
Stärkung der Banksicherheit: maschinelles Lernen zur Betrugserkennung
Veröffentlicht: 2023-11-14Mit jeder Gelegenheit geht eine Bedrohung einher. Der Wandel hin zur Digitalisierung im Bankensektor verbesserte das Kundenerlebnis und erweiterte den Kundenstamm auf Bevölkerungsgruppen, die zuvor kein Bankkonto hatten. Der Nachteil bestand darin, dass Online-Transaktionen und digitale Zahlungslösungen Betrügern neue Möglichkeiten eröffneten.
Die Ergebnisse einer KMPG-Betrugsumfrage deuten darauf hin, dass Cyberangriffe häufiger und schwerwiegender werden und zu Verlusten in Milliardenhöhe führen.
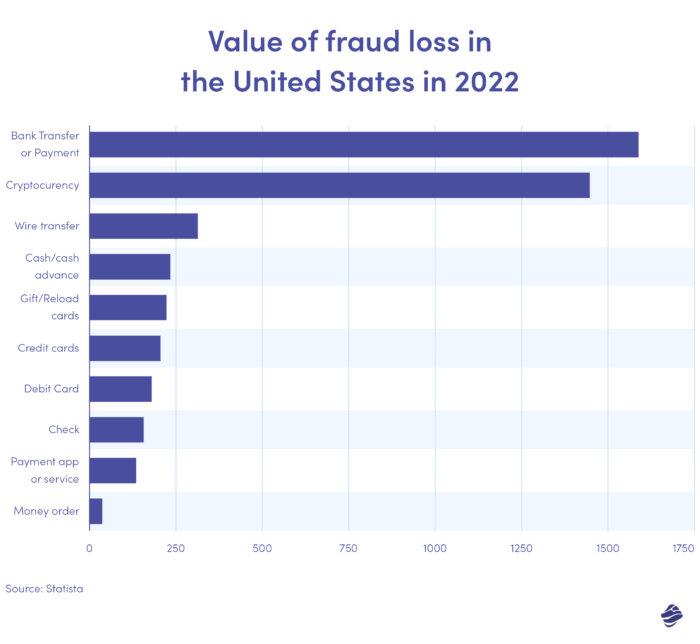
Die obige Grafik zeigt den Wert der Betrugsverluste nach Zahlungsmethode in den Vereinigten Staaten im Jahr 2022. Banküberweisungen und Zahlungen waren mit einem Verlust von 1,59 Milliarden US-Dollar am höchsten.
Diese Verluste haben Bankinstitute gezwungen, neue Lösungen zur Erkennung, Eindämmung und Verhinderung von Finanzbetrug einzuführen. Eine solche Methode ist künstliche Intelligenz (KI), genauer gesagt maschinelles Lernen.
In diesem Artikel besprechen wir alles, was Sie über maschinelles Lernen zur Betrugserkennung wissen müssen, einschließlich der Vorteile und realen Anwendungen.
Entwicklung der Betrugserkennung
Die herkömmliche Betrugserkennung folgt einem regelbasierten Ansatz. Wie der Name schon sagt, unterliegt es einer Reihe von Regeln oder Bedingungen, die bestimmen, ob eine Transaktion echt oder betrügerisch ist. Zu den üblichen Bedingungen gehören der Ort (liegt der Kauf außerhalb des üblichen Aufenthaltsbereichs des Nutzers?) und die Häufigkeit (ist die Anzahl und Art des Kaufs für den Nutzer üblich?).
Eine Transaktion wird nur dann durchgeführt, wenn sie die Bedingungen erfüllt. Ein Kunde in Ohio hat beispielsweise plötzlich eine POS-Gebühr in Neuseeland. Der Standort liegt außerhalb der Vorwahl des Benutzers, sodass das System die Transaktionen als betrügerisch kennzeichnet.
Diese Art von Betrugserkennungssystem weist mehrere Nachteile auf.
- Es kommt zu einer hohen Anzahl falsch positiver Ergebnisse. Hier blockieren Sie Zahlungen von echten Kunden.
- Es ist unflexibel. Der regelbasierte Ansatz verwendet feste Ergebnisse, was eine Anpassung an Trends im digitalen Banking erschwert. Sie müssen die Regeln ändern, um neue Formen des Betrugs zu erkennen.
- Es lässt sich nicht skalieren. Wenn die Datenmenge zunimmt, steigt auch der Aufwand, der zu ihrer Verhinderung erforderlich ist. Alle Änderungen am System werden manuell vorgenommen, was teuer und zeitaufwändig ist.
Die regelbasierte Betrugserkennung funktioniert. Aufgrund seiner Nachteile ist es jedoch für moderne digitale Umgebungen ungeeignet. Es kann keine Muster erkennen und ist auf menschliches Eingreifen angewiesen.
Darüber hinaus halten sich Hacker nicht an einen 9-5-Zeitplan und können ausgefeilte Methoden wie Standortfälschung und Nachahmung des Kundenverhaltens einsetzen, um Betrugserkennungssysteme auszutricksen. Daher benötigen Sie ein ebenso hochentwickeltes System, das rund um die Uhr funktioniert.
Betreten Sie maschinelles Lernen.
Maschinelles Lernen ist eine künstliche Intelligenz (KI) , die Daten nutzt, um Algorithmen zur Betrugserkennung zu trainieren, um Datenmuster und Zusammenhänge aufzudecken, Einblicke zu gewinnen und Vorhersagen zu treffen.
Sie sind bereits mit maschinellem Lernen vertraut, auch wenn Sie es nicht wissen. Wenn Sie beispielsweise mit einem Instagram-Beitrag interagieren, geben Sie dem Algorithmus Informationen über die Art des Inhalts, der Ihnen gefällt. Anschließend durchsucht es die App nach ähnlichen Inhalten, die Sie Ihrem Feed hinzufügen können.
Wie maschinelles Lernen die Betrugserkennung verändern wird
Die Betrugserkennung im Bankwesen mithilfe maschinellen Lernens verändert die Branche bereits durch eine schnellere, flexiblere und genauere Erkennung und Reaktion auf Betrug.
Das KI-System analysiert Muster in Kundendaten und ändert automatisch Regeln basierend auf historischen und neu auftretenden Bedrohungen.
Erinnern Sie sich an die neuseeländische POS-Gebühr, die wir bereits erwähnt haben? Bei der Betrugserkennung mithilfe von maschinellem Lernen wird davon ausgegangen, dass mit derselben Bankkarte ein Flug zu diesem Ort gekauft wurde. Daher ist die neue Abbuchung höchstwahrscheinlich legitim.
Zwei Modelle werden verwendet, um Algorithmen zur Betrugserkennung zu trainieren: überwachtes maschinelles Lernen und unüberwachtes maschinelles Lernen.
Überwachtes maschinelles Lernen
Das überwachte Lernmodell füttert Algorithmen mit großen Datenmengen, die entweder als Betrug oder Nichtbetrug gekennzeichnet sind. Der Algorithmus untersucht diese Beispiele und lernt, welche Muster und Beziehungen legitime Transaktionen von betrügerischen unterscheiden.
Dieses Lernmodell ist zeitaufwändig, da es eine manuelle Kennzeichnung der Daten erfordert. Darüber hinaus müssen Ihre Datensätze korrekt beschriftet und gut organisiert sein. Eine falsch gekennzeichnete Transaktion beeinträchtigt die Genauigkeit des Algorithmus.
Darüber hinaus lernt es nur aus Eingaben, die im Trainingssatz enthalten sind. Daher werden Transaktionen über Ihre neu eingeführten Mobile-Banking-App-Funktionen, die nicht Teil der historischen Daten waren, nicht gekennzeichnet. Es gibt jetzt eine Lücke, die Betrüger ausnutzen können.
Unüberwachtes maschinelles Lernen
Das unbeaufsichtigte Lernmodell verwendet nur minimale menschliche Eingaben. Der Algorithmus lernt Muster und Beziehungen aus großen Mengen nicht markierter Daten und gruppiert Datensätze basierend auf Ähnlichkeiten und Unterschieden.
Ziel ist es, ungewöhnliche Aktivitäten zu erkennen, die nicht im Trainingsdatensatz enthalten sind. Somit setzt unüberwachtes Lernen dort an, wo überwachtes Lernen aufhört, und erkennt neue Betrugsfälle.
Denken Sie daran, dass Sie sich nicht zwischen einem überwachten oder unbeaufsichtigten Modell für maschinelles Lernen entscheiden müssen. Sie können sie zusammen (halbüberwachtes Lernmodell) oder unabhängig voneinander verwenden.
Vorteile der Verwendung von ML zur Betrugserkennung
Wir haben bereits auf die Vorteile der Betrugserkennung durch maschinelles Lernen im Bankwesen hingewiesen, aber lassen Sie uns diese näher besprechen.
- Geschwindigkeit
Berechnungen durch maschinelles Lernen erfolgen schnell und liefern Betrugsentscheidungen in Echtzeit. Während regelbasierte Algorithmen ebenfalls in Echtzeit entscheiden, stützen sie sich bei der Erkennung von Betrug auf schriftliche Regeln.
Was passiert in neuen Szenarien ohne vordefinierte Regeln? Es führt zu falsch-positiven oder falsch-negativen Ergebnissen.
Maschinelles Lernen erkennt automatisch neue Muster, analysiert die regelmäßige Kundenaktivität und berechnet innerhalb von Millisekunden entsprechende Ergebnisse.
- Genauigkeit
Regelbasierte Erkennungssysteme blockieren echte Transaktionen oder erlauben betrügerische Transaktionen, weil sie Nuancen im Kundenverhalten nicht erkennen.
Maschinelle Lernsysteme berücksichtigen Variablen, die über die schriftlichen Regeln hinausgehen, beispielsweise bekanntes betrügerisches Verhalten. Diese Variablen helfen bei der Kontextualisierung der Transaktion und senken so die Rate falsch positiver Ergebnisse.
- Flexibilität
Maschinelles Lernen ist flexibel und reaktiv. Die Selbstlernfähigkeit ermöglicht es diesem System, sich an neue Szenarien anzupassen und neue Bedrohungen zu erkennen. Regelbasierte Systeme sind starr und verfügen nicht über Lernfähigkeiten. Daher kann auf betrügerische Aktivitäten nur nach vordefinierten Regeln reagiert werden.
- Effizienz
Algorithmen für maschinelles Lernen können Tausende von Transaktionsdaten pro Sekunde analysieren. Anstatt Arbeits- und Gemeinkosten für die Untersuchung geringer bis mittelschwerer Betrugsfälle aufzuwenden, kann maschinelles Lernen sich wiederholende oder eindeutige Betrugsfälle verarbeiten. Es ermöglicht Betrugsspezialisten, sich auf komplexe Muster zu konzentrieren, die menschliche Einblicke erfordern.
- Skalierbarkeit
Erhöhtes Datenvolumen setzt regelbasierte Systeme unter Druck. Neue Regeln erhöhen die Komplexität des Systems und erschweren dessen Wartung. Jeder Fehler oder Widerspruch kann dazu führen, dass das gesamte Modell unwirksam wird.
Maschinelle Lernsysteme sind das Gegenteil. Sie verarbeiten nicht nur große Mengen neuer Daten, sondern verbessern sich auch.
Techniken des maschinellen Lernens zur Betrugserkennung
Bevor wir die verschiedenen Algorithmen untersuchen, die bei der KI-Betrugserkennung verwendet werden, werfen wir einen Überblick über die Funktionsweise des Systems.
Der erste Schritt ist die Dateneingabe. Die Genauigkeit des Modells hängt vom Umfang und der Qualität der Daten ab. Je mehr hochwertige Daten Sie hinzufügen, desto genauer wird das Modell.
Anschließend analysiert das Modell die Daten und extrahiert Schlüsselmerkmale , die normales Verhalten im Vergleich zu betrügerischem Verhalten beschreiben. Zu diesen Funktionen gehören die Kundenidentität (E-Mail-Adresse oder Telefonnummer), der Standort (IP-Adresse oder Lieferadresse), Zahlungsmethoden (Name des Karteninhabers und Herkunftsland) und mehr.
Der dritte Schritt besteht darin, den Algorithmus (mit mehr Daten) zu trainieren , um zwischen echten und betrügerischen Transaktionen zu unterscheiden. Das Modell erhält einen Trainingsdatensatz und prognostiziert die Betrugswahrscheinlichkeit in verschiedenen Fällen. Sobald der Algorithmus ausreichend trainiert ist, können Sie ihn starten.
Schauen wir uns nun die verschiedenen Algorithmen an, die Sie verwenden können.
1. Logistische Regression
Die logistische Regression ist ein überwachter Lernalgorithmus. Es berechnet die Betrugswahrscheinlichkeit auf einer binären Skala – Betrug oder Nichtbetrug – basierend auf den Parametern des Modells.
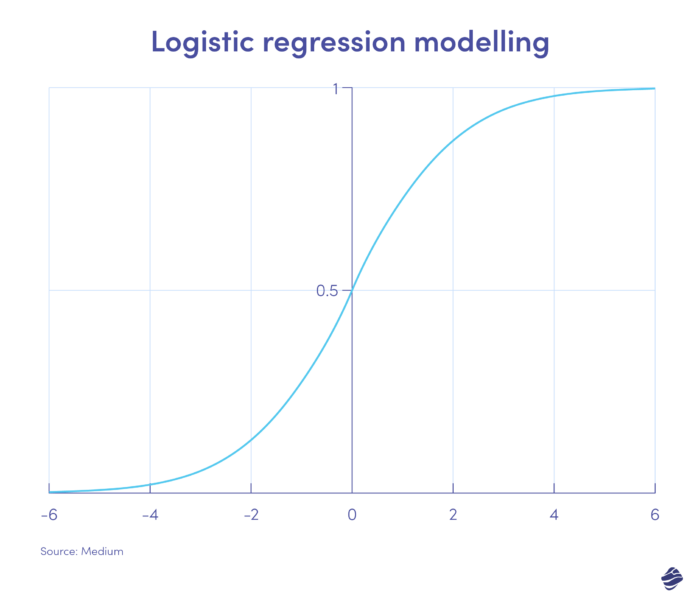
Transaktionen, die auf der positiven Seite der Grafik liegen, sind höchstwahrscheinlich betrügerisch, während Transaktionen auf der negativen Seite höchstwahrscheinlich legitim sind.
2. Entscheidungsbaum
Ein Entscheidungsbaum ist ein überwachter Lernalgorithmus, geht aber über logistische Regressionsalgorithmen hinaus. Dabei handelt es sich um eine hierarchische Entscheidungsstruktur, die Daten auf mehreren Ebenen analysiert, um festzustellen, ob eine Transaktion echt oder betrügerisch ist.
Unten sehen Sie eine Abbildung eines Entscheidungsbaums zur Erkennung von Kreditkartenbetrug.
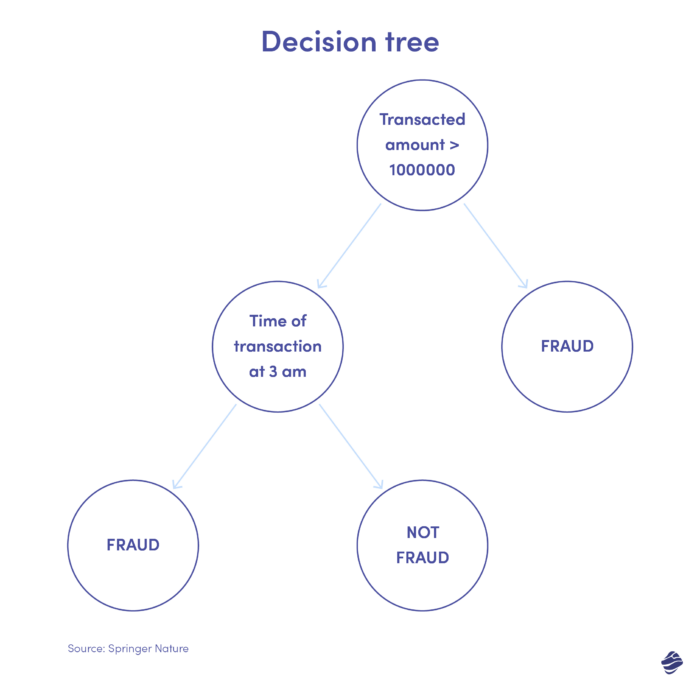
Die Bedingung zur Feststellung, ob die Transaktion betrügerisch ist, ist der Transaktionsbetrag. Übersteigt der Wert der Transaktion einen festgelegten Schwellenwert, betrachtet der Algorithmus sie als betrügerisch. Wenn nicht, prüft der Baum eine andere Bedingung – die Transaktionszeit. Wenn der Zeitpunkt ungewöhnlich ist (hier 3 Uhr morgens), handelt es sich wahrscheinlich um einen Betrug. Wenn nicht, prüft es eine andere Bedingung. Es geht weiter.
3. Zufälliger Wald
Random Forest ist eine Kombination aus vielen Entscheidungsbäumen, wobei jeder Entscheidungsbaum auf unterschiedliche Bedingungen prüft – Identität, Standort usw.
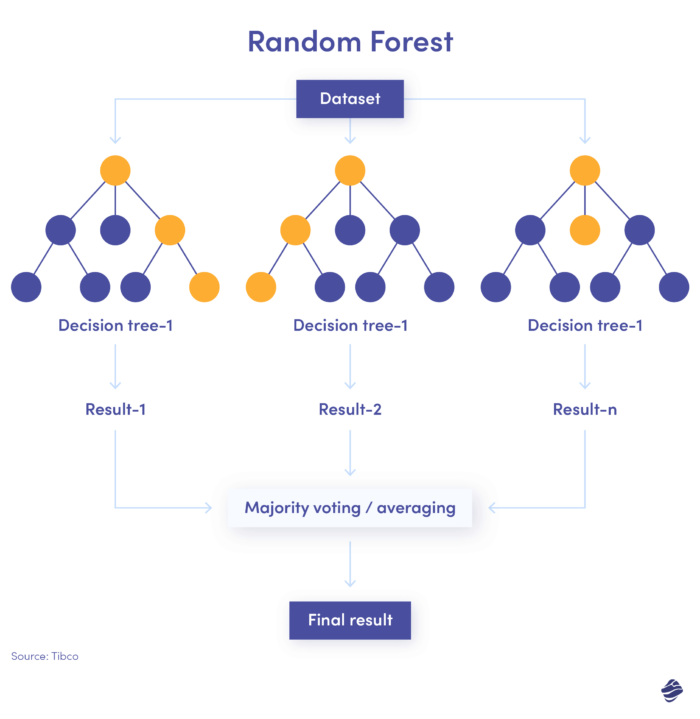
Nach Überprüfung aller Parameter bietet jeder Teilbaum eine Entscheidung. Die Gesamtsumme bestimmt, ob die Transaktion echt oder betrügerisch ist.

4. Neuronale Netze
Neuronale Netze sind komplexe, unbeaufsichtigte Algorithmen. Inspiriert vom menschlichen Gehirn verarbeiten neuronale Netze Daten in mehreren Schichten, um übergeordnete Merkmale zu extrahieren. Dieser Algorithmus geht Hand in Hand mit Deep Learning, das Muster in Bildern, Text, Audio und anderen Daten erkennen kann.
Hier ist eine vereinfachte Version eines neuronalen Netzwerks.
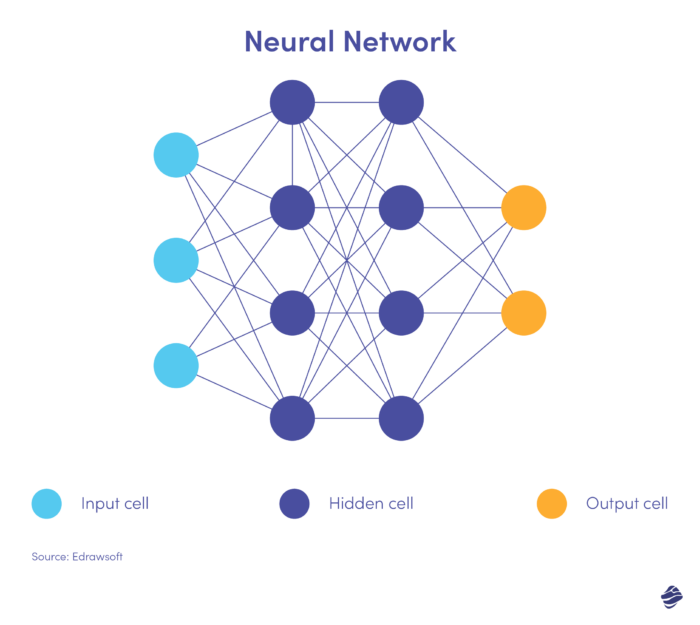
Ein neuronales Netzwerk besteht aus drei Schichten: Eingabe, verborgen und Ausgabe. Die Eingabeschicht verarbeitet Daten, die verborgene Schicht analysiert die Daten der Eingabeschicht, um verborgene Muster zu identifizieren, und die Ausgabeschicht klassifiziert die Daten.
Tiefe neuronale Netze verfügen über mehrere verborgene Schichten. Sie eignen sich hervorragend zur Identifizierung nichtlinearer Zusammenhänge und zur Erkennung beispielloser Betrugsszenarien.
5. Support-Vektor-Maschine
Support Vector Machines (SVM) sind überwachte Lernalgorithmen, die Ausreißer vorhersagen, klassifizieren und erkennen.
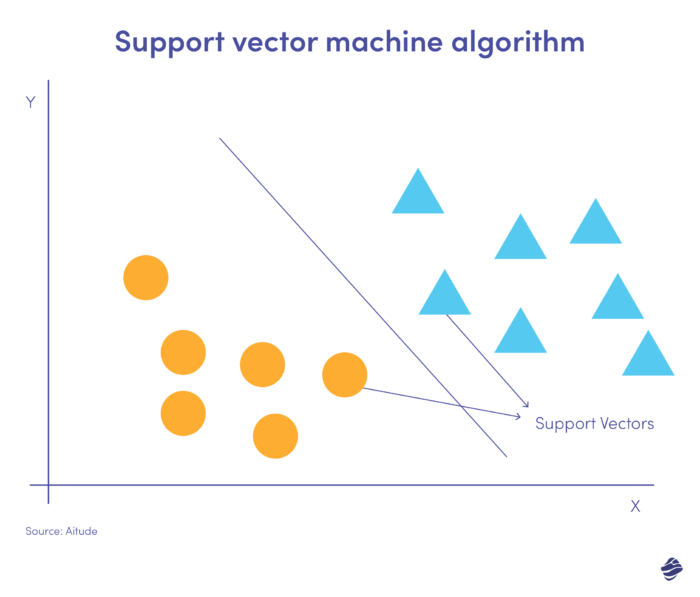
Diese lineare SVM-Abbildung zeigt zwei Datensätze, die durch eine gerade Linie, eine sogenannte Hyperebene, getrennt sind. Es ist die Entscheidungsgrenze, die Daten als Betrug vs. Nichtbetrug klassifiziert.
Datenpunkte, die weiter von der Hyperebene entfernt sind, lassen sich leicht klassifizieren. Unterstützungsvektoren (die der Hyperebene am nächsten liegen) sind schwer zu kategorisieren. Diese Ausreißer können die Position der Hyperebene beeinflussen, wenn sie entfernt werden.
6. K-nächster Nachbar
K-Nearest Neighbor (KNN) ist ein überwachter Lernalgorithmus. Dabei wird davon ausgegangen, dass ähnliche Elemente nahe beieinander existieren.
Unten finden Sie eine einfache Illustration.
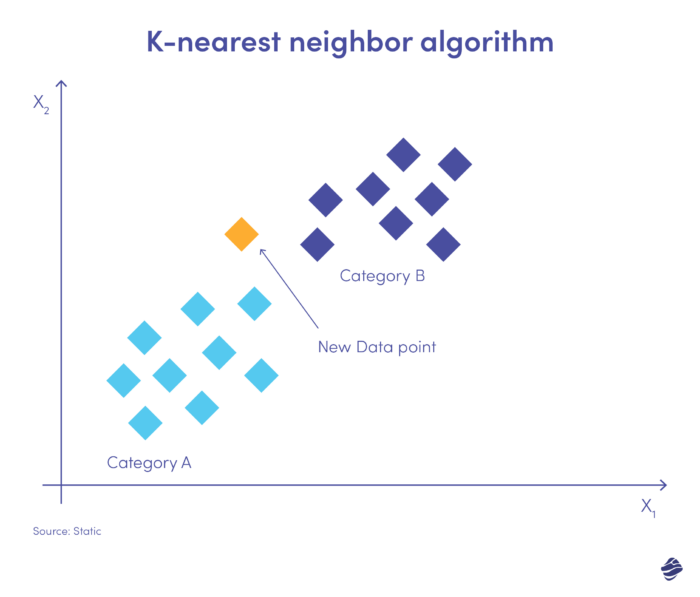
Ein neuer Dateneintrag muss entweder in die Kategorie A oder B eingeordnet werden. Der Algorithmus berechnet den Abstand zwischen Datenpunkten mithilfe einer mathematischen Gleichung, die als euklidischer Abstand bezeichnet wird. Der neue Datenpunkt fällt in die Gruppe mit den meisten Nachbarn. Wenn der nächstgelegene Datensatz mit „Betrug“ gekennzeichnet ist, wird diese Transaktion als betrügerisch eingestuft.
Bewältigung von Herausforderungen und strategischen Überlegungen
Wie bei jeder Technologie ist die Integration von maschinellem Lernen zur Betrugserkennung mit zunehmenden Problemen verbunden. Hier sind einige häufige Herausforderungen, denen Sie möglicherweise gegenüberstehen.
Unzureichende Infrastruktur
Viele Bankensysteme sind nicht in der Lage, große Mengen komplexer Daten zu analysieren. Darüber hinaus sind die meisten Daten isoliert und in separaten Speichereinrichtungen untergebracht.
Leider gibt es keine schnelle Lösung für dieses Problem. Sie müssen in die entsprechende Hard- und Software investieren.
Sie müssen mit einer erfahrenen Fintech-App-Entwicklungsagentur zusammenarbeiten und eine Infrastruktur einrichten, um automatisch geeignete Algorithmen für bestimmte Datensätze auszuwählen, Rohdaten zu importieren und für maschinelles Lernen vorzubereiten, die Daten zu visualisieren, den Algorithmus zu testen und vieles mehr.
Datenqualität und -sicherheit
Die Datenqualität ist ein wichtiges Thema für Finanzinstitute, die maschinelles Lernen zur Betrugserkennung implementieren möchten. Modelle des maschinellen Lernens unterscheiden nicht zwischen guten und schlechten Daten. Wenn der Algorithmus also mit irrelevanten oder unvollständigen Daten verunreinigt ist, ist die Genauigkeit Ihres Modells falsch.
Datenerfassungslösungen wie Amazon Kinesis sammeln, bereinigen und transformieren Rohdaten und machen sie so für Modelle des maschinellen Lernens geeignet. Sobald die Daten bereinigt und organisiert sind, müssen Sie sensible und nicht sensible Daten trennen. Verschlüsseln Sie vertrauliche Informationen und speichern Sie sie in sicheren Einrichtungen. Sie sollten auch den Zugriff auf diese Daten einschränken.
Mangel an Talent
Entgegen den Befürchtungen der Menschen stiehlt maschinelles Lernen keine Arbeitsplätze. Es ist genau das Gegenteil. Wir brauchen weiterhin Betrugsanalysten, die komplexe Fälle verwalten, die menschliche Einsicht und Erfahrung erfordern. Außerdem ist maschinelles Lernen eine neue Technologie und es gibt nicht genügend Experten auf diesem Gebiet.
Das sind gute Nachrichten für Arbeitssuchende, aber nicht für Institutionen, die nicht das volle Potenzial des maschinellen Lernens ausschöpfen können. Sie können diesen Geschwindigkeitsschub überwinden, indem Sie mit Unternehmen zusammenarbeiten, die über die nötigen Fähigkeiten zur Implementierung von maschinellem Lernen verfügen.
Fallstudien zur Betrugserkennung im Bankwesen mittels maschinellem Lernen
Schauen wir uns nun reale Beispiele für die Betrugserkennung im Bankwesen mithilfe von maschinellem Lernen an.
Entdeckung eines Betruges
Danske Bank ist ein dänischer multinationaler Finanzkonzern. Sie ist die größte Bank in Dänemark und eine führende Privatkundenbank in Nordeuropa. Im Rahmen des regelbasierten Erkennungssystems hatte die Bank Mühe, Betrug einzudämmen. Die Betrugserkennungsrate lag bei 40 % und die Falsch-Positiv-Rate bei 99,5 %.
In Zusammenarbeit mit Teradata, einem Datensoftwareunternehmen, integrierte Danske Deep-Learning-Software, um potenzielle betrügerische Aktivitäten zu erkennen. Das Ergebnis war eine 60-prozentige Reduzierung der falsch-positiven Ergebnisse und eine 50-prozentige Steigerung der richtig-positiven Ergebnisse.
Geldwäschebekämpfung
OakNorth ist eine kommerzielle Kreditbank im Vereinigten Königreich, die geschäftliche und private Finanzdienstleistungen für expandierende Unternehmen bereitstellt. Die Bank verfügte über einen fragmentierten Überprüfungsprozess, mit einem Anbieter für Anti-Geldwäsche-Prüfungen und einem anderen für Kunden. Darüber hinaus führten die Screenings auf politisch exponierte Personen (PEP) zu vielen Fehlalarmen.
In Zusammenarbeit mit ComplyAdvantage, einem Unternehmen zur Betrugs- und AML-Erkennung, integrierte die Bank eine Screening- und laufende Überwachungslösung, um die Compliance zu optimieren und Daten zu konsolidieren. Dies ermöglichte einen schnellen Datentransfer zwischen den Kredit- und Spargeschäften der Bank.
Kreditvergabe
Die Hawaii USA Credit Union ist die größte Kreditgenossenschaft in Hawaii und eine der besten Kreditgenossenschaften des Forbes Magazine. Das Unternehmen wollte gegenüber Fintech-Unternehmen konkurrenzfähig sein und sein Privatkreditportfolio erweitern, ohne das Risiko zu erhöhen.
In Zusammenarbeit mit Zest AI automatisierte die Kreditgenossenschaft ihre Entscheidungsprozesse mithilfe eines KI-gesteuerten Privatkreditmodells. Das Modell nutzte 278 Variablen, um tiefere Erkenntnisse zu liefern als das Kreditbewertungssystem VantageScore. Das Ergebnis war ein Anstieg der Genehmigungsrate um 21 % und eine Ausfall-/Betrugsrate bei Kreditanträgen von 0 %.
Wichtige Überlegungen bei der Verwendung von ML zur Betrugserkennung
Die Betrugserkennung im Bankwesen mithilfe von maschinellem Lernen ist zwar effizient, aber auch entmutigend. Diese Systeme erfordern viele genaue Daten, oder die Modelle funktionieren nicht so gut, wie sie sollten.
Hier sind einige Tipps zur Optimierung des maschinellen Lernprozesses.
1. Begrenzen Sie die Anzahl der Eingabevariablen
In diesem Artikel haben wir immer gesagt: Mehr ist mehr. Das gilt auch für das Datenvolumen. Bei der Anzahl der Betrugserkennungsvariablen gilt jedoch: Weniger ist mehr.
Zu den typischen Merkmalen, die bei der Untersuchung von Betrug zu berücksichtigen sind, gehören:
- IP Adresse
- E-Mail-Adresse
- Lieferanschrift
- Durchschnittlicher Bestell-/Transaktionswert
Der Vorteil weniger Funktionen besteht in kürzeren Trainingszeiten für den Algorithmus. Sie vermeiden außerdem Probleme durch überlappende oder irrelevante Datensätze.
2. Stellen Sie die Einhaltung gesetzlicher Vorschriften sicher
Betrugsprävention ist ein Teil der Datensicherheit. Das andere ist der Datenschutz. In vielen Ländern gibt es Gesetze darüber, wie Institutionen Kundendaten sammeln, verwenden und speichern dürfen. Es gibt das chinesische Gesetz zum Schutz personenbezogener Daten (PIPL), das California Consumer Privacy Act (CCPA) und die Datenschutz-Grundverordnung (DSGVO) der Europäischen Union, um nur einige zu nennen.
Diese Gesetze haben Auswirkungen auf die beim maschinellen Lernen verwendeten Daten. Das Hauptprinzip der meisten Datenschutz-Compliance-Vorschriften ist die Mitteilung/Einwilligung. Sie müssen die Verwendung von Kundendaten für andere Zwecke als Benutzeranfragen, einschließlich Daten zum Trainieren von Algorithmen für maschinelles Lernen, benachrichtigen und eine Genehmigung einholen.
Der einfachste Weg, die Einhaltung von Datenschutzstandards sicherzustellen, ist die Nutzung technischer Partner mit gesetzeskonformen Funktionen. Sie sollten beispielsweise mit einem Entwicklungsunternehmen für Banking-Apps zusammenarbeiten, das sich mit der Wahrung des Datenschutzes und der Datensicherheit auskennt.
3. Legen Sie einen angemessenen Schwellenwert fest
Für Transaktionswertregeln gelten Mindestanforderungen, um eine Annahme- oder Ablehnungsantwort auszulösen. Sie möchten einen Schwellenwert, der Sicherheit und Benutzererfahrung in Einklang bringt. Wenn der Schwellenwert zu streng ist, besteht die Gefahr, dass legitime Transaktionen blockiert werden. Wenn der Schwellenwert zu lasch ist, erhöhen Sie die Erfolgsquote bei Betrug.
Berechnen Sie Ihre Risikobereitschaft, um das richtige Gleichgewicht zu finden. Das Risikoniveau ist je nach Finanzinstitut oder Produkt unterschiedlich. Beispielsweise kann ein Mikrokreditangebot einer Bank einen hohen Schwellenwert für Kredite mit geringem Wert festlegen. Eine Geschäftsbank kann bei Hypothekendarlehen nicht so großzügig sein.
Die Zukunft antizipieren
Die Zukunft ist jetzt, doch nur 17 % der Unternehmen nutzen maschinelles Lernen in Betrugsbekämpfungsprogrammen. Lass dich nicht zurücklassen.
Hier sind einige Durchbrüche, die Sie durch maschinelles Lernen für die Sicherheit Ihrer Bank erwarten können.
- Geräteprofilierung : Identifizieren Sie die verschiedenen Geräte, die eine Verbindung zu Ihrem Banknetzwerk herstellen, und analysieren Sie die Funktionen und Verhaltensweisen jedes einzelnen Geräts.
- Automatisierte Erkennung und Reaktion auf Anomalien : Identifizieren Sie betrügerisches Verhalten bekannter Geräte und isolieren Sie betroffene Systeme.
- Zero-Day-Erkennung : Identifizieren Sie bisher unbekannte Schwachstellen und Malware, um Unternehmen vor Cyberangriffen zu schützen.
- Datenmaskierung : Erkennt und anonymisiert automatisch vertrauliche Daten.
- Skalierte Erkenntnisse : Identifizieren Sie Betrugstrends über mehrere Geräte und Standorte hinweg.
- Innovative Richtlinien : Nutzen Sie Erkenntnisse aus maschinellem Lernen, um relevante Sicherheitsrichtlinien voranzutreiben.
Ganz gleich, ob Sie ein Vermögensverwaltungsinstitut oder eine Kreditgenossenschaft sind, KI und maschinelles Lernen bieten enorme Möglichkeiten zur Betrugserkennung.
Es ist jedoch wichtig zu bedenken, dass Hacker diese Technologien auch nutzen, um Schutzmaßnahmen zu umgehen. Aktualisieren Sie Ihre Modelle für maschinelles Lernen, um diesen Angriffen immer einen Schritt voraus zu sein. Sie können Ihre KI-basierte Sicherheit auch mit der guten alten menschlichen Intelligenz stärken.