
Wie definiere ich das Crawl-Budget?
Veröffentlicht: 2016-09-14Wir alle sprechen als SEOs darüber, aber wie funktioniert das Crawl-Budget eigentlich? Wir wissen, dass die Anzahl der Seiten, die Suchmaschinen crawlen und indizieren, wenn sie die Websites unserer Kunden besuchen, mit ihrem Erfolg in der organischen Suche korreliert, aber ist ein größeres Crawl-Budget immer besser?
Wie alles bei Google glaube ich nicht, dass die Beziehung zwischen dem Crawl-Budget Ihrer Website und der Ranking-/SERP-Leistung zu 100 % einfach ist, sie hängt von einer Reihe von Faktoren ab.
Warum ist das Crawl-Budget wichtig? Aufgrund des Caffeine-Updates 2010. Mit diesem Update hat Google die Art und Weise, wie Inhalte indiziert werden, mit inkrementeller Indizierung neu gestaltet. Durch die Einführung des „Percolator“-Systems beseitigten sie den „Engpass“ bei der Indizierung von Seiten.
Wie bestimmt Google das Crawl-Budget?
Es dreht sich alles um Ihren PageRank, Citation Flow und Trust Flow.
Warum habe ich Domain Authority nicht erwähnt? Ehrlich gesagt ist es meiner Meinung nach eine der am meisten missbrauchten und missverstandenen Metriken, die SEOs und Content-Vermarktern zur Verfügung stehen, die ihren Platz hat, aber viel zu viele Agenturen und SEOs legen zu viel Wert darauf, insbesondere beim Linkaufbau.
PageRank ist jetzt natürlich veraltet, zumal sie die Toolbar fallen gelassen haben, also dreht sich alles um die Trust Ratio einer Seite (Trust Ratio = Trust Flow/Citation Flow). Im Wesentlichen haben die leistungsfähigeren Domains größere Crawl-Budgets. Wie identifizieren Sie also die Google-Bot-Aktivität auf Ihrer Website und vor allem alle Bot-Crawling-Probleme? Server-Log-Dateien.
Jetzt wissen wir alle, dass wir, um dem Google-Bot Seiten anzuzeigen, die wir indexiert (und eingestuft) haben, eine interne Linkstruktur verwenden und sie in der Nähe der Stammdomäne halten, nicht in 5 Unterordnern entlang der URL. Aber was ist mit eher technischen Fragen? Wie Verschwendung von Crawl-Budget, Bot-Traps oder wenn Google versucht, Formulare auf der Website auszufüllen (es passiert).
Identifizieren der Crawler-Aktivität
Dazu müssen Sie sich einige Server-Logfiles besorgen. Möglicherweise müssen Sie diese bei Ihrem Kunden anfordern oder Sie können sie direkt vom Hosting-Unternehmen herunterladen.
Die Idee dahinter ist, dass Sie versuchen möchten, eine Aufzeichnung des Google-Bots zu finden, der auf Ihre Website zugreift – aber da dies kein geplantes Ereignis ist, müssen Sie möglicherweise Daten von einigen Tagen abrufen. Es gibt verschiedene Software, um diese Dateien zu analysieren.
Unten ist ein Beispiel für einen Hit auf einen Apache-Server:
50.56.92.47 – – [31/May/2012:12:21:17 +0100] „GET“ – „/wp-content/themes/wp-theme/help.php“ – „404“ „-“ „Mozilla/ 5.0 (kompatibel; Googlebot/2.1; +http://www.google.com/bot.html)“ – www.hit-example.com
Von hier aus können Sie Tools (wie OnCrawl) verwenden, um die Protokolldateien zu analysieren und Probleme wie das Crawlen von PPC-Seiten durch Google oder unendliche GET-Anforderungen an JSON-Skripte zu identifizieren – beides kann in der Robots.txt-Datei behoben werden.
Wann ist das Crawl-Budget ein Problem?
Das Crawling-Budget ist nicht immer ein Problem, wenn Ihre Website viele URLs und eine proportionale Zuteilung von „Crawlings“ hat, ist alles in Ordnung. Aber was ist, wenn Ihre Website 200.000 URLs hat und Google jeden Tag nur 2.000 Seiten auf Ihrer Website crawlt? Es kann bis zu 100 Tage dauern, bis Google neue oder aktualisierte URLs bemerkt – das ist jetzt ein Problem.
Ein schneller Test, um festzustellen, ob Ihr Crawl-Budget ein Problem darstellt, besteht darin, die Google Search Console und die Anzahl der URLs auf Ihrer Website zu verwenden, um Ihre „Crawl-Nummer“ zu berechnen.
- Zuerst müssen Sie bestimmen, wie viele Seiten sich auf Ihrer Website befinden. Sie können dies tun, indem Sie eine Website: Suche durchführen, zum Beispiel hat oncrawl.com ungefähr 512 Seiten im Index:
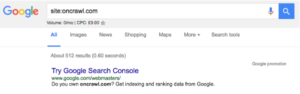

- Zweitens müssen Sie zu Ihrem Google Search Console-Konto gehen und zu Crawl und dann zu Crawl Stats gehen. Wenn Ihr GSC-Konto nicht richtig konfiguriert wurde, verfügen Sie möglicherweise nicht über diese Daten.
- Der dritte Schritt besteht darin, die durchschnittliche Anzahl der „pro Tag gecrawlten Seiten“ (die mittlere) und die Gesamtzahl der URLs auf Ihrer Website zu nehmen und sie zu teilen:
Gesamtzahl der Seiten auf der Website / Durchschnittlich gecrawlte Seiten pro Tag = X
Wenn X größer als 10 ist, müssen Sie Ihr Crawl-Budget optimieren. Wenn es weniger als 5 ist, bravo. Sie müssen nicht weiterlesen.
Optimierung Ihrer Crawl-Budget-Kapazität
Sie können das größte Crawl-Budget im Internet haben, aber wenn Sie nicht wissen, wie man es einsetzt, ist es wertlos.
Ja, es ist ein Klischee, aber es ist wahr. Wenn Google alle Seiten Ihrer Website durchsucht und feststellt, dass die überwiegende Mehrheit von ihnen doppelt oder leer ist oder so langsam lädt, dass sie Zeitüberschreitungsfehler verursachen, kann Ihr Budget genauso gut Null sein.
Um das Beste aus Ihrem Crawl-Budget herauszuholen (auch ohne Zugriff auf die Serverprotokolldateien), müssen Sie Folgendes sicherstellen:
Entfernen Sie doppelte Seiten
Auf E-Commerce-Websites können Tools wie OpenCart häufig mehrere URLs für dasselbe Produkt erstellen. Ich habe Instanzen desselben Produkts auf 4 URLs mit unterschiedlichen Unterordnern zwischen dem Ziel und dem Stamm gesehen.
Sie möchten nicht, dass Google mehr als eine Version jeder Seite indexiert, stellen Sie also sicher, dass Sie kanonische Tags verwenden, die Google auf die richtige Version verweisen.
Beheben Sie defekte Links
Verwenden Sie die Google Search Console oder Crawling-Software und finden Sie alle defekten internen und externen Links auf Ihrer Website und reparieren Sie sie. Die Verwendung von 301-Links ist großartig, aber wenn es sich um fehlerhafte Navigationslinks oder Fußzeilen-Links handelt, ändern Sie einfach die URL, auf die sie verweisen, ohne sich auf einen 301-Link zu verlassen.
Schreiben Sie keine dünnen Seiten
Vermeiden Sie viele Seiten auf Ihrer Website, die Benutzern oder Suchmaschinen wenig oder keinen Mehrwert bieten. Ohne Kontext fällt es Google schwer, die Seiten zu klassifizieren, was bedeutet, dass sie nichts zur Gesamtrelevanz der Website beitragen und nur Passagiere sind, die das Crawl-Budget in Anspruch nehmen.
Entfernen Sie 301-Umleitungsketten
Kettenumleitungen sind unnötig, chaotisch und werden missverstanden. Umleitungsketten können Ihr Crawl-Budget auf verschiedene Weise beschädigen. Wenn Google eine URL erreicht und einen 301 sieht, folgt es ihr nicht immer sofort, sondern fügt die neue URL zu einer Liste hinzu und folgt ihr dann.
Sie müssen auch sicherstellen, dass Ihre XML-Sitemap (und HTML-Sitemap) korrekt ist, und wenn Ihre Website mehrsprachig ist, stellen Sie sicher, dass Sie Sitemaps für jede Sprache der Website haben. Sie müssen auch eine intelligente Site-Architektur und URL-Architektur implementieren und Ihre Seiten beschleunigen. Es wäre auch von Vorteil, Ihre Website hinter ein CDN wie CloudFlare zu stellen.
TL;DR:
Das Crawl-Budget ist wie jedes Budget eine Gelegenheit. Theoretisch verwenden Sie Ihr Budget, um Zeit zu kaufen, die Googlebot, Bingbot und Slurp auf Ihrer Website verbringen. Es ist wichtig, dass Sie das Beste aus dieser Zeit machen.
Die Optimierung des Crawl-Budgets ist nicht einfach und sicherlich kein „schneller Gewinn“. Wenn Sie eine kleine Website oder eine mittelgroße Website haben, die gut gepflegt wird, sind Sie wahrscheinlich in Ordnung. Wenn Sie eine gigantische Website mit Zehntausenden von URLs haben und Serverprotokolldateien über Ihren Kopf gehen, ist es möglicherweise an der Zeit, die Experten hinzuzuziehen.