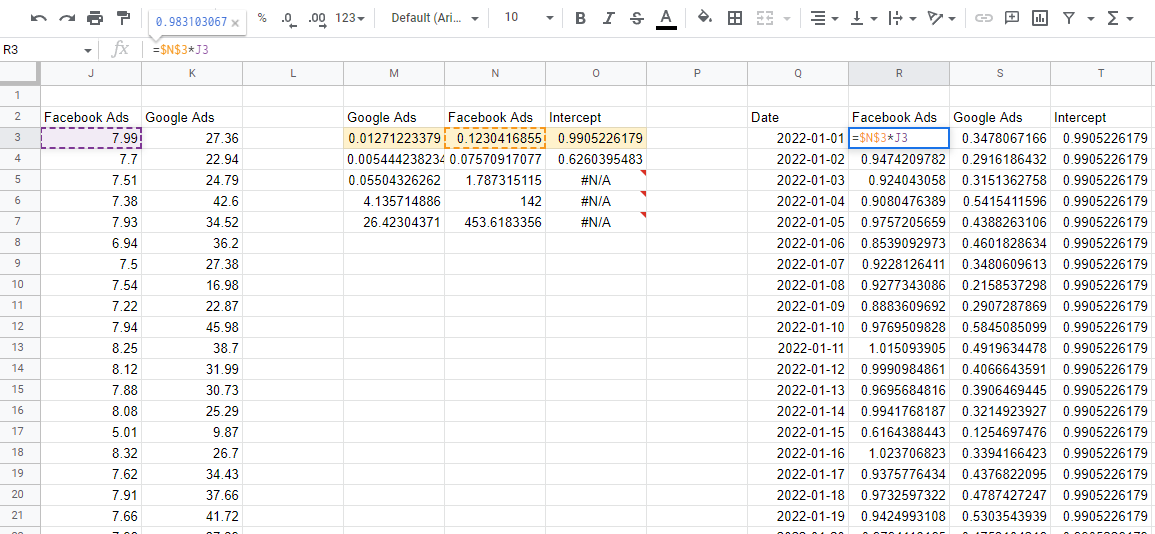
Da wir nun ein Modell haben, müssen wir die Koeffizienten verwenden, um die Auswirkung jedes Kanals abzuschätzen. Wenn wir die oberste Zahlenreihe nehmen, das sind die Koeffizienten, und sie mit den entsprechenden Eingabewerten aus unseren Daten multiplizieren, erhalten wir den Beitrag jeder Variablen zum Gesamtumsatz.

Eine Sache, auf die Sie achten sollten, ist, dass RGP die Koeffizienten rückwärts ausgibt. Der erste Wert, beginnend von links, ist immer die letzte Variable, die Sie eingeben, dann fahren sie in umgekehrter Reihenfolge fort, bis Sie zum letzten Wert gelangen, der der Schnittpunkt ist. Wenn Sie alle diese Beitragswerte addieren, erhalten Sie die Vorhersagen aus dem Modell, die Sie mit den tatsächlichen Werten vergleichen können, um sicherzustellen, dass das Modell genau ist.
Überprüfen der Modellgenauigkeitsmetriken
Woher wissen wir, ob unser Modell zuverlässig ist? Das Modell sollte gut zu den Daten passen, es sollte in der Lage sein, neue Daten vorherzusagen, die es nicht gesehen hat, und es sollte plausible Koeffizienten haben. Mehrere Validierungsmetriken erfassen diese Anforderungen.
Überprüfen Sie die Funktionen in der Vorlage, um zu sehen, wie diese Metriken berechnet werden.
Um die Vorlage zu verwenden, gehen Sie zu „Datei“ > „Kopie erstellen“ > „Supermetrics starten“ aus der Liste der Add-Ons > duplizieren Sie diese Datei für ein anderes Konto und fahren Sie dann mit der Kontoauswahl fort.
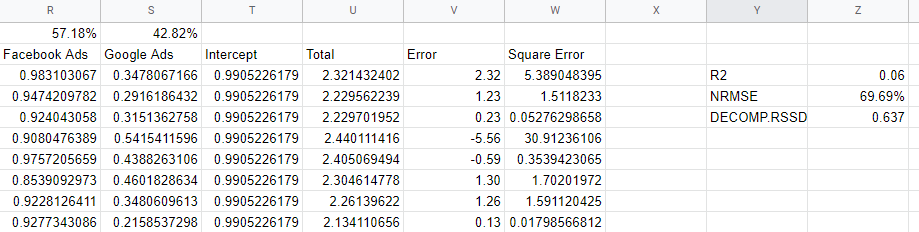
R2 oder R-Squared ist ein Maß dafür, wie viel der Varianz in den Daten durch das Modell erklärt wird, und liegt zwischen 0 und 1: Ein gutes Modell würde über 0,7 liegen, aber alles, was sich 1 nähert, ist wahrscheinlich verdächtig. Nahe 0, wie es unser Modell ist, ist ein Zeichen dafür, dass wir nicht genügend Variablen in unser Modell aufnehmen und Dinge wie organische Kanäle, Feiertage und makroökonomische Faktoren einbeziehen müssen.
„Normalisierter mittlerer quadratischer Fehler“ ist, wie wir die Genauigkeit messen, und er wird ermittelt, indem die Differenz zwischen den Modellvorhersagen und den tatsächlichen Werten genommen und dann die Wurzel der quadrierten Werte als Prozentsatz des tatsächlichen Werts ermittelt wird. Idealerweise geschieht dies auf der Grundlage von unsichtbaren Daten – einer Holdout-Gruppe –, aber in unserem einfachen Modell haben wir nur den Fehler gegenüber In-Sample-Daten berechnet.
Die Root-and-Squaring-Prozedur handhabt negative Werte für uns und handelt, um wirklich große Fehler zu bestrafen. Dies kann so interpretiert werden, dass der Prozentsatz des Modells an einem bestimmten Tag aus ist, also ist es ein nützliches, intuitives Maß.
Plausibilität ist ein großes Thema, und normalerweise sollte ein Analyst das letzte Wort haben. Es ist jedoch hilfreich, einen Messwert zu haben, den Sie programmatisch berechnen können, damit Sie verstehen, wie weit das Modell in Bezug auf seine Ergebnisse von Ihrem aktuellen Kanalmix abweicht.
Decomp RSSD ist eine vom Robyn-Team bei Facebook erfundene Metrik, die den Unterschied zwischen Ihrer aktuellen Ausgabenzuweisung und den Kanälen gemessen hat, die die größten Effekte erzielt haben, wie vom Modell vorhergesagt. Wenn das Modell sagen würde, dass Ihr größter Kanal tatsächlich nicht so viele Verkäufe ankurbelt, dann hätten Sie eine hohe Decomp-RSSD.
In unserem Fall haben wir einen hohen Wert von 0,6, weil das Modell Facebook zu viel Anerkennung zuschreibt, was eine kleine Menge an Ausgaben darstellt.
MMMs automatisch und in großem Umfang bereitstellen
Die Marketing-Mix-Modellierung ist eine dieser Aktivitäten, die unendlich skalierbar ist. Sie können an einem Nachmittag mit Excel oder Google Sheets und Supermetrics anständige Ergebnisse erzielen, wie wir es hier getan haben, aber Sie könnten auch 3 Monate mit einem Team von 6 Datenwissenschaftlern verbringen, die benutzerdefinierten Code mit ausgefeilten Algorithmen wie Bayesian MCMC schreiben, um etwas mehr zu bauen robust und genau.
Es gibt eine Checkliste mit Funktionen, die zum Erstellen eines erweiterten Modells erforderlich sind, von denen einige fortgeschrittene Statistikkenntnisse erfordern. Fügen Sie der Mischung mehrere teure Dateningenieure zum Erstellen von Datenpipelines hinzu, wenn Sie Supermetrics nicht verwenden, um diesen Teil für Sie zu automatisieren.
Möchten Sie mehr über die Automatisierung von Modellierungsmischungen erfahren?
Sehen Sie sich unseren Artikel zur automatisierten Marketing-Mix-Modellierung an
Seien Sie gewarnt: MMM ist hart. Sie könnten 500, 5.000 oder 50.000 US-Dollar für die Modellierung ausgeben und sehr unterschiedliche Ergebnisse in Bezug auf Genauigkeit und Robustheit sehen. Was wirklich zählt, sind die Opportunitätskosten einer falschen Zuweisung Ihrer Marketingausgaben.
Wenn Sie monatlich 10.000 $ ausgeben, ist ein Tabellenkalkulationsmodell einmal im Quartal in Ordnung. Wenn Sie jedoch mehr als 100.000 US-Dollar pro Monat ausgeben, kann Sie sogar ein Rabatt von 5 % Zehntausende von US-Dollar über ein Jahr kosten.
Sie sind sich nicht sicher, welches Datenzugriffsmodell Sie für Ihren MMM-Feed benötigen?
Lesen Sie unseren Artikel, um das richtige für Ihr Unternehmen auszuwählen
Dann ist es sinnvoll, in fortschrittlichere Modellierung zu investieren. Führen Sie eine Build-vs.-Buy-Analyse durch, um sich zwischen einer benutzerdefinierten Lösung zu entscheiden, die auf Open-Source-Bibliotheken wie Robyn von Facebook basiert, oder einer fortschrittlichen Attributionssoftware, wie wir sie bei Recast entwickelt haben.
Über den Autor
Michael Kaminsky ist ausgebildeter Ökonometriker mit einem Hintergrund in Gesundheits- und Umweltökonomie. Zuvor baute er das Marketing-Wissenschaftsteam bei der Herrenpflegemarke Harry's auf, bevor er Recast mitbegründete.

Verbessern Sie Ihre Geschäftsleistung
durch die Kombination von Marketing und Business Intelligence in Ihrem Data Warehouse