
Google Core Updates: Auswirkungen, Probleme und Lösungen für YMYL-Sites
Veröffentlicht: 2019-12-04In dieser Fallstudie werde ich mich mit Hangikredi.com befassen, einem der größten finanziellen und digitalen Assets der Türkei. Wir werden technische SEO-Unterüberschriften und einige Grafiken sehen.
Diese Fallstudie wird in zwei Artikeln vorgestellt. Dieser Artikel behandelt das Google Core Update vom 12. März, das die Website stark negativ beeinflusst hat, und was wir dagegen unternommen haben. Wir werden 13 technische Probleme und Lösungen sowie ganzheitliche Probleme betrachten.
Lesen Sie den zweiten Teil, um zu sehen, wie ich das Lernen aus diesem Update angewendet habe, um ein Gewinner aus jedem Google Core-Update zu werden.
Probleme und Lösungen: Behebung der Auswirkungen des Google Core-Updates vom 12. März
Bis zum Update des Kernalgorithmus am 12. März lief alles reibungslos für die Website, basierend auf den Analysedaten. An einem Tag, nachdem die Nachricht über das Core Algorithm Update veröffentlicht wurde, gab es einen enormen Rückgang der Rankings und große Frustration im Büro. Ich persönlich habe diesen Tag nicht gesehen, weil ich erst angekommen bin, als sie mich eingestellt haben, um 14 Tage später ein neues SEO-Projekt und einen neuen Prozess zu starten.
[Fallstudie] Verbesserung von Rankings, organischen Besuchen und Verkäufen durch Analyse von Protokolldateien
 Lesen Sie die Fallstudie
Lesen Sie die FallstudieDer Schadensbericht für die Website des Unternehmens nach der Aktualisierung des Kernalgorithmus vom 12. März ist unten:
- 36 % organischer Sitzungsverlust
- 65 % klicken auf Drop
- 30 % CTR-Verlust
- 33 % organischer Benutzerverlust
- 100 000 verlorene Impressionen pro Tag.
- 9,72 % Impressionsverlust
- 8 000 Keywords verloren

Nun, wie wir am Anfang des Fallstudienartikels gesagt haben, sollten wir eine Frage stellen. Wir konnten nicht fragen: „Wann wird das nächste Update des Kernalgorithmus stattfinden?“ weil es schon passiert ist. Es blieb nur noch eine Frage.
„Welche unterschiedlichen Kriterien hat Google zwischen mir und meinem Konkurrenten berücksichtigt?“
Wie Sie der obigen Grafik und dem Schadensbericht entnehmen können, hatten wir unseren Hauptverkehr und unsere Schlüsselwörter verloren.
1. Problem: Interne Verlinkung
Als ich zum ersten Mal die Anzahl der internen Links, den Ankertext und den Linkfluss überprüfte, bemerkte ich, dass mein Konkurrent mir voraus war.
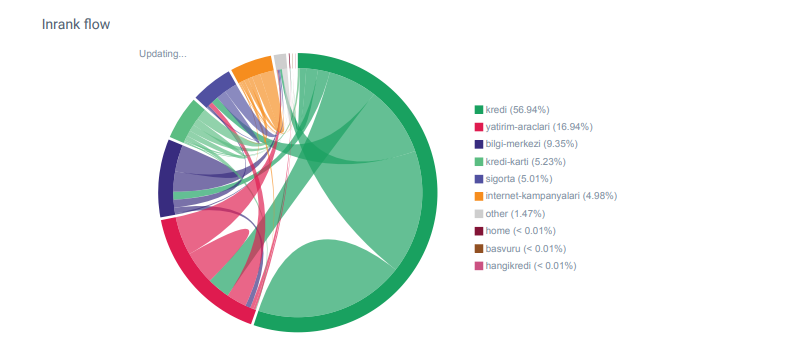
Linkflow-Bericht für die Kategorien von Hangikredi.com von OnCrawl
Mein Hauptkonkurrent hat über 340.000 interne Links mit Tausenden von Ankertexten. Damals hatte unsere Website nur 70.000 interne Links ohne wertvolle Ankertexte. Darüber hinaus hatte das Fehlen interner Links das Crawling-Budget und die Produktivität der Website beeinträchtigt. Obwohl 80 % unseres Traffics auf nur 20 Produktseiten gesammelt wurde, bestanden 90 % unserer Website aus Leitseiten mit nützlichen Informationen für Benutzer. Und die meisten unserer Keywords und Relevanzwerte für Finanzanfragen stammen von diesen Seiten. Außerdem gab es unzählige zu viele verwaiste Seiten.
Aufgrund der fehlenden internen Linkstruktur bemerkte ich bei der Protokollanalyse mit Kibana, dass die am häufigsten gecrawlten Seiten diejenigen waren, die den wenigsten Traffic erhielten. Als ich dies mit dem internen Link-Netzwerk kombinierte, stellte ich außerdem fest, dass die Unternehmensseiten mit dem geringsten Datenverkehr (Datenschutz, Cookies, Sicherheit, Über uns-Seiten) die maximale Anzahl interner Links aufweisen.
Wie ich im nächsten Abschnitt erläutern werde, veranlasste dies den Googlebot, den internen Linkfaktor aus Pagerank zu entfernen, als er die Website durchsuchte, da er feststellte, dass interne Links nicht wie beabsichtigt aufgebaut waren.
2. Problem: Site-Architektur, interner Pagerank, Traffic- und Crawl-Effizienz
Laut Aussage von Google helfen interne Links und Ankertexte dem Googlebot, die Bedeutung und den Kontext einer Webseite zu verstehen. Interner Pagerank oder Inrank wird basierend auf mehr als einem Faktor berechnet. Laut Bill Slawski sind interne und externe Links nicht alle gleich. Der Wert eines Links für den Pagerank-Fluss ändert sich entsprechend seiner Position, Art, Stil und Schriftstärke.

Wenn der Googlebot versteht, welche Seiten für Ihre Website wichtig sind, werden sie stärker gecrawlt und schneller indexiert. Interne Links und ein korrektes Site-Tree-Design sind dafür wichtige Faktoren. Auch andere Experten haben diesen Zusammenhang im Laufe der Jahre kommentiert:
„Die meisten Links bieten durch ihren Ankertext ein wenig zusätzlichen Kontext. Zumindest sollten sie das, oder?“
–John Mueller, Google 2017„Wenn Sie Seiten auf Ihrer Website haben, die Sie für wichtig halten, vergraben Sie sie nicht 15 Links tief in Ihrer Website, und ich spreche nicht von der Verzeichnislänge, sondern von der Tatsache, dass Sie 15 Links durchklicken müssen, um diese Seite zu finden Wenn es eine Seite gibt, die wichtig ist oder große Gewinnmargen hat oder wirklich – nun – eskaliert, dass ein Link von Ihrer Stammseite zu dieser Seite gesetzt wird, kann das sehr sinnvoll sein.“
–Matt Cutts, Google 2011„Wenn eine Seite mit dem Wort „Kontakt“ oder dem Wort „Über“ auf eine andere Seite verlinkt und die Seite, auf die verlinkt wird, eine Adresse enthält, kann diese Adresse als relevant für die Seite angesehen werden, die diese Verknüpfung durchführt.“
12 Methoden zur Analyse von Google-Links, die sich möglicherweise geändert haben – Bill Slawski
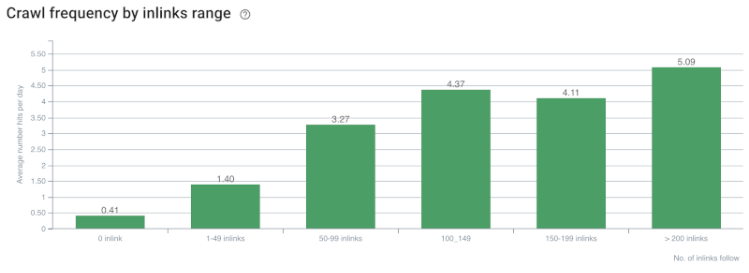
Korrelation zwischen Crawling-Rate/Nachfrage und Anzahl interner Links. Quelle: OnCrawl.
Bisher können wir diese Schlussfolgerungen ziehen:
- Google kümmert sich um die Klicktiefe. Wenn eine Webseite näher an der Homepage liegt, sollte sie wichtiger sein. Dies bestätigte auch John Mueller am 1. Juli 2018 im englischen Google Webmaster Hangout.
- Wenn eine Webseite viele interne Links hat, die darauf verweisen, sollte es wichtig sein.
- Ankertexte können einer Webseite kontextuelle Kraft verleihen.
- Ein interner Link kann je nach Position, Typ, Schriftstärke oder Stil unterschiedliche Pagerank-Beträge übertragen.
- Ein UX-freundlicher Site-Tree, der den Suchmaschinen-Crawlern klare Botschaften über die Autorität der internen Seite gibt, ist eine bessere Wahl für die Inrank-Verteilung und Crawl-Effizienz.
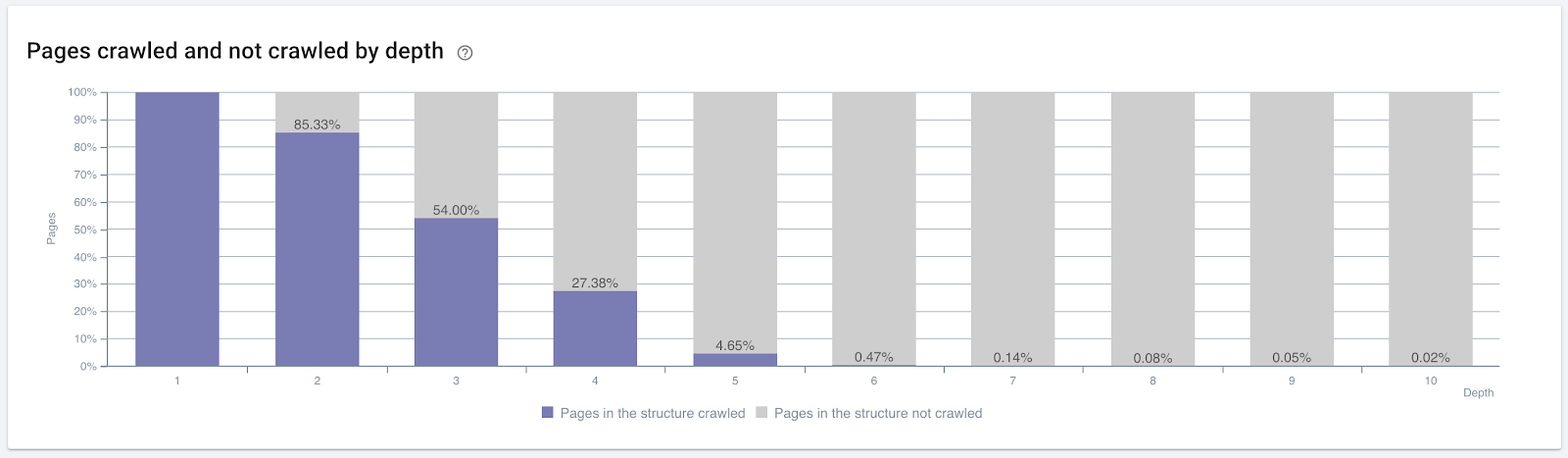
Prozentsatz der gecrawlten Seiten nach Klicktiefe. Quelle: OnCrawl.
Dies reicht jedoch nicht aus, um die Art und Auswirkungen interner Links auf die Crawl-Effizienz zu verstehen.
Oncrawl SEO-Crawler
 Mehr erfahren
Mehr erfahrenWenn Ihre meisten intern verlinkten Seiten keinen Traffic generieren oder angeklickt werden, gibt dies Signale, die darauf hindeuten, dass Ihr Site-Tree und Ihre interne Linkstruktur nicht gemäß der Benutzerabsicht aufgebaut sind. Und Google versucht immer, Ihre relevantesten Seiten mit Benutzerabsicht oder Suchentitäten zu finden. Wir haben ein weiteres Zitat von Bill Slawski, das dieses Thema klarer macht:
„Wenn eine Ressource mit einer Anzahl von Ressourcen verknüpft ist, die in Bezug auf den durch die Verwendung dieser Links erhaltenen Datenverkehr unverhältnismäßig ist, kann diese Ressource im Ranking-Prozess herabgestuft werden.“
Hat das Groundhog-Update gerade bei Google stattgefunden? – Bill Slawski„Die Auswahlqualitätspunktzahl kann für eine Auswahl, die zu einer langen Verweilzeit führt, höher sein (z. B. größer als ein Schwellenwertzeitraum) als die Auswahlqualitätspunktzahl für eine Auswahl, die zu einer kurzen Verweilzeit führt.“
Hat das Groundhog-Update gerade bei Google stattgefunden? – Bill Slawski
Wir haben also zwei weitere Faktoren:
- Verweildauer auf der verlinkten Seite.
- Benutzerverkehr, der durch den Link erzeugt wurde.
Anzahl der internen Links und Stil/Position sind nicht die einzigen Faktoren. Die Anzahl der Benutzer, die diesen Links folgen, und ihre Verhaltensmetriken sind ebenfalls wichtig. Außerdem wissen wir, dass Links und Seiten, die angeklickt/besucht werden, von Google viel häufiger gecrawlt werden als Links und Seiten, die nicht angeklickt oder besucht werden.
„Wir haben uns immer mehr dazu bewegt, Abschnitte einer Website zu verstehen, um die Qualität dieser Abschnitte zu verstehen.“
John Mueller, 2. Mai 2017, englischer Google Webmasters Hangout.
Angesichts all dieser Faktoren werde ich zwei unterschiedliche Pagerank Simulator-Ergebnisse teilen:
Diese Pagerank-Berechnungen werden unter der Annahme durchgeführt, dass alle Seiten gleich sind, einschließlich der Homepage. Der wirkliche Unterschied wird durch die Verknüpfungshierarchie bestimmt.
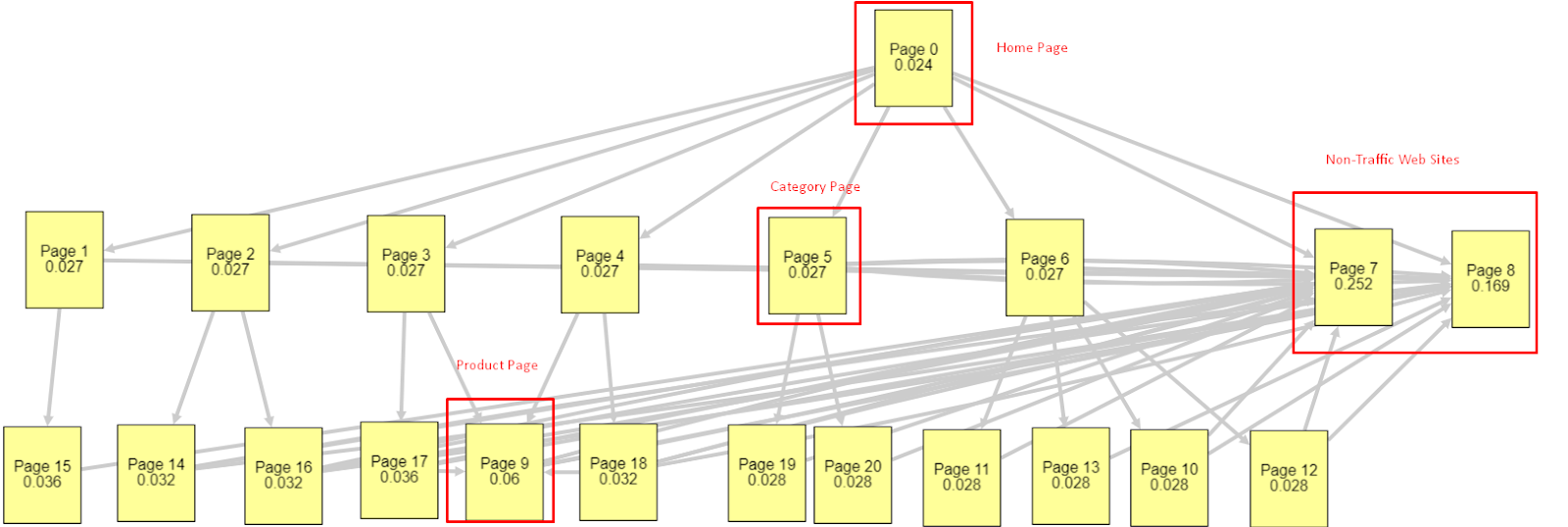
Das hier gezeigte Beispiel entspricht eher der internen Linkstruktur vor dem 12. März. PR der Startseite: 0,024, PR der Kategorieseite: 0,027, PR der Produktseite: 0,06, PR der nicht frequentierten Webseiten: 0,252.
Wie Sie vielleicht bemerkt haben, kann Googlebot dieser internen Linkstruktur nicht vertrauen, um den internen Pagerank und die Wichtigkeit interner Seiten zu berechnen. Nicht-Traffic- und produktfreie Seiten haben 12-mal mehr Autorität als die Homepage. Es hat mehr als nur Produktseiten.

Dieses Beispiel kommt unserer Situation vor dem Update des Kernalgorithmus am 5. Juni näher. Startseiten-PR: 0,033, Kategorieseite: 0,037, Produktseite: 0,148 und PR der Nicht-Traffic-Seiten: 0,037.
Wie Sie vielleicht bemerkt haben, ist die interne Linkstruktur immer noch nicht richtig, aber zumindest haben Non-Traffic-Webseiten nicht mehr PR als Kategorieseiten und Produktseiten.
Was ist ein weiterer Beweis dafür, dass Google den internen Link und die Seitenstruktur gemäß dem Benutzerfluss und den Anforderungen und Absichten aus dem Pagerank-Bereich genommen hat? Natürlich das Verhalten des Googlebots und Inlink-Pagerank und Ranking-Korrelationen:
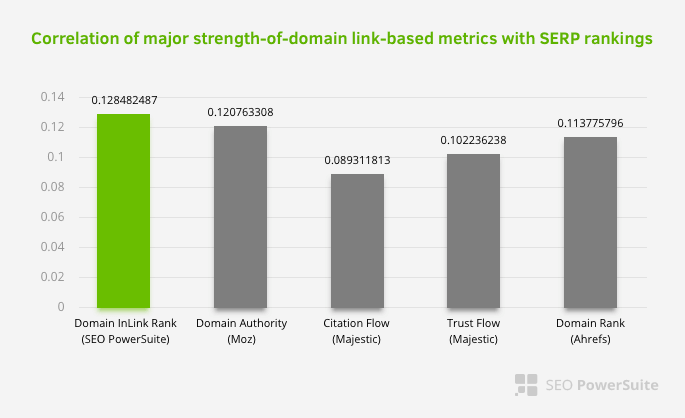
Dies bedeutet nicht, dass insbesondere das interne Linknetzwerk wichtiger ist als andere Faktoren. Die SEO-Perspektive, die sich auf einen einzigen Punkt konzentriert, kann niemals erfolgreich sein. Im Vergleich zwischen Drittanbieter-Tools zeigt sich, dass der interne Pagerank-Wert im Verhältnis zu anderen Kriterien voranschreitet.
Laut der Inlink-Rang- und Rangkorrelationsforschung von Aleh Barysevich haben die Seiten mit den meisten internen Links höhere Rankings als die anderen Seiten der Website. Laut der vom 4. bis 6. März 2019 durchgeführten Umfrage wurden 1.000.000 Seiten nach der internen Pagerank-Metrik für 33.500 Keywords analysiert. Die Ergebnisse dieser von SEO PowerSuite durchgeführten Forschung wurden mit den verschiedenen Metriken von Moz, Majestic und Ahrefs verglichen und ergaben genauere Ergebnisse.
Hier sind einige der internen Linknummern von unserer Website vor dem 12. März Core Algorithm Update:
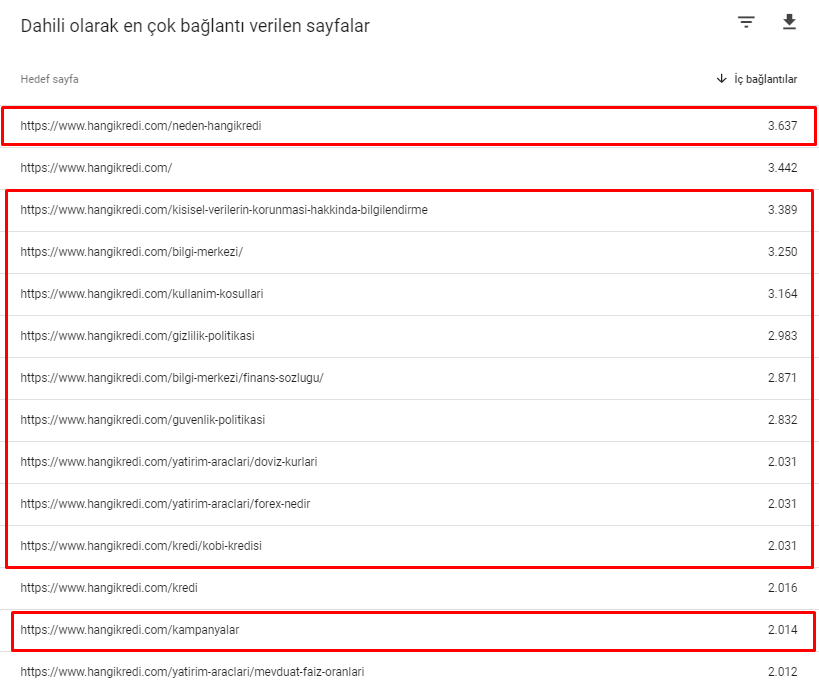
Wie Sie sehen können, spiegelte unser internes Verbindungsschema nicht die Absicht und den Ablauf des Benutzers wider. Die Seiten, die den wenigsten Traffic erhalten (kleinere Produktseiten) oder die nie Traffic erhalten (in rot), waren direkt in der 1. Klicktiefe und erhalten PR von der Homepage. Und einige hatten sogar mehr interne Links als die Startseite.
Angesichts all dessen gibt es nur die letzten beiden Punkte, die wir zu diesem Thema zeigen können.
- Crawling-Rate / Nachfrage nach den meisten intern verlinkten Seiten
- Link Sculpting und Pagerank
Hier sind die Seiten, die der Googlebot zwischen dem 1. Februar und dem 31. März am häufigsten gecrawlt hat:
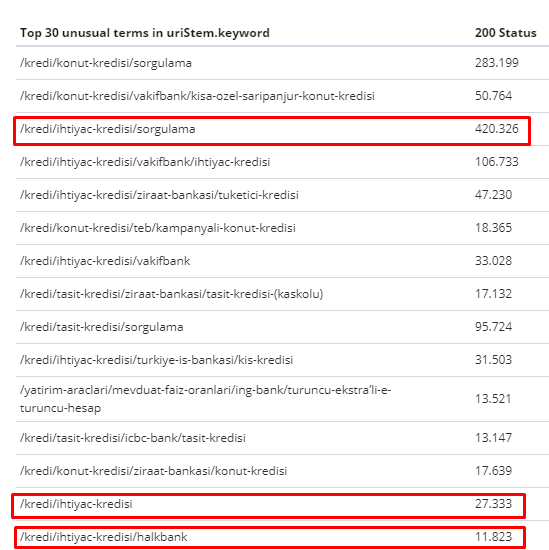
Wie Sie vielleicht bemerkt haben, unterscheiden sich gecrawlte Seiten und Seiten mit den meisten internen Links völlig voneinander. Seiten mit den meisten internen Links waren für die Benutzerabsicht nicht geeignet; Sie haben keine organischen Keywords oder irgendeinen direkten SEO-Wert. (
Die URLs in den roten Kästchen sind unsere meistbesuchten und wichtigsten Produktseitenkategorien. Die anderen Seiten in dieser Liste sind die am zweit- oder dritthäufigsten besuchten und wichtigsten Kategorien.)
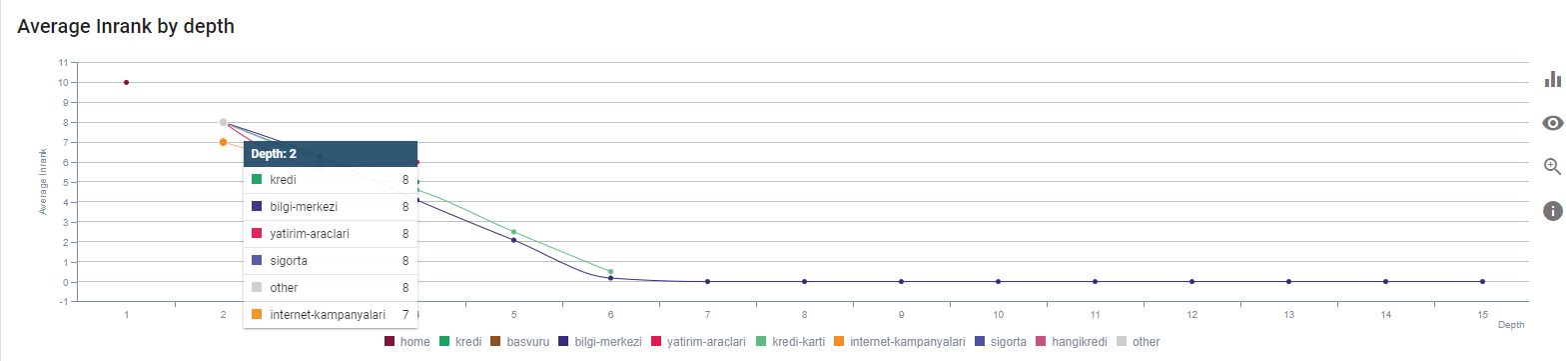
Unser aktueller Inrank nach Seitentiefe. Quelle: Oncrawl.
Was ist Link Sculpting und was tun mit intern Nofollow-Links?
Im Gegensatz zu dem, was die meisten SEOs glauben, geben Links, die mit einem „nofollow“-Tag gekennzeichnet sind, immer noch den internen Pagerank-Wert weiter. Für mich hat nach all den Jahren niemand dieses SEO-Element besser erzählt als Matt Cutts in seinem Pagerank Sculpting Article vom 15. Juni 2009.
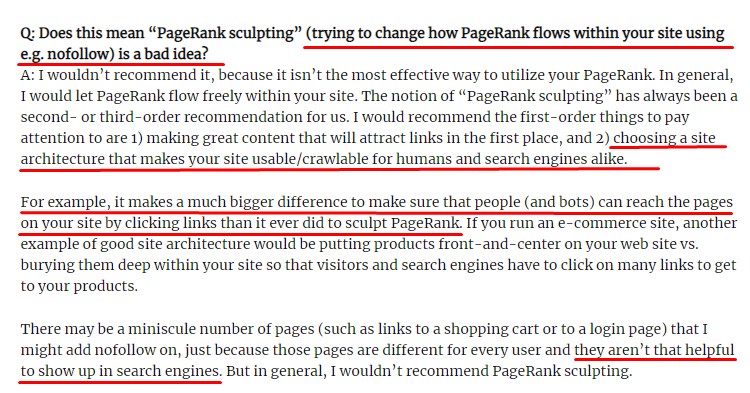
Ein nützlicher Teil für das Link Sculpting, der den wahren Zweck des Pagerank Sculpting zeigt.
„Ich würde empfehlen , nofollow nicht für eine Art PageRank-Sculpting innerhalb einer Website zu verwenden, da es wahrscheinlich nicht das tut, was Sie denken.“
–John Mueller, Google 2017
Wenn Sie für Google und Nutzer wertlose Webseiten haben, sollten Sie diese nicht mit „nofollow“ taggen. Es wird den Pagerank-Fluss nicht stoppen. Sie sollten sie in der robots.txt-Datei verbieten. Auf diese Weise wird der Googlebot sie nicht crawlen, aber auch den internen Pagerank nicht an sie weitergeben. Das sollte man aber nur für wirklich wertlose Seiten verwenden, wie Matt Cutts schon vor zehn Jahren sagte. Seiten, die automatische Weiterleitungen für Affiliate-Marketing machen, oder Seiten mit größtenteils keinem Inhalt sind hier einige praktische Beispiele.
Lösung: Bessere und natürlichere interne Verlinkungsstruktur
Unser Konkurrent hatte einen Nachteil. Ihre Website hatte mehr Ankertext, mehr interne Links, aber ihre Struktur war nicht natürlich und nützlich. Auf jeder Seite ihrer Website wurde derselbe Ankertext mit demselben Satz verwendet. Der Eingangsabsatz für jede Seite wurde mit diesem sich wiederholenden Inhalt bedeckt. Jeder Nutzer und jede Suchmaschine kann leicht erkennen, dass dies keine natürliche Struktur ist, die den Nutzen des Nutzers berücksichtigt.
Also habe ich mich für drei Dinge entschieden, um die interne Linkstruktur zu korrigieren:
- Site Information Architecture oder Site-Tree sollte einem anderen Pfad folgen als die im Inhalt platzierten Links. Es sollte stärker dem Geist des Benutzers folgen und ein neuronales Netzwerk als Schlüsselwort verwenden.
- In jedem Inhaltsteil sollten die Nebenschlüsselwörter zusammen mit den Hauptschlüsselwörtern der Zielseite verwendet werden.
- Ankertexte sollten natürlich, dem Inhalt angepasst und auf jeder Seite an einer anderen Stelle mit Augenmerk auf die Wahrnehmung des Nutzers eingesetzt werden
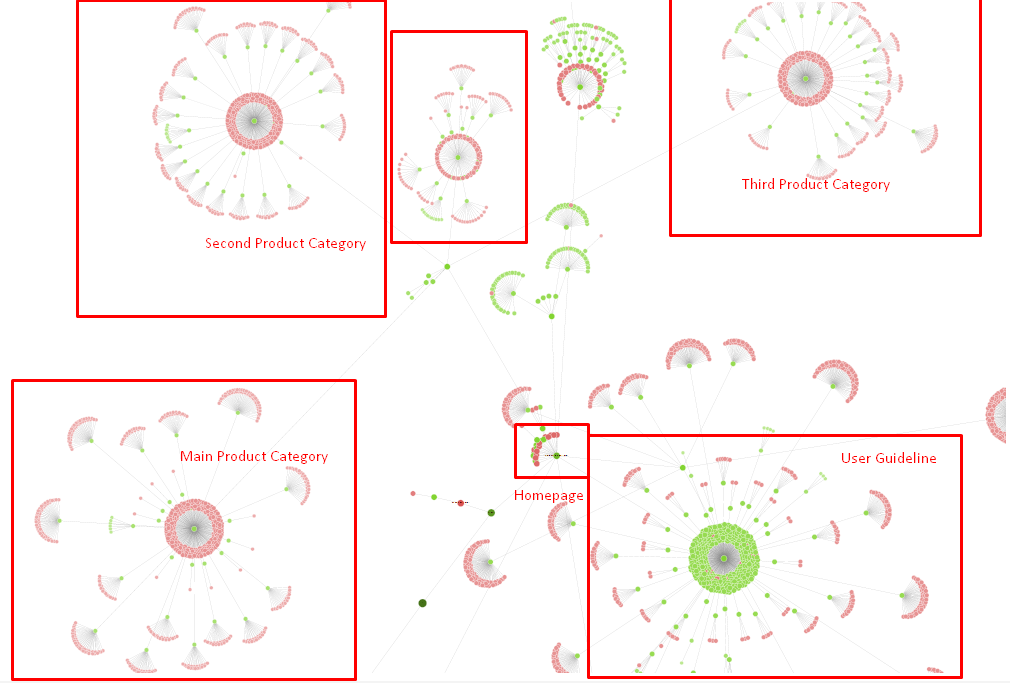
Unser Seitenbaum und vorerst ein Teil der Inlink-Struktur.
Im obigen Diagramm sehen Sie unseren aktuellen internen Link-Link und Site-Baum.
Einige der Dinge, die wir zur Behebung dieses Problems getan haben, sind unten aufgeführt:
- Wir haben 30.000 weitere interne Links mit nützlichen Ankern erstellt.
- Wir haben natürliche Spots und Schlüsselwörter für den Benutzer verwendet.
- Wir haben die sich wiederholenden Sätze und Muster für die interne Verlinkung nicht verwendet.
- Wir haben dem Googlebot die richtigen Signale über den Rang einer Webseite gegeben.
- Wir haben die Auswirkungen einer korrekten internen Linkstruktur auf die Crawling-Effizienz über die Protokollanalyse untersucht und festgestellt, dass unsere Hauptproduktseiten im Vergleich zu früheren Statistiken stärker gecrawlt wurden.
- Erstellt mehr als 50.000 interne Links für verwaiste Seiten.
- Verwendete interne Links auf der Startseite, um die Unterseiten zu versorgen, und erstellte mehr interne Linkquellen auf der Startseite.
- Um Pagerank Power zu schützen, haben wir auch nofollow-Tags für einige unnötige externe Links verwendet. (Hier ging es nicht um interne Links, aber es dient demselben Ziel.)
3. Problem: Inhaltliche Struktur
Google sagt, dass für YMYL-Websites Vertrauenswürdigkeit und Autorität viel wichtiger sind als für andere Arten von Websites.

Früher waren Keywords nur Keywords. Aber jetzt sind sie auch gut definierte, singuläre, bedeutungsvolle und unterscheidbare Einheiten . In unserem Inhalt gab es vier Hauptprobleme:
- Unser Inhalt war kurz. (Normalerweise ist die Länge des Inhalts nicht wichtig. Aber in diesem Fall enthielten sie nicht genügend Informationen zu den Themen.)
- Die Namen unserer Autoren waren nicht singulär, bedeutungsvoll oder als Einheit unterscheidbar.
- Unser Inhalt war nicht augenfreundlich. Mit anderen Worten, es handelte sich nicht um „Fast-Food“-Inhalte. Es war Inhalt ohne Unterüberschriften.
- Wir haben Marketingsprache verwendet. In einem Absatz konnten wir den Markennamen und seine Werbung für den Benutzer identifizieren.
- Es gab viele Schaltflächen, die Benutzer von Informationsseiten zu den Produktseiten leiteten.
- In den Inhalten unserer Produktseiten gab es nicht genügend Informationen oder umfassende Richtlinien.
- Das Design war nicht benutzerfreundlich. Wir haben im Grunde die gleiche Farbe für Schriftart und Hintergrund verwendet. (Aufgrund von Infrastrukturproblemen ist dies meistens immer noch der Fall.)
- Bilder und Videos wurden nicht als Teil des Inhalts angesehen.
- User-Intent und Search-Intent für ein bestimmtes Keyword wurden bisher nicht als wichtig angesehen.
- Es gab viele doppelte, unnötige und sich wiederholende Inhalte zum gleichen Thema.
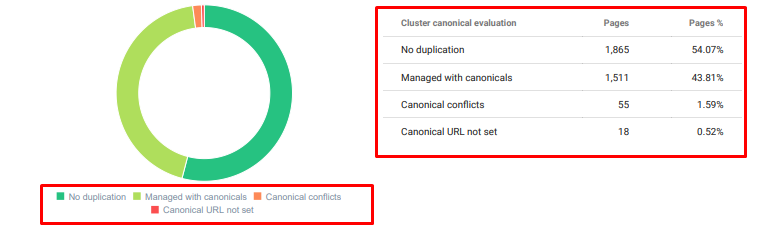
Oncrawl Duplicate Content Audit ab heute.
Lösung: Bessere Inhaltsstruktur für das Vertrauen der Benutzer
Bei der Überprüfung eines Website-weiten Problems ist die Verwendung eines Website-weiten Audit-Programms als Assistent eine bessere Möglichkeit, die Zeit für SEO-Projekte zu organisieren. Wie im Bereich der internen Links habe ich Oncrawl Site Audit zusammen mit anderen Tools und Xpath-Inspektionen verwendet.
Erstens hätte es zu viel Zeit gekostet, jedes Problem im Inhaltsbereich zu beheben. In diesen Tagen der zusammenbrechenden Krise war Zeit ein Luxus. Also beschloss ich, Quick-Win-Probleme zu beheben, wie zum Beispiel:
- Löschen von doppelten, unnötigen und sich wiederholenden Inhalten
- Kurze und dünne Inhalte vereinheitlichen, denen umfassende Informationen fehlen
- Neuveröffentlichung von Inhalten, denen Unterüberschriften und eine mit Augen verfolgbare Struktur fehlten
- Fixierung des intensiven Marketing-Tons im Inhalt
- Löschen vieler Call-to-Action-Buttons aus dem Inhalt
- Bessere visuelle Kommunikation mit Bildern und Videos
- Inhalte und Ziel-Keywords mit Benutzer- und Suchabsicht kompatibel machen
- Verwenden und Zeigen von Finanz- und Bildungseinrichtungen in den Inhalten für Vertrauen
- Nutzung der sozialen Gemeinschaft zur Erstellung eines sozialen Bestätigungsnachweises
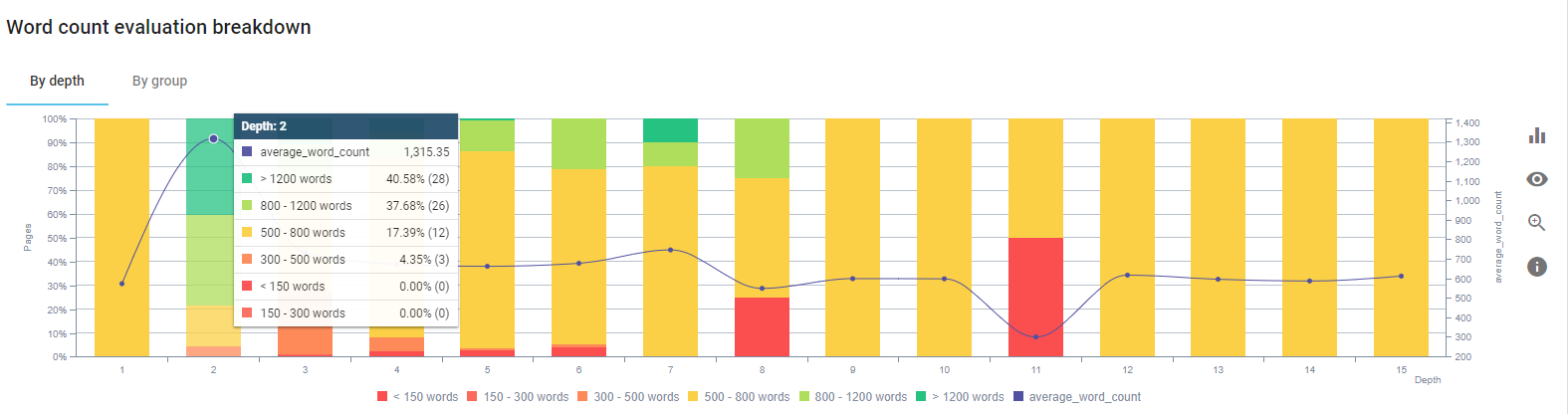

Wir haben uns darauf konzentriert, den Inhalt der Produktseiten und der ihnen am nächsten liegenden Ratgeberseiten zu fixieren.
Zu Beginn dieses Prozesses enthielten die meisten unserer Produkt- und Transaktions-Landing-/Richtlinienseiten weniger als 500 Wörter ohne umfassende Informationen.
In 25 Tagen haben wir folgende Aktionen durchgeführt:
- 228 Seiten mit doppelten, unnötigen und sich wiederholenden Inhalten gelöscht. (Die Backlink-Profile von Ccontent wurden vor dem Löschvorgang überprüft. Und wir haben 301- oder 410-Statuscodes für eine bessere Kommunikation mit dem Googlebot verwendet.)
- Zusammen mehr als 123 Seiten ohne umfassende Informationen.
- Verwendete Unterüberschriften entsprechend ihrer Wichtigkeit und Benutzernachfrage in den Inhalten.
- Gelöschter Markenname und CTA-Schaltflächen mit Marketingsprache.
- Fügen Sie Text in Bilder ein, um das Hauptthema zu verstärken.
Dies ist ein Screenshot von Googles Vision AI. Google kann Text in Bildern lesen und Gefühle und Identitäten innerhalb von Entitäten erkennen.
- Aktiviert unser soziales Netzwerk, um mehr Benutzer anzuziehen.
- Inhaltslücke zwischen Wettbewerbern und uns untersucht und mehr als 80 neue Inhalte erstellt.
- Verwendete Google Analytics, Search Console und Google Data Studio, um die leistungsschwachen Seiten mit hoher Absprungrate und geringem Traffic zu ermitteln.
- Habe nach Featured Snippets und deren Keywords und Inhaltsstruktur recherchiert. Wir haben die gleichen Überschriften und die gleiche Inhaltsstruktur zu unseren verwandten Inhalten hinzugefügt. Dadurch haben wir unsere Featured Snippets erhöht.
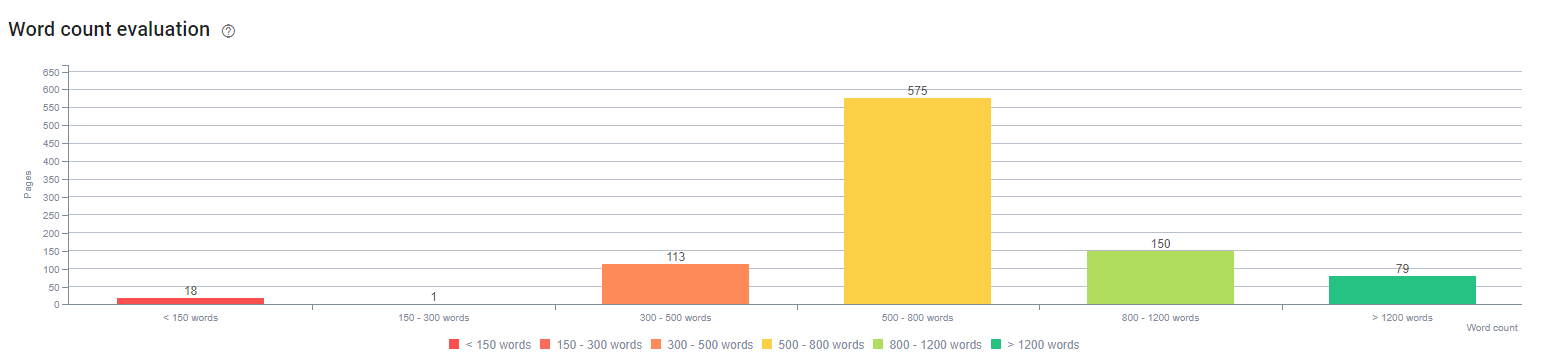
Zu Beginn dieses Prozesses bestanden unsere Inhalte meist aus zwischen 150 und 300 Wörtern. Unsere durchschnittliche Inhaltslänge hat sich für die gesamte Website um 350 Wörter erhöht.
4. Problem: Indexverschmutzung, Aufblasen und kanonische Tags
Google hat sich nie zu Index Pollution geäußert und ich bin mir nicht sicher, ob ihn jemand schon einmal als SEO-Begriff verwendet hat oder nicht. Alle Seiten, die für Google für einen effizienteren Index-Score keinen Sinn machen, sollten aus den Google-Indexseiten entfernt werden. Seiten, die eine Indexverschmutzung verursachen, sind Seiten, die seit Monaten keinen Traffic mehr erzeugt haben. Sie haben null CTR und null organische Keywords. In den Fällen, in denen sie ein paar organische Schlüsselwörter haben, müssten sie zu einem Konkurrenten anderer Seiten auf Ihrer Website für dieselben Schlüsselwörter werden.
Außerdem hatten wir nach Index-Bloat recherchiert und noch mehr unnötige indizierte Seiten gefunden. Diese Seiten existierten aufgrund einer fehlerhaften Site-Informationsstruktur oder aufgrund einer fehlerhaften URL-Struktur.
Ein weiterer Grund für dieses Problem waren falsch verwendete Canonical Tags. Seit mehr als zwei Jahren werden kanonische Tags nur als Hinweise für den Googlebot behandelt. Wenn sie falsch verwendet werden, wird der Googlebot sie nicht berechnen oder bei der Bewertung der Website berücksichtigen. Und außerdem werden Sie für diese Berechnung Ihr Crawl-Budget wahrscheinlich ineffizient verbrauchen. Aufgrund der fehlerhaften Verwendung von Canonical-Tags wurden mehr als 300 Kommentarseiten mit doppeltem Inhalt indiziert.
Meine Theorie zielt darauf ab, Google nur qualitativ hochwertige und notwendige Seiten mit dem Potenzial zu zeigen, Klicks zu verdienen und einen Mehrwert für die Nutzer zu schaffen.
Lösung: Index-Verschmutzung und Aufblasen beheben
Zuerst nahm ich Rat von John Mueller von Google. Ich fragte ihn, ob ich das noindex-Tag für diese Seiten verwende, aber Googlebot trotzdem folgen lasse: „Würde ich Link Equity und Crawling-Effizienz verlieren?“
Wie Sie sich vorstellen können, sagte er zuerst ja, schlug dann aber vor, dass die Verwendung interner Links dieses Hindernis überwinden kann.
Ich fand auch heraus, dass die gleichzeitige Verwendung von noindex-Tags und dofollow die Crawling-Rate des Googlebot auf diesen Seiten verringerte. Diese Strategien ermöglichten es mir, den Googlebot dazu zu bringen, meine Produkt- und wichtigen Richtlinienseiten häufiger zu crawlen. Ich habe auch meine interne Linkstruktur geändert, wie John Mueller es empfohlen hat.
In einer kurzen Zeit:
- Unnötige indizierte Seiten wurden entdeckt.
- Mehr als 300 Seiten wurden aus dem Index entfernt.
- Noindex-Tag wurde implementiert.
- Die interne Linkstruktur wurde für die Seiten geändert, die Links von Seiten erhielten, die aus dem Index entfernt wurden.
- Crawl-Effizienz und -Qualität wurden im Laufe der Zeit untersucht.
5. Problem: Falsche Statuscodes
Am Anfang ist mir aufgefallen, dass der Googlebot viele gelöschte Inhalte aus der Vergangenheit besucht. Sogar Seiten von vor acht Jahren wurden noch gecrawlt. Dies war auf die Verwendung falscher Statuscodes insbesondere für gelöschte Inhalte zurückzuführen.
Es gibt einen großen Unterschied zwischen 404- und 410-Funktionen. Eine davon ist für eine Fehlerseite, auf der kein Inhalt vorhanden ist, und die andere für gelöschte Inhalte. Darüber hinaus verweisen gültige Seiten auch auf viele gelöschte Quell- und Inhalts-URLs. Einige gelöschte Bilder und CSS- oder JS-Assets wurden auch auf den gültigen veröffentlichten Seiten als Ressourcen verwendet. Schließlich gab es viele weiche 404-Seiten und mehrere Umleitungsketten sowie temporäre 302-307-Umleitungen für dauerhaft umgeleitete Seiten.
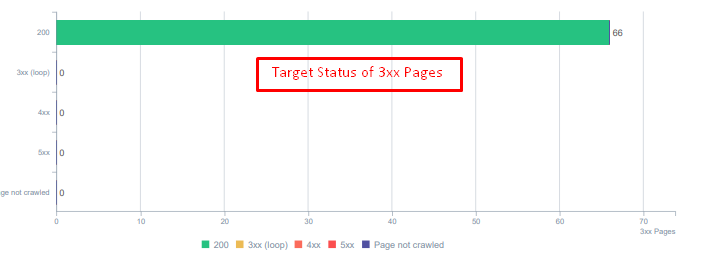
Statuscodes für umgeleitete Assets heute.
Lösung: Korrigieren falscher Statuscodes
- Jeder 404-Statuscode wurde in den 410-Statuscode umgewandelt. (Mehr als 30000)
- Jede Ressource mit dem Statuscode 404 wurde durch eine neue gültige Ressource ersetzt. (Mehr als 500)
- Jede 302-307-Weiterleitung wurde in eine permanente 301-Weiterleitung umgewandelt. (Mehr als 1500)
- Umleitungsketten wurden aus den verwendeten Assets entfernt.
- Jeden Monat hatten wir in unserer Protokollanalyse mehr als 25.000 Zugriffe auf Seiten und Ressourcen mit einem 404-Statuscode erhalten. Jetzt sind es weniger als 50 für 404-Statuscodes pro Monat und null Treffer für 410-Statuscodes…
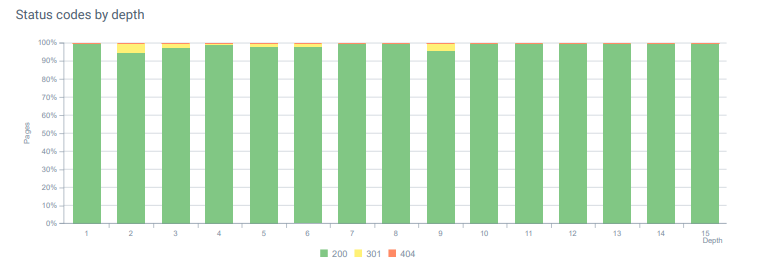
Statuscodes in der gesamten Seitentiefe heute.
6. Problem: Semantisches HTML
Semantik bezieht sich darauf, was etwas bedeutet. Semantisches HTML enthält Tags, die der Seitenkomponente innerhalb einer Hierarchie die Bedeutung geben. Mit dieser hierarchischen Codestruktur können Sie Google mitteilen, was der Zweck eines Teils des Inhalts ist. Auch für den Fall, dass der Googlebot nicht alle Ressourcen crawlen kann, die zum vollständigen Rendern Ihrer Seite erforderlich sind, können Sie dem Googlebot zumindest das Layout Ihrer Webseite und die Funktionen Ihrer Inhaltsteile angeben.
Auf Hangikredi.com wusste ich nach der Aktualisierung des Google Core-Algorithmus vom 12. März, dass aufgrund der nicht optimierten Website-Struktur nicht genügend Crawl-Budget vorhanden war. Damit der Googlebot Ziel, Funktion, Inhalt und Nützlichkeit der Webseite leichter verstehen kann, habe ich mich für die Verwendung von semantischem HTML entschieden.
Lösung: Semantische HTML-Nutzung
Gemäß den Quality Rater Guidelines von Google hat jeder Suchende eine Absicht und jede Webseite hat eine Funktion gemäß dieser Absicht. Um diese Funktionen dem Googlebot zu beweisen, haben wir einige Verbesserungen an unserer HTML-Struktur für einige der Seiten vorgenommen, die weniger vom Googlebot gecrawlt werden.
- Verwendetes <main>-Tag zum Anzeigen des Hauptinhalts und der Funktion der Seite.
- Verwendet <nav> für den Navigationsteil.
- Verwendet <footer> für die Fußzeile der Website.
- <article> für den Artikel verwendet.
- Verwendete <section>-Tags für jedes Überschriften-Tag.
- Verwendete <picture>-, <table>-, <citation>-Tags für Bilder, Tabellen und Zitate im Inhalt.
- Verwendet, <aside>-Tag für den ergänzenden Inhalt.
- Die H1-H6-Hierarchieprobleme wurden behoben (Trotz der neuesten Google-Aussage „Die Verwendung von zwei H1 ist kein Problem“, hilft die Verwendung der richtigen Struktur dem Googlebot.)
- Wie im Abschnitt Inhaltsstruktur haben wir auch semantisches HTML für Featured Snippets verwendet, wir haben Tabellen und Listen für mehr Featured Snippet-Ergebnisse verwendet.

Für uns war das keine realistisch umsetzbare Entwicklung für den gesamten Standort. Dennoch implementieren wir mit jedem Design-Update semantische HTML-Tags für zusätzliche Webseiten.
7. Problem: Strukturierte Datennutzung
Wie bei der Verwendung von semantischem HTML können strukturierte Daten verwendet werden, um dem Googlebot die Funktionen und Definitionen von Webseitenteilen anzuzeigen. Darüber hinaus sind strukturierte Daten für Rich-Ergebnisse obligatorisch. Auf unserer Website wurden strukturierte Daten bis Ende März nicht oder häufiger falsch verwendet. Um bessere Beziehungen zu Unternehmen auf unserer Website und unseren Off-Page-Konten aufzubauen, haben wir mit der Implementierung strukturierter Daten begonnen.
Lösung: Korrekte und getestete strukturierte Datennutzung
Für Finanzinstitute und YMYL-Websites können strukturierte Daten viele Probleme beheben. Sie können beispielsweise die Identität der Marke, die Art des Inhalts zeigen und eine bessere Snippet-Ansicht erstellen. Wir haben die folgenden strukturierten Datentypen für die gesamte Website und einzelne Seiten verwendet:
- FAQ Strukturierte Daten für Hauptproduktseiten
- Strukturierte Webseitendaten
- Organisationsstrukturierte Daten
- Breadcrumb-strukturierte Daten
8. Sitemap- und Robots.txt-Optimierung
Auf Hangikredi.com gibt es keine dynamische Sitemap. Die damalige Sitemap enthielt nicht alle notwendigen Seiten und enthielt auch gelöschte Inhalte. Außerdem wurden in der Robots.txt-Datei einige der Affiliate-Referrer-Seiten mit Tausenden von externen Links nicht gesperrt. Dazu gehörten auch einige JS-Dateien von Drittanbietern, die nichts mit Inhalten zu tun haben, und andere zusätzliche Ressourcen, die für den Googlebot unnötig waren.
Folgende Schritte wurden angewendet:
- Erstellt eine sitemap_index.xml für mehrere Sitemaps, die nach Site-Kategorien erstellt werden, um bessere Crawling-Signale und eine bessere Abdeckungsprüfung zu erzielen.
- Einige der JS-Dateien von Drittanbietern und einige unnötige JS-Dateien wurden in der robots.txt-Datei nicht zugelassen.
- Affiliate-Seiten mit externen Links und ohne Zielseitenwert wurden nicht zugelassen, wie wir im Abschnitt „Pagerank“ oder „Internal Link Sculpting“ erwähnt haben.
- Mehr als 500 Abdeckungsprobleme behoben. (Die meisten davon waren Seiten, die indexiert wurden, obwohl sie von Robots.txt nicht zugelassen wurden.)
Sie können unsere Crawling-Rate, Auslastung und Nachfragesteigerung aus dem folgenden Diagramm entnehmen:
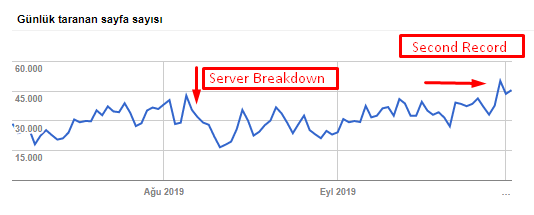
Anzahl der gecrawlten Seiten pro Tag durch den Googlebot. Bis zum 1. August gab es einen stetigen Anstieg der pro Tag gecrawlten Seiten. Nachdem ein Angriff Anfang August einen Serverausfall verursacht hatte, erlangte er seine Stabilität in etwas mehr als einem Monat wieder.

Die vom Googlebot pro Tag gecrawlte Last hat sich parallel zur Anzahl der pro Tag gecrawlten Seiten entwickelt.
9. AMP-Probleme beheben
Auf der Website des Unternehmens hat jede Blogseite eine AMP-Version. Aufgrund fehlerhafter Code-Implementierung und fehlender AMP-Canonicals wurden alle AMP-Seiten wiederholt aus dem Index gelöscht. Dies führte zu einem instabilen Indexwert und mangelndem Vertrauen in die Website. Außerdem hatten AMP-Seiten standardmäßig englische Begriffe und Wörter in türkischen Inhalten.
- Canonical-Tags wurden für mehr als 400 AMP-Seiten korrigiert.
- Es wurden fehlerhafte Codeimplementierungen gefunden und behoben. (Dies lag hauptsächlich an der fehlerhaften Implementierung von AMP-Analytics- und AMP-Canonical-Tags.)
- Englische Begriffe wurden standardmäßig ins Türkische übersetzt.
- Für die Blog-Seite der Kanzlei-Website wurde Index- und Ranking-Stabilität geschaffen.
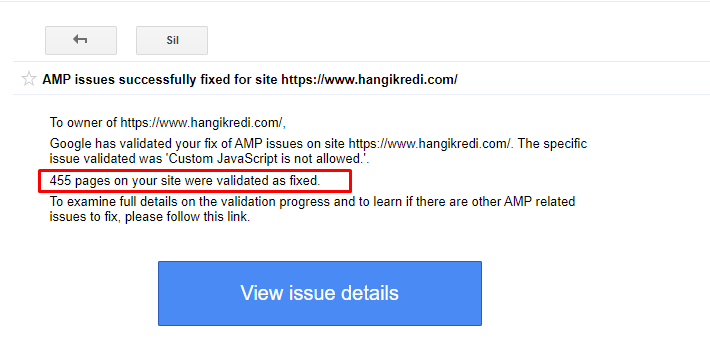
Eine Beispielnachricht in GSC zu AMP-Verbesserungen
10. Meta-Tag-Probleme und -Lösungen
Aufgrund der Probleme mit dem Crawl-Budget, manchmal bei kritischen Suchanfragen für wichtige Hauptproduktseiten, hat Google Inhalte in den Meta-Tags nicht indexiert oder angezeigt. Anstelle des Metatitels zeigte das SERP-Listing nur den aus zwei Wörtern zusammengesetzten Firmennamen. Es wurde keine Snippet-Beschreibung angezeigt. Dies senkte unsere CTR und schadete unserer Markenidentität. Wir haben dieses Problem behoben, indem wir die Meta-Tags wie unten gezeigt an den Anfang unseres Quellcodes verschoben haben.
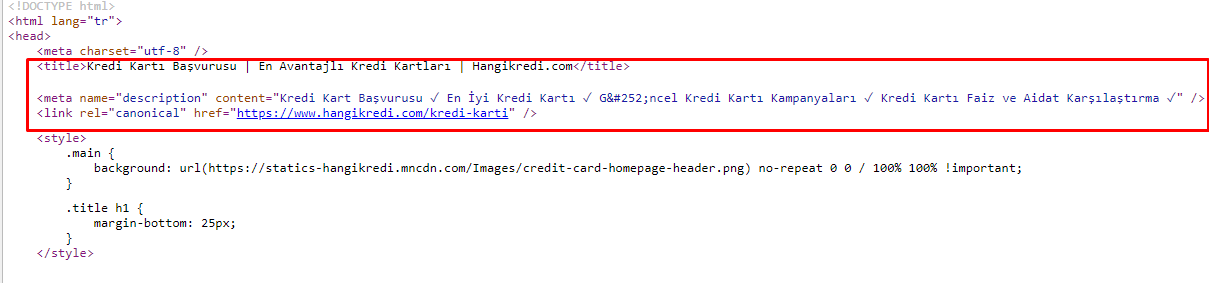
Neben dem Crawl-Budget haben wir auch mehr als 600 Meta-Tags für Transaktions- und Informationsseiten optimiert:
- Optimierte Zeichenlänge für Mobilgeräte.
- Mehr Keywords in den Titeln verwendet
- Verwendete verschiedene Arten von Meta-Tags und untersuchte CTR, Keyword-Lücke und Ranking-Änderungen
- Dank dieser Optimierungsprozesse wurden mehr Seiten mit korrekter Site-Baumstruktur erstellt, um sekundäre Keywords besser anzusprechen.
- Auf unserer Website haben wir noch verschiedene Metatitel, Beschreibungen und Überschriften zum Testen des Google-Algorithmus und der CTR der Suchbenutzer.
11. Bildleistungsprobleme und Lösungen
Bildprobleme können in zwei Arten unterteilt werden. Für Inhaltskomfort und Seitengeschwindigkeit. Für beide hat die Website der Firma noch viel zu tun.
Im März und April nach dem negativen Kernalgorithmus-Update vom 12. März:
- Bilder hatten keine Alt-Tags oder sie hatten falsche Alt-Tags.
- Sie hatten keine Titel.
- Sie hatten keine korrekte URL-Struktur.
- Sie hatten keine Erweiterungen der nächsten Generation.
- Sie wurden nicht komprimiert.
- Sie hatten nicht für jede Bildschirmgröße des Geräts die richtige Auflösung.
- Sie hatten keine Bildunterschriften.
So bereiten Sie sich auf das nächste Update des Google Core-Algorithmus vor:
- Bilder wurden komprimiert.
- Ihre Erweiterungen wurden teilweise geändert.
- Für die meisten von ihnen wurden Alt-Tags geschrieben.
- Titel und Bildunterschriften wurden für den Benutzer behoben.
- URL-Strukturen wurden teilweise für den Benutzer korrigiert.
- Wir haben einige unbenutzte Bilder gefunden, die noch vom Browser geladen werden, und sie aus dem System gelöscht.
Aufgrund der Website-Infrastruktur haben wir teilweise Bild-SEO-Korrekturen implementiert.
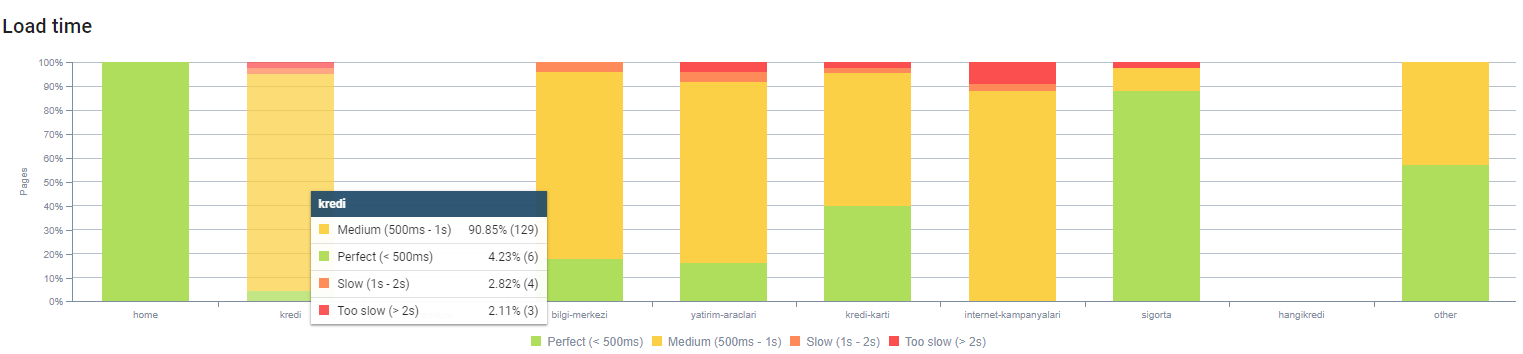
Sie können unsere Seitenladezeit nach Seitentiefe oben beobachten. Wie Sie sehen können, sind die meisten Produktseiten immer noch schwer.
12. Cache-, Prefetch- und Preload-Probleme und -Lösungen
Vor dem Update des Kernalgorithmus vom 12. März gab es auf der Website der Firma ein lockeres Cache-System. Einige der Inhaltsteile befanden sich im Cache, andere jedoch nicht. Dies war insbesondere für Produktseiten ein Problem, da diese doppelt so langsam waren wie die Produktseiten unserer Mitbewerber. Die meisten Komponenten unserer Webseiten sind eigentlich statische Quellen, aber sie hatten immer noch keine Etags zur Angabe des Cache-Bereichs.
So bereiten Sie sich auf das nächste Update des Google Core-Algorithmus vor:
- Wir haben einige Komponenten für jede Webseite zwischengespeichert und sie statisch gemacht.
- Diese Seiten waren wichtige Produktseiten.
- Wir verwenden aufgrund der Website-Infrastruktur immer noch keine E-Tags.
- Insbesondere Bilder, statische Ressourcen und einige wichtige Inhaltsteile werden jetzt vollständig auf der gesamten Website zwischengespeichert.
- Wir haben damit begonnen, DNS-Prefetch-Code für einige vergessene ausgelagerte Ressourcen zu verwenden.
- Wir verwenden den Preload-Code immer noch nicht, aber wir arbeiten an der User-Journey auf der Website, um ihn in Zukunft zu implementieren.
13. Optimierung und Minimierung von HTML, CSS und JS
Aufgrund der Probleme mit der Site-Infrastruktur gab es nicht so viele Dinge, die für die Site-Geschwindigkeit zu tun waren. Ich habe versucht, die Lücke mit allen möglichen Methoden zu schließen, einschließlich des Löschens einiger Seitenkomponenten. Für wichtige Produktseiten haben wir die HTML-Codestruktur bereinigt, verkleinert und komprimiert.
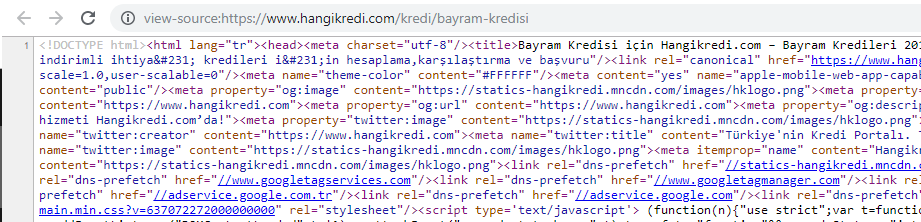
Ein Screenshot aus dem Quellcode einer unserer saisonalen, aber wichtigen Produktseiten. Der Einsatz von FAQ Structured Data, HTML Minifying, Image Optimization, Content Refreshing und Internal Linking verschaffte uns zur richtigen Zeit den ersten Platz. (Stichwort ist „Bayram Kredisi“ auf Türkisch und bedeutet „Urlaubskredit“)
Auch CSS Factoring, Refactoring und JS Compression haben wir teilweise in kleinen Schritten implementiert. Als die Platzierungen fielen, untersuchten wir die Geschwindigkeitslücke der Website zwischen den Seiten unserer Konkurrenten und unserer. Wir hatten einige dringende Seiten ausgewählt, die wir beschleunigen könnten. Wir haben auf diesen Seiten auch kritische CSS-Dateien teilweise gereinigt und komprimiert. Wir haben den Prozess zum Entfernen einiger JS-Dateien von Drittanbietern eingeleitet, die von verschiedenen Abteilungen der Firma verwendet werden, aber sie wurden noch nicht entfernt. Bei einigen Produktseiten konnten wir auch die Ladereihenfolge der Ressourcen ändern.
Prüfung der Konkurrenten
Zusätzlich zu jeder technischen SEO-Verbesserung war die Untersuchung der Wettbewerber meine beste Anleitung, um die Art und die Ziele eines Kernalgorithmus-Updates zu verstehen. Ich habe einige nützliche und hilfreiche Programme verwendet, um Design-, Inhalts-, Rang- und Technologieänderungen meiner Konkurrenten zu verfolgen.
- Für Keyword-Ranking-Änderungen habe ich Wincher, Semrush und Ahrefs verwendet.
- Für Markenerwähnungen habe ich Google Alerts, BuzzSumo und Talkwalker verwendet.
- Für Berichte über neue Links und neue Keywords habe ich Ahrefs Alert verwendet.
- Für Inhalts- und Designänderungen habe ich Visualping verwendet.
- Für Technologieänderungen habe ich SimilarTech verwendet.
- Für Google Update News and Inspection habe ich hauptsächlich Semrush Sensor, Algoroo und CognitiveSEO Signals verwendet.
- Um den URL-Verlauf von Mitbewerbern zu untersuchen, habe ich die Wayback Machine verwendet.
- Für die Servergeschwindigkeit von Wettbewerbern habe ich Chrome DevTools und ByteCheck verwendet.
- Für Crawl- und Renderkosten habe ich „Was kostet meine Website“ verwendet. (Since last month, I have started using Onely's new JS Tools like WWJD or TL:DR..)

A screenshot from SimilarTech for my main competitor.
A screenshot from Visualping which shows the layout changes for my secondary competitor.
Testing the value of the changes
With all of these problems identified and solutions in place, I was ready to see whether the website would hold up to the next Google core algorithm updates.
In the next article, I'll look at the major core algorithm updates over the next several months, and how the site performed.