
Bedeutung des semantischen Netzwerks für SEO: Erstellen von semantischen Inhaltsnetzwerken mit Abfrage- und Dokumentvorlagen – Fallstudie
Veröffentlicht: 2022-01-11Ein semantisches Netzwerk ist mit dem Konzept einer Wissensbasis verbunden, die reale Informationen für Dinge darstellen kann, die relationale Verbindungen haben. Eine Wissensdatenbank kann Tausende von Beziehungstypen mit Milliarden von Entitäten und Billionen von Fakten haben. Ein semantisches Netzwerk kann aus jeder realen Existenz mit gemeinsamen Merkmalen wie Gewicht, Größe, Typ, Geruch oder Farbe erstellt werden. Die Beziehung zwischen Semantischen Netzen und dem Semantischen Web wird durch semantische Suchmaschinen und Optimierung hergestellt.
Semantische Netzwerke werden beim semantischen Parsing, der Wortsinn-Disambiguierung, der WordNet-Erstellung, der Graphentheorie, der Verarbeitung natürlicher Sprache, dem Verständnis und der Generierung verwendet. Die Perspektive eines semantischen Netzes kann innerhalb der semantischen Suchmaschinenoptimierung genutzt werden, indem ein semantisches Inhaltsnetz bereitgestellt wird.
In dieser SEO-Fallstudie werden zwei verschiedene Websites mit zwei unterschiedlichen Methoden mit derselben Perspektive anhand der Query-, Document-, Intent-Templates und der dahinter stehenden Entity-Attribut-Paare erklärt.
Mit einem Verständnis dafür, wie Suchmaschinen Wissen darstellen und wie sie ihre Wissensdarstellung erweitern, bin ich in der Lage, dies zu nutzen, um unglaubliche Ranking-Ergebnisse zu erzielen. Sobald Sie die grundlegenden Konzepte verstanden haben, werde ich erklären, wie ich sie auf die beiden verschiedenen Websites angewendet habe, und dann werde ich die Methoden, die ich verwendet habe, detailliert beschreiben.
Wie können semantische Netzwerke das Ranking Ihrer Website verbessern?
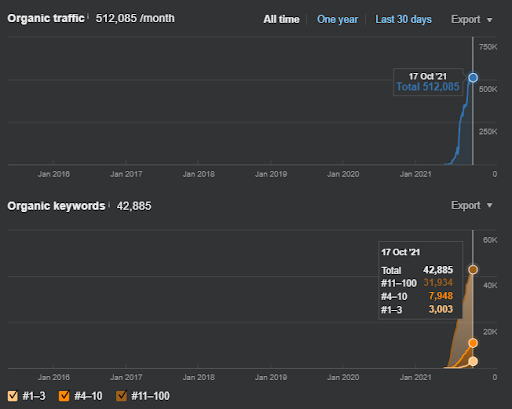
Unten finden Sie die gesamten Rohergebnisse für Projekt I.
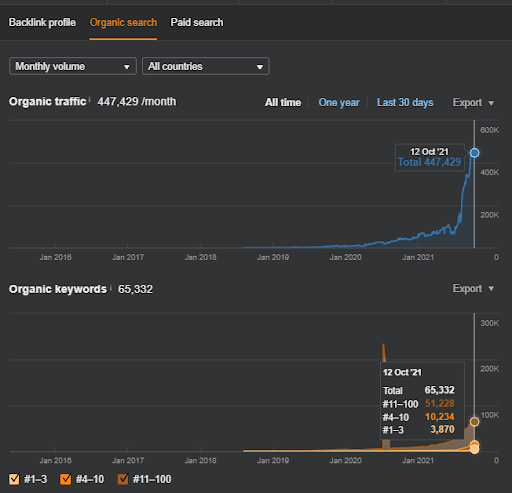
Ergebnisse für das erste Projekt, das IstanbulBogaziciEnstitu.com ist. Um zu beweisen, dass die „Semantischen Netzwerke“ für SEO mit Abfrage- und Dokumentvorlagen verwendet werden können, werde ich zwei verschiedene Inhaltsnetzwerke von Project One demonstrieren. Project One wird in naher Zukunft dank Semantic Content Network Two deutlich bessere Ergebnisse erzielen. Der Kunde wird für die Einführung dieses zweiten Netzwerks verantwortlich sein, aber ich werde auch seine Logik erläutern.
17 Tage später, hier ist der Fortschritt bei Projekt I: 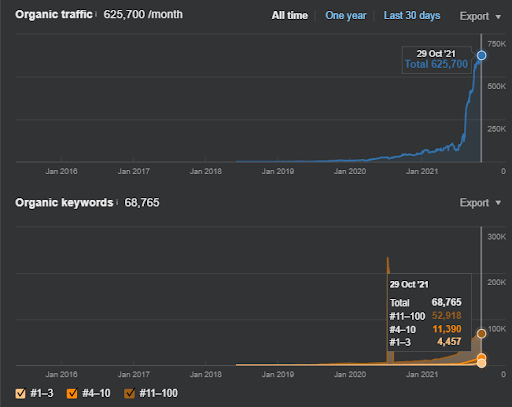
17 Tage später ist der Re-Ranking-Prozess des Semantic Content Network klarer.
Konzepte des semantischen Inhaltsnetzwerks helfen uns, den Wert von Suchanfragen, Suchabsichten, Verhaltensweisen und Dokumentvorlagen für Entitäten desselben Typs zu verstehen. In dieser Semantic Network-Fokus-SEO-Fallstudie werden die vorherige Topical Authority und Semantic SEO Case Study durch die beiden neuen Websites vertieft, die semantisch erstellte Content-Netzwerke um dieselben Entitätstypen verwenden.
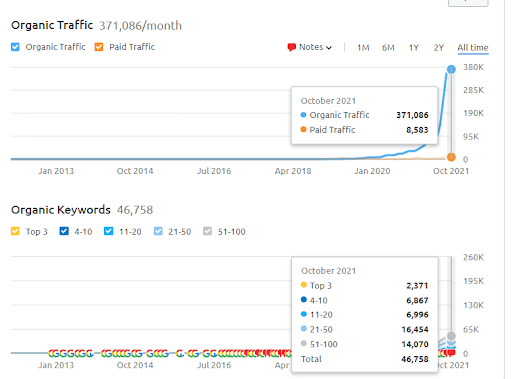
Dies ist die SEMRush-Grafik des ersten Projekts. Ich muss auch erwähnen, dass diese Website das June Broad Core Algorithm Update verloren hat, wenn sie nicht ihre „Rankability“ verlieren würde, wären die Ergebnisse besser. Für das nächste Broad Core Algorithm Update kann es mit einer besseren thematischen Autorität, Abdeckung und historischen Daten die „Rangfähigkeit“ leicht wiederherstellen.
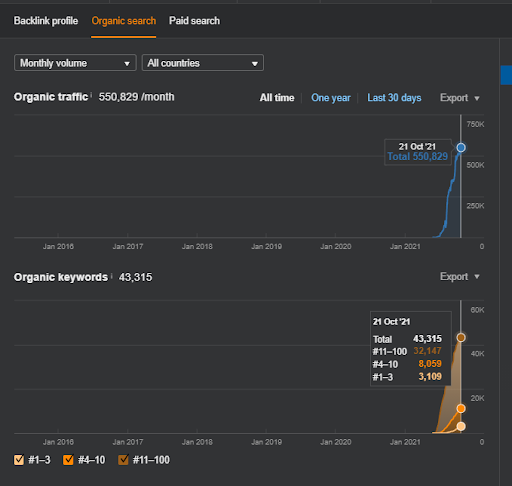
Der Name des zweiten Projekts ist Vizem.net. Im Gegensatz zu Project One können Sie sehen, dass Vizem.net einen langsameren, aber stetigen Anstieg hat. Das liegt daran, dass sie die Semantic Content Networks mit leicht unterschiedlichen Perspektiven verwenden. Unten sehen Sie die Ahrefs-Ergebnisse des zweiten Projekts.
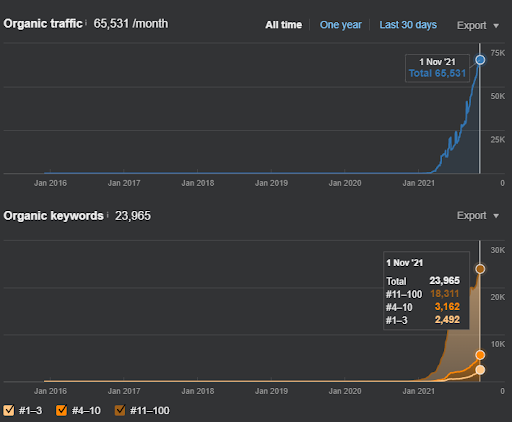
Die Ergebnisse des zweiten Projekts stellen einen „langsamen Re-Ranking-Prozess“ dar, indem die thematische Abdeckung und Autorität schrittweise verbessert werden. Die Begriffe „Re-Ranking“ und „Initial Ranking“ werden nach den Konzepten in Bezug auf die Semantic Content Networks erläutert. Wenn Sie die „Stabilität“ in den Grafiken erkennen, liegt das daran, dass ich aufgehört habe, neue Inhalte in der Quelle zu veröffentlichen. Und es wirkt sich auf den Re-Ranking-Prozess aus, wie Sie anhand der Zählungen der Top-3-Suchanfragen erkennen. Die Beziehungen „Momentum“ und „Re-Ranking“ finden Sie nach den Erläuterungen der grundlegenden Konzepte.
Unten finden Sie die SEMRush-Ergebnisse von Vizem.net.
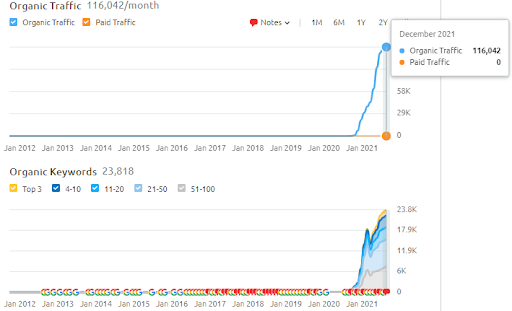
Der tatsächliche Verkehr dieser Website ist 3x höher als die Zahl, die im SEMRush angegeben ist. Sie können die gleichen „Stabilitäts“- und „Impuls“-Konzepte auch in diesen Diagrammen realisieren.
Während ich die Topical Authority SEO Case Study schrieb, dankte ich Bill Slawski für die Erläuterung meiner Sichtweise. Ich wiederhole es auch für die Semantic Content Network SEO-Fallstudie. Um die Konzepte „Re-ranking“ und „Initial-ranking“ zu verstehen, sollte „Ways Search Engines May Rerank Search Results“ gelesen werden.
Am 18. März 2021 haben Oncrawl, RankSense und Holistic SEO & Digital ein Python-SEO- und Data-Science-Webinar veröffentlicht. Im Webinar wurde die SERP aufgezeichnet, um die Ergebnisunterschiede zu animieren. Es ist zu erkennen, dass die Suchmaschine die Rankings bestimmter Quellen mit anderen mit ähnlicher Häufigkeit verändert.
Bevor ich fortfahre, weiß ich, dass dies ein langer Artikel ist. Aber eigentlich ist dies eine kurze Erklärung einer hochkomplexen SEO-Methodik. Semantische Inhaltsnetzwerke erfordern zu viel Nachdenken bei der Gestaltung und monatelange Schulungen für Kunden, Autoren und das Onboarding. Daher möchte ich mich in diesem Artikel auf die Definitionen der Konzepte mit den bestmöglich ausführbaren kurzen Vorschlägen und wichtigen Patenten von Google und anderen Suchmaschinen, Forschungsarbeiten zusammen mit ihren eigenen Konzepten konzentrieren. In der langen Version (im Grunde ein Buch) habe ich mich auf „Anfangsranking“ und „Neuranking“ von semantischen Inhaltsnetzwerken konzentriert.
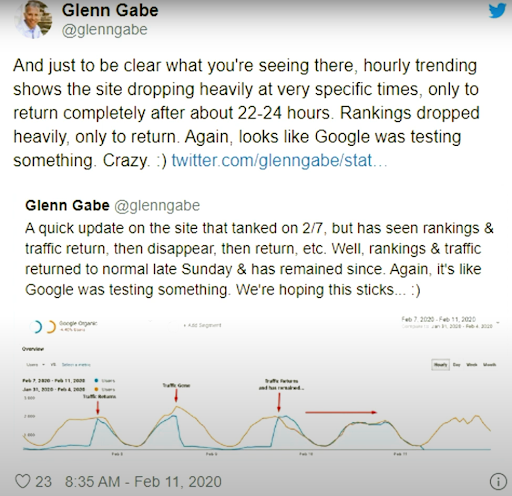
Ab dem 11. Februar 2020 hat Glenn Gabe ein gutes Beispiel für die Re-Ranking- und Testing-Methodik der Suchmaschinen bildlich dargestellt.
Wenn Sie mehr erfahren möchten, lesen Sie den Abschnitt „Bedeutung des anfänglichen Rankings und des Re-Rankings für SEO“.
Um tief in die realen Daten für die SEO-Fallstudie einzutauchen, sollten die Konzepte zum Verständnis des semantischen Inhaltsnetzwerks mit einer Perspektive des Suchmaschinenverständnisses und der Kommunikation verarbeitet werden.
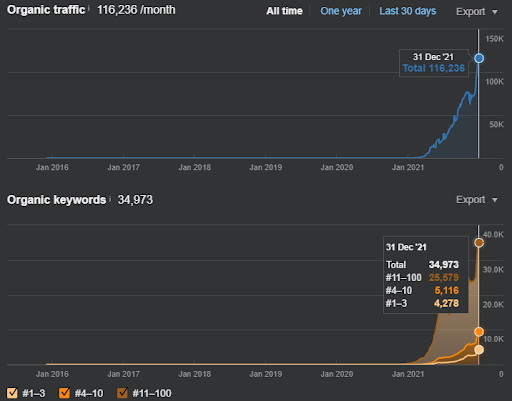
Als Beispiel für die Neubewertung von Vizem.net ist die aktualisierte Situation oben zu sehen. In den zukünftigen Abschnitten der SEO-Fallstudie wird es weitere Erläuterungen zu den Re-Ranking-Algorithmen von Google für SEO geben.
Was ist ein semantisches Netzwerk?
Ein semantisches Netzwerk kann zum Verbinden und Analysieren des Internets der Dinge verwendet werden. Es kann nützlich sein, um die potenziellen Käufer auf dem Technologiemarkt zu erkennen, oder nur eine Co-Wort-Analyse für die Erstellung von Keyword-Netzwerken und Clustering. Ein semantisches Netzwerk kann verwendet werden, um die Navigation zu unterstützen und die Struktur von Beziehungen oder die relative Bedeutung einer Sache zu einer anderen Sache aufzudecken. Semantic Network hat die folgenden Komponenten:
- Lexikalische Semantik: Verstehen, welches Wort und welcher Begriff mit welchen anderen verknüpft ist, mit welchen Unterschieden.
- Strukturelle Komponente: Verstehen, welcher Knoten mit welcher Information mit welcher Kante verbunden ist.
- Semantische Komponente: Definition der Fakten.
- Prozeduraler Teil: Hilft, weitere Verbindungen zwischen Komponenten herzustellen.
Da semantische Netze vielseitig sind, können NLP-Algorithmen auch für sehr unterschiedliche Zwecke verwendet werden, beispielsweise um bei der Identifizierung komplizierter Gesundheitsprobleme zu helfen. Dieselbe semantische Netzwerkstruktur kann in mehreren anderen Bereichen implementiert werden, solange diese anderen Bereiche eine semantische Beziehung zueinander haben.
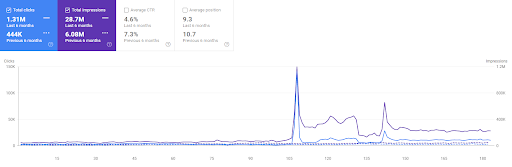
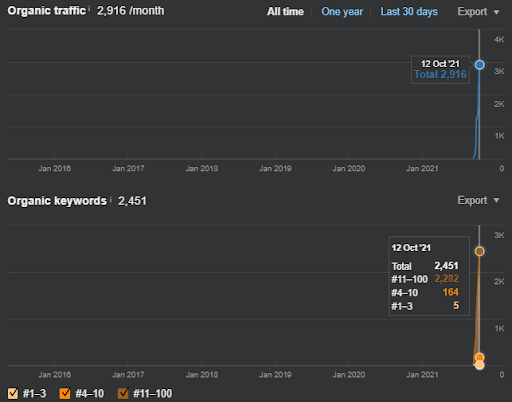
Der Vergleich der letzten 6 Monate des ersten Projekts.
Was ist eine Wissensdatenbank?
Eine Wissensdatenbank ist eine Informationsbibliothek mit Klassifikation in maschinenlesbarer Form. Eine Wissensdatenbank kann als Enzyklopädie verwendet werden, die basierend auf der Abfrage eingegrenzt und vertieft werden kann. Eine Wissensbasis kann basierend auf Vorschlägen, Faktenextraktion und Informationsextraktion gebildet werden. Die Beziehung zwischen einem semantischen Netzwerk und einer Wissensbasis besteht darin, dass alles, was sich im semantischen Netzwerk befindet, in die Wissensbasis gestellt wird, während die Fakten extrahiert werden.
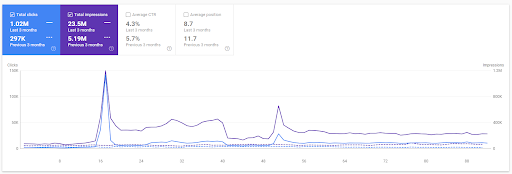
Der Vergleich der letzten 3 Monate des ersten Projekts
Was ist ein semantisches Inhaltsnetzwerk?
Das semantische Inhaltsnetzwerk stellt ein Inhaltsnetzwerk dar, das auf der Grundlage der Komponenten und des Verständnisses des semantischen Netzwerks erstellt wurde. Ein semantisches Inhaltsnetzwerk kann mehrere Attribute einer Entität oder von Entitäten derselben Gruppe enthalten, um eine Wissensbasis mit mehr Details bereitzustellen.
Innerhalb eines semantischen Inhaltsnetzwerks können die Wissensdomänenbegriffe und Tripel verwendet werden, um den Hauptzweck eines Dokuments und mögliche benachbarte Inhaltsteile zu signalisieren.
Eine Suchmaschine kann ihre eigene Wissensbasis mit der Wissensbasis vergleichen, die aus dem Inhalt einer Website generiert werden kann. Wenn die Website ein hohes Maß an Genauigkeit und Vollständigkeit für verschiedene Kontextebenen aufweist, kann die Suchmaschine ihre eigene Wissensbasis aus den Inhalten der Website verbessern. Wenn eine Suchmaschine ihre eigene Wissensbasis aus einer anderen Quelle im offenen Web verbessert und erweitert, ist dies ein Signal für ein hohes Maß an wissensbasiertem Vertrauen.
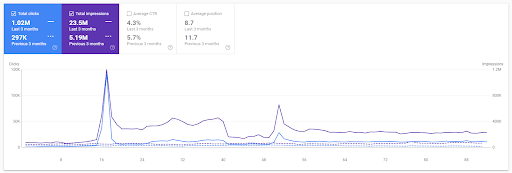
Jahresvergleich für die letzten 3 Monate basierend auf dem ersten Projekt.
Was ist wissensbasiertes Vertrauen?
Wissensbasiertes Vertrauen konzentriert sich auf offene Web-basierte Informationen auf die „Genauigkeit der Informationen“, nicht auf den „PageRank“. Es ist ein Algorithmus ähnlich dem RankMerge. Wissensbasiertes Vertrauen umfasst Tripletts, Faktenextraktion, Genauigkeitsprüfung und Textverständnis durch Entfernen der Textmehrdeutigkeit. Wissensbasiertes Vertrauen kann erworben werden, indem semantische Inhaltsnetzwerke bereitgestellt werden, die die stark verbundenen Komponenten innerhalb des Artikels haben, basierend auf unterschiedlichen, aber relevanten kontextuellen Schichten.
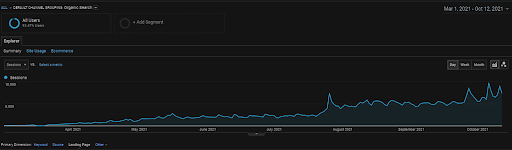
Die organische Sitzung des Vizem.net von GA für die letzten 6 Monate.
Unten sehen Sie ein Beispiel einer wissensbasierten Trust-Präsentation von Luna Dong. Es zeigt, wie sich eine Suchmaschine auf die „internen Ranking-Faktoren“ statt auf die exogenen Ranking-Faktoren konzentrieren kann. Es erklärt, dass ein hoher PageRank allein keine hohe Qualität und Genauigkeit des Inhalts darstellen kann. Daher ist es wichtig, einen KBT (Knowledge-based Trust) zu haben.
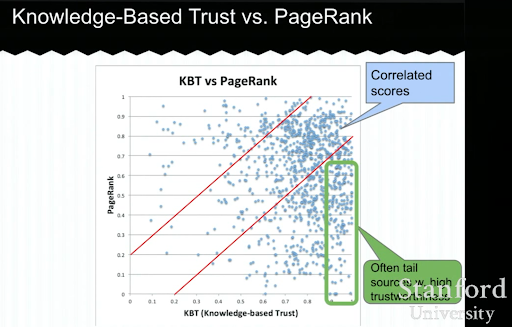
Vielen Dank an Arnout Hellemans, der diesen lehrreichen Vortrag während eines privaten SEO-Chats mit mir geteilt hat. Wenn Sie mehr über wissensbasiertes Vertrauen erfahren möchten: Stanford Seminar – Wissenstresor und wissensbasiertes Vertrauen
Was ist Kontextabdeckung?
Kontextbezogene Abdeckung und thematische Abdeckung sind nicht dasselbe wie Wissensdomäne und Kontextdomäne nicht dasselbe sind. Eine kontextabhängige Abdeckung repräsentiert die Verarbeitungswinkel eines Konzepts. Ein Konzept kann anhand seiner gemeinsamen Punkte zu den anderen Dingen verarbeitet werden. Wenn die Entität beispielsweise ein Land ist, kann ihre Haltung zur Umweltkrise verarbeitet werden. Wenn andere Länder aus demselben Blickwinkel verarbeitet werden, bedeutet dies, dass wir einen Kontextbereich abdecken.

Die Google-Suchmaschine baut ihre Forschungsarbeiten und Patente im Laufe der Zeit auf. Das rechte Zitat aus dem obigen Abschnitt ist ein Attribut der „Kontextvektoren“, während der linke Abschnitt ein Attribut der „Phrasentaxonomie“ ist. Das Interessante ist, dass sogar das Beispiel dasselbe ist, nämlich „Digitalkamera“.
Die vertieften Details und Unterteile dieser Kombinationen repräsentieren die kontextuellen Schichten innerhalb einer kontextuellen Domäne. Jede Entität, ob benannt oder nicht, hat viele kontextabhängige Domänen. Daher extrahiert Google jedes Jahr mehr Kontextdomänen und Benutzer suchen längere Suchanfragen. Wenn die Verarbeitung natürlicher Sprache und das Verständnis natürlicher Sprache entwickelt werden, erweitern sich die Abfragen und die Dokumente in Bezug auf Details und Kontext.
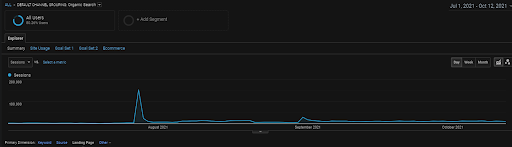
Die Grafik der GA Organic Sessions für die letzten 4 Monate des BogaziciEnstitu-Projekts. Aufgrund der „historischen Datengewinnungsphase“ des Projekts sind die erhöhten Details nicht eindeutig als linear zu sehen.
Eine kontextbezogene Abdeckung kann unter den „Kontextqualifizierern“ verstanden werden. Ein Kontextkennzeichner kann ein Adjektiv, Adverbial oder jede andere Präposition sein, wie zum Beispiel Sätze, die mit „for, in, at, during, while“ beginnen. Die nachstehenden entitätsbezogenen Fragen sind in Bezug auf die kontextbezogene Domäne nicht gleich:
- Was sind die nützlichsten Früchte für Kinder mit Schlaflosigkeit?
- Was sind die nützlichsten Früchte für Kinder mit Angst?
Die folgenden entitätsbezogenen Fragen sind in Bezug auf die kontextbezogene Ebene nicht gleich:
- Was sind die nützlichsten Früchte für Kinder mit schwerer Schlaflosigkeit über 6 Jahren?
- Was sind die nützlichsten Früchte für Kinder mit geringer Angst unter 6 Jahren?
Die nachstehenden unternehmensbezogenen Fragen sind in Bezug auf die Wissensdomänen nicht gleich:
- Was sind die nützlichsten Bücher für Kinder mit schwerer Schlaflosigkeit über 6 Jahren?
- Was sind die nützlichsten Spiele für Kinder mit geringer Angst unter 6 Jahren?
Aber alle diese Fragen können im selben Semantic Content Network sein, da sie alle dasselbe „Konzept“ und denselben „Interessenbereich“ mit ähnlicher Suchaktivität und suchbezogenen Aktivitäten in der realen Welt betreffen.
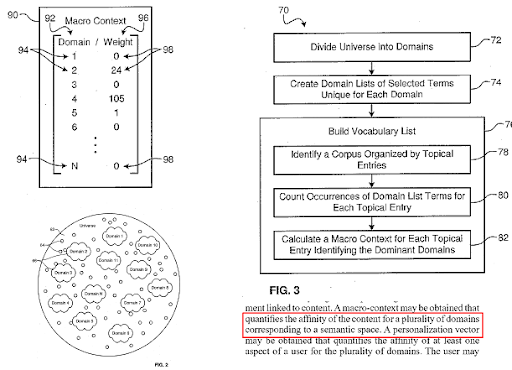
Eine Suchmaschine unterteilt das Web in verschiedene Wissensdomänen und berechnet gleichzeitig die Makro- und Mikrokontextwerte für eine Quelle, eine Webseite und einen Webseitenabschnitt.
Ich weiß, dass ich viele neue Konzepte für Sie habe, und da dies die Kurzfassung dieses Artikels ist, kann ich hier nicht auf alles eingehen, aber in einem zukünftigen Semantik-SEO-Kurs werde ich diese Dinge verarbeiten, z der Unterschied zwischen „Suchaktivität“ und „suchbezogener Aktivität in der realen Welt“.
Kommen wir noch ein wenig zu den konkreteren Dingen.
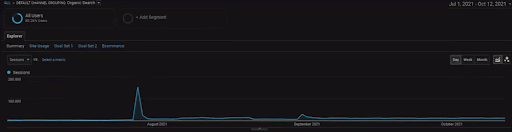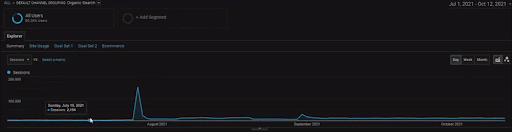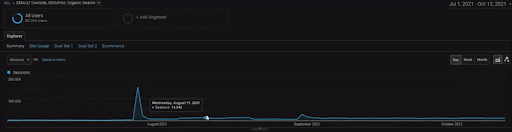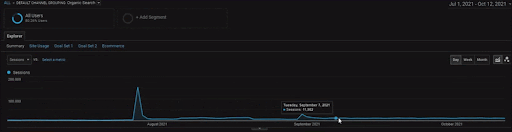
Um die Details des BogaziciEnstitu-Projekts anzuzeigen, können Sie die interaktive Bildversion überprüfen. Der Test- und Re-Ranking-Prozess von Suchmaschinen ist bei diesem Projekt nach dem Ereignis der historischen Datenquelle klarer.
Wie hängt MuM mit den semantischen Inhaltsnetzwerken zusammen?
Multitask Learning mit einem Unified Transformer oder dem Multitask Unified Model trainiert Sprachmodelle, um sowohl visuelle Eingaben als auch Text auszuwerten. Es ist in der Lage, Text zusammen mit Verständnis zu generieren. Außerdem ist MuM sprachagnostisch, d. h. semantisches SEO hängt von Sprachkenntnissen ab, ist aber nicht auf eine Sprache beschränkt. Da Entitäten keine Sprache haben und die Bedeutung universell ist, nutzt MuM die Informationen aus mehreren Sprachen und mehreren Kontexten in einer einzigen Wissensbasis.
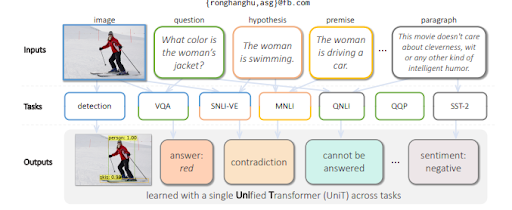
Um die Fragen aus einem Bild zu beantworten, generiert MuM Fragen basierend auf den erkannten Objekten in einem Bild. In naher Zukunft können auch audio- und videobezogene Fragen generiert werden.
MuM verwendet verschiedene Domänen für die Objekterkennung und das Verstehen natürlicher Sprache mit einer Transformer-Encoder-Decoder-Struktur. Jede Eingabe stammt aus einem anderen Bereich des offenen Webs, während alle von einem einzigen gemeinsamen Decoder ausgewertet werden. Nachfolgend sehen Sie ein weiteres Beispiel aus der Forschungsarbeit.
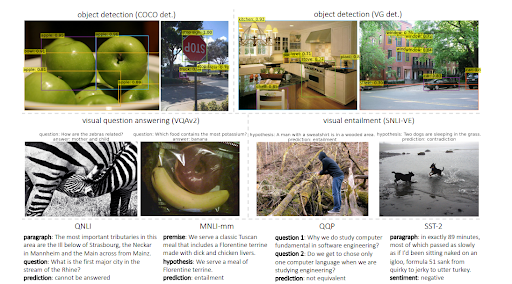
Als Anmerkung, MuM kann 1000-mal stärker sein als BERT, aber BERT wird immer noch im Text-Encoder von MuM verwendet. Der Hauptvorteil von MuM besteht darin, dass es direkt für Bildmaterial und Audio verwendet werden kann, weshalb es als „Multitask“-Modell bezeichnet werden kann. Der zweite Vorteil ist, dass alle Sprachbarrieren direkt beseitigt werden. Der dritte Vorteil ist, dass alles ohne zusätzliche Vermittler miteinander verbunden werden kann. Der vierte Vorteil ist, dass MuM im Gegensatz zu BERT auch Text generieren kann.
Die Verbindung zwischen MuM, der Wissensbasis, semantischen Netzen und Kontextabdeckung besteht darin, dass die Suchmaschine in der Lage ist, viel mehr Kontextdomänen über Kontextqualifizierer und ihre Kombinationen mit möglichen Wissensdomänen zu finden. Somit kann ein gut strukturiertes semantisches Inhaltsnetzwerk, das mit einer geeigneten thematischen Karte und einem geeigneten Quellkontext gestaltet ist, das Vertrauen in die Wissensbasis zusammen mit der thematischen Autorität verbessern.
Was ist der Kontext der Quelle?
Der Kontext der Quelle repräsentiert zwei Dinge. Das zentrale Suchinternet der Quelle und die zentrale Suchaktivität, die mit der zugehörigen Suchaktivität durchgeführt werden kann. Bei einer E-Commerce-Website ist der Quellkontext der Kauf eines bestimmten Produkts oder eines bestimmten Produkttyps. Wenn es sich um eine Reise-Website handelt, geht der Kontext der Quelle irgendwohin von einem anderen Ort für verschiedene Arten von Lebensmitteln, Landschaften oder einfach nur Geschäft. Basierend auf dem Kontext der Quelle müssen das Design des semantischen Inhaltsnetzwerks und die thematische Karte weiter konfiguriert werden. Dies erfordert die Auswahl der zentralen Abschnitte innerhalb der thematischen Karte und der ergänzenden Abschnitte innerhalb der thematischen Karte.
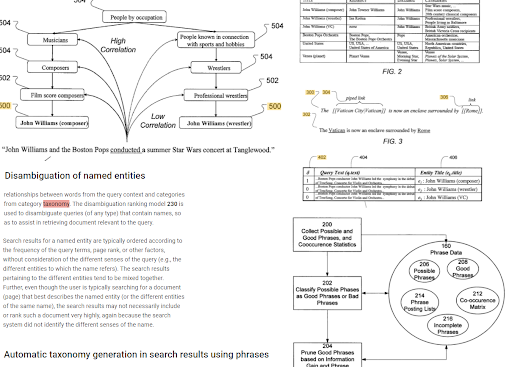
Die phrasenbasierte Indexierung und das entitätsorientierte Suchverständnis sind semantisch miteinander verbunden. Oben sind die „Named Entity Disambiguation“ und die „Automatic Taxonomy Generation in Search Results Using Phrases“ zusammen zu sehen, um den „Context“ zu ermitteln. Die guten Formulierungen und die einzigartigen, aber korrelierten Informationen zu einem Thema helfen bei der besseren Erst- und Neubewertung.
Wiederum sind einige dieser Konzepte, die „topical map configuration“, „semantic content network design“ noch nicht definiert worden, und dies ist nicht der richtige Ort dafür. Aber die zugehörige Suchaktivität wurde zusammen mit der kanonischen Suchabsicht und repräsentativen Phrasen für diese kanonischen Suchabsichten erklärt.
Hintergrund der Semantic Network Focused SEO Case Study
Basierend auf den oben genannten Konzepten habe ich semantische Netzwerke verwendet, um eine SEO-Fallstudie zu erstellen. Wir sehen uns die beiden Website-Projekte an, die ich am Anfang dieses Artikels erwähnt habe, und untersuchen die Ergebnisse und wie ich Semantische Netze implementiert habe, um sie zu produzieren.
Um Ihnen eine Vorstellung davon zu geben, wie leistungsfähig diese Netzwerke sein können, sind die SEO-bezogenen Ergebnisse für die auf semantische Netzwerke ausgerichtete SEO-Fallstudie unten aufgeführt.
- Das Verständnis semantischer Netzwerke ist eine Notwendigkeit, um eine richtige Topical Map zu erstellen.
- Bei beiden Projekten wird auf technisches SEO verzichtet, um die Auswirkungen von semantischem SEO zu isolieren.
- Page Speed Optimization wird aus dem gleichen Grund nicht verwendet.
- Design und WUX (Website User Experience) Optimierung werden nicht verwendet.
- Backlinks (externe Referenzen und PageRank-Flow) werden nicht verwendet.
- Beide Marken haben keine historischen Daten. Vizem.net ist völlig neu, BogaziciEnstitusu hat eine ältere Geschichte, war aber niedriger als das eigentliche Unternehmen.
- OnPage SEO oder andere Verticals der SEO werden nicht genutzt.
- Beide Marken haben einen besseren Server als das vorherige Fallstudienbeispiel von Topical Authority.
Diese Semantic Network-fokussierte SEO-Fallstudie wird Menschen helfen, die ihre semantische SEO-Perspektive mit zwei verschiedenen Methoden und Konzepten verbessern möchten, die sich auf zwei verschiedene Websites konzentrieren.
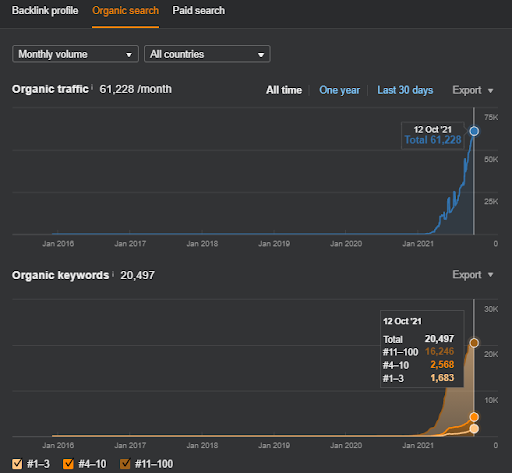
Projekt Zwei: Vizem.net konzentriert sich auf das Visumantragsverfahren. Bevor ich diese Projekte geschrieben, veröffentlicht oder sogar gestartet habe, habe ich diese beiden Websites viele Male meinen anderen Kunden oder Partnern gezeigt. Und Vizem.net hat kürzlich seine „Topical Authority“-Reise begonnen.
SEO basierend auf Semantic Networks Case Study wurde in zwei verschiedenen Versionen geschrieben. Wenn Sie alle zugehörigen Patente, Forschungsarbeiten und sehr detaillierten Untersuchungen, Interpretationen aus der Sicht von Suchmaschinen lesen und gleichzeitig die Entscheidungsbäume von Suchmaschinen weiter verstehen möchten, können Sie die Bedeutung von SEO für Erst- und Neubewertung lesen Fallstudienartikel, der länger als 30.000 Wörter ist. Wenn Sie nicht über genügend theoretisches Wissen für SEO und historische Hintergründe verfügen, können Sie weiterhin die Zusammenfassung lesen.
Unten sehen Sie die Grafik des zweiten Projekts (Vizem.net) von SEMRush.
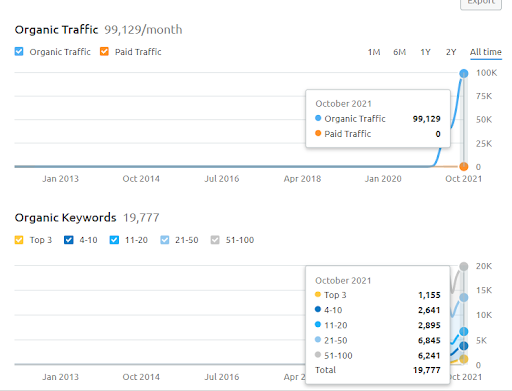
Die SEMRush-Grafik der zweiten Website. Vizem.net ist eine völlig neue Quelle, die auf Branchen mit einem hohen Grad an verwurzelten Wettbewerbern wie „Visa Application“ abzielt. Insbesondere aufgrund der jüngsten Ereignisse in der Türkei nimmt die Wettbewerbsintensität der Branche zu. Daher ist es sinnvoll, die Perspektive des semantischen Netzwerks zum Erstellen eines Inhaltsnetzwerks zu verwenden.
Erstes Projekt: Istanbul Bogazici Enstitusu: 600 % mehr organische Klicks in 3 Monaten – Nutzung historischer Daten und anfängliches Ranking
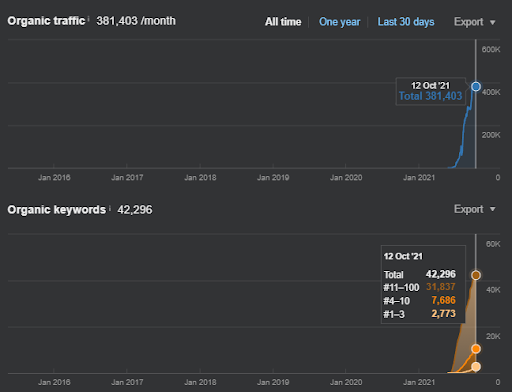
IstanbulBogazici Enstitusu ist eine der schwierigsten SEO-Fallstudien, die ich durchgeführt habe, nicht wegen der Suchmaschinen, sondern wegen der Menschen und meiner Gesundheitsprobleme. Daher habe ich das Projekt verlassen und das dritte semantische Inhaltsnetzwerk nicht veröffentlicht, das die semantischen Beziehungen basierend auf dem Kontext der Quelle vervollständigen soll. Selbst wenn es keine Begriffe aus Wissensdomänen und kontextbezogene Phrasen richtig implementiert hat, ist es mit ausreichend semantischen Verbindungen und Genauigkeit konfiguriert, um eine organische Suchleistung von insgesamt über drei Millionen Sitzungen pro Monat zu ermöglichen, wenn das dritte Content-Werbenetzwerk dies ist zukünftig veröffentlicht werden, was auch der zunehmenden Wirkung des zweiten semantischen Inhaltsnetzes Rechnung trägt.
Unten sehen Sie die wechselnden Grafiken der IstanbulBogazici Enstitusu auf GSC für die letzten 12 Monate. Das Projekt wurde im Mai 2021 ordnungsgemäß gestartet und endete im September 2021 mit der Veröffentlichung von zwei Semantic Content Networks.
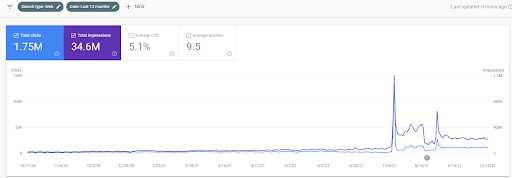
Unten sehen Sie die ausführlichere Version. Von 1400 täglichen Klicks bis zu 140000 Klicks und dann regelmäßig 10.000+ Klicks pro Tag können innerhalb der Leistung der organischen Suche gesehen werden
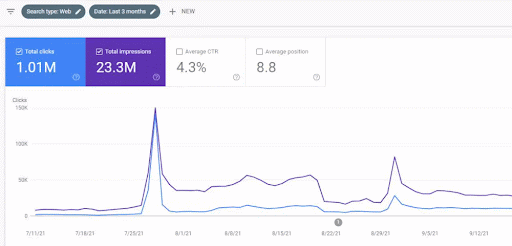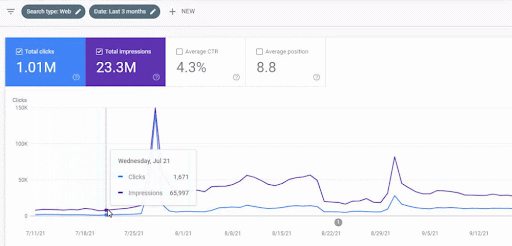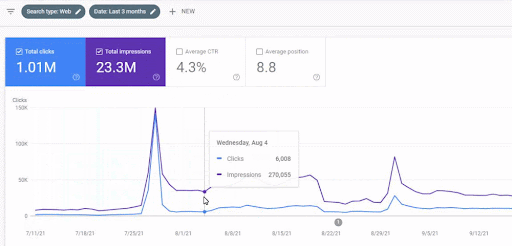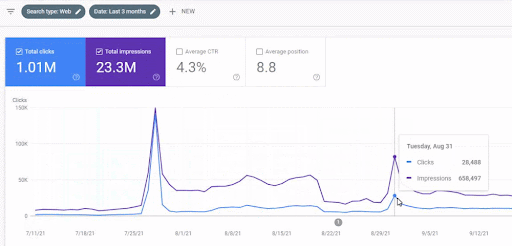
Die Verkehrszunahme des ersten Content-Werbenetzwerks nach dem Start ist unten zu sehen.
Dieser Screenshot zeigt den 4. Monat des First Semantic Content Network.
Wie Sie der Grafik entnehmen können, wurde der gesamte Datenverkehr der gesamten Website vom First Semantic Content Network dominiert und beeinflusst, das sich auf die „Bildungszweige“ konzentriert. Das zweite Content-Werbenetzwerk, das ich mit dieser Website gestartet habe, ist unten in der Google Search Console zu sehen. Der folgende Screenshot stammt vom 16. Tag des zweiten semantischen Content-Netzwerks.
Das anfängliche Ranking und das Re-Ranking wurden in diesem Artikel verwendet, da sie die Phasen der Ranking-Algorithmen zusammen mit ihren Typen und Zwecken vor dem Testen einer Quelle und einer Webseite aus der Quelle innerhalb der SERP für wichtigere Suchanfragen mit Popularität definieren .
Worauf konzentriert sich das erste semantische Inhaltsnetzwerk des ersten Projekts?
„Semantic Content Network“ verwendet ein semantisches Netzwerk aus einer Wissensbasis, um die Haupt-, Sekundär- und Tertiärbeziehungen zwischen den Dingen innerhalb der Wissensbasis zu erklären. Daher erfordert das Erstellen eines semantischen Inhaltsnetzwerks das Entwerfen des nächsten semantischen Inhaltsnetzwerks basierend auf dem Kontext der Quelle, der die Hauptfunktion der Website ist. In diesem Zusammenhang hat sich das erste semantische Inhaltsnetzwerk auf „Universitätsfakultäten, Bildungszweige und die Notwendigkeiten für eine Universitätsausbildung innerhalb einer bestimmten Organisation und Branche“ konzentriert.
Unten finden Sie die Ahrefs-Grafik des First Semantic Content Network.
Dies ist fünf Tage später als der vorherige Screenshot.
„Root: istanbulbogazicienstitu.com/bolum“, nach der ersten ersten Ranking-Phase ist der Re-Ranking-Prozess effizienter und produktiver.
Sie können die vier Tage spätere Version wie unten sehen, um die Art der „Neubewertung“ zu unterstützen.
Worauf konzentriert sich das zweite semantische Inhaltsnetzwerk des ersten Projekts?
Das zweite semantische Inhaltsnetzwerk hat sich auf die Berufe, Jobs, Fähigkeiten und die notwendige Ausbildung für diese Fähigkeiten oder Routine konzentriert. Basierend auf dem ersten semantischen Inhaltsnetzwerk wurde das zweite semantische Inhaltsnetzwerk unterstützt. Und gemäß den „Abfragevorlagen-Intent-Vorlagen“ werden zwei weitere unterschiedliche semantische Sub-Content-Netzwerke erstellt und mit den „relationalen Verbindungen“ platziert, während sie mit den oberen ähnlichen hierarchischen Ebenen verbunden sind.
Ich weiß, dass diese Abschnitte für Sie kompliziert sind, weil Sie noch keine Definition für die folgenden Dinge gesehen haben.
- Semantisches Inhaltsnetzwerk
- Quellkontext
- Semantisches Sub-Content-Netzwerk
- Wissensbasis
- Relationale Verbindungen
- Erstes Ranking
- Neubewertung
- Kontextbezogene Berichterstattung
- Vergleichsrangliste
- Faktenextraktion
Nachdem Sie die zweite Website erklärt haben, wird es einfacher sein, diese Konzepte und Sätze zu verstehen.
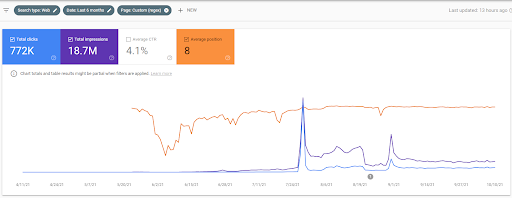
Vizem.net: Von 0 auf 9.000+ tägliche Klicks pro Tag in 6 Monaten – Gehebeltes Vergleichsranking mit kontextbezogener Abdeckung
Sie können die Grafik von Vizem.net für die letzten 12 Monate sehen. Bei diesem Projekt hatten wir aufgrund von Covid-19 viele wirtschaftliche Probleme, da der Investor aus der Fitnessstudiobranche stammt. Daher kann ich sagen, dass die wirtschaftlichen Probleme das Projekt verlangsamt haben und eine gewisse Latenz für die „Re-Ranking-Prozesse“ verursacht haben.
Um das anfängliche Ranking zu verstehen und etwas weiter zu re-ranken, können Sie die folgende Grafik verwenden.
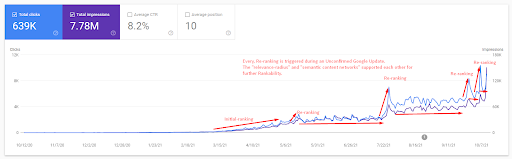
Einige der Definitionen in Bezug auf das anfängliche Ranking und das Re-Ranking aus der obigen Grafik finden Sie unten.
- Die großen Ranking-Sprünge geschahen während der unbestätigten Google-Updates. Einige Tests ergaben Featured Snippets, und Leute stellten auch Fragen.
- Einige Tests von Google entfernten die FS- und PAA-Einnahmen.
- Jedes Mal war die Zeitspanne zwischen zwei Neubewertungsprozessen kürzer.
- Die Re-Ranking-Prozesse verbesserten jedes Mal die Rankability der Quelle.
- Die Quelle hat ihren Relevanzradius immer weiter verbessert und gleichzeitig die Anfragecluster erweitert.
Als Anmerkung kann ich unten einen Satz hinterlassen.
Wenn eine Suchmaschine Ihre Webseite indexiert, bedeutet das nicht, dass die Suchmaschine die Webseite verstanden hat. Die Indizierung erfolgt schneller als das Verstehen, und meistens ordnet eine Suchmaschine eine Webseite mit Vorhersagen „zunächst“. Nach dem Verstehen erfolgt das „Re-Ranking“. 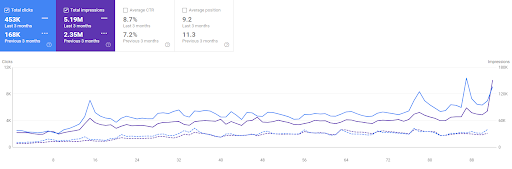
Der Vergleich der letzten 3 Monate des Vizem.net
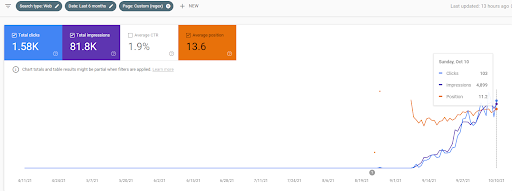
Wie ist das Semantic Content Network von Vizem.net?
Ich erinnere mich, dass ich vielen meiner Kunden, Freunde oder geheimen SEO-Gruppen während der Meetings diese beiden Websites demonstriert habe, indem ich sagte: „Sie werden explodieren“. Und während ich diesen Artikel schreibe, sage ich Ihnen Folgendes:
Sehen Sie sich das Semantic Content Network „istanbulbogazicienstitu.com/meslek“ an, denn es wird explodieren. Und Sie können ein Video finden, das ich vor dem Schreiben dieses Artikels veröffentlicht habe, während es die „Historischen Daten“ eines saisonalen Ereignisses und seine Auswirkungen auf die Erst- und Neubewertungsprozesse demonstriert. Sie können es unten sehen.
Auf dieser Grundlage ist das Semantic Content Network von Vizem.net dem IstanbulBogazici Enstitusu nicht ähnlich, daher habe ich kein „intensives Maß an thematischer Abdeckung und Erhöhung historischer Daten“ verwendet, ich musste die Autorität in Bezug auf das Bestimmte schaffen Arten von Entitäten, ihre Attribute und mögliche Aktionen hinter den Abfragen für diese Entitäts-Attribut-Paare. Vizem.net hat nicht nur „Bildungsuniversitätszweige“ oder die „Berufe und Online-Kurse“ darin. Es hat „Länder für Visumanträge“. Daher erfordert die Schaffung eines ausreichenden Niveaus an Topical Authority Konsistenz im Laufe der Zeit mit mindestens 190 verschiedenen semantischen Inhaltsnetzwerken.
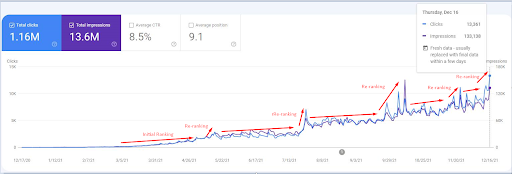
Ein Screenshot vom 18. Dezember 2021. Sie können die kontinuierliche Neubewertung und Steigerung der Impressionen und der Klicks sehen. Dies ist 4 Wochen später als im vorherigen Screenshot.
Um die Re-Ranking-Ereignisse zu sehen, können Sie die nackte Version der organischen Suchleistungsgrafik vergleichen, die den Effekt der semantischen SEO demonstriert. 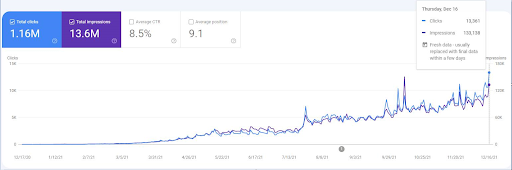
Diese 190 verschiedenen semantischen Inhaltsnetzwerke werden basierend auf dem „Land“ selbst geformt, und die Länder werden mit jeder möglichen kontextuellen Ebene in die Mitte der thematischen Karte gestellt, um die Abdeckung der Suchaktivitäten zu verbessern.
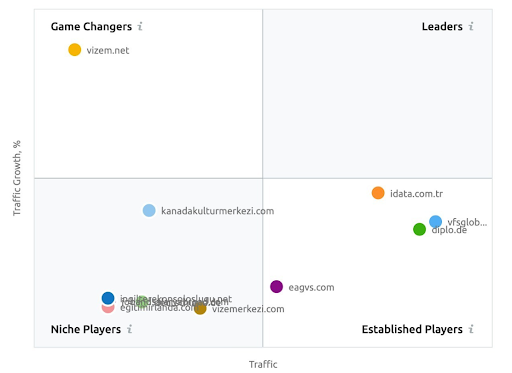
Ein Screenshot von SEMRush, der ihre Wahrnehmung für das Vizem.net im Gegensatz zu anderen Branchenakteuren zeigt.
Ich habe auch ein weiteres Video veröffentlicht, nur für Vizem.net. In diesem Video ist die letzte Situation der Website nicht vorhanden, daher bietet es meiner Meinung nach auch einen schönen Vergleich zwischen heute und damals.
Schließlich kann die Veröffentlichung irrelevanter Dinge innerhalb eines irrelevanten Artikels, Website-Segments oder einer irrelevanten Quelle die Gesamtrelevanz der Web-Entität für den spezifischen Wissensbereich verringern. Vizem.net wird seinen wahren Wert zeigen, und die Rankability in der Zukunft wird viel besser sein.
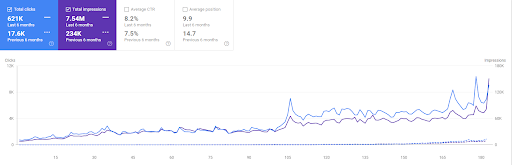
Der Vergleich der letzten 6 Monate von Vizem.net.
Bevor ich fortfahre, weiß ich, dass dies ein langer Artikel ist. Aber eigentlich ist dies eine kurze Erklärung einer hochkomplexen SEO-Methodik. Semantische Inhaltsnetzwerke erfordern zu viel Nachdenken bei der Gestaltung und monatelange Schulungen für Kunden, Autoren und das Onboarding. Daher möchte ich mich in diesem Artikel auf die Definitionen der Konzepte mit den bestmöglich ausführbaren kurzen Vorschlägen und wichtigen Patenten von Google und anderen Suchmaschinen, Forschungsarbeiten zusammen mit ihren eigenen Konzepten konzentrieren. In der langen Version (im Grunde ein Buch) habe ich mich auf „Anfangsranking“ und „Neuranking“ von semantischen Inhaltsnetzwerken konzentriert.
Wenn Sie mehr erfahren möchten, lesen Sie den Abschnitt „Bedeutung des anfänglichen Rankings und des Re-Rankings für SEO“.
Bisher haben wir die folgenden Dinge verarbeitet.
- Semantisches Netzwerk
- Wissensbasis
- Semantisches Inhaltsnetzwerk
- Wissensbasiertes Vertrauen
- Kontextbezogene Berichterstattung
- Kontextbezogene Domäne und Schichten
- Die Relevanz von MuM für die semantischen Inhaltsnetzwerke
- Kontext der Quelle
Diese Konzepte sollen verstehen, wie semantische Inhaltsnetzwerke funktionieren und wie sie mit einer thematischen Karte verwendet werden können. In den nächsten Abschnitten geht es darum, wie eine Suchmaschine zunächst semantische Inhaltsnetzwerke einstuft und später modifiziert. In diesem Zusammenhang werden folgende Dinge verarbeitet.
- Erstes Ranking
- Neubewertung
- Abfragevorlage
- Dokumentvorlage
- Suchabsichtsvorlage
- Was Sie tun sollten, um Semantic Content Networks zu nutzen
Was ist das anfängliche Ranking für SEO?
Dies ist ein neuer Begriff und Konzept für SEO, aber ein altes für Suchmaschinen. Die Langversion der „Semantic Network Focused SEO Case Study“ konzentriert sich auf die Ranking-Algorithmen basierend auf abfrageabhängigen, dokumentenabhängigen, quellenabhängigen Algorithmen und mehreren Patenten. Predictive Information Retrieval oder Predictive Ranking-Algorithmen versuchen, die Rechenkosten zu senken. Und selbst wenn die Indexierung an einem Tag erfolgt, kann das Verstehen eines Dokuments Monate oder sogar Jahre dauern. Die Berechnung eines anfänglichen Rankings ist daher eine Möglichkeit, die SERP-Qualität zu verbessern und gleichzeitig die Kosten zu senken. Einige Aufgaben im Zusammenhang mit Suchmaschinen haben eine höhere Priorität als andere, um den Index lebendig, aktuell und von ausreichend hoher Qualität zu halten.

Der Begriff „Initial-Ranking“ taucht in Zehntausenden verschiedener Google-Patente und Forschungsarbeiten auf, weil er eine klassische Perspektive unter den Suchmaschinenbauern ist. Daher sehen Sie oben verschiedene Patentdokumente mit Fortsetzung der gleichen Absätze und Begriffe mit geringfügigen Änderungen rund um den Begriff in der Anfangsrangfolge.
Das anfängliche Ranking repräsentiert den Rang eines Dokuments auf der SERP unmittelbar nach der Indexierung. Das anfängliche Ranking eines Dokuments repräsentiert die allgemeine Autorität und Relevanz der Quelle für das spezifische Thema, die Abfragevorlage und die Suchabsicht. Derselbe Inhalt kann in Bezug auf das anfängliche Ranking zwischen verschiedenen Quellen unterschiedlich eingestuft werden. Das anfängliche Ranking ist bei der Verwendung von Semantic Content Networks wichtig, um die allgemeine Qualitäts- und Autoritätssteigerung der Quelle zu sehen. Jedes neue Dokument erhöht sein anfängliches Ranking und verringert gleichzeitig die Indizierungsverzögerung, wenn das Design des semantischen Inhaltsnetzwerks richtig strukturiert ist.
Das initiale Ranking unterstützt den Re-Ranking-Prozess und dessen Effizienz für die Quelle. Und „Rangfähigkeit einer Quelle“ sollte mit diesen beiden Begriffen verarbeitet werden, initial und re-ranking.
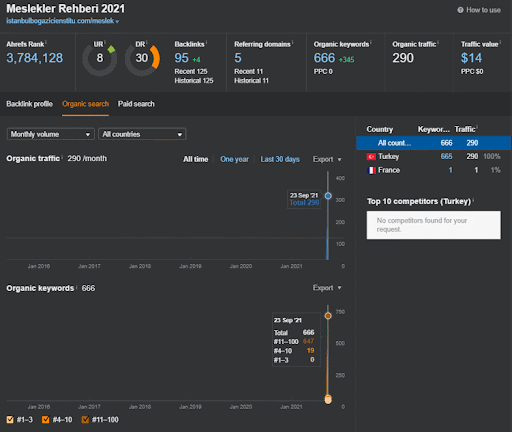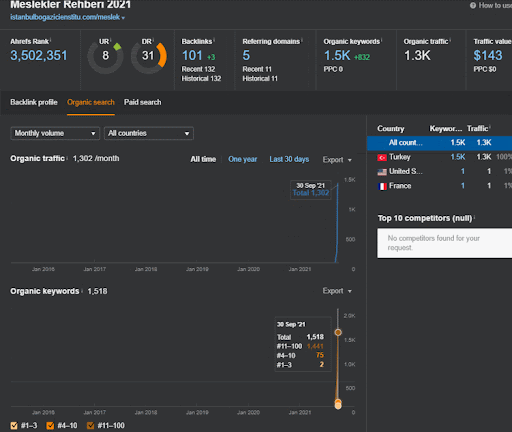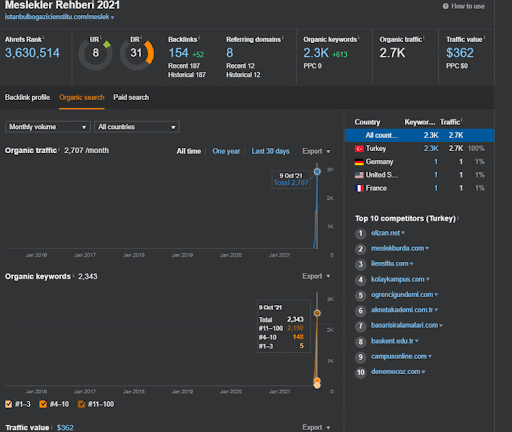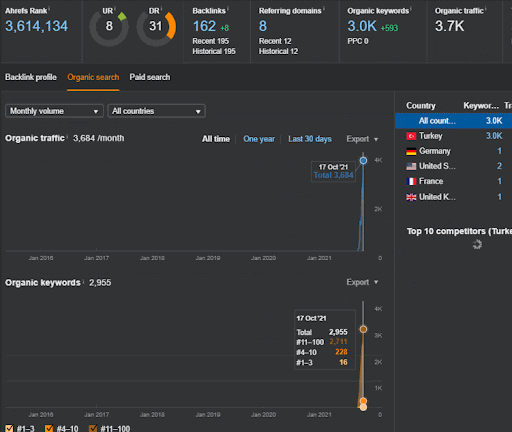
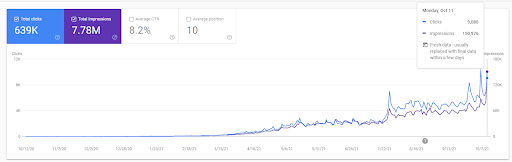
Sie können sich die ersten 20 Tage der organischen Leistungsänderung des zweiten Content-Werbenetzwerks von Projekt I ansehen.
Wann immer Vizem.net ein neues Dokument veröffentlicht oder wenn das IstanbulBogazici Enstitu ein neues semantisches Inhaltsnetzwerk veröffentlicht, ist das anfängliche Ranking in diesem Zusammenhang besser als zuvor, während der Inhalt schneller indexiert wird.
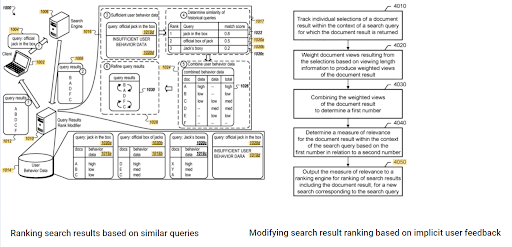
Die Bedeutung des anfänglichen Rankings und der historischen Daten ist zwischen diesen beiden komplementären Google-Patenten zu sehen. Einer ist für die Erst- und Neubewertung von Dokumenten basierend auf dem impliziten Benutzer-Feedback. The other one is for doing the same if enough level of user data doesn't exist, based on the similar queries. The similar queries are also the point that relate the Semantics. Creating a Semantic Content Network will decrease the energy for reading the mind of the website owner from the search engine's point of view.
What is Re-ranking for SEO?
The re-ranking is the process of changing a document's ranking on the SERP based on the feedback of the users, or relevance, and quality evaluation algorithms. Re-ranking frequency can signal an algorithm update, or an update on the document, or a site-wide update for a source. Re-ranking is affected by the historical data which is explained in the previous SEO Case Study that focuses on the Topical Authority. Examining the re-ranking processes and the feedback from the search engines help for the configuration of the semantic content network design. Re-ranking timelines can be shortened with the help of the actual traffic, as well as with historical data if the contextual and topical coverage is improved.
The re-ranking processes are affected by the initial ranking and the quality of the neighborhood content. The neighborhood content will affect the ranking of any strongly connected components. Re-ranking processes can signal the weak spots, and the ability of the search engine to understand certain sections of the semantic content network. If the design is correctly created, the semantic content network will continue to rise and rise in terms of organic search performance over time, and any Google Updates will confirm these processes.
Below, you can see the comparison of the Semantic Content Network 1 and Semantic Content Network 2 of the IstanbulBogazici Enstitu in terms of the initial and re-ranking. 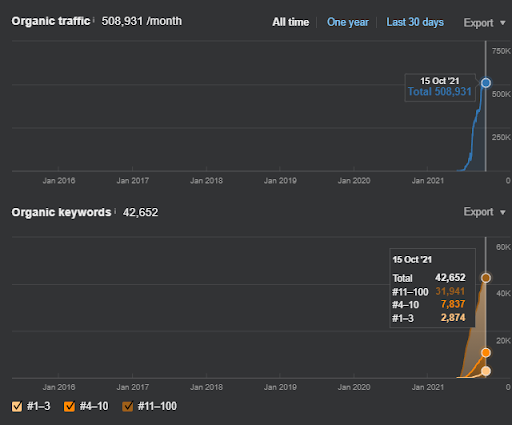
15 October 2021, performance of the first semantic content network of the IstanbulBogaziciEnstitusu which is the 124th day of the launch. 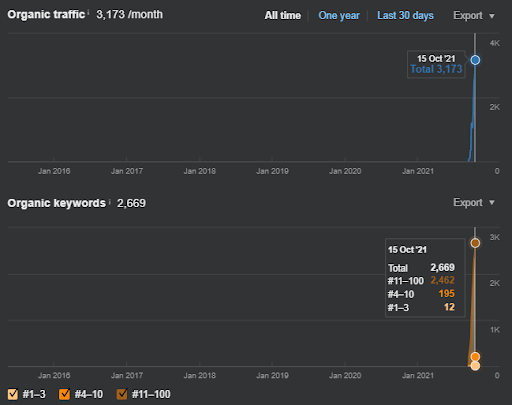
15 October 2021, performance of the Second Semantic Content Network of IstanbulBogazici Enstitu which is the 19th day of the launch. 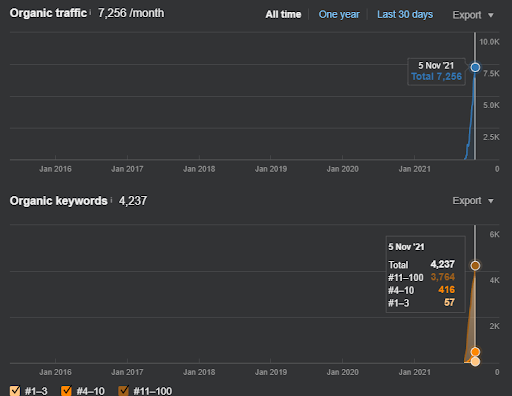
As you see, the second content network increases the organic query count and the rankings much faster than the first one. The Semantic Content Network 1 has the benefit of the “seasonal SEO” which gives enough level of historical data in a positive way. If there is a seasonal SEO event, the search engine will re-rank the pages, and assign the new relevance-radius and search activity coverage scores to the documents and the sources. Thus, I have chosen to use a “sudden launch” for the “university branches” first. It was the first step of the Topical Authority Building which is equal to the “historical data * topical coverage”. 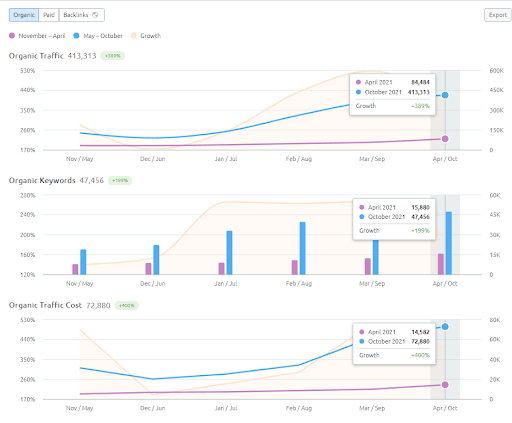
The 6 Months of Growth Comparison of the IstanbulBogazici Enstitu from SEMRush.
Note: To compensate for weaknesses in the execution, I designed a Semantic Content Network 3 to unite the first two using conceptual connections by providing the source's context. If I launched it, you would see that the source would acquire more than 1,2M organic traffic based on the Ahrefs graphic, in reality, it can be more than 2M. You can see my prediction's validity from the performance of the Second Content Network. Whenever you check it, you will see that it has thousands of new queries with higher rankings.
In the first Semantic Content Network, the first 3 ranking queries appeared after 2 months' for the second one, they appeared on the 15th day. You can imagine the increase in authority. Since the knowledge base of the website is left partially incomplete, after the source loses its momentum for semantic network completion, the search engine can prioritize other sources, and it can decrease the re-ranking positivity along with the relevance-radius and Rankability.
Implementing Semantic Networks on these sites makes use of a few concepts and “templates” used by search engines. Before I tell you about the method for setting up a Semantic Network, you should also understand what these templates are and how they work. This will help you understand how search patterns and document structure impact ranking, and therefore why the method I used in this case study is so effective.

The Initial Ranking, and Re-ranking are two different ranking algorithm types for a search engine based on timing. Search engines have other types of ranking algorithms such as query-dependent, query-independent, content-based, link-based, usage-based. To be able to understand the ranking systems, and clustering-associating technology of the search engines, the query-document-intent templates, and their relation to each other should be understood.
Oncrawl-Daten³
 Mehr erfahren
Mehr erfahrenWhat is a query template?
A query template represents a search pattern with ordered phrases that cover an entity for seeking factual information. A query template can have a question format, a proposition format, or an order of word types such as one adjective and one noun. A query template is useful for generating seed and synthetic queries from the point of view of a search engine. A seed query can help a search engine to choose centroids for the query clusters while helping the clustering web page documents, their types, and possible search activities for them. 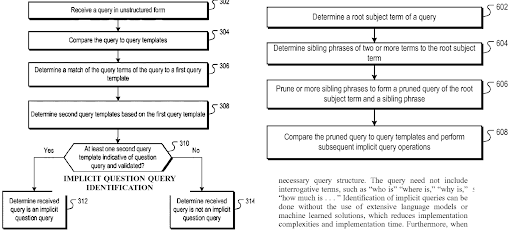
Another Google Patent about “Implicit Question Query Identification” which Nitin Gupta invented along with Steven Baker. “Implicit Question Query Identification” is also related to the question generation which is connected to the “K2Q System”.
In this context, a query template can be used for feeding the search engines' historical data for creating trust. Even if a search engine doesn't understand all aspects of a query, or a document for it, still some certain sources can be ranked earlier and better than others because of the document templates. If a source satisfies queries from a template, the search engine will rank the specific source for these types of queries from the same template better initially and during the re-ranking processes. Thus, on the web, we have sources that only focus on a single vertical with a single query template, like Wikihow, or GiftIdeas. 
“Query Suggestion Templates” is one of the documents that explains how a search engine can generate query templates based on query logs. Since, Nitin Gupta is one of the inventors of this patent, it has more value for me.
A query template can be used for creating a successful semantic content network, but in page contextual domains, and connections should be configured properly for connecting multiple semantic content networks for multiple query templates.
Note: The topic Query Templates, Intent Templates and the Document Templates are closely related, and another SEO Case Study will be published to demonstrate further details about it. 
A section from the Representation Learning for Information Extraction
from Form-like Documents of Google for extracting information from templatic content.
What is a document template?
A document template can signal the purpose of a web page based on the design elements, or even the request size, count and types. If a web page has too much JS, it can be a js-dependent website, or the interactivity needs can be higher than others. This can be confirmed easily by just checking the event-listeners on the web page, or input types, and API endpoints. When it comes to thinking like a search engine, remember that the web is a chaotic place. And, everything possible for understanding the users, especially if the users are Markovian , meaning that they are more influenced by the current page than their history of navigation. 
A section that explains how a search engine can use the document templates to see a user's interest area.
Did you know that Prabhakar Raghavan, the VP of Search on Google, also has a research that asks the same question? “Are Web Users Markovian?”. 
A section from the “Are web users Markovian?” research paper.
Ja, sind Sie. Probabilistic Ranking und Degraded Relevance Ranking sind die Hauptsäulen einer semantischen Suchmaschine, um die Benutzer zu verstehen und das bestmögliche SERP von höchster Qualität zu erstellen, das auf Zustände der Möglichkeiten vorbereitet ist. 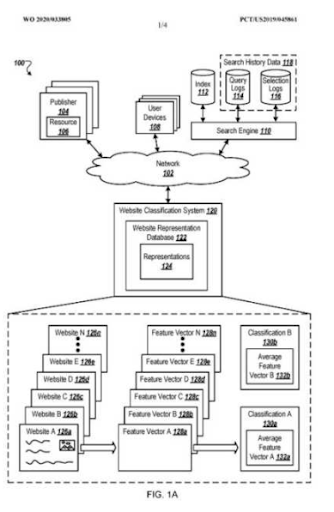
Um „das Website-Design und Aussehen oder die Tonalität“ zu einem Argument für das Repräsentationslernen für Websites zu machen, hat Bill Slawski zuvor die „Website Representation Vectors“ geschrieben.
Was ist eine Suchabsichtsvorlage?
Eine Suchabsichtsvorlage kann durch die Notwendigkeit hinter der Abfragevorlage dargestellt werden. Eine Abfragedokumentvorlage kann basierend auf einer Absichtsvorlage vereint werden. Eine Suchabsichtsvorlage mit möglichem „Degraded Relevance Ranking“ und „Probabilistic Ranking“-Verständnis hilft dabei, die bestmögliche Suchaktivität und Suchabsichtsabdeckung mit der richtigen Reihenfolge zu erstellen. Beim Erstellen eines semantischen Inhaltsnetzwerks ist das Wichtigste, die Dokumentabfrageabsichtsvorlage basierend auf dem Kontext der Quelle anzupassen, um ein semantisches Netzwerk basierend auf einer Wissensdomäne zu vervollständigen, indem die kontextbezogene Abdeckung verbessert wird, um das wissensbasierte Vertrauen und die thematische Autorität zu verbessern . 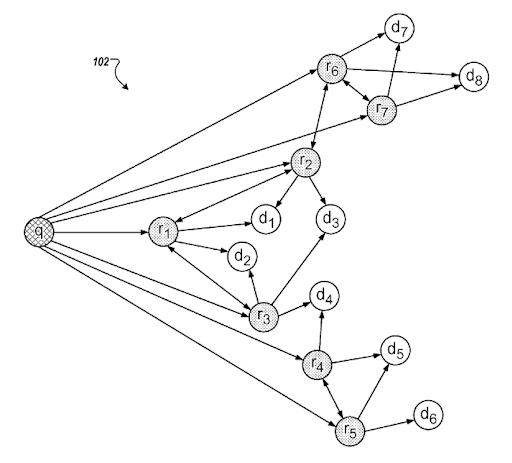
Ein Abschnitt aus Googles „Query Refinements based on Inferred Intent“. Es funktioniert über Abfragecluster und Absichtsvorlagen mit semantischen Verbindungen. Sie können es auf verschiedenen Ebenen der Ausdruckstaxonomie erleben.
Bevor ich zu einigen konkreten Beispielen und Vorschlägen übergehe, die Ihnen helfen, ein besseres semantisches Inhaltsnetzwerk zu erstellen, muss ich Ihnen sagen, dass selbst die einfache Version dieser SEO-Fallstudie ein hohes Maß an Suchmaschinenverständnis und Kommunikationsfähigkeiten erfordert. Obwohl ich das Gefühl habe, Informationen auf hohem Niveau zu geben, weiß ich, dass der Semantische SEO-Kurs, den ich erstellen werde, Ihnen einige weitere und bessere konkrete Beispiele zeigen wird. 
Dasselbe Patent erklärt die richtigen Verbindungen zwischen verschiedenen „Abfragepfaden“ und „Kontextverschiebungen“.
Was Sie über die Nutzung semantischer Inhaltsnetzwerke wissen sollten
Um ein semantisches Inhaltsnetzwerk zu erstellen, kann manchmal sogar ein einfaches semantisches Inhalts-Briefing und -Design eine Stunde dauern, wenn Sie alle relevanten Details auf der Grundlage der lexikalischen Semantik oder der Beziehungstypen zwischen Entitäten und Phrasen angeben. Die gleichzeitige Verwendung mehrerer Blickwinkel, wie z. B. die phrasenbasierte Indexierung, und die Wortvektoren oder Kontextvektoren zum Berechnen der kontextuellen Relevanz eines Inhalts insgesamt für eine kontextbezogene Domäne oder seiner Relevanz basierend auf den einzelnen Unterinhaltstypen, it erfordert ein hohes Maß an semantischem Suchmaschinenverständnis.
Daher wird die Verwendung einer generativen Methodik mit den Konzepten, die ich Ihnen oben erklärt habe, alles einfacher machen, denn selbst wenn Sie jeden Teil des semantischen Inhaltsnetzwerks perfekt vorbereiten, werden die Autoren und Schreiber nicht in der Lage sein, es zu schreiben, oder die Inhaltsmanager wird deiner Vision nicht folgen können. Daher könnte es Sie umsonst ermüden und Sie dazu bringen, ein Projekt zu verlassen, wie ich es bei einigen dieser SEO-Fallstudienprojekte getan habe, nachdem ich das Konzept auf eine ausreichend lebendige und überprüfbare Weise bewiesen habe.
Die folgenden Vorschläge sind nur für einfach ausführbare und kurze Schritte, die Ihnen helfen werden.
1. Verwenden Sie keine festen Sidebar-Links aus allen Semantic Content Network-Netzen
Jeder Link sollte eine Verbindungsbeschreibung zwischen zwei Hypertext-Dokumenten haben, wie jedes Wort innerhalb einer Webseite. Die semantische HTML-Nutzung kann dabei helfen, die Position und Funktion eines Dokuments auf einer Webseite zu spezifizieren und Suchmaschinen helfen, die Abschnitte inhaltlich unterschiedlich zu gewichten.
Im Vizem.net-Beispiel habe ich nicht das gleiche Design der Seitenleiste verwendet. Die Seitenleiste zeigte nicht die neuesten Beiträge oder die kritischsten. Die Seitenleisten zeigen nur die Attribute der zentralen Entitäten, und sie sind nicht festgelegt, sie sind dynamisch. Mit anderen Worten, basierend auf der Hierarchie innerhalb der thematischen Karte ändern sich die Netze des semantischen Inhaltsnetzwerks, selbst wenn sie sich in der Seitenleiste befinden. 
Das Nachdenken über die vernünftigen Surfer- und vorsichtigen Surfer-Modelle kann einem SEO helfen, eine bessere Relevanz zwischen verschiedenen Hypertext-Dokumenten zu schaffen.
Darüber hinaus fließt der Link in Bezug auf die Bekanntheit, und die Popularität sollte dem Kontext der Quelle aus den bestmöglichen Verbindungen folgen. Unten sehen Sie die Seitenleistenabschnitte mit angepassten semantischen HTML-Codes. 
Entsprechend der Hierarchie des Artikels, der in der Sitzung des Benutzers aktiv ist, ändern sich die Registerkarten, die Reihenfolge der Registerkarten und die Links innerhalb der Registerkarten. Das obige Beispiel stammt aus der Breadcrumb-Hierarchie unten. ![]()
2. Unterstützen Sie die Semantic Content Networks mit PageRank
Auch wenn der externe PageRank aus den externen Quellen kein Muss ist, werden Sie feststellen, dass das anfängliche Ranking und das Re-Ranking besser sind, wenn Sie ihn verwenden können. Für diese beiden Projekte habe ich sie nicht verwendet, aber diesmal war es nicht der Zweck. Für Vizem.net gab es wirtschaftliche Probleme, und ich wollte das Budget nicht für digitale PR und Öffentlichkeitsarbeit ausgeben. Für Istanbul BogaziciEnstitusu habe ich ein paar „lokal miteinander verbundene Quellen“ arrangiert, um die Authentizität der Quelle für das spezifische Thema zu unterstützen, aber auch hier konnte das Unternehmen dies aufgrund von Problemen mit dem Budget und der organisatorischen Disziplin nicht umsetzen. 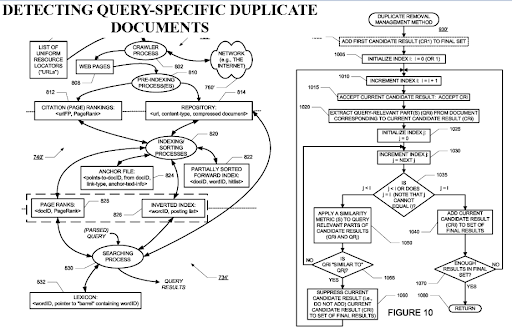
Das Erkennen von abfragespezifischen doppelten Dokumenten ist eine wichtige Perspektive von Suchmaschinen, da der PageRank dazu beitragen kann, dass ein Dokument als wertvoll gefiltert wird, selbst wenn es dupliziert ist. Da die hoch organisierten semantischen Inhaltsnetzwerke einander ähnlich sein können, sind der PageRank-Fluss und historische Daten nützlich.
Wenn es darum geht, den externen PageRank-Flusspunkt für diese Art von semantischen Inhaltsnetzwerken auszuwählen, verwenden Sie die Quellen mit historischen Daten. In meinem Fall hatte ich diese PageRank-Endpunkte früher eingerichtet, bevor ich das erste semantische Inhaltsnetzwerk gestartet und veröffentlicht hatte. So konnte ich externe Referenzen von direkten Konkurrenten übernehmen, aber als ich das Semantic Content Network veröffentlichte, gaben die Konkurrenten die Verlinkung der Quelle auf, weil sie den Massenzuwachs der Quelle als Konkurrenten gesehen haben.
Diese Situation bringt uns zum dritten Vorschlag. Wenn wir in der Lage wären, den PageRank-Fluss von externen Referenzen zu verwenden, wäre der Prozess des Neurankings schneller und das anfängliche Ranking wäre höher.
3. Verwenden Sie unterschiedliche Ankertexte aus Fußzeile, Kopfzeile und Hauptinhalt für die prominenten Teile des semantischen Inhaltsnetzwerks
Ankertexte oder der „Linktext“ aus Sicht der Suchmaschine signalisieren die Relevanz eines Hypertext-Dokuments für ein anderes. Laut dem Originaldokument des PageRank ist die Linkanzahl proportional zum PageRank-Fluss. Später änderte Google dies jedoch, um „Link Stuffing“ zu verhindern, und beschränkte die Links, die den PageRank tatsächlich weitergeben können. Darauf aufbauend werden der TrustRank, Cautious Surfer, Hilltop Algorithm oder die Reasonable Surfer Models entwickelt. 
Dies sind zwei Links zu den zwei verschiedenen semantischen Inhaltsnetzwerken für das BogaziciEnstitusu, aber da ich keine technischen SEO- oder UX-Verbesserungen implementiert habe, können Sie die „Billigkeit“ der Schaltflächendesigns erkennen.
Laut Google kann derselbe Link den PageRank kein zweites Mal an eine andere Webseite weitergeben, während der PageRank nur vom ersten Link weitergegeben wird. Und in der ursprünglichen Form des PageRank-Algorithmus kann ein Hypertext-Dokument sich selbst verlinken, um seinen PageRank zu verbessern, oder 301-Weiterleitungen können verwendet werden, um den PageRank des Link-Zieldokuments zu übernehmen. Beide Situationen haben alte Black-Hat-Techniken hervorgebracht, wie z. B. das vorübergehende Umleiten einer Webseite auf eine andere, nur um ihren PageRank zu nehmen. Dies war aus den Tagen, als die SEOs den PageRank einer Webseite von der Google Search Console oder dem SERP sehen konnten. Später fing Google an, den PageRank mit jeder Weiterleitung zu dämpfen, während Danny Sullivan erklärte, dass 301-Weiterleitungen den PageRank vollständig passieren würden. Neben all diesen Änderungen ist hier wichtig, dass auch wenn der zweite Link den PageRank nicht übergibt, so doch die Relevanz des Linktextes. 
Prominente Abschnitte des semantischen Inhaltsnetzwerks wurden von der HomePage aus verlinkt, basierend auf den „mittleren Abfrageverfeinerungen“, die die „Verben, Prädikate“ oder „Sucheraktivitäten“ beinhalten.
So sollten die prominenten Abschnitte des Semantic Content Network aus dem Kopf- und Fußzeilenmenü mit den höheren Taxonomieabschnitten verlinkt werden, und die Linktexte sollten sich voneinander unterscheiden. In diesen Beispielen habe ich die Header-Links mit den markanten, aber kurzen Linktexten verwendet, während ich die Footer-Beispiele länger belassen habe. 
Ein Abschnitt der „Anker-Tag-Indizierung in einem Web-Crawler-System“ fasst die Bedeutung eines Ankertexts und Anmerkungstexts zusammen, um eine Webseite innerhalb der Abfrage-Cluster und Webseiten-Cluster zu positionieren.
Wenn der Abschnitt Semantic Content Network zu prominent ist, um den PageRank und die Crawl-Priorität richtig weiterzugeben, habe ich die wichtigsten Abschnitte mit richtigen Linktexten und erklärenden Absätzen verlinkt, die die prominenten Attribute mit verschiedenen Variationen relevanter N-Grams enthalten. 
Dies ist der zweite verlinkte Bereich von der Homepage des Vizem.net, er befindet sich hinter einer Ziehharmonika, konzentriert sich auf die Länder innerhalb der Abfragen und verlinkt den mittleren Bereich des semantischen Inhaltsnetzwerks.
Hinweis: Um die Ankertexte herum wurde immer ein geplanter „Anmerkungstext“ verwendet, um die Genauigkeit des Zwecks des Links zu verbessern.
4. Begrenzen Sie die Beschränkung der Linkanzahl und passen Sie die Desktop- und mobilen Links und den Hauptinhalt an
Beide Projekte sind auf weniger als 150 interne Links pro Webseite beschränkt. Mit Hilfe von Semantic HTML werden den Crawlern die Orte der Links und Funktionen der Links klar gemacht. Das IstanbulBogazici Enstitusu hatte mehr als 450 Links pro Webseite, und einige davon waren Selbstlinks (ein Link von derselben Seite zu derselben Seite). Das Schlimmste ist, dass die Hälfte dieser Links in der mobilen Version des Inhalts nicht vorhanden war. 
URL Keep Score, Crawl Score und andere Arten von Scores können verwendet werden, um die Hervorhebung eines Links innerhalb der internen URL-Map zu bestimmen, und Dokumentidentifikations-Tags innerhalb der verschiedenen Ebenen können verwendet werden, um den Index basierend auf abfrageunabhängigen Relevanzscores zu sortieren.
Da Google nur die mobile Indexierung verwendet, werden Inhalte, die nicht in der mobilen Version vorhanden sind, ignoriert und nicht für Relevanzbewertungs- und Rankingzwecke verwendet. Daher wurden die mobilen und Desktop-Inhalte so konfiguriert, dass sie aufeinander abgestimmt sind. Selbst wenn Google die inhaltlichen Diskrepanzen zwischen der Desktop- und der mobilen Version toleriert, erschwert es den Suchmaschinen dennoch das Verständnis und das Ranking einer Webseite. 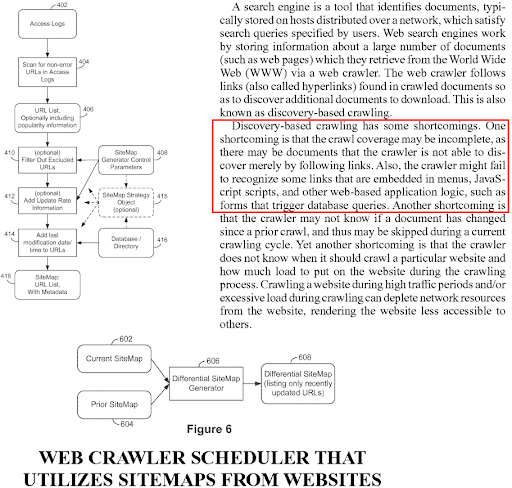
Eine Suchmaschine kann eine Sitemap für die Website generieren, und diese Sitemap kann in einer Schleife neu generiert werden, wenn die Links und URL-Metadaten nicht zwischen Benutzeragenten oder Zeitleisten abgeglichen werden. Daher ist es wichtig, den Crawling-Pfad kurz, die Crawling-Warteschlange kurz und die internen Links konsistent zu halten.
Neben den Links zwischen verschiedenen Webseiten werden auch Links zu den Unterbereichen der Webseiten mit dem „Inhaltsverzeichnis“ und den „URL-Fragmenten“ verwendet. Diese URL-Fragmente zielen auf einen bestimmten Unterabschnitt der Webseite ab, während sie richtig benannt werden, und der bestimmte Abschnitt wurde in ein Abschnitts-Tag mit einem h2 eingefügt. Mit Hilfe von URL-Fragmenten mit den „In-Page-Navigationslinks“ war es einfacher, einen Benutzer von SERP zu einem bestimmten Abschnitt der Webseite zu führen, während die unteren Abschnitte des Inhalts hervorgehoben wurden, um die dahinter stehenden Anforderungen zu erfüllen Anfrage.
5. Haben Sie eine militärische Disziplin für Ihre SEO-Projekte
Dies ist ein ganz anderes Thema, und es kann ein weiterer Artikel geschrieben werden, um zu definieren, was die Disziplin auf militärischer Ebene bedeutet oder warum sie für ein SEO-Projekt nützlich ist. Aber ich muss Ihnen sagen, dass ich in den letzten 2 Monaten viele CEOs und SEOs von anderen Agenturen zusammen mit ihren Teams geschult habe, um zu sehen, ob mein Kursdesign gut funktioniert oder nicht.
Wann immer ich Erfolg sehe und ein hohes Maß an Verständnis für die von mir durchgeführten Schulungssitzungen, sind ein starker Wille und Ausdauer vorhanden. Das Hauptproblem ist, dass semantisches SEO viel schwieriger ist als die anderen SEO-Vertikalen. Technisches SEO ist universell und es gibt sogar schriftliche Anleitungen für jeden Schritt. Das OnPage-SEO oder WUX- und Layout-Design kann mit numerischen Messungen verfolgt werden. Wenn es um Semantik geht, ist es die Praxis, die Perspektive einer Maschine, die auf der Grundlage eines komplexen adaptiven Systems funktioniert, mit Homo-sapiens zu vereinen, die nicht verstehen, wie die Maschine funktioniert.
Diese Unterscheidung erfordert einen konkreten Untergrund, der vom ersten Tag des Projekts an gelegt werden sollte. Meistens verwende ich die folgenden Regeln.
- Die Inhaltsdesigns und das semantische Inhaltsnetzwerk müssen für einen Autor oder Schriftsteller nicht logisch sein.
- Die Aufgabe des Content Managers besteht darin, die Kompatibilität des Inhalts mit dem Inhaltsdesign zu prüfen.
- Die Aufgabe des Autors besteht darin, den Inhalt mit den zugehörigen Informationen zu schreiben, der ein hohes Maß an Genauigkeit und Detailgenauigkeit beinhaltet.
- Die Links, Definitionen, Beweise, Vergleiche, Vorschläge, Verweise sollten mit konkreten Beispielen gemacht werden, nicht mit Flusen.
- Jedes unnötige Wort verwässert den Kontext und das Konzept.
Wenn Sie lesen, klingt es vielleicht einfach umzusetzen, aber es ist nicht so einfach. Daher kann ich sagen, dass ich sogar kurz davor war, einige meiner eigenen Mitarbeiter zu entlassen. Ich bin froh, dass ich es zumindest vorerst nicht getan habe. Unter normalen Bedingungen werden Ihnen viele Fragen gestellt, wenn der Eigentümer der Frage kein SEO oder Eigentümer des Unternehmens ist, beantworten Sie sie nicht. Sparen Sie Ihre Energie auf den Datenspeicher der Suchmaschine, der Ihr positives Feedback speichert, nicht das redundante und irrelevante Feedback zu den Rankings.
6. Erweitern Sie die Quelle mit Kontextrelevanz
In diesem Abschnitt geht es ausschließlich darum, die Notwendigkeit von Google für die Erstellung des MuM zu verstehen. Wenn Sie eine thematische Karte entwerfen, enthält sie viele semantische Inhaltsnetzwerke, die eine bessere Wissensdatenbank auf Site-Ebene bieten. Während diese Unterabschnitte veröffentlicht werden, sollten sie also in der Lage sein, eine Verbindung zum Kontext der Quelle herzustellen, oder es kann sich ändern, wie die Suchmaschine die Quelle sieht, und das Thema der Website kann zu einem anderen Wissensbereich wechseln. Beispielsweise erfordert das Verbinden von Dingen rund um Konzepte und Interessenbereiche mit möglichen Aktionen das Verständnis komplizierter Bedeutungszusammenhänge untereinander. Diese Verbindungen einem Benutzer, einem Schreiber und auch einer Maschine gleichzeitig deutlich zu machen, ist der Prozess der Semantic Content Network-Erstellung. 
Um dies zu erreichen, sollte jeder neue Abschnitt für die Website mit dem zentralen Abschnitt der thematischen Karte verbunden werden können. Diese kontextabhängigen Brücken sind aus dem LaMDA-Design und der Erklärung von Google ersichtlich.
Ich stoße auf viele Fragen wie „soll ich über ein anderes Thema schreiben“, „wenn ich zwei verschiedene Nischen habe, schadet das?“. Wenn Sie all diese Unterabschnitte, Website-Segmente als stark verbundene Komponenten verbinden, unterstützen sich diese semantischen Content-Netzwerke gegenseitig für bessere Rankings, anstatt die Markenidentität und thematische Autorität für zwei verschiedene und irrelevante Themen aufzuteilen.
7. Erstellen Sie tatsächlichen Traffic und prüfen Sie ihn mit der benutzerdefinierten Segmentierung von Google Analytics
Tatsächlicher Traffic ist mit dem RankMerge auf die gleiche Weise verbunden, wie der wissensbasierte Trust mit dem PageRank verbunden ist. Bald denke ich darüber nach, einen weiteren Artikel mit dem Titel „When the PageRank Lies…“ zu schreiben, um zu erklären, warum die Suchmaschine versucht, den PageRank mit Nebensignalen zu beeinflussen. Tatsächlich ist der PageRank kein definitives Signal, das die Autorität, Expertise und Vertrauenswürdigkeit einer Quelle zeigt. Es kann ein Signal für das Ranking und ein Faktor sein, aber man kann ihm nicht allein vertrauen. RankMerge ist der Prozess, den Website-Traffic und den PageRank so zu vereinen, dass die Website für die Suchmaschine sinnvoll ist. Hoher PageRank und niedriger Traffic können auf „unbeliebten Traffic“ oder „PageRank-Manipulation“ hinweisen.
Um die historischen Daten der Quelle zu verbessern, habe ich daher die saisonalen SEO-Ereignisse verwendet und die Abfragen „Marke + Oberbegriff“ erhöht. Der direkte Verkehr und die mit Lesezeichen versehenen Webseiten werden durch tatsächlichen und authentischen Verkehr erhöht.
Diese Arten von Daten helfen einer Suchmaschine, ihr zu vertrauen, dass sie in den SERPs immer höher eingestuft werden.
Um diesen tatsächlichen Traffic aus dem Semantic Content Network prüfen zu können, kann ein SEO ein benutzerdefiniertes Segment aus Google Analytics erstellen, um zu sehen, wie er als direkter Traffic kommt. Außerdem können benutzerdefinierte Ziele erstellt werden, z. B. das Erstellen einer möglichen Suchreise vom ersten semantischen Inhaltsnetzwerk zum zweiten Inhaltsnetzwerk. Dies ist der Proof of Concept, dass das semantische Netzwerk um die Interessen, Konzepte und möglichen suchbezogenen Aktionen herum aufgebaut ist.
Nachfolgend finden Sie nur ein Beispiel für eine der Webseiten, die im ersten Semantic Content Network platziert sind, um den gewonnenen direkten Traffic über organischen Traffic zu demonstrieren. 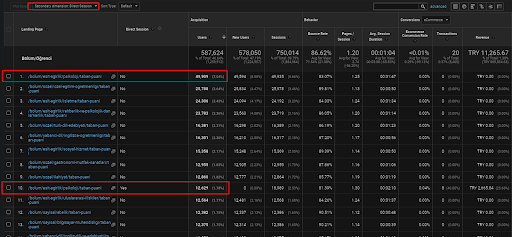
In den letzten 3 Monaten wurde nur eine Webseite aus dem ersten semantischen Content-Netzwerk von den 49.000 organischen Nutzern verwendet. Und 12.900 zusätzliche Benutzer kamen als direkter Traffic, der zum ersten Mal durch die organische Suche gewonnen wurde. Und die Sitzungs-/Seitenmetriken und die durchschnittliche Sitzungsdauer sind für diese Benutzersegmente höher.
Wie bereits erwähnt, kann eine Suchmaschine Abfragen, Dokumente, Absichten, Konzepte, Interessen und Aktionen gruppieren, aber auch Benutzer gruppieren. Wenn eine Benutzergruppe positive Rückmeldungen hinterlässt und gleichzeitig einen Markenwert schafft, indem sie diese Webseiten zu den Lesezeichen hinzufügt, die Adressleiste direkt eintippt und die allgemeinen Begriffe zusammen mit dem Markennamen sucht, zeigt dies, dass die Quelle ihre Autorität und Suchmaschine verbessert kann alles von SERP, Chrome und seinen eigenen DNS-Adressen erkennen. 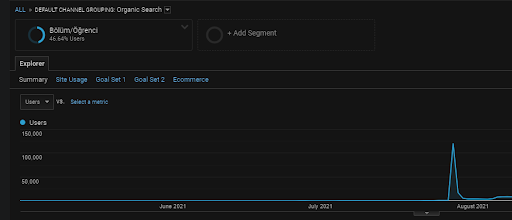
Oben sehen Sie das Nutzersegment des ersten Content-Werbenetzwerks. Sie können ein Benutzersegment für jedes semantische Content-Werbenetzwerk mit benutzerdefinierten Zielen erstellen, und Sie können auch untergeordnete Benutzersegmente für die semantischen untergeordneten Content-Netzwerke hinzufügen.
8. Semantische Inhaltsnetzwerke mit Unterabschnitten basierend auf Suchaktivitäten unterstützen
In diesem Abschnitt geht es auch um die Auflösung von Entitätsattributen und die Analyse, was ein weiteres Thema ist. Aber, einfach ausgedrückt, einige Attribute dieser Entitäten, die auf Kontextdomänen basieren, sollten in eine niedrigere Hierarchie gestellt werden, nicht in die obere Hierarchie. In diesem Fall kann „Vizem.net“ ein besseres Beispiel geben, während es für das Bogazici Enstitusu mit „Gehältern von Berufen“ und „Prüfungspunkten von Universitäten“ demonstriert werden kann. Diese beiden herausragenden Attribute wurden basierend auf den Abfrage- und Dokumentvorlagen zu den semantischen Sub-Content-Netzwerken platziert. 
Die Identifizierung semantischer Einheiten innerhalb einer Suchanfrage ist ein weiteres Google-Patent, das die Phrasen in verschiedene semantische Kategorien unterteilt und die Relevanz eines Dokuments basierend auf seiner Nähe zu allen Variationen der Suchanfrage aggregiert.
In einer früheren SEO-Fallstudie habe ich diese Art von Struktur nicht befolgt, sondern einen Crawling-Pfad erstellt, der auf der „Chronologie“ und den streng begrenzten internen Links basiert. In diesen Artikeln ist die Anzahl interner Links im Hauptinhalt höher als im vorherigen.
9. Verwenden Sie thematische Wörter innerhalb der URLs
Wenn Google ohne Kanonisierungssignal auf zwei verschiedene URLs mit demselben Inhalt stößt, wählt es die kurze als die kanonische aus. Weil kurze URLs einfacher zu analysieren, aufzulösen und anzufordern sind. Wenn Sie Billionen von Webseiten haben, die Sie jeden Tag milliardenfach aktualisieren, können sogar die Buchstaben in URLs das „Kosten-Qualitäts-Verhältnis“ einer Website anzeigen. Wie ich bereits sagte, sollten die „Kosten des Abrufens“ niedriger sein als die „Kosten des Nicht-Abrufens“. Wer von einer Suchmaschine verstanden werden möchte, sollte die „geordneten und komplementären Kontextsignale“ auf jeder Ebene, einschließlich der URLs, platzieren. 
Ein Ausschnitt aus dem „evidence-based“ Ranking via Evidence Aggregation. Es erklärt, wie eine Antwort mit einer Frage abgeglichen werden kann.
In diesem Zusammenhang verwende ich meistens ein einzelnes Wort innerhalb der URL. Diese können die Hierarchie und Struktur des semantischen Inhaltsnetzwerks widerspiegeln. Einige denken immer noch, dass die „Layer-Anzahl“ innerhalb der URL die Crawl-Frequenz beeinflusst, vor 2019 war es wahr. Aber solange der Inhalt sinnvoll ist und die Benutzer eines beliebten oder prominenten Themas zufriedenstellt, wird er von einer solchen Situation nicht betroffen sein.
Um dies zu demonstrieren, können Sie dem folgenden Beispiel folgen.
- Root-Domain/Semantic-Content-Network-1/Type-1/Sub-Content-Network-Part-for-Type-1
- Root-Domain/Semantic-Content-Network-2/Type-2/Sub-Content-Network-Part-for-Type-2
Diese beiden semantischen Inhaltsnetzwerke können sich aus der gleichen Hierarchie heraus verbinden, und sie können sich auch selbst basierend auf der Relevanz verbinden. Hier gibt es noch mehr Dinge, über die wir sprechen können, wie zum Beispiel „Entity Grouper Contents – Hub Type Content“, aber das Thema eines anderen Tages.
Hinweis: Das geplante Third Semantic Content Network kann auch als „Conceptual Grouper Content Network“ verarbeitet werden. Und wenn es veröffentlicht wird, kann der organische Gesamtverkehr mit dem Effekt des zweiten semantischen Inhaltsnetzwerks über 3 Millionen Sitzungen pro Monat betragen.
10. Verstehen Sie den Unterschied zwischen Verschachteln und Verbinden
Als praktischer methodischer Unterschied ist das Verbinden das Verbinden ähnlicher Dinge auf der Grundlage einer kontextuellen Domäne, während das Verschachteln die Gruppierung ähnlicher Inhalte mit demselben Zweck darstellt. Dieses Clustering hilft einer Suchmaschine, ähnliche Inhalte schneller zu finden und eine Quellenqualitätsbewertung für diese Gruppen zu erstellen, oder diese verschachtelten Inhalte, die auf einem semantischen Netzwerk basieren, werden einfacher. 
Stellen Sie sich vor, es gibt zwei verschiedene Crawling-Pfade wie unten.
- Crawl-Pfad 1: Trifft URLs zufällig, ohne Vorlage, Ähnlichkeit und Kontextrelevanz.
- Crawling-Pfad 2: Findet URLs, die sogar von den URLs selbst her sinnvoll sind, mit einer Vorlage, einem hohen Maß an Ähnlichkeit und Relevanz basierend auf dem Kontext.
Wenn der Inhalt sogar vom Crawling-Pfad her sinnvoll ist, werden das „Anfangsranking“ und das „Neuranking“ dank der „Neurankingauslösung basierend auf dem Abdeckungsverständnis der Suchmaschine“ besser.
Hinweis: Die richtige Verwendung interner Links mit Phrasen-Taxonomie ist wichtig für das Verschachteln und Verbinden.
Dies bringt uns zu den letzten beiden praktischen Methoden, die kurz geteilt werden. Und dieser Abschnitt bezieht sich wiederum auf das hohe Maß an Disziplin und organisatorischer Hinlänglichkeit. 
Ein Patent von Trystan Upstill und Steven D. Baker zur Erkennung der gleichzeitig vorkommenden Begriffe in den HTML-Listen. Die Hervorhebung dieses Patents besteht darin, dass es den Wert einer einzelnen HTML-Liste zeigt, um die gleichzeitig vorkommenden Begriffslisten für ein Thema oder einen Teil der Ausdruckstaxonomie zu bestimmen.
11. Verstehen Sie, wann ein semantisches Inhaltsnetzwerk mit einer angepassten Häufigkeit veröffentlicht werden sollte
Dies wurde bereits erklärt, aber in einem dieser SEO-Fallstudienprojekte habe ich fast 400 Inhalte an einem Tag veröffentlicht. Was das andere betrifft, habe ich angefangen, plötzlich nur noch 10-15 Inhalte zu veröffentlichen, dann habe ich die Geschwindigkeit im Laufe der Zeit mit einer Stetigkeit erhöht, bis die Covid-bedingten wirtschaftlichen Probleme beginnen.
Wenn eine neue Quelle ein neues Semantic Content Network erstellt, ist die Veröffentlichung am ersten Tag möglicherweise etwas schwieriger als Sie denken, die Überprüfung aller internen Links, Grammatiken und Informationen auf der Webseite ist nicht so einfach. Wenn der gesamte Inhalt jedoch nur aus einem einzigen Thema und einer Abfragevorlage stammt und die Quelle keine Historie zu diesem Thema hat, hat die Veröffentlichung des größten Teils des semantischen Inhaltsnetzwerks Vorteile wie schnellere Indizierung, Verständnis und Neubewertung.
In meiner Situation gab es auch ein historisches Ereignis mit Saisonalität. Mein Ziel war es also, eine ausreichende durchschnittliche Position zu haben, bis ich von der Suchmaschine für die spezifischen Entitäten und Suchaktivitäten gegen die älteren Quellen getestet werden kann. Daher habe ich das erste Semantic Content Network mit einem hohen Vorbereitungsniveau vor den 45 Tagen nach dem saisonalen Ereignis veröffentlicht.
Dann können Sie sehen, wie die Suchmaschine die Quelle wie unten wiederholt getestet hat. 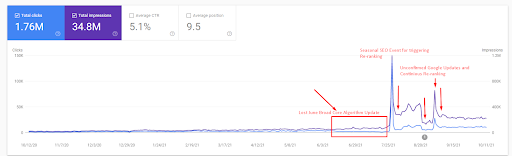
Eine genauere Erklärung finden Sie weiter unten. 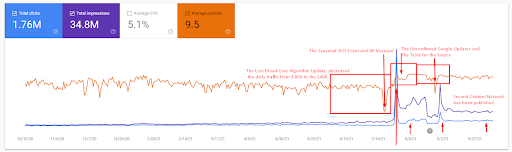
Einen schnellen Faktencheck finden Sie unten für die obige Screenshot-Erklärung.
- Das Broad Core Algorithm Update hat den Traffic der Website um mehr als 200 % verringert.
- Die Website verlor auch mehr als 15.000 Anfragen.
- Dies wirkte sich auf die Gesamtindexierung der Quelle für das neue semantische Content-Netzwerk aus, wie im ausführlichen Artikel zur SEO-Fallstudie besser erläutert wurde.
- Dank des saisonalen SEO-Ereignisses fand die Neubewertung früher statt, und nach dem saisonalen SEO-Ereignis normalisierte die Suchmaschine das Ranking der Quelle basierend auf dem tatsächlichen Verkehr während der unbestätigten Aktualisierungen.
- Die Abfragen und Rankings, die dank des First Semantic Content Network und des Seasonal Event erzielt werden, wurden geschützt und weiter verbessert.
- Das erste Semantic Content Network unterstützte auch das neue und zweite Semantic Content Network.
Der Abfrageverlust und der durchschnittliche Ranking-Verlust können auch von Ahrefs wie unten eingesehen werden. Sie können den Effekt des Google Broad Core Algorithm Update (GBCAU) vom Juni 2021 zusammen mit dem Effekt des unbestätigten Updates überprüfen. 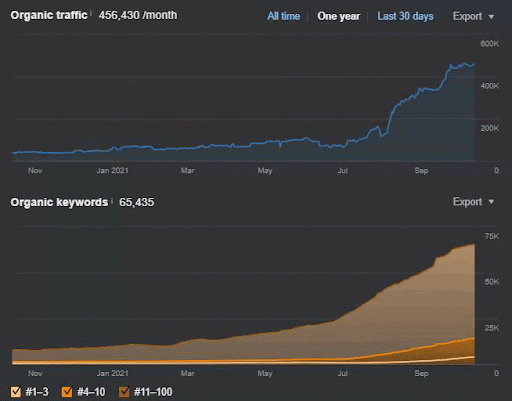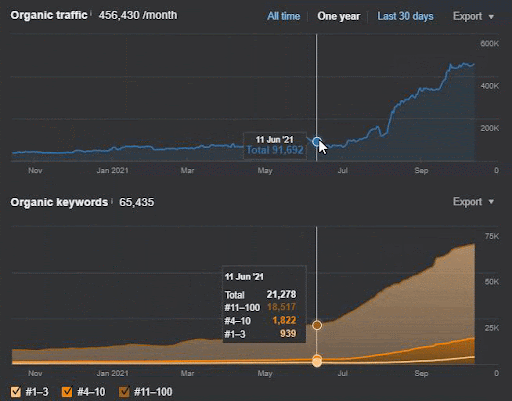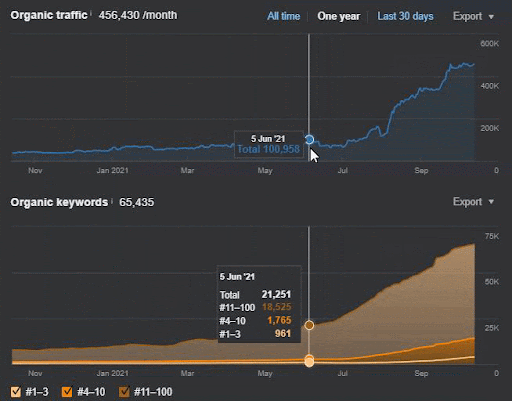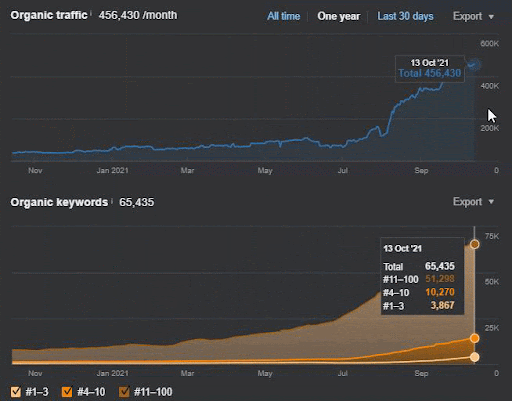
Daher ist die Verwendung eines semantischen Inhaltsnetzwerks mit mehreren möglichen Strategien eine Notwendigkeit. Selbst wenn der GCBAU verloren geht, kann natura dank anderer Faktoren im Zusammenhang mit der Suchmaschine einem SEO helfen. Sie können sich also vorstellen, warum es schwieriger ist, einem Autor oder Kunden diese Dinge zu erklären als technisches SEO. Semantisches SEO verwendet keine numerischen Werte, sondern theoretisches Wissen, das aus dem Verständnis von Suchmaschinen über Patente, Forschungsarbeiten, Erfahrungen und historische Ankündigungen stammt.
12. Verwenden Sie In-Page-Satzoptimierung für eine bessere Sachstruktur
Um ehrlich zu sein, selbst das 10. Listing ist ein völlig neues Thema und es kann hier sogar das Schreiben von 20.000 Wörtern erfordern. Aber ich werde mit einem einfachen Beispiel beginnen.
- X ist Y.
- Y ist X.
Für die obigen Beispielsätze können Sie die folgenden Dinge verstehen.
- Die obigen Sätze sind kein Duplicate Content.
- Die obigen Vorschläge sind doppelt.
- Die relationalen Erklärungen zwischen zwei Sätzen sind die gleichen.
- Die semantischen Rollenbezeichnungen sind zu 100 % unterschiedlich.
- Die Ausgabe der Named Entity Recognition ist zu 100 % gleich.
Die In-Page-Satzoptimierung bezieht sich auf die Fragegenerierungsalgorithmen und Frage-Antwort-Pairing-Technologien. Ein Frageformat erfordert einen bestimmten Satztyp. Und bestimmte Arten von Fragen sollten mit bestimmten Arten von Sätzen beantwortet werden. Das Inhaltsformat, die NER und die Faktenextraktion werden von der Satzstrukturoptimierung beeinflusst. 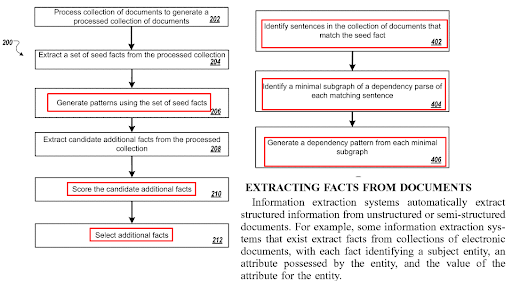
Die Tripletts (ein Objekt, zwei Subjekte) können schneller extrahiert und auf Genauigkeit überprüft werden. Zwei ähnliche Sätze bedeuten nicht, dass sie doppelt vorhanden sind, sondern dass sie in Bezug auf die Satzstruktur nahe beieinander liegen. Solange der Vorschlag unterschiedlich ist, ist die Verwendung ähnlicher Sätze zwischen ähnlichen Dokumentvorlagen für unterschiedliche Frage-Intent-Paare eine Notwendigkeit für die Erstellung semantischer Inhaltsnetzwerke. 
Klare Satzstrukturen mit einem geeigneten Muster sind nützlich, um Textstücke füreinander relevanter zu machen und gleichzeitig einer Suchmaschine zu helfen, benannte Entitäten, Themen und Attribute zusammen mit ihren Werten füreinander zu erkennen.
Es hilft auch zu sehen, welcher Abschnitt eines Artikels besser gemacht werden kann und in den Topical Nets, wo Ihr Inhalt für welche Arten von Wortpaaren, Wortvektoren und Absichten besser rankt. Denn wenn bestimmte Arten von Satzstrukturen für bestimmte Arten von Fragen über mehrere Webseiten hinweg beobachtet werden können, hilft dies für erweiterte SEO-A/B-Tests mit endlosen Mengen an Datenproben und Testproben. Sie können mehrere In-Page-Satzdesigns erstellen, um zu überprüfen, wie eine Suchmaschine die Fakten für den Vergleich extrahiert. 
Wenn es um die Angabe von Fakten geht, sollten der „Knowledge Vault“ und der Luna Dong nicht vergessen werden.
13. Geben Sie Informationen aus der realen Welt mit Präzision und Konsistenz weiter, nicht Meinungen mit Fluff
Die Genauigkeit bedeutet hier Vergleichbarkeit mit Zahlenwerten oder begrifflich konkreten Zusammenhängen. Die Konsistenz bedeutet, dass Sie Ihre Haltung für die spezifische Aussage schützen. Sagen Sie zum Beispiel nicht bei jeder Produktbewertung, die sich auf Y bezieht, „Produkt X ist das Beste für Y“. Machen Sie keine widersprüchlichen Aussagen auf der gesamten Website. Und wenn das Produkt das Beste ist, was ist der Beweis dafür? Material, Größe oder Farbe und Geruch? Fluff im Text bedeutet, dass Sie unnötige Brückenwörter verwenden oder Dinge nicht sagen, die nicht bewiesen werden können, oder der Wahrheit widersprechen.
Im Zusammenhang mit diesen nicht-definierenden Anweisungen, die durch einige der Beispiele unterstützt werden, können Sie eines der Sprachmodelle von Google überprüfen, nämlich KeALM.
Es dient zum Generieren von Text aus einer Datenbank mit den Daten-zu-Text-Modellen und zum Überprüfen der Genauigkeit des Inhalts. 
KELM ist ein Beispiel für ein Genauigkeitsaudit für die Vorschläge mit Text-zu-Daten-Methoden.
Hier geht es auch ein wenig um die Definition von „Triplet“ und „Open Information Extraction for Unknown Entities“, aber wie Sie wissen, ist dies die Kurzversion, und ich denke, ich habe genug erzählt. Wenn Sie auf Ihrer Website falsche Informationen angeben, stellen Sie grundsätzlich sicher, dass Google diese verstehen kann, um das wissensbasierte Vertrauen der Quelle zu verringern. Hier müssen Sie möglicherweise auch wissen, dass eine Suchmaschine, da Sie die Wissensdatenbank erweitern können, ihre eigene Wissensdatenbank basierend auf Ihren Informationen ändern kann, wenn Sie eine korrelierte Quelle mit PageRank und Wissensdatenbank-Vertrauen haben mit hoher Genauigkeit und einzigartigen Drillingen.
14. Den semantischen Abhängigkeitsbaum für Entitäten verstehen
Semantischer Abhängigkeitsbaum bedeutet, dass Attribute, die Beziehungen zu anderen Entitäten signalisieren, eine hierarchische Abhängigkeit zwischen ihnen haben. Der semantische Abhängigkeitsbaum kann beobachtet werden, indem mehrere Entitätsprofile und -winkel überprüft werden, z. B. kann ein Land Mitglied einer Organisation sein, und als andere Entität kann diese Organisation einige andere Attribute haben, die den verbundenen Ländern mit abgeleiteten Beziehungen zugeordnet werden können.
Unten sehen Sie direkt ein einfaches Beispiel aus der Suchmaschine. 
REALM ist eine Methode, die semantische Abhängigkeitsbäume verwendet, um Informationen aus mehrdeutigem Text zu extrahieren.
Im offenen Web kann die offene Informationsextraktion neue benannte Entitäten erkennen und dieselben Entitäten als gemeinsam mit anderen Entitäten auftretend extrahieren. Diese Co-Auftreten und gegenseitigen Attribute innerhalb des Artikels können einen Kontext- und Kandidatenbeziehungstyp zwischen Entitäten zuweisen. Basierend auf den Verbindungen und dem Typ der Entität kann der semantische Abhängigkeitsbaum erstellt werden. Die gleiche Logik gilt auch für die lexikalische Semantik. Das Wort „Junge“ hat einige mögliche Bedeutungen und einige genaue andere Bedeutungen. Zum Beispiel ist ein Junge ein Mann und wahrscheinlich ein Teenager, der nicht verheiratet ist. Es kann auch in der Nähe des Schülers verwendet werden. Das Wort „Königin“ hingegen enthält andere Neben- und genaue Bedeutungen wie „weiblich“ und „eine Gouverneurin sein“. Etwas zu regeln ist also eine natürliche semantische Abhängigkeitsbaumhierarchie, die einige bestimmte Arten von Abfragevorlagen wie „Königin von …“ oder „Für Quen“ signalisieren kann. These contextual layers with context qualifiers should be united naturally with contextual domains and knowledge domains for improving the topical and contextual coverage together. 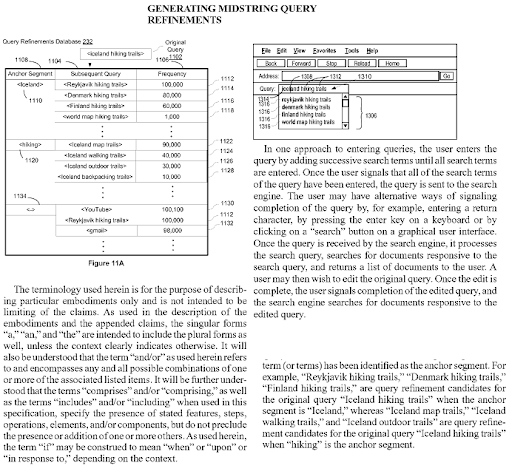
Generating Midstring Query Refinements is another Google Patent that shows the Semantic Content Network's connections to each other. Every midstring query refinement is a part of the topic's sub-topical net. A semantic content network that focuses on all these query refinement candidates with the correct semantic annotations will have the advantage of better re-ranking and initial ranking.
Last Thoughts on Semantic Content Network
I know that this content was highly technical in terms of Semantic SEO. And, before publishing my Semantic SEO Course, I still want to increase the knowledge, so that the first theoretical lessons can be digested by our minds faster than usual. The Semantic Content Networks can be defined as the sum of topical map, and individual content designs that include all of the headings, questions, heading levels, anchor texts, content hierarchy, and positions within the site-tree, or anything related to the content piece, including the featured images and in-page detailed images.
Here, besides the in-page sentence structure designs, or question-answer formats, or synonym sentence formats, we can also talk about the contextual vectors, contextual hierarchies, sequential sentences with bridged contexts, or evidence-based ranking by evidence aggregation. All these things would make this SEO Case Study and Guide more complicated but yet detailed. Thus, like in the previous, Importance of Topical Authority SEO Case Study and Guide, explaining Semantic Networks would make that article more complicated but yet detailed.
The future SEO Case Studies will include more and more details by supporting the previous ones. Lastly, I have gotten lots of screenshots and thank you messages from all of you that show the positive results that you have gotten thanks to Topical Authority understanding. I hope, Initial-ranking, and Re-ranking along with the Semantic Content Network understanding help you further.
See you in the next SEO Case Studies.
“The acquisition of knowledge is always of use to
the intellect, because it may thus drive out useless
things and retain the good. For nothing can be
loved or hated unless it is first known.”
– Leonardo da Vinci.