
Wie extrahiert man relevanten Textinhalt aus einer HTML-Seite?
Veröffentlicht: 2021-10-13Kontext
In der Forschungs- und Entwicklungsabteilung von Oncrawl suchen wir zunehmend nach Mehrwert für den semantischen Inhalt Ihrer Webseiten. Mithilfe von Machine-Learning-Modellen für Natural Language Processing (NLP) können Aufgaben mit echtem Mehrwert für SEO durchgeführt werden.
Zu diesen Aufgaben gehören Tätigkeiten wie:
- Feinabstimmung des Inhalts Ihrer Seiten
- Erstellen automatischer Zusammenfassungen
- Fügen Sie Ihren Artikeln neue Tags hinzu oder korrigieren Sie vorhandene
- Optimierung von Inhalten gemäß Ihren Google Search Console-Daten
- usw.
Der erste Schritt in diesem Abenteuer besteht darin, den Textinhalt der Webseiten zu extrahieren, die diese Modelle für maschinelles Lernen verwenden werden. Wenn wir über Webseiten sprechen, umfasst dies HTML, JavaScript, Menüs, Medien, Kopfzeilen, Fußzeilen usw. Das automatische und korrekte Extrahieren von Inhalten ist nicht einfach. In diesem Artikel schlage ich vor, das Problem zu untersuchen und einige Tools und Empfehlungen zu diskutieren, um diese Aufgabe zu erfüllen.
Problem
Das Extrahieren von Textinhalten aus einer Webseite mag einfach erscheinen. Mit ein paar Zeilen Python zum Beispiel, ein paar regulären Ausdrücken (regexp), einer Parsing-Bibliothek wie BeautifulSoup4, und fertig.
Wenn Sie für ein paar Minuten ignorieren, dass immer mehr Websites JavaScript-Rendering-Engines wie Vue.js oder React verwenden, ist das Parsen von HTML nicht sehr kompliziert. Wenn Sie dieses Problem umgehen möchten, indem Sie unseren JS-Crawler in Ihren Crawls nutzen, schlage ich vor, dass Sie „Wie crawlt man eine Website in JavaScript?“ lesen.
Wir möchten jedoch sinnvollen Text extrahieren, der so informativ wie möglich ist. Wenn Sie beispielsweise einen Artikel über das letzte posthume Album von John Coltrane lesen, ignorieren Sie die Menüs, die Fußzeile, … und sehen offensichtlich nicht den gesamten HTML-Inhalt. Diese HTML-Elemente, die auf fast allen Ihren Seiten erscheinen, werden Boilerplate genannt. Wir wollen ihn loswerden und nur einen Teil behalten: den Text, der relevante Informationen enthält.
Daher wollen wir nur diesen Text an maschinelle Lernmodelle zur Verarbeitung übergeben. Deshalb ist es wichtig, dass die Extraktion so qualitativ wie möglich ist.
Lösungen
Insgesamt möchten wir alles loswerden, was um den Haupttext „herumhängt“: Menüs und andere Seitenleisten, Kontaktelemente, Fußzeilen-Links usw. Dafür gibt es mehrere Methoden. Wir interessieren uns hauptsächlich für Open-Source-Projekte in Python oder JavaScript.
nurText
jusText ist eine vorgeschlagene Implementierung in Python aus einer Doktorarbeit: „Removing Boilerplate and Duplicate Content from Web Corpora“. Das Verfahren erlaubt es, Textblöcke aus HTML nach unterschiedlichen Heuristiken in „gut“, „schlecht“, „zu kurz“ zu kategorisieren. Diese Heuristiken basieren hauptsächlich auf der Anzahl der Wörter, dem Text/Code-Verhältnis, dem Vorhandensein oder Fehlen von Links usw. Mehr über den Algorithmus erfahren Sie in der Dokumentation.
Trafilatur
Trafilatura, ebenfalls in Python erstellt, bietet Heuristiken sowohl zum Typ des HTML-Elements als auch zu seinem Inhalt, z. B. Textlänge, Position/Tiefe des Elements im HTML-Code oder Wortanzahl. trafilatura verwendet auch jusText, um einige Verarbeitungen durchzuführen.
Lesbarkeit
Haben Sie jemals die Schaltfläche in der URL-Leiste von Firefox bemerkt? Es ist die Leseansicht: Sie ermöglicht es Ihnen, die Boilerplate von HTML-Seiten zu entfernen, um nur den Haupttextinhalt zu behalten. Ziemlich praktisch für Nachrichtenseiten. Der Code hinter dieser Funktion ist in JavaScript geschrieben und wird von Mozilla Lesbarkeit genannt. Es basiert auf Arbeiten, die vom Arc90-Labor initiiert wurden.
Hier ist ein Beispiel dafür, wie diese Funktion für einen Artikel von der France Musique-Website gerendert wird. 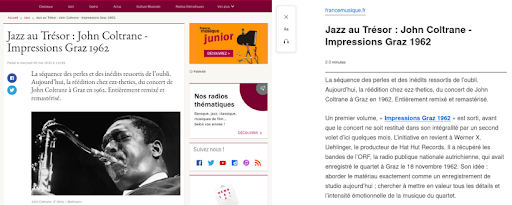
Auf der linken Seite ist es ein Auszug aus dem Originalartikel. Auf der rechten Seite ist es ein Rendering der Reader View-Funktion in Firefox.
Andere
Unsere Recherchen zu Tools zum Extrahieren von HTML-Inhalten veranlassten uns auch, andere Tools in Betracht zu ziehen:
- Zeitung: eine Inhaltsextraktionsbibliothek, die eher Nachrichtenseiten gewidmet ist (Python). Diese Bibliothek wurde verwendet, um Inhalte aus dem OpenWebText2-Korpus zu extrahieren.
- Boilerpy3 ist eine Python-Portierung der Boilerpipe-Bibliothek.
- Dragnet-Python-Bibliothek, die auch von Boilerpipe inspiriert ist.
Oncrawl-Daten³
 Mehr erfahren
Mehr erfahrenBewertung und Empfehlungen
Bevor wir die verschiedenen Tools bewerten und vergleichen, wollten wir wissen, ob die NLP-Community einige dieser Tools verwendet, um ihr Korpus (große Menge an Dokumenten) vorzubereiten. Beispielsweise enthält der Datensatz namens The Pile, der zum Trainieren von GPT-Neo verwendet wird, über 800 GB an englischen Texten aus Wikipedia, Openwebtext2, Github, CommonCrawl usw. Wie BERT ist GPT-Neo ein Sprachmodell, das Typtransformatoren verwendet. Es bietet eine Open-Source-Implementierung ähnlich der GPT-3-Architektur.

Der Artikel „The Pile: An 800GB Dataset of Diverse Text for Language Modeling“ erwähnt die Verwendung von jusText für einen großen Teil ihres Korpus von CommonCrawl. Diese Forschergruppe hatte auch geplant, einen Benchmark der verschiedenen Extraktionswerkzeuge durchzuführen. Leider konnten sie die geplanten Arbeiten aufgrund fehlender Ressourcen nicht durchführen. In ihren Schlussfolgerungen ist Folgendes festzuhalten:
- jusText hat manchmal zu viel Inhalt entfernt, aber immer noch gute Qualität geliefert. Angesichts der Menge an Daten, die sie hatten, war dies für sie kein Problem.
- trafilatura war besser darin, die Struktur der HTML-Seite beizubehalten, behielt aber zu viele Boilerplates bei.
Für unsere Bewertungsmethode haben wir ungefähr dreißig Webseiten genommen. Wir haben den Hauptinhalt „manuell“ extrahiert. Mit diesem sogenannten „Referenz“-Content haben wir dann die Textextraktion der verschiedenen Tools verglichen. Als Metrik haben wir den ROUGE-Score verwendet, der hauptsächlich zur Bewertung automatischer Textzusammenfassungen verwendet wird.
Wir haben diese Tools auch mit einem „hausgemachten“ Tool verglichen, das auf HTML-Parsing-Regeln basiert. Es stellt sich heraus, dass Trafilatura, jusText und unser selbst entwickeltes Tool für diese Metrik besser abschneiden als die meisten anderen Tools.
Hier ist eine Tabelle mit Durchschnittswerten und Standardabweichungen des ROUGE-Scores:
| Werkzeug | Bedeuten | Std |
|---|---|---|
| Trafilatur | 0,783 | 0,28 |
| Oncrawl | 0,779 | 0,28 |
| nurText | 0,735 | 0,33 |
| Kesselpy3 | 0,698 | 0,36 |
| Lesbarkeit | 0,681 | 0,34 |
| Schleppnetz | 0,672 | 0,37 |
Beachten Sie bei den Werten der Standardabweichungen, dass die Qualität der Extraktion stark variieren kann. Die Art und Weise, wie der HTML-Code implementiert wird, die Konsistenz der Tags und die angemessene Verwendung der Sprache können große Unterschiede in den Ergebnissen der Extraktion verursachen.
Die drei Tools, die am besten abschneiden, sind Trafilatura, unser hauseigenes Tool mit dem Namen „oncrawl“, und jusText. Da jusText als Fallback von Trafilatura verwendet wird, haben wir uns entschieden, Trafilatura als unsere erste Wahl zu verwenden. Wenn letzteres jedoch fehlschlägt und null Wörter extrahiert, verwenden wir unsere eigenen Regeln.
Beachten Sie, dass der Trafilatura-Code auch einen Benchmark auf mehreren hundert Seiten bietet. Es berechnet Präzisionswerte, f1-Werte und Genauigkeit basierend auf dem Vorhandensein oder Fehlen bestimmter Elemente im extrahierten Inhalt. Zwei Tools stechen hervor: Trafilatura und goose3. Vielleicht möchten Sie auch lesen:
- Auswahl des richtigen Tools zum Extrahieren von Inhalten aus dem Web (2020)
- das Github-Repository: Artikelextraktions-Benchmark: Open-Source-Bibliotheken und kommerzielle Dienste
Schlussfolgerungen
Die Qualität des HTML-Codes und die Heterogenität des Seitentyps machen es schwierig, qualitativ hochwertige Inhalte zu extrahieren. Wie die EleutherAI-Forscher – die hinter The Pile und GPT-Neo stecken – herausgefunden haben, gibt es keine perfekten Tools. Es gibt einen Kompromiss zwischen manchmal abgeschnittenem Inhalt und Restrauschen im Text, wenn nicht alle Textbausteine entfernt wurden.
Der Vorteil dieser Tools ist, dass sie kontextfrei sind. Das heißt, sie benötigen keine anderen Daten als den HTML-Code einer Seite, um den Inhalt zu extrahieren. Unter Verwendung der Ergebnisse von Oncrawl könnten wir uns eine hybride Methode vorstellen, die die Häufigkeit des Auftretens bestimmter HTML-Blöcke auf allen Seiten der Website verwendet, um sie als Boilerplate zu klassifizieren.
Bei den Datensätzen, die in den Benchmarks verwendet werden, auf die wir im Web gestoßen sind, handelt es sich oft um denselben Seitentyp: Nachrichtenartikel oder Blogbeiträge. Dazu gehören nicht unbedingt Websites von Versicherungen, Reisebüros, E-Commerce usw., bei denen der Textinhalt manchmal komplizierter zu extrahieren ist.
In Bezug auf unseren Benchmark sind wir uns bewusst, dass etwa dreißig Seiten aus Mangel an Ressourcen nicht ausreichen, um eine detailliertere Ansicht der Ergebnisse zu erhalten. Idealerweise hätten wir gerne eine größere Anzahl unterschiedlicher Webseiten, um unsere Benchmark-Werte zu verfeinern. Und wir möchten auch andere Tools wie goose3, html_text oder inscriptis einbinden.