
Google Crawl Stats Report vs. Log File Analysis: Wer ist der Gewinner?
Veröffentlicht: 2020-12-22Am 24. November veröffentlichte Google eine neue Version seines Search Console Crawl Stats-Berichts. Mit diesem Update erhalten Sie Daten, mit denen Sie Crawling-Probleme beheben und den Zustand Ihrer Website überprüfen können.
Die vorherige Version zeigt nur die Anzahl der pro Tag gecrawlten Seiten, die pro Tag heruntergeladenen Kilobytes und die für das Herunterladen von Seiten pro Tag aufgewendete Zeit an.
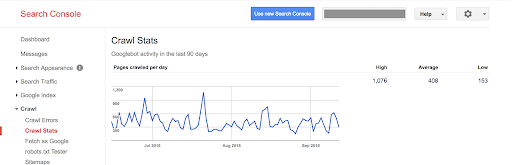
Mit dieser neuen Version sind die gleichen Informationen in einem aktualisierten Look-and-Feel verfügbar, um dem Rest der Search Console zu entsprechen:
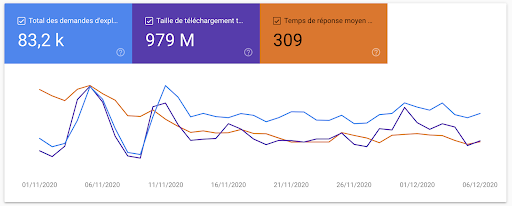
Aber es hört hier nicht auf. Google bietet viel mehr Informationen darüber, wie sie Ihre Website crawlen. Und bei so vielen Informationen, die direkt von Google verfügbar sind, stellt sich die Frage: Brauchen wir noch Protokolldateien?
Sehen wir uns zunächst den neuen Bericht selbst an.
Alles, was Sie über den Crawl-Statistikbericht der Google Search Console wissen müssen
Wo finden Sie den neuen Crawling-Statistikbericht?
Der neue Crawling-Statistikbericht ist automatisch für jeden mit einem Google Search Console-Konto verfügbar.
Melden Sie sich bei der Search Console an und navigieren Sie in der linken Seitenleiste zu „Einstellungen“. Klicken Sie dann auf „Crawling-Statistiken“.
Was enthält der neue Crawling-Statistikbericht?
Damit Sie sich in den umfangreichen neuen Informationen besser zurechtfinden, empfehlen wir Tomek Rudzkis Walkthrough auf Twitter:
Die neuen GSC-Crawl-Statistiken sind fantastisch!
Der erste Screenshot ähnelt der vorherigen Version des Berichts, aber es gibt versteckte Schätze in anderen Berichten
1/n pic.twitter.com/oCNzMhnGsQ– Tomek Rudzki (@TomekRudzki) 24. November 2020
Tomek hebt jeweils neue Daten- und SEO-Anwendungsfälle hervor:
- Hosts mit den meisten Googlebot-Treffern: Finden Sie die Subdomains, die am häufigsten von Google gecrawlt werden.
- Statuscodes, die an Googlebot zurückgegeben werden: Finden Sie heraus, wie viel Prozent Ihres Crawl-Budgets von Nicht-200-Antworten (d. h. Weiterleitungen, fehlende Seiten und Fehler) verwendet werden.
- Dateityp: Erfahren Sie, wie häufig der Googlebot Ressourcendateien wie CSS-Dateien, JavaScript-Dateien und Bilder anfordert.
- Der Zweck des Googlebot-Besuchs: Erfahren Sie, ob Google neue Inhalte entdeckt oder bereits bekannte Inhalte aktualisiert.
- Die Aufteilung zwischen Anfragen des Smartphone-Googlebots und denen des Desktop-Googlebots: Bestätigen Sie, ob Ihre Website für die vollständige Umstellung auf Mobile-First-Indexierung im März 2021 bereit ist.
- Ein Beispiel für gecrawlte URLs: Machen Sie sich ein Bild von einigen der kürzlich gecrawlten URLs auf Ihrer Website.
- Host-Status: eine neue Metrik, die anzeigt, ob Ihr Server in letzter Zeit Probleme hatte. Dies berücksichtigt beispielsweise die Verfügbarkeit von robots.txt und die DNS-Auflösung.
Unsere drei beliebtesten Dinge am Crawl-Statistikbericht
Der Crawl-Statistikbericht bietet zu viele Vorteile, um sie alle aufzulisten, insbesondere wenn Sie keinen Zugriff auf Protokolldateien haben. Aber hier sind unsere Top 3:
1. Dieser Bericht ist für alle bestimmt.
Es bietet einfach zu lesende, hochrangige Googlebot-Crawling-Statistiken. Es ist klar, wenn die Dinge gut laufen und wenn es Probleme gibt, die möglicherweise angegangen werden müssen. Teilweise geht es sogar noch weiter: So liefert es zum Beispiel Hinweise wie die grün/gelb/rote Statusanzeige für den Host-Status.
Auch wenn Sie neu in der Bot- und Crawl-Budgetverfolgung sind, sollten Sie sich beim Betrachten dieser Berichte nicht verirren.
2. Die Dokumentation ist großartig.
Die Dokumentation beantwortet nicht nur 99 % Ihrer Fragen, sondern enthält auch Best Practices und Tipps für den Serverzustand, Warnhinweise, die Verwaltung der Crawl-Frequenz und grundlegende Probleme mit Googlebots.
3. Daten zum „Warum“ hinter Googlebot-Anfragen
Wir können den Googlebot verfolgen, aber viele Rückschlüsse darauf, warum Google eine Seite besucht, müssen auf der Grundlage begrenzter Daten gezogen werden. Der Abschnitt „Crawl By Purpose“ und die unter „Page Resource Load“ sichtbaren Rendering-Requests geben eine eindeutige Antwort auf einige unserer Fragen. Wir wissen jetzt mit Sicherheit, ob Google eine Seite entdeckt, die Seite aktualisiert oder eine Ressource in einem separaten, zweiten Durchgang herunterlädt, um die Seite zu rendern.
[Fallstudie] Verwaltung des Bot-Crawlings von Google
 Lesen Sie die Fallstudie
Lesen Sie die FallstudieWas ist der Unterschied zwischen den in Protokolldateien verfügbaren Informationen und dem Crawling-Statistikbericht?
Crawling-Statistiken sind auf Googlebots beschränkt
Crawling-Statistiken: 0
Protokolle: 1
Die Protokolldateien Ihres Servers zeichnen jede Anfrage für Dateien und Ressourcen auf, aus denen Ihre Website besteht, unabhängig davon, von wem sie stammen. Das bedeutet, dass Protokolle Sie über mehr als nur den Googlebot informieren können.
Der Crawl-Statistikbericht von Google ist jedoch (natürlich!) auf Googles eigene Aktivitäten auf Ihrer Website beschränkt.
Hier sind einige der Einblicke, die Sie aus Protokolldateien erhalten können, die nicht in den Crawling-Statistiken angezeigt werden:
- Informationen über andere Suchmaschinen wie Bing. Sie können sehen, wie sie Ihre Website crawlen, aber auch, wie sich ihr Verhalten von dem des Googlebot unterscheidet oder mit ihm übereinstimmt:
Logflare ist so nützlich. Interessant das unterschiedliche Crawling-Verhalten von Googlebots im Vergleich zu Bingbots in Live-Logs zu sehen. Googlebot sieht 301 und die nächste zurückgegebene URL ist die umgeleitete URL, aber Bingbot scheint dies nicht zu tun. Sieht nur die 301 und geht dann woanders hin
– Dawn Anderson (@dawnieando) 22. Januar 2020
- Informationen darüber, welche Tools (und Konkurrenten) versuchen, Ihre Website zu crawlen. Da die verfügbaren Informationen nicht auf den Googlebot beschränkt sind, können Sie auch sehen, ob andere Bots auf Ihrer Website aktiv sind.
- Informationen zu verweisenden Seiten. Dies kann Ihnen helfen, mehr Informationen über Ihre aktivsten Backlinks zu finden. Bei HTTPS wird bei jeder Anfrage auch die zuletzt besuchte Seite bzw. die „verweisende Seite“ erfasst.
- Informationen über organischen Traffic… und nicht nur Traffic von Google! Anhand von Verweisseiten können Sie Zugriffe von Suchmaschinen-Ergebnisseiten identifizieren und besser sehen, wie diese Besucher mit Ihrer Website interagieren. Diese Art von Informationen kann verwendet werden, um Zahlen zu bestätigen oder zu korrigieren, die von Ihrer Analytics-Lösung bereitgestellt werden, falls Sie eine verwenden.
- Identifizierung verwaister Seiten. Da Ihre Protokolle alle von Besuchern angeforderten URLs enthalten, werden alle „aktiven“ Seiten mit Bot- oder menschlichem Datenverkehr, die nicht in Ihrer Websitestruktur verlinkt sind, in Ihren Protokollen angezeigt. Indem Sie eine Liste von URLs in Ihren Protokolldateien mit einer Liste von URLs in Ihrer Websitestruktur aus einem Crawl vergleichen, ist es einfach, verwaiste Seiten zu erkennen.
Vollständig und aktuell?
Crawling-Statistiken: 0
Protokolle: 2

Sind Ihre Daten vollständig und aktuell? Ihre Protokolle sind. Und Ihre Crawl-Statistiken könnten es sein.
Viele Leute bemerkten schnell Unterschiede von 20-40% zwischen dem Google Search Console-Bericht und ihren Protokolldateien: Der Crawl-Statistikbericht zeigt die Googlebot-Aktivität im Moment zu niedrig an. Dies ist ein bekanntes Problem in den Crawling-Statistiken – aber nicht in Ihren Protokollen!
Außerdem kann es, wie bei allen Informationen in der Search Console, zu einer Verzögerung zwischen dem letzten verfügbaren Datendatum und dem heutigen Datum kommen. Bisher haben wir im Crawl-Statistikbericht einen Unterschied von bis zu acht Tagen festgestellt.
Andererseits können Sie Ihre Protokolldateien für die Echtzeitüberwachung verwenden: Es gibt nie eine Verzögerung!
Aggregierte vs. vollständige Listen gecrawlter URLs
Crawling-Statistiken: 0
Protokolle: 3
Die Crawl-Statistiken liefern aggregierte Daten für alle Ihre URLs. Der Bericht entspricht einem Dashboard. Wenn Sie nach der Liste der URLs hinter einer bestimmten Metrik suchen, sehen Sie eine Liste mit „Beispielen“. Beispielsweise könnten Sie einige hundert Beispiele Ihrer 4,56 KB-Anfragen für Bilddateien haben:
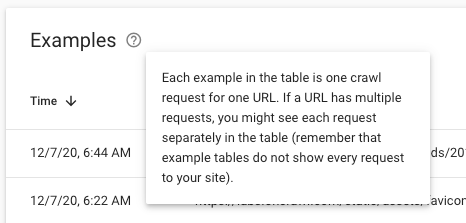
In Protokolldateien haben Sie jedoch eine vollständige Liste der URLs hinter jeder Metrik. Sie können ALLE Anfragen in Ihren Protokollen sehen, nicht nur ein Beispiel.
Filtern nach Regionen, Daten, URLs…
Crawling-Statistiken: 0
Protokolle: 4
Um wirklich nützlich zu sein, könnten die Crawl-Statistiken von umfassenderen Filtern profitieren, die für alle Anfragen gelten, nicht nur für die Stichproben: 
Es wäre großartig, mehr Flexibilität zu haben, um:
- Ändern Sie den betrachteten Zeitraum
- Konzentrieren Sie sich auf eine bestimmte geografische Region durch IP-Lookup
- Filtern Sie besser nach URL-Gruppen
- Wenden Sie Filteroptionen auf Diagramme an
All dies – und noch viel mehr – können Sie in Protokolldateien tun.
Googlebot-spezifische Informationen
Crawling-Statistiken: 1
Protokolle: 4
Wie wir gesehen haben, verwendet Google den Crawl-Statistikbericht, um Informationen über den Zweck ihres Crawls bereitzustellen:
- Aktualisieren vs. Entdecken
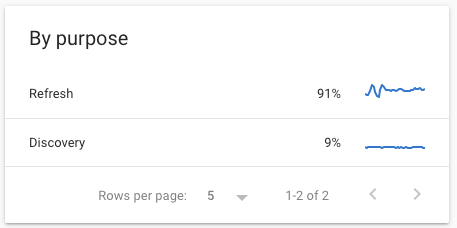
- Seitenressourcen (ein sekundärer Abruf)

Diese Informationen sind nirgendwo anders zu finden, egal wie schlau Sie sich die Daten in Ihren Protokolldateien ansehen.
Einfacher Zugriff
Crawling-Statistiken: 2
Protokolle: 4
Der Zugriff auf den Bericht „Crawling-Statistiken“ ist unkompliziert: Crawling-Statistiken sind automatisch für jeden verfügbar, der Zugriff auf die Search Console hat.
Logfiles sollten technisch gesehen auch jedem Webmaster zur Verfügung stehen. Aber das ist oft nicht der Fall. Oft verstehen Entwicklerteams, IT-Teams oder Kundenunternehmen nicht, wie wichtig es ist, Zugriff auf Protokolldateien zu gewähren. In Gebieten wie der EU, in denen Datenschutzgesetze den Zugriff auf „personenbezogene Daten“ wie IP-Adressen einschränken, kann der Zugriff auf Protokolldateien ein rechtliches Problem darstellen. Sie können bestimmte Tools wie OnCrawl verwenden, die keine sensiblen Informationen speichern.
Sobald Sie Zugriff auf Protokolldateien haben, gibt es kostenlose Tools zur Analyse der Daten, und es gibt nur wenige proprietäre Formate. Mit anderen Worten, Protokolldateien sind eine ziemlich demokratische Datenquelle … sobald Sie sie in die Hände bekommen.
Es ist eine Tatsache: Viele SEOs haben Probleme, Zugriff auf Protokolle zu erhalten. Während Protokolldateien also theoretisch einen einfachen Zugriff auf Daten bieten, geht es in diesem Fall um den Crawl Stats Report, der mit zwei Klicks aus dem kostenlosen Tool von Google verfügbar ist.
Oncrawl Log Analyzer
 Mehr erfahren
Mehr erfahren(Noch) nicht für die Integration in andere Tools und Analysen verfügbar
Crawling-Statistiken: 2
Protokolle: 5
Mit der Google Search Console können Sie die über die Weboberfläche des Crawl Stats Report verfügbaren Informationen exportieren und herunterladen. Das bedeutet jedoch, dass die heruntergeladenen Informationen dieselben Einschränkungen haben wie die Bildschirmversionen.
Darüber hinaus sind die Crawl-Statistiken (noch?) nicht über die API verfügbar, sodass es schwierig sein kann, diese Informationen in automatisierte Prozesse für Berichte und Analysen einzubinden oder sie sogar für eine breitere Ansicht historischer Daten zu sichern.
Bei Protokolldateien liegt die Speicherung, der Zugriff und die Wiederverwendung grundsätzlich bei Ihnen. Dadurch sind Protokolldateien viel einfacher zu verwenden, wenn sie mit anderen Datenquellen wie Rangverfolgung, Crawl-Daten oder Analysedaten zusammengeführt werden. Sie lassen sich auch einfacher in Reporting-, Dashboarding- und Datenvisualisierungsabläufe integrieren.
Der endgültige Gewinner: Protokolldateien!
Mit fünf Punkten zu nur zwei Punkten für den Crawl Stats-Bericht sind Protokolldateien hier der klare Gewinner, wenn Sie vollständige Einblicke in die Interaktion von Suchmaschinen mit Ihrer Website erhalten möchten.
Aber seien wir klar: Der aktualisierte Crawl-Statistikbericht bietet viele neue Informationen: Statuscodes, Dateitypen, Subdomains (für Domain-Eigenschaften), Host-Statusdetails und mehr. Es gibt Ihnen detailliertere Einblicke und umsetzbare Daten, um zu verstehen, wie Ihre Website gecrawlt wird, und Sie können jetzt Änderungen in Crawling-Mustern verfolgen.
Es wird ein großer Schritt nach vorne für Leute sein, die keinen Zugriff auf die Logdateien ihrer oder ihrer Kunden haben.
Es sind jedoch nicht alle Profis!
Vor- und Nachteile der neuen GSC-Crawling-Statistiken: https://t.co/bjpG7QjeVt
Vorteile:
+ Verbesserte Datenmetriken
+Bessere UX (Low Bar TBH)
+ Herunterladbare Daten der gecrawlten URLs!
+Aufschlüsselung von Crawling-Anfragen
+Wichtige Host-Probleme festgestelltNachteile:
-Keine Filter für Datumsbereiche
-Keine Filteroptionen zum Ändern der Diagramme– Micah Fisher-Kirshner (@micahfk) 24. November 2020
Die Nachteile des neuen Berichts sind, dass er zwar ein gutes Dashboard für die Googlebot-Überwachung und eine großartige Ergänzung zur Ergänzung der Protokolldateianalyse ist, aber in vielerlei Hinsicht eingeschränkt ist. Vergessen Sie nicht, nur Ihre Protokolldateien zeigen Ihnen alle Ihre Anfragen pro URL und nicht einen aggregierten Trend.
Darüber hinaus gibt es ein bekanntes Problem im GSC-Bericht, bei dem einige Anfragen derzeit nicht gezählt werden und es bis zu einer Woche dauern kann, bis Daten im Crawl-Statistikbericht erscheinen. (Wir vertrauen jedoch darauf, dass Google an diesen Problemen arbeitet und sie bald verschwinden werden!)
Wir empfehlen Folgendes: Verwenden Sie diesen Bericht, um genau zu wissen, wonach Sie in Ihren Protokolldateien suchen müssen. Und tauchen Sie dann in Ihre Protokollanalyse ein!