
Was ist eine CTR-Kurve und wie berechnet man sie mit Python?
Veröffentlicht: 2022-03-22Die CTR-Kurve, oder mit anderen Worten die organische Klickrate basierend auf der Position, sind Daten, die Ihnen zeigen, wie viele blaue Links auf einer Suchmaschinen-Ergebnisseite (SERP) basierend auf ihrer Position CTR erzielen. Zum Beispiel erhält der erste blaue Link in SERP meistens die meiste CTR.
Am Ende dieses Tutorials können Sie die CTR-Kurve Ihrer Website basierend auf ihren Verzeichnissen berechnen oder die organische CTR basierend auf CTR-Abfragen berechnen. Die Ausgabe meines Python-Codes ist ein aufschlussreiches Box- und Balkendiagramm, das die CTR-Kurve der Website beschreibt.
Wenn Sie ein Anfänger sind und die CTR-Definition nicht kennen, werde ich sie im nächsten Abschnitt näher erläutern.
Was ist die organische CTR oder organische Klickrate?
Die CTR ergibt sich aus der Aufteilung organischer Klicks in Impressionen. Wenn beispielsweise 100 Personen nach „Apfel“ suchen und 30 Personen auf das erste Ergebnis klicken, beträgt die CTR des ersten Ergebnisses 30 / 100 * 100 = 30 %.
Das bedeutet, dass Sie von 100 Suchanfragen 30 % erhalten. Es ist wichtig, sich daran zu erinnern, dass die Impressionen in der Google Search Console (GSC) nicht auf dem Erscheinen Ihres Website-Links im Viewport des Suchers basieren. Wenn das Ergebnis auf der Suchmaschine SERP erscheint, erhalten Sie für jede Suche eine Impression.
Wozu dient die CTR-Kurve?
Eines der wichtigsten Themen im SEO sind Vorhersagen zum organischen Traffic. Um die Platzierungen in einigen Schlüsselwörtern zu verbessern, müssen wir Tausende und Abertausende von Dollar zuweisen, um mehr Anteile zu erhalten. Aber die Frage auf Marketingebene eines Unternehmens lautet oft: „Ist es für uns kosteneffizient, dieses Budget bereitzustellen?“.
Neben dem Thema Budgetzuweisungen für SEO-Projekte müssen wir auch eine Schätzung unserer zukünftigen organischen Traffic-Zunahme oder -Abnahme erhalten. Wenn wir zum Beispiel sehen, dass einer unserer Konkurrenten hart versucht, uns in unserer SERP-Rangposition zu ersetzen, wie viel wird uns das kosten?
In dieser Situation oder vielen anderen Szenarien benötigen wir die CTR-Kurve unserer Website.
Warum verwenden wir keine CTR-Kurvenstudien und verwenden unsere Daten?
Einfach gesagt, es gibt keine andere Website, die Ihre Website-Eigenschaften in SERP hat.
Es gibt viele Untersuchungen zu CTR-Kurven in verschiedenen Branchen und verschiedenen SERP-Funktionen, aber wenn Sie Ihre Daten haben, warum berechnen Ihre Websites dann nicht die CTR, anstatt sich auf Quellen von Drittanbietern zu verlassen?
Fangen wir damit an.
Berechnung der CTR-Kurve mit Python: Erste Schritte
Bevor wir in den Berechnungsprozess der Klickrate von Google basierend auf der Position eintauchen, müssen Sie die grundlegende Python-Syntax kennen und ein grundlegendes Verständnis gängiger Python-Bibliotheken wie Pandas haben. Dies wird Ihnen helfen, den Code besser zu verstehen und ihn auf Ihre Weise anzupassen.
Außerdem verwende ich für diesen Vorgang lieber ein Jupyter-Notebook .
Zur Berechnung der organischen CTR basierend auf der Position müssen wir diese Python-Bibliotheken verwenden:
- Pandas
- Plotzlich
- Kaleido
Außerdem verwenden wir diese Python-Standardbibliotheken:
- os
- json
Wie gesagt, werden wir zwei verschiedene Möglichkeiten zur Berechnung der CTR-Kurve untersuchen. Einige Schritte sind bei beiden Methoden gleich: Importieren der Python-Pakete, Erstellen eines Ausgabeordners für Plotbilder und Festlegen der Ausgabeplotgrößen.
# Importieren benötigter Bibliotheken für unseren Prozess Betriebssystem importieren json importieren pandas als pd importieren import plotly.express als px plotly.io als pio importieren Kaleido importieren
Hier erstellen wir einen Ausgabeordner zum Speichern unserer Plotbilder.
# Ausgabeordner für Plotbilder erstellen
wenn nicht os.path.exists('./output plot images'):
os.mkdir('./Ausgabe von Plotbildern')
Sie können die Höhe und Breite der Ausgabeplotbilder unten ändern.
# Einstellen von Breite und Höhe der ausgegebenen Plotbilder pio.kaleido.scope.default_height = 800 pio.kaleido.scope.default_width = 2000
Beginnen wir mit der ersten Methode, die auf der Abfrage-CTR basiert.
Erste Methode: Berechnen Sie die CTR-Kurve für eine gesamte Website oder eine bestimmte URL-Eigenschaft basierend auf der Abfrage-CTR
Zunächst müssen wir alle unsere Suchanfragen mit ihrer CTR, durchschnittlichen Position und Impression erhalten. Ich ziehe es vor, einen kompletten Monat mit Daten aus dem letzten Monat zu verwenden.
Dazu erhalte ich Abfragedaten aus der GSC-Datenquelle für Websiteimpressionen in Google Data Studio. Alternativ können Sie diese Daten auf beliebige Weise abrufen, z. B. über die GSC-API oder das Google Sheets-Add-on „Search Analytics for Sheets“. Wenn Ihre Blog- oder Produktseiten über eine dedizierte URL-Eigenschaft verfügen, können Sie diese auf diese Weise als Datenquelle in GDS verwenden.
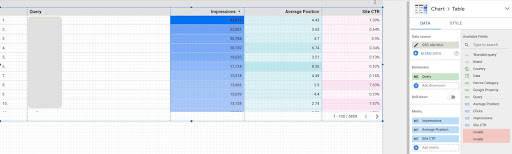
1. Abfragedaten von Google Data Studio (GDS) abrufen
Um dies zu tun:
- Erstellen Sie einen Bericht und fügen Sie ihm ein Tabellendiagramm hinzu
- Fügen Sie dem Bericht Ihre Website-Datenquelle "Website-Impression" hinzu
- Wählen Sie „Abfrage“ für die Dimension sowie „ctr“, „durchschnittliche Position“ und „Impression“ für die Metrik
- Filtern Sie Suchanfragen heraus, die den Markennamen enthalten, indem Sie einen Filter erstellen (Fragen, die Marken enthalten, haben eine höhere Klickrate, was die Genauigkeit unserer Daten verringert)
- Klicken Sie mit der rechten Maustaste auf die Tabelle und klicken Sie auf Exportieren
- Speichern Sie die Ausgabe als CSV
2. Laden unserer Daten und Kennzeichnungsabfragen basierend auf ihrer Position
Um die heruntergeladene CSV-Datei zu manipulieren, verwenden wir Pandas.
Die beste Vorgehensweise für die Ordnerstruktur unseres Projekts besteht darin, einen „Daten“-Ordner zu haben, in dem wir alle unsere Daten speichern.
Hier habe ich aus Gründen der Fließfähigkeit des Tutorials darauf verzichtet.
query_df = pd.read_csv('./downloaded_data.csv')
Dann kennzeichnen wir unsere Abfragen basierend auf ihrer Position. Ich habe eine 'for'-Schleife zum Beschriften der Positionen 1 bis 10 erstellt.
Wenn beispielsweise die durchschnittliche Position einer Suchanfrage 2,2 oder 2,9 beträgt, wird sie mit „2“ gekennzeichnet. Indem Sie den durchschnittlichen Positionsbereich manipulieren, können Sie die gewünschte Genauigkeit erreichen.
für i im Bereich (1, 11):
query_df.loc[(query_df['Durchschnittliche Position'] >= i) & (
query_df['Durchschnittliche Position'] < i + 1), 'Positionsbezeichnung'] = i
Jetzt gruppieren wir Abfragen basierend auf ihrer Position. Dies hilft uns, die Daten jeder Positionsabfrage in den nächsten Schritten besser zu manipulieren.
query_grouped_df = query_df.groupby(['Positionsbezeichnung'])
3. Filtern von Abfragen basierend auf ihren Daten für die Berechnung der CTR-Kurve
Der einfachste Weg, die CTR-Kurve zu berechnen, besteht darin, alle Abfragedaten zu verwenden und die Berechnung durchzuführen. Jedoch; Vergessen Sie nicht, an die Abfragen mit einer Impression an Position zwei in Ihren Daten zu denken.
Diese Abfragen machen meiner Erfahrung nach einen großen Unterschied im Endergebnis. Aber der beste Weg ist, es selbst zu versuchen. Aufgrund des Datensatzes kann sich dies ändern.
Bevor wir mit diesem Schritt beginnen, müssen wir eine Liste für unsere Balkendiagrammausgabe und einen DataFrame zum Speichern unserer manipulierten Abfragen erstellen.
# Erstellen eines DataFrame zum Speichern von 'query_df' manipulierten Daten Modified_df = pd. DataFrame () # Eine Liste zum Speichern jedes Positionsmittelwertes für unser Balkendiagramm mean_ctr_list = []
Dann durchlaufen wir query_grouped_df Gruppen und hängen die Top-20-%-Abfragen basierend auf den Impressionen an den modified_df -Datenrahmen an.
Wenn die Berechnung der CTR nur basierend auf den obersten 20 % der Suchanfragen mit den meisten Impressionen nicht das Beste für Sie ist, können Sie dies ändern.
Dazu können Sie ihn erhöhen oder verringern, indem Sie .quantile(q=your_optimal_number, interpolation='lower')] manipulieren, und your_optimal_number muss zwischen 0 und 1 liegen.
Wenn Sie beispielsweise die obersten 30 % Ihrer Suchanfragen erhalten möchten, ist your_optimal_num die Differenz zwischen 1 und 0,3 (0,7).
für i im Bereich (1, 11):
# Ein Versuch - außer für Situationen, in denen ein Verzeichnis für einige Positionen keine Daten enthält
Versuchen:
tmp_df = query_grouped_df.get_group(i)[query_grouped_df.get_group(i)['Impressionen'] >= query_grouped_df.get_group(i)['Impressionen']
.quantile(q=0.8, interpolation='lower')]
mean_ctr_list.append(tmp_df['ctr'].mean())
Modified_df = Modified_df.append(tmp_df,ignore_index=True)
außer KeyError:
mean_ctr_list.append(0)
# Löschen von 'tmp_df' DataFrame zur Reduzierung der Speichernutzung
del [tmp_df]
4. Zeichnen eines Boxplots
Auf diesen Schritt haben wir gewartet. Um Plots zu zeichnen, können wir Matplotlib, Seaborn als Wrapper für Matplotlib oder Plotly verwenden.
Ich persönlich denke, dass die Verwendung von Plotly eine der besten Lösungen für Vermarkter ist, die es lieben, Daten zu erforschen.
Im Vergleich zu Mathplotlib ist Plotly so einfach zu bedienen und mit nur wenigen Codezeilen können Sie eine schöne Handlung zeichnen.
# 1. Der Boxplot
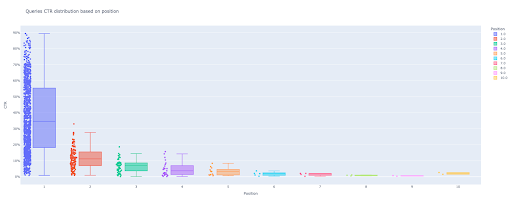
box_fig = px.box(modified_df, x='Positionslabel', y='Site CTR', title='Fragen die CTR-Verteilung basierend auf der Position',
points='all', color='position label', labels={'position label': 'Position', 'Site CTR': 'CTR'})
# Alle zehn X-Achsen-Ticks anzeigen
box_fig.update_xaxes(tickvals=[i für i im Bereich (1, 11)])
# Änderung des Tick-Formats der Y-Achse in Prozent
box_fig.update_yaxes(tickformat=".0%")
# Plot im Verzeichnis 'Output Plot Images' speichern
box_fig.write_image('./output plot images/Queries box plot CTR curve.png')
Mit nur diesen vier Zeilen können Sie ein schönes Boxplot erstellen und mit der Erkundung Ihrer Daten beginnen.
Wenn Sie mit dieser Spalte interagieren möchten, führen Sie in einer neuen Zelle Folgendes aus:
box_fig.show()
Jetzt haben Sie einen attraktiven Boxplot in der Ausgabe, der interaktiv ist.
Wenn Sie den Mauszeiger über ein interaktives Diagramm in der Ausgabezelle bewegen, ist die wichtige Zahl, an der Sie interessiert sind, der „Mann“ jeder Position.
Dies zeigt die durchschnittliche CTR für jede Position. Wie Sie sich erinnern, erstellen wir aufgrund der mittleren Wichtigkeit eine Liste, die den Mittelwert jeder Position enthält. Als Nächstes fahren wir mit dem nächsten Schritt fort, um ein Balkendiagramm basierend auf dem Mittelwert jeder Position zu zeichnen.
5. Zeichnen eines Balkendiagramms
Wie bei einem Boxplot ist das Zeichnen des Balkenplots so einfach. Sie können den title von Diagrammen ändern, indem Sie das title von px.bar() .
# 2. Das Balkendiagramm
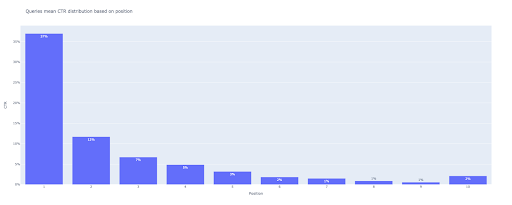
bar_fig = px.bar(x=[pos for pos in range(1, 11)], y=mean_ctr_list, title='Queries bedeuten CTR-Verteilung basierend auf Position',
label={'x': 'Position', 'y': 'CTR'}, text_auto=True)
# Alle zehn X-Achsen-Ticks anzeigen
bar_fig.update_xaxes(tickvals=[i für i im Bereich (1, 11)])
# Änderung des Tick-Formats der Y-Achse in Prozent
bar_fig.update_yaxes(tickformat='.0%')
# Plot im Verzeichnis 'Output Plot Images' speichern
bar_fig.write_image('./output plot images/Queries bar plot CTR curve.png')
Als Ausgabe erhalten wir diesen Plot:
Wie beim Boxplot können Sie mit diesem Plot interagieren, indem bar_fig.show() .
Das ist es! Mit ein paar Zeilen Code erhalten wir die organische Klickrate basierend auf der Position mit unseren Abfragedaten.
Wenn Sie für jede Ihrer Subdomains oder Verzeichnisse eine URL-Eigenschaft haben, können Sie diese URL-Eigenschaften abfragen und die CTR-Kurve dafür berechnen.
[Fallstudie] Verbesserung von Rankings, organischen Besuchen und Verkäufen durch Analyse von Protokolldateien
 Lesen Sie die Fallstudie
Lesen Sie die FallstudieZweite Methode: Berechnung der CTR-Kurve basierend auf Landing-Pages-URLs für jedes Verzeichnis
Bei der ersten Methode haben wir unsere organische CTR basierend auf der CTR der Suchanfragen berechnet, aber mit diesem Ansatz erhalten wir alle Daten unserer Zielseiten und berechnen dann die CTR-Kurve für unsere ausgewählten Verzeichnisse.

Ich liebe diesen Weg. Wie Sie wissen, ist die CTR für unsere Produktseiten ganz anders als die unserer Blogbeiträge oder anderer Seiten. Jedes Verzeichnis hat seine eigene CTR basierend auf der Position.
Auf fortgeschrittenere Weise können Sie jede Verzeichnisseite kategorisieren und die organische Klickrate von Google basierend auf der Position für eine Reihe von Seiten abrufen.
1. Abrufen von Zielseitendaten
Genau wie bei der ersten Methode gibt es mehrere Möglichkeiten, Daten der Google Search Console (GSC) zu erhalten. Bei dieser Methode habe ich es vorgezogen, die Zielseitendaten vom GSC-API-Explorer unter https://developers.google.com/webmaster-tools/v1/searchanalytics/query abzurufen.
Für das, was bei diesem Ansatz benötigt wird, liefert GDS keine soliden Zielseitendaten. Sie können auch das Add-on „Search Analytics for Sheets“ für Google Sheets verwenden.
Beachten Sie, dass der Google API Explorer gut für Websites mit weniger als 25.000 Datenseiten geeignet ist. Bei größeren Websites können Sie Landing-Pages-Daten teilweise abrufen und miteinander verketten, ein Python-Skript mit einer „for“-Schleife schreiben, um alle Ihre Daten aus GSC abzurufen, oder Tools von Drittanbietern verwenden.
So erhalten Sie Daten von Google API Explorer:
- Navigieren Sie zur GSC-API-Dokumentationsseite „Search Analytics: query“: https://developers.google.com/webmaster-tools/v1/searchanalytics/query
- Verwenden Sie den API Explorer auf der rechten Seite der Seite
- Geben Sie im Feld „siteUrl“ Ihre URL-Property-Adresse ein, z. B.
https://www.example.com. Sie können Ihre Domäneneigenschaft auch wie folgt einfügensc-domain:example.com - Fügen Sie im Feld „Anfragetext“
startDateundendDate. Ich bevorzuge die Daten des letzten Monats. Das Format dieser Werte istYYYY-MM-DD -
dimensionhinzufügen und ihre Werte aufpagesetzen - Erstellen Sie „dimensionFilterGroups“ und filtern Sie Abfragen mit Markenvariationsnamen heraus (ersetzen
brand_variation_namesdurch Ihre Markennamen RegExp) - Fügen Sie
rawLimitund setzen Sie es auf 25000 - Am Ende drücken Sie die 'EXECUTE'-Taste
Sie können auch den folgenden Anfragetext kopieren und einfügen:
{
"startDate": "2022-01-01",
"endDate": "2022-02-01",
"Maße": [
"Seite"
],
"dimensionFilterGroups": [
{
"Filter": [
{
"Dimension": "ABFRAGE",
"Ausdruck": "Markenvarianten_Namen",
"operator": "EXCLUDING_REGEX"
}
]
}
],
"rowLimit": 25000
}
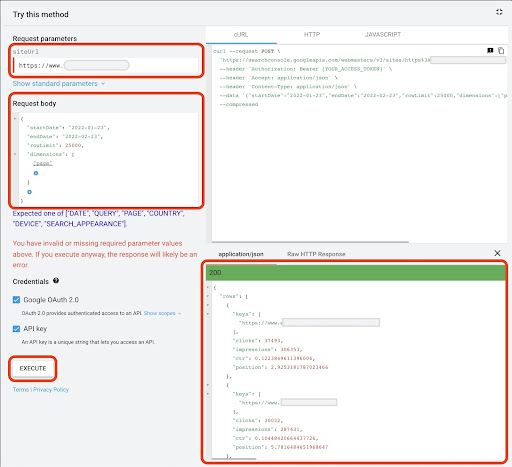
Nachdem die Anfrage ausgeführt wurde, müssen wir sie speichern. Aufgrund des Antwortformats müssen wir eine JSON-Datei erstellen, alle JSON-Antworten kopieren und sie mit dem Dateinamen „ downloaded_data.json “ speichern.
Wenn Ihre Website klein ist, wie z. B. die Website eines SASS-Unternehmens, und Ihre Landingpage-Daten weniger als 1000 Seiten umfassen, können Sie Ihr Datum einfach in GSC festlegen und Landingpage-Daten für die Registerkarte „SEITEN“ als CSV-Datei exportieren.
2. Laden von Zielseitendaten
Für dieses Tutorial gehe ich davon aus, dass Sie Daten von Google API Explorer abrufen und in einer JSON-Datei speichern. Um diese Daten zu laden, müssen wir den folgenden Code ausführen:
# Erstellen eines DataFrame für die heruntergeladenen Daten
mit open('./downloaded_data.json') als json_file:
Landings_data = json.loads(json_file.read())['rows']
Landungen_df = pd.DataFrame(Landungen_Daten)
Außerdem müssen wir einen Spaltennamen ändern, um ihm mehr Bedeutung zu verleihen, und eine Funktion anwenden, um Zielseiten-URLs direkt in der Spalte „Zielseite“ abzurufen.
# Umbenennung der Spalte „Schlüssel“ in Spalte „Zielseite“ und Konvertieren der Liste „Zielseite“ in eine URL
landings_df.rename(columns={'keys': 'landing page'}, inplace=True)
Landings_df['Landingpage'] = Landings_df['Landingpage'].apply(lambda x: x[0])
3. Abrufen aller Zielseiten-Stammverzeichnisse
Zunächst müssen wir unseren Site-Namen definieren.
# Definieren Sie Ihren Site-Namen zwischen Anführungszeichen. Beispiel: 'https://www.example.com/' oder 'http://mydomain.com/' site_name = ''
Dann führen wir eine Funktion auf Zielseiten-URLs aus, um ihre Stammverzeichnisse abzurufen und sie in der Ausgabe anzuzeigen, um sie auszuwählen.
# Jedes Landing Page (URL)-Verzeichnis abrufen
Landings_df['Verzeichnis'] = Landings_df['Zielseite'].str.extract(pat=f'((?<={site_name})[^/]+)')
# Um alle Verzeichnisse in der Ausgabe zu erhalten, müssen wir Pandas Optionen manipulieren
pd.set_option("display.max_rows", Keine)
# Website-Verzeichnisse
Landungen_df['Verzeichnis'].value_counts()
Dann wählen wir aus, für welche Verzeichnisse wir ihre CTR-Kurve erhalten müssen.
Fügen Sie die Verzeichnisse in die Variable important_directories ein.
Beispiel: product,tag,product-category,mag . Trennen Sie Verzeichniswerte durch Kommas.
wichtige_verzeichnisse = ''
wichtige_verzeichnisse = wichtige_verzeichnisse.split(',')
4. Landingpages beschriften und gruppieren
Wie bei Suchanfragen kennzeichnen wir Landingpages auch anhand ihrer durchschnittlichen Position.
# Landing Pages Position kennzeichnen
für i im Bereich (1, 11):
Landungen_df.loc[(Landungen_df['Position'] >= i) & (
Landungen_df['Position'] < i + 1), 'Positionsbezeichnung'] = i
Dann gruppieren wir Zielseiten basierend auf ihrem „Verzeichnis“.
# Gruppierung von Zielseiten basierend auf ihrem 'Verzeichnis'-Wert Landungen_grouped_df = Landungen_df.groupby(['Verzeichnis'])
5. Erstellen von Box- und Balkendiagrammen für unsere Verzeichnisse
In der vorherigen Methode haben wir keine Funktion zum Generieren der Diagramme verwendet. Jedoch; Um die CTR-Kurve für verschiedene Zielseiten automatisch zu berechnen, müssen wir eine Funktion definieren.
# Die Funktion zum Erstellen und Speichern der einzelnen Verzeichnisdiagramme
def each_dir_plot(dir_df, Schlüssel):
# Gruppierung von Verzeichnis-Landingpages basierend auf ihrem 'Positionslabel'-Wert
dir_grouped_df = dir_df.groupby(['Positionsbezeichnung'])
# Erstellen eines DataFrame zum Speichern von 'dir_grouped_df' manipulierten Daten
Modified_df = pd. DataFrame ()
# Eine Liste zum Speichern jedes Positionsmittelwertes für unser Balkendiagramm
mean_ctr_list = []
'''
Looping über 'query_grouped_df'-Gruppen und Anhängen der Top-20 %-Abfragen basierend auf den Impressionen an den 'modified_df'-DataFrame.
Wenn die Berechnung der CTR nur basierend auf den obersten 20 % der Suchanfragen mit den meisten Impressionen nicht das Beste für Sie ist, können Sie dies ändern.
Um es zu ändern, können Sie es erhöhen oder verringern, indem Sie '.quantile(q=your_optimal_number, interpolation='lower')]' manipulieren.
„you_optimal_number“ muss zwischen 0 und 1 liegen.
Wenn Sie beispielsweise die obersten 30 % Ihrer Suchanfragen erhalten möchten, ist „your_optimal_num“ die Differenz zwischen 1 und 0,3 (0,7).
'''
für i im Bereich (1, 11):
# Ein Versuch - außer für Situationen, in denen ein Verzeichnis für einige Positionen keine Daten enthält
Versuchen:
tmp_df = dir_grouped_df.get_group(i)[dir_grouped_df.get_group(i)['Impressionen'] >= dir_grouped_df.get_group(i)['Impressionen']
.quantile(q=0.8, interpolation='lower')]
mean_ctr_list.append(tmp_df['ctr'].mean())
Modified_df = Modified_df.append(tmp_df,ignore_index=True)
außer KeyError:
mean_ctr_list.append(0)
# 1. Der Boxplot
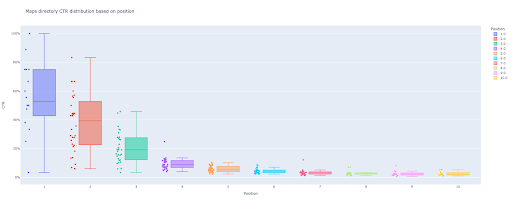
box_fig = px.box(modified_df, x='position label', y='ctr', title=f'{key} Verzeichnis-CTR-Verteilung basierend auf Position',
points='all', color='position label', labels={'position label': 'Position', 'ctr': 'CTR'})
# Alle zehn X-Achsen-Ticks anzeigen
box_fig.update_xaxes(tickvals=[i für i im Bereich (1, 11)])
# Änderung des Tick-Formats der Y-Achse in Prozent
box_fig.update_yaxes(tickformat=".0%")
# Plot im Verzeichnis 'Output Plot Images' speichern
box_fig.write_image(f'./output plot images/{key} directory-Box plot CTR curve.png')
# 2. Das Balkendiagramm
bar_fig = px.bar(x=[pos for pos in range(1, 11)], y=mean_ctr_list, title=f'{key} Verzeichnis mittlere CTR-Verteilung basierend auf Position',
label={'x': 'Position', 'y': 'CTR'}, text_auto=True)
# Alle zehn X-Achsen-Ticks anzeigen
bar_fig.update_xaxes(tickvals=[i für i im Bereich (1, 11)])
# Änderung des Tick-Formats der Y-Achse in Prozent
bar_fig.update_yaxes(tickformat='.0%')
# Plot im Verzeichnis 'Output Plot Images' speichern
bar_fig.write_image(f'./output plot images/{key} directory-Bar plot CTR curve.png')
Nachdem wir die obige Funktion definiert haben, benötigen wir eine „for“-Schleife, um die Verzeichnisdaten zu durchlaufen, für die wir ihre CTR-Kurve erhalten möchten.
# Verzeichnisse durchlaufen und die Funktion 'each_dir_plot' ausführen
für Schlüssel, Element in landings_grouped_df:
if key in important_directories:
each_dir_plot(Element, Schlüssel)
In der Ausgabe erhalten wir unsere Plots im Ordner output plot images .
Tipp für Fortgeschrittene!
Sie können auch die CTR-Kurven der verschiedenen Verzeichnisse berechnen, indem Sie die Zielseite für Suchanfragen verwenden. Mit ein paar Funktionsänderungen können Sie Abfragen basierend auf ihren Zielseitenverzeichnissen gruppieren.
Sie können den folgenden Anfragetext verwenden, um eine API-Anfrage im API Explorer zu stellen (vergessen Sie nicht die Beschränkung auf 25000 Zeilen):
{
"startDate": "2022-01-01",
"endDate": "2022-02-01",
"Maße": [
"Anfrage",
"Seite"
],
"dimensionFilterGroups": [
{
"Filter": [
{
"Dimension": "ABFRAGE",
"Ausdruck": "Markenvarianten_Namen",
"operator": "EXCLUDING_REGEX"
}
]
}
],
"rowLimit": 25000
}
Tipps zum Anpassen der CTR-Kurvenberechnung mit Python
Um genauere Daten zur Berechnung der CTR-Kurve zu erhalten, müssen wir Tools von Drittanbietern verwenden.
Neben dem Wissen, welche Suchanfragen ein Featured Snippet enthalten, können Sie beispielsweise weitere SERP-Funktionen erkunden. Wenn Sie Tools von Drittanbietern verwenden, können Sie außerdem das Abfragepaar mit dem Zielseitenrang für diese Abfrage erhalten, basierend auf den SERP-Funktionen.
Dann Landingpages mit ihrem Stammverzeichnis (Elternverzeichnis) kennzeichnen, Abfragen basierend auf Verzeichniswerten gruppieren, SERP-Funktionen berücksichtigen und schließlich Abfragen basierend auf der Position gruppieren. Für CTR-Daten können Sie CTR-Werte von GSC mit ihren Peer-Abfragen zusammenführen.