
Eine Einführung in Webcrawler
Veröffentlicht: 2016-03-08Wenn ich mit Leuten darüber spreche, was ich tue und was SEO ist, verstehen sie es normalerweise ziemlich schnell oder sie handeln so, wie sie es tun. Eine gute Website-Struktur, ein guter Inhalt, gute unterstützende Backlinks. Aber manchmal wird es etwas technischer und am Ende spreche ich von Suchmaschinen, die Ihre Website crawlen, und ich verliere sie normalerweise…
Warum eine Website crawlen?
Web-Crawling begann mit der Kartierung des Internets und wie jede Website miteinander verbunden war. Es wurde auch von Suchmaschinen verwendet, um neue Online-Seiten zu entdecken und zu indizieren. Web-Crawler wurden auch verwendet, um die Schwachstelle einer Website zu testen, indem eine Website getestet und analysiert wurde, ob ein Problem erkannt wurde.
Jetzt können Sie Tools finden, die Ihre Website crawlen, um Ihnen Einblicke zu geben. Beispielsweise liefert OnCrawl Daten zu Ihren Inhalten und Onsite-SEO oder Majestic, das Einblicke in alle Links bietet, die auf eine Seite verweisen.
Crawler werden verwendet, um Informationen zu sammeln, die dann verwendet und verarbeitet werden können, um Dokumente zu klassifizieren und Einblicke in die gesammelten Daten zu geben.
Das Erstellen eines Crawlers ist für jeden zugänglich, der sich mit Code auskennt. Die Herstellung eines effizienten Crawlers ist jedoch schwieriger und braucht Zeit.
Wie funktioniert es ?
Um eine Website oder das Web zu crawlen, benötigen Sie zunächst einen Einstiegspunkt. Roboter müssen wissen, dass Ihre Website existiert, damit sie kommen und sie sich ansehen können. Früher hätten Sie Ihre Website bei Suchmaschinen eingereicht, um ihnen mitzuteilen, dass Ihre Website online war. Jetzt können Sie ganz einfach ein paar Links zu Ihrer Website erstellen und voila, Sie sind auf dem Laufenden!
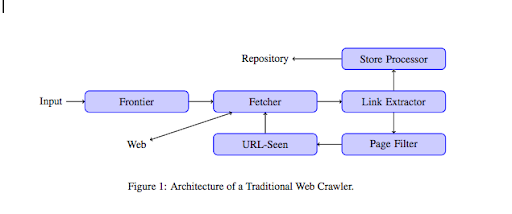
Sobald ein Crawler auf Ihrer Website landet, analysiert er alle Ihre Inhalte Zeile für Zeile und folgt jedem Ihrer Links, ob es sich um interne oder externe handelt. Und so weiter, bis es auf einer Seite ohne weitere Links landet oder auf Fehler wie 404, 403, 500, 503 stößt.
Aus technischer Sicht arbeitet ein Crawler mit einem Seed (oder einer Liste) von URLs. Diese wird an einen Fetcher weitergegeben, der den Inhalt einer Seite abruft. Dieser Inhalt wird dann an einen Link-Extraktor weitergeleitet, der den HTML-Code parst und alle Links extrahiert. Diese Links werden an einen Store-Prozessor gesendet, der sie, wie der Name schon sagt, speichert. Diese URLs durchlaufen auch einen Seitenfilter, der alle interessanten Links an ein URL-gesehenes Modul sendet. Dieses Modul erkennt, ob die URL bereits gesehen wurde oder nicht. Wenn nicht, wird es an den Fetcher gesendet, der den Inhalt der Seite abruft und so weiter.
Denken Sie daran, dass einige Inhalte wie Flash nicht von Spidern gecrawlt werden können. Javascript wird jetzt korrekt vom GoogleBot gecrawlt, aber hin und wieder crawlt er nichts davon. Bilder sind keine Inhalte, die Google technisch crawlen kann, aber es wurde intelligent genug, um sie zu verstehen!
Wenn Robotern nicht das Gegenteil gesagt wird, werden sie alles kriechen. Hier wird die robots.txt-Datei sehr nützlich. Es teilt Crawlern mit (es kann für jeden Crawler spezifisch sein, dh GoogleBot oder MSN Bot – erfahren Sie hier mehr über Bots), welche Seiten sie nicht crawlen können. Nehmen wir zum Beispiel an, Sie haben eine Navigation mit Facetten, Sie möchten vielleicht nicht, dass Roboter sie alle crawlen, da sie wenig Mehrwert haben und das Crawl-Budget verwenden. Die Verwendung dieser einfachen Linie hilft Ihnen, zu verhindern, dass ein Roboter sie kriecht
User-Agent: *
Nicht zulassen: /Ordner-a/
Dies weist alle Roboter an, Ordner A nicht zu crawlen.
User-Agent: GoogleBot
Nicht zulassen: /repertoire-b/
Dies wiederum gibt an, dass nur Google Bot Ordner B nicht crawlen kann.
Sie können auch Hinweise in HTML verwenden, die Robots mitteilen, dass sie einem bestimmten Link nicht folgen sollen, indem Sie das Tag rel=”nofollow” verwenden. Einige Tests haben gezeigt, dass selbst die Verwendung des Tags rel="nofollow" auf einem Link den Googlebot nicht daran hindert, ihm zu folgen. Dies widerspricht seinem Zweck, wird aber in anderen Fällen nützlich sein.
[Fallstudie] Erhöhen Sie die Sichtbarkeit, indem Sie die Website-Crawlbarkeit für den Googlebot verbessern
 Lesen Sie die Fallstudie
Lesen Sie die Fallstudie
Sie haben das Crawl-Budget erwähnt, aber was ist das?
Angenommen, Sie haben eine Website, die von Suchmaschinen entdeckt wurde. Sie kommen regelmäßig, um zu sehen, ob Sie Aktualisierungen an Ihrer Website vorgenommen und neue Seiten erstellt haben.
Jede Website hat ihr eigenes Crawling-Budget, das von mehreren Faktoren abhängt, wie z. B. der Anzahl der Seiten Ihrer Website und ihrer Integrität (z. B. wenn sie viele Fehler enthält). Sie können sich schnell einen Überblick über Ihr Crawl-Budget verschaffen, indem Sie sich in die Search Console einloggen.
Ihr Crawl-Budget legt die Anzahl der Seiten fest, die ein Roboter auf Ihrer Website bei jedem Besuch durchsucht. Sie ist proportional mit der Anzahl der Seiten verknüpft, die Sie auf Ihrer Website haben, und sie wurde bereits gecrawlt. Einige Seiten werden häufiger gecrawlt als andere, insbesondere wenn sie regelmäßig aktualisiert oder von wichtigen Seiten verlinkt werden.
Zum Beispiel ist Ihr Zuhause Ihr Haupteinstiegspunkt, der sehr oft gecrawlt wird. Wenn Sie einen Blog oder eine Kategorieseite haben, werden diese oft gecrawlt, wenn sie mit der Hauptnavigation verlinkt sind. Ein Blog wird auch oft gecrawlt, da es regelmäßig aktualisiert wird. Ein Blogbeitrag wird möglicherweise häufig gecrawlt, wenn er zum ersten Mal veröffentlicht wird, aber nach ein paar Monaten wird er wahrscheinlich nicht mehr aktualisiert.
Je öfter eine Seite gecrawlt wird, desto wichtiger ist sie für einen Roboter im Vergleich zu anderen. Dies ist der Zeitpunkt, an dem Sie anfangen müssen, an der Optimierung Ihres Crawl-Budgets zu arbeiten.
Optimierung Ihres Crawl-Budgets
Um Ihr Budget zu optimieren und sicherzustellen, dass Ihre wichtigsten Seiten die Aufmerksamkeit erhalten, die sie verdienen, können Sie Ihre Serverprotokolle analysieren und nachsehen, wie Ihre Website gecrawlt wird:
- Wie häufig werden Ihre Top-Seiten gecrawlt?
- Können Sie sehen, dass weniger wichtige Seiten häufiger gecrawlt werden als andere, die wichtiger sind?
- Erhalten Roboter beim Crawlen Ihrer Website häufig einen 4xx- oder 5xx-Fehler?
- Treffen Roboter auf Spinnenfallen? (Matthew Henry hat einen tollen Artikel darüber geschrieben)
Durch die Analyse Ihrer Protokolle sehen Sie, welche Seiten, die Sie für weniger wichtig halten, viel gecrawlt werden. Dann müssen Sie tiefer in Ihre interne Linkstruktur eintauchen. Wenn es gecrawlt wird, müssen viele Links darauf verweisen.
Sie können auch an der Behebung all dieser Fehler (4xx und 5xx) mit OnCrawl arbeiten. Es wird die Crawlbarkeit sowie die Benutzererfahrung verbessern, es ist ein Win-Win-Fall.
Krabbeln VS Scraping?
Krabbeln und Kratzen sind zwei verschiedene Dinge, die für unterschiedliche Zwecke verwendet werden. Das Crawlen einer Website bedeutet, auf einer Seite zu landen und den Links zu folgen, die Sie finden, wenn Sie den Inhalt scannen. Ein Crawler wechselt dann zu einer anderen Seite und so weiter.
Scraping hingegen scannt eine Seite und sammelt bestimmte Daten von der Seite: Titel-Tag, Meta-Beschreibung, h1-Tag oder einen bestimmten Bereich Ihrer Website wie eine Preisliste. Scraper agieren normalerweise als „Menschen“, sie ignorieren alle Regeln aus der robots.txt-Datei, legen Formulare ab und verwenden einen Browser-Benutzeragenten, um nicht entdeckt zu werden.
Suchmaschinen-Crawler fungieren normalerweise als Scraper, da sie Daten sammeln müssen, um sie für ihren Ranking-Algorithmus zu verarbeiten. Sie suchen nicht nach bestimmten Daten im Vergleich zu Scrapper, sie verwenden einfach alle verfügbaren Daten auf der Seite und noch mehr (Ladezeit ist etwas, das Sie von einer Seite nicht bekommen können). Suchmaschinen-Crawler identifizieren sich immer als Crawler, damit der Eigentümer einer Website weiß, wann er seine Website zuletzt besucht hat. Dies kann sehr hilfreich sein, wenn Sie echte Benutzeraktivitäten verfolgen.
Nachdem Sie nun etwas mehr über Crawling wissen, wie es funktioniert und warum es wichtig ist, besteht der nächste Schritt darin, mit der Analyse von Serverprotokollen zu beginnen. Dadurch erhalten Sie tiefe Einblicke, wie Roboter mit Ihrer Website interagieren, welche Seiten sie häufig besuchen und auf wie viele Fehler sie beim Besuch Ihrer Website stoßen.
Weitere technische und historische Informationen über Webcrawler finden Sie unter „Eine kurze Geschichte der Webcrawler“.