
So prognostizieren Sie den Umsatz aus nicht markenbezogenem organischem Traffic basierend auf der URL-Position mit Python
Veröffentlicht: 2022-05-24Was ist SEO-Prognose?
SEO-Prognose oder Schätzung des organischen Verkehrs ist der Prozess, bei dem die Daten Ihrer eigenen Website oder Daten von Drittanbietern verwendet werden, um den zukünftigen organischen Verkehr, die SEO-Einnahmen und den SEO-ROI Ihrer Website zu schätzen. Diese Schätzung kann mit vielen verschiedenen Methoden basierend auf unseren Daten berechnet werden.
In diesem Tutorial möchten wir unseren markenlosen organischen Umsatz und den markenlosen organischen Traffic basierend auf unseren URL-Positionen und ihrem aktuellen Umsatz vorhersagen. Dies kann uns als SEOs helfen, mehr Unterstützung von anderen Interessengruppen zu erhalten: von einem erhöhten monatlichen, vierteljährlichen oder jährlichen Budget bis hin zu mehr Arbeitsstunden des Produkt- und Entwicklungsteams.
Denken Sie daran, dass dieses Tutorial nicht nur für markenlosen organischen Traffic gilt; Indem Sie ein paar Änderungen vornehmen und Python kennen, können Sie damit den Traffic Ihrer Zielseiten schätzen.
Als Ergebnis können wir ein Google Sheet wie das Bild unten erstellen.
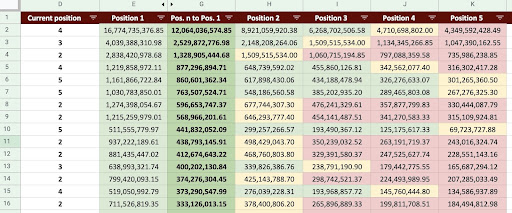
Google Sheets-Bild
Nicht markenbezogene SEO-Traffic-Prognose
Die erste Frage, die Sie nach dem Lesen der Einführung stellen können, lautet: „Warum markenlosen organischen Traffic berechnen?“.
Betrachten wir ein Unternehmen wie Amazon. Wenn Sie ein Buch oder eine Maske kaufen möchten, suchen Sie einfach nach „Maske Amazon kaufen“.
Marken stehen oft im Vordergrund, und wenn Sie etwas kaufen möchten, kaufen Sie die Dinge, die Sie benötigen, am liebsten bei diesen Unternehmen. In jeder Branche gibt es Markenunternehmen, die das Verhalten der Nutzer bei der Google-Suche beeinflussen.
Wenn wir die Daten der Google Search Console (GSC) von Amazon überprüfen würden, würden wir wahrscheinlich feststellen, dass sie viel Verkehr von Markenanfragen erhält, und meistens ist das erste Ergebnis von Markenanfragen die Website dieser Marke.
Als SEO haben Sie wie ich wahrscheinlich schon oft gehört: „Nur unsere Marke hilft unserer SEO!“ Wie können wir sagen: „Nein, das ist nicht der Fall“ und den Traffic und Umsatz von Suchanfragen ohne Marke anzeigen?
Es ist sogar noch komplizierter, dies zu beweisen, da wir wissen, dass die Algorithmen von Google so komplex sind und es schwierig ist, markenbezogene von nicht markenbezogenen Suchanfragen eindeutig zu trennen. Aber das macht unsere Arbeit als SEO umso wichtiger.
In diesem Tutorial zeige ich Ihnen, wie Sie zwischen den beiden unterscheiden können – Marken und Nicht-Marken – und zeige Ihnen, wie mächtig SEO sein kann.
Auch wenn Ihr Unternehmen keine Marke hat, können Sie dennoch viel von diesem Artikel profitieren: Sie können lernen, wie Sie die organischen Daten Ihrer Website schätzen.
SEO-ROI basierend auf Traffic-Schätzung
Egal wo Sie sind oder was Sie tun, es gibt eine Begrenzung der Ressourcen; sei es ein Budget oder einfach die Anzahl der Stunden eines Arbeitstages. Zu wissen, wie Sie Ihre Ressourcen am besten einsetzen, spielt eine wichtige Rolle für den Gesamt- und SEO-Return on Investment (ROI).
Ein CMO, ein Marketing-VP oder ein Performance-Vermarkter haben alle unterschiedliche KPIs und benötigen unterschiedliche Ressourcen, um ihre Ziele zu erreichen. Der beste Weg, um sicherzustellen, dass Sie das bekommen, was Sie brauchen, besteht darin, seine Notwendigkeit zu beweisen, indem Sie die Renditen demonstrieren, die es dem Unternehmen bringen wird. Der SEO-ROI ist nicht anders. Wenn die Budgetzuweisungszeit des Jahres näher rückt und Ihr Team ein größeres Budget anfordern möchte, kann Ihnen die Schätzung Ihres SEO-ROI bei Verhandlungen die Oberhand geben. Nachdem Sie die markenunabhängige Traffic-Schätzung berechnet haben, können Sie das erforderliche Budget zum Erreichen der gewünschten Ergebnisse besser einschätzen.
Die Auswirkung der SEO-Vorhersage auf die SEO-Strategie
Wie wir wissen, überprüfen wir alle 3 oder 6 Monate unsere SEO-Strategie und passen sie an, um die bestmöglichen Ergebnisse zu erzielen. Aber was passiert, wenn Sie nicht wissen, wo der größte Gewinn für Ihr Unternehmen liegt? Sie können Entscheidungen treffen, aber diese sind nicht so effektiv wie Entscheidungen, die getroffen werden, wenn Sie einen umfassenderen Überblick über den Traffic der Website haben.
Die Umsatzschätzung für markenlosen organischen Traffic kann mit der Segmentierung Ihrer Zielseiten und Abfragen kombiniert werden, um ein Gesamtbild zu erhalten, das Ihnen hilft, bessere Strategien als SEO-Manager oder SEO-Stratege zu entwickeln.
Die verschiedenen Möglichkeiten, organischen Traffic zu prognostizieren
In der SEO-Community gibt es viele verschiedene Methoden und öffentliche Skripte, um den zukünftigen organischen Traffic vorherzusagen.
Einige dieser Methoden umfassen:
- Organische Traffic-Prognose auf der gesamten Website
- Organische Verkehrsprognose auf bestimmten Seiten (Blog, Produkte, Kategorien usw.) oder auf einer einzelnen Seite
- Organische Traffic-Prognose für bestimmte Suchanfragen (Suchanfragen enthalten „Kaufen“, „How-To“ usw.) oder eine Suchanfrage
- Organische Verkehrsprognose für bestimmte Zeiträume (insbesondere für saisonale Ereignisse)
Meine Methode ist für bestimmte Seiten und der Zeitrahmen ist für einen Monat.
[Fallstudie] Förderung des Wachstums in neuen Märkten mit On-Page-SEO
 Lesen Sie die Fallstudie
Lesen Sie die FallstudieSo berechnen Sie den Umsatz aus organischem Traffic
Der genaue Weg basiert auf Ihren Google Analytics (GA)-Daten. Wenn Ihre Website brandneu ist, müssen Sie Tools von Drittanbietern verwenden. Ich ziehe es vor, solche Tools zu vermeiden, wenn Sie über eigene Daten verfügen.
Denken Sie daran, dass Sie die Daten von Drittanbietern, die Sie verwenden, mit einigen Ihrer echten Seitendaten vergleichen müssen, um mögliche Fehler in ihren Daten zu finden.
So berechnen Sie die Einnahmen aus nicht markenbezogenem SEO-Traffic mit Python
Bisher haben wir viele theoretische Konzepte behandelt, mit denen wir vertraut sein sollten, um die verschiedenen Aspekte unserer organischen Verkehrs- und Umsatzprognose besser zu verstehen. Jetzt tauchen wir in den praktischen Teil dieses Artikels ein.
Zuerst beginnen wir mit der Berechnung unserer CTR-Kurve. In meinem CTR-Kurven -Artikel zu Oncrawl erkläre ich zwei verschiedene Methoden und auch andere Methoden, die Sie verwenden können, indem Sie ein paar Änderungen in meinem Code vornehmen. Ich empfehle Ihnen, zuerst den Artikel zur Klickkurve zu lesen; Es gibt Ihnen Einblicke in diesen Artikel.
In diesem Artikel optimiere ich einige Teile meines Codes, um die spezifischen Ergebnisse zu erhalten, die wir bei der Traffic-Schätzung wollen. Dann erhalten wir unsere Daten von GA und verwenden die GA-Umsatzdimension, um unseren Umsatz zu schätzen.
Prognose der Einnahmen aus organischem Traffic ohne Marke mit Python: Erste Schritte
Sie können diesen Code selbst ausführen, ohne Python zu kennen. Ich bevorzuge jedoch, dass Sie ein wenig über die Python-Syntax und Grundkenntnisse über die Python-Bibliotheken wissen, die ich in diesem Prognosecode verwenden werde. Dies wird Ihnen helfen, meinen Code besser zu verstehen und ihn so anzupassen, dass er für Sie nützlich ist.
Um diesen Code auszuführen, verwende ich Visual Studio Code mit der Python-Erweiterung von Microsoft, die die Erweiterung „Jupyter“ enthält. Sie können jedoch das Jupyter-Notebook selbst verwenden.
Für den gesamten Prozess müssen wir diese Python-Bibliotheken verwenden:
- Nüppig
- Pandas
- Plotzlich
Außerdem werden wir einige Python-Standardbibliotheken importieren:
- JSON
# Importieren der Bibliotheken, die wir für unseren Prozess benötigen json importieren aus pprint import pprint importiere numpy als np pandas als pd importieren import plotly.express als px
Schritt 1: Berechnung der relativen CTR-Kurve (Relative Klickkurve)
Im ersten Schritt wollen wir unsere relative CTR-Kurve berechnen. Aber was ist die relative CTR-Kurve?
Was ist die relative CTR-Kurve?
Beginnen wir zunächst damit, über die „absolute CTR-Kurve“ zu sprechen. Wenn wir die absolute CTR-Kurve berechnen, sagen wir, dass die mittlere CTR (oder mittlere CTR) der ersten Position 36 % und die zweite Position 20 % beträgt, und so weiter.
In der relativen CTR-Kurve teilen wir den Median jeder Position durch die CTR der ersten Position. Beispielsweise wäre die relative CTR-Kurve der ersten Position 0,36 / 0,36 = 1, die zweite wäre 0,20 / 0,36 = 0,55 und so weiter.
Vielleicht fragen Sie sich, warum es sinnvoll ist, dies zu berechnen? Stellen Sie sich eine Seite vor, die an Position eins rankt und eine Klickrate von 44 % hat. Wenn diese Seite auf Position zwei wechselt, sinkt die CTR-Kurve nicht auf 20 %, sondern eher auf 44 % * 0,55 = 24,2 %.
1. Abrufen von markenbezogenen und nicht markenbezogenen organischen Verkehrsdaten von GSC
Für unseren Berechnungsprozess benötigen wir unsere Daten von GSC. Beim ersten Mal basieren alle Daten auf markenbezogenen Suchanfragen und beim nächsten Mal basieren alle Daten auf nicht markenbezogenen Suchanfragen.
Um diese Daten zu erhalten, können Sie verschiedene Methoden verwenden: aus Python-Skripten oder aus dem Google Sheets-Add-on „Search Analytics for Sheets“. Ich werde den GSC-API-Explorer verwenden.
Die Ausgabe dieser Daten sind zwei JSON-Dateien, die die Leistung jeder Seite zeigen. Eine JSON-Datei, die die Leistung der Zielseiten basierend auf markenbezogenen Abfragen anzeigt, und die andere die Leistung der Zielseiten basierend auf den nicht markenbezogenen Abfragen.
Führen Sie die folgenden Schritte aus, um Daten vom GSC-API-Explorer abzurufen:
- Gehen Sie zu https://developers.google.com/webmaster-tools/v1/searchanalytics/query.
- Maximieren Sie den API-Explorer, der sich in der oberen rechten Ecke der Seite befindet.
- Geben Sie im Feld „
siteUrl“ Ihren Domainnamen ein. Zum Beispiel „https://www.example.com“ oder „http://your-domain.com“. - Im Anfragetext müssen wir zuerst die Parameter „
startDate“ und „endDate“ definieren. Meine Präferenz sind die letzten 30 Tage. - Dann fügen wir „
dimensions“ hinzu und wählen für diese Liste „page“ aus. - Jetzt fügen wir „
dimensionFilterGroups“ hinzu, um unsere Abfragen zu filtern. Einmal für die gebrandeten und ein zweites für nicht gebrandete Suchanfragen. - Am Ende setzen wir unser „
rowLimit“ auf 25.000. Wenn die Seiten Ihrer Website, die jeden Monat organischen Traffic erhalten, mehr als 25.000 betragen, müssen Sie Ihren Anfragetext ändern. - Speichern Sie nach jeder Anforderung die JSON-Antwort. Speichern Sie für markenbezogene Leistung die JSON-Datei als „
branded_data.json“ und für nicht markenbezogene Leistung die JSON-Datei als „non_branded_data.json“.
Nachdem wir die Parameter in unserem Anfragetext verstanden haben, müssen Sie sie nur noch kopieren und unter den Anfragetext einfügen. Erwägen Sie, Ihre Markennamen durch „ brand variation names “ zu ersetzen.
Sie müssen Markennamen mit einer Pipeline oder „ | “ trennen “. Zum Beispiel „ amazon|amazon.com|amazn “.
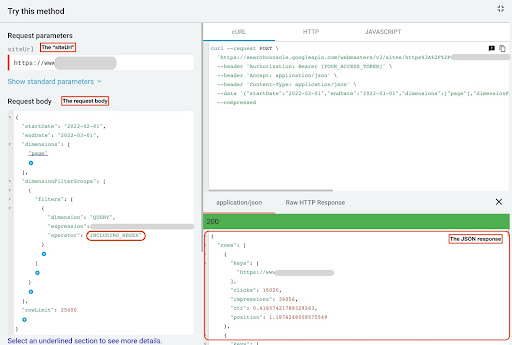
GSC-API-Explorer
Branding-Anfragetext:
{
"startDate": "2022-02-01",
"endDate": "2022-03-01",
"Maße": [
"Seite"
],
"dimensionFilterGroups": [
{
"Filter": [
{
"Dimension": "ABFRAGE",
"Ausdruck": "Namen der Markenvarianten",
"operator": "INCLUDING_REGEX"
}
]
}
],
"rowLimit": 25000
}
Nicht markenbezogener Anfragetext:
{
"startDate": "2022-02-01",
"endDate": "2022-03-01",
"Maße": [
"Seite"
],
"dimensionFilterGroups": [
{
"Filter": [
{
"Dimension": "ABFRAGE",
"Ausdruck": "Namen der Markenvarianten",
"operator": "EXCLUDING_REGEX"
}
]
}
],
"rowLimit": 25000
}
2. Importieren der Daten in unser Jupyter-Notebook und Extrahieren von Site-Verzeichnissen
Jetzt müssen wir unsere Daten in unser Jupyter-Notebook laden, um sie ändern und daraus extrahieren zu können, was wir wollen. Machen wir da weiter, wo wir oben aufgehört haben.
Um Markendaten zu laden, müssen Sie diesen Codeblock ausführen:
# Erstellen eines DataFrame für die Leistung der Website-URLs in Bezug auf die Marke und Markenabfragen
mit open(./branded_data.json") als json_file:
branded_data = json.loads(json_file.read())["rows"]
branded_df = pd.DataFrame(branded_data)
# Umbenennung der Spalte „Schlüssel“ in Spalte „Zielseite“ und Konvertieren der Liste „Zielseite“ in eine URL
branded_df.rename(columns={"keys": "landing page"}, inplace=True)
branded_df["Landingpage"] = branded_df["Landingpage"].apply(lambda x: x[0])
Für die Leistung von Zielseiten ohne Markenzeichen müssen Sie diesen Codeblock ausführen:
# Erstellen eines DataFrame für die Leistung der Website-URLs bei nicht markenbezogenen Abfragen
mit open(./non_branded_data.json") als json_file:
non_branded_data = json.loads(json_file.read())["rows"]
non_branded_df = pd.DataFrame(non_branded_data)
# Umbenennung der Spalte „Schlüssel“ in Spalte „Zielseite“ und Konvertieren der Liste „Zielseite“ in eine URL
non_branded_df.rename(columns={"keys": "landing page"}, inplace=True)
non_branded_df["Landingpage"] = non_branded_df["Landingpage"].apply(lambda x: x[0])
Wir laden unsere Daten, dann müssen wir unseren Site-Namen definieren, um seine Verzeichnisse zu extrahieren.
# Definieren Sie Ihren Site-Namen zwischen Anführungszeichen. Beispiel: 'https://www.example.com/' oder 'http://mydomain.com/' SITE_NAME = "https://www.ihre_domain.com/"
Wir müssen nur die Verzeichnisse aus der nicht markengebundenen Leistung extrahieren.
# Jedes Landing Page (URL)-Verzeichnis abrufen
non_branded_df["Verzeichnis"] = non_branded_df["Zielseite"].str.extract(
pat=f"((?<={SITE_NAME})[^/]+)"
)
Dann drucken wir die Verzeichnisse aus, um auszuwählen, welche für diesen Prozess wichtig sind. Sie können alle Verzeichnisse auswählen, um einen besseren Einblick in Ihre Website zu erhalten.

# Um alle Verzeichnisse in der Ausgabe zu erhalten, müssen wir Pandas Optionen manipulieren
pd.set_option("display.max_rows", Keine)
# Website-Verzeichnisse
non_branded_df["Verzeichnis"].value_counts()
Hier können Sie die für Sie wichtigen Verzeichnisse einfügen.
""" Wählen Sie aus, welche Verzeichnisse wichtig sind, um ihre CTR-Kurve zu erhalten.
Fügen Sie die Verzeichnisse in die Variable „important_directories“ ein.
Beispiel: „Produkt,Tag,Produktkategorie,Magazin“. Trennen Sie Verzeichniswerte durch Kommas.
"""
IMPORTANT_DIRECTORIES = "Ihre_wichtigen_Verzeichnisse"
IMPORTANT_DIRECTORIES = IMPORTANT_DIRECTORIES.split(",")
3. Beschriftung der Seiten anhand ihrer Position und Berechnung der relativen CTR-Kurve
Jetzt müssen wir unsere Zielseiten basierend auf ihrer Position kennzeichnen. Wir tun dies, weil wir die relative CTR-Kurve für jedes Verzeichnis basierend auf der Position seiner Zielseite berechnen müssen.
# Kennzeichnung von Nicht-Markenpositionen
für i im Bereich (1, 11):
non_branded_df.loc[
(non_branded_df["Position"] >= i) & (non_branded_df["Position"] < i + 1),
"Positionsbezeichnung",
] = ich
Dann gruppieren wir Zielseiten basierend auf ihrem Verzeichnis.
# Gruppierung von Zielseiten basierend auf ihrem 'Verzeichnis'-Wert non_brand_grouped_df = non_branded_df.groupby(["Verzeichnis"])
Lassen Sie uns die Funktion zur Berechnung der relativen CTR-Kurve definieren.
def each_dir_relative_ctr_curve(dir_df, key):
"""Die Funktion berechnet jede IMPORTANT_DIRECTORIES relative CTR-Kurve.
"""
# Gruppierung von „non_brand_grouped_df“ basierend auf ihrem „Positionslabel“-Wert
dir_grouped_df = dir_df.groupby(["Positionsbezeichnung"])
# Eine Liste zum Speichern der mittleren CTR jeder Position
median_ctr_list = []
# Speicherung jedes Verzeichnisses als Schlüssel und "median_ctr_list" als Wert
directorys_median_ctr = {}
# Schleife über jede "dir_grouped_df"-Gruppe
für i im Bereich (1, 11):
# Ein Versuch - außer für die Behandlung von Situationen, in denen ein Verzeichnis beispielsweise keine Daten für Position 4 enthält
Versuchen:
tmp_df = dir_grouped_df.get_group(i)
median_ctr_list.append(np.median(tmp_df["ctr"]))
außer:
median_ctr_list.append(0)
# Berechnung der relativen CTR-Kurve
Verzeichnisse_median_ctr[Schlüssel] = np.array(median_ctr_list) / np.array(
[mittlere_ctr_liste[0]] * 10
)
gib Verzeichnisse_median_ctr zurück
Nachdem wir die Funktion definiert haben, führen wir sie aus.
# Verzeichnisse durchlaufen und die Funktion 'each_dir_relative_ctr_curve' ausführen
directories_median_ctr_dict = dict()
für Schlüssel, Artikel in non_brand_grouped_df:
wenn Sie IMPORTANT_DIRECTORIES eingeben:
directories_median_ctr_dict.update(each_dir_relative_ctr_curve(item, key))
pprint(directories_median_ctr_dict)
Jetzt laden wir unsere Zielseiten mit und ohne Marke sowie die Leistung und berechnen die relative CTR-Kurve für unsere Nicht-Marken-Daten. Warum tun wir dies nur für markenfremde Daten? Weil wir den markenunabhängigen organischen Traffic und Umsatz vorhersagen möchten.
Schritt 2: Vorhersage der Einnahmen aus nicht markenbezogenem organischem Verkehr
In diesem zweiten Schritt erfahren Sie, wie Sie unsere Umsatzdaten abrufen und unseren Umsatz vorhersagen.
1. Zusammenführen von markenbezogenen und nicht markenbezogenen organischen Daten
Jetzt werden wir unsere markenbezogenen und nicht markenbezogenen Daten zusammenführen. Dies hilft uns bei der Berechnung des Prozentsatzes des nicht markenbezogenen organischen Traffics auf jeder Zielseite im Vergleich zum gesamten Traffic.
# „main_df“ ist eine Kombination aus DataFrames „Gesamte Site-Daten“ und „Nicht-Markendaten“.
# Mit diesem DataFrame können Sie herausfinden, wo die meisten unserer Klicks und Impressionen sind
# kommen von Abfragen, die nicht gebrandet sind.
main_df = non_branded_df.merge(
branded_df, on="Zielseite", Suffixe=("_non_brand", "_branded")
)
Dann ändern wir die Spalten, um nutzlose zu entfernen.
# Ändern der 'main_df'-Spalten auf die, die wir brauchen
main_df = main_df[
[
"Landingpage",
"clicks_non_brand",
"ctr_non_brand",
"Verzeichnis",
"Positionsbezeichnung",
"clicks_branded",
]
]
Lassen Sie uns nun den Prozentsatz der nicht markenbezogenen Klicks im Verhältnis zu den Gesamtklicks einer Zielseite berechnen.
# Berechnung des Prozentsatzes der Klicks auf nicht markenbezogene Suchanfragen basierend auf Zielseiten im Vergleich zu den Klicks auf die gesamte Zielseite
main_df.loc[:, "clicks_non_brand_percentage"] = main_df.apply(
lambda x: x["clicks_non_brand"] / (x["clicks_non_brand"] + x["clicks_branded"]),
Achse=1,
)
[Ebook] Automatisierung von SEO mit Oncrawl
 Lesen Sie das E-Book
Lesen Sie das E-Book2. Laden der organischen Verkehrseinnahmen
Genau wie beim Abrufen der GSC-Daten haben wir eine Reihe von Möglichkeiten, um die GA-Daten zu erhalten: Wir könnten das „Google Analytics Sheets Add-on“ oder die GA-API verwenden. In diesem Tutorial verwende ich wegen seiner Einfachheit lieber Google Data Studio (GDS).
Um die GA-Daten von GDS zu erhalten, gehen Sie folgendermaßen vor:
- Erstellen Sie in GDS einen neuen Bericht oder Explorer und eine Tabelle.
- Fügen Sie für die Dimension „Zielseite“ und für die Metrik „Umsatz“ hinzu.
- Dann müssen Sie ein benutzerdefiniertes Segment in GA basierend auf Quelle und Medium erstellen. Filtern Sie den „Google/Organic“-Traffic. Fügen Sie es nach der Segmenterstellung dem Segmentabschnitt in GDS hinzu.
- Exportieren Sie im letzten Schritt die Tabelle und speichern Sie sie als „
landing_pages_revenue.csv“.
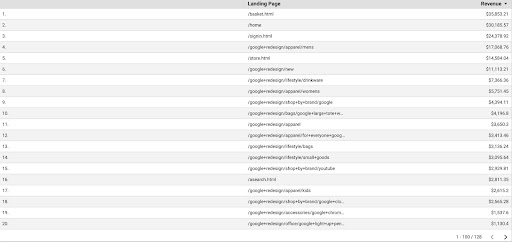
Landingpages-Umsatz im CSV-Format exportieren
Lassen Sie uns unsere Daten laden.
organic_revenue_df = pd.read_csv(./data/landing_pages_revenue.csv")
Jetzt müssen wir unseren Site-Namen an die URLs der GA-Zielseiten anhängen.
Wenn wir unsere Daten aus GA exportieren, liegen die Zielseiten in relativer Form vor, unsere GSC-Daten jedoch in absoluter Form.
Vergessen Sie nicht, die Daten Ihrer GA-Zielseiten zu überprüfen. In den Datensätzen, mit denen ich gearbeitet habe, habe ich festgestellt, dass die GA-Daten jedes Mal ein wenig bereinigt werden müssen.
# GA-Zielseiten-URLs mit SITE_NAME verknüpfen.
# Auch das Umbenennen der Spalten
organic_revenue_df.loc[:, "Zielseite"] = (
SITE_NAME[:-1] + organischer_Umsatz_df[organischer_Umsatz_df.columns[0]]
)
organic_revenue_df.rename(columns={"Landing Page": "Landing Page", "Revenue": "Revenue"}, inplace=True)
Lassen Sie uns nun unsere GSC-Daten mit GA-Daten zusammenführen.
# In diesem Schritt füge ich „main_df“ mit dem DataFrame „dk_organic_revenue_df“ zusammen, der den Prozentsatz der Nicht-Marken-Anfragedaten enthält main_df = main_df.merge(organic_revenue_df, on="landing page", how="left")
Am Ende dieses Abschnitts führen wir eine kleine Bereinigung unserer DataFrame-Spalten durch.
# Ein wenig Aufräumen des 'main_df' DataFrame
main_df = main_df[
[
"Landingpage",
"clicks_non_brand",
"ctr_non_brand",
"Verzeichnis",
"Positionsbezeichnung",
"clicks_non_brand_percentage",
"Einnahmen",
]
]
3. Berechnung des Non-Branded-Umsatzes
In diesem Abschnitt verarbeiten wir Daten, um die gesuchten Informationen zu extrahieren.
Aber zuerst filtern wir unsere Landing Pages nach „ IMPORTANT_DIRECTORIES “:
# Entfernen anderer Zielseiten für Verzeichnisse, die nicht in "IMPORTANT_DIRECTORIES" enthalten sind
main_df = (
main_df[main_df["Verzeichnis"].isin(WICHTIGE_VERZEICHNISSE)]
.dropna(subset=["Einnahmen"])
.reset_index(drop=True)
)
Lassen Sie uns nun den markenfreien organischen Umsatzverkehr berechnen.
Ich habe eine Metrik definiert, die wir nicht einfach berechnen können, und es ist mehr Intuition als alles andere, die uns dazu bringt, ihr eine Zahl zuzuweisen.
Die Metrik „ brand_influence “ zeigt die Stärke Ihrer Marke. Wenn Sie der Meinung sind, dass Suchanfragen ohne_Marke weniger Umsatz für Ihr Unternehmen erzielen, verringern Sie diese Zahl. etwas wie 0,8 zum Beispiel.
# Wenn Ihre Marke so stark ist, dass Abfragen ohne Ihre Marke genauso viel verkaufen können wie Abfragen mit Ihrer Marke, dann ist 1 gut für Sie.
# Denken Sie daran, nach einem Buch zu suchen, ohne dass ein Markenname in Ihrer Suchanfrage enthalten ist. Wenn Sie Amazon sehen, kaufen Sie auf anderen Marktplätzen oder in Geschäften?
Markeneinfluss = 1
main_df.loc[:, "non_brand_revenue"] = main_df.apply(
Lambda x: x["Umsatz"] * x["Klicks_nicht_Markenprozentsatz"] * Markeneinfluss, Achse=1
)
Lassen Sie uns ein Tortendiagramm zeichnen, um einen Einblick in die markenfreien Einnahmen basierend auf den wichtigen Verzeichnissen zu erhalten.
# In dieser Zelle möchte ich alle Einnahmen aus Nicht-Marken-Zielseiten basierend auf ihrem Verzeichnis erhalten
non_branded_directory_dist_revenue_df = pd.pivot_table(
main_df,
index="Verzeichnis",
values="non_brand_revenue"],
aggfunc={"non_brand_revenue": "sum"},
)
pie_fig = px.pie(
non_branded_directory_dist_revenue_df,
values="non_brand_revenue",
names=non_branded_directory_dist_revenue_df.index,
title="Non-branded-Einnahmen basierend auf Website-Verzeichnissen",
)
pie_fig.update_traces(textposition="inside", textinfo="percent+label")
pie_fig.show()
Dieses Diagramm zeigt die Verteilung der nicht markenbezogenen Suchanfragen in Ihren IMPORTANT_DIRECTORIES .
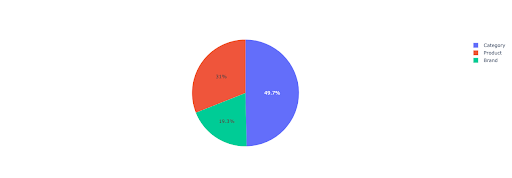
Verteilung von markenlosen Abfragen
Anhand meiner CTR-Kurvendaten sehe ich, dass ich mich nicht auf die CTR für Positionen über 5 verlassen kann. Aus diesem Grund filtere ich meine Daten basierend auf der Position.
Sie können den folgenden Codeblock basierend auf Ihren Daten ändern.
# Aufgrund der CTR-Genauigkeit in unserer CTR-Kurve können wir meines Erachtens Landungen mit einer Position von mehr als 5 überspringen. Aus diesem Grund habe ich andere Zielseiten herausgefiltert main_df = main_df[main_df["Positionsbezeichnung"] < 6].reset_index(drop=True)
4. Berechnung des „Revenue per Click“ (RPC)
Hier habe ich eine benutzerdefinierte Metrik erstellt und sie „Revenue per Click“ oder RPC genannt. Dies zeigt uns den Umsatz, den jeder nicht markenbezogene Klick generiert.
Sie können diese Metrik auf verschiedene Weise verwenden. Ich habe eine Seite mit hohem RPC, aber wenig Klicks gefunden. Als ich die Seite überprüfte, stellte ich fest, dass sie vor weniger als einer Woche indexiert wurde und wir verschiedene Methoden anwenden können, um die Seite zu optimieren.
# Berechnung des mit jedem Klick generierten Umsatzes (RPC: Revenue Per Click)
main_df["rpc"] = main_df.apply(
lambda x: x["non_brand_revenue"] / x["clicks_non_brand"], Achse=1
)
5. Prognose der Einnahmen!
Wir kommen zum Ende, wir haben bis jetzt gewartet, um unsere markenfreien organischen Einnahmen vorherzusagen.
Lassen Sie uns die letzten Codeblöcke ausführen.
# Die Hauptfunktion zur Berechnung des Umsatzes basierend auf verschiedenen Positionen
für index, row_values in main_df.iterrows():
# Zwischen Verzeichnissen wechseln CTR-Liste
ctr_curve = Verzeichnisse_Median_ctr_dict[Zeilenwerte["Verzeichnis"]]
# Schleifen Sie über Position 1 bis 5 und berechnen Sie den Umsatz basierend auf der Erhöhung oder Verringerung der CTR
für i im Bereich (1, 6):
if i == row_values["Positionsbezeichnung"]:
main_df.loc[index, i] = row_values["non_brand_revenue"]
anders:
# main_df.loc[index, i + 1] ==
main_df.loc[index, i] = (
row_values["non_brand_revenue"]
* (ctr_curve[i - 1])
/ ctr_curve[int(row_values["Positionsbezeichnung"] - 1)]
)
# Berechnung der "N zu 1"-Metrik. Dies zeigt die Umsatzsteigerung, wenn Ihr Rang von "N" auf "1" steigt.
main_df.loc[index, "N to 1"] = main_df.loc[index, 1] - main_df.loc[index, row_values["position label"]]
Wenn wir uns die endgültige Ausgabe ansehen, haben wir neue Spalten. Die Namen dieser Spalten sind „1“, „2“, „3“, „4“, „5“.
Was bedeuten diese Namen? Zum Beispiel haben wir eine Seite auf Position 3 und möchten ihren Umsatz vorhersagen, wenn sie ihre Position verbessert, oder wir möchten wissen, wie viel wir verlieren, wenn wir im Rang fallen.
Die Spalten „1“ und „2“ zeigen den Umsatz der Seite, wenn sich die durchschnittliche Position dieser Seite verbessert, und die Spalten „4“ und „5“ zeigen den Umsatz dieser Seite, wenn wir im Ranking fallen.
Spalte „3“ in diesem Beispiel zeigt den aktuellen Umsatz der Seite.
Außerdem habe ich eine Metrik namens „N to 1“ erstellt. Dies zeigt Ihnen, ob sich die durchschnittliche Position dieser Seite von „3“ (oder N) auf „1“ bewegt und wie stark sich die Verschiebung auf den Umsatz auswirken kann.
Einpacken
Ich habe in diesem Artikel viel behandelt, und jetzt sind Sie an der Reihe, sich die Hände schmutzig zu machen und Ihre Einnahmen aus organischem Traffic ohne Markenzeichen vorherzusagen.
Dies ist die einfachste Art, wie wir diese Vorhersage verwenden können. Wir könnten diesen Algorithmus komplexer machen und ihn mit einigen ML-Modellen kombinieren, aber das würde den Artikel komplizierter machen.
Ich speichere diese Daten lieber in einer CSV-Datei und lade sie in ein Google Sheet hoch. Oder, wenn ich vorhabe, es mit den anderen Mitgliedern meines Teams oder der Organisation zu teilen, öffne ich es mit Excel und formatiere die Spalten mit Farben, damit es einfacher zu lesen ist.
Basierend auf diesen Daten können Sie den ROI Ihres markenlosen organischen Traffics vorhersagen und in Ihrem Verhandlungsprozess verwenden.