
Statistische Signifikanz von A/B-Tests: Wie und wann ein Test beendet wird
Veröffentlicht: 2020-05-22
In unserer jüngsten Analyse von 28.304 Experimenten, die von Convert-Kunden durchgeführt wurden, haben wir festgestellt, dass nur 20 % der Experimente das statistische Signifikanzniveau von 95 % erreichen. Econsultancy entdeckte in seinem Optimierungsbericht 2018 einen ähnlichen Trend. Zwei Drittel der Befragten sehen in nur 30 % oder weniger ihrer Experimente einen „eindeutigen und statistisch signifikanten Gewinner“.
Daher sind die meisten Experimente (70-80 %) entweder nicht schlüssig oder wurden vorzeitig abgebrochen.
Von diesen machen diejenigen, die früh gestoppt wurden, einen merkwürdigen Fall, da Optimierer den Aufruf annehmen, Experimente zu beenden, wenn sie es für angebracht halten. Sie tun dies, wenn sie entweder einen klaren Gewinner (oder Verlierer) oder einen eindeutig unbedeutenden Test „sehen“ können. Normalerweise haben sie auch einige Daten, um dies zu rechtfertigen.
Dies mag nicht so überraschend erscheinen, wenn man bedenkt, dass 50 % der Optimierer keinen standardmäßigen „Haltepunkt“ für ihre Experimente haben. Für die meisten ist dies eine Notwendigkeit, dank des Drucks, eine bestimmte Testgeschwindigkeit (XXX Tests/Monat) und des Wettlaufs, ihre Konkurrenz zu dominieren, aufrechterhalten zu müssen.
Dann besteht auch die Möglichkeit, dass ein negatives Experiment den Umsatz beeinträchtigt. Unsere eigene Forschung hat gezeigt, dass nicht gewinnbringende Experimente im Durchschnitt zu einem Rückgang der Conversion-Rate um 26 % führen können !
Alles in allem ist es immer noch riskant, Experimente vorzeitig zu beenden …
… weil es die Wahrscheinlichkeit belässt, dass das Ergebnis anders hätte ausfallen können, wenn das Experiment seine beabsichtigte Länge, angetrieben durch die richtige Stichprobengröße, durchlaufen hätte.
Wie also wissen Teams, die Experimente frühzeitig beenden, wann es Zeit ist, sie zu beenden? Für die meisten liegt die Antwort darin, Stoppregeln zu entwickeln, die die Entscheidungsfindung beschleunigen, ohne die Qualität zu beeinträchtigen.
Abkehr von traditionellen Stoppregeln
Für Webexperimente gilt ein p-Wert von 0,05 als Standard. Diese 5-prozentige Fehlertoleranz oder das statistische Signifikanzniveau von 95 % hilft Optimierern, die Integrität ihrer Tests aufrechtzuerhalten. Sie können sicherstellen, dass die Ergebnisse tatsächliche Ergebnisse und keine Zufallstreffer sind.
In herkömmlichen statistischen Modellen für Tests mit festem Horizont – bei denen die Testdaten nur einmal zu einem festgelegten Zeitpunkt oder bei einer bestimmten Anzahl engagierter Benutzer ausgewertet werden – akzeptieren Sie ein Ergebnis als signifikant, wenn Sie einen p-Wert von weniger als 0,05 haben. An dieser Stelle können Sie die Nullhypothese verwerfen, dass Ihre Kontrolle und Behandlung gleich sind und die beobachteten Ergebnisse nicht zufällig sind.
Im Gegensatz zu statistischen Modellen, die Ihnen die Möglichkeit geben, Ihre Daten während der Erfassung auszuwerten, verbieten Ihnen solche Testmodelle, sich die Daten Ihres Experiments anzusehen, während es läuft. Von dieser Praxis – auch bekannt als Peeking – wird in solchen Modellen abgeraten, da der p-Wert fast täglich schwankt. Sie werden sehen, dass ein Experiment an einem Tag signifikant ist und am nächsten Tag sein p-Wert bis zu einem Punkt ansteigt, an dem er nicht mehr signifikant ist.
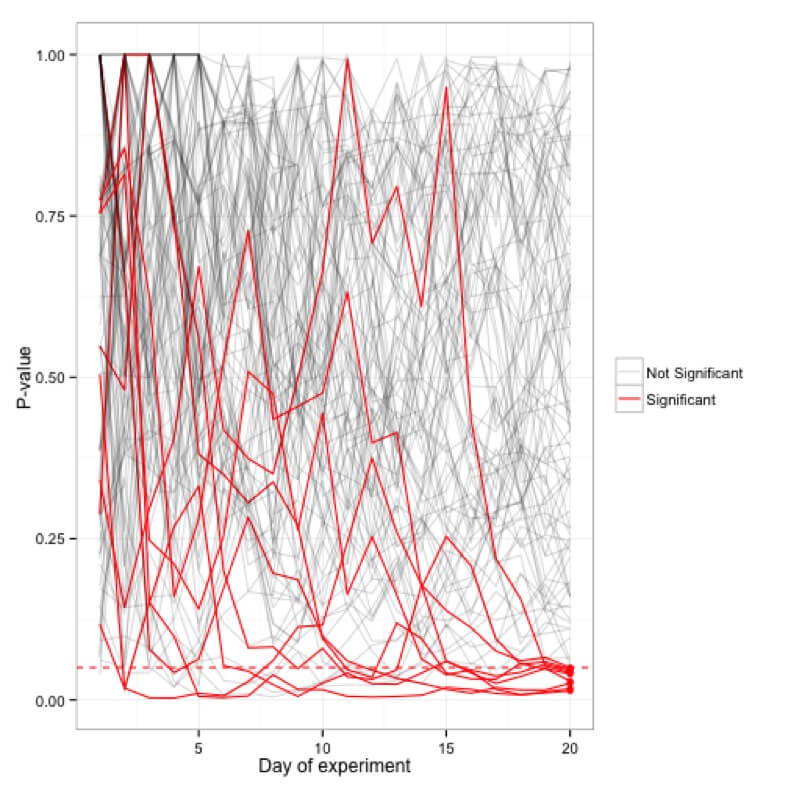
Simulationen der p-Werte, aufgetragen für hundert (20 Tage) Experimente; nur 5 Experimente sind nach 20 Tagen tatsächlich signifikant, während viele in der Zwischenzeit gelegentlich den Grenzwert von <0,05 erreichten.
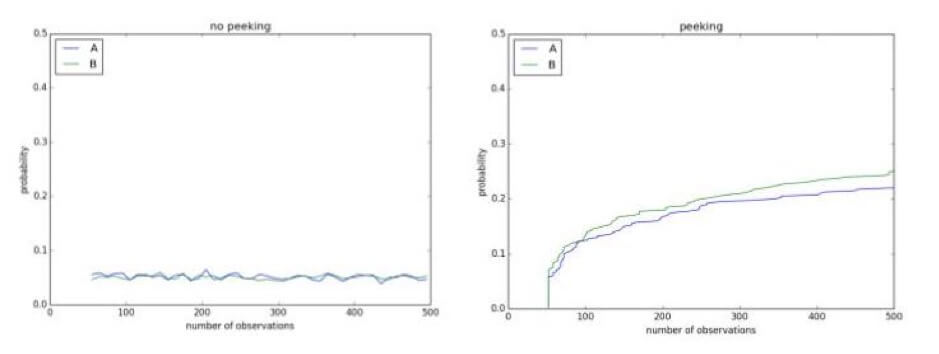
Ein kurzer Blick auf Ihre Experimente in der Zwischenzeit kann Ergebnisse zeigen, die nicht existieren. Unten haben Sie zum Beispiel einen A/A-Test mit einem Signifikanzniveau von 0,1. Da es sich um einen A/A-Test handelt, gibt es keinen Unterschied zwischen der Kontrolle und der Behandlung. Nach 500 Beobachtungen während des laufenden Experiments besteht jedoch eine Wahrscheinlichkeit von über 50 %, zu dem Schluss zu kommen, dass sie unterschiedlich sind und dass die Nullhypothese verworfen werden kann:
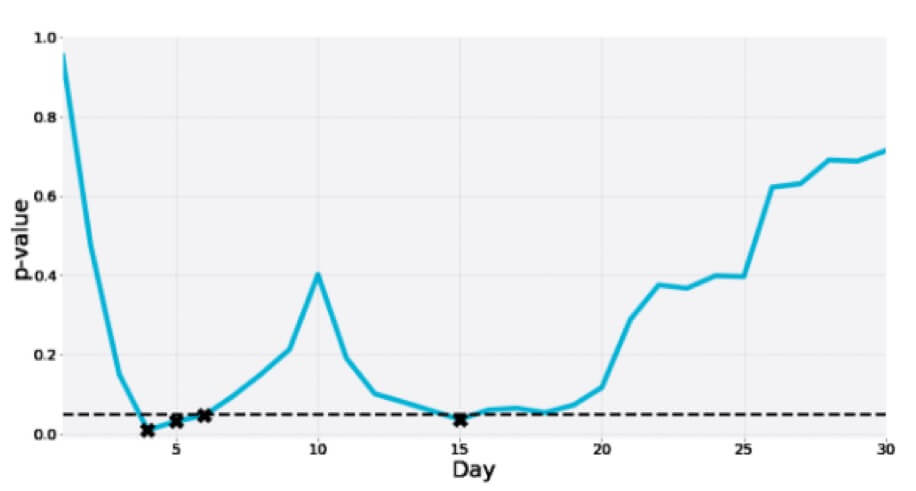
Hier ist ein weiterer eines 30-tägigen A/A-Tests, bei dem der p-Wert in der Zwischenzeit mehrmals in den Signifikanzbereich eintaucht, nur um schließlich weit über dem Grenzwert zu liegen:
Die korrekte Angabe eines p-Werts aus einem Experiment mit festem Horizont bedeutet, dass Sie sich im Voraus auf eine feste Stichprobengröße oder Testdauer festlegen müssen. Einige Teams fügen diesem Teststoppkriterium auch eine bestimmte Anzahl von Conversions und eine beabsichtigte Dauer hinzu.
Das Problem hierbei ist jedoch, dass es für die meisten Websites schwierig ist, genügend Test-Traffic zu haben, um jedes einzelne Experiment zum optimalen Stoppen mit dieser Standardpraxis zu betreiben.
Hier hilft die Verwendung sequenzieller Testmethoden, die optionale Stoppregeln unterstützen.
Hin zu flexiblen Stoppregeln, die schnellere Entscheidungen ermöglichen
Mit sequenziellen Testmethoden können Sie auf die Daten Ihrer Experimente zugreifen, sobald sie angezeigt werden, und Ihre eigenen statistischen Signifikanzmodelle verwenden, um Gewinner mit flexiblen Stoppregeln früher zu erkennen.
Optimierungsteams auf den höchsten Ebenen der CRO-Reife entwickeln oft ihre eigenen statistischen Methoden, um solche Tests zu unterstützen. Einige A/B-Testing-Tools haben dies ebenfalls eingebaut und könnten darauf hindeuten, ob eine Version zu gewinnen scheint. Und einige geben Ihnen die volle Kontrolle darüber, wie Ihre statistische Signifikanz berechnet werden soll, mit Ihren benutzerdefinierten Werten und mehr. So können Sie auch in einem laufenden Experiment einen Gewinner sehen und erkennen.

Georgi Georgiev, Statistiker, Autor und Dozent des beliebten CXL-Kurses zu A/B-Teststatistiken, setzt sich für solche sequenziellen Testmethoden ein, die eine Flexibilität bei der Anzahl und dem Zeitpunkt von Zwischenanalysen ermöglichen:
„ Durch sequentielles Testen können Sie Ihre Gewinne maximieren, indem Sie frühzeitig eine erfolgreiche Variante einsetzen, und Tests beenden, bei denen die Wahrscheinlichkeit eines Gewinners so früh wie möglich gering ist. Letzteres minimiert Verluste aufgrund minderwertiger Varianten und beschleunigt das Testen, wenn es einfach unwahrscheinlich ist, dass die Varianten die Kontrolle übertreffen. Statistische Strenge wird in allen Fällen gewahrt. ”
Georgiev hat sogar an einem Taschenrechner gearbeitet, der den Teams dabei hilft, die Testmodelle mit festen Stichproben gegen ein Modell auszutauschen, das einen Gewinner erkennen kann, während ein Experiment noch läuft. Sein Modell berücksichtigt viele Statistiken und hilft Ihnen, Tests etwa 20-80 % schneller als standardmäßige statistische Signifikanzberechnungen zu nennen, ohne die Qualität zu beeinträchtigen.
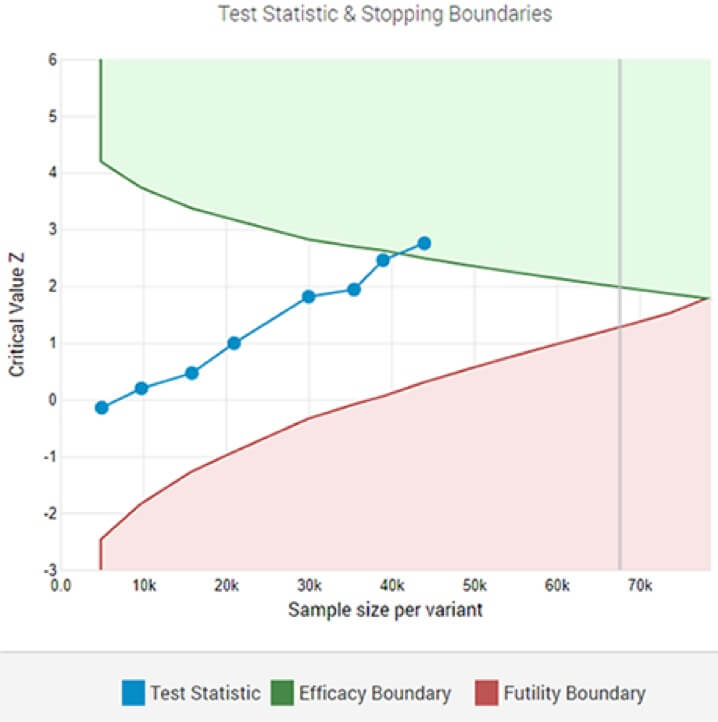
Ein adaptiver A/B-Test, der nach der 8. Zwischenanalyse einen statistisch signifikanten Gewinner an der festgelegten Signifikanzschwelle zeigt.
Während solche Tests Ihren Entscheidungsprozess beschleunigen können, gibt es einen wichtigen Aspekt, der berücksichtigt werden muss: die tatsächlichen Auswirkungen des Experiments . Ein Experiment in der Zwischenzeit zu beenden, kann dazu führen, dass Sie es überschätzen.
Der Blick auf nicht angepasste Schätzungen für die Effektgröße kann gefährlich sein, warnt Georgiev. Um dies zu vermeiden, verwendet sein Modell Methoden zur Anwendung von Anpassungen, die die durch die Zwischenüberwachung entstandene Verzerrung berücksichtigen. Er erklärt, wie ihre agile Analyse die Schätzungen „abhängig von der Stoppphase und dem beobachteten Wert der Statistik (Überschreitung, falls vorhanden)“ anpasst. Unten sehen Sie die Analyse für den obigen Test: (Beachten Sie, dass die geschätzte Steigerung niedriger ist als die beobachtete und das Intervall nicht darum herum zentriert ist.)
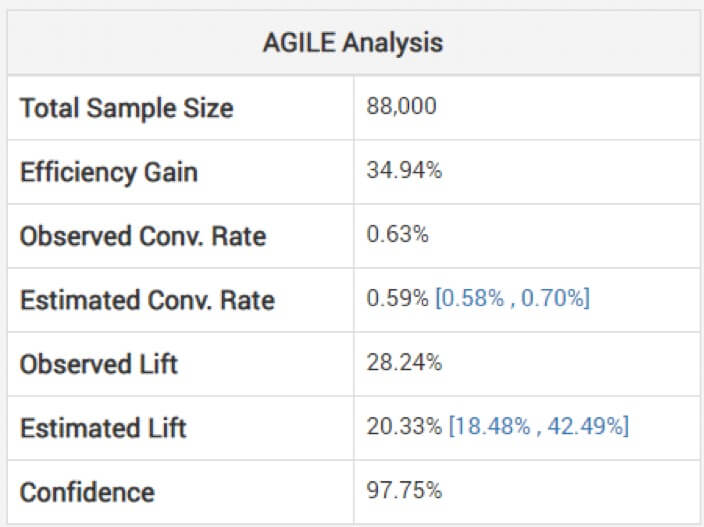
Ein Gewinn ist also möglicherweise nicht so groß, wie es aufgrund Ihres kürzer als beabsichtigten Experiments scheint.
Auch der Verlust muss einkalkuliert werden, da Sie vielleicht doch irrtümlicherweise zu früh einen Gewinner genannt haben. Dieses Risiko besteht jedoch auch bei Tests mit festem Horizont. Die externe Validität kann jedoch ein größeres Problem darstellen, wenn Experimente frühzeitig aufgerufen werden, verglichen mit einem länger laufenden Test mit festem Horizont. Dies ist jedoch, wie Georgiev erklärt, „ eine einfache Folge der kleineren Stichprobengröße und damit der Testdauer. „
Am Ende… Es geht nicht um Gewinner oder Verlierer…
… sondern um bessere Geschäftsentscheidungen, wie Chris Stucchio sagt.
Oder wie Tom Redman (Autor von Data Driven: Profiting from Your Most Important Business Asset) im Geschäftsleben sagt: „ Es gibt oft wichtigere Kriterien als statistische Signifikanz. Die wichtige Frage lautet: „ Hält sich das Ergebnis am Markt, wenn auch nur für kurze Zeit? ”'
Und das wird es höchstwahrscheinlich, und das nicht nur für einen kurzen Zeitraum, bemerkt Georgiev, „ wenn es statistisch signifikant ist und Überlegungen zur externen Validität in der Designphase in zufriedenstellender Weise berücksichtigt wurden.“
Die ganze Essenz des Experimentierens besteht darin, Teams zu befähigen, fundiertere Entscheidungen zu treffen. Wenn Sie also die Ergebnisse – auf die die Daten Ihrer Experimente hinweisen – früher weitergeben können, warum dann nicht?
Es könnte sich um ein kleines UI-Experiment handeln, für das Sie praktisch nicht „genügend“ Stichprobengröße erreichen können. Es könnte auch ein Experiment sein, bei dem Ihr Herausforderer das Original vernichtet und Sie diese Wette einfach annehmen könnten!
Wie Jeff Bezos in seinem Brief an die Aktionäre von Amazon schreibt, zahlen sich große Experimente aus:
„ Bei einer zehnprozentigen Chance auf eine 100-fache Auszahlung sollten Sie diese Wette jedes Mal eingehen. Aber Sie werden immer noch in neun von zehn Fällen falsch liegen. Wir alle wissen, dass Sie viel schlagen werden, wenn Sie nach den Zäunen schwingen, aber Sie werden auch einige Homeruns treffen. Der Unterschied zwischen Baseball und Business besteht jedoch darin, dass Baseball eine abgeschnittene Ergebnisverteilung aufweist. Wenn Sie schwingen, können Sie, unabhängig davon, wie gut Sie mit dem Ball in Kontakt kommen, höchstens vier Läufe erzielen. Im Geschäftsleben können Sie hin und wieder 1.000 Runs erzielen, wenn Sie auf den Teller steigen. Diese lange Renditeverteilung ist der Grund, warum es wichtig ist, mutig zu sein. Große Gewinner zahlen für so viele Experimente. „
Das frühzeitige Aufrufen von Experimenten ist in hohem Maße so, als würde man sich jeden Tag die Ergebnisse ansehen und an einem Punkt aufhören, der eine gute Wette garantiert.

