
Javascript: Wie teste ich die SSR- und/oder Pre-Rendering-Implementierung mit Oncrawl?
Veröffentlicht: 2021-09-13Die Diagnose von SEO-Problemen bei der JavaScript-Implementierung einer Website ist nicht immer einfach. Wenn Sie sich für Server Side Rendering oder Pre-Rendering für Bots entscheiden, kann die Aufgabe noch komplexer werden.
Sie müssen sicherstellen, dass die den Google-Bots bereitgestellte Version vollständig ist, dass alle Javascript-Elemente serverseitig ausgeführt wurden und in der vom Bot gecrawlten HTML-Datei vorhanden sind.
In diesem Artikel werden wir sehen, wie Sie Ihr JS-Rendering aller Ihrer Seiten mit Oncrawl schnell und einfach testen können.
SEO und JS
Bevor wir mit der Praxis beginnen, lassen Sie uns kurz das Interesse an SEO von Server Side Rendering (SSR) und Pre-Rendering von Javascript-Elementen einer Website durchgehen.
JS und Google: gute Praktiken
Standardmäßig erfolgt die HTML-Wiedergabe von Javascript durch den Client, dh Ihren Webbrowser. Wenn Sie eine Seite mit JS-Elementen anfordern, führt Ihr Browser diesen Javascript-Code aus, um die vollständige Seite anzuzeigen. Dies wird Clientseitiges Rendern (CSR) genannt.
Für Google ist dies ein Problem, da es viel Zeit und vor allem Ressourcen erfordert. Es zwingt es, Ihre Seite zweimal zu durchlaufen, einmal, um den Code abzurufen, und dann ein zweites Mal, nachdem der HTML-Code des JS gerendert wurde.
Als direkte Folge der CSR für Ihr SEO ist der vollständige Inhalt Ihrer Seiten nicht sofort für Google sichtbar und kann daher die Indexierung verzögern. Darüber hinaus wird auch das Ihrer Website zugewiesene Crawling-Budget beeinträchtigt, da Ihre Seiten zweimal gecrawlt werden müssen.
Das SSR (serverseitiges Rendern)
Im Fall von SSR erfolgt die HTML-Wiedergabe des Javascript auf der Serverseite für alle Besucher der Website, Menschen und Bots. Infolgedessen muss Google den Inhalt nicht in JS verwalten, da es zum Zeitpunkt des Crawls direkt das vollständige HTML erhält. Dies behebt den Fehler von Javascript in SEO.
Andererseits können die Ressourcenkosten zum Erzielen dieser Wiedergabe auf der Serverseite wichtig sein. Hier kommt die dritte Option ins Spiel, das Pre-Rendering.
Vorab-Rendering
In dieser hybriden Konfiguration erfolgt die Ausführung des JS clientseitig für alle Besucher (CSR) mit Ausnahme der Suchmaschinen-Bots. Ein vorgerenderter HTML-Inhalt wird an Google-Bots geliefert, um die SEO-Vorteile von SSR, aber auch die wirtschaftlichen Vorteile von CSR zu erhalten.
Diese Vorgehensweise, die auf den ersten Blick als Cloaking (das Anbieten unterschiedlicher Versionen für Bots und Besucher einer Webseite) angesehen werden könnte, ist tatsächlich eine Idee von Google, die sehr zu empfehlen ist. Wir können leicht erraten, warum.
Wie teste ich das Javascript-Rendering mit Oncrawl?
Es gibt viele Möglichkeiten, SEO-Fehler in der JS-Implementierung zu diagnostizieren. Durch die Verwendung von Oncrawl können Sie alle Ihre Seiten automatisch testen, ohne manuelle Vergleiche durchführen zu müssen.
Oncrawl ist in der Lage, eine Website zu crawlen, indem es Javascript auf der Client-Seite ausführt. Die Idee ist, zwei Crawls zu starten und einen Vergleich zu generieren zwischen:
- Ein Crawl mit aktiviertem JS-Rendering
- Ein Crawl mit deaktiviertem JS-Rendering
Um dann anhand mehrerer Metriken die Unterschiede zwischen diesen beiden Crawls zu messen, deutet dies darauf hin, dass ein Teil des Javascripts nicht auf der Serverseite ausgeführt wird.
Beachten Sie, dass beim Vorab-Rendering das zweite Crawling mit einem Google-User-Agent erfolgen sollte, um die vorab gerenderte Version der Website zu crawlen.
Dieser Test kann in drei Schritten durchgeführt werden:
- Erstellen Sie die Crawling-Profile
- Crawlen Sie die Website mit jedem Profil und generieren Sie ein Crawl-Over-Crawl
- Analysieren Sie die Ergebnisse
Erstellen Sie die Crawling-Profile
Das Profil mit JS
Klicken Sie auf Ihrer Projektseite auf „+ Neuen Crawl einrichten“ .
Dadurch gelangen Sie zur Seite mit den Crawling-Einstellungen. Ihre standardmäßigen Crawling-Einstellungen werden angezeigt. Sie können sie entweder ändern oder eine neue Crawling-Konfiguration erstellen.
Ein Crawl-Profil ist eine Reihe von Einstellungen, die unter einem Namen für die zukünftige Verwendung gespeichert wurden.
Um ein neues Crawl-Profil zu erstellen, klicken Sie oben rechts auf die blaue Schaltfläche „+ Crawl-Profil erstellen“ .
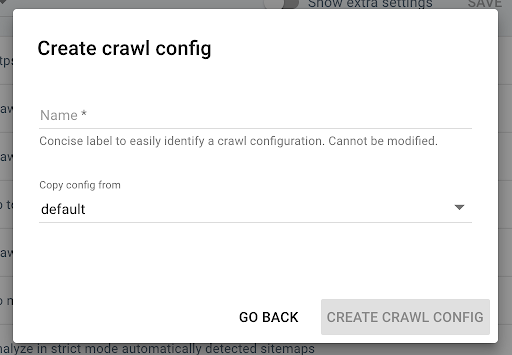
Nennen Sie es „Crawl with JS“ und kopieren Sie Ihr übliches Crawl-Profil (z. B. den Standard).
Um den JS auf diesem neuen Profil zu aktivieren, müssen Sie die zusätzlichen Parameter anzeigen, die standardmäßig ausgeblendet sind. Um darauf zuzugreifen, klicken Sie oben auf der Seite auf die Schaltfläche „Zusätzliche Einstellungen anzeigen“ .
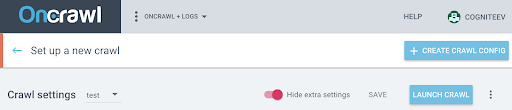
Gehen Sie dann zu den Extra-Einstellungen und klicken Sie in der Option Crawl JS auf „Aktivieren“ .
Hinweis: Denken Sie daran, Ihre Crawling-Geschwindigkeit an die Kapazität der Server Ihrer Website anzupassen, da Oncrawl viel mehr Aufrufe pro URL tätigt, um die Elemente in Javascript auszuführen. Die ideale Geschwindigkeit ist diejenige, die Ihre Server- und Site-Architektur am besten unterstützen kann. Wenn die Crawling-Geschwindigkeit von OnCrawl zu hoch ist, kann Ihr Server möglicherweise nicht mithalten.
Das Profil ohne JS
Führen Sie für dieses zweite Crawling-Profil die gleichen Schritte aus und deaktivieren Sie das Kontrollkästchen JS aktivieren .
Hinweis: Es ist wichtig, zwei Profile mit identischem Umfang zu haben, damit der Vergleich aussagekräftig ist.
Wenn sich Ihre Website im serverseitigen Rendering befindet, fahren Sie mit dem nächsten Schritt fort.
Wenn Ihre Website für Google-Bots vorab gerendert wird, sollten Sie uns eine Anfrage senden, um den User Agent für das Crawlen zu ändern. Sobald das Profil erstellt ist, senden Sie uns eine Nachricht über Intercom direkt in der Anwendung, damit wir den Oncrawl User Agent durch einen Google Bot User Agent ersetzen können.
Starten Sie Ihre kostenlose 14-Tage-Testversion
 Starten Sie Ihre Testversion
Starten Sie Ihre TestversionStarten Sie Ihre Crawls und generieren Sie Crawl über Crawl
Sobald die beiden Profile erstellt wurden, müssen Sie Ihre Website nur noch mit diesen beiden Profilen nacheinander crawlen. Um es einfacher zu machen, können Sie die Crawl-Programmierfunktion verwenden.

Planen Sie einen Crawl
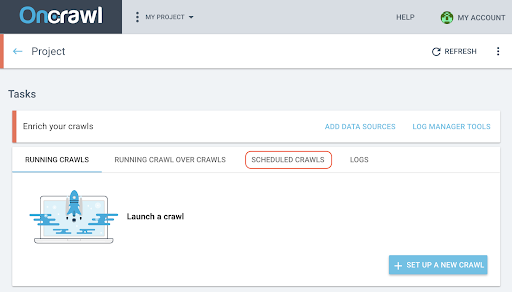
- Klicken Sie auf der Projektseite oben im Crawl-Verfolgungsfeld auf die Registerkarte „Geplante Crawls“ .
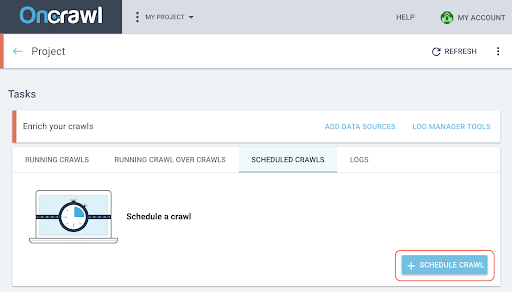
- Klicken Sie auf „+ Crawl planen“ , um einen neuen Crawl zu planen.
- Sie müssen dann wählen:
- Das Crawling-Profil, das Sie für das zukünftige Crawling verwenden möchten
- Die Häufigkeit, mit der das Crawlen wiederholt werden soll, wählen Sie „Nur einmal“.
- Das Datum, die Uhrzeit (im 24-Stunden-Format) und die Zeitzone (nach Stadt), wann das Crawling beginnen soll.
- Klicken Sie auf „Crawl planen“ .
Sobald beide Analysen Ihrer Crawls verfügbar sind, müssen Sie ein Crawl-over-Crawl erstellen. 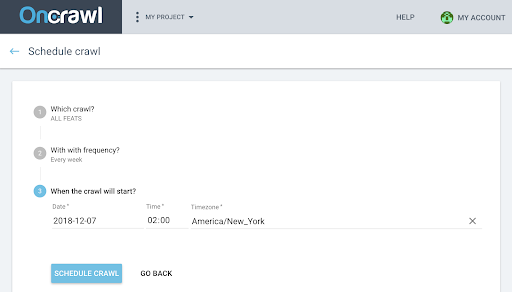
Generieren Sie ein Crawl-over-Crawl
- Starten Sie auf der Startseite des Projekts einen Crawl-Over-Crawl:
- Klicken Sie unter „Aufgaben“ auf die Registerkarte „Running Crawl over Crawls“ .
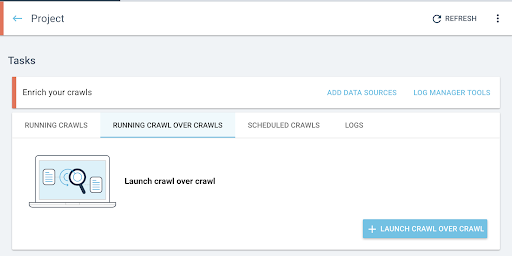
- Klicken Sie auf „+ Crawl über Crawl starten“ .
- Wählen Sie die beiden Crawls aus, die Sie vergleichen möchten.
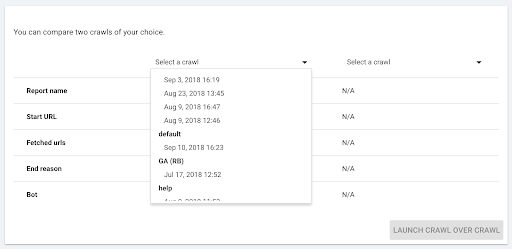
Wenn Sie auf „+ Run Crawl Over Crawl“ klicken, analysiert Oncrawl die Unterschiede zwischen den beiden vorhandenen Crawls und fügt den Crawl Over Crawl-Bericht zu den Analyseergebnissen der beiden Crawls hinzu.
Sie können den Fortschritt dieses Crawl-Over-Crawl auf der Registerkarte „Crawl-Over-Crawl starten“ auf der Projekthomepage verfolgen. Da der Crawl bereits abgeschlossen ist, überspringt der Overcrawl den Zustand „Crawling“ und startet direkt mit „Analysis“.
Analysieren Sie die Ergebnisse
Rufen Sie den Crawl-Over-Crawl-Bericht in den folgenden drei Ansichten auf:
- Struktur
- Inhalt
- Interne Verlinkung
Sie können auch unser benutzerdefiniertes Dashboard herunterladen.
Welche Metriken sind zu beachten?
Gecrawlte Seite, durchschnittliche Wortanzahl pro Seite und durchschnittliches Verhältnis von Text zu Code
Der erste Indikator Seite gecrawlt zeigt Ihnen sofort, ob die beiden Profile gleich viele Seiten gecrawlt haben.
Wenn der Unterschied nicht signifikant ist, können Sie zwei Indikatoren auf der Seite überprüfen:
- Durchschnittliche Wortzahl pro Seite
- Durchschnittliches Verhältnis von Text zu Code
Diese beiden Metriken zeigen einen Unterschied im HTML-Inhalt mit oder ohne Javascript-Ausführung auf der Client-Seite auf.
Wenn im Durchschnitt weniger Wörter pro Seite vorhanden sind, bedeutet dies, dass ein Teil des Seiteninhalts ohne JS-Rendering nicht verfügbar ist.
Wenn das Text-zu-Verhältnis niedriger ist, bedeutet dies in ähnlicher Weise, dass ein Teil des Seiteninhalts ohne JS-Rendering nicht verfügbar ist.
Das Verhältnis von Text zu Code misst, wie viel vom Inhalt einer Seite sichtbar ist (Text) und wie viel verschlüsselter Inhalt ist (Code). Je höher der gemeldete Prozentsatz, desto mehr Text enthält die Seite im Vergleich zur Codemenge.
Tiefe, Inrank und Inlinks
Sie können sich dann die Metriken in Bezug auf Ihr internes Mesh ansehen, die sensibler sind. Dass ein kleiner Teil des Seiteninhalts ohne JS-Rendering nicht verfügbar ist, ist nicht unbedingt problematisch für Ihr SEO, aber wenn es sich auf Ihr internes Mesh auswirkt, sind die Auswirkungen auf die Crawlbarkeit Ihrer Website und das Crawl-Budget wichtiger.
Vergleichen Sie die durchschnittliche Tiefe, den durchschnittlichen Inrank, die durchschnittliche Anzahl an Inlinks und internen Outlinks.
Eine zunehmende durchschnittliche Tiefe, ein abnehmender durchschnittlicher Inrank und eine abnehmende durchschnittliche Anzahl von Inlinks und Outlinks sind Indikatoren für das Vorhandensein von in JS verwalteten Mesh-Blöcken, die serverseitig nicht vorgerendert wurden. Daher sind einige der Links für den Google-Bot nicht sofort verfügbar.
Dies kann Auswirkungen auf die gesamte oder einen Teil Ihrer Website haben. Es ist dann notwendig, diese Änderungen nach Seitengruppen zu untersuchen, um festzustellen, ob einige Arten von Seiten durch dieses Javascript-Netz benachteiligt werden.
Der Daten-Explorer ermöglicht es Ihnen, mit den Filtern zu spielen, um diese Elemente hervorzuheben.
Gehen Sie weiter mit dem Datenexplorer und den URL-Details
Im Datenexplorer
Wenn Sie sich die Crawl-over-Crawl-Daten im Datenexplorer ansehen, sehen Sie zwei Spalten mit URLs: eine für die Crawl 1-URLs und eine für die Crawl 2-URLs.
Sie können dann jede der oben genannten Metriken (gecrawlte Seiten, Wortzahl, Verhältnis von Text zu Code, Tiefe, Inrank, Inlinks) jeweils zweimal hinzufügen, um den Wert von Crawl 1 und Crawl 2 nebeneinander anzuzeigen.
Mithilfe der Filter können Sie die URLs mit den größten Unterschieden identifizieren.
URL-Details
Wenn Sie Unterschiede zwischen der SSR- und/oder vorgerenderten Version und der clientseitig gerenderten Version festgestellt haben, müssen Sie genauer darauf eingehen, um zu verstehen, welche JS-Elemente nicht für SEO optimiert sind.
Durch Klicken auf eine Seite im Daten-Explorer wechseln Sie zu den URL-Details und können dann den Quellcode aus der Sicht von Oncraw anzeigen, indem Sie auf die Registerkarte „Quelle anzeigen“ klicken.
Anschließend können Sie den HTML-Code abrufen, indem Sie auf HTML-Quelle kopieren klicken.
Oben links können Sie von einem Crawl zu einem anderen wechseln, um die andere Version des Codes abzurufen.
Durch die Verwendung eines HTML-Code-Vergleichstools können Sie die beiden Versionen einer Seite vergleichen, mit JS und ohne JS, das auf der Clientseite ausgeführt wird. Für den Rest liegt es an Ihnen!