
Extrahieren Sie Daten aus der Google Search Console API für die Datenanalyse in Python
Veröffentlicht: 2022-03-01Die Google Search Console (GSC) ist definitiv eines der nützlichsten Tools für SEO-Spezialisten, da Sie damit Informationen über die Indexabdeckung und insbesondere über die Suchanfragen erhalten, für die Sie derzeit ranken. In diesem Wissen analysieren viele Leute GSC-Daten mithilfe von Tabellenkalkulationen, und das ist in Ordnung, solange Sie verstehen, dass es bei Tools wie Programmiersprachen viel mehr Raum für Verbesserungen gibt.
Leider ist die GSC-Schnittstelle sowohl in Bezug auf die angezeigten Zeilen (nur 5000) als auch auf den verfügbaren Zeitraum von nur 16 Monaten ziemlich begrenzt. Es ist klar, dass dies Ihre Fähigkeit, Einblicke zu erhalten, stark einschränken kann und für größere Websites nicht geeignet ist.
Mit Python können Sie ganz einfach GSC-Daten abrufen und komplexere Berechnungen automatisieren, die in herkömmlicher Tabellenkalkulationssoftware viel mehr Aufwand erfordern würden.
Dies ist die Lösung für eines der größten Probleme in Excel, nämlich Zeilenbegrenzung und -geschwindigkeit. Heutzutage haben Sie viel mehr Alternativen zur Datenanalyse als früher, und hier kommt Python ins Spiel.
Sie benötigen keine fortgeschrittenen Programmierkenntnisse, um diesem Tutorial zu folgen, nur das Verständnis einiger grundlegender Konzepte und etwas Übung mit Google Colab.
Erste Schritte mit der Google Search Console API
Bevor wir beginnen, ist es wichtig, die Google Search Console API einzurichten. Der Prozess ist ziemlich einfach, alles, was Sie brauchen, ist ein Google-Konto. Die Schritte sind wie folgt:
- Erstellen Sie ein neues Projekt auf der Google Cloud Platform. Sie sollten ein Google-Konto haben und ich bin mir ziemlich sicher, dass Sie eines haben. Gehen Sie zur Konsole und Sie sollten oben eine Option zum Erstellen eines neuen Projekts finden.
- Klicken Sie auf das Menü links und wählen Sie „API und Dienste“, Sie gelangen zu einem anderen Bildschirm.
- Suchen Sie in der Suchleiste oben nach „Google Search Console API“ und aktivieren Sie sie.
- Wechseln Sie dann zur Registerkarte „Credentials“. Sie benötigen eine Art Berechtigung, um die API zu verwenden.
- Konfigurieren Sie den Bildschirm „Zustimmung“, da dies obligatorisch ist. Für die Verwendung, die wir machen werden, spielt es keine Rolle, ob es öffentlich ist oder nicht.
- Sie können „Desktop-App“ als Anwendungstyp auswählen
- Wir werden OAuth 2.0 für dieses Tutorial verwenden, Sie sollten eine JSON-Datei herunterladen und jetzt sind Sie fertig.
Dies ist eigentlich der schwierigste Teil für die meisten Menschen, insbesondere für diejenigen, die nicht an Google-APIs gewöhnt sind. Keine Sorge, die nächsten Schritte werden viel einfacher und weniger problematisch sein.
Daten von der Google Search Console API mit Python abrufen
Meine Empfehlung ist, dass Sie ein Notebook wie Jupyter Notebook oder Google Colab verwenden. Letzteres ist besser, da Sie sich keine Gedanken über Anforderungen machen müssen. Daher basiert das, was ich erklären werde, auf Google Colab.
Bevor wir beginnen, aktualisieren Sie Ihre JSON-Datei mit dem folgenden Code auf Google Colab:
aus google.colab Importdateien files.upload()
Installieren wir dann alle Bibliotheken, die wir für unsere Analyse benötigen, und erstellen wir mit diesem Code-Snippet eine bessere Tabellenvisualisierung:
%%Erfassung #lade was gebraucht wird !pip installiere git+https://github.com/joshcarty/google-searchconsole pandas als pd importieren importiere numpy als np importiere matplotlib.pyplot als plt aus google.colab import data_table !git-Klon https://github.com/jroakes/querycat.git !pip install -r querycat/requirements_colab.txt !pip installiere umap-learn data_table.enable_dataframe_formatter() #für eine bessere Tabellenvisualisierung
Schließlich können Sie die Suchkonsolenbibliothek laden, die die einfachste Möglichkeit bietet, dies zu tun, ohne auf lange Funktionen angewiesen zu sein. Führen Sie den folgenden Code mit den von mir verwendeten Argumenten aus und stellen Sie sicher, dass client_config denselben Namen wie die hochgeladene JSON-Datei hat.
Suchkonsole importieren account = searchconsole.authenticate(client_config='client_secret_.json',serialize='credentials.json', flow='console')
Sie werden zur Autorisierung der Anwendung auf eine Google-Seite weitergeleitet, wählen Sie Ihr Google-Konto aus und kopieren Sie dann den Code, den Sie erhalten, und fügen Sie ihn in die Google Colab-Leiste ein.
Wir sind noch nicht fertig, Sie müssen die Eigenschaft auswählen, für die Sie Daten benötigen. Sie können Ihre Immobilien ganz einfach über account.webproperties überprüfen, um zu sehen, was Sie auswählen sollten.
property_name = input('Geben Sie den Namen Ihrer Website ein, wie er im GSC aufgelistet ist: ')
webproperty=account[str(property_name)]
Sobald Sie fertig sind, werden Sie eine benutzerdefinierte Funktion ausführen, um ein Objekt zu erstellen, das unsere Daten enthält.
def extract_gsc_data(webproperty, start, stop, *args):
wenn webproperty nicht None ist:
print(f'Extrahieren von Daten für {webproperty}')
gsc_data = webproperty.query.range(start, stop).dimension(*args).get()
gsc_data zurückgeben
anders:
print('Webproperty nicht gefunden, bitte richtige auswählen')
Rückgabe Keine
Die Idee der Funktion besteht darin, die zuvor definierte Eigenschaft und einen Zeitrahmen in Form von Start- und Enddaten sowie Dimensionen zu verwenden.
Die Möglichkeit, Dimensionen auswählen zu können, ist für SEO-Spezialisten von entscheidender Bedeutung, da Sie so nachvollziehen können, ob Sie ein bestimmtes Maß an Granularität benötigen. Beispielsweise sind Sie in einigen Fällen möglicherweise nicht daran interessiert, die Datumsdimension zu erhalten.
Mein Vorschlag ist, immer Abfrage und Seite auszuwählen, da die Google Search Console-Oberfläche sie separat exportieren kann und es sehr lästig ist, sie jedes Mal zusammenzuführen. Dies ist ein weiterer Vorteil der Search Console API.
In unserem Fall können wir auch direkt die Datumsdimension erhalten, um einige interessante Szenarien zu zeigen, in denen Sie die Zeit berücksichtigen müssen.
ex = extract_gsc_data(webproperty, '2021-09-01', '2021-12-31', 'query', 'page', 'date')
Wählen Sie einen angemessenen Zeitrahmen, da Sie bei größeren Objekten lange warten müssen. Für dieses Beispiel betrachte ich nur eine Zeitspanne von 3 Monaten, die ausreicht, um im Durchschnitt wertvolle Erkenntnisse aus den meisten Datensätzen zu gewinnen.
Sie können sogar eine Woche auswählen, wenn Sie es mit einer großen Datenmenge zu tun haben, was uns wichtig ist, ist der Prozess.
Was ich Ihnen hier zeigen werde, basiert entweder auf synthetischen Daten oder modifizierten realen Daten, um für Beispiele geeignet zu sein. Folglich ist das, was Sie hier sehen, absolut realistisch und kann reale Szenarien widerspiegeln.
Datenreinigung
Für diejenigen, die es nicht wissen, wir können unsere Daten nicht so verwenden, wie sie sind, es gibt einige zusätzliche Schritte, um sicherzustellen, dass wir richtig arbeiten. Zunächst müssen wir unser Objekt in einen Pandas-Datenrahmen konvertieren, eine Datenstruktur, mit der Sie vertraut sein müssen, da sie die Grundlage der Datenanalyse in Python ist.
df = pd.DataFrame(data=ex) df.head()
Die head-Methode kann die ersten 5 Zeilen Ihres Datensatzes anzeigen, es ist sehr praktisch, einen Blick darauf zu werfen, wie Ihre Daten aussehen. Wir können zählen, wie viele Seiten wir haben, indem wir eine einfache Funktion verwenden.
Eine gute Methode zum Entfernen von Duplikaten besteht darin, ein Objekt in eine Menge umzuwandeln, da Mengen keine doppelten Elemente enthalten können.
Einige der Codeschnipsel wurden von Hamlet Batistas Notizbuch inspiriert, andere von Masaki Okazawa.
Markenbegriffe entfernen
Das allererste, was Sie tun müssen, ist, Marken-Keywords zu entfernen. Wir suchen nach Suchanfragen, die unsere Markenbegriffe nicht enthalten. Dies ist mit einer benutzerdefinierten Funktion ziemlich einfach und Sie haben normalerweise eine Reihe von Markenbegriffen.
Für Demonstrationszwecke müssen Sie nicht alle herausfiltern, aber tun Sie es bitte für echte Analysen. Dies ist einer der wichtigsten Schritte zur Datenbereinigung im SEO, da Sie sonst riskieren, irreführende Ergebnisse zu präsentieren.
domain_name = str(input('Markenbegriffe durch Komma getrennt einfügen: ')).replace(',', '|')
importieren re
Domänenname = re.sub(r"\s+", "", Domänenname)
print('Entferne alle Leerzeichen mit RegEx:\n')
df['Marke/Nicht-Marke'] = np.where(
df['query'].str.contains(domain_name), 'Brand', 'Non-branded'
)
Wir werden unserem Datensatz eine neue Spalte hinzufügen, um den Unterschied zwischen den beiden Klassen zu erkennen. Wir können über Tabellen oder Balkendiagramme visualisieren, wie viel sie für die Gesamtzahl der Abfragen ausmachen.
Ich werde Ihnen das Balkendiagramm nicht zeigen, da es sehr einfach ist und ich denke, dass eine Tabelle für diesen Fall besser ist.
brand_count_df = df['Marke/Ohne Marke'].value_counts().rename_axis('cats').to_frame('counts')
brand_count_df['Prozent'] = brand_count_df['counts']/sum(brand_count_df['counts'])
pd.options.display.float_format = '{:.2%}'.format
brand_count_df
Sie können schnell sehen, wie das Verhältnis zwischen Marken- und Nicht-Marken-Keywords ist, um eine Vorstellung davon zu bekommen, wie viel Sie aus Ihrem Datensatz entfernen werden. Hier gibt es kein ideales Verhältnis, obwohl Sie auf jeden Fall einen höheren Anteil an nicht markenbezogenen Keywords haben möchten.
Dann können wir einfach alle als Marken gekennzeichneten Zeilen löschen und mit anderen Schritten fortfahren.
#Nur markenfremde Keywords auswählen df = df.loc[df['Marke/Ohne Marke'] == 'Ohne Marke']
Füllen fehlender Werte und andere Schritte
Wenn Ihr Datensatz fehlende Werte (oder NAs im Fachjargon) aufweist, haben Sie mehrere Möglichkeiten. Am häufigsten werden sie entweder alle gelöscht oder mit einem Platzhalterwert wie 0 oder dem Mittelwert dieser Spalte gefüllt.
Es gibt keine richtige Antwort und beide Ansätze haben ihre Vor- und Nachteile sowie Risiken. Für Google Search Console-Daten ist mein bester Rat, einen Platzhalterwert wie 0 zu setzen, um die Wirkung einiger Metriken zu unterschätzen.
df.fillna(0, inplace = True)
Bevor wir zur eigentlichen Datenanalyse übergehen, müssen wir unsere Funktionen anpassen, nämlich die Spalten unseres Datensatzes. Die Position ist besonders interessant, da wir sie für einige coole Pivot-Tabellen verwenden möchten.
Wir können die Position auf eine ganze Zahl runden, was unserem Zweck dient.
df['Position'] = df['Position'].round(0).astype('int64')
Sie sollten alle anderen oben beschriebenen Reinigungsschritte ausführen und dann die Datumsspalte anpassen.
Wir extrahieren Monate und Jahre mit Hilfe von Pandas. Sie müssen nicht so genau sein, wenn Sie mit einem kürzeren Zeitrahmen arbeiten, dies ist ein Beispiel, das ein halbes Jahr berücksichtigt.
#Datum in das richtige Format konvertieren df['date'] = pd.to_datetime(df['date']) #Monate extrahieren df['Monat'] = df['Datum'].dt.Monat #Jahre extrahieren df['Jahr'] = df['Datum'].dt.Jahr
[Ebook] Data SEO: Das nächste große Abenteuer
 Lesen Sie das E-Book
Lesen Sie das E-BookExplorative Datenanalyse
Der Hauptvorteil von Python ist, dass Sie die gleichen Dinge tun können wie in Excel, aber mit viel mehr Optionen und einfacher. Beginnen wir mit etwas, das jeder Analyst wirklich gut kennt: Pivot-Tabellen.
Analyse der durchschnittlichen CTR pro Positionsgruppe
Analysieren von Durchschn. Die CTR pro Positionsgruppe ist eine der aufschlussreichsten Aktivitäten, da sie es Ihnen ermöglicht, die allgemeine Situation einer Website zu verstehen. Wenden Sie den Pivot an und lassen Sie ihn uns dann plotten.
pd.options.display.float_format = '{:.2%}'.format
query_analysis = df.pivot_table(index=['position'], values=['ctr'], aggfunc=['mean'])
query_analysis.sort_values(by=['position'], ascending=True).head(10)
ax = query_analysis.head(10).plot(kind='bar')
ax.set_xlabel('Durchschn. Position')
ax.set_ylabel('CTR')
ax.set_title('CTR nach durchschnittlicher Position')
ax.grid('on')
ax.get_legend().remove()
plt.xticks(rotation=0)
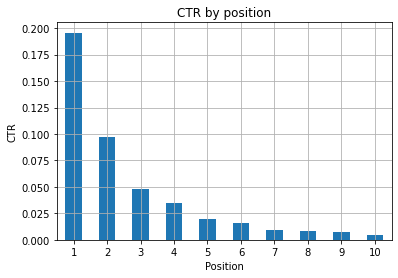
Abbildung 1: Darstellung der CTR nach Position, um Anomalien zu erkennen.
Das ideale Szenario hier ist eine bessere CTR auf der linken Seite des Diagramms, da die Ergebnisse in Position 1 normalerweise eine viel höhere CTR aufweisen sollten. Seien Sie jedoch vorsichtig, Sie können einige Fälle sehen, in denen die ersten 3 Spots eine niedrigere CTR als erwartet haben, und Sie müssen dies untersuchen.
Bitte berücksichtigen Sie auch Grenzfälle, zum Beispiel solche, bei denen Position 11 besser ist als Erster zu sein. Wie in der Google-Dokumentation für die Search Console erläutert, folgt diese Metrik nicht der Reihenfolge, die Sie vielleicht zunächst annehmen.
Darüber hinaus fügt es hinzu, dass diese Metrik ein Durchschnitt ist, da sich die Position des Links jedes Mal ändert und es unmöglich ist, eine 100%ige Genauigkeit zu haben.
Manchmal haben Ihre Seiten einen hohen Rang, sind aber nicht überzeugend genug, sodass Sie versuchen könnten, den Titel zu korrigieren. Da dies eine Übersicht auf hoher Ebene ist, werden Sie keine granularen Unterschiede sehen. Erwarten Sie also, schnell zu handeln, wenn dieses Problem in großem Umfang auftritt.
Achten Sie auch darauf, wenn eine Gruppe von Seiten an niedrigeren Positionen eine höhere durchschnittliche Klickrate aufweist als Seiten an besseren Positionen.
Aus diesem Grund sollten Sie Ihre Analyse möglicherweise bis Position 15 oder mehr ausdehnen, um seltsame Muster zu erkennen.
Anzahl der Abfragen pro Position und Messung der SEO-Bemühungen
Eine Zunahme der Suchanfragen, für die Sie ranken, ist immer ein gutes Signal, bedeutet jedoch nicht unbedingt bessere Platzierungen in der Zukunft. Die Anzahl der Abfragen ist der Prozess des Zählens der Anzahl der Abfragen, für die Sie ein Ranking erstellen, und ist eine der wichtigsten Aufgaben, die Sie mit GSC-Daten ausführen können.
Pivot-Tabellen sind wieder eine große Hilfe, und wir können die Ergebnisse grafisch darstellen.
ranking_queries = df.pivot_table(index=['position'], values=['query'], aggfunc=['count']) ranking_queries.sort_values(by=['position']).head(10)
Was Sie als SEO-Spezialist wollen, ist eine höhere Abfrageanzahl auf der linken Seite, den oberen Plätzen. Der Grund ist ganz natürlich, dass hohe Positionen im Durchschnitt eine bessere Klickrate erzielen, was dazu führen kann, dass mehr Leute auf Ihre Seite klicken.
ax = ranking_queries.head(10).plot(kind='bar')
ax.set_ylabel('Anzahl der Abfragen')
ax.set_xlabel('Position')
ax.set_title('Rangverteilung')
ax.grid('on')
ax.get_legend().remove()
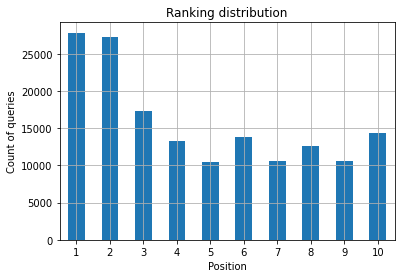
Abbildung 2: Wie viele Abfragen habe ich nach Position?
Was Ihnen wichtig ist, ist die Erhöhung der Abfrageanzahl in den oberen Positionen im Laufe der Zeit.
Mit der Datumsdimension spielen
Sehen wir uns an, wie sich die Klicks in einem bestimmten Zeitintervall ändern, lassen Sie uns zuerst die Summe der Klicks ermitteln:
clicks_sum = df.groupby('date')['clicks'].sum()
Wir gruppieren Daten nach der Datumsdimension und erhalten die Summe der Klicks für jede von ihnen, es ist eine Art Zusammenfassung.
Wir sind jetzt bereit zu zeichnen, was wir bekommen haben, der Code wird ziemlich lang sein, nur um die Visualisierung zu verbessern, haben Sie keine Angst davor.

# Summe der Klicks im Zeitraum
%config InlineBackend.figure_format = 'retina'
aus matplotlib.pyplot Importfigur
figure(figsize=(8, 6), dpi=80)
ax = clicks_sum.plot(color='red')
ax.grid('on')
ax.set_ylabel('Summe der Klicks')
ax.set_xlabel('Monat')
ax.set_title('Änderung der Klicks auf monatlicher Basis')
xlab = ax.xaxis.get_label()
ylab = ax.yaxis.get_label()
xlab.set_style('kursiv')
xlab.set_size(10)
ylab.set_style('kursiv')
ylab.set_size(10)
ttl = ax.titel
ttl.set_weight('fett')
ax.spines['right'].set_color((.8,.8,.8))
ax.spines['oben'].set_color((.8,.8,.8))
ax.yaxis.set_label_coords(-.15, .50)
ax.fill_between(clicks_sum.index, clicks_sum.values, facecolor='yellow')
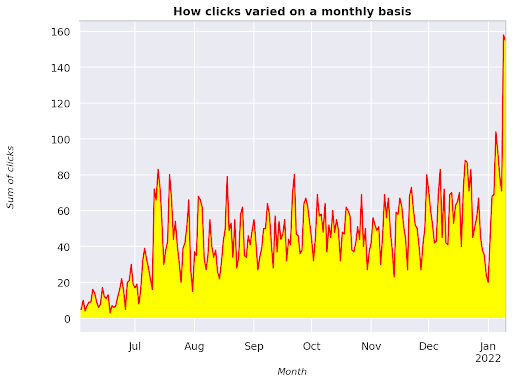
Abbildung 3: Darstellung der Summe der Klicks im Verhältnis zur Monatsvariable
Dies ist ein Beispiel ab Juni 2021 bis Mitte Januar 2022. Alle Linien, die Sie oben sehen, haben die Aufgabe, diese Visualisierung schöner zu machen. Sie können versuchen, damit zu spielen, um zu sehen, was passiert.
Anzahl der Abfragen pro Position, monatlicher Snapshot
Eine weitere coole Visualisierung, die wir in Python zeichnen können, ist die Heatmap, die noch visueller ist als ein einfaches Balkendiagramm. Ich werde Ihnen zeigen, wie Sie die Anzahl der Abfragen im Zeitverlauf und entsprechend ihrer Position anzeigen.
seegeboren als sns importieren sns.set_theme() df_neu = df.loc[(df['Position'] <= 10) & (df['Jahr'] != 2022),:] # Laden Sie den Beispielflugdatensatz und konvertieren Sie ihn in Langform df_heat = df_new.pivot_table(index = "position", column = "month", values = "query", aggfunc='count') # Zeichnen Sie eine Heatmap mit den numerischen Werten in jeder Zelle f, ax = plt.subplots(figsize=(20, 12)) x_axis_labels = ["September", "Oktober", "November", "Dezember"] sns.heatmap(df_heat, annot=True, linewidths=.5, ax=ax, fmt='g', cmap = sns.cm.rocket_r, xticklabels=x_axis_labels) ax.set(xlabel = 'Monat', ylabel='Position', title = 'Wie sich die Abfrageanzahl pro Position mit der Zeit ändert') #rotate Positionsbeschriftungen, um sie besser lesbar zu machen plt.yticks(rotation=0)
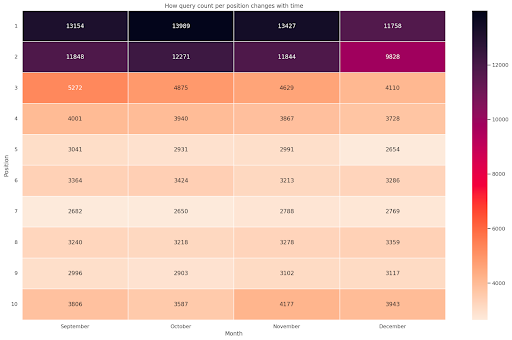
Abbildung 4: Heatmap, die den Fortschritt der Abfrageanzahl nach Position und Monat zeigt.
Dies ist einer meiner Favoriten, Heatmaps können sehr effektiv sein, um Pivot-Tabellen anzuzeigen, wie in diesem Beispiel. Der Zeitraum erstreckt sich über 4 Monate und wenn Sie ihn horizontal lesen, können Sie sehen, wie sich die Anzahl der Abfragen im Laufe der Zeit ändert. Für Position 10 haben Sie von September bis Dezember einen kleinen Anstieg, aber für Position 2 haben Sie einen auffälligen Rückgang, wie durch die violette Farbe angezeigt wird.
Im folgenden Szenario befinden sich die meisten Suchanfragen an den oberen Plätzen, was auffallend ungewöhnlich sein kann. In diesem Fall möchten Sie vielleicht zurückgehen und den Datenrahmen analysieren und nach möglichen Markenbegriffen suchen, falls vorhanden.
Wie Sie dem Code entnehmen können, ist es nicht so schwer, komplexe Plots zu erstellen, solange Sie die Logik dahinter verstehen.
Die Anzahl der Abfragen sollte mit der Zeit steigen, wenn Sie die „richtigen“ Dinge tun, und wir können den Unterschied über zwei verschiedene Zeiträume hinweg darstellen. In dem von mir bereitgestellten Beispiel ist dies eindeutig nicht der Fall, da Sie insbesondere für Top-Positionen eine höhere CTR haben sollten.
Einführung in einige grundlegende NLP-Konzepte
Natural Language Processing (NLP) ist ein Glücksfall für SEO und Sie müssen kein Experte sein, um die grundlegenden Algorithmen anzuwenden. N-Gramme sind eine der leistungsstärksten, aber einfachsten Ideen, die Ihnen Einblicke in GSC-Daten verschaffen können.
N-Gramme sind zusammenhängende Folgen von Buchstaben, Silben oder Wörtern. Für unsere Analyse sind Wörter die Maßeinheit. Ein N-Gramm wird Bigramm genannt, wenn die benachbarten Elemente zwei (ein Paar) sind, und Trigramm, wenn sie drei sind, und so weiter. Ich empfehle Ihnen, mit verschiedenen Kombinationen zu testen und höchstens auf 5 Gramm zu gehen.
Auf diese Weise können Sie die häufigsten Sätze auf den Seiten Ihrer Mitbewerber ausfindig machen oder Ihre eigenen einschätzen. Da sich Google möglicherweise auf eine satzbasierte Indexierung stützt, ist es besser, auf Sätze als auf einzelne Schlüsselwörter zu optimieren, wie Google-Patente zu diesem Thema zeigen.
Wie auf der obigen Seite von Bill Slawski selbst erwähnt, ist der Wert des Verständnisses verwandter Begriffe für die Optimierung und für Ihre Benutzer von großem Wert.
Die nltk-Bibliothek ist sehr bekannt für NLP-Anwendungen und gibt uns die Möglichkeit, Stoppwörter in einer bestimmten Sprache wie Englisch zu entfernen. Betrachten Sie sie als Rauschen, das Sie entfernen möchten, tatsächlich tragen Artikel und sehr häufige Wörter nicht zum Verständnis eines Textes bei.
nltk importieren
nltk.download('Stoppwörter')
aus nltk.corpus import stopwords
stoplist = stopwords.words('english')
aus sklearn.feature_extraction.text import CountVectorizer
c_vec = CountVectorizer(stop_words=stoplist, ngram_range=(2,3))
# Matrix von ngrams
ngrams = c_vec.fit_transform(df['query'])
# Zählfrequenz von ngrams
count_values = ngrams.toarray().sum(axis=0)
# Liste von ngrams
vocab = c_vec.vokabular_
df_ngram = pd.DataFrame(sorted([(count_values[i],k) for k,i in vocab.items()], reverse=True)
).rename(columns={0: 'frequency', 1:'bigram/trigram'})
df_ngram.head(20).style.background_gradient()
Wir nehmen die Abfragespalte und zählen die Häufigkeit von Bigrammen, um einen Datenrahmen zu erstellen, der Bigramme und ihre Häufigkeit speichert.
Dieser Schritt ist eigentlich sehr wichtig, um auch die Websites der Mitbewerber zu analysieren. Sie können einfach ihren Text kratzen und überprüfen, was die häufigsten N-Gramme sind, indem Sie das n jedes Mal anpassen, um zu sehen, ob Sie auf hochrangigen Seiten unterschiedliche Muster erkennen.
Wenn man kurz darüber nachdenkt, macht es viel mehr Sinn, da ein einzelnes Keyword nichts über den Kontext aussagt.
Tiefhängende Früchte
Eines der schönsten Dinge, die Sie tun können, ist das Überprüfen von niedrig hängenden Früchten, den Seiten, die Sie leicht verbessern können, um so früh wie möglich gute Ergebnisse zu sehen. Dies ist in den ersten Schritten eines jeden SEO-Projekts entscheidend, um Ihre Stakeholder zu überzeugen. Wenn es also die Möglichkeit gibt, solche Seiten zu nutzen, tun Sie es einfach!
Unsere Kriterien, um eine Seite als solche zu betrachten, sind Quantile für Impressions und CTR. Mit anderen Worten, wir filtern Zeilen, die zu den oberen 80 % der Impressionen gehören, aber zu den 20 % gehören, die die niedrigste CTR erzielen. Diese Zeilen haben eine schlechtere Klickrate als 80 % der übrigen Zeilen.
top_impressions = df[df['impressions'] >= df['impressions'].quantile(0.8)]
(top_impressions[top_impressions['ctr'] <= top_impressions['ctr'].quantile(0.2)].sort_values('impressions', ascending = False))
Jetzt haben Sie eine Liste mit allen Opportunities, sortiert nach Impressions, in absteigender Reihenfolge.
Sie können sich andere Kriterien ausdenken, um zu definieren, was eine niedrig hängende Frucht ist, je nach den Anforderungen Ihrer Website und ihrer Größe.
Bei kleineren Websites können Sie nach höheren Prozentsätzen suchen, während Sie bei großen Websites bereits viele Informationen mit den von mir verwendeten Kriterien erhalten sollten.
[Ebook] Technisches SEO für Nicht-Techniker
 Lesen Sie das E-Book
Lesen Sie das E-BookEinführung in querycat: Klassifikation und Assoziationen
Querycat ist eine einfache, aber leistungsstarke Bibliothek, die Assoziationsregel-Mining für das Clustering von Schlüsselwörtern und vieles mehr bietet. Ich werde Ihnen nur die Assoziationen zeigen, da sie bei dieser Art von Analyse wertvoller sind.
Sie können mehr über diese großartige Bibliothek erfahren, indem Sie sich das querycat GitHub-Repository ansehen.
Kurze Einführung zum Lernen von Assoziationsregeln
Das Lernen von Assoziationsregeln ist eine Methode, um Regeln zu finden, die Assoziationen und Kookkurrenzen zwischen Sätzen von Elementen definieren. Dies unterscheidet sich geringfügig von einem anderen unüberwachten maschinellen Lernverfahren, dem sogenannten Clustering.
Das Endziel ist jedoch das gleiche, Keyword-Cluster zu erhalten, um zu verstehen, wie unsere Website für einige Themen abschneidet.
Querycat bietet Ihnen die Möglichkeit, zwischen zwei Algorithmen zu wählen: Apriori und FP-Growth. Wir werden letzteres für bessere Leistungen wählen, sodass Sie ersteres ignorieren können.
FP-Growth ist eine verbesserte Version von Apriori, um häufige Muster in Datensätzen zu finden. Das Lernen von Assoziationsregeln ist auch für E-Commerce-Transaktionen sehr nützlich, Sie könnten beispielsweise daran interessiert sein, zu verstehen, was Menschen zusammen kaufen.
In diesem Fall konzentrieren wir uns ausschließlich auf Abfragen, aber die andere Anwendung, die ich erwähnt habe, kann eine weitere nützliche Idee für Google Analytics-Daten sein.
Diese Algorithmen aus Sicht der Datenstruktur zu erklären, ist ziemlich herausfordernd und meiner Meinung nach für Ihre SEO-Aufgaben nicht notwendig. Ich werde nur einige grundlegende Konzepte erklären, um zu verstehen, was die Parameter bedeuten.
Die 3 Hauptelemente der 2 Algorithmen sind:
- Unterstützung – Es drückt die Beliebtheit eines Artikels oder eines Artikelsets aus. In technischen Worten ist dies die Anzahl der Transaktionen, bei denen Abfrage X und Abfrage Y zusammen angezeigt werden, dividiert durch die Gesamtzahl der Transaktionen.
Darüber hinaus kann es als Schwellenwert verwendet werden, um seltene Elemente zu entfernen. Sehr nützlich, um die statistische Signifikanz und Leistung zu erhöhen. Das Festlegen einer guten Mindestunterstützung ist sehr gut. - Vertrauen – Sie können es sich als die Wahrscheinlichkeit des gemeinsamen Auftretens von Begriffen vorstellen.
- Lift – Das Verhältnis zwischen der Unterstützung für (Term 1 und Term 2) und der Unterstützung von Term 1. Wir können uns den Wert ansehen, um Einblicke in die Beziehung zwischen den Termen zu erhalten. Wenn größer als 1, sind die Terme korreliert; wenn kleiner als 1, ist es unwahrscheinlich, dass die Terme eine Assoziation haben: wenn Lift genau 1 (oder nahe) ist, gibt es keine signifikante Beziehung.
Weitere Details finden Sie in diesem Artikel über querycat, der vom Autor der Bibliothek geschrieben wurde.
Jetzt können wir zum praktischen Teil übergehen.
Abfragekat importieren
query_cat = querycat.Categorize(df, 'query', min_support=10, alg='fpgrowth')
dfgrouped = df.groupby('category').agg(sumclicks = ('clicks', 'sum')).sort_values('sumclicks', ascending=False)
#Gruppe erstellen, um Kategorien mit weniger als 15 Klicks zu filtern (beliebige Zahl)
filtergroup = dfgrouped[dfgrouped['sumclicks'] > 15]
Filtergruppe
#Filter anwenden
df = df.merge(filtergroup, on=['category','category'], how='inner')
Wir haben dabei weniger häufige Kategorien gefiltert, ich habe in meinem Fall 15 als Benchmark gewählt. Es ist nur eine willkürliche Zahl, es gibt kein Kriterium dahinter.
Lassen Sie uns unsere Kategorien mit dem folgenden Ausschnitt überprüfen:
df['Kategorie'].value_counts()
Was ist mit den 10 meistgeklickten Kategorien? Lassen Sie uns überprüfen, wie viele Abfragen wir für jeden von ihnen haben.
df.groupby('category').sum()['clicks'].sort_values(ascending=False).head(10)
Die zu wählende Anzahl ist willkürlich, stellen Sie sicher, dass Sie eine auswählen, die einen guten Prozentsatz der Gruppen herausfiltert. Eine mögliche Idee besteht darin, den Median der Impressionen zu erhalten und die niedrigsten 50 % zu streichen, vorausgesetzt, Sie möchten kleine Gruppen ausschließen.
Cluster erhalten und was mit der Ausgabe zu tun ist
Meine Empfehlung ist, Ihren neuen Datenrahmen zu exportieren, um zu vermeiden, dass FP-Growth erneut ausgeführt wird. Bitte tun Sie dies, um wertvolle Zeit zu sparen.
Sobald Sie Cluster haben, möchten Sie die Klicks und Impressionen für jeden von ihnen kennen, um zu beurteilen, in welchen Bereichen die meisten Verbesserungen erforderlich sind.
grouped_df = df.groupby('category')[['clicks', 'impressions']].agg('sum')
Mit einigen Datenmanipulationen können wir unsere Zuordnungsergebnisse verbessern und haben Klicks und Impressionen für jeden Cluster.
group_ex = df.groupby(['category'])['query'].apply(' | '.join).reset_index()
#Entfernen Sie doppelte Abfragen und sortieren Sie sie dann alphabetisch
group_ex['query'] = group_ex['query'].apply(lambda x: ' | '.join(sorted(list(set(x.split('|'))))))
df_final = group_ex.merge(grouped_df, on=['category', 'category'], how='inner')
df_final.head()
Sie haben jetzt eine CSV-Datei mit all Ihren Keyword-Clustern zusammen mit Klicks und Impressionen.
# CSV-Datei speichern und auf Ihren lokalen Rechner herunterladen. Wenn Sie Safari verwenden, sollten Sie zum Herunterladen dieser Dateien zu Chrome wechseln, da dies möglicherweise nicht funktioniert.
df_final.to_csv('clusters_queries.csv')
files.download('clusters_queries.csv')
Tatsächlich gibt es bessere Methoden für das Clustering, dies ist nur ein Beispiel dafür, wie Sie querycat verwenden können, um mehrere Aufgaben für eine sofortige Verwendung auszuführen. Das Hauptziel hier ist es, so viele Einblicke wie möglich zu erhalten, insbesondere für neue Websites, auf denen Sie nicht so viel Wissen haben.
Im Moment beinhalten die besten Ansätze Semantik. Wenn Sie sich also auf Clustering konzentrieren möchten, schlage ich vor, dass Sie das Lernen von Graphen oder Einbettungen in Betracht ziehen.
Dies sind jedoch fortgeschrittene Themen, wenn Sie ein Anfänger sind, und Sie können einfach einige vorgefertigte Streamlit-Apps ausprobieren, die online verfügbar sind.
Oncrawl-Daten³
 Mehr erfahren
Mehr erfahrenFazit und wie es weiter geht
Python kann eine große Hilfe bei der Analyse Ihrer Website bieten und Ihnen dabei helfen, Datenbereinigung, Visualisierung und Analyse an einem einzigen Ort zu kombinieren. Das Extrahieren von Daten aus der GSC-API wird definitiv für fortgeschrittenere Aufgaben benötigt und ist eine „sanfte“ Einführung in die Datenautomatisierung.
Während Sie mit Python viele fortgeschrittenere Berechnungen durchführen können, ist meine Empfehlung, zu prüfen, was in Bezug auf den SEO-Wert sinnvoll ist.
Zum Beispiel ist der Query Count auf lange Sicht insgesamt viel wichtiger, da Sie möchten, dass Ihre Website für mehr Anfragen berücksichtigt wird.
Die Verwendung von Notizbüchern ist eine große Hilfe beim Packen von Code mit Kommentaren, und das ist der Hauptgrund, warum ich vorschlage, dass Sie sich an Google Colab gewöhnen.
Dies ist nur der Anfang dessen, was die Datenanalyse Ihnen bieten kann, da die besten Ideen aus der Zusammenführung verschiedener Datensätze entstehen.
Die Google Search Console ist per se ein leistungsstarkes Tool und völlig kostenlos. Die Menge an praktischen Informationen, die Sie daraus erhalten können, ist in guten Händen nahezu unbegrenzt.