
Vorhersage von SEO-Traffic mit Prophet und Python
Veröffentlicht: 2021-03-16Das Festlegen von Zielen und das Bewerten der Leistung im Laufe der Zeit ist eine sehr interessante Übung, um zu verstehen, was wir erreichen können und ob die von uns angewandte Strategie effektiv ist oder nicht. Allerdings ist es in der Regel nicht so einfach, diese Ziele festzulegen, da wir zunächst eine Prognose erstellen müssen.
Das Erstellen einer Prognose ist keine mühelose Sache, aber dank einiger verfügbarer Prognoseverfahren, unserer CPU und einiger Programmierkenntnisse können wir die Komplexität erheblich reduzieren. In diesem Beitrag werde ich Ihnen zeigen, wie wir genaue Vorhersagen treffen können und wie Sie dies auf SEO anwenden können, indem Sie Python und die Bibliothek Prophet verwenden und keine Wahrsager-Superkräfte haben müssen.
Wenn Sie noch nie von Prophet gehört haben, fragen Sie sich vielleicht, was es ist. Kurz gesagt, Prophet ist ein von Facebooks Core Data Science-Team veröffentlichtes Verfahren zur Prognose, das in Python und R verfügbar ist und sehr gut mit Ausreißern und saisonalen Effekten umgehen kann
liefern genaue und schnelle Vorhersagen.
Wenn wir über Prognosen sprechen, müssen wir zwei Dinge berücksichtigen:
- Je mehr historische Daten wir haben, desto genauer werden unser Modell und damit unsere Vorhersagen sein.
- Das Vorhersagemodell ist nur gültig, wenn die internen Faktoren gleich bleiben und keine externen Faktoren es beeinflussen. Das bedeutet, wenn wir beispielsweise einen Beitrag pro Woche veröffentlicht haben und mit der Veröffentlichung von zwei Beiträgen pro Woche beginnen, ist dieses Modell möglicherweise nicht gültig, um vorherzusagen, was das Ergebnis dieser Strategieänderung sein wird. Wenn andererseits ein Algorithmus aktualisiert wird, ist das Modell möglicherweise auch nicht gültig. Denken Sie daran, dass das Modell auf der Grundlage historischer Daten erstellt wird.
Um dies auf SEO anzuwenden, werden wir SEO-Sitzungen für den kommenden Monat vorhersagen, indem wir den nächsten Schritten folgen:
- Abrufen von Daten von Google Analytics über die organischen Sitzungen für einen bestimmten Zeitraum.
- Training unseres Modells.
- Prognose des SEO-Verkehrs für den kommenden Monat.
- Bewerten, wie gut unser Modell mit dem mittleren absoluten Fehler ist.
Sie möchten mehr über die Funktionsweise dieses Prognoseverfahrens erfahren? Dann fangen wir an!
Abrufen der Daten von Google Analytics
Wir können die Datenextraktion aus Google Analytics auf zwei Arten angehen: Exportieren einer Excel-Datei von der normalen Schnittstelle oder Verwenden der API zum Abrufen dieser Daten.
Importieren der Daten aus einer Excel-Datei
Der einfachste Weg, diese Daten aus Google Analytics zu erhalten, besteht darin, zum Abschnitt Kanäle in der Seitenleiste zu gehen, auf Organisch zu klicken und die Daten mit der Schaltfläche oben auf der Seite zu exportieren. Stellen Sie sicher, dass Sie im Dropdown-Menü über dem Diagramm die Variable auswählen, die Sie analysieren möchten, in diesem Fall Sitzungen.
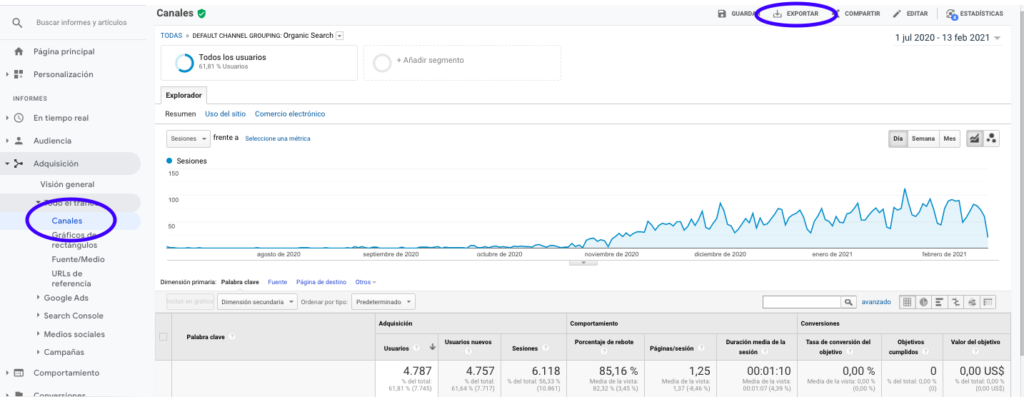
Nachdem wir die Daten als Excel-Datei exportiert haben, können wir sie mit Pandas in unser Notebook importieren. Beachten Sie, dass die Excel-Datei mit solchen Daten verschiedene Registerkarten enthält, sodass die Registerkarte mit dem monatlichen Datenverkehr als Argument im folgenden Codeabschnitt angegeben werden muss. Wir löschen auch die letzte Zeile, da sie die Gesamtzahl der Sitzungen enthält, was unser Modell verzerren würde.
pandas als pd importieren
df = pd.read_excel ('.xlsx', Tabellenname = "")
df = df.drop(len(df) - 1)
Wir können mit Matplotlib zeichnen, wie die Daten aussehen:
aus matplotlib importiere pyplot
df["Sitzungen"].plot(title = "Sitzungen")
pyplot.show() 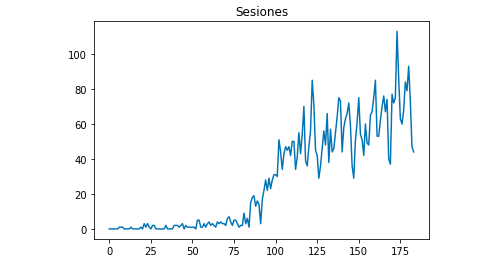
Verwendung der Google Analytics-API
Um die Google Analytics-API nutzen zu können, müssen wir zunächst ein Projekt in der Google-Entwicklerkonsole erstellen, den Google Analytics-Berichtsdienst aktivieren und die Anmeldeinformationen abrufen. Jean-Christophe Chouinard erklärt in diesem Artikel sehr gut, wie man das einrichtet.
Sobald die Anmeldeinformationen vorliegen, müssen wir uns authentifizieren, bevor wir unsere Anfrage stellen können. Die Authentifizierung muss mit der Anmeldeinformationsdatei erfolgen, die ursprünglich von der Entwicklerkonsole von Google bezogen wurde. Wir müssen in unserem Code auch die GA-Ansichts-ID der Eigenschaft notieren, die wir verwenden möchten.
aus apiclient.discovery import build
aus oauth2client.service_account importieren Sie ServiceAccountCredentials
SCOPES = ['https://www.googleapis.com/auth/analytics.readonly']
KEY_FILE_LOCATION = ''
AUSSICHT_
Anmeldeinformationen = ServiceAccountCredentials.from_json_keyfile_name (KEY_FILE_LOCATION, SCOPES)
analytics = build('analyticsreporting', 'v4', Credentials=Credentials)Nach der Authentifizierung müssen wir nur noch die Anfrage stellen. Diejenige, die wir verwenden müssen, um die Daten über die organischen Sitzungen für jeden Tag zu erhalten, ist:
Antwort = analytics.reports().batchGet(body={
'reportRequests': [{
'viewId': VIEW_ID,
'dateRanges': [{'startDate': '2020-09-01', 'endDate': '2021-01-31'}],
'Metriken': [
{"Ausdruck": "ga:sessions"}
], "Maße": [
{"name": "ga:date"}
],
"filtersExpression":"ga:channelGrouping=~Organic",
"includeEmptyRows": "true"
}]}).ausführen()Beachten Sie, dass wir den Zeitbereich in dateRanges auswählen. In meinem Fall werde ich Daten vom 1. September bis zum 31. Januar abrufen: [{'startDate': '2020-09-01', 'endDate': '2021-01-31'}]
Danach müssen wir nur noch die Antwortdatei abrufen, um die Tage mit ihren organischen Sitzungen an eine Liste anzuhängen:
list_values = [] für x als Antwort["Berichte"][0]["Daten"]["Zeilen"]: list_values.append([x["Dimensionen"][0],x["Metriken"][0]["Werte"][0]])
Wie Sie sehen können, ist die Verwendung der Google Analytics API recht einfach und kann für viele Zwecke verwendet werden. In diesem Artikel habe ich erklärt, wie Sie die Google Analytics-API verwenden können, um Warnungen zu erstellen, um leistungsschwache Seiten zu erkennen.

Anpassen der Listen an Dataframes
Um Prophet zu verwenden, müssen wir einen Datenrahmen mit zwei Spalten eingeben, die benannt werden müssen: „ds“ und „y“. Wenn Sie die Daten aus einer Excel-Datei importiert haben, haben wir sie bereits als Dataframe, sodass Sie nur die Spalten „ds“ und „y“ benennen müssen:
df.columns = ['ds', 'y']
Falls Sie die API zum Abrufen der Daten verwendet haben, müssen wir die Liste in einen Datenrahmen umwandeln und die Spalten wie erforderlich benennen:
von pandas import dataframe df_sessions = DataFrame(list_values,columns=['ds','y'])
Trainieren des Modells
Sobald wir den Datenrahmen mit dem erforderlichen Format haben, können wir unser Modell sehr einfach bestimmen und trainieren mit:
fbprophet importieren von fbprophet import Prophet Modell = Prophet() model.fit(df_sessions)
Unsere Vorhersagen treffen
Endlich, nachdem wir unser Modell trainiert haben, können wir mit der Prognose beginnen! Um mit den Vorhersagen fortzufahren, müssen wir zunächst eine Liste mit dem Zeitbereich erstellen, den wir vorhersagen möchten, und das datetime-Format anpassen:
von pandas import to_datetime Prognose_Tage = [] für x im Bereich (1, 28): date = "2021-02-" + str(x) prognose_tage.append([datum]) Prognose_Tage = DataFrame(Prognose_Tage) prognose_tage.spalten = ['ds'] prognose_tage['ds']= to_datetime(vorhersage_tage['ds'])
In diesem Beispiel verwende ich eine Schleife, die einen Datenrahmen erstellt, der alle Tage ab Februar enthält. Und jetzt geht es nur noch darum, das zuvor trainierte Modell zu verwenden:
Prognose = model.predict(Prognose_Tage)
Wir können ein Diagramm zeichnen, das den prognostizierten Zeitraum hervorhebt:
aus matplotlib importiere pyplot model.plot (Vorhersage) pyplot.show()
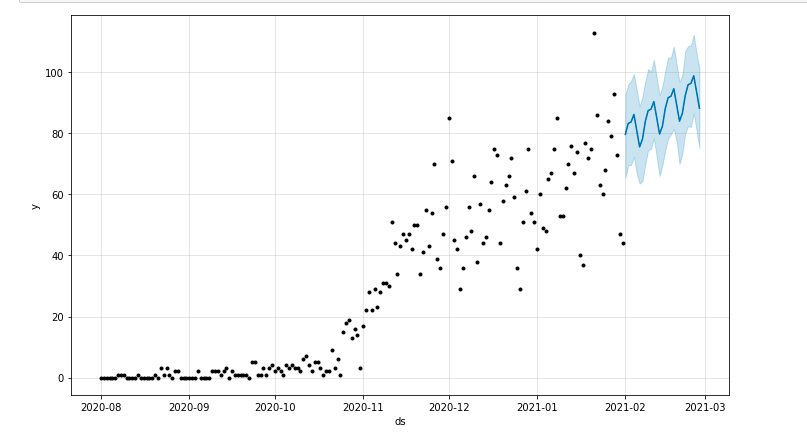
Bewertung des Modells
Schließlich können wir bewerten, wie genau unser Modell ist, indem wir einige Tage aus den Daten entfernen, die zum Trainieren des Modells verwendet werden, die Sitzungen für diese Tage vorhersagen und den mittleren absoluten Fehler berechnen.
Als Beispiel werde ich die letzten 12 Tage ab Januar aus dem ursprünglichen Datenrahmen entfernen, die Sitzungen für jeden Tag prognostizieren und den tatsächlichen Verkehr mit dem prognostizierten vergleichen.
Zuerst entfernen wir die 12 letzten Tage mit Pop aus dem ursprünglichen Datenrahmen und erstellen einen neuen Datenrahmen, der nur die 12 Tage enthält, die für die Prognose verwendet werden:
train = df_sessions.drop(df_sessions.index[-12:]) future = df_sessions.loc[df_sessions["ds"]> train.iloc[len(train)-1]["ds"]]["ds"]
Jetzt trainieren wir das Modell, erstellen die Prognose und berechnen den mittleren absoluten Fehler. Am Ende können wir ein Diagramm zeichnen, das die Differenz zwischen den tatsächlich prognostizierten und den tatsächlichen Werten zeigt. Das habe ich aus diesem Artikel von Jason Brownlee gelernt.
aus sklearn.metrics import mean_absolute_error
importiere numpy als np
aus dem numpy-Import-Array
#Wir trainieren das Modell
Modell = Prophet()
model.fit (Zug)
#Passen Sie den Datenrahmen, der für die Vorhersagetage verwendet wird, an das erforderliche Format von Prophet an.
Zukunft = Liste(Zukunft)
Zukunft = DataFrame(Zukunft)
future = future.rename(columns={0: 'ds'})
# Wir machen die Prognose
Prognose = model.predict(Zukunft)
# Wir berechnen den MAE zwischen den tatsächlichen Werten und den vorhergesagten Werten
y_true = df_sessions['y'][-12:].values
y_pred = Prognose['yhat'].values
mae = mean_absolute_error(y_true, y_pred)
# Wir zeichnen die endgültige Ausgabe für ein visuelles Verständnis
y_true = np.stack(y_true).astype(float)
pyplot.plot(y_true, label='Actual')
pyplot.plot(y_pred, label='Vorhergesagt')
pyplot.legend()
pyplot.show()
drucken 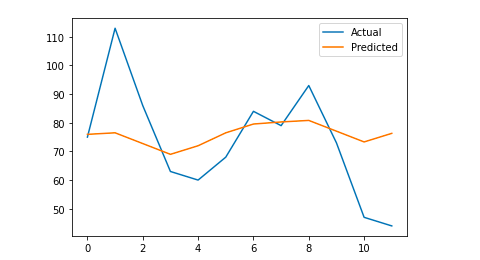
Mein mittlerer absoluter Fehler beträgt 13, was bedeutet, dass mein prognostiziertes Modell jedem Tag 13 Sitzungen mehr zuweist als die tatsächlichen, was ein akzeptabler Fehler zu sein scheint.
Das war's Leute! Ich hoffe, dass Sie diesen Artikel interessant fanden und Sie Ihre SEO-Prognosen erstellen können, um Ziele festzulegen.
Weiter gehen: OnCrawl Labs
Wenn Ihnen die Vorhersage Ihres Datenverkehrs mit dieser Methode Spaß gemacht hat, werden Sie auch an OnCrawl Labs interessiert sein, dem Labor für Datenwissenschaft und maschinelles Lernen von OnCrawl, das vorcodierte Projekte für Ihre SEO-Workflows anbietet.
Bei der SEO-Prognose hilft Ihnen OnCrawl Labs, Ihre SEO-Prognosen zu verfeinern:
- Gewinnen Sie ein besseres Verständnis der Theorien und des Prozesses hinter dem Facebook-Propheten-Algorithmus
- Analysieren Sie ein Traffic-Segment, z. B. nur Traffic zu Long-Tail-Keywords oder nur Branded-Keywords…
- Folgen Sie einem Schritt-für-Schritt-Prozess, um historische Ereignisse einzurichten und ihren Einfluss und ihre Wiederholungswahrscheinlichkeit anzupassen.