
Wie viele A/B-Tests sollten Sie pro Monat durchführen?
Veröffentlicht: 2023-01-19
Dies ist eine wichtige Frage, die Sie für den Erfolg Ihres Testprogramms berücksichtigen sollten.
Führen Sie zu viele Tests durch, verschwenden Sie möglicherweise Ressourcen, ohne dass einzelne Experimente viel Wert haben.
Wenn Sie jedoch zu wenige Tests durchführen, verpassen Sie möglicherweise wichtige Optimierungsmöglichkeiten, die zu mehr Conversions führen könnten.
Was ist also angesichts dieses Rätsels die ideale Testkadenz?
Um diese Frage zu beantworten, lohnt sich ein Blick auf einige der erfolgreichsten und fortschrittlichsten Experimentierteams der Welt.
Amazon ist ein solcher Name, der mir in den Sinn kommt.
Der E-Commerce-Riese ist auch ein Experimentier-Gigant. Tatsächlich soll Amazon über 12.000 Experimente pro Jahr durchführen! Diese Menge gliedert sich auf etwa tausend Experimente pro Monat.
Unternehmen wie Google und Microsofts Bing sollen ein ähnliches Tempo halten.
Laut Wikipedia führen die Suchmaschinengiganten jeweils über 10.000 A/B-Tests im Jahr oder etwa 800 Tests im Monat durch.
Und es sind nicht nur Suchmaschinen, die mit dieser Geschwindigkeit laufen.
Booking.com ist ein weiterer bemerkenswerter Name beim Experimentieren. Es wird berichtet, dass die Reisebuchungsseite über 25.000 Tests pro Jahr durchführt, was über 2.000 Tests pro Monat oder 70 Tests pro Tag entspricht!
Studien zeigen jedoch, dass das durchschnittliche Unternehmen nur 2-3 Tests pro Monat durchführt.
Wenn also die meisten Unternehmen nur wenige Tests pro Monat durchführen, einige der weltbesten jedoch Tausende von Experimenten pro Monat durchführen, wie viele Tests sollten Sie im Idealfall durchführen?
Im wahren CRO-Stil lautet die Antwort: Es kommt darauf an.
Wovon hängt es ab? Eine Reihe wichtiger Faktoren, die Sie berücksichtigen müssen.
Die ideale Anzahl der durchzuführenden A/B-Tests wird durch die spezifische Situation und Faktoren wie Stichprobengröße, Komplexität der Testideen und verfügbare Ressourcen bestimmt.
Die 6 Faktoren, die bei der Durchführung von A/B-Tests zu berücksichtigen sind
Bei der Entscheidung, wie viele Tests pro Monat durchgeführt werden sollen, sind 6 wesentliche Faktoren zu berücksichtigen. Sie beinhalten
- Anforderungen an die Stichprobengröße
- Organisatorische Reife
- Verfügbare Ressourcen
- Komplexität von Testideen
- Zeitpläne testen
- Interaktionseffekte
Lassen Sie uns tief in jedes eintauchen.
Anforderungen an die Stichprobengröße
Bei A/B-Tests beschreibt die Stichprobengröße die Menge an Traffic, die Sie benötigen, um einen vertrauenswürdigen Test durchzuführen.
Um eine statistisch gültige Studie durchzuführen, benötigen Sie eine große, repräsentative Stichprobe von Benutzern.
Obwohl Sie theoretisch ein Experiment mit nur wenigen Benutzern durchführen können, werden Sie keine sehr aussagekräftigen Ergebnisse erzielen.
Niedrige Stichprobenumfänge können immer noch statistisch signifikante Ergebnisse liefern
Stellen Sie sich zum Beispiel einen A/B-Test vor, bei dem nur 10 Benutzer gesehen haben, wie Version A und 2 konvertiert wurden. Und nur 8 Benutzer sahen Version B mit 6, die konvertierten.
Wie diese Grafik zeigt, sind die Ergebnisse statistisch signifikant:
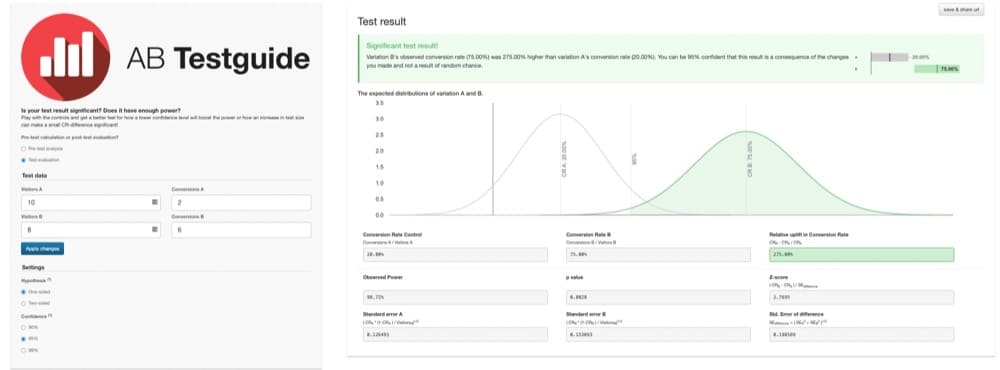
Version B scheint um 275 % besser zu sein. Aber diese Ergebnisse sind nicht sehr vertrauenswürdig. Die Stichprobengröße ist zu gering, um aussagekräftige Ergebnisse zu liefern.
Die Studie ist zu schwach. Es enthält keine große, repräsentative Stichprobe von Benutzern.
Da der Test zu schwach ist, sind die Ergebnisse fehleranfällig. Und es ist nicht klar, ob das Ergebnis nur zufällig zustande kam oder ob eine Version wirklich überlegen ist.
Bei dieser kleinen Stichprobe kann man leicht falsche Schlüsse ziehen.
Tests mit richtiger Stromversorgung
Um diese Falle zu überwinden, müssen A/B-Tests mit einer großen, repräsentativen Stichprobe von Benutzern angemessen unterstützt werden.
Wie groß ist groß genug?
Diese Frage kann durch einige einfache Berechnungen der Stichprobengröße beantwortet werden.
Um Ihre Anforderungen an die Stichprobengröße am einfachsten zu berechnen, empfehle ich die Verwendung eines Stichprobengrößenrechners. Es gibt viele von ihnen da draußen.
Mein Favorit ist das von Evan Miller, weil es flexibel und gründlich ist. Plus, wenn Sie verstehen können, wie man es benutzt, können Sie fast jeden Taschenrechner da draußen verstehen.
So sieht der Taschenrechner von Evan Miller aus:
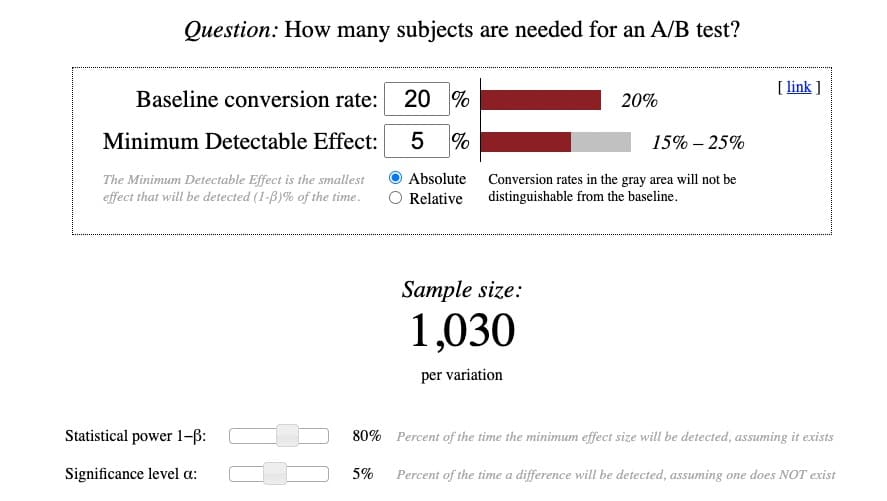
Während die Berechnungen selbst ziemlich einfach sind, ist es das Verständnis der Terminologie dahinter nicht. Also habe ich versucht, den Komplex zu verdeutlichen:
Baseline-Conversion-Rate
Die Baseline-Conversion-Rate ist die vorhandene Conversion-Rate der Kontroll- oder Originalversion. Beim Einrichten eines A/B-Tests wird es normalerweise als „Version A“ bezeichnet.
Sie sollten diese Konversionsrate in Ihrer Analyseplattform finden können.
Wenn Sie noch nie einen A/B-Test durchgeführt haben oder die Baseline-Conversion-Rate nicht kennen, raten Sie nach bestem Wissen und Gewissen.
Die durchschnittliche Konversionsrate liegt bei den meisten Websites, Branchen und Gerätetypen zwischen 2 und 5 %. Wenn Sie sich also bezüglich Ihrer Basis-Conversion-Rate wirklich nicht sicher sind, gehen Sie auf Nummer sicher und beginnen Sie mit einer Basislinie von 2 %.
Je niedriger die Baseline-Conversion-Rate ist, desto größer ist die Stichprobengröße, die Sie benötigen. Und umgekehrt.
Minimal nachweisbarer Effekt (MDE)
Minimum Detectable Effect (MDE) klingt nach einem komplizierten Konzept. Viel verständlicher wird es aber, wenn man den Begriff in seine drei Teile zerlegt:
- Minimum = am kleinsten
- Detectable = wollen Sie zu erkennen oder zu finden versuchen, indem Sie das Experiment ausführen
- Wirkung = Konversionsdifferenz zwischen der Kontrolle und der Behandlung
Daher ist der minimal erkennbare Effekt die kleinste Conversion-Steigerung, die Sie durch die Ausführung des Tests zu erkennen hoffen.
Einige Datenpuristen werden argumentieren, dass diese Definition tatsächlich den minimalen Zinseffekt (MEI) beschreibt. Wie auch immer Sie es nennen möchten, das Ziel ist es, vorherzusagen, wie groß die Conversion-Steigerung ist, die Sie durch die Durchführung des Tests erwarten.
Auch wenn sich diese Übung sehr spekulativ anfühlen kann, können Sie einen Stichprobengrößenrechner wie diesen oder den A/B-Test-Statistikrechner von Convert verwenden, um den erwarteten MDE zu berechnen.
Als sehr allgemeine Faustregel gelten 2-5 % MDE als angemessen. Alles, was viel höher ist, ist normalerweise unrealistisch, wenn ein wirklich richtiger Test durchgeführt wird.
Je kleiner die MDE, desto größer die benötigte Stichprobengröße. Und umgekehrt.
Ein MDE kann als absoluter oder relativer Betrag ausgedrückt werden.
Absolut
Ein absoluter MDE ist die rohe Zahlendifferenz zwischen der Konversionsrate der Kontrolle und der Variante.
Wenn die Basis-Conversion-Rate beispielsweise 2,77 % beträgt und Sie davon ausgehen, dass die Variante einen absoluten MDE von +3 % erzielt, beträgt die absolute Differenz 5,77 %.
Relativ
Ein relativer Effekt drückt dagegen den prozentualen Unterschied zwischen den Varianten aus.
Wenn die Basis-Conversion-Rate beispielsweise 2,77 % beträgt und Sie davon ausgehen, dass die Variante einen relativen MDE von +3 % erzielt, beträgt die relative Differenz 2,89 %.
Im Allgemeinen verwenden die meisten Experimentatoren eine relative prozentuale Steigerung, daher ist es in der Regel am besten, die Ergebnisse auf diese Weise darzustellen.
Statistische Aussagekraft 1−β
Potenz bezieht sich auf die Wahrscheinlichkeit, einen Effekt oder Konversionsunterschied zu finden, vorausgesetzt, es existiert wirklich einer.
Beim Testen ist es Ihr Ziel, sicherzustellen, dass Sie über genügend Leistung verfügen, um einen Unterschied, falls vorhanden, ohne Fehler sinnvoll zu erkennen. Daher ist eine höhere Leistung immer besser. Der Nachteil ist jedoch, dass eine größere Stichprobengröße erforderlich ist.
Eine Potenz von 0,80 gilt als bewährte Standardmethode. Sie können es also als Standardbereich auf diesem Rechner belassen.
Dieser Betrag bedeutet, dass eine Wahrscheinlichkeit von 80 % besteht, dass Sie einen Effekt genau und fehlerfrei erkennen. Daher besteht nur eine Wahrscheinlichkeit von 20 %, dass Sie den Effekt nicht richtig erkennen. Ein Risiko, das es wert ist, eingegangen zu werden.
Signifikanzniveau α
Als sehr einfache Definition ist das Signifikanzniveau Alpha die Falsch-Positiv-Rate oder der Prozentsatz der Zeit, in der eine Conversion-Differenz erkannt wird – obwohl keine existiert.
Als Best Practice für A/B-Tests sollte Ihr Signifikanzniveau 5 % oder weniger betragen. Sie können es also einfach als Standard auf diesem Rechner belassen.
Ein Signifikanzniveau α von 5 % bedeutet, dass eine Wahrscheinlichkeit von 5 % besteht, dass Sie einen Unterschied zwischen der Kontrolle und der Variante finden – wenn tatsächlich kein Unterschied besteht.
Wieder ein Risiko, das es wert ist, eingegangen zu werden.
Bewertung Ihrer Anforderungen an die Stichprobengröße
Wenn Sie diese Zahlen in Ihren Rechner einstecken, können Sie jetzt sicherstellen, dass Ihre Website über genügend Traffic verfügt, um einen Test mit angemessener Leistung über einen standardmäßigen Testzeitraum von 2 bis 6 Wochen durchzuführen.
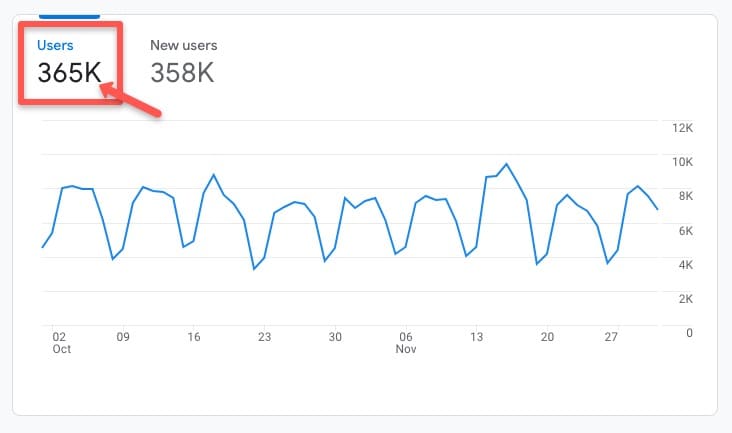
Rufen Sie zur Überprüfung Ihre bevorzugte Analyseplattform auf und sehen Sie sich die historische durchschnittliche Verkehrsrate der Website oder Seite, die Sie testen möchten, über einen begrenzten Zeitraum an.
In diesem Google Analytics 4 (GA4)-Konto können Sie beispielsweise auf der Registerkarte Lebenszyklus > Akquisition > Akquisitionsübersicht sehen, dass es im letzten historischen Zeitraum zwischen Oktober und November 2022 365.000 Benutzer gab:
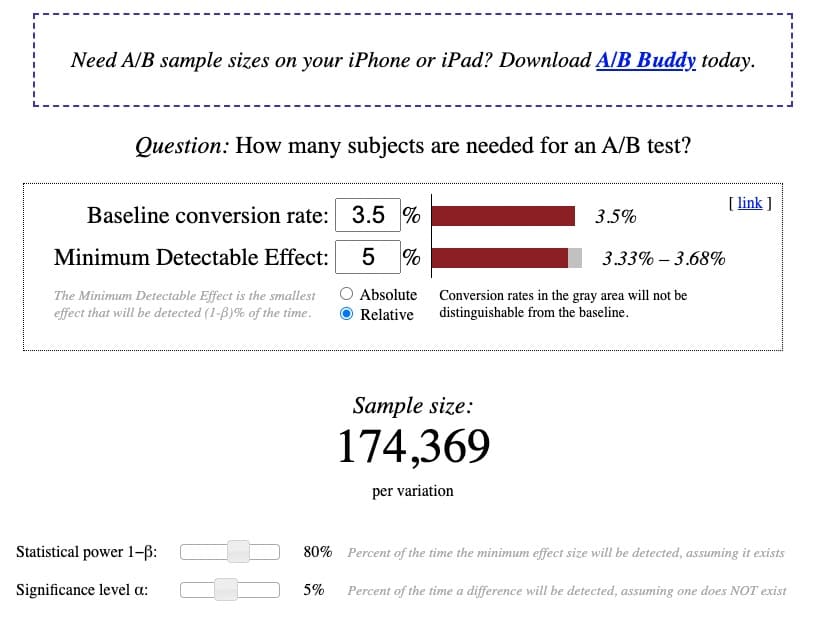
Basierend auf einer bestehenden Baseline-Conversion-Rate von 3,5 %, mit 5 % relativer MDE, bei einer Standard-Power von 80 % und einem Standard-Signifikanzniveau von 5 % zeigt der Rechner, dass eine Stichprobengröße von 174.369 Besuchern pro Variante erforderlich ist, um eine ordnungsgemäße Powered A/B-Test:
Unter der Annahme, dass die Verkehrstrends in den kommenden Monaten relativ stabil bleiben, ist davon auszugehen, dass die Website innerhalb eines angemessenen Testzeitraums etwa 365.000 Benutzer oder (365.000/2 Varianten) 182.000 Besucher pro Variante erreichen wird.
Die Anforderungen an die Stichprobengröße sind erreichbar, was grünes Licht für die Durchführung des Tests gibt.
Ein wichtiger Hinweis: Diese Überprüfung der Stichprobengröße sollte immer VOR der Durchführung einer Studie durchgeführt werden, damit Sie wissen, ob Sie genügend Datenverkehr haben, um einen Test mit angemessener Leistung durchzuführen.
Darüber hinaus sollten Sie bei der Durchführung des Tests den Test NIEMALS anhalten, bevor Sie Ihre vorberechneten Anforderungen an die Stichprobengröße erreicht haben – selbst wenn die Ergebnisse früher signifikant erscheinen.
Das vorzeitige Erklären eines Gewinners oder Verlierers, bevor die Anforderungen an die Stichprobengröße erfüllt sind, wird als „Peeking“ bezeichnet und ist eine gefährliche Testpraxis, die dazu führen kann, dass Sie falsche Entscheidungen treffen, bevor die Ergebnisse vollständig gelöscht sind.
Wie viele Tests können Sie durchführen, wenn Sie genug Traffic haben?
Angenommen, die Website oder Seite(n), die Sie testen möchten, erfüllen die Anforderungen an die Stichprobengröße, wie viele Tests können Sie ausführen?
Die Antwort ist, wieder, es kommt darauf an.
Laut einer Präsentation von Ronny Kohavi, dem ehemaligen Vizepräsidenten für Experimente bei Microsofts Bing, führt Microsoft normalerweise über 300 Experimente pro Tag durch.
Aber sie haben den Verkehr, um es zu tun.
Jedes Experiment sieht über 100.000 Benutzer:

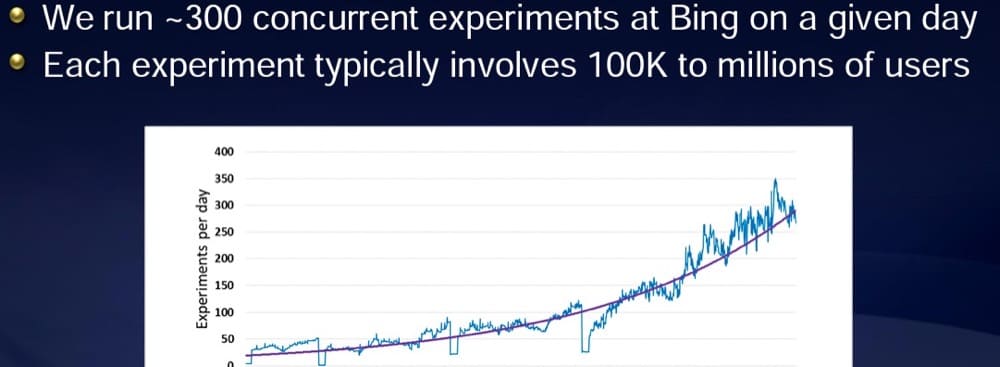
Je größer Ihr verfügbarer Datenverkehr ist, desto mehr Tests können Sie ausführen.
Bei jedem Test müssen Sie sicherstellen, dass Sie über eine ausreichend große Stichprobengröße verfügen, um ein Experiment mit ausreichender Leistung durchzuführen.
Wenn Sie eine kleinere Organisation mit begrenztem Datenverkehr sind, sollten Sie weniger qualitativ hochwertige Tests in Betracht ziehen.
Letztendlich geht es nicht wirklich darum, wie viele Tests Sie durchführen, sondern um das Ergebnis Ihrer Experimente.
Optionen, wenn Sie die Anforderungen an die Stichprobengröße nicht erfüllen können
Machen Sie sich keine Sorgen, wenn Sie feststellen, dass Sie die Anforderungen an die Stichprobengröße nicht erfüllen können. Experimentieren ist für Sie nicht vom Tisch. Ihnen stehen einige potenzielle Experimentiermöglichkeiten zur Verfügung:
- Konzentrieren Sie sich auf die Traffic-Erfassung
Selbst große Websites können auf bestimmten Seiten wenig Verkehr haben.
Wenn Sie feststellen, dass Website-Traffic oder Traffic auf bestimmten Seiten die Anforderungen an die Stichprobengröße nicht erfüllt, sollten Sie Ihre Bemühungen auf die Gewinnung von mehr Traffic konzentrieren.
Um dies zu erreichen, können Sie aggressive SEO-Taktiken (Search Engine Optimization) anwenden, um in Suchmaschinen einen höheren Rang einzunehmen und mehr Klicks zu erhalten.
Sie können auch bezahlten Traffic über Kanäle wie Google Ads, LinkedIn-Anzeigen oder sogar Bannerwerbung erwerben.
Diese beiden Akquisitionsaktivitäten können dazu beitragen, den Web-Traffic zu steigern und Ihnen eine stärkere Möglichkeit zu geben, zu testen, was bei den Benutzern am besten konvertiert.
Wenn Sie jedoch bezahlten Traffic verwenden, um die Anforderungen an die Stichprobengröße zu erfüllen, sollten Sie die Testergebnisse nach Traffic-Typ segmentieren, da das Besucherverhalten je nach Traffic-Quelle unterschiedlich sein kann.
- Beurteilen Sie, ob A/B-Tests die beste Experimentiermethode für Sie sind
Während A/B-Tests als Goldstandard des Experimentierens gelten, sind die Ergebnisse nur so gut wie die Daten dahinter.
Wenn Sie feststellen, dass Sie nicht genug Traffic haben, um einen angemessenen Test durchzuführen, sollten Sie überlegen, ob A/B-Tests wirklich die beste Experimentieroption für Sie sind.
Es gibt andere forschungsbasierte Ansätze, die viel kleinere Stichproben erfordern und dennoch unglaublich wertvolle Erkenntnisse zur Optimierung liefern können.
User Experience (UX)-Tests, Verbraucherbefragungen, Exit-Umfragen oder Kundeninterviews sind einige andere Experimentiermodalitäten, die Sie als Alternative zu A/B-Tests ausprobieren können.
- Realise-Ergebnisse können nur Richtungsdaten liefern
Aber wenn Sie weiterhin A/B-Tests durchführen möchten, können Sie trotzdem Tests durchführen.
Denken Sie nur daran, dass die Ergebnisse möglicherweise nicht ganz genau sind und nur „Richtungsdaten“ liefern, die das wahrscheinliche – und nicht das vollständig vertrauenswürdige – Ergebnis anzeigen.
Da die Ergebnisse möglicherweise nicht ganz zutreffen, sollten Sie den Conversion-Effekt im Laufe der Zeit genau überwachen.
Was jedoch oft wichtiger ist als genaue Conversion-Zahlen, sind die Zahlen auf dem Bankkonto. Wenn sie steigen, wissen Sie, dass Ihre Optimierungsarbeit funktioniert.
Prüfung der Reife
Neben den Anforderungen an die Stichprobengröße ist ein weiterer Faktor, der die Testfrequenz beeinflusst, der Reifegrad der Testorganisation.
Testreife ist ein Begriff, der verwendet wird, um zu beschreiben, wie tief das Experimentieren in einer Organisationskultur verankert ist und wie fortgeschritten die Experimentierpraktiken sind.
Organisationen wie Amazon, Google, Bing und Booking – die jeden Monat Tausende von Tests durchführen – haben fortschrittliche, ausgereifte Testteams.
Das ist kein Zufall.
Die Testfrequenz ist in der Regel eng mit dem Reifegrad einer Organisation verknüpft.
Wenn das Experimentieren in der Organisation verwurzelt ist, verpflichtet sich das Management dazu. Außerdem werden Mitarbeiter im gesamten Unternehmen in der Regel ermutigt, Experimente zu unterstützen und zu priorisieren, und können sogar dabei helfen, Testideen bereitzustellen.
Wenn diese Faktoren zusammenkommen, ist es viel einfacher, ein sinnvolles Testprogramm durchzuführen.
Wenn Sie das Testen intensivieren möchten, kann es hilfreich sein, sich zunächst den Reifegrad Ihrer Organisation anzusehen.
Beginnen Sie mit der Bewertung von Fragen wie
- Wie wichtig ist Experimentieren für die C-Suite?
- Welche Ressourcen werden bereitgestellt, um das Experimentieren zu fördern?
- Welche Kommunikationskanäle stehen zur Verfügung, um Testaktualisierungen mitzuteilen?
Wenn die Antwort „keine“ oder nahe daran ist, sollten Sie zunächst daran arbeiten, eine Testkultur zu schaffen.
Wenn Ihre Organisation eine progressivere Kultur des Experimentierens annimmt, wird es natürlich einfacher, die Testfrequenz zu erhöhen.
Für Vorschläge, wie Sie eine Kultur des Experimentierens schaffen können, sehen Sie sich Ressourcen wie diesen Artikel und diesen an.
Ressourcenbeschränkungen
Angenommen, Sie haben bereits ein gewisses Maß an organisatorischem Buy-in, ist das nächste Problem, das es zu bekämpfen gilt, Ressourcenbeschränkungen.
Zeit, Geld und menschliche Kraft sind Einschränkungen, die Ihre Testfähigkeit einschränken können. Und schnell testen.
Um Ressourcenengpässe zu überwinden, kann es hilfreich sein, mit der Bewertung der Testkomplexität zu beginnen.
Balancieren Sie einfache und komplexe Tests
Als Experimentator können Sie Tests durchführen, die von super einfach bis verrückt komplex reichen.
Einfache Tests können das Optimieren von Elementen wie Text oder Farbe, das Aktualisieren von Bildern oder das Verschieben einzelner Elemente auf einer Seite umfassen.
Bei komplexen Tests können mehrere Elemente geändert, die Seitenstruktur geändert oder der Conversion-Funnel aktualisiert werden. Diese Art von Tests erfordert oft Deep-Coding-Arbeit.
Durch die Durchführung von Tausenden von A/B-Tests habe ich festgestellt, dass es nützlich ist, jederzeit eine Mischung aus etwa ⅗ einfacheren und ⅖ komplexeren Tests gleichzeitig laufen zu lassen.
Einfachere Tests können Ihnen schnelle und einfache Erfolge bescheren.
Aber größere Tests mit größeren Änderungen führen oft zu größeren Effekten. Laut einigen Optimierungsforschungen ist der Erfolg umso wahrscheinlicher, je mehr und komplexere Tests Sie durchführen. Scheuen Sie sich also nicht, häufig große Swing-Tests durchzuführen.
Beachten Sie jedoch, dass Sie mehr Ressourcen für das Entwerfen und Erstellen des Tests aufwenden müssen. Und es gibt keine Garantie, dass es gewinnt.
Test basierend auf verfügbaren Humanressourcen
Wenn Sie ein Solo-CRO-Stratege sind oder mit einem kleinen Team arbeiten, sind Ihre Kapazitäten begrenzt. Ob einfach oder komplex, Sie werden vielleicht 2-5 Tests pro Monat finden, die Sie ansprechen.
Wenn Sie dagegen in einer Organisation arbeiten, die über ein engagiertes Team aus Forschern, Strategen, Designern, Entwicklern und QA-Spezialisten verfügt, haben Sie wahrscheinlich die Kapazität, Dutzende bis Hunderte von Tests pro Monat durchzuführen.
Um zu bestimmen, wie viele Tests Sie durchführen sollten, bewerten Sie die Verfügbarkeit Ihrer Personalressourcen.
Im Durchschnitt kann ein einfacher Test 3-6 Stunden dauern, um Ideen zu entwickeln, Wireframe, Design, Entwicklung, Implementierung, QA und Ergebnisse zu überwachen.
Andererseits kann ein hochkomplexer Test 15-20 Stunden aufwärts dauern.
Es gibt ungefähr 730 Stunden in einem Monat, also solltest du sehr kalkuliert sein mit den Tests und der Anzahl der Tests, die du in dieser kostbaren Zeit durchführst.
Planen und priorisieren Sie Ihre Testideen
Erwägen Sie die Verwendung eines Testpriorisierungs-Frameworks wie PIE, ICE oder PXL, um Ihnen dabei zu helfen, Ihre optimale Teststruktur abzubilden.
Diese Frameworks bieten eine quantitative Technik, um Ihre besten Testideen zu bewerten, die einfache Implementierung zu bewerten und zu beurteilen, welche Tests am wahrscheinlichsten die Conversions steigern.
Nach Durchführung dieser Bewertung sieht Ihre priorisierte Liste mit Testideen in etwa so aus:

Nachdem Ihre besten Testideen in eine Rangfolge gebracht wurden, empfiehlt es sich außerdem, eine Test-Roadmap zu erstellen, um Ihren Testzeitplan und die nächsten Schritte visuell zu planen.
Ihre Roadmap könnte in etwa so aussehen:
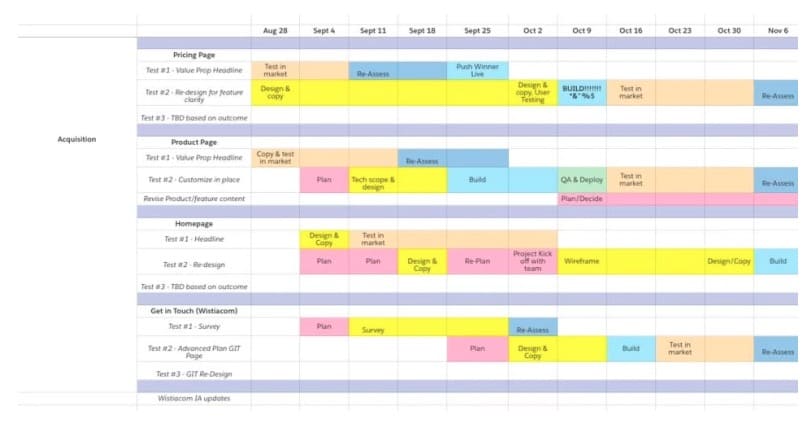
Es sollte enthalten:
- Die Liste der Ideen, die Sie testen möchten, nach Seite.
- Wie lange Sie voraussichtlich jede Testphase (Design, Entwicklung, QA usw.) dauern werden.
- Wie lange Sie planen, jeden Test auszuführen, basierend auf den vorberechneten Anforderungen an die Stichprobengröße. Sie können die Anforderungen an die Testdauer mit einem Testdauerrechner wie diesem berechnen.
Indem Sie Ihre Testideen ausarbeiten, können Sie die Testfrequenz und -kapazität genauer bestimmen.
Wenn Sie Ihre Test-Roadmap ausfüllen, wird möglicherweise sehr deutlich, dass die Anzahl der Tests, die Sie ausführen können, von den verfügbaren Ressourcen abhängt.
Sollten Sie mehrere Tests gleichzeitig ausführen?
Aber nur weil Sie etwas tun können, heißt das nicht immer, dass Sie es tun sollten.
Wenn es darum geht, mehrere Tests gleichzeitig durchzuführen, gibt es große Diskussionen über den besten Ansatz.
Artikel wie dieser von Rommil Santiago, dem Leiter von Experiment Nation, werfen eine umstrittene Frage auf: Ist es in Ordnung, mehrere A/B-Tests gleichzeitig durchzuführen?
Einige Experimentatoren werden sagen, absolut nicht!
Sie werden argumentieren, dass Sie immer nur einen Test, eine Seite auf einmal, ausführen sollten. Andernfalls können Sie keinen Effekt richtig isolieren.
Ich war früher in diesem Lager, weil mir das vor fast einem Jahrzehnt beigebracht wurde.
Mir wurde streng gesagt, dass Sie immer nur einen Test mit einer Änderung auf einer Seite gleichzeitig durchführen sollten. Ich habe viele Jahre lang mit dieser Denkweise gearbeitet – sehr zum Entsetzen besorgter Kunden, die schneller mehr Ergebnisse wollten.
Dieser Artikel von Timothy Chan, einem ehemaligen Datenwissenschaftler bei Facebook und jetzt leitender Datenwissenschaftler bei Statsig, hat meine Meinung jedoch komplett geändert.
In seinem Artikel, argumentiert Chan, werden Interaktionseffekte völlig überschätzt.
Tatsächlich ist die gleichzeitige Ausführung mehrerer Tests nicht nur kein Problem; Es ist wirklich die einzige Möglichkeit zu testen!
Diese Haltung wird durch Daten aus seiner Zeit bei Facebook gestützt, wo Chan sah, wie der Social-Media-Riese Hunderte von Experimenten gleichzeitig erfolgreich durchführte, viele davon sogar auf derselben Seite.
Datenexperten wie Ronny Kohavi und Hazjier Pourkhalkhali sind sich einig: Interaktionseffekte sind höchst unwahrscheinlich. Und in der Tat ist der beste Weg, um den Erfolg zu testen, mehrere Tests zu mehreren Zeiten und auf kontinuierlicher Basis durchzuführen.
Wenn Sie also die Testfrequenz in Betracht ziehen, machen Sie sich keine Gedanken über den Interaktionseffekt sich überschneidender Tests. Testen Sie großzügig.
Zusammenfassung
Bei A/B-Tests gibt es keine optimale Anzahl von A/B-Tests, die Sie durchführen sollten.
Die ideale Zahl ist die richtige für Ihre individuelle Situation.
Diese Zahl basiert auf mehreren Faktoren, darunter die Beschränkungen der Stichprobengröße Ihrer Website, die Komplexität der Testideen sowie der verfügbare Support und die verfügbaren Ressourcen.
Am Ende geht es nicht so sehr um die Anzahl der durchgeführten Tests, sondern um die Qualität der Tests und der erzielten Ergebnisse. Ein einzelner Test, der einen großen Auftrieb bringt, ist viel wertvoller als mehrere nicht schlüssige Tests, die die Nadel nicht bewegen.
Beim Testen geht es wirklich um Qualität statt Quantität!
Weitere Informationen dazu, wie Sie das Beste aus Ihrem A/B-Testprogramm herausholen, finden Sie in diesem Convert-Artikel.

