
Deep Learning vs. Machine Learning – wie erkennt man den Unterschied?
Veröffentlicht: 2020-03-10Machine Learning, Deep Learning und Künstliche Intelligenz sind in den letzten Jahren zu Schlagworten geworden. Daher findet man sie überall in Marketingmaterialien und Anzeigen von immer mehr Unternehmen.
Aber was sind Machine Learning und Deep Learning? Außerdem, was sind die Unterschiede zwischen ihnen? In diesem Artikel werde ich versuchen, diese Fragen zu beantworten und Ihnen einige Fälle von Deep- und Machine-Learning-Anwendungen zeigen.
Was ist maschinelles Lernen?
Maschinelles Lernen ist ein Teilbereich der Informatik, der sich mit der Darstellung realer Ereignisse oder Objekte mit mathematischen Modellen auf der Grundlage von Daten befasst. Diese Modelle werden mit speziellen Algorithmen erstellt, die die allgemeine Struktur des Modells so anpassen, dass es zu den Trainingsdaten passt. Abhängig von der Art des zu lösenden Problems definieren wir überwachte und unüberwachte Machine Learning- und Machine Learning-Algorithmen.
Beaufsichtigtes vs. unbeaufsichtigtes maschinelles Lernen
Überwachtes maschinelles Lernen konzentriert sich auf die Erstellung von Modellen, die in der Lage wären, bereits vorhandenes Wissen über die vorliegenden Daten auf neue Daten zu übertragen. Die neuen Daten werden während der Trainingsphase vom Modellbildungsalgorithmus (Trainingsalgorithmus) nicht gesehen. Wir stellen einem Algorithmus die Daten der Merkmale zusammen mit den entsprechenden Werten zur Verfügung, die der Algorithmus daraus ableiten lernen soll (sogenannte Zielvariable).
Beim unüberwachten maschinellen Lernen stellen wir dem Algorithmus nur Features zur Verfügung. Dadurch kann es ihre Struktur und/oder Abhängigkeiten selbst herausfinden. Es ist keine eindeutige Zielvariable angegeben. Der Begriff des unüberwachten Lernens kann zunächst schwer zu verstehen sein, aber ein Blick auf die Beispiele in den vier Diagrammen unten sollte diese Idee verdeutlichen.
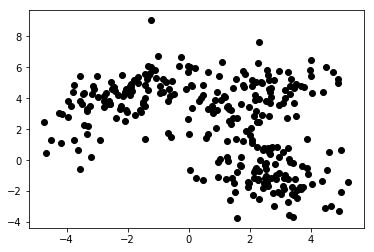
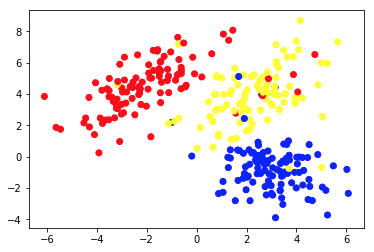
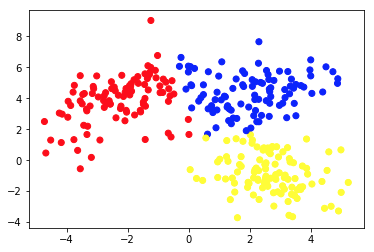

Diagramm 1a zeigt einige Daten, die mit 2 Merkmalen auf den Achsen x und y beschrieben werden. Der als 1b markierte zeigt die gleichen Daten farbig. Wir haben den K-Means- Clustering-Algorithmus verwendet, um diese Punkte in 3 Cluster zu gruppieren und sie entsprechend einzufärben. Dies ist ein Beispiel für einen Algorithmus für unbeaufsichtigtes maschinelles Lernen. Dem Algorithmus wurden nur die Merkmale gegeben, und die Labels (Clusternummern) sollten herausgefunden werden.
Das zweite Bild zeigt Diagramm 2a, das einen anderen Satz beschrifteter (und entsprechend gefärbter) Daten darstellt. Wir kennen die Gruppen, denen jeder der Datenpunkte a priori angehört. Wir verwenden einen SVM -Algorithmus, um 2 gerade Linien zu finden, die uns zeigen würden, wie Datenpunkte aufgeteilt werden müssen, um diese Gruppen am besten anzupassen. Diese Teilung ist nicht perfekt, aber dies ist das Beste, was mit geraden Linien erreicht werden kann. Wenn wir eine Gruppe einem neuen, unbeschrifteten Datenpunkt zuweisen wollen, müssen wir nur prüfen, wo sie auf der Ebene liegt. Dies ist ein Beispiel für eine überwachte Anwendung für maschinelles Lernen.
Anwendungen von Machine-Learning-Modellen
Für den Umgang mit Daten in tabellarischer Form werden Standardalgorithmen für maschinelles Lernen erstellt. Das bedeutet, dass wir, um sie zu verwenden, eine Art Tabelle benötigen. In solchen Tabellen können Zeilen als Instanzen des modellierten Objekts (z. B. ein Darlehen) betrachtet werden. Gleichzeitig sind die Spalten als Merkmale (Merkmale) dieses speziellen Falles zu sehen (zB monatliche Auszahlung des Darlehens, monatliches Einkommen des Kreditnehmers).

Neugierig auf die Entwicklung von Machine Learning?
Mehr erfahrenTabelle 1. ist ein sehr kurzes Beispiel für solche Daten. Das bedeutet natürlich nicht, dass die reinen Daten selbst tabellarisch und strukturiert sein müssen. Aber wenn wir einen Standard-Algorithmus für maschinelles Lernen auf einen Datensatz anwenden möchten, müssen wir ihn normalerweise bereinigen, mischen und in eine Tabelle umwandeln. Beim überwachten Lernen gibt es zusätzlich eine spezielle Spalte, die den Zielwert enthält (z. B. Information, ob der Kredit ausgefallen ist).
Der Trainingsalgorithmus versucht, die allgemeine Struktur des Modells in diese Daten einzupassen. Der genannte Algorithmus tut dies, indem er die Parameter des Modells optimiert. Das Ergebnis ist ein Modell, das den Zusammenhang zwischen den gegebenen Daten und der Zielgröße möglichst genau beschreibt.
Wichtig ist, dass das Modell nicht nur gut zu den gegebenen Trainingsdaten passt, sondern auch verallgemeinern kann. Verallgemeinerung bedeutet, dass wir das Modell verwenden können, um das Ziel für Instanzen abzuleiten, die während des Trainings nicht verwendet werden. Es ist auch ein entscheidendes Merkmal eines nützlichen Modells. Der Aufbau eines gut verallgemeinernden Modells ist keine leichte Aufgabe. Es erfordert oft ausgefeilte Validierungstechniken und gründliche Modelltests.
| Darlehens-ID | Kreditnehmer_Alter | Einkommen_monatlich | Darlehensbetrag | Monatliche Bezahlung | Ursprünglich |
| 1 | 34 | 10.000 | 100.000 | 1.200 | 0 |
| 2 | 43 | 5.700 | 25.000 | 800 | 0 |
| 3 | 25 | 2.500 | 24.000 | 400 | 0 |
| 4 | 67 | 4.600 | 40.000 | 2.000 | 1 |
| 5 | 38 | 35.000 | 2.500.000 | 10.000 | 0 |
Tabelle 1. Kreditdaten in tabellarischer Form
Menschen verwenden Algorithmen des maschinellen Lernens in einer Vielzahl von Anwendungen. Tabelle 2. zeigt einige geschäftliche Anwendungsfälle, die nicht tiefgreifende Machine-Learning-Algorithmen und Modellanwendungen ermöglichen. Es gibt auch kurze Beschreibungen der potenziellen Daten, Zielvariablen und ausgewählter anwendbarer Algorithmen.
| Anwendungsfall | Datenbeispiele | Zielwert (modellierter Wert). | Verwendeter Algorithmus/Modell |
| Empfehlungen von Artikeln auf einer Blog-Site | IDs von Artikeln, die von Benutzern gelesen wurden, Zeit, die für jeden von ihnen aufgewendet wurde | Präferenzen der Benutzer gegenüber Artikeln | Kollaboratives Filtern mit alternierenden kleinsten Quadraten |
| Bonitätsprüfung von Hypotheken | Transaktions- und Kredithistorie, Einkommensdaten eines potenziellen Kreditnehmers | Binärer Wert, der angibt, ob ein Kredit vollständig zurückgezahlt wird oder in Verzug gerät | LichtGBM |
| Vorhersage der Abwanderung von Premium-Nutzern eines Handyspiels | Tägliches Spielen, Zeit seit dem ersten Start, Fortschritt im Spiel | Binärwert, der anzeigt, ob ein Benutzer das Abonnement im nächsten Monat kündigen wird | XGBoost |
| Erkennung von Kreditkartenbetrug | Historische Kreditkartentransaktionsdaten – Betrag, Ort, Datum und Uhrzeit | Binärwert, der anzeigt, ob eine Kreditkartentransaktion betrügerisch ist | Zufälliger Wald |
| Segmentierung der Kunden eines Internetshops | Kaufhistorie von Mitgliedern des Treueprogramms | Jedem Kunden zugeordnete Segmentnummer | K-bedeutet |
| Vorausschauende Wartung eines Maschinenparks | Daten von Leistungs-, Temperatur-, Feuchtigkeits- usw. Sensoren | Eine der folgenden Klassen – „in Ordnung“, „zu beachten“, „erfordert Wartung“ | Entscheidungsbaum |
Tabelle 2. Beispiele für Anwendungsfälle des maschinellen Lernens
Deep Learning und Deep Neural Networks
Deep Learning ist Teil des maschinellen Lernens, bei dem wir Modelle eines bestimmten Typs verwenden, die als Deep Artificial Neural Networks (ANNs) bezeichnet werden. Seit ihrer Einführung haben künstliche neuronale Netze einen umfangreichen Evolutionsprozess durchlaufen. Das führte zu einer Reihe von Untertypen, von denen einige sehr kompliziert sind. Aber um sie vorzustellen, erklärt man am besten eine ihrer Grundformen – ein Multilayer-Perceptron (MPL).
Mehrschichtiges Perzeptron
Einfach ausgedrückt hat ein MLP die Form eines Graphen (Netzwerk) aus Scheitelpunkten (auch Neuronen genannt) und Kanten (dargestellt durch Zahlen, die Gewichte genannt werden). Die Neuronen sind in Schichten angeordnet, und die Neuronen in aufeinanderfolgenden Schichten sind miteinander verbunden. Daten fließen durch das Netzwerk von der Eingabe- zur Ausgabeschicht. Die Daten werden dann an den Neuronen und den Kanten zwischen ihnen transformiert. Sobald ein Datenpunkt das gesamte Netzwerk durchläuft, enthält die Ausgabeschicht die vorhergesagten Werte in ihren Neuronen.
Jedes Mal, wenn ein Teil der Trainingsdaten das Netzwerk durchläuft, vergleichen wir die Vorhersagen mit den entsprechenden wahren Werten. Dadurch können wir die Parameter (Gewichte) des Modells anpassen, um bessere Vorhersagen zu treffen. Wir können dies mit einem Algorithmus namens Backpropagation tun. Nach einer Reihe von Iterationen, wenn die Struktur des Modells speziell für die Bewältigung des vorliegenden Problems des maschinellen Lernens gut konzipiert ist.
Erhalt eines Modells mit hoher Genauigkeit
Sobald genügend Daten das Netzwerk mehrmals durchlaufen haben, erhalten wir ein hochgenaues Modell. In der Praxis gibt es viele Transformationen, die an Neuronen angewendet werden können. Das macht die ANNs sehr flexibel und leistungsfähig. Die Leistungsfähigkeit von ANNs hat jedoch ihren Preis. Je komplizierter die Struktur des Modells ist, desto mehr Daten und Zeit sind normalerweise erforderlich, um es mit hoher Genauigkeit zu trainieren.
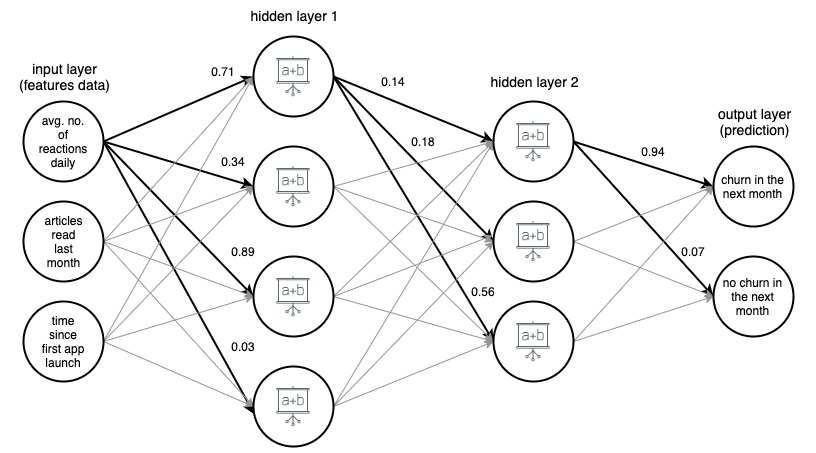
Bild 1. (draw.io) Struktur eines vierschichtigen künstlichen neuronalen Netzwerks, das basierend auf drei einfachen Merkmalen vorhersagt, ob ein Benutzer einer Nachrichten-App im nächsten Monat abwandern wird.
Der Übersichtlichkeit halber wurden Gewichtungen nur für ausgewählte (fettgedruckte) Kanten markiert, aber jede Kante hat ihre eigene Gewichtung. Daten fließen von der Eingabeschicht zur Ausgabeschicht und passieren dabei zwei verborgene Schichten in der Mitte. An jeder Kante wird ein Eingabewert mit der Gewichtung der Kante multipliziert, und das resultierende Produkt geht an den Knoten, an dem die Kante endet. Dann werden in jedem der Knoten in den verborgenen Schichten die eingehenden Signale von Kanten summiert und dann mit irgendeiner Funktion transformiert. Das Ergebnis dieser Transformationen wird dann als Eingabe für die nächste Schicht behandelt.
In der Ausgabeschicht werden die eingehenden Daten erneut aufsummiert und transformiert, was das Ergebnis in Form von zwei Zahlen ergibt – die Wahrscheinlichkeit, dass ein Nutzer die App im nächsten Monat verlässt, und die Wahrscheinlichkeit, dass dies nicht der Fall ist.
Fortgeschrittene Arten von neuronalen Netzen
In neuronalen Netzwerken fortgeschrittenerer Art haben die Schichten eine viel komplexere Struktur. Sie bestehen nicht nur aus einfachen dichten Schichten mit Ein-Operations-Neuronen, die von MLPs bekannt sind, sondern auch aus viel komplizierteren Schichten mit mehreren Operationen wie Faltungs- und Rekurrentenschichten.
Faltungs- und wiederkehrende Schichten
Faltungsschichten werden hauptsächlich in Computer-Vision- Anwendungen verwendet. Sie bestehen aus kleinen Zahlenfeldern, die über die Pixeldarstellung des Bildes gleiten. Pixelwerte werden mit diesen Zahlen multipliziert und dann aggregiert, was eine neue, komprimierte Darstellung des Bildes ergibt.
Wiederkehrende Schichten werden verwendet, um geordnete sequentielle Daten wie Zeitreihen oder Text zu modellieren . Sie wenden sehr komplizierte Transformationen mit mehreren Argumenten auf eingehende Daten an und versuchen, die Abhängigkeiten zwischen den Sequenzelementen herauszufinden. Unabhängig von der Art und Struktur des Netzwerks gibt es jedoch immer einige (eine oder mehrere) Eingabe- und Ausgabeschichten sowie fest definierte Pfade und Richtungen, in denen die Daten durch das Netzwerk fließen.
Im Allgemeinen sind Deep Neural Networks ANNs mit mehreren Schichten. Die Bilder 1, 2 und 3 unten zeigen Architekturen ausgewählter tiefer künstlicher neuronaler Netze. Sie wurden alle bei Google entwickelt und trainiert und der Öffentlichkeit zugänglich gemacht. Sie geben eine Vorstellung davon, wie komplex heute verwendete hochpräzise tiefe künstliche Netzwerke sind.
Diese Netzwerke haben enorme Größen. Zum Beispiel, teilweise gezeigt in Bild 3, hat InceptionResNetV2 572 Schichten und insgesamt mehr als 55 Millionen Parameter! Sie wurden alle als Bildklassifizierungsmodelle entwickelt (sie weisen einem bestimmten Bild eine Bezeichnung zu, zB „Auto“), und wurden mit Bildern aus dem ImageNet-Satz trainiert, der aus mehr als 14 Millionen gekennzeichneten Bildern besteht.

Bild 2. Struktur von NASNetMobile (Keras-Paket)

Bild 3. Struktur von XCeption (Keras-Paket)

Bild 4. Struktur eines Teils (ca. 25 %) von InceptionResNetV2 (Keras-Paket)
In den letzten Jahren haben wir eine große Entwicklung beim Deep Learning und seinen Anwendungen beobachtet. Viele der „intelligenten“ Funktionen unserer Smartphones und Anwendungen sind das Ergebnis dieses Fortschritts. Obwohl die Idee von ANNs nicht neu ist, ist dieser jüngste Boom das Ergebnis der Erfüllung einiger Bedingungen. Zunächst einmal haben wir das Potenzial des GPU-Computing entdeckt. Die Architektur der grafischen Verarbeitungseinheiten eignet sich hervorragend für parallele Berechnungen und ist sehr hilfreich für effizientes Deep Learning.
Darüber hinaus hat der Aufstieg von Cloud-Computing-Diensten den Zugang zu hocheffizienter Hardware viel einfacher, billiger und in viel größerem Umfang möglich gemacht. Schließlich ist die Rechenleistung der neuesten Mobilgeräte groß genug, um Deep-Learning-Modelle anzuwenden, wodurch ein riesiger Markt potenzieller Nutzer von DNN-gesteuerten Funktionen entsteht.
Anwendungen von Deep-Learning-Modellen
Deep-Learning-Modelle werden normalerweise auf Probleme angewendet, die sich mit Daten befassen, die keine einfache Zeilen-Spalten-Struktur haben, wie Bildklassifizierung oder Sprachübersetzung, da sie hervorragend mit unstrukturierten und komplex strukturierten Daten arbeiten können, die diese Aufgaben behandeln – Bilder, Text , und Ton. Es gibt Probleme beim Umgang mit Daten dieser Art und Größe mit klassischen Algorithmen für maschinelles Lernen, und die Erstellung und Anwendung einiger tiefer neuronaler Netze auf diese Probleme hat zu enormen Entwicklungen in den Bereichen Bilderkennung, Spracherkennung, Textklassifizierung und Sprachübersetzung geführt letzten paar Jahren.
Die Anwendung von Deep Learning auf diese Probleme war aufgrund der Tatsache möglich, dass DNNs mehrdimensionale Zahlentabellen, sogenannte Tensoren, sowohl als Eingabe als auch als Ausgabe akzeptieren und die räumlichen und zeitlichen Beziehungen zwischen ihren Elementen verfolgen können. Beispielsweise können wir ein Bild als dreidimensionalen Tensor darstellen, wobei die Dimension eins und zwei die Auflösung des digitalen Bildes darstellen (also die Größe der Bildbreite bzw. -höhe) und die dritte Dimension die RGB-Farbe darstellt Kodierung jedes Pixels (also hat die dritte Dimension die Größe 3).
Dadurch können wir nicht nur alle Informationen über das Bild in einem Tensor darstellen, sondern auch die räumlichen Beziehungen zwischen Pixeln beibehalten, was sich bei der Anwendung sogenannter Faltungsschichten als entscheidend für erfolgreiche Bildklassifizierungs- und Erkennungsnetzwerke herausstellt.
Die Flexibilität des neuronalen Netzwerks in den Eingabe- und Ausgabestrukturen hilft auch bei anderen Aufgaben, wie der Sprachübersetzung . Beim Umgang mit Textdaten füttern wir die tiefen neuronalen Netze mit Zahlendarstellungen der Wörter, geordnet nach ihrem Erscheinen im Text. Jedes Wort wird durch einen Vektor aus einhundert oder einigen hundert Zahlen dargestellt, die (normalerweise unter Verwendung eines anderen neuronalen Netzwerks) so berechnet werden, dass die Beziehungen zwischen Vektoren, die verschiedenen Wörtern entsprechen, die Beziehungen der Wörter selbst nachahmen. Diese als Einbettungen bezeichneten Vektorsprachdarstellungen können nach dem Training in vielen Architekturen wiederverwendet werden und sind ein zentraler Baustein von Sprachmodellen für neuronale Netze.
Beispiele für die Verwendung von Deep-Learning-Modellen
Tabelle 3. enthält Beispiele für die Anwendung von Deep-Learning-Modellen auf reale Probleme. Wie Sie sehen können, sind Probleme, die von Deep-Learning-Algorithmen angegangen und gelöst werden, viel komplexer als Aufgaben, die durch Standardtechniken des maschinellen Lernens gelöst werden, wie sie in Tabelle 1 dargestellt sind.
Dennoch ist es wichtig, sich daran zu erinnern, dass viele der Anwendungsfälle, die maschinelles Lernen heute in Unternehmen unterstützen kann, keine so ausgefeilten Methoden erfordern und durch Standardmodelle effizienter (und mit höherer Genauigkeit) gelöst werden können. Tabelle 3. gibt auch eine Vorstellung davon, wie viele verschiedene Arten von künstlichen neuronalen Netzwerkschichten es gibt und wie viele verschiedene nützliche Architekturen damit konstruiert werden können.
| Anwendungsfall | Daten | Ziel/Ergebnis des Modells | Verwendeter Algorithmus/Modell |
| Bildklassifizierung | Bilder | Einem Bild zugewiesene Bezeichnung | Convolutional Neural Network (CNN) |
| Bilderkennung durch selbstfahrende Autos | Bilder | Beschriftungen und Begrenzungsrahmen um auf Bildern identifizierte Objekte | Schnelles R-CNN |
| Gefühl Analyse von Kommentare in einem Online-Shop | Text von Online-Kommentaren | Stimmungsbezeichnung (z. B. positiv, neutral, negativ), die jedem Kommentar zugeordnet ist | Bidirektionales Long-Short Term Memory (LSTM)-Netzwerk |
| Harmonisierung einer Melodie | MIDI-Datei mit einer Melodie | MIDI-Datei mit dieser Melodie harmonisiert | Generatives gegnerisches Netzwerk |
| Vorhersage des nächsten Wortes in einem (n online Editor | Sehr großer Textblock (z. B. Dump aller Wikipedia-Artikel in Englisch) | Ein Wort, das als nächstes zum bisher geschriebenen Text passt | Recurrent Neural Network (RNN) mit einer Embedding-Schicht |
| Textübersetzung in eine andere Sprache | Text auf Polnisch | Derselbe Text ins Englische übersetzt | Encoder – Decoder-Netzwerk, das mit rekurrenten neuronalen Netzwerkschichten (RNN) aufgebaut ist |
| Übertragung von Monets Stil auf jedes Bild | Eine Reihe von Bildern von Monets Gemälden und eine Reihe anderer Bilder | Bilder so modifiziert, dass sie wie von Monet gemalt aussehen | Generatives gegnerisches Netzwerk |
Tabelle 3. Beispiele für Anwendungsfälle von Deep Learning
Vorteile von Deep-Learning-Modellen
Generative gegnerische Netzwerke
Eine der beeindruckendsten Anwendungen von Deep Neural Networks kam mit dem Aufstieg von Generative Adversarial Networks (GANs). Sie wurden 2014 von Ian Goodfellow eingeführt, und seine Idee wurde seitdem in viele Tools integriert, einige mit erstaunlichen Ergebnissen.
GANs sind verantwortlich für die Existenz von Anwendungen, die uns auf Fotos älter aussehen lassen, Bilder so umwandeln, dass sie aussehen, als wären sie von van Gogh gemalt worden, oder sogar Melodien für mehrere Instrumentengruppen harmonisieren. Während des Trainings eines GAN konkurrieren zwei neuronale Netze. Ein Generatornetzwerk generiert aus zufälligen Eingaben eine Ausgabe, während der Diskriminator versucht, generierte Instanzen von echten zu unterscheiden. Während des Trainings lernt der Generator, wie er den Diskriminator erfolgreich „täuschen“ kann, und ist schließlich in der Lage, eine Ausgabe zu erzeugen, die aussieht, als wäre sie echt.
Leistungsstarke tiefe neuronale Netze in mobilen Apps
Es ist wichtig zu beachten, dass, obwohl das Trainieren eines tiefen neuronalen Netzwerks eine sehr rechenintensive Aufgabe ist und viel Zeit in Anspruch nehmen kann, die Anwendung eines trainierten Netzwerks zur Erledigung einer bestimmten Aufgabe dies nicht sein muss, insbesondere wenn es auf eine oder eine angewendet wird wenige Fälle auf einmal. Tatsächlich sind wir heute in der Lage, leistungsstarke tiefe neuronale Netze in mobilen Anwendungen auf unseren Smartphones auszuführen.
Es gibt sogar einige Netzwerkarchitekturen, die speziell dafür ausgelegt sind, bei der Anwendung auf Mobilgeräten effizient zu sein (z. B. NASNetMobile, dargestellt in Bild 1). Obwohl sie im Vergleich zu den hochmodernen Netzwerken viel kleiner sind, können sie dennoch eine hochpräzise Vorhersageleistung erzielen.
Lernen übertragen
Ein weiteres sehr leistungsfähiges Merkmal künstlicher neuronaler Netze, das eine breite Nutzung der Deep-Learning-Modelle ermöglicht, ist Transfer Learning . Sobald wir ein Modell mit einigen Daten trainiert haben (entweder von uns selbst erstellt oder aus einem öffentlichen Repository heruntergeladen), können wir ganz oder teilweise darauf aufbauen, um ein Modell zu erhalten, das unseren speziellen Anwendungsfall löst. Zum Beispiel könnten wir ein vortrainiertes NASNetLarge-Modell verwenden, das auf dem riesigen ImageNet-Datensatz trainiert wurde, das einem Bild ein Label zuweist, einige kleine Änderungen an der Spitze seiner Struktur vornehmen, es mit einem neuen Satz von beschrifteten Bildern weiter trainieren und Verwenden Sie es, um eine bestimmte Art von Objekten zu kennzeichnen (z. B. eine Baumart, die auf dem Bild seines Blattes basiert).
Vorteile des Transferlernens
Transfer Learning ist sehr nützlich, da normalerweise das Trainieren eines tiefen neuronalen Netzwerks, das einige praktische, nützliche Aufgaben ausführt, riesige Datenmengen und eine enorme Rechenleistung erfordert. Dies kann oft Millionen gekennzeichneter Dateninstanzen und Hunderte von Grafikprozessoren (GPUs) bedeuten, die wochenlang laufen.
Nicht jeder kann sich solche Assets leisten oder hat Zugriff darauf, was es sehr schwierig machen kann, eine hochpräzise benutzerdefinierte Lösung von Grund auf neu zu erstellen, beispielsweise für die Bildklassifizierung. Glücklicherweise sind einige vortrainierte Modelle (insbesondere Netzwerke zur Bildklassifizierung und vortrainierte Einbettungsmatrizen für Sprachmodelle) Open-Source und in einer leicht anwendbaren Form kostenlos verfügbar (z. B. als Modellinstanz in Keras, einem neuronalen Netzwerk-API).
So wählen und erstellen Sie das richtige Machine Learning-Modell für Ihre Anwendung
Wenn Sie maschinelles Lernen anwenden möchten, um ein Geschäftsproblem zu lösen, müssen Sie sich wahrscheinlich nicht sofort für die Art des Modells entscheiden. Normalerweise gibt es einige Ansätze, die getestet werden könnten. Es ist oft verlockend, zunächst mit den kompliziertesten Modellen zu beginnen, aber es lohnt sich, einfach anzufangen und die Komplexität der angewandten Modelle schrittweise zu erhöhen. Einfachere Modelle sind in der Regel günstiger in Bezug auf Einrichtung, Rechenzeit und Ressourcen. Darüber hinaus sind ihre Ergebnisse ein großartiger Maßstab, um fortgeschrittenere Ansätze zu bewerten.
Solche Benchmarks können Datenwissenschaftlern dabei helfen, zu beurteilen, ob die Richtung, in die sie ihre Modelle entwickeln, die richtige ist. Ein weiterer Vorteil ist die Möglichkeit, einige der zuvor gebauten Modelle wiederzuverwenden und mit neueren zu fusionieren, wodurch ein sogenanntes Ensemble-Modell entsteht. Das Mischen von Modellen unterschiedlicher Typen ergibt oft höhere Leistungsmetriken als jedes der kombinierten Modelle allein hätte. Prüfen Sie auch, ob es einige vortrainierte Modelle gibt, die verwendet und per Transfer Learning an Ihren Business Case angepasst werden könnten.
Weitere praktische Tipps
Stellen Sie in erster Linie sicher, dass die Daten ordnungsgemäß verarbeitet werden, unabhängig davon, welches Modell Sie verwenden. Beachten Sie die Regel „Garbage in, Garbage out“. Wenn die dem Modell bereitgestellten Trainingsdaten von geringer Qualität sind oder nicht ordnungsgemäß gekennzeichnet und bereinigt wurden, ist es sehr wahrscheinlich, dass das resultierende Modell ebenfalls eine schlechte Leistung erbringt. Stellen Sie außerdem sicher, dass das Modell – unabhängig von seiner Komplexität – während der Modellierungsphase umfassend validiert und am Ende getestet wurde, ob es sich gut auf unbekannte Daten verallgemeinern lässt.
Stellen Sie ganz praktisch sicher, dass die erstellte Lösung in der Produktion auf der verfügbaren Infrastruktur implementiert werden kann. Und wenn Ihr Unternehmen mehr Daten sammeln kann, die in Zukunft zur Verbesserung Ihres Modells verwendet werden könnten, sollte eine Umschulungspipeline vorbereitet werden, um eine einfache Aktualisierung zu gewährleisten. Eine solche Pipeline kann sogar eingerichtet werden, um das Modell mit einer vordefinierten Zeitfrequenz automatisch neu zu trainieren.
Abschließende Gedanken
Vergessen Sie nicht, die Leistung und Benutzerfreundlichkeit des Modells nach seiner Bereitstellung in der Produktion zu verfolgen, da das Geschäftsumfeld sehr dynamisch ist. Einige Beziehungen innerhalb Ihrer Daten können sich im Laufe der Zeit ändern, und es können neue Phänomene auftreten. Sie können daher die Effizienz Ihres Modells verändern und sollten entsprechend behandelt werden. Außerdem können neue, leistungsstarke Modelltypen erfunden werden. Einerseits können sie Ihre Lösung relativ schwach machen, andererseits bieten sie Ihnen die Möglichkeit, Ihr Geschäft weiter zu verbessern und die Vorteile der neuesten Technologie zu nutzen.
Darüber hinaus können Ihnen Machine- und Deep-Learning-Modelle dabei helfen, leistungsstarke Tools für Ihr Unternehmen und Ihre Anwendungen zu entwickeln und Ihren Kunden ein außergewöhnliches Erlebnis zu bieten . Das Erstellen dieser „intelligenten“ Funktionen erfordert zwar erhebliche Anstrengungen, aber die potenziellen Vorteile sind es wert. Stellen Sie einfach sicher, dass Sie und Ihr Data Science-Team geeignete Modelle ausprobieren und bewährte Verfahren befolgen, und Sie sind auf dem richtigen Weg, um Ihr Unternehmen und Ihre Anwendungen mit innovativen Lösungen für maschinelles Lernen zu stärken.
Quellen:
- https://en.wikipedia.org/wiki/Unsupervised_learning
- https://keras.io/
- https://developer.nvidia.com/deep-learning
- https://keras.io/applications/
- https://arxiv.org/abs/1707.07012
- http://yifanhu.net/PUB/cf.pdf
- https://towardsdatascience.com/detecting-financial-fraud-using-machine-learning-three-ways-of-winn-the-war-against-imbalanced-a03f8815cce9
- https://scikit-learn.org/stable/modules/tree.html
- https://aws.amazon.com/deepcomposer/
- https://blog.keras.io/a-ten-minute-introduction-to-sequence-to-sequence-learning-in-keras.html
- https://keras.io/examples/nlp/bidirectional_lstm_imdb/
- https://towardsdatascience.com/how-do-self-driving-cars-see-13054aee2503
- https://towardsdatascience.com/r-cnn-fast-r-cnn-faster-r-cnn-yolo-object-detection-algorithms-36d53571365e
- https://towardsdatascience.com/building-a-next-word-predictor-in-tensorflow-e7e681d4f03f
- https://keras.io/applications/
- https://arxiv.org/pdf/1707.07012.pdf