
So optimieren Sie Ihr Crawl-Budget
Veröffentlicht: 2017-07-05Im Mai haben wir ein Webinar auf Französisch zum Crawling-Budget von Google abgehalten. Für sein zweites Webinar mit OnCrawl stellt Erle Alberton, ehemaliger SEO-Leiter von Orange & Sosh (einem französischen Internetanbieter) und jetzt Customer Success Manager für OnCrawl, das Crawl-Budget-Konzept, Best Practices zu seiner Optimierung, was zu vermeiden ist usw. vor. Praktisch Beispiele veranschaulichen dieses Konzept, das kürzlich vom Google-Team bestätigt wurde.
Was Google über das Crawl-Budget sagt
Mitte Januar veröffentlichte Google einen Artikel in seinem Blog , in dem es heißt: „Wir haben keinen einzigen Begriff, der alles beschreiben würde, wofür „Crawl-Budget“ extern steht. “ Mit anderen Worten, was wir SEOs als Crawl-Budget betrachten.
Der Webgigant gibt außerdem an, dass Sie sich um das Crawl-Budget keine Gedanken machen müssen, wenn Ihre neuen Seiten normalerweise am selben Tag ihrer Veröffentlichung gecrawlt werden. Es heißt auch, dass eine Website, die weniger als ein paar tausend URLs hat, korrekt gecrawlt wird, da das Crawl-Budget normalerweise für Websites mit hohem Volumen reserviert ist… Dies ist sowohl richtig als auch falsch, da alle Websites in der Google Search Console ein Crawl-Budget haben. Wir können dies leicht in den Google-Metriken sehen.
Wir erfahren in diesem Artikel auch, dass Google versucht, ein „Crawl Rate Limit“ zu erreichen, das die maximale Abrufrate für eine bestimmte Website begrenzt. Wir können sehen, dass Google beispielsweise bei einer zu langen Ladezeit sein Budget fast um 2 kürzt. Allerdings gibt es Faktoren, die sich auf das Crawl-Budget auswirken können, wie z. B. schlechte Architektur (System, Statuscodes, interne Struktur ), schlechter und / oder doppelter Inhalt, Spinnenfallen usw.
Wie funktioniert das Crawl-Budget von Google?
Das Crawlen von Google besteht aus einer Reihe einfacher Schritte, die rekursiv für jede Website ausgeführt werden. Hier ist ein Diagramm von Google, in dem wir sehen, dass der Crawl mit einem Treffer auf einem TXT-Roboter beginnt und sich dann in eine Reihe von URLs aufteilt, die in einer Liste zusammengestellt werden. Anschließend versucht Google, sie abzurufen, während es mit den URLs vergleicht, die er bereits kennt, zusätzlich zu denen, die er bereits im Backup hat.
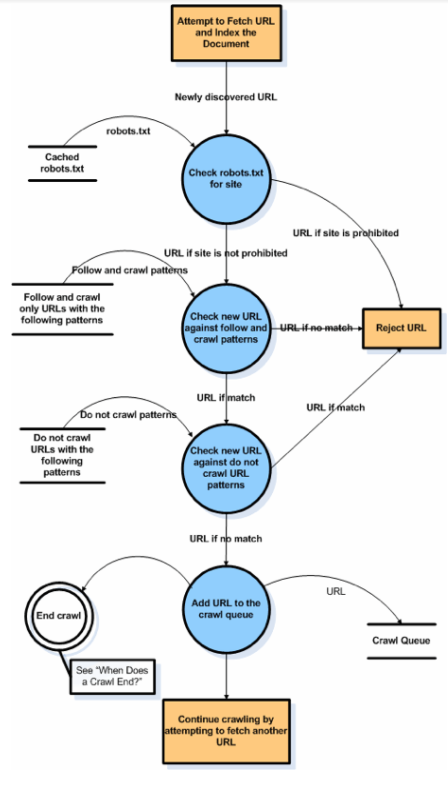
Sein Ziel ist es, seinen Index vollständig und genau zu vervollständigen. Wir sehen, dass Google, selbst wenn die Website in JavaScript ist, Crawler der dritten Ebene sendet. Bei JavaScript-Seiten sollten Sie dennoch vorsichtig sein, da diese viele Bot-Ressourcen verbrauchen und im Schnitt nur einmal im Quartal versendet werden. Wir müssen unsere Methode überdenken, damit Google Zugriff auf Seiten außerhalb einer JavaScript-Navigation hat.
Google überprüft dann den Status der Seitenaktualisierung (Vergleich mit zuvor indexierten Inhalten), um zu bewerten, ob die Seite wichtig oder weniger wichtig ist. Tatsächlich muss Google seine Crawling-Ressourcen optimieren, da es nicht jede Seite aller Websites crawlen kann. Es heißt Seitenwichtigkeit… es ist eine sehr wichtige Punktzahl, der zu folgen ist und die wir weiter unten im Detail sehen werden!
Tatsache: Wenn Google optimiert, dann weil es einen Grund gibt
Das Crawling-Budget hängt ab von:
- Die Fähigkeit der Website, schnell zu antworten;
- Vernunft der Site – 4xx, 5xx, 3xx (wenn eine Site anfängt, 404er oder 500er zu haben, wird das Crawl-Budget beeinträchtigt, da es immer doppelt überprüft, ob Korrekturen vorgenommen wurden);
- Inhaltsqualität – Semantik und Vollständigkeit;
- Diversität von Anchor (eine Seite gilt als wichtig, wenn sie viele Links erhält. Mit dem InRank von OnCrawl können Sie das Ganze analysieren);
- Seitenpopularität – extern und intern;
- Optimierbare Faktoren – Vereinfachen Sie das Crawlen (Reduzieren der Bildgröße, Kapazität für CSS, JS, GIF, Schriftarten usw.)
[Fallstudie] Erhöhen Sie das Crawl-Budget auf strategischen Seiten
 Lesen Sie die Fallstudie
Lesen Sie die FallstudieDie Schlüsselkomponenten von Google Page Importance
Die Definition der Seitenwichtigkeit ist nicht dasselbe wie der Seitenrang:
- Seitenposition auf der Website – Tiefe der Crawling-Rate;
- Seitenrang: TF/CF der Seite – Majestätisch;
- Interner Seitenrang – InRank von OnCrawl;
- Art des Dokuments: PDF, HTML, TXT (PDF ist normalerweise ein endgültiges qualitatives Dokument, daher wird es häufig gecrawlt);
- Aufnahme in sitemap.xml;
- Anzahl der internen Links:
- Qualität/Bedeutung des Ankers;
- Qualitativer Inhalt: Anzahl der Wörter, wenige Beinahe-Duplikate (Google bestraft ähnliche Inhalte, wenn die Seiten inhaltlich zu ähnlich sind);
- Bedeutung der „Home“-Seite.
So planen Sie das Crawlen wichtiger URLs
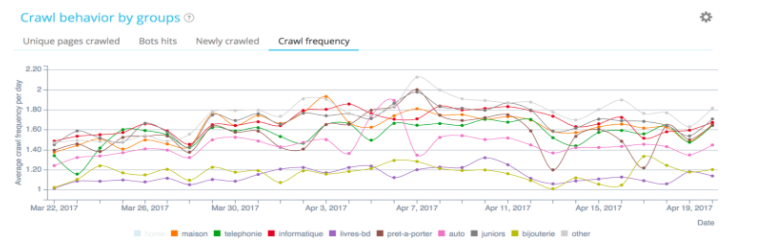
URL-Planung: Welche Seiten will Google besuchen und wie oft?
Im obigen Beispiel (Beobachtung einer Crawl-Häufigkeit derselben Website) crawlt Google nicht mit der gleichen Frequenz auf den verschiedenen Gruppen. Wir sehen, dass die Auswirkungen des Rankings schnell sichtbar werden, wenn Google einen Teil der Website durchsucht.
Weitere Informationen zum Crawl-Budget von Google
- 100 % der Websites der Google Search Console verfügen über Crawl-Daten.
- Wir können sein Crawling-Verhalten dank einer Protokollanalyse verfolgen, die Ihnen hilft, eine Anomalie im Verhalten des Bots schnell zu erkennen;
- Eine schlechte interne Struktur (Paginierung, verwaiste Seiten, Spinnenfallen) kann Google daran hindern, die richtigen Seiten zu crawlen;
- Das Crawl-Budget ist direkt mit dem Ranking verknüpft.
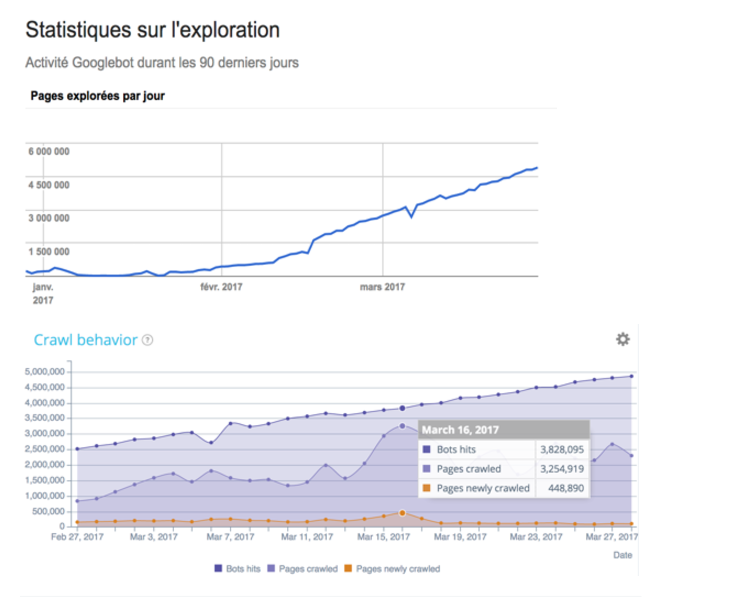
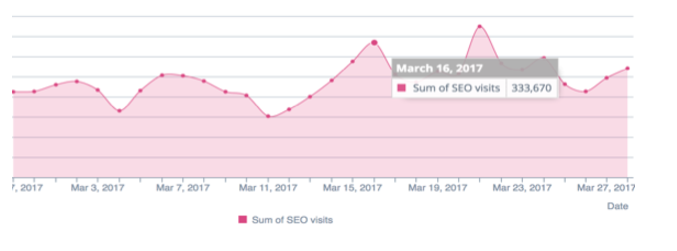
Seitengeschwindigkeit zuerst
Der wichtigste Faktor ist die Ladezeit einer Seite, da sie eine entscheidende Rolle für das Crawl-Budget spielt. Tatsächlich befinden wir uns heute in einer mobilen Welt. Ihr größtes Kapital ist daher die Ladezeit der Seite, um Ihr Crawl-Budget und Ihr SEO zu optimieren. Mit der mobilen Revolution ist die Ladezeit ein wesentlicher Faktor bei der Beurteilung der Qualität einer Website. Seine Fähigkeit, schnell zu reagieren – insbesondere für Mobile und Index Mobile First.
Um es zu optimieren, können wir CDN-Lösungen (Content Delivery Network) wie Cloudflare verwenden. Diese Lösungen ermöglichen es den Robotern von Google, so nah wie möglich an Ressourcen zu sein und Seiten so schnell wie möglich zu laden.
Google testet ständig die Fähigkeit einer Website, schnell zu reagieren. Architektur und Codierungsqualität haben einen starken Einfluss auf die Notation von Google.
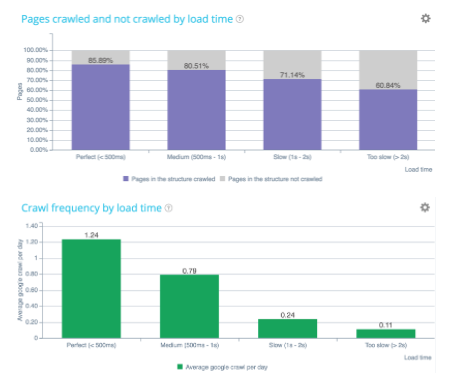

Ladezeit
Es ist der erste Allokationsfaktor des Crawl-Budgets!
In Bezug auf den Server müssen Sie:
- Umleitungen vermeiden;
- Komprimierung autorisieren;
- Reaktionszeit verbessern.
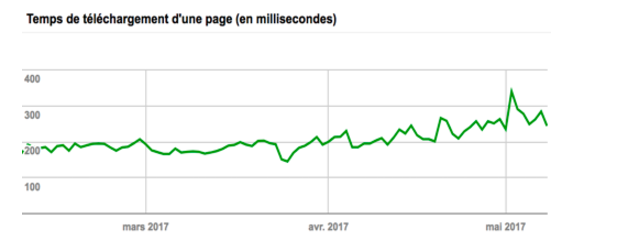
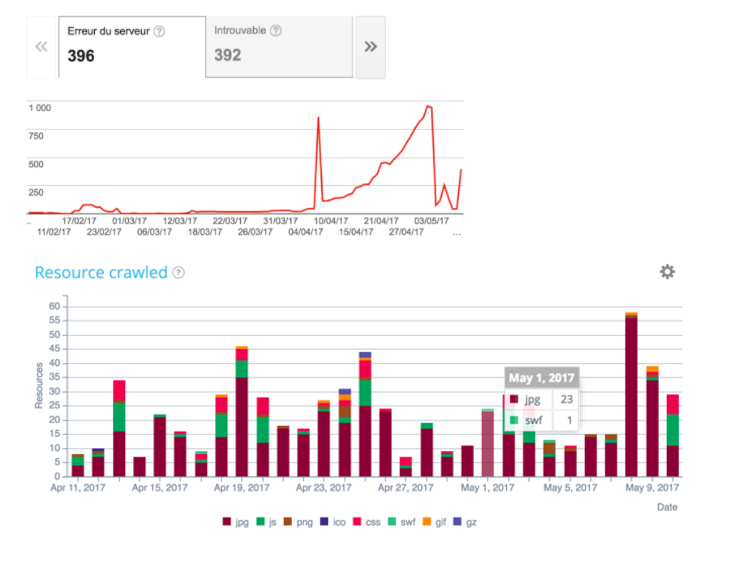
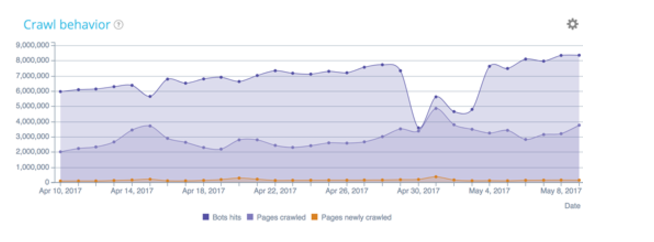
Oben ein Beispiel mit der Website von Manageo , die ein lineares Crawl-Budget hatte und bei der wir einen linearen Anstieg sehen können. Im Mai sinkt die Anzahl der pro Tag gecrawlten Seiten und damit auch die Geschwindigkeit der Website. Google stellt fest, dass die Website weniger schnell reagiert, sodass das Crawling-Budget halbiert wird. Um all dies zu korrigieren, müssen Sie Ihre Codes auf der Serverseite optimieren, Umleitungen reduzieren, Komprimierung verwenden und so weiter.
Von vorne gesehen müssen Sie:
- Browser-Caching betreiben
- Reduzieren Sie die Ressourcengröße (Bildoptimierung, verwenden Sie CDN/lazy loading/löschen Sie JS, das die Anzeige blockiert;
- Verwenden Sie asynchrone Skripts.
Qualitätsverlust = keine Liebe mehr = kein Budget mehr
Es ist notwendig, die Statuscodes zu überprüfen, die an die Roboter von Google zurückgesendet werden, um sicherzustellen, dass der IS sauber ist. Nur so kann Google überprüfen, ob die Qualität Ihres Codes und Ihrer Architektur sauber ist.
Die Verfolgung ihrer Entwicklung im Laufe der Zeit stellt sicher, dass Code-Updates SEO-freundlich sind. Google gibt viel für Ressourcen aus (css, img, js), also stellen Sie sicher, dass sie fehlerfrei sind.
Einzigartige und reichhaltige Inhalte
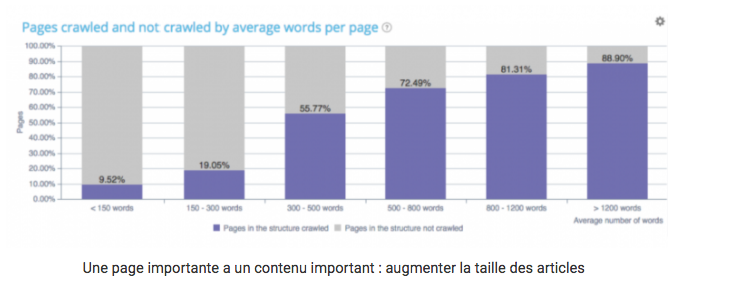
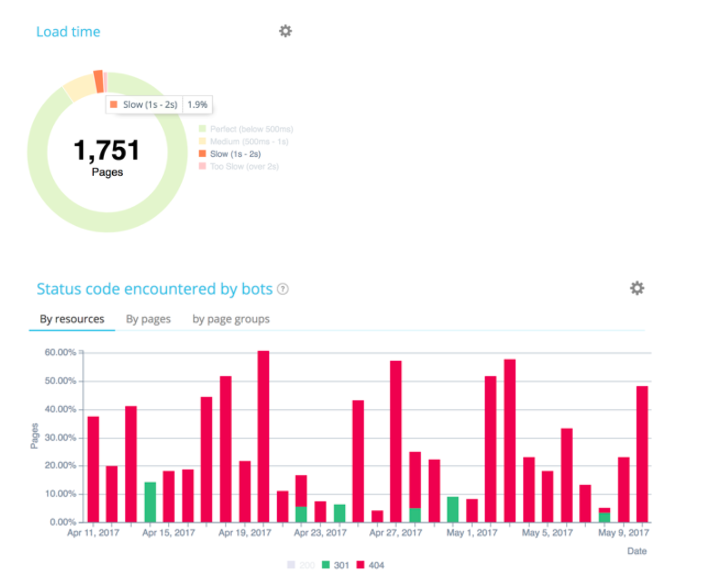
Je wichtiger eine Seite ist, desto reichhaltiger ist ihr Text. Wie oben gezeigt, hängt die Anzahl der von Google gecrawlten und nicht gecrawlten Seiten mit der Anzahl der Wörter auf der Seite zusammen. Ihre Seiten sollten daher so regelmäßig wie möglich weiterentwickelt und aktualisiert werden.
Vorsicht vor Canonicals und Duplicate Content
Google wird doppelt so viel Budget ausgeben, wenn zwei ähnliche Seiten nicht auf dieselbe kanonische URL verweisen. Daher kann die kanonische Verwaltung für Websites mit Facetten oder externen Links mit queryString kritisch werden.
Content Management in Near Duplicate und Canonicals werden zu wichtigen Aspekten der Optimierung des Crawl-Budgets.
Interne Struktur und InRank-Verteilung
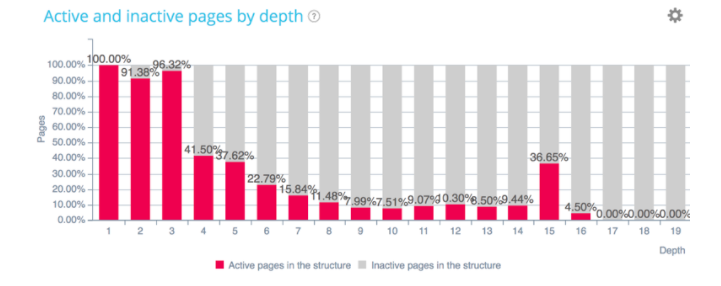
Seiten, die SEO-Besuche generieren, gelten als aktiv. Dies sind diejenigen, die sich an der Spitze der Architektur der Site befinden. Andererseits sehen wir hier, dass auf Seite 15 eine Gruppe von Seiten entsteht. Vielleicht werden diese Seiten von Ihren Benutzern viel häufiger gesucht als Sie dachten und müssten in der Architektur aktualisiert werden, um ihr Ranking zu verbessern.
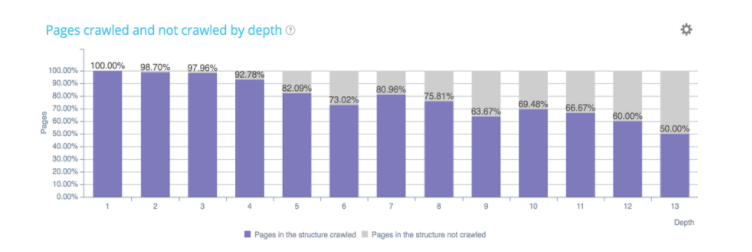
Wie wir wissen, je tiefer die Seiten sind, desto weniger wird Google sie besuchen!
Sind meine Geldseiten gut platziert?
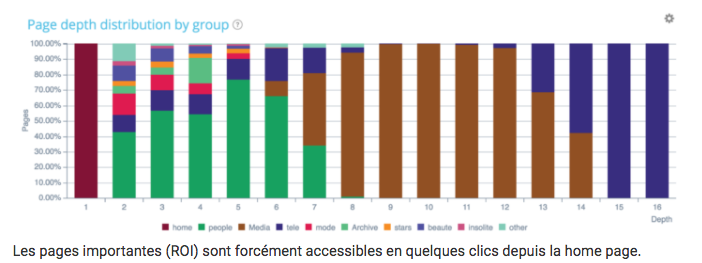
Tipp: Wenn Sie die Tiefe bestimmter Seitengruppen optimieren möchten, zögern Sie nicht, HTML-Site-Pläne zu erstellen, also Seiten, die für die Verwaltung Ihrer Tiefe entscheidend sind.
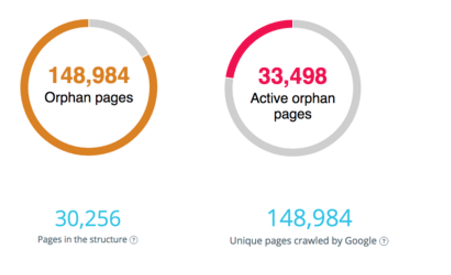
Google vergleicht die Seiten Ihrer Struktur mit den gecrawlten und den aktiven Seiten. Allerdings wäre es zu Ihrem Vorteil, das Problem verwaister Seiten zu lösen, für die Google unnötig Geld ausgibt, und die Architektur der Website so zu korrigieren, dass Links zu aktiven, aber nicht strukturierten Seiten zurückgegeben werden.
Manchmal erhalten Seiten keine Links mehr, sie werden als verwaiste Seiten bezeichnet. Andererseits hat Google sie nicht vergessen. Er wird sie weiterhin besuchen. Sie erhalten keine Links mehr, sodass sie an Bedeutung verlieren, aber im rechten Diagramm erhalten einige verwaiste Seiten weiterhin SEO-Besuche. Was Sie wissen müssen, ist, wie Sie sie schnell identifizieren und die Verknüpfungsprobleme in der Architektur beheben können. Dies ist eine großartige Möglichkeit, Ihr Crawl-Budget zu optimieren.
Fehler, von denen man sich fernhalten sollte
- robots.txt in 404;
- Sitemap.xml & sitemap.html veraltet;
- 50x / 40x / weiche 404-Fehler;
- Kettenumleitungen haben;
- Kanonische Fehler;
- Doppelter Inhalt (Fußzeile) / nahezu doppelt / HTTP vs. HTTPS;
- Zu lange Reaktionszeit;
- Seitenschwere zu wichtig;
- AMP/ Fehler. Dieses Protokoll wird von Google häufig verwendet, insbesondere für E-Commerce-Websites (nicht nur für Medien-Websites);
- Schlechte interne Verlinkung + Rel=nofollow;
- Verwendung von JS ohne andere Alternative.
Schlussfolgerungen
Um Ihr Crawl-Budget zu optimieren, müssen Sie:
- Kennen Sie Ihre Geldseiten und kennen Sie die Reaktionen von Google;
- Ladezeit verbessern;
- Optimieren Sie Ihre interne Verlinkung: Platzieren Sie alle Ihre Geldseiten ganz oben in der Struktur;
- Reparieren Sie Ihre verwaisten Seiten;
- Fügen Sie Ihren Geldseiten Text hinzu;
- Aktualisieren Sie Ihre Geldseiten in vollen Zügen – Frische;
- Reduzieren Sie Ihre schlechten Inhalte und Duplikate;
- Optimieren Sie Ihre Canonicals, Bilder und Ressourcengewichte;
- Vermeiden Sie Kettenumleitungen;
- Überwachen Sie Ihre Protokolle und reagieren Sie, wenn es Auffälligkeiten gibt (sehen Sie sich diesen Anwendungsfall von Manageo während des SEOcamp Lyon zum Thema an).
Um Ihr Crawl-Budget zu optimieren, müssen Sie den Crawler von Google genau überwachen
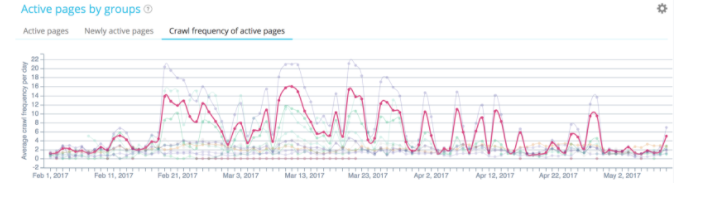
Einige Momente des Weges von Google auf Ihrer Website sind wichtiger als andere, daher müssen Sie wissen, wie Sie sie optimieren können.
Um Ihr Crawling-Budget zu optimieren, ist es notwendig, Ihre HTTPS (HTTP2)-Migration korrekt zu verwalten
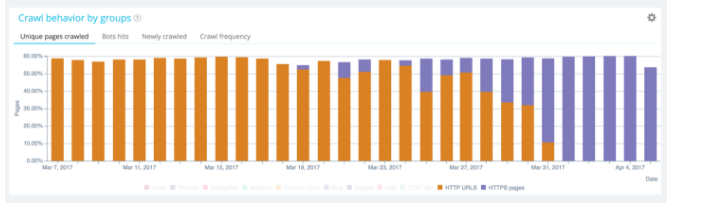
Sie müssen in der Lage sein, es zu verfolgen und zu überwachen. Fordern Sie Ihre IT-Teams auf, mit HTTPS auf HTTP2 zu migrieren.
OnCrawl hilft Ihnen, das Crawling-Budget von Google täglich zu verfolgen und zielt schnell auf Korrekturen und strukturelle Änderungen ab, um Ihre SEO-Leistung zu verbessern.
Starten Sie Ihre kostenlose 14-Tage-Testversion
 Starten Sie Ihre Testversion
Starten Sie Ihre Testversion