
Kontrolle von Crawling und Indizierung: Ein SEO-Leitfaden für Robots.txt und Tags
Veröffentlicht: 2019-02-19Die Optimierung des Crawl-Budgets und das Blockieren von Bots von der Indexierung von Seiten sind Konzepte, mit denen viele SEOs vertraut sind. Aber der Teufel steckt im Detail. Zumal sich die Best Practices in den letzten Jahren stark verändert haben.
Eine kleine Änderung an einer robots.txt-Datei oder Roboter-Tags kann dramatische Auswirkungen auf Ihre Website haben. Um sicherzustellen, dass die Auswirkungen für Ihre Website immer positiv sind, werden wir uns heute mit Folgendem befassen:
Optimierung des Crawl-Budgets
Was ist eine Robots.txt-Datei
Was sind Meta Robots-Tags?
Was sind X-Robots-Tags
Roboterrichtlinien & SEO
Best-Practice-Roboter-Checkliste
Optimierung des Crawl-Budgets
Ein Suchmaschinen-Spider hat eine „Freigabe“ dafür, wie viele Seiten er auf Ihrer Website crawlen kann und möchte. Dies wird als „Crawl-Budget“ bezeichnet.
Finden Sie das Crawling-Budget Ihrer Website im Bericht „Crawling-Statistiken“ der Google Search Console (GSC). Beachten Sie, dass der GSC eine Ansammlung von 12 Bots ist, die nicht alle für SEO bestimmt sind. Es sammelt auch AdWords- oder AdSense-Bots, die SEA-Bots sind. Daher gibt Ihnen dieses Tool eine Vorstellung von Ihrem globalen Crawl-Budget, aber nicht von seiner genauen Verteilung.
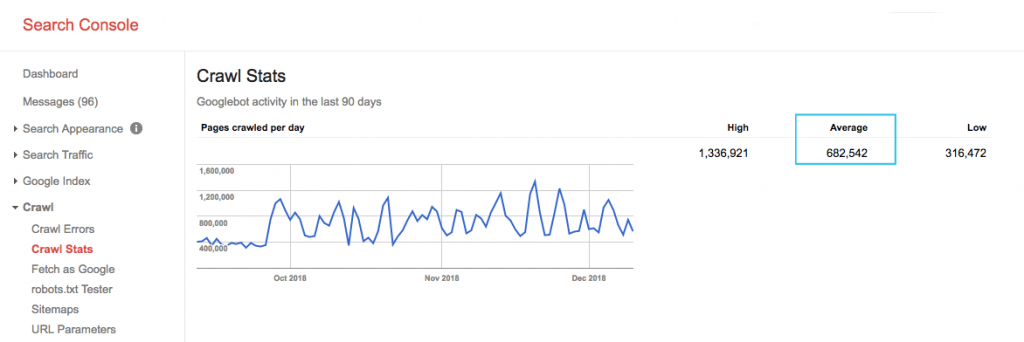
Um die Zahl aussagekräftiger zu machen, teilen Sie die durchschnittlich gecrawlten Seiten pro Tag durch die Gesamtzahl der crawlbaren Seiten auf Ihrer Website – Sie können Ihren Entwickler nach der Zahl fragen oder einen unbegrenzten Website-Crawler ausführen. Dadurch erhalten Sie eine erwartete Crawl-Rate, gegen die Sie mit der Optimierung beginnen können.
Willst du tiefer gehen? Erhalten Sie eine detailliertere Aufschlüsselung der Aktivität des Googlebot, z. B. welche Seiten besucht werden, sowie Statistiken für andere Crawler, indem Sie die Serverprotokolldateien Ihrer Website analysieren.
Es gibt viele Möglichkeiten, das Crawling-Budget zu optimieren, aber ein einfacher Anfang ist, den GSC-Bericht „Abdeckung“ zu überprüfen, um das aktuelle Crawling- und Indexierungsverhalten von Google zu verstehen.
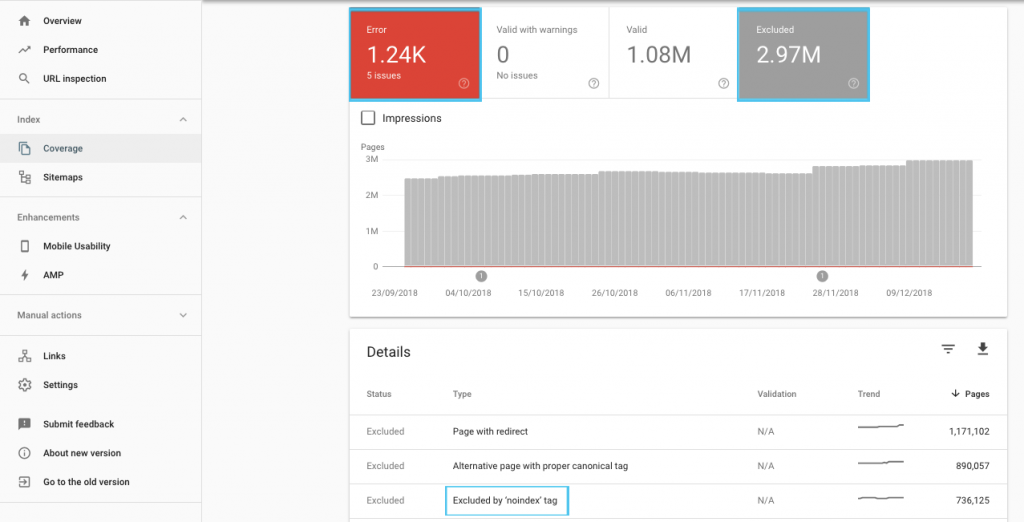
Wenn Sie Fehler wie „Gesendete URL als 'noindex' markiert“ oder „Gesendete URL durch robots.txt blockiert“ sehen, wenden Sie sich an Ihren Entwickler, um sie zu beheben. Untersuchen Sie alle Robots-Ausschlüsse, um zu verstehen, ob sie aus SEO-Sicht strategisch sind.
Im Allgemeinen sollten SEOs darauf abzielen, Crawl-Beschränkungen für Roboter zu minimieren. Die beste Strategie ist es, die Architektur Ihrer Website zu verbessern, um URLs nützlich und für Suchmaschinen zugänglich zu machen.
Google selbst merkt an, dass „eine solide Informationsarchitektur wahrscheinlich eine weitaus produktivere Nutzung von Ressourcen ist, als sich auf die Crawl-Priorisierung zu konzentrieren“.
Davon abgesehen ist es hilfreich zu verstehen, was mit robots.txt-Dateien und Robots-Tags getan werden kann, um das Crawling, die Indexierung und die Weitergabe von Link-Equity zu steuern. Und was noch wichtiger ist, wann und wie man es am besten für modernes SEO nutzt.
[Fallstudie] Verwaltung des Bot-Crawlings von Google
 Lesen Sie die Fallstudie
Lesen Sie die FallstudieWas ist eine Robots.txt-Datei
Bevor eine Suchmaschine eine Seite durchsucht, überprüft sie die robots.txt. Diese Datei teilt Bots mit, welche URL-Pfade sie besuchen dürfen. Diese Einträge sind aber nur Weisungen, keine Mandate.
Die robots.txt kann das Crawlen nicht zuverlässig verhindern wie eine Firewall oder ein Passwortschutz. Es ist das digitale Äquivalent zu einem „Bitte nicht eintreten“-Schild an einer unverschlossenen Tür.
Höfliche Crawler, wie große Suchmaschinen, befolgen im Allgemeinen Anweisungen. Feindliche Crawler, wie E-Mail-Scraper, Spambots, Malware und Spider, die nach Schwachstellen auf Websites suchen, achten oft nicht darauf.
Außerdem handelt es sich um eine öffentlich zugängliche Datei . Jeder kann Ihre Anweisungen sehen.
Verwenden Sie Ihre robots.txt-Datei nicht für Folgendes:
- Um vertrauliche Informationen zu verbergen. Passwortschutz verwenden.
- Um den Zugriff auf Ihre Staging- und/oder Entwicklungsseite zu blockieren. Verwenden Sie die serverseitige Authentifizierung.
- Um feindliche Crawler explizit zu blockieren. Verwenden Sie IP-Blockierung oder User-Agent-Blockierung (auch bekannt als Ausschluss eines bestimmten Crawler-Zugriffs mit einer Regel in Ihrer .htaccess-Datei oder einem Tool wie CloudFlare).
Jede Website sollte eine gültige robots.txt-Datei mit mindestens einer Direktivengruppierung haben. Ohne einen erhalten alle Bots standardmäßig vollen Zugriff – jede Seite wird also als crawlbar behandelt. Auch wenn Sie dies beabsichtigen, machen Sie dies besser mit einer robots.txt-Datei für alle Beteiligten deutlich. Außerdem werden Ihre Serverprotokolle ohne eine solche mit fehlgeschlagenen Anfragen für robots.txt übersät sein.
Struktur einer robots.txt-Datei
Um von Crawlern anerkannt zu werden, muss Ihre robots.txt:
- Seien Sie eine Textdatei mit dem Namen „robots.txt“. Beim Dateinamen wird zwischen Groß- und Kleinschreibung unterschieden. „Robots.TXT“ oder andere Varianten funktionieren nicht.
- Sich im Top-Level-Verzeichnis Ihrer kanonischen Domain und gegebenenfalls Subdomains befinden. Um beispielsweise das Crawling für alle URLs unterhalb von https://www.example.com zu steuern, muss sich die robots.txt-Datei unter https://www.example.com/robots.txt und für subdomain.example.com unter befinden subdomain.example.com/robots.txt.
- Gibt einen HTTP-Status von 200 OK zurück.
- Verwenden Sie eine gültige robots.txt-Syntax – Überprüfen Sie dies mit dem robots.txt-Testtool der Google Search Console.
Eine robots.txt-Datei besteht aus Gruppierungen von Anweisungen. Die Einträge bestehen hauptsächlich aus:
- 1. User-Agent: Adressiert die verschiedenen Crawler. Sie können eine Gruppe für alle Roboter haben oder Gruppen verwenden, um bestimmte Suchmaschinen zu benennen.
- 2. Nicht zulassen: Gibt Dateien oder Verzeichnisse an, die vom Crawlen durch den oben genannten Benutzeragenten ausgeschlossen werden sollen. Sie können eine oder mehrere dieser Linien pro Block haben.
Eine vollständige Liste der Benutzeragentennamen und weitere Beispiele für Anweisungen finden Sie im robots.txt-Leitfaden auf Yoast.
Zusätzlich zu den Direktiven „User-agent“ und „Disallow“ gibt es einige Nicht-Standard-Direktiven:
- Allow: Geben Sie Ausnahmen von einer disallow-Anweisung für ein übergeordnetes Verzeichnis an.
- Crawl-Verzögerung: Drosseln Sie schwere Crawler, indem Sie Bots mitteilen, wie viele Sekunden sie warten sollen, bevor sie eine Seite besuchen. Wenn Sie nur wenige organische Sitzungen erhalten, kann die Crawl-Verzögerung Serverbandbreite sparen. Aber ich würde den Aufwand nur investieren, wenn die Crawler aktiv Probleme mit der Serverlast verursachen. Google erkennt diesen Befehl nicht an und bietet die Möglichkeit, die Crawling-Rate in der Google Search Console zu begrenzen.
- Clean-param: Vermeiden Sie das erneute Crawlen von doppelten Inhalten, die durch dynamische Parameter generiert wurden.
- Kein Index: Entwickelt, um die Indizierung zu steuern, ohne ein Crawl- Budget zu verwenden. Es wird nicht mehr offiziell von Google unterstützt. Obwohl es Hinweise darauf gibt, dass es immer noch Auswirkungen haben kann, ist es nicht zuverlässig und wird von Experten wie John Mueller nicht empfohlen.
@maxxeight @google @DeepCrawl Ich würde es wirklich vermeiden, dort den noindex zu verwenden.
— ???? John ???? (@JohnMu) 1. September 2015
- Sitemap: Der optimale Weg, Ihre XML-Sitemap einzureichen, ist über die Google Search Console und die Webmaster-Tools anderer Suchmaschinen. Das Hinzufügen einer Sitemap-Anweisung an der Basis Ihrer robots.txt-Datei hilft jedoch anderen Crawlern, die möglicherweise keine Übermittlungsoption anbieten.
Einschränkungen von robots.txt für SEO
Wir wissen bereits, dass robots.txt das Crawlen nicht für alle Bots verhindern kann. Ebenso verhindert das Verbieten von Crawlern von einer Seite nicht, dass sie in Suchmaschinen-Ergebnisseiten (SERPs) aufgenommen wird.
Wenn eine blockierte Seite andere starke Ranking-Signale hat, kann Google sie für relevant halten, um sie in den Suchergebnissen anzuzeigen. Obwohl ich die Seite nicht gecrawlt habe.
Da der Inhalt dieser URL Google unbekannt ist, sieht das Suchergebnis so aus:

Um das Erscheinen einer Seite in SERPs endgültig zu blockieren, müssen Sie ein „noindex“-Roboter-Meta-Tag oder einen X-Robots-Tag-HTTP-Header verwenden.
Verbieten Sie die Seite in diesem Fall nicht in robots.txt , da die Seite gecrawlt werden muss, damit das „noindex“-Tag gesehen und befolgt werden kann. Wenn die URL blockiert ist, sind alle Robots-Tags unwirksam.
Wenn eine Seite viele eingehende Links angesammelt hat, Google jedoch durch robots.txt daran gehindert wird, diese Seiten zu crawlen, während die Links Google bekannt sind, geht der Linkwert verloren.
Was sind Meta Robots-Tags?
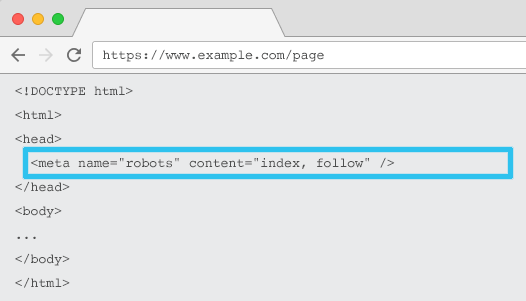
Metaname=“robots“ wird im HTML jeder URL platziert und teilt Crawlern mit, ob und wie sie den Inhalt „indizieren“ und ob sie allen On-Page-Links „folgen“ (d. h. crawlen) sollen, wodurch der Linkwert weitergegeben wird.
Mit dem allgemeinen Metanamen = „robots“ gilt die Direktive für alle Crawler. Sie können auch einen bestimmten Benutzeragenten angeben. Beispiel: Metaname = „googlebot“. Es kommt jedoch selten vor, dass mehrere Meta-Roboter-Tags verwendet werden müssen, um Anweisungen für bestimmte Spinnen festzulegen.
Bei der Verwendung von Meta-Robots-Tags gibt es zwei wichtige Überlegungen:
- Ähnlich wie bei robots.txt sind die Meta-Tags Anweisungen, keine Mandate, und können daher von einigen Bots ignoriert werden.
- Die Robots-Nofollow-Richtlinie gilt nur für Links auf dieser Seite. Es ist möglich, dass ein Crawler dem Link von einer anderen Seite oder Website ohne Nofollow folgt. Der Bot kann also trotzdem Ihre unerwünschte Seite erreichen und indizieren.
Hier ist die Liste aller Meta-Robots-Tag-Anweisungen:
- index: Weist Suchmaschinen an, diese Seite in den Suchergebnissen anzuzeigen. Dies ist der Standardzustand, wenn keine Direktive angegeben ist.
- noindex: Weist Suchmaschinen an, diese Seite nicht in den Suchergebnissen anzuzeigen.
- follow: Weist Suchmaschinen an, allen Links auf dieser Seite zu folgen und Eigenkapital weiterzugeben, auch wenn die Seite nicht indexiert ist. Dies ist der Standardzustand, wenn keine Direktive angegeben ist.
- nofollow: Weist Suchmaschinen an, keinem Link auf dieser Seite zu folgen oder Eigenkapital weiterzugeben.
- all: Äquivalent zu „index, follow“.
- none: Äquivalent zu „noindex, nofollow“.
- noimageindex: Weist Suchmaschinen an, keine Bilder auf dieser Seite zu indizieren.
- noarchive: Weist Suchmaschinen an, keinen zwischengespeicherten Link zu dieser Seite in den Suchergebnissen anzuzeigen.
- nocache: Dasselbe wie noarchive, aber nur von Internet Explorer und Firefox verwendet.
- nosnippet: Weist Suchmaschinen an, keine Meta-Beschreibung oder Videovorschau für diese Seite in den Suchergebnissen anzuzeigen.
- notranslate: Weist die Suchmaschine an, keine Übersetzung dieser Seite in den Suchergebnissen anzubieten.
- unavailable_after: Suchmaschinen anweisen, diese Seite nach einem bestimmten Datum nicht mehr zu indizieren.
- noodp: Jetzt veraltet, es hat Suchmaschinen einmal daran gehindert, die Seitenbeschreibung von DMOZ in Suchergebnissen zu verwenden.
- noydir: Jetzt veraltet, hat es Yahoo einmal daran gehindert, die Seitenbeschreibung aus dem Yahoo-Verzeichnis in den Suchergebnissen zu verwenden.
- noyaca: Verhindert, dass Yandex die Seitenbeschreibung aus dem Yandex-Verzeichnis in den Suchergebnissen verwendet.
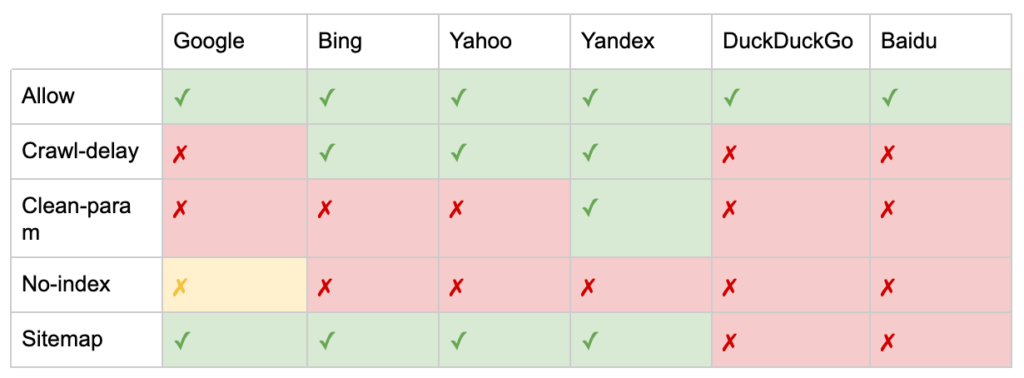
Wie von Yoast dokumentiert, unterstützen nicht alle Suchmaschinen alle Robots-Meta-Tags oder machen sogar deutlich, was sie tun und was nicht.
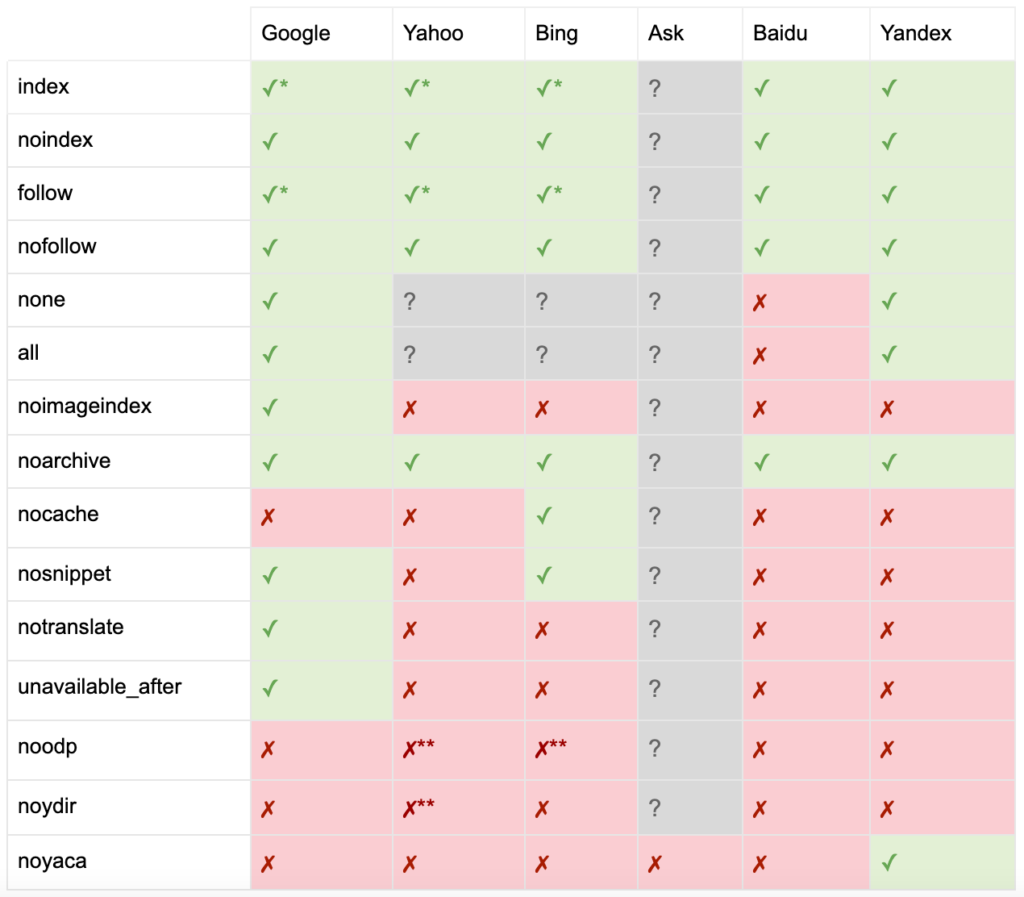
* Die meisten Suchmaschinen haben keine spezifische Dokumentation dafür, aber es wird davon ausgegangen, dass die Unterstützung für das Ausschließen von Parametern (z. B. nofollow) die Unterstützung für das positive Äquivalent (z. B. folgen) impliziert.
** Während die noodp- und noydir-Attribute möglicherweise noch „unterstützt“ werden, existieren die Verzeichnisse nicht mehr, und es ist wahrscheinlich, dass diese Werte nichts bewirken.

Üblicherweise werden Robots-Tags auf „index, follow“ gesetzt. Einige SEOs sehen das Hinzufügen dieses Tags im HTML-Code als überflüssig an, da es der Standard ist. Das Gegenargument ist, dass eine klare Spezifikation von Richtlinien dazu beitragen kann, menschliche Verwirrung zu vermeiden.
Beachten Sie: URLs mit einem „noindex“-Tag werden seltener gecrawlt und führen bei längerer Anwesenheit dazu, dass Google die Links der Seite nicht mehr verfolgt.
Es ist selten, einen Anwendungsfall zu finden, um alle Links auf einer Seite mit einem Meta-Robots-Tag zu „nofollowen“. Es kommt häufiger vor, dass „nofollow“ mit einem rel=“nofollow“-Linkattribut zu einzelnen Links hinzugefügt wird. Zum Beispiel möchten Sie vielleicht das Attribut rel="nofollow" zu nutzergenerierten Kommentaren oder bezahlten Links hinzufügen.
Noch seltener gibt es einen SEO-Anwendungsfall für Robots-Tag-Anweisungen, die sich nicht mit der grundlegenden Indizierung und dem Folgeverhalten befassen, wie z. B. Caching, Bildindizierung und Handhabung von Snippets usw.
Die Herausforderung bei Meta-Robots-Tags besteht darin, dass sie nicht für Nicht-HTML-Dateien wie Bilder, Videos oder PDF-Dokumente verwendet werden können. Hier können Sie sich an X-Robots-Tags wenden.
Was sind X-Robots-Tags
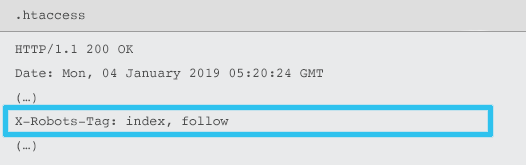
X-Robots-Tag werden vom Server als Element des HTTP-Response-Headers für eine bestimmte URL unter Verwendung von .htaccess- und httpd.conf-Dateien gesendet.
Jede Robots-Meta-Tag-Direktive kann auch als X-Robots-Tag angegeben werden. Ein X-Robots-Tag bietet jedoch noch einige zusätzliche Flexibilität und Funktionalität.
Sie würden X-Robots-Tag anstelle von Meta-Roboter-Tags verwenden, wenn Sie:
- Steuern Sie das Roboterverhalten für Nicht-HTML-Dateien und nicht nur für HTML-Dateien.
- Steuern Sie die Indizierung eines bestimmten Elements einer Seite und nicht der Seite als Ganzes.
- Fügen Sie Regeln hinzu, ob eine Seite indiziert werden soll oder nicht. Wenn ein Autor beispielsweise mehr als 5 veröffentlichte Artikel hat, indizieren Sie seine Profilseite.
- Wenden Sie index & follow-Anweisungen auf einer Site-weiten Ebene an, anstatt seitenspezifisch.
- Verwenden Sie reguläre Ausdrücke.
Vermeiden Sie die Verwendung von Meta-Robotern und dem X-Robots-Tag auf derselben Seite – dies wäre überflüssig.
Um X-Robots-Tags anzuzeigen, können Sie die „Fetch as Google“-Funktion in der Google Search Console verwenden.
Roboterrichtlinien & SEO
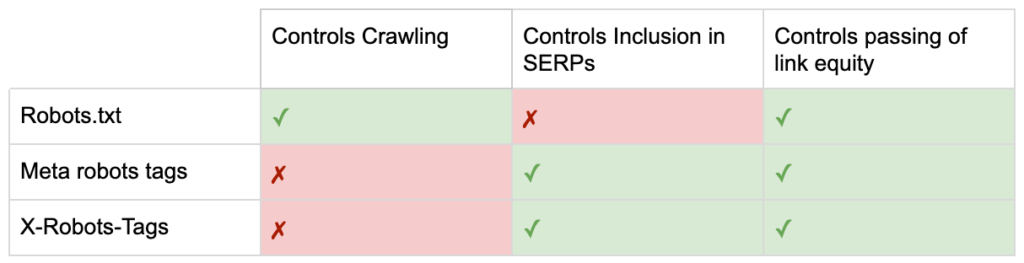
Jetzt kennen Sie also die Unterschiede zwischen den drei Roboterrichtlinien.
robots.txt konzentriert sich darauf, Crawling-Budget zu sparen, verhindert aber nicht, dass eine Seite in den Suchergebnissen angezeigt wird. Es fungiert als erster Gatekeeper Ihrer Website und weist Bots an, nicht darauf zuzugreifen, bevor die Seite angefordert wird.
Beide Arten von Robots-Tags konzentrieren sich auf die Kontrolle der Indexierung und die Weitergabe von Link-Equity. Robots-Meta-Tags werden erst wirksam, nachdem die Seite geladen wurde . Während X-Robots-Tag-Header eine genauere Kontrolle bieten und wirksam werden, nachdem der Server auf eine Seitenanforderung geantwortet hat.
Mit diesem Verständnis können SEOs die Art und Weise weiterentwickeln, wie wir Robots-Anweisungen verwenden, um Crawling- und Indexierungsherausforderungen zu lösen.
Blockieren von Bots, um Serverbandbreite zu sparen
Problem: Beim Analysieren Ihrer Protokolldateien werden Sie sehen, dass viele Benutzeragenten Bandbreite beanspruchen, aber wenig Wert zurückgeben.
- SEO-Crawler wie MJ12bot (von Majestic) oder Ahrefsbot (von Ahrefs).
- Tools, die digitale Inhalte offline speichern, wie Webcopier oder Teleport.
- Suchmaschinen, die in Ihrem Markt nicht relevant sind, wie Baiduspider oder Yandex.
Suboptimale Lösung: Blockieren dieser Spider mit robots.txt, da diese nicht garantiert eingehalten werden und eine eher öffentliche Erklärung sind, die Interessenten Wettbewerbseinblicke verschaffen könnte.
Best-Practice-Ansatz: Die subtilere Anweisung der User-Agent-Blockierung. Dies kann auf unterschiedliche Weise erreicht werden, aber üblicherweise geschieht dies durch Bearbeiten Ihrer .htaccess-Datei, um alle unerwünschten Spider-Anfragen auf eine 403 – Forbidden-Seite umzuleiten.
Interne Website-Suchseiten mit Crawl-Budget
Problem: Auf vielen Websites werden interne Website-Suchergebnisseiten dynamisch auf statischen URLs generiert, die dann das Crawl-Budget auffressen und bei Indexierung zu dünnen oder doppelten Inhalten führen können.
Suboptimale Lösung: Verzeichnis mit robots.txt verbieten. Während dies Crawlerfallen verhindern kann, schränkt es Ihre Fähigkeit ein, für wichtige Kundensuchen zu ranken und für solche Seiten Linkkapital weiterzugeben.
Best-Practice-Ansatz: Ordnen Sie relevante Suchanfragen mit hohem Volumen vorhandenen suchmaschinenfreundlichen URLs zu. Wenn ich beispielsweise nach „Samsung-Telefon“ suche, anstatt eine neue Seite für /search/samsung-phone zu erstellen, leite ich zu /phones/samsung um.
Wo dies nicht möglich ist, erstellen Sie eine parameterbasierte URL. Sie können dann innerhalb der Google Search Console einfach angeben, ob der Parameter gecrawlt werden soll oder nicht.
Wenn Sie Crawling zulassen, analysieren Sie, ob solche Seiten von ausreichender Qualität sind, um einen Rang einzunehmen. Wenn nicht, fügen Sie eine „noindex, follow“-Anweisung als kurzfristige Lösung hinzu, während Sie Strategien entwickeln, wie Sie die Ergebnisqualität verbessern können, um sowohl SEO als auch Benutzererfahrung zu unterstützen.
Blockieren von Parametern mit Robotern
Problem: Abfragezeichenfolgenparameter, wie sie beispielsweise durch Facettennavigation oder Tracking generiert werden, sind berüchtigt dafür, dass sie das Crawl-Budget auffressen, doppelte Inhalts-URLs erstellen und Ranking-Signale aufteilen.
Suboptimale Lösung: Das Crawlen von Parametern mit robots.txt oder mit einem „noindex“-Roboter-Meta-Tag verbieten, da beides (ersteres sofort, späteres über einen längeren Zeitraum) den Fluss von Link Equity verhindert.
Best-Practice-Ansatz: Stellen Sie sicher, dass jeder Parameter einen klaren Existenzgrund hat, und implementieren Sie Ordnungsregeln, die Schlüssel nur einmal verwenden und leere Werte verhindern. Fügen Sie geeigneten Parameterseiten ein rel=canonical-Linkattribut hinzu, um die Ranking-Fähigkeit zu kombinieren. Konfigurieren Sie dann alle Parameter in der Google Search Console, wo es detailliertere Optionen gibt, um Crawling-Einstellungen zu kommunizieren. Weitere Einzelheiten finden Sie im Leitfaden zur Parameterbehandlung von Search Engine Journal.
Sperren von Admin- oder Kontobereichen
Problem: Verhindern Sie, dass die Suchmaschine private Inhalte durchsucht und indiziert.
Suboptimale Lösung: Verwenden der robots.txt zum Blockieren des Verzeichnisses, da dies private Seiten nicht garantiert aus den SERPs fernhält.
Best-Practice-Ansatz: Verwenden Sie einen Passwortschutz, um zu verhindern, dass Crawler auf die Seiten zugreifen, und einen Fallback der „noindex“-Anweisung im HTTP-Header.
Blockieren von Marketing-Zielseiten und Dankesseiten
Problem: Häufig müssen Sie URLs ausschließen, die nicht für die organische Suche bestimmt sind, wie z. B. dedizierte Zielseiten für E-Mail- oder CPC-Kampagnen. Ebenso möchten Sie nicht, dass Personen, die nicht konvertiert haben, Ihre Dankeschön-Seiten über SERPs besuchen.
Suboptimale Lösung: Verbieten Sie die Dateien mit robots.txt, da dies nicht verhindert, dass der Link in die Suchergebnisse aufgenommen wird.
Best-Practice-Ansatz: Verwenden Sie ein „noindex“-Meta-Tag.
Verwalten Sie Duplicate Content vor Ort
Problem: Einige Websites benötigen aus Gründen der Benutzererfahrung eine Kopie bestimmter Inhalte, z. B. eine druckerfreundliche Version einer Seite, möchten aber sicherstellen, dass die kanonische Seite und nicht die doppelte Seite von Suchmaschinen erkannt wird. Auf anderen Websites ist der doppelte Inhalt auf schlechte Entwicklungspraktiken zurückzuführen, z. B. das Rendern desselben Artikels zum Verkauf auf URLs mit mehreren Kategorien.
Suboptimale Lösung: Das Verbieten der URLs mit robots.txt verhindert, dass die doppelte Seite Ranking-Signale weitergibt. Noindexing für Robots wird schließlich dazu führen, dass Google die Links auch als „nofollow“ behandelt, und verhindert, dass die doppelte Seite Link-Equity weitergibt.
Best-Practice-Ansatz: Wenn der doppelte Inhalt keinen Grund hat, entfernen Sie die Quelle und 301-Weiterleitung auf die suchmaschinenfreundliche URL. Wenn es einen Grund dafür gibt, fügen Sie ein rel=canonical-Link-Attribut hinzu, um Ranking-Signale zu konsolidieren.
Dünner Inhalt von zugänglichen kontobezogenen Seiten
Problem: Kontobezogene Seiten wie Login, Registrierung, Warenkorb, Kasse oder Kontaktformulare sind oft inhaltlich dünn und bieten Suchmaschinen wenig Wert, sind aber für Benutzer notwendig.
Suboptimale Lösung: Verbieten Sie die Dateien mit robots.txt, da dies nicht verhindert, dass der Link in die Suchergebnisse aufgenommen wird.
Best-Practice-Ansatz: Für die meisten Websites sollten diese Seiten sehr wenige sein, und Sie sehen möglicherweise keine KPI-Auswirkungen der Implementierung der Roboterhandhabung. Wenn Sie das Bedürfnis haben, verwenden Sie am besten eine „noindex“-Direktive, es sei denn, es gibt Suchanfragen für solche Seiten.
Markieren Sie Seiten mit dem Crawl-Budget
Problem: Unkontrolliertes Tagging verschlingt das Crawling-Budget und führt häufig zu Problemen mit dünnen Inhalten.
Suboptimale Lösungen: Verbieten mit robots.txt oder Hinzufügen eines „noindex“-Tags, da beide SEO-relevante Tags am Ranking hindern und (sofort oder irgendwann) die Weitergabe von Link-Equity verhindern.
Best-Practice-Ansatz: Bewerten Sie den Wert jedes Ihrer aktuellen Tags. Wenn die Daten zeigen, dass die Seite Suchmaschinen oder Benutzern wenig Wert bringt, leiten Sie sie per 301 weiter. Arbeiten Sie für die Seiten, die die Keulung überleben, daran, die On-Page-Elemente zu verbessern, damit sie sowohl für Benutzer als auch für Bots wertvoll werden.
Crawling von JavaScript & CSS
Problem: Bisher konnten Bots JavaScript und andere Rich-Media-Inhalte nicht crawlen. Das hat sich geändert und es wird jetzt dringend empfohlen, Suchmaschinen den Zugriff auf JS- und CSS-Dateien zu erlauben, um Seiten optional darzustellen.
Suboptimale Lösung: JavaScript- und CSS- Dateien mit robots.txt nicht zulassen, um Crawl-Budget zu sparen, kann zu einer schlechten Indexierung führen und sich negativ auf Rankings auswirken. Beispielsweise kann das Blockieren des Suchmaschinenzugriffs auf JavaScript, das eine Werbeanzeige liefert oder Benutzer umleitet, als Cloaking angesehen werden.
Best-Practice-Ansatz: Prüfen Sie mit dem Tool „Abruf wie durch Google“ auf Rendering-Probleme oder verschaffen Sie sich mit dem Bericht „Blockierte Ressourcen“ einen schnellen Überblick darüber, welche Ressourcen blockiert sind. Beides ist in der Google Search Console verfügbar. Wenn Ressourcen blockiert sind, die Suchmaschinen daran hindern könnten, die Seite richtig darzustellen, entfernen Sie die robots.txt-Sperrung.
Oncrawl SEO-Crawler
 Mehr erfahren
Mehr erfahrenBest-Practice-Roboter-Checkliste
Es kommt erschreckend häufig vor, dass eine Website versehentlich von Google durch einen Roboter entfernt wurde, der Fehler kontrolliert.
Nichtsdestotrotz kann die Handhabung von Robotern eine leistungsstarke Ergänzung Ihres SEO-Arsenals sein, wenn Sie wissen, wie man sie benutzt. Seien Sie sicher, dass Sie weise und mit Vorsicht vorgehen.
Um Ihnen dabei zu helfen, hier eine kurze Checkliste:
- Sichern Sie private Informationen durch den Passwortschutz
- Blockieren Sie den Zugriff auf Entwicklungsseiten mithilfe der serverseitigen Authentifizierung
- Beschränken Sie Crawler, die Bandbreite verbrauchen, aber wenig Wert zurückgeben, mit User-Agent-Blockierung
- Stellen Sie sicher, dass die primäre Domain und alle Subdomains eine Textdatei mit dem Namen „robots.txt“ im Verzeichnis der obersten Ebene haben, die einen 200-Code zurückgibt
- Stellen Sie sicher, dass die robots.txt-Datei mindestens einen Block mit einer User-Agent-Zeile und einer Disallow-Zeile enthält
- Stellen Sie sicher, dass die robots.txt-Datei mindestens eine Sitemap-Zeile enthält, die als letzte Zeile eingegeben wird
- Validieren Sie die robots.txt-Datei im robots.txt-Tester von GSC
- Stellen Sie sicher, dass jede indexierbare Seite ihre Robots-Tag-Anweisungen angibt
- Stellen Sie sicher, dass es keine widersprüchlichen oder redundanten Anweisungen zwischen robots.txt, Robots-Meta-Tags, X-Robots-Tags, .htaccess-Datei und GSC-Parameterbehandlung gibt
- Beheben Sie alle Fehler „Übermittelte URL als ‚noindex‘ markiert“ oder „Übermittelte URL blockiert durch robots.txt“ im GSC-Abdeckungsbericht
- Verstehen Sie den Grund für Ausschlüsse im Zusammenhang mit Robotern im GSC-Abdeckungsbericht
- Stellen Sie sicher, dass nur relevante Seiten im GSC-Bericht „Blockierte Ressourcen“ angezeigt werden
Überprüfen Sie die Handhabung Ihrer Roboter und stellen Sie sicher, dass Sie es richtig machen.